python爬虫入门(六) Scrapy框架之原理介绍
Scrapy框架
Scrapy简介
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Scrapy 使用了 Twisted
['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
Scrapy架构
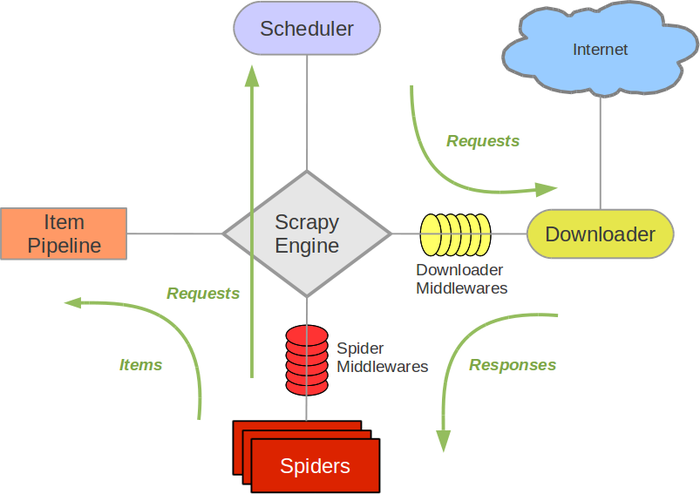
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
白话讲解Scrapy运作流程
代码写好,程序开始运行...
引擎:Hi!Spider, 你要处理哪一个网站?Spider:老大要我处理xxxx.com。引擎:你把第一个需要处理的URL给我吧。Spider:给你,第一个URL是xxxxxxx.com。引擎:Hi!调度器,我这有request请求你帮我排序入队一下。调度器:好的,正在处理你等一下。引擎:Hi!调度器,把你处理好的request请求给我。调度器:给你,这是我处理好的request引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。引擎:Hi !管道我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。管道``调度器:好的,现在就做!
制作Scrapy爬虫步骤
1.新建项目
scrapy startproject mySpider

scrapy.cfg :项目的配置文件 mySpider/ :项目的Python模块,将会从这里引用代码 mySpider/items.py :项目的目标文件 mySpider/pipelines.py :项目的管道文件 mySpider/settings.py :项目的设置文件 mySpider/spiders/ :存储爬虫代码目录
2.明确目标(mySpider/items.py)
想要爬取哪些信息,在Item里面定义结构化数据字段,保存爬取到的数据
3.制作爬虫(spiders/xxxxSpider.py)
import scrapy class ItcastSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["itcast.cn"]
start_urls = (
'http://www.itcast.cn/',
) def parse(self, response):
pass
name = "":这个爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字。allow_domains = []是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽略。start_urls = ():爬取的URL元祖/列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。parse(self, response):解析的方法,每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数,主要作用如下:
4.保存数据(pipelines.py)
在管道文件里面设置保存数据的方法,可以保存到本地或数据库
温馨提醒
第一次运行scrapy项目的时候
出现-->"DLL load failed" 错误提示,需要安装pypiwin32模块
先写个简单入门的实例
(1)items.py
想要爬取的信息
# -*- coding: utf-8 -*- import scrapy class ItcastItem(scrapy.Item):
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()
(2)itcastspider.py
写爬虫程序
#!/usr/bin/env python
# -*- coding:utf-8 -*- import scrapy
from mySpider.items import ItcastItem # 创建一个爬虫类
class ItcastSpider(scrapy.Spider):
# 爬虫名
name = "itcast"
# 允许爬虫作用的范围
allowd_domains = ["http://www.itcast.cn/"]
# 爬虫起始的url
start_urls = [
"http://www.itcast.cn/channel/teacher.shtml#",
] def parse(self, response):
teacher_list = response.xpath('//div[@class="li_txt"]')
# 所有老师信息的列表集合
teacherItem = []
# 遍历根节点集合 for each in teacher_list:
# Item对象用来保存数据的
item = ItcastItem()
# name, extract() 将匹配出来的结果转换为Unicode字符串
# 不加extract() 结果为xpath匹配对象
name = each.xpath('./h3/text()').extract()
# title
title = each.xpath('./h4/text()').extract()
# info
info = each.xpath('./p/text()').extract() item['name'] = name[0].encode("gbk")
item['title'] = title[0].encode("gbk")
item['info'] = info[0].encode("gbk") teacherItem.append(item) return teacherItem
输入命令:scrapy crawl itcast -o itcast.csv 保存为 ".csv"的格式
管道文件pipelines.py的用法
(1)setting.py修改
ITEM_PIPELINES = {
#设置好在管道文件里写的类
'mySpider.pipelines.ItcastPipeline': 300,
}
(2)itcastspider.py
#!/usr/bin/env python
# -*- coding:utf-8 -*- import scrapy
from mySpider.items import ItcastItem # 创建一个爬虫类
class ItcastSpider(scrapy.Spider):
# 爬虫名
name = "itcast"
# 允许爬虫作用的范围
allowd_domains = ["http://www.itcast.cn/"]
# 爬虫其实的url
start_urls = [
"http://www.itcast.cn/channel/teacher.shtml#aandroid", ] def parse(self, response):
#with open("teacher.html", "w") as f:
# f.write(response.body)
# 通过scrapy自带的xpath匹配出所有老师的根节点列表集合
teacher_list = response.xpath('//div[@class="li_txt"]') # 遍历根节点集合
for each in teacher_list:
# Item对象用来保存数据的
item = ItcastItem()
# name, extract() 将匹配出来的结果转换为Unicode字符串
# 不加extract() 结果为xpath匹配对象
name = each.xpath('./h3/text()').extract()
# title
title = each.xpath('./h4/text()').extract()
# info
info = each.xpath('./p/text()').extract() item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0] yield item
(3)pipelines.py
数据保存到本地
# -*- coding: utf-8 -*-
import json class ItcastPipeline(object):
# __init__方法是可选的,做为类的初始化方法
def __init__(self):
# 创建了一个文件
self.filename = open("teacher.json", "w") # process_item方法是必须写的,用来处理item数据
def process_item(self, item, spider):
jsontext = json.dumps(dict(item), ensure_ascii = False) + "\n"
self.filename.write(jsontext.encode("utf-8"))
return item # close_spider方法是可选的,结束时调用这个方法
def close_spider(self, spider):
self.filename.close()
(4)items.py
# -*- coding: utf-8 -*- import scrapy class ItcastItem(scrapy.Item):
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()
python爬虫入门(六) Scrapy框架之原理介绍的更多相关文章
- Python爬虫入门六之Cookie的使用
大家好哈,上一节我们研究了一下爬虫的异常处理问题,那么接下来我们一起来看一下Cookie的使用. 为什么要使用Cookie呢? Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在 ...
- Python爬虫进阶之Scrapy框架安装配置
Python爬虫进阶之Scrapy框架安装配置 初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此 ...
- python爬虫学习之Scrapy框架的工作原理
一.Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网 ...
- 爬虫入门之Scrapy 框架基础功能(九)
Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非 ...
- 零基础写python爬虫之使用Scrapy框架编写爬虫
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻 ...
- PYTHON 爬虫笔记十一:Scrapy框架的基本使用
Scrapy框架详解及其基本使用 scrapy框架原理 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了 ...
- python 爬虫相关含Scrapy框架
1.从酷狗网站爬取 新歌首发的新歌名字.播放时长.链接等 from bs4 import BeautifulSoup as BS import requests import re import js ...
- Python爬虫知识点四--scrapy框架
一.scrapy结构数据 解释: 1.名词解析: o 引擎(Scrapy Engine)o 调度器(Scheduler)o 下载器(Downloader)o 蜘蛛(Spiders)o 项目管 ...
- 芝麻HTTP:Python爬虫进阶之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
随机推荐
- Gradle 1.12翻译——第二十章. 构建环境
有关其他已翻译的章节请关注Github上的项目:https://github.com/msdx/gradledoc/tree/1.12,或访问:http://gradledoc.qiniudn.com ...
- 4.2、Libgdx各个模块概览
(原文:http://www.libgdx.cn/topic/34/4-2-libgdx%E5%90%84%E4%B8%AA%E6%A8%A1%E5%9D%97%E6%A6%82%E8%A7%88) ...
- VMware中安装系统提示没有可用的映像(No image available)
今天新建了个虚机在装系统的时候提示"没有可用的映像" 之所以会出现这种情况是因为在新建虚机的时候选择的设置不同导致的,此处不管选第一项还是第二项都会虚机设置中多了一个软盘的配置项, ...
- ORACLE收集统计信息
1. 理解什么是统计信息 优化器统计信息就是一个更加详细描述数据库和数据库对象的集合,这些统计信息被用于查询优化器,让其为每条SQL语句选择最佳的执行计划.优化器统计信息包括: · ...
- OpenCV特征点检测算法对比
识别算法概述: SIFT/SURF基于灰度图, 一.首先建立图像金字塔,形成三维的图像空间,通过Hessian矩阵获取每一层的局部极大值,然后进行在极值点周围26个点进行NMS,从而得到粗略的特征点, ...
- 【一天一道LeetCode】#25. Reverse Nodes in k-Group
一天一道LeetCode系列 (一)题目 Given a linked list, reverse the nodes of a linked list k at a time and return ...
- (视频)《快速创建网站》2.1 在Azure上创建网站及网站运行机制
现在让我们开始一天的建站之旅. 本文是<快速创建网站>系列的第2篇,如果你还没有看过之前的内容,建议你点击以下目录中的章节先阅读其他内容再回到本文. 1. 网站管理平台WordPress和 ...
- PDA(Windows Mobile)调用远程WebService
之前用模拟器测试过调用远程的WebService,发现总是提示"无法连接到远程服务器"的错误,不管是Windows Mobile6.0 还是6.5都是一样,按照网上的办法,改注册表 ...
- 我所理解的Android 启动模式
首先,这是从 一个开源网站转载的,觉得写得不错,对我们之前理解的activity的启动模式是一个新的理解方式,并给出实际的应用场景. 任务栈是什么 任务栈Task,是一种用来放置Activity实例的 ...
- 安卓Eclipse开发者的福音
我们知道,谷歌已经放弃对Eclipse(ADT)的维护更新了,现在官网上也找不到ADT的下载链接了,我们大多数同学仍在使用的ADT版本可能已经很老了,估计大多数的SDK版本只到4.4,而,在尝试升级以 ...