pandas简单应用
机器学习离不开数据,数据分析离不开pandas。昨天感受了一下,真的方便。按照一般的使用过程,将pandas的常用方法说明一下。
首先,我们拿到一个excel表,我们将之另存为csv文件。因为文件是实验室的资源,我就不分享了。
首先是文件读取
def load_csv(filename):
data=pd.read_csv(filename)
data = data.drop(data.columns[39:], axis=1)
return data
我们调用read_csv文件可以直接读取csv文件。其返回值为DataFrame。excel如果横向拖动太多的话,会生成很多空列。这里我们通过drop方法删掉39列之后的列。
然后pandas为了让显示美观,会在输出信息的时候自动隐藏数据。我们调整参数,使数据全部显示。
pd.set_option('display.max_rows', 10)
pd.set_option('display.max_columns', 500)
pd.set_option('display.width', 500)
设置最多显示10行,500列。宽度为500.
使用 data.head()可以查看前4行的数据。
print(data.head())

可以看到全部数据都被显示出来了。然后我们可以使用data.info() ,data.discribe()、data.count()查看数据的整体信息。
print(data.info())
print(data.describe())
print(data.count())
data.info()显示的是:

data.describe()显示的是:
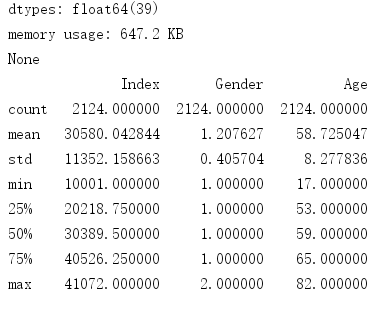
data.count()显示的是:

可以看到数据的值跨度很大,所以我们对数据进行normalization:
keys=X.keys().tolist()
keys.remove("Index")
keys.remove("Label") for key in keys:
#将数值范围限定在-0.5~0.5
#normalize_col=(X[key]-(X[key].max()+X[key].min())/2)/(X[key].max()-X[key].min())
#用mean来normolize
normalize_col = (X[key] - X[key].mean()) / (X[key].max() - X[key].min())
X = X.drop(key, axis=1)
X[key]=normalize_col
我们可以通过keys中列名来有选择的进行归一化处理。
有时候,有的不和规范的数据我们想删掉:
#删掉JiGan为-1的人
data = data[data["JiGan"].isin([-1.0]) == False]
数据筛选还有其他函数,用到了在慢慢补充吧。
pandas简单应用的更多相关文章
- python之pandas简单介绍及使用(一)
python之pandas简单介绍及使用(一) 一. Pandas简介1.Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据 ...
- numpy和pandas简单使用
numpy和pandas简单使用 import numpy as np import pandas as pd 一维数据分析 numpy中使用array, pandas中使用series numpy一 ...
- 数据处理之pandas简单介绍
Offical Website :http://pandas.pydata.org/ 一:两种基本的数据类型结构 Series 和 DataFrame 先来看一下Series import panda ...
- [Python]Pandas简单入门(转)
本篇文章转自 https://colab.research.google.com/notebooks/mlcc/intro_to_pandas.ipynb?hl=zh-cn#scrollTo=zCOn ...
- Python Pandas 简单使用之 API熟悉
1.read_csv li_index = ['round_id', 'index', 'c-sequen' ] dataset = pd.read_csv(file, low_memory=Fals ...
- python pandas简单使用处理csv文件
这里jira.csv是个大文件 1) >>> import pandas >>> jir=pandas.read_csv(r'C:\Temp\jira.csv') ...
- \(\rm LightOJ 1371 - Energetic Pandas 简单计数+组合\)
http://www.lightoj.com/volume_showproblem.php?problem=1371 题意:给你n根竹子,和n只熊猫(XD),每个熊猫只能选择重量不大于它的竹子,问有几 ...
- Pandas简单操作(学习总结)
Pandas 的主要数据结构是 Series (一维数据)与 DataFrame(二维数据),是一个提供高性能.易于使用的数据结构和数据分析工具. 接下来查看Pandas的基本使用: # 导入模块 i ...
- Pandas模块:表计算与数据分析
目录 Pandas之Series Pandas之DataFrame 一.pandas简单介绍 1.pandas是一个强大的Python数据分析的工具包.2.pandas是基于NumPy构建的. 3.p ...
随机推荐
- linux达人养成计划学习笔记(四)—— 压缩命令
一.常见的压缩格式: 二..zip格式压缩 1.压缩文件.文件夹 zip 压缩后文件名(.zip结尾) 压缩文件名zip -r 压缩后文件夹(.zip结尾) 压缩文件 2.解压缩 unzip 压缩文件 ...
- Unicode和UTF的关系
目录结构: contents structure [+] 什么是USC UCS的编码方式 Unicode的来源 为什么需要Unicode Unicode的方式 Unicode和UTF UTF和Unic ...
- 在Linux上rpm安装运行Redis 3.0.4
http://www.rpmfind.net搜索redis,找到redis3.0.4的rpm源选做 wget ftp://fr2.rpmfind.net/linux/remi/enterprise/6 ...
- Swift 对象
1.对象 对象是类的具体化的东西,从抽象整体中具体化出的特定个体. 对象是一个动态的概念. 每一个对象都存在着有别于其他对象的属于自己的独特属性和行为. 对象的属性可以随着他自己的行为的变化而改变. ...
- JAVA中使用HTTP 1.1提高基于AXIS 1.4的web service的性能
HTTP 1.1会在第一次连接的时候进行认证, 而在一定时间内保持连接而不用重新验证. 一般情形下,每个web service请求都会在web service服务端验证, 而验证会消耗很多时间, 因此 ...
- 为什么有时候PHP没有闭合标签结束符 ?>
找了一些资料,大家对PHP闭合标签的总结如下: 好处:如果这个是一个被别人包含的程序,没有这个结束符,可以减少很多很多问题,比如说:header, setcookie, session_start这些 ...
- 训练深度学习网络时候,出现Nan 或者 震荡
出现Nan : 说法1: 说法2:说法3: 震荡 : 分析原因: 1:训练的batch_size太小 1. 当数据量足够大的时候可以适当的减小batch_size,由于数据量太大,内存不够 ...
- Knockout: radio选项切换引发click事件的一点总结
1.场景:如下图,当选择定期存款时,输入框右边出现红色的必输项星号,当选择活期存款时,不再出现该星号. 2.思路一:不使用knockout,直接用click事件,就可以实现这个需求,代码如下: < ...
- ubuntu 安装 2.10.x版本的scala
Ubuntu 14.04.1 LTS上默认的scala版本是2.9的,而最新版本的spark-1.3需要最低版本的scala版本为2.10.x,先使用apt-get remove scala将机器上的 ...
- ELK收集mysql_slow.log
关于慢查询的收集及处理也耗费了我们太多的时间和精力,如何在这一块也能提升效率呢?且看本文讲解如何利用ELK做慢日志收集. ELK 介绍 ELK 最早是 Elasticsearch(以下简称ES).Lo ...