urllib,request 设置代理
通常防止爬虫被反主要有以下几个策略:
1.动态设置User-Agent(随机切换User-Agent,模拟不同用户的浏览器信息)
2.使用IP地址池:VPN和代理IP,现在大部分网站都是根据IP来ban的。
3.禁用Cookies(也就是不启用cookies middleware,不向Server发送cookies,有些网站通过cookie的使用发现爬虫行为)
4.可以通过COOKIES_ENABLED 控制 CookiesMiddleware 开启或关闭
5.设置延迟下载(防止访问过于频繁,设置为 2秒 或更高)要明白爬虫重要的是拿到数据。
6.Google Cache 和 Baidu Cache:如果可能的话,使用谷歌/百度等搜索引擎服务器页面缓存获取页面数据。
7.使用 Crawlera(专用于爬虫的代理组件),正确配置和设置下载中间件后,项目所有的request都是通过crawlera发出。
反爬第一招,动态设置User-Agent:
怎么动态设置?其实就是事先准备一堆User-Agent.每次发送请求时就从中间随机选取一个。有些网站反爬检查user-agent的话就可以骗过去了。
采用 random随机模块的choice方法随机选择User-Agent,这样每次请求都会从中选择,请求很频繁的话就多找几个user-agent。
def load_page(url, form_data):
USER_AGENTS = [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5"
] user_agent = random.choice(USER_AGENTS) headers = {
'User-Agent':user_agent
}
#!/usr/bin/env python3
# -*- coding=utf-8 -*-
import urllib2
import urllib
import json
import random def parser(args):
data = json.load(args)
print data['translateResult'][0][0]['tgt'] def load_page(url, form_data):
USER_AGENTS = [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5"
] user_agent = random.choice(USER_AGENTS)
print user_agent
headers = {
'User-Agent':user_agent
} form_data = urllib.urlencode(form_data)
request = urllib2.Request(url, data=form_data, headers=headers)
request.add_header('Referer','http://fanyi.youdao.com/')
request.add_header('Connection','keep-alive')
request.add_header('Host','fanyi.youdao.com')
request.add_header('Host','fanyi.youdao.com')
request.add_header('Cookie','OUTFOX_SEARCH_USER_ID_NCOO=1025239439.503166; _ga=GA1.2.1461890182.1495089101; OUTFOX_SEARCH_USER_ID=-1839555294@113.116.87.174; JSESSIONID=aaa5jeP7FUzLkcsJTGU6v; ___rl__test__cookies=1506169229935')
result = urllib2.urlopen(request)
return result def translate(words):
form_data = {'i':words,
'from':'AUTO',
'to':'AUTO',
'smartresult':'dict',
'client':'fanyideskweb',
'salt':'',
'sign':'2755425d7a2f9ebd79a8fdd94d1a3af0',
'doctype':'json',
'version':'2.1',
'keyfrom':'fanyi.web',
'action':'FY_BY_REALTIME',
'typoResult':'true'} base_url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule' result = load_page(base_url, form_data)
parser(result) def main():
while True:
kw = raw_input('请输入需要翻译的单词:')
translate(kw) if __name__ == "__main__":
main()
实例代码有道翻译:
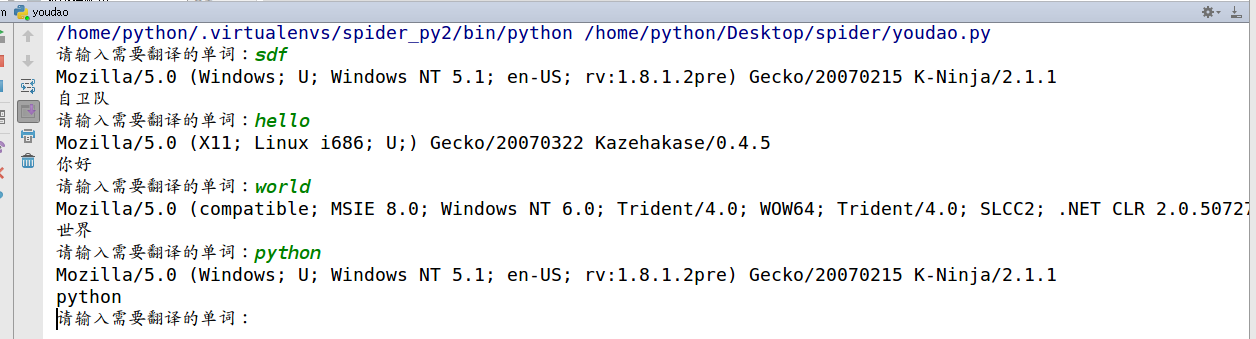
反爬第二招,使用代理IP,这是爬虫/反爬虫的第二大招,通常也是最好用的。
很多网站会检测某一段时间某个IP的访问次数(通过流量统计,系统日志等),如果访问次数多的不像正常人,它会禁止这个IP的访问。
所以我们可以设置一些代理服务器,每隔一段时间换一个代理,就算IP被禁止,依然可以换个IP继续爬取。
urllib2中通过ProxyHandler来设置使用代理服务器
ProxyHandler处理器(代理设置): 这样就设置了一个无需认证的代理
import urllib2
#设置一个代理hander
httpproxy_handler = urllib2.ProxyHandler({"http" : "124.88.67.81:80"}) opener = urllib2.build_opener(httpproxy_handler) request = urllib2.Request("http://www.baidu.com/") response = opener.open(request) print response.read()
如果代理IP足够多,就可以随机选择一个代理去访问网站。
import urllib2
import random proxy_list = [
{"http" : "124.88.67.81:80"},
{"http" : "124.88.67.81:80"},
{"http" : "124.88.67.81:80"},
{"http" : "124.88.67.81:80"},
{"http" : "124.88.67.81:80"}
] # 随机选择一个代理
proxy = random.choice(proxy_list)
# 使用选择的代理构建代理处理器对象
httpproxy_handler = urllib2.ProxyHandler(proxy) opener = urllib2.build_opener(httpproxy_handler) request = urllib2.Request("http://www.baidu.com/")
response = opener.open(request)
print response.read()
( ProxyHandler 代理授权验证)
上面都是一些免费代理写法,下面这个是付费代理写法:
proxy = urllib2.ProxyHandler({"http":"账号:密码@143.226.164.130:16816"})
opener = urllib2.build_opener(proxy)
repsonse = opener.open(url)
print repsonse.read()
requset 模块设置代理方法:
request 模块比较简单。
普通代理
import requests # 根据协议类型,选择不同的代理
proxies = {
"http": "http://12.34.56.79:9527",
"https": "http://12.34.56.79:9527",
} response = requests.get("http://www.baidu.com", proxies = proxies)
print response.text
私密代理
import requests # 如果代理需要使用HTTP Basic Auth,可以使用下面这种格式:
proxy = { "http": "账号:密码@61.158.163.130:16816" } response = requests.get("http://www.baidu.com", proxies = proxy) print response.text
没钱买代理?免费代理来搞定(便宜没好货,这个是真理),免费代理不稳定,速度慢,要是公司用老兄赶紧让你老板买代理去(没有金刚钻,怎么揽瓷器活),
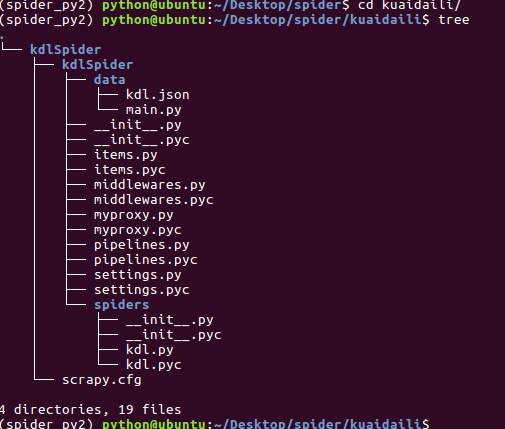
好吧,要是个人玩玩的自己 去爬点免费代理来用用。你老哥我用scrapy写来了个爬取快代理的ip。如果你懒得写的话,copy将就着用吧。里面的代理应该用不了,自己去找几个替换了玩玩!爬下来的数据存在了 data/kdl.json
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html import scrapy class KdlspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
ip = scrapy.Field()
port = scrapy.Field()
type = scrapy.Field()
items
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json class KdlspiderPipeline(object):
def __init__(self):
self.filename = open('kdl.json','w') def process_item(self, item, spider):
self.filename.write(json.dumps(dict(item))+",\n")
return item def spider_close(self):
self.filename.close()
Pipelines
# -*- coding: utf-8 -*-
import scrapy
from kdlSpider.items import KdlspiderItem class KdlSpider(scrapy.Spider):
name = "kdl"
allowed_domains = ["kuaidaili.com"]
base_url = 'http://www.kuaidaili.com/free/inha/'
offset = 1
start_urls = [base_url+str(offset)+"/"] def parse(self, response):
ip_list = response.xpath('//tr/td[@data-title="IP"]/text()')
port_list = response.xpath('//tr/td[@data-title="PORT"]/text()')
type_list = response.xpath(u'//tr/td[@data-title="类型"]/text()')
for ip,port,type in zip(ip_list,port_list,type_list):
item = KdlspiderItem()
item['ip'] = ip.extract()
item['port'] = port.extract()
item['type'] = type.extract()
yield item
self.offset += 1
if self.offset < 1864:
yield scrapy.Request(self.base_url+str(self.offset),callback=self.parse)
kdl
# -*- coding=utf-8 -*- import random
from myproxy import PROXY
import base64
from settings import USER_AGENTS class RandomUserAgentMiddleware(object): def process_request(self,request,spider):
user_agent = random.choice(USER_AGENTS)
request.headers.setdefault('User-Agent', user_agent) class ProxyMiddleware(object): def process_request(self,request,spider):
# 免认证代理
random_proxy = random.choice(PROXY)
request.meta['proxy']='http://'+random_proxy['ip_port'] # 需要认证代理写法
# proxy = "116.62.128.50:16816"
# request.meta["proxy"] = "http://" + proxy
# proxy_user_passwd = "代理账号:代理密码"
# base64_user_passwd = base64.b64encode(proxy_user_passwd)
# request.headers["Proxy-Authorization"] = "Basic " + base64_user_passwd
middlewares
# -*- coding: utf-8 -*- # Scrapy settings for kdlSpider project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html BOT_NAME = 'kdlSpider' SPIDER_MODULES = ['kdlSpider.spiders']
NEWSPIDER_MODULE = 'kdlSpider.spiders' USER_AGENTS = [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.104 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36 QIHU 360SE",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"
] # Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'kdlSpider (+http://www.yourdomain.com)' # Obey robots.txt rules
# ROBOTSTXT_OBEY = True # Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
# DOWNLOAD_DELAY = 5
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default)
COOKIES_ENABLED = False # Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False # Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.104 Safari/537.36',
'Host':'www.kuaidaili.com',
} # Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'kdlSpider.middlewares.MyCustomSpiderMiddleware': 543,
#} # Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'kdlSpider.middlewares.RandomUserAgentMiddleware': 543,
'kdlSpider.middlewares.ProxyMiddleware':250,
} # Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#} # Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'kdlSpider.pipelines.KdlspiderPipeline': 300,
} # Enable and configure the AutoThrottle extension (disabled by default)
# See http://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default)
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
settings
urllib,request 设置代理的更多相关文章
- 网络爬虫之scrapy框架设置代理
前戏 os.environ()简介 os.environ()可以获取到当前进程的环境变量,注意,是当前进程. 如果我们在一个程序中设置了环境变量,另一个程序是无法获取设置的那个变量的. 环境变量是以一 ...
- 爬虫入门【1】urllib.request库用法简介
urlopen方法 打开指定的URL urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, ca ...
- requests与urllib.request
requests很明显,在写法上与urllib.request不同,前者多一个 S.导入包时:import requestsimport urllib.requesturllib.request请求模 ...
- python urllib.request
一.简介 urllib.request 模块提供了访问 URL 的相关功能 二.常用函数 urllib.request.urlopen("http://httpbin.org", ...
- Handler处理器&&使用代理服务器urllib.request.ProxyHandler
urllib.request.urlopen(url) 不能定制请求头 urllib.request.Request(url,headers,data) 可以定制请求头 Handler 定制更高级的 ...
- 关于python requests包新版本设置代理的问题
在更新了requests包之后,发现我电脑上的charles工具无法再成功抓取到数据包.百度了半年都没有找到原因. 然后 我使用了 google 查到了 charles的最新的文档发现.需要设置代理, ...
- HttpHelps类,用来实现Http访问,Post或者Get方式的,直接访问,带Cookie的,带证书的等方式,可以设置代理
原文地址:http://blog.csdn.net/cdefg198/article/details/8315438 万能框架:http://www.sufeinet.com/forum.php?mo ...
- crawler_java应用集锦9:httpclient4.2.2的几个常用方法,登录之后访问页面问题,下载文件_设置代理
在工作中要用到android,然后进行网络请求的时候,打算使用httpClient. 总结一下httpClient的一些基本使用. 版本是4.2.2. 使用这个版本的过程中,百度很多,结果都是出现的o ...
- python3.6 urllib.request库实现简单的网络爬虫、下载图片
#更新日志:#0418 爬取页面商品URL#0421 更新 添加爬取下载页面图片功能#0423 更新 添加发送邮件功能# 优化 爬虫异常处理.错误页面及空页面处理# 优化 爬虫关键字黑名单.白名单,提 ...
随机推荐
- 什么是MQTT协议?
MQTT协议介绍 MQTT协议是什么? MQTT(Message Queuing Telemetry Transport Protocol)的全称是消息队列遥感传输协议的缩写,是一种基于轻量级代理的发 ...
- SpringCloud的服务注册中心(二)注册中心服务端和两个微服务应用客户端
一.构建EurekaServer工程 1.pom.xml 2.application.yml 3. EurekaServerApp.java 4.启动EurekaServer 二.构建部署 Eurek ...
- Spark-1.X编译构建及配置安装
前提条件(环境要求) jdk版本:1.7+ scala版本:1.10.4+ maven版本:3.3.3+ 本博客中使用的软件版本 spark版本:spark-1.6.1.tar.gz(源码) jdk版 ...
- 使用nodeJS的 crypto模块来为你的密码hash加盐
这篇文章将向你解释如何使用Node.js的Crypto模块对你的密码进行加盐hash.在这里,我们将不会对不懂的密码存储方式进行详细的比较.我们将要做的是知道在Node.js中使用加盐hash在进行密 ...
- hdu 6205 card card card
https://vjudge.net/contest/184514#problem/L题意:排成一行的一堆牌,每堆牌都有一定数量的牌,然后每堆牌对应有一个惩罚值.一开始所有的牌都是正面向下的,并且在游 ...
- spark2.1:在RDD[unit].foreach(s=>{})内部调用sparkSession对象抛出NullPointException
问题代码: val sample_data_combine_result=List( (0,(List(FitModel(4022,1447.92,-8.38983306721434,2.0),Fit ...
- scrapy爬取全部知乎用户信息
# -*- coding: utf-8 -*- # scrapy爬取全部知乎用户信息 # 1:是否遵守robbots_txt协议改为False # 2: 加入爬取所需的headers: user-ag ...
- [JCIP笔记](四)踩在巨人的肩上
读完第三章那些繁琐的术语和细节,头疼了整整一个星期.作者简直是苦口婆心,说得我如做梦一般.然而进入第四章,难度骤然降低,仿佛坐杭州的过山公交车突然下坡,鸟鸣花香扑面而来,看到了一片西湖美景. 从开始看 ...
- Oracle表空间的管理方式
解释说明:表空间是一个逻辑概念:=> oracle 逻辑概念段区块管理方式: number one => tablespace number two=> segments Oracl ...
- 遗传算法详解(LINGO及MatlabGA工具箱求解实现)
遗传算法 1.前言 遗传算法是一种基于生物界自然群体遗传进化机制的自适应全局优化概率搜索算法.它与传统算法不同,不依赖梯度信息,而是通过模拟自然进化过程来搜索最优解. 例子:兔子的遗传进化 有人说,现 ...