主成分分析(PCA)学习笔记
这两天学习了吴恩达老师机器学习中的[主成分分析法](https://study.163.com/course/courseMain.htm?courseId=1004570029)(Principal Component Analysis, PCA),PCA是一种常用的降维方法。这里对PCA算法做一个小笔记,并利用python完成对应的练习(ps:最近公式有点多,开始没找到怎么敲公式,前面几篇都是截的图^_^,后面问了度娘,原来是支持latex的)。代码和数据见[github](https://github.com/zhoujinhai/pca)
一、PCA基本思路
将数据从原来的坐标系转换到新的坐标系,新坐标系的选择由数据本身决定。第一个新坐标轴选择的是原始数据中方差最大的方向,第二个新坐标轴选择的是和第一个坐标轴正交且具有最大方差的方向,依次类推,直到找出\(k\)个新坐标轴。也就是将原始数据投影到一个低维的坐标系中。
二、PCA目标函数
以最小化投影误差为目标函数,这里注意与线性回归的区别,线性回归是最小化垂直距离。下图左边图中蓝线是线性回归的目标,右图中蓝线是PCA的目标。
三、PCA算法步骤
1、数据预处理,数据维度为 $ m*n $ 。
对 $ X= x^{(1)}, x^{(2)}, ... , x^{(m)} $ 计算平均值和方差,$$ u_j = \frac{1}{m}\sum_{i=1}{m}x_j{(i)} $$ $$ s_j = \frac{1}{m}\sum_{i=1}{m}(x_j{(i)}-u_j)^2 $$
对原始数据进行归一化处理得到 $$ x_j = \frac{x_j-u_j}{s_j} $$
其中 $ u_j $ 表示均值, $ s_j $ 表示方差。
2、计算协方差矩阵 $ \Sigma $ 。
\]
其中 $ x^{(i)} $ 是 $ n \times 1 $ 维的,则其转秩是$ 1 \times n $ 维的,所以 $ \Sigma $ 是 $ n \times n $ 维的。
3、对 $ \Sigma $ 进行奇异值分解。
\]
奇异值分解可以参考博客,博主讲的比较清楚。上式中
\]
从中选取 $ k $ 个主要成分
\]
则 $ x^{(i)} $ 在新坐标上的投影可以表示为
u^{(1)}\\
u^{(2)}\\
\vdots \\
u^{(k)}\\
\end{bmatrix}\cdot x^{(i)} \]
其中 $ U_k $ 是 $ k \times n $ 维的,其转秩为 $ n \times k $ 维的,$ x^{(i)} $ 是 $ n \times 1 $ 维,所以 $ z^{(i)} $ 是 $ k \times 1 $ 维的。投影 $ Z $ 可以表示为
\]
4、计算重构后特征 $ x_{approx}^{(i)} $ 。
\]
其中 $ U_k $ 是 $ n \times k $ 维,$ z^{(i)} $ 是 $ k \times 1 $ 维,则 $ x_{approx}^{(i)} $ 是 $ n \times 1 $ 维。
5、根据投影误差检验选择的 $ k $ 个主要成分是否满足要求。
\]
如果不满足上式,则从步骤3中重新选择 $ k $ 个主成分,继续第4和第5步,直到满足要求为止。小于等于0.01表明保留了原始数据99%信息,这里可以根据需求进行更改。
这里如果不用奇异值分解后的 $ U $ 矩阵,也可以根据奇异值矩阵 $ S $ 计算 ,$ S $ 是主对角线上为从大到小排列的奇异值,其他元素全为0的对角矩阵。
\]
PCA应用实例
1、二维数据投影到一维,熟悉PCA流程
第一步 引入相关库并导入数据
from scipy.io import loadmat
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data1 = loadmat('./ex7/ex7data1.mat')
data1

X = data1['X']
X.shape

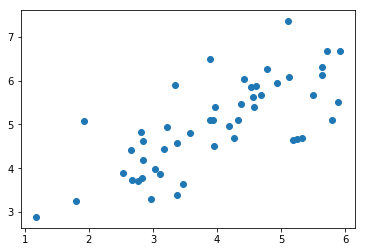
原始数据展示
plt.scatter(X[:,0], X[:,1])
plt.show()
第二步 数据预处理
# 定义归一化函数featureNormalize
def featureNormalizse(x):
mean = x.mean(axis=0)
std = x.std(axis=0)
return (x-mean)/std, mean, std
# test
x_norm, means, stds = featureNormalizse(X)
x_norm[:5]

第三步 计算协方差矩阵
print(x_norm.shape)
sigma = (x_norm.T.dot(x_norm))/x_norm.shape[0]
sigma

第四步 奇异值分解
U,S,V = np.linalg.svd(sigma)
U,S,V

# 整合sigma和svd
def pca(x):
sigma = (x.T.dot(x))/x.shape[0]
U,S,V = np.linalg.svd(sigma)
return U,S,V
可视化主成分
x_norm, means, stds = featureNormalizse(X)
U, S, V = pca(x_norm)
plt.figure(figsize=(8, 6))
plt.scatter(X[:,0], X[:,1], label='sample data') # 样本数据点
plt.plot([means[0], means[0] + 1.5*S[0]*U[0,0]],
[means[1], means[1] + 1.5*S[0]*U[0,1]],
c='r', linewidth=3, label='First Principal Component') # 第一个成分
plt.plot([means[0], means[0] + 1.5*S[1]*U[1,0]],
[means[1], means[1] + 1.5*S[1]*U[1,1]],
c='g', linewidth=3, label='Second Principal Component') # 第二个成分
plt.grid()
plt.axis("equal")
plt.legend()
plt.show()

第五步 计算 $ x_{approx} $
# 根据U_reduce计算x_norm的投影Z
def compute_z(X, U, k):
Z = X.dot(U[:,:k])
return Z
# test
Z = compute_z(x_norm, U, 1)
Z[:5]

# 计算x_approx
def compute_x_approx(U, k, Z):
x_approx = Z.dot(U[:,:k].T) # 50*1 * 1*2
return x_approx
# test
x_approx = compute_x_approx(U, 1, Z)
x_approx[:5]

第六步 可视化投影效果
plt.figure(figsize=(8,6))
plt.axis("equal")
plot = plt.scatter(x_norm[:,0], x_norm[:,1], s=30, facecolors='none',
edgecolors='b',label='Original Data Points') # 画出归一化后原始样本点
plot = plt.scatter(x_approx[:,0], x_approx[:,1], s=30, facecolors='none',
edgecolors='r',label='PCA Reduced Data Points') # 画出经过PCA后构造的估计值
plt.title("Example Dataset: Reduced Dimension Points Shown",fontsize=14)
plt.xlabel('x1 [Feature Normalized]',fontsize=14)
plt.ylabel('x2 [Feature Normalized]',fontsize=14)
plt.grid(True)
for x in range(x_norm.shape[0]): # 画出变换前后的连线
plt.plot([x_norm[x,0],x_approx[x,0]],[x_norm[x,1],x_approx[x,1]],'k--')
# 输入第一项全是X坐标,第二项都是Y坐标
plt.legend()
plt.show()

2、利用PCA减少图片维度
第一步 导入数据
# 导入数据
face_data = loadmat('./ex7/ex7faces.mat')
face = face_data['X']
face.shape
第二步 展示数据
def showFace(X, row, col):
fig, axs = plt.subplots(row, col, figsize=(8,8))
for r in range(row):
for c in range(col):
axs[r][c].imshow(X[r*col + c].reshape(32,32).T, cmap = 'Greys_r')
axs[r][c].set_xticks([])
axs[r][c].set_yticks([])
showFace(face, 10, 10)
plt.show()

第三步 降维并重构
face_norm, means, stds = featureNormalizse(face) # 归一化
U, S, V = pca(face_norm) # 奇异值分解
Z = compute_z(face_norm, U, 16) # 计算Z
face_approx = compute_x_approx(U, 16, Z) # 计算降维重构后的数据
face_approx.shape

第四步 前后对比图
showFace(face, 10, 10)
showFace(face_approx, 10, 10)
plt.show()


主成分分析(PCA)学习笔记的更多相关文章
- PCA学习笔记
主成分分析(Principal Component Analysis,简称PCA)是最常用过的一种降维方法 在引入PCA之前先提到了如何使用一个超平面对所有的样本进行恰当的表达? 即若存在这样的超平面 ...
- 机器学习之主成分分析PCA原理笔记
1. 相关背景 在许多领域的研究与应用中,通常需要对含有多个变量的数据进行观测,收集大量数据后进行分析寻找规律.多变量大数据集无疑会为研究和应用提供丰富的信息,但是也在一定程度上增加了数据采集的 ...
- 机器学习13—PCA学习笔记
主成分分析PCA 机器学习实战之PCA test13.py #-*- coding:utf-8 import sys sys.path.append("pca.py") impo ...
- 数据降维PCA——学习笔记
PCA主成分分析 无监督学习 使方差(数据离散量)最大,更易于分类. 可以对隐私数据PCA,数据加密. 基变换 投影->内积 基变换 正交的基,两个向量垂直(内积为0,线性无关) 先将基化成各维 ...
- 主成分分析PCA学习一条龙
转自:https://yoyoyohamapi.gitbooks.io/mit-ml/content/%E7%89%B9%E5%BE%81%E9%99%8D%E7%BB%B4/articles/PCA ...
- LDA PCA 学习笔记
提要: 本文主要介绍了和推导了LDA和PCA,参考了这篇博客 LDA LDA的原理是,将带上标签的数据(点),通过投影的方法,投影到维度更低的空间中,使得投影后的点,会形成按类别区分,一簇一簇的情况, ...
- PCA 学习笔记
先简单记下,等有时间再整理 PCA 主要思想,把 协方差矩阵 对角化,协方差矩阵是实对称的.里面涉及到矩阵论的一点基础知识: 基变换: Base2 = P · Base1 相应的 坐标变换 P · c ...
- 深度学习入门教程UFLDL学习实验笔记三:主成分分析PCA与白化whitening
主成分分析与白化是在做深度学习训练时最常见的两种预处理的方法,主成分分析是一种我们用的很多的降维的一种手段,通过PCA降维,我们能够有效的降低数据的维度,加快运算速度.而白化就是为了使得每个特征能有同 ...
- 机器学习实战(Machine Learning in Action)学习笔记————09.利用PCA简化数据
机器学习实战(Machine Learning in Action)学习笔记————09.利用PCA简化数据 关键字:PCA.主成分分析.降维作者:米仓山下时间:2018-11-15机器学习实战(Ma ...
- 机器学习降维方法概括, LASSO参数缩减、主成分分析PCA、小波分析、线性判别LDA、拉普拉斯映射、深度学习SparseAutoEncoder、矩阵奇异值分解SVD、LLE局部线性嵌入、Isomap等距映射
机器学习降维方法概括 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/u014772862/article/details/52335970 最近 ...
随机推荐
- 【BZOJ1814】Ural 1519 Formula 1 插头DP
[BZOJ1814]Ural 1519 Formula 1 题意:一个 m * n 的棋盘,有的格子存在障碍,求经过所有非障碍格子的哈密顿回路个数.(n,m<=12) 题解:插头DP板子题,刷板 ...
- How are you vs How are you doing
How are you与How are you doing,有何不同呢? 貌似没有不同…… 中国教科书式的回答是"Fine, thank you, and you?" 随便一点&q ...
- 在 arc里面打印 引用计数的方法
查阅资料: You can use CFGetRetainCount with Objective-C objects, even under ARC: NSLog(@"Retain c ...
- Spark2 ML包之决策树分类Decision tree classifier详细解说
所用数据源,请参考本人博客http://www.cnblogs.com/wwxbi/p/6063613.html 1.导入包 import org.apache.spark.sql.SparkSess ...
- AllowOverride None
PHP Advanced and Object-Oriented Programming Larry Ullman <Directory /> AllowOverride None < ...
- iOS多线程编程之自定义NSOperation(转载)
一.实现一个简单的tableView显示效果 实现效果展示: 代码示例(使用以前在主控制器中进行业务处理的方式) 1.新建一个项目,让控制器继承自UITableViewController. 1 // ...
- Frogger--poj2253
http://poj.org/problem?id=2253 题意:The frog distance (humans also call it minimax distance) between t ...
- oracle查询表结构语句
select o.table_name, tmp.comments, o.COLUMN_NAME, t.comments, o.DATA_TYPE || CASE TRIM(o.DATA_TYPE) ...
- [.NET]解决EMF图像自动放大空白
在.NET中产生emf主要使用Metafile对象,但在使用过程中会发生图像自动放大,多余空白的问题. 模拟:声明Size(100,100)的区域,并绘制p1(-50,-50)->p2(50,5 ...
- Windows操作系统上各种服务使用的端口号, 以及它们使用的协议的列表
Windows操作系统上各种服务使用的端口号, 以及它们使用的协议的列表 列表如下 Port Protocol Network Service System Service System Servic ...