机器学习---感知机(Machine Learning Perceptron)
感知机(perceptron)是一种线性分类模型,通常用于二分类问题。感知机由Rosenblatt在1957年提出,是神经网络和支持向量机的基础。通过修改损失函数,它可以发展成支持向量机;通过多层堆叠,它可以发展成神经网络。因此,虽然现在已经不再广泛使用感知机模型了,但是了解它的原理还是有必要的。
先来举一个简单的例子。比如我们可以通过某个同学的智商和学习时间(特征)来预测其某一次的考试成绩(目标),如果考试成绩在60分以上即为及格,在60分以下为不及格。这和线性回归类似,只不过设定了一个阈值,使得其可以处理分类问题。
因此,我们定义:给定特征向量x=([x1,x2,...,xn])T以及每个特征的权重w=([w1,w2,...,wn])T,目标y共有正负两类。那么:
对于某个样本,如果其 wx > 阈值(threshold),那么将其分类到正类,记为y=+1;
如果其 wx < 阈值(threshold),那么将其分类到负类,记为y=-1;
(注:wx是特征向量和权重向量的点积/内积,wx=w1x1+w2x2+...+wnxn)
也就是说,上式分为两种情况:wx - 阈值(threshold)> 0 或 wx - 阈值(threshold)< 0。我们可以将目标方程式简写成:f(x)=sign(wx+b)。
(注:sign是符号函数)
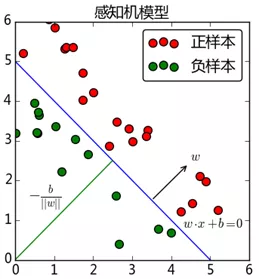
wx+b=0对应于特征空间中的一个超平面,用来分隔两个类别,其中w是超平面的法向量,b是超平面的截距。
为了便于叙述,把b并入权重向量w,记作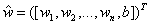 ,特征向量则扩充为
,特征向量则扩充为 。这样我们可以把目标方程式写成:
。这样我们可以把目标方程式写成: 。(为了简便的缘故,下面还是都写成f(x)=sign(wx))
。(为了简便的缘故,下面还是都写成f(x)=sign(wx))
我们希望能找出这样一个超平面(当然在二维空间是找到一条直线),使得所有样本都能分类正确。那么应该怎么做呢?一个自然的想法就是先随意初始化一个超平面,如果出现分类错误的现象,那么我们再将原来的这个超平面进行修正,直至所有样本分类正确。从一定程度上讲,人类就是如此进行学习的,发现错误即改正,所以说感知机是一个知错能改的模型。
错误分为两种情况:
一种情况是错误地将正样本(y=+1)分类为负样本(y=-1)。此时,wx<0,即w与x的夹角大于90度,因此修正的方法是让夹角变小,可以把w向量减去x向量,也就是将w修正为w+yx。
另一种情况是错误地将负样本(y=-1)分类为正样本(y=+1)。此时,wx>0,即w与x的夹角小于90度,因此修正的方法是让夹角变大,可以把w向量加上x向量,也就是将w修正为w+yx。
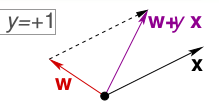

可以看到,这两种情况下修正的方式都是相同的,因此,我们可以通过不断迭代,最终使超平面做到完全分类正确。我们将PLA(Perceptron Linear Algorithm,即线性感知机算法)简单总结如下:
1,初始化w
2,找出一个分类错误点
3,修正错误,假设迭代次数为t次(t=0,1,...),那么修正公式为: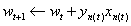
4,直至没有分类错误点,返回最终的w
下面是台湾大学林轩田老师在《Machine Learning Foundation》中提到的示例,用来说明感知机算法。
首先,用原点到x1点的向量作为wt的初始值。

分类平面与wt垂直,可以看到,有一个点x3被分类错误,本来是正类,却被分到了负类,因此我们需要使wt与x3之间的夹角变小,wt更新为wt+1。
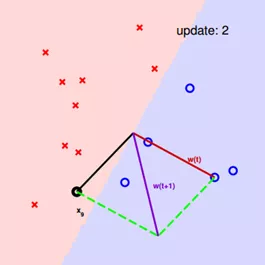
不断修正,直至完全分类正确。


从另一个角度来看,我们只要确定了参数w,也就可以找到这个分离超平面。和其他机器学习模型类似,我们首先定义损失函数,然后转化为最优化问题,可以用梯度下降等方法不断迭代,最终学习到模型的参数w。
我们很自然的会想到用错误分类点的总数来作为损失函数,也就是 ,但是根据林轩田老师所说,这是一个NP Hard问题,是无法解决的。
,但是根据林轩田老师所说,这是一个NP Hard问题,是无法解决的。
既然不能用错误分类点的总数作为损失函数,那么只能寻找其它表现形式。感知机算法选择所有错误分类点距离分离超平面的总距离作为损失函数,也就是要让错误分类点距离超平面的总长度最小。
这个总长度是怎么来的呢?
首先,输入空间Rn中任意一点x0到超平面S的距离为:
对于错误分类点(xi,yi)来说:
因此,错误分类点xi到超平面S的距离可以写成:
假设超平面的错误分类点的集合为M,那么所有的错误分类点到超平面S的总距离为:
不考虑 ||w|| ,就得到感知机学习的损失函数:
然后就是使用随机梯度下降法(SGD)不断极小化损失函数。损失函数L(w,b)的梯度由以下式子给出(对w,b分别求偏导):
随机选取一个误分类点(xi,yi),对w,b进行更新:
算法看起来很简单是吧?但是还有几个小细节我们需要考虑。
- 分离超平面是否只有一个?显然,如果我们把上面示例里的这个平面稍微倾斜一点,新的平面也还是可以完全分类正确的。也就是说,感知机算法的解不止一个,这主要取决于w初始值和分类错误点的选择。
- 使用感知机算法是否需要满足某种假设?由于感知机算法是线性分类器,因此数据必须线性可分(linear seperable),否则,感知机算法就无法找到一个完全分类正确的超平面,算法会一直迭代下去,不会停止。
- 假如数据满足线性可分这一假设,那么是否经过T次迭代,感知机算法一定能停止呢?也就是说,感知机算法最后是否一定能收敛。答案是会收敛。感知机算法收敛性的证明:http://txshi-mt.com/2017/08/03/NTUML-2-Learning-to-Answer-Yes-No/。
- 我们现在知道感知机算法最终一定会停下来,但是多久会停呢?由于T和目标参数wf有关,而wf是未知的,因此我们不知道T最大是多少。
上面讨论的是数据完美线性可分的情况,那么如果数据线性不可分呢?现实中,很多时候都存在两个分类的数据混淆在一起的情况,PLA显然解决不了这样的问题。那么怎么办呢?其实只需把感知机算法稍微修改一下,找到一个犯错最少的超平面即可。具体的做法就是在寻找的过程中把最好的超平面记住(放在口袋里),因此这被称之为口袋算法(Pocket Algorithm)。
Pocket Algorithm简单总结如下:
1,初始化w,把w作为最好的解放入口袋
2,随机找出一个分类错误点
3,修正错误,假设迭代次数为t次(t=0,1,...),那么修正公式为:
4,如果wt+1比w犯的错误少,那么用wt+1替代w
5,经过t次迭代后停止,返回口袋里最终的结果
机器学习---感知机(Machine Learning Perceptron)的更多相关文章
- 我在 B 站学机器学习(Machine Learning)- 吴恩达(Andrew Ng)【中英双语】
我在 B 站学机器学习(Machine Learning)- 吴恩达(Andrew Ng)[中英双语] 视频地址:https://www.bilibili.com/video/av9912938/ t ...
- 机器学习(Machine Learning)
机器学习(Machine Learning)是一门专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能的学科.
- Domain adaptation:连接机器学习(Machine Learning)与迁移学习(Transfer Learning)
domain adaptation(域适配)是一个连接机器学习(machine learning)与迁移学习(transfer learning)的新领域.这一问题的提出在于从原始问题(对应一个 so ...
- 学习笔记之机器学习(Machine Learning)
机器学习 - 维基百科,自由的百科全书 https://zh.wikipedia.org/wiki/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0 机器学习是人工智能的一个分 ...
- K近邻 Python实现 机器学习实战(Machine Learning in Action)
算法原理 K近邻是机器学习中常见的分类方法之间,也是相对最简单的一种分类方法,属于监督学习范畴.其实K近邻并没有显式的学习过程,它的学习过程就是测试过程.K近邻思想很简单:先给你一个训练数据集D,包括 ...
- 学习笔记之机器学习实战 (Machine Learning in Action)
机器学习实战 (豆瓣) https://book.douban.com/subject/24703171/ 机器学习是人工智能研究领域中一个极其重要的研究方向,在现今的大数据时代背景下,捕获数据并从中 ...
- 统计机器学习(statistical machine learning)
组要组成部分:监督学习(supervised learning),非监督学习(unsupervised learning),半监督学习(semi-supervised learning),强化学习(r ...
- 机器学习( Machine Learning)的定义
关于机器学习有两个相关的定义: 1)给计算机赋予没有固定编程的学习能力的研究领域. 2)一种计算机的程序,能从一些任务(T)和性能的度量(P),经验(E)中进行学习.在学习中,任务T的性能P能够随着P ...
- 机器学习(Machine Learning)算法总结-决策树
一.机器学习基本概念总结 分类(classification):目标标记为类别型的数据(离散型数据)回归(regression):目标标记为连续型数据 有监督学习(supervised learnin ...
随机推荐
- SpringBoot系列——jar包与war包的部署
前言 Spring Boot支持传统部署和更现代的部署形式.jar跟war都支持,这里参考springboot参考手册学习记录 两种方式 jar springboot项目支持创建可执行Jar,参考手册 ...
- 基于Windows服务的WCF
(1)创建WCF 代码示例: [ServiceContract] public interface ILimsDBService { [OperationContract] int ExecuteSq ...
- 【并发编程】Future模式及JDK中的实现
1.1.Future模式是什么 先简单举个例子介绍,当我们平时写一个函数,函数里的语句一行行同步执行,如果某一行执行很慢,程序就必须等待,直到执行结束才返回结果:但有时我们可能并不急着需要其中某行的执 ...
- 2014年第五届蓝桥杯javaB组 试题 答案 解析
1.武功秘籍 小明到X山洞探险,捡到一本有破损的武功秘籍(2000多页!当然是伪造的).他注意到:书的第10页和第11页在同一张纸上,但第11页和第12页不在同一张纸上. 小明只想练习该书的第81页到 ...
- 折腾Java设计模式之建造者模式
博文原址:折腾Java设计模式之建造者模式 建造者模式 Separate the construction of a complex object from its representation, a ...
- pdf文件下载水印添加的中文与空格问题解决
public static boolean waterMark(String inputFile, String outputFile, String waterMarkName)throws IOE ...
- 《JavaScript高级程序设计》笔记:DOM2和DOM3(十二)
DOM1级主要定义的是HTML和XML文档的底层结构.DOM2级和DOM3级在这个结构基础上引入了更多的交互能力,也支持更高级的XML特性.为此DOM2级和DOM3级分为了很多的模块(模块直接具有某种 ...
- go的生产者-消费者模式
package main import ( "fmt" "math/rand" "time" ) // 数据生产者 func produce ...
- 【css】一行或者多行文字垂直水平居中
1.方法一:使用css3弹性盒子(兼容IE10及以上浏览器,firefox,chrome,safari 5.1.7不支持) <!DOCTYPE html> <html> < ...
- 28 Python初学(事件驱动模型)
参考文章地址:http://www.cnblogs.com/yuanchenqi/articles/5722574.html 两个步骤: recvfrom 系统调用 : 拷贝数据 从kernel到数据 ...