Python+Requests接口测试教程(2):requests
开讲前,告诉大家requests有他自己的官方文档:http://cn.python-requests.org/zh_CN/latest/
2.1 发get请求
前言
requests模块,也就是老污龟,为啥叫它老污龟呢,因为这个官网上的logo就是这只污龟,接下来就是学习它了。
环境准备(小编环境):
python:2.7.12
pycharm:5.0.4
requests:2.13.0
(这学本篇之前,先要有一定的python基础,因为后面都是直接用python写代码了,小编主要以讲接口为主,python基础东西就自己去补了)
一、环境安装
1.用pip安装requests模块
>>pip install requests
二、get请求
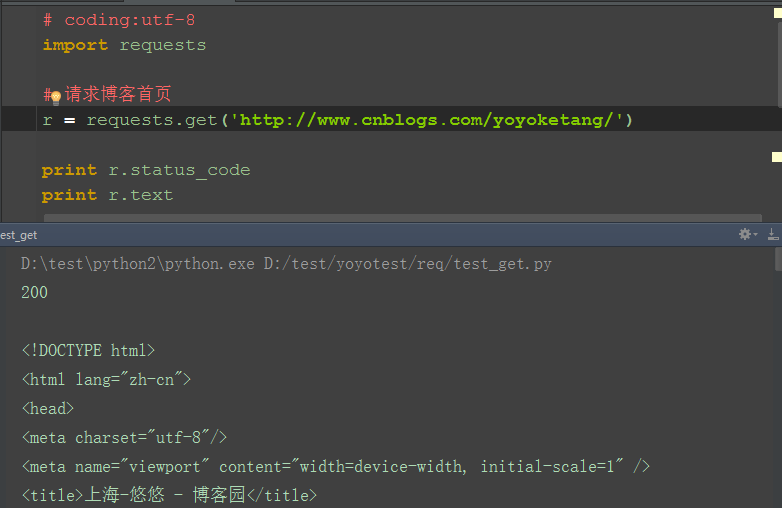
1.导入requests后,用get方法就能直接访问url地址,如:http://www.cnblogs.com/yoyoketang/,看起来是不是很酷
2.这里的r也就是response,请求后的返回值,可以调用response里的status_code方法查看状态码
3.状态码200只能说明这个接口访问的服务器地址是对的,并不能说明功能OK,一般要查看响应的内容,r.text是返回文本信息
三、params
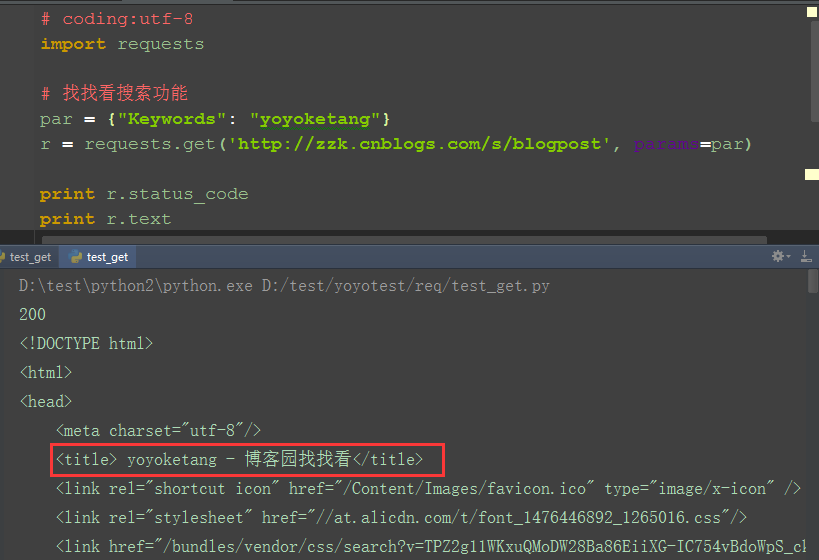
1.再发一个带参数的get请求,如在博客园搜索:yoyoketang,url地址为:http://zzk.cnblogs.com/s/blogpost?Keywords=yoyoketang
2.请求参数:Keywords=yoyoketang,可以以字典的形式传参:{"Keywords": "yoyoketang"}
3.多个参数格式:{"key1": "value1", "key2": "value2", "key3": "value3"}
四、content
1.百度首页如果用r.text会发现获取到的内容有乱码,因为百度首页响应内容是gzip压缩的(非text文本)
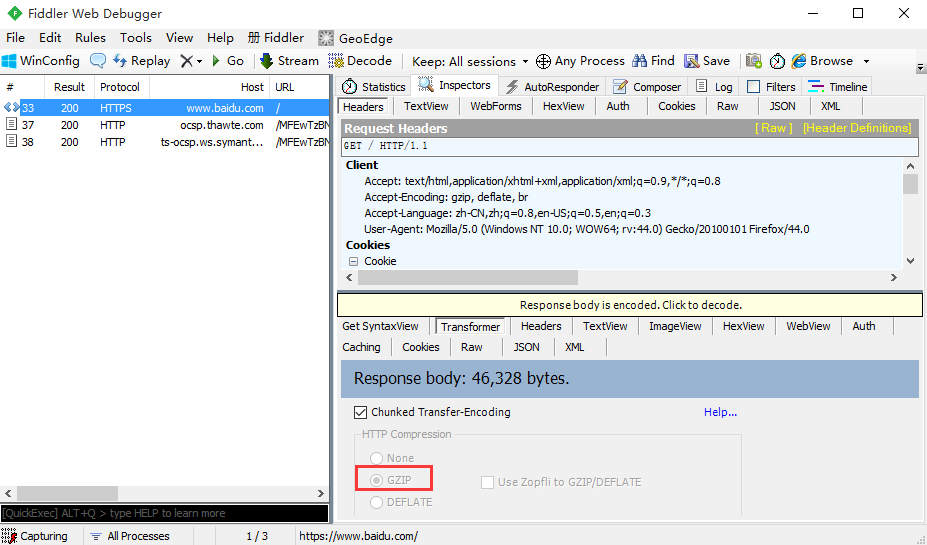
2.如果是在fiddler工具乱码,是可以点击后解码的,在代码里面可以用r.content这个方法,content会自动解码 gzip 和deflate压缩
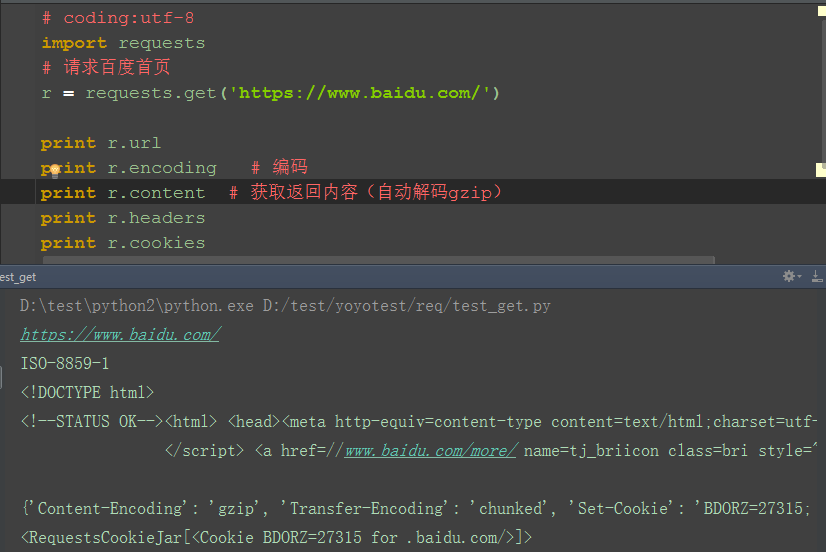
五、response
1.response的返回内容还有其它更多信息
-- r.status_code #响应状态码
-- r.content #字节方式的响应体,会自动为你解码 gzip 和 deflate 压缩
-- r.headers #以字典对象存储服务器响应头,但是这个字典比较特殊,字典键不区分大小写,若键不存在则返回None
-- r.json() #Requests中内置的JSON解码器
-- r.url # 获取url
-- r.encoding # 编码格式
-- r.cookies # 获取cookie
-- r.raw #返回原始响应体
-- r.text #字符串方式的响应体,会自动根据响应头部的字符编码进行解码
-- r.raise_for_status() #失败请求(非200响应)抛出异常
2.2 发post请求(json)
前言
发送post的请求参考例子很简单,实际遇到的情况却是很复杂的,首先第一个post请求肯定是登录了,但登录是最难处理的。登录问题解决了,后面都简单了。
一、查看官方文档
1.学习一个新的模块,其实不用去百度什么的,直接用help函数就能查看相关注释和案例内容。
>>import requests
>>help(requests)
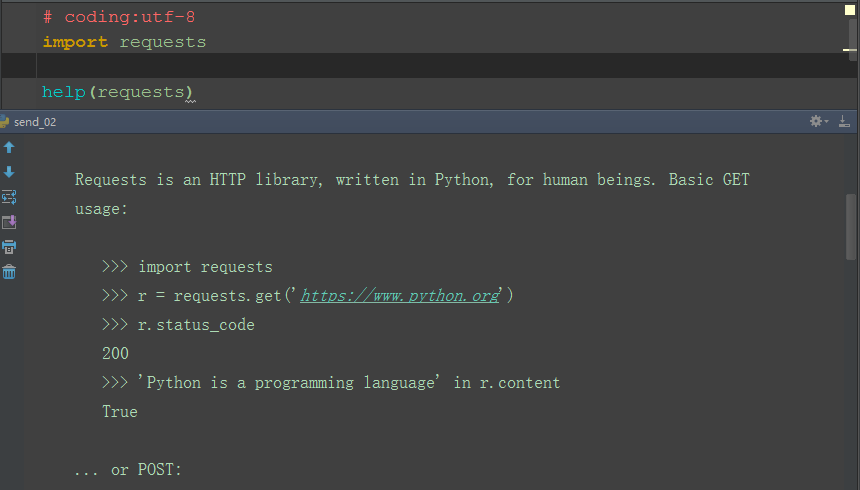
2.查看python发送get和post请求的案例
>>> import requests
>>> r = requests.get('https://www.python.org')
>>> r.status_code
200
>>> 'Python is a programming language' in r.content
True
... or POST:
>>> payload = dict(key1='value1', key2='value2')
>>> r = requests.post('http://httpbin.org/post', data=payload)
>>> print(r.text)
{
...
"form": {
"key2": "value2",
"key1": "value1"
},
...
}
二、发送post请求
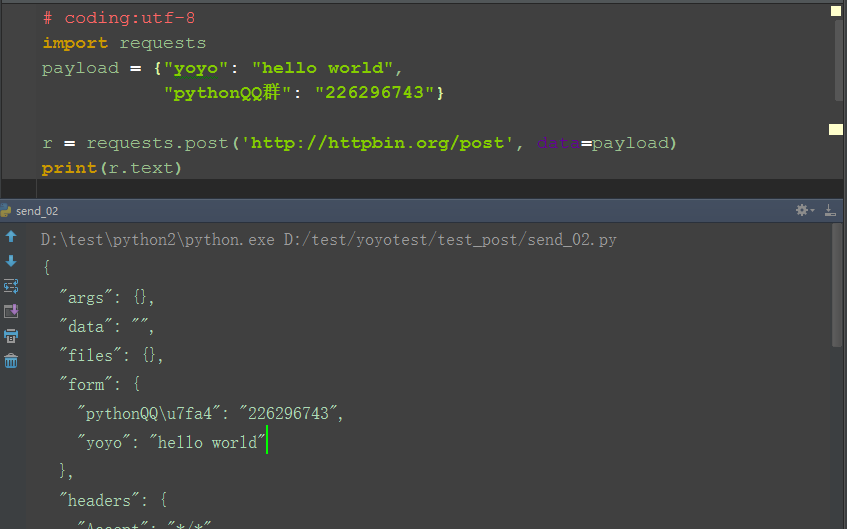
1.用上面给的案例,做个简单修改,发个post请求
2.payload参数是字典类型,传到如下图的form里
三、json
1.post的body是json类型,也可以用json参数传入。
2.先导入json模块,用dumps方法转化成json格式。
3.返回结果,传到data里。

四、headers
1.以博客园为例,模拟登陆,实际的情况要比上面讲的几个基本内容要复杂很多,一般登陆涉及安全性方面,登陆会比较复杂
2.这里需添加请求头headers,可以用fiddler抓包
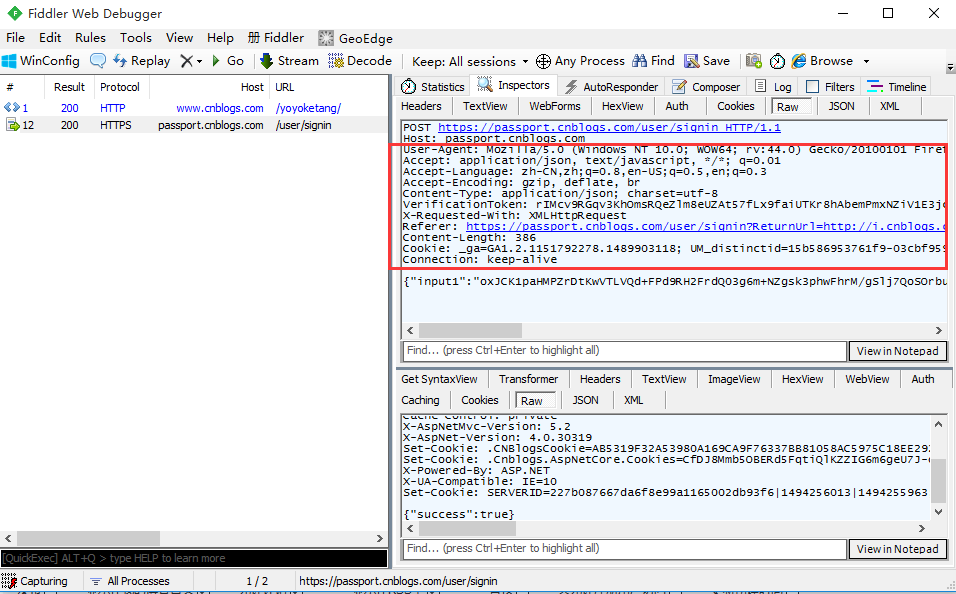
3.将请求头写成字典格式
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate, br",
"Content-Type": "application/json; charset=utf-8",
"X-Requested-With": "XMLHttpRequest",
"Cookie": "xxx.............", # 此处cookie省略了
"Connection": "keep-alive"
}
五、登陆博客园
1.由于这里是https请求,直接发送请求会报错误:SSLError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:590)
2.可以加个参数:verify=False,表示忽略对 SSL 证书的验证
3.这里请求参数payload是json格式的,用json参数传
4.红色注释那两行可以不用写
5.最后结果是json格式,可以直接用r.json返回json数据:{u'success': True}
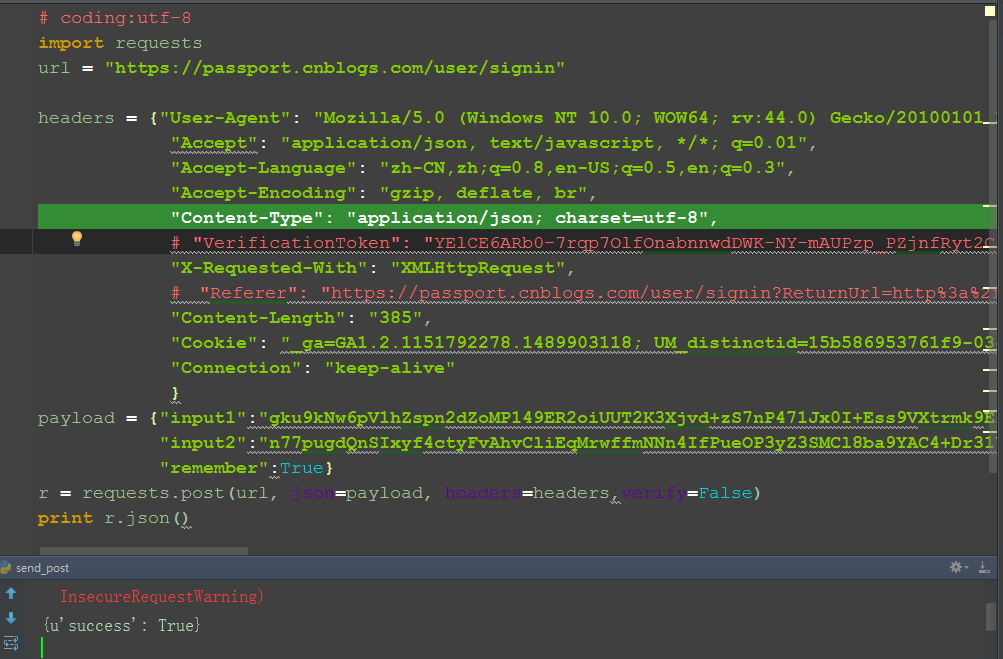
六、参考代码
# coding:utf-8
import requests
url = "https://passport.cnblogs.com/user/signin"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate, br",
"Content-Type": "application/json; charset=utf-8",
# "VerificationToken": "",
"X-Requested-With": "XMLHttpRequest",
# "Referer": "",
"Content-Length": "",
"Cookie": "xxx...", # 此处省略
"Connection": "keep-alive"
}
payload = {"input1":"xxx",
"input2":"xxx",
"remember":True}
r = requests.post(url, json=payload, headers=headers,verify=False)
print r.json()
2.3 发post请求(data)
前言:
前面登录博客园的是传json参数,有些登录不是传json的,如jenkins的登录,本篇以jenkins登录为案例,传data参数。
一、登录jenkins抓包
1.登录jenkins,输入账号和密码
2.fiddler抓包
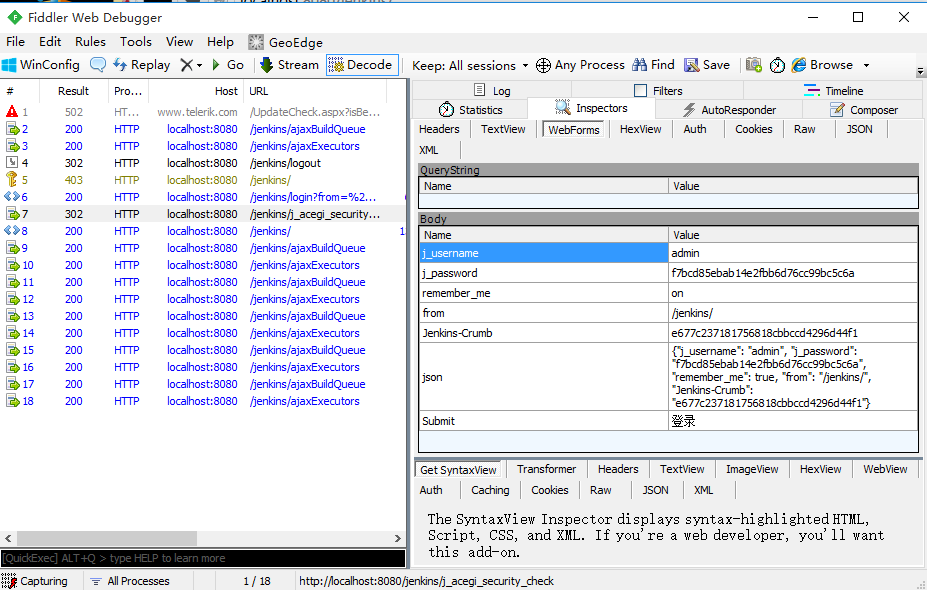
3.这个body参数并不是json格式,是key=value格式,也就是前面介绍post请求四种数据类型里面的第二种

二、请求头部
1.上面抓包已经知道body的数据类型了,那么头部里面Content-Type类型也需要填写对应的参数类型
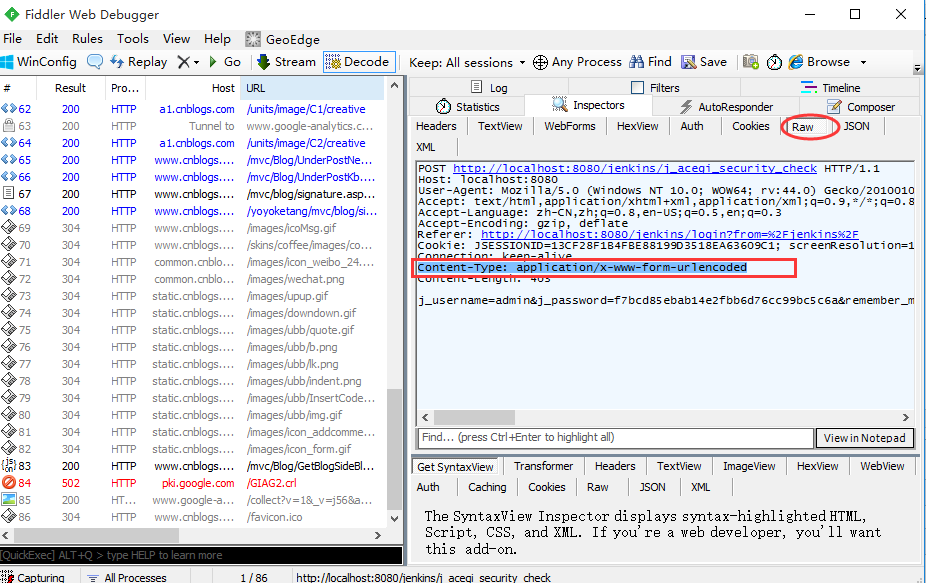
三、实现登录
1、登录代码如下:
# coding:utf-8
import requests
# 先打开登录首页,获取部分cookie
url = "http://localhost:8080/jenkins/j_acegi_security_check"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0"
} # get方法其它加个ser-Agent就可以了
d = {"from": "",
"j_password": "f7bcd85ebab14e2fbb6d76cc99bc5c6a",
"j_username": "admin",
"Jenkins-Crumb": "e677c237181756818cbbccd4296d44f1",
"json": {"j_username": "admin",
"j_password": "f7bcd85ebab14e2fbb6d76cc99bc5c6a",
"remember_me": True,
"from": "",
"Jenkins-Crumb": "e677c237181756818cbbccd4296d44f1"},
"remember_me": "on",
"Submit": u"登录"
}
s = requests.session()
r = s.post(url, headers=headers, data=d)
print r.content
2.打印结果
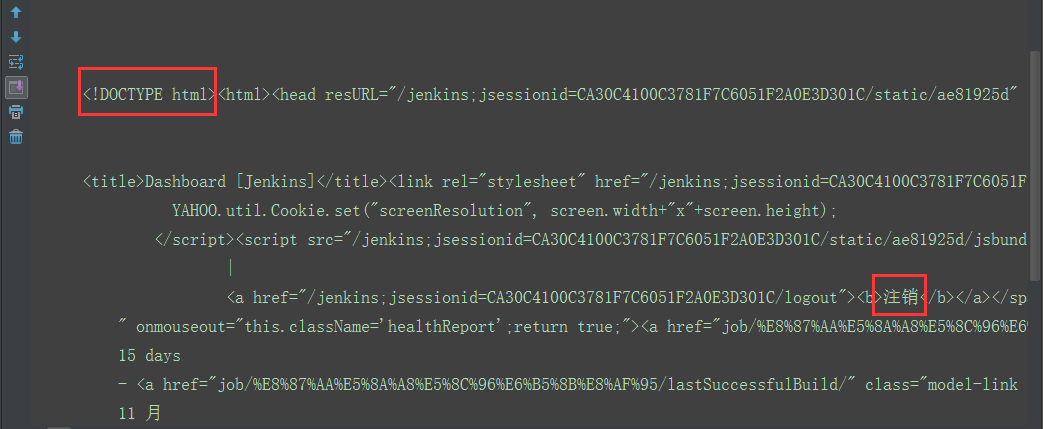
四、判断登录是否成功
1.首先这个登录接口有重定向,看左边会话框302,那登录成功的结果看最后一个200就行
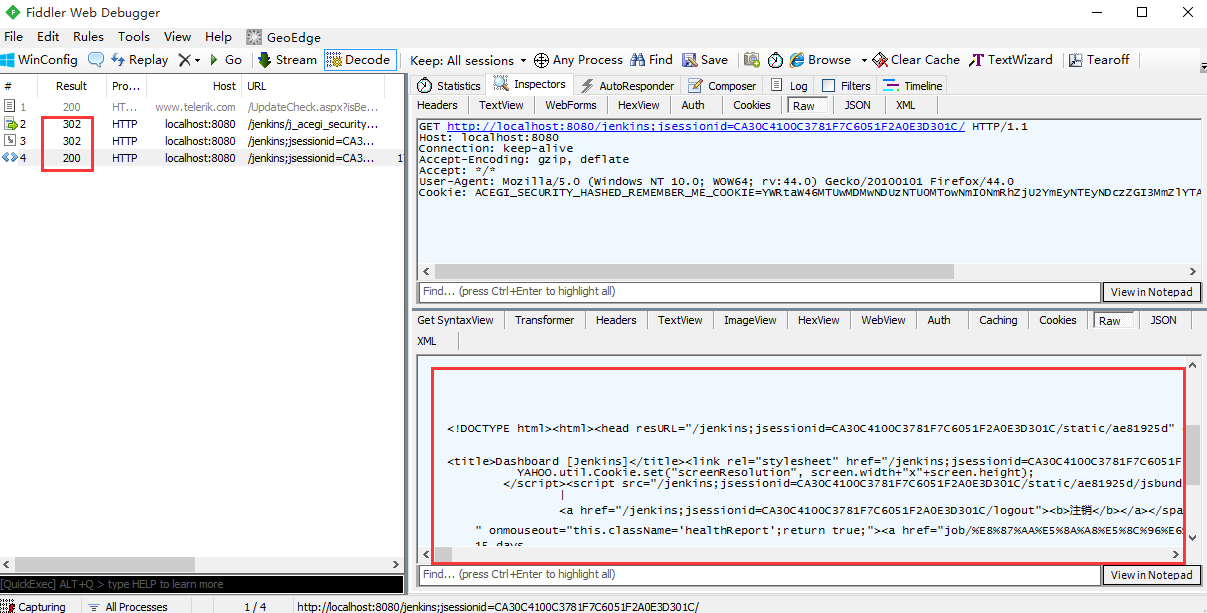
2.返回的结果并不是跟博客园一样的json格式,返回的是一个html页面
五、判断登录成功
1.判断登录成功,可以抓取页面上的关键元素,比如:账号名称admin,注销按钮
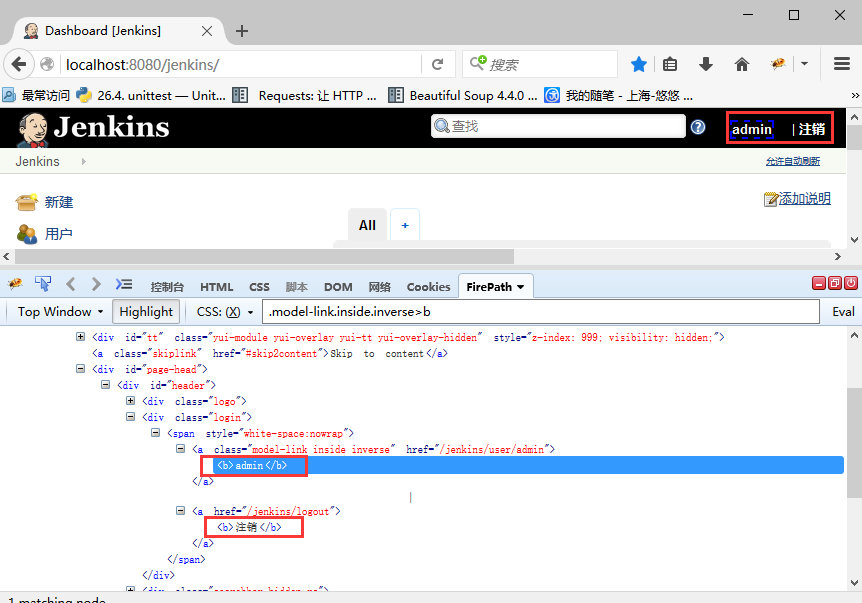
2.通过正则表达式提出这2个关键字
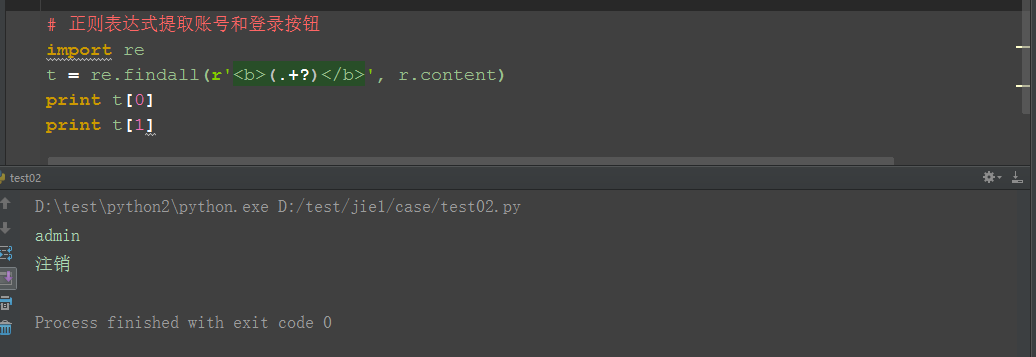
六、参考代码
# coding:utf-8
import requests
# 先打开登录首页,获取部分cookie
url = "http://localhost:8080/jenkins/j_acegi_security_check"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0"
} # get方法其它加个ser-Agent就可以了
d = {"from": "",
"j_password": "f7bcd85ebab14e2fbb6d76cc99bc5c6a",
"j_username": "admin",
"Jenkins-Crumb": "e677c237181756818cbbccd4296d44f1",
"json": {"j_username": "admin",
"j_password": "f7bcd85ebab14e2fbb6d76cc99bc5c6a",
"remember_me": True,
"from": "",
"Jenkins-Crumb": "e677c237181756818cbbccd4296d44f1"},
"remember_me": "on",
"Submit": u"登录"
}
s = requests.session()
r = s.post(url, headers=headers, data=d)
# 正则表达式提取账号和登录按钮
import re
t = re.findall(r'<b>(.+?)</b>', r.content) # 用python3的这里r.content需要解码
print t[0]
print t[1]
2.4 data和json傻傻分不清
前言
在发post请求的时候,有时候body部分要传data参数,有时候body部分又要传json参数,那么问题来了:到底什么时候该传json,什么时候该传data?
一、识别json参数
1.在前面1.8章节讲过,post请求的body通常有四种类型,最常见的就是json格式的了,这个还是很好识别的

2.用抓包工具查看,首先点开Raw去查看body部分,如下图这种,参数最外面是大括号{ }包起来的,这种已经确诊为json格式了。
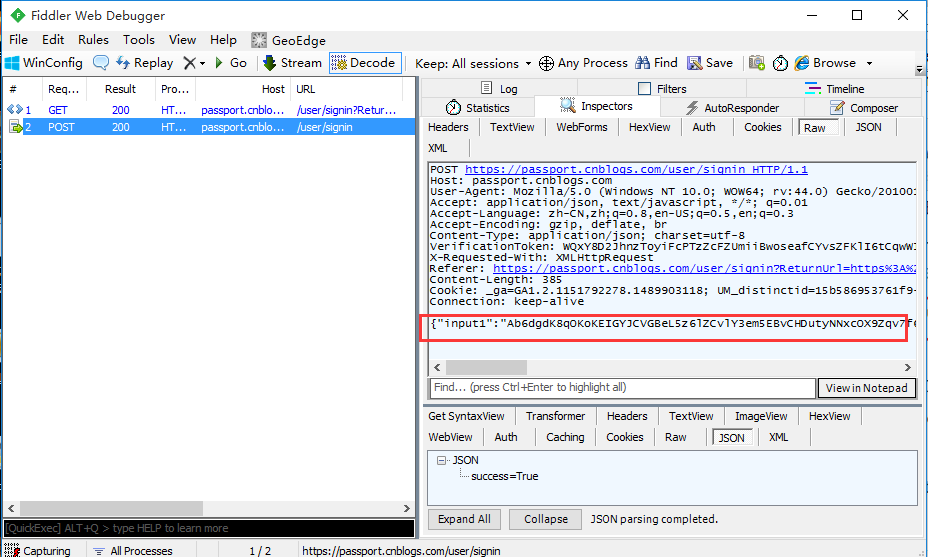
3.再一次确认,可以点开Json这一项查看,点开之后可以看到这里的几组参数是json解析后的(记住它的样子)
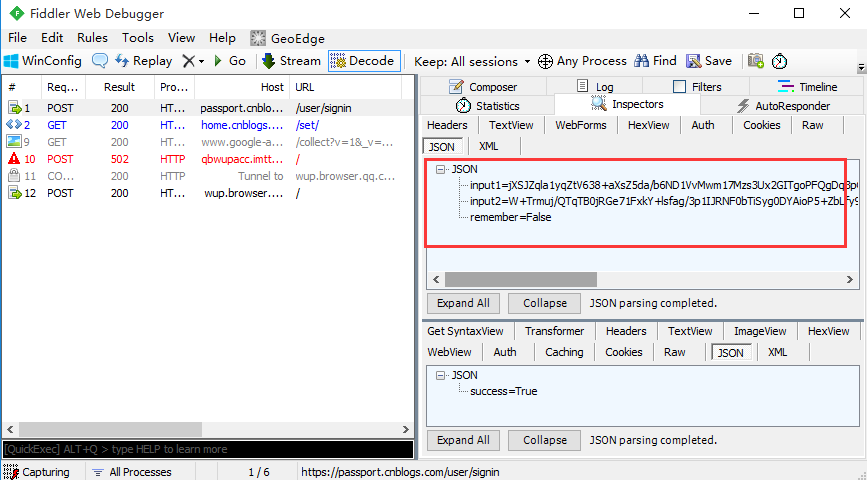
4.这时候,就可以用前面2.2讲的传json参数
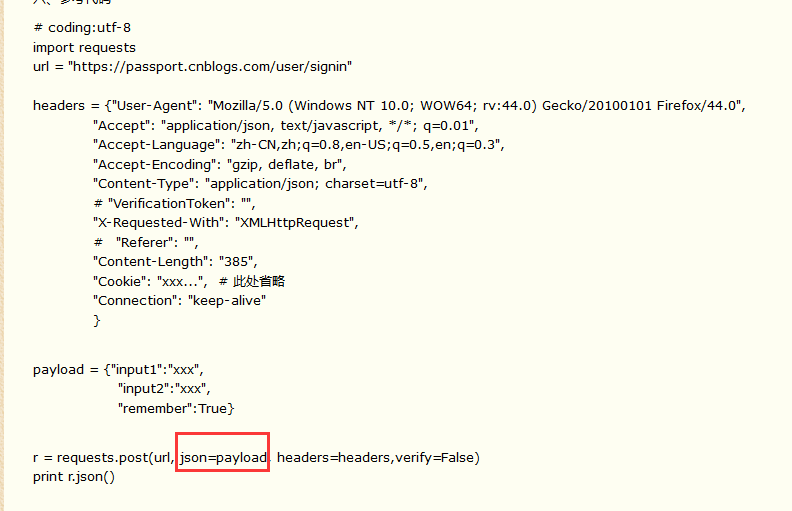
二、识别data参数
1.data参数也就是这种格式:key1=value1&key2=value2...这种格式很明显没有大括号
点开Raw查看,跟上面的json区别还是很大的
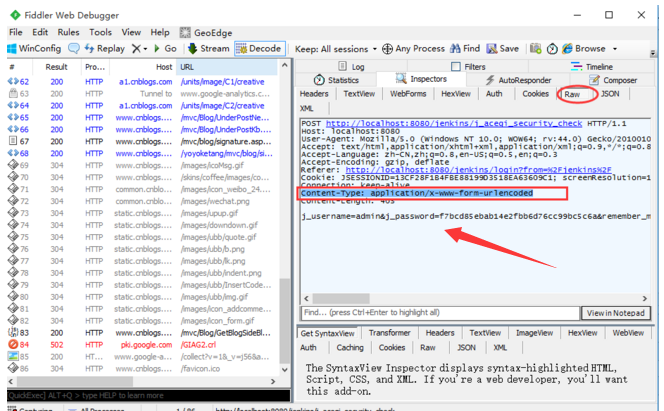
2.因为这个是非json的,所以点开Json这个菜单是不会有解析的数据的,这种数据在WebForms里面查看
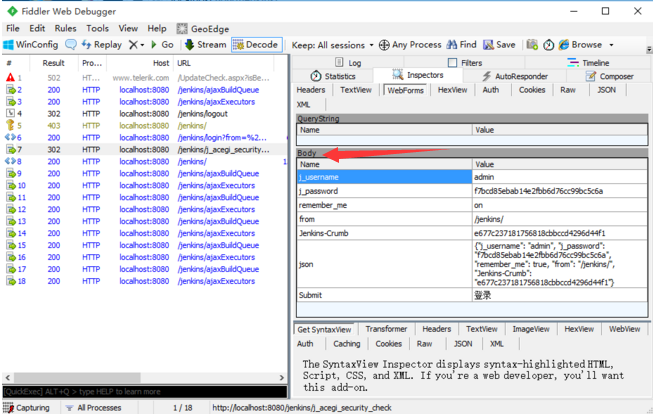
3.可以看到这种参数显示在Body部分,左边的Name这项就是key值,右边的Value就是对应的value值,像这种参数转化从python的字典格式就行了

4.这一种发post时候就传data参数就可以了,格式如下:
s = requests.session()
r = s.post(url, headers=headers, data=d) # 这里的d就是上一步的字典格式的参数
现在能分得清data参数和json参数的不?
2.5 发https请求(ssl)
前言
本来最新的requests库V2.13.0是支持https请求的,但是一般写脚本时候,我们会用抓包工具fiddler,这时候会 报:requests.exceptions.SSLError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:590)
小编环境:
python:2.7.12
requests:2.13.0
fiddler:v4.6.2.0
一、SSL问题
1.不启用fiddler,直接发https请求,不会有SSL问题(也就是说不想看到SSL问题,关掉fiddler就行)

2.启动fiddler抓包,会出现这个错误:requests.exceptions.SSLError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:590)
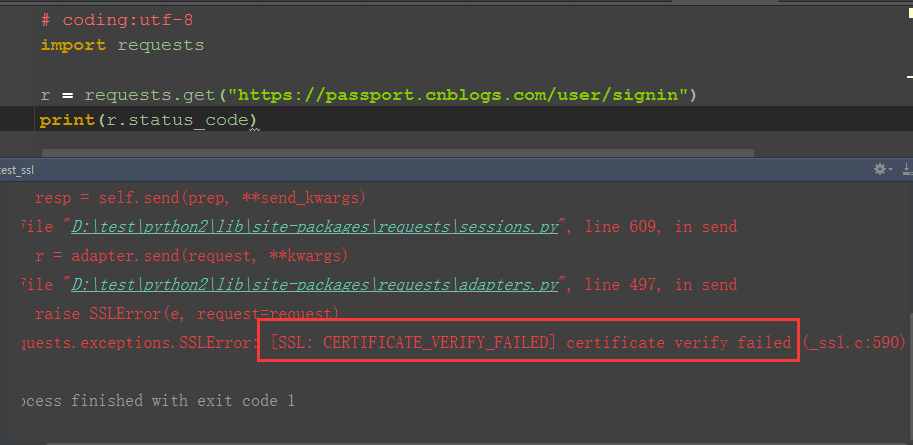
二、verify参数设置
1.Requests的请求默认verify=True
2.如果你将 verify设置为 False,Requests 也能忽略对 SSL 证书的验证
3.但是依然会出现两行Warning,可以不用管
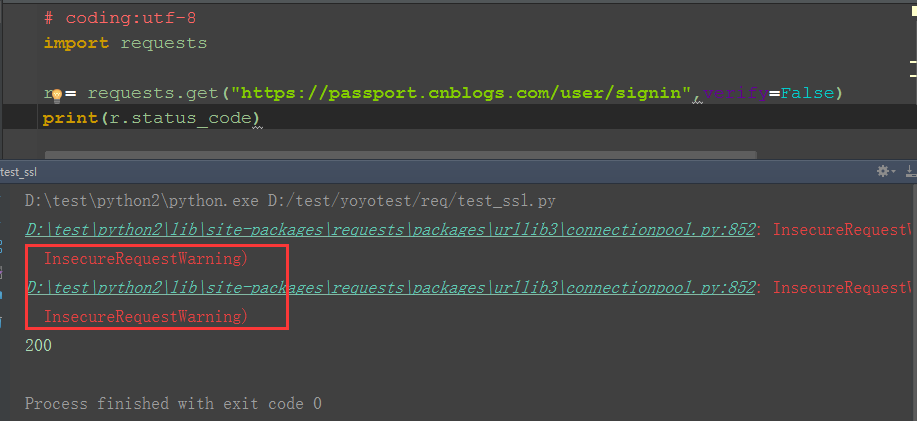
三、忽略Warning
1.有些小伙伴有强迫症看到红色的心里就发慌,这里加两行代码可以忽略掉警告,眼不见为净!
2.参考代码:
# coding:utf-8
import requests
# 禁用安全请求警告
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
url = "https://passport.cnblogs.com/user/signin"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0"
}
r = requests.get(url, headers=headers, verify=False)
print(r.status_code)
2.6 session关联接口
前言
上一篇模拟登录博客园,但这只是第一步,一般登录后,还会有其它的操作,如发帖,评论等,这时候如何保持会话呢?
一、session简介
1.查看帮助文档,贴了一部分,后面省略了
>>import requests
>>help(requests.session())
class Session(SessionRedirectMixin)
| A Requests session.
|
| Provides cookie persistence, connection-pooling, and configuration.
|
| Basic Usage::
|
| >>> import requests
| >>> s = requests.Session()
| >>> s.get('http://httpbin.org/get')
| <Response [200]>
|
| Or as a context manager::
|
| >>> with requests.Session() as s:
| >>> s.get('http://httpbin.org/get')
| <Response [200]>
二、使用session登录
1.使用session登录只需在上一篇基础上稍做修改
# coding:utf-8
import requests
url = "https://passport.cnblogs.com/user/signin"
headers = {
#头部信息已省略
}
payload = {"input1":"xxx",
"input2":"xxx",
"remember":True}
# r = requests.post(url, json=payload, headers=headers,verify=False)
# 修改后如下
s = requests.session()
r = s.post(url, json=payload, headers=headers,verify=False)
print r.json()
三、保存编辑
1.先打开我的随笔,手动输入内容后,打开fiddler抓包
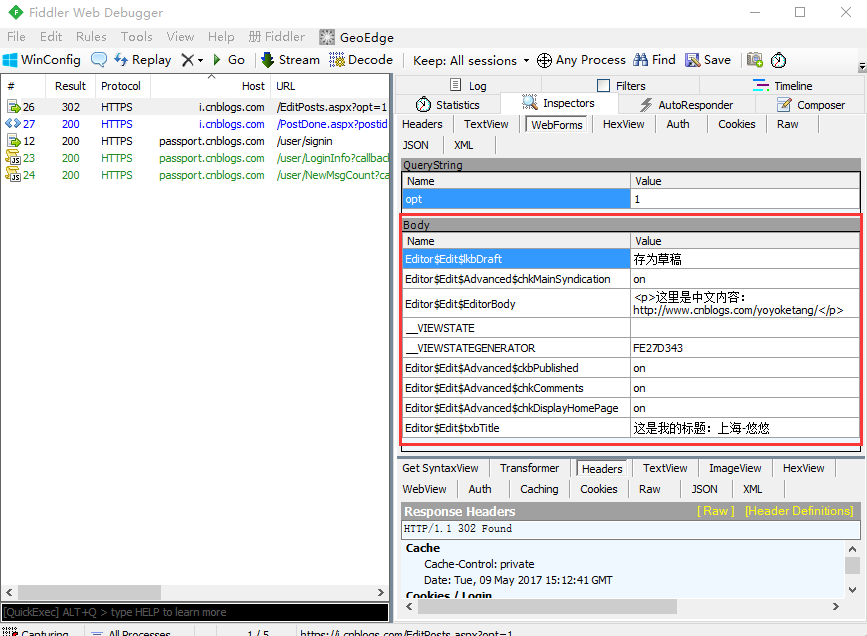
2.把body的参数内容写成字典格式,有几个空的参数不是必填的,可以去掉
body = {"__VIEWSTATE": "",
"__VIEWSTATEGENERATOR":"FE27D343",
"Editor$Edit$txbTitle":"这是我的标题:上海-悠悠",
"Editor$Edit$EditorBody":"<p>这里是中文内容:http://www.cnblogs.com/yoyoketang/</p>",
"Editor$Edit$Advanced$ckbPublished":"on",
"Editor$Edit$Advanced$chkDisplayHomePage":"on",
"Editor$Edit$Advanced$chkComments":"on",
"Editor$Edit$Advanced$chkMainSyndication":"on",
"Editor$Edit$lkbDraft":"存为草稿",
}
3.用上面的session继续发送post请求
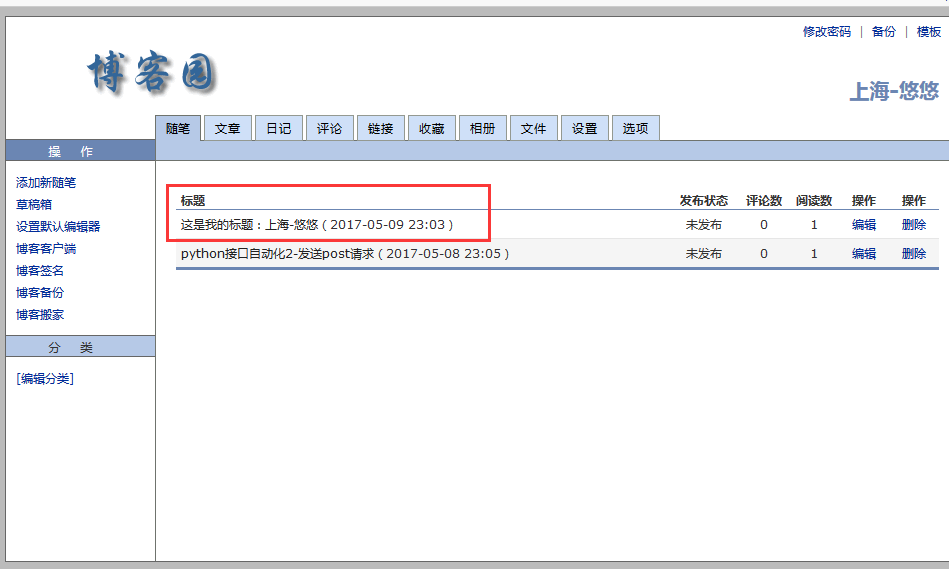
4.执行后,查看我的草稿箱就多了一条新增的了
四、参考代码
# coding:utf-8
import requests
url = "https://passport.cnblogs.com/user/signin"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate, br",
"Content-Type": "application/json; charset=utf-8",
# "VerificationToken": "xxx...", # 已省略
"X-Requested-With": "XMLHttpRequest",
# "Referer":
"https://passport.cnblogs.com/user/signin?ReturnUrl=http%3a%2f%2fmsg.cnblogs.com%2fsend%2f%e4%b8%8a%e6%b5%b7-%e6%82%a0%e6%82%a0",
"Content-Length": "",
"Cookie": "xxx.....", # 已省略
"Connection": "keep-alive"
}
# 登录的参数
payload = {"input1":"xxx",
"input2":"xxx",
"remember":True}
s = requests.session()
r = s.post(url, json=payload, headers=headers,verify=False)
print r.json()
# 保存草稿箱
url2= "https://i.cnblogs.com/EditPosts.aspx?opt=1"
body = {"__VIEWSTATE": "",
"__VIEWSTATEGENERATOR":"FE27D343",
"Editor$Edit$txbTitle":"这是我的标题:上海-悠悠",
"Editor$Edit$EditorBody":"<p>这里是中文内容:http://www.cnblogs.com/yoyoketang/</p>",
"Editor$Edit$Advanced$ckbPublished":"on",
"Editor$Edit$Advanced$chkDisplayHomePage":"on",
"Editor$Edit$Advanced$chkComments":"on",
"Editor$Edit$Advanced$chkMainSyndication":"on",
"Editor$Edit$lkbDraft":"存为草稿",
}
r2 = s.post(url2, data=body, verify=False)
print r.content
这里我是用保存草稿箱写的案例,小伙伴们可以试下自动发帖
(备注:别使用太频繁了哦,小心封号嘿嘿!!!)
2.7 cookie绕过验证码登录
前言
有些登录的接口会有验证码:短信验证码,图形验证码等,这种登录的话验证码参数可以从后台获取的(或者查数据库最直接)。
获取不到也没关系,可以通过添加cookie的方式绕过验证码。
(注意:并不是所有的登录都是用cookie来保持登录的,有些是2.11章节讲的token)
一、抓登录cookie
1.如博客园登录后会生成一个已登录状态的cookie,那么只需要直接把这个值添加到cookies里面就可以了。
2.可以先手动登录一次,然后抓取这个cookie,这里就需要用抓包工具fiddler了
3.先打开博客园登录界面,手动输入账号和密码(勾选下次自动登录)
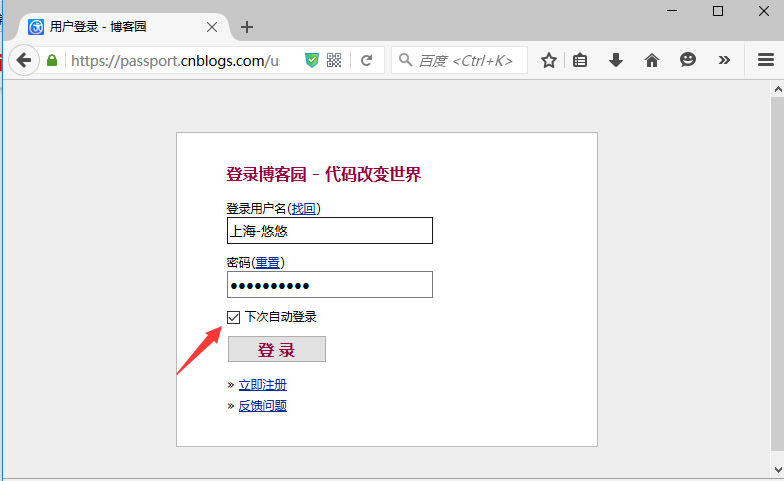
4.打开fiddler抓包工具,刷新下登录首页,就是登录前的cookie了
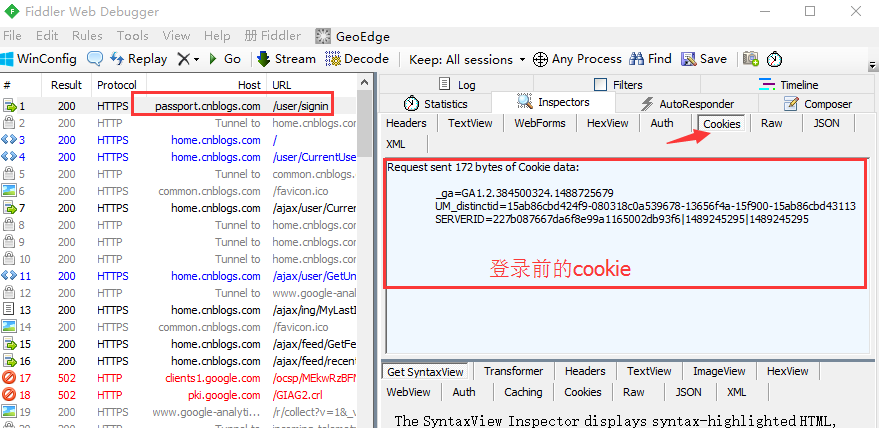
5.登录成功后,再查看cookie变化,发现多了两组参数,多的这两组参数就是我们想要的,copy出来,一会有用
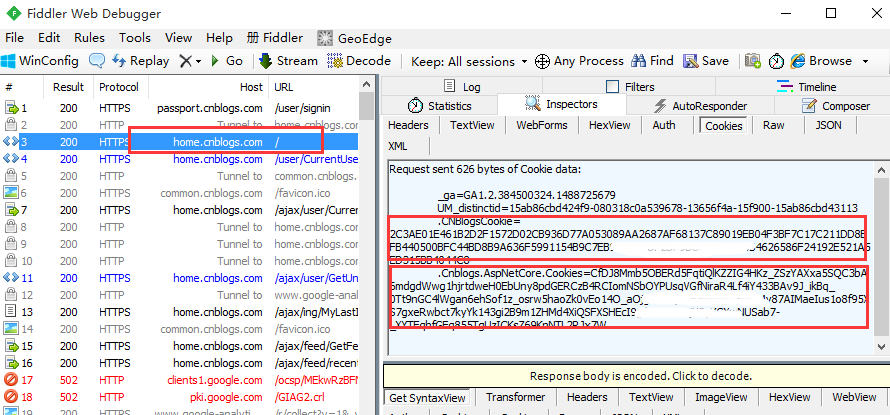
二、cookie组成结构
1.用抓包工具fidller只能看到cookie的name和value两个参数,实际上cookie还有其它参数
2.以下是一个完整的cookie组成结构
cookie ={u'domain': u'.cnblogs.com',
u'name': u'.CNBlogsCookie',
u'value': u'xxxx',
u'expiry': 1491887887,
u'path': u'/',
u'httpOnly': True,
u'secure': False}
name:cookie的名称
value:cookie对应的值,动态生成的
domain:服务器域名
expiry:Cookie有效终止日期
path:Path属性定义了Web服务器上哪些路径下的页面可获取服务器设置的Cookie
httpOnly:防脚本攻击
secure:在Cookie中标记该变量,表明只有当浏览器和Web Server之间的通信协议为加密认证协议时,
浏览器才向服务器提交相应的Cookie。当前这种协议只有一种,即为HTTPS。
三、添加cookie
1.往session里面添加cookie可以用以下方式
2.set里面参数按括号里面的参数格式
coo = requests.cookies.RequestsCookieJar()
coo.set('cookie-name', 'cookie-value', path='/', domain='.xxx.com')
s.cookies.update(c)
3.于是添加登录的cookie,把第一步fiddler抓到的内容填进去就可以了
c = requests.cookies.RequestsCookieJar()
c.set('.CNBlogsCookie', 'xxx')
c.set('.Cnblogs.AspNetCore.Cookies','xxx')
s.cookies.update(c)
print(s.cookies)
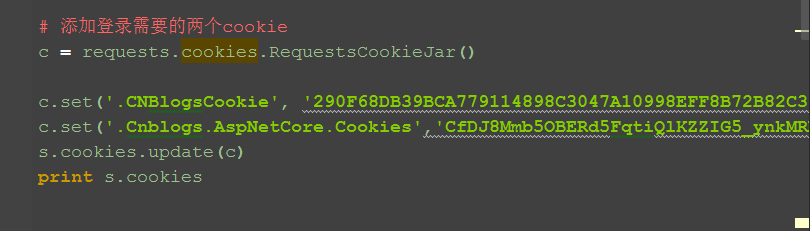
四、参考代码
1.由于登录时候是多加2个cookie,我们可以先用get方法打开登录首页,获取部分cookie
2.再把登录需要的cookie添加到session里
3.添加成功后,随便编辑正文和标题保存到草稿箱
# coding:utf-8
import requests
# 先打开登录首页,获取部分cookie
url = "https://passport.cnblogs.com/user/signin"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0"
} # get方法其它加个ser-Agent就可以了
s = requests.session()
r = s.get(url, headers=headers,verify=False)
print s.cookies
# 添加登录需要的两个cookie
c = requests.cookies.RequestsCookieJar()
c.set('.CNBlogsCookie', 'xxx') # 填上面抓包内容
c.set('.Cnblogs.AspNetCore.Cookies','xxx') # 填上面抓包内容
s.cookies.update(c)
print s.cookies
# 登录成功后保存编辑内容
url2= "https://i.cnblogs.com/EditPosts.aspx?opt=1"
body = {"__VIEWSTATE": "",
"__VIEWSTATEGENERATOR":"FE27D343",
"Editor$Edit$txbTitle":"这是绕过登录的标题:上海-悠悠",
"Editor$Edit$EditorBody":"<p>这里是中文内容:http://www.cnblogs.com/yoyoketang/</p>",
"Editor$Edit$Advanced$ckbPublished":"on",
"Editor$Edit$Advanced$chkDisplayHomePage":"on",
"Editor$Edit$Advanced$chkComments":"on",
"Editor$Edit$Advanced$chkMainSyndication":"on",
"Editor$Edit$lkbDraft":"存为草稿",
}
r2 = s.post(url2, data=body, verify=False)
print r.content
2.8 json数据处理
前言
有些post的请求参数是json格式的,这个前面第二篇post请求里面提到过,需要导入json模块处理。
一般常见的接口返回数据也是json格式的,我们在做判断时候,往往只需要提取其中几个关键的参数就行,这时候就需要json来解析返回的数据了。
一、json模块简介
1.Json简介:Json,全名 JavaScript Object Notation,是一种轻量级的数据交换格式,常用于http请求中
2.可以用help(json),查看对应的源码注释内容:
Encoding basic Python object hierarchies::
>>> import json
>>> json.dumps(['foo', {'bar': ('baz', None, 1.0, 2)}])
'["foo", {"bar": ["baz", null, 1.0, 2]}]'
>>> print json.dumps("\"foo\bar")
"\"foo\bar"
>>> print json.dumps(u'\u1234')
"\u1234"
>>> print json.dumps('\\')
"\\"
>>> print json.dumps({"c": 0, "b": 0, "a": 0}, sort_keys=True)
{"a": 0, "b": 0, "c": 0}
>>> from StringIO import StringIO
>>> io = StringIO()
>>> json.dump(['streaming API'], io)
>>> io.getvalue()
'["streaming API"]'
二、Encode(python->json)
1.首先说下为什么要encode,python里面bool值是True和False,json里面bool值是true和false,并且区分大小写,这就尴尬了,明明都是bool值。
在python里面写的代码,传到json里,肯定识别不了,所以需要把python的代码经过encode后成为json可识别的数据类型。
2.举个简单例子,下图中dict类型经过json.dumps()后变成str,True变成了true,False变成了fasle
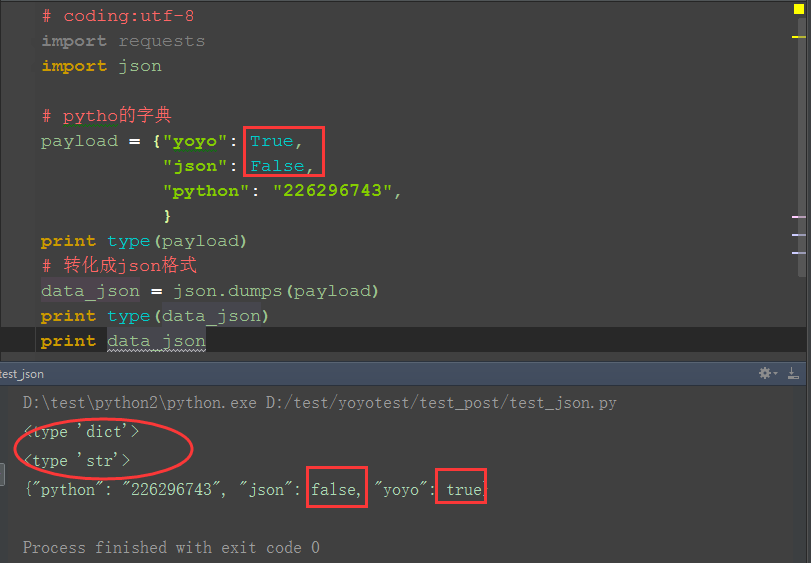
3.以下对应关系表是从json模块的源码里面爬出来的.python的数据类,经过encode成json的数据类型,对应的表如下:
| | Python | JSON |
| +===================+===============+
| | dict | object |
| +-------------------+---------------+
| | list, tuple | array |
| +-------------------+---------------+
| | str, unicode | string |
| +-------------------+---------------+
| | int, long, float | number |
| +-------------------+---------------+
| | True | true |
| +-------------------+---------------+
| | False | false |
| +-------------------+---------------+
| | None | null |
| +-------------------+---------------+
三、decode(json->python)
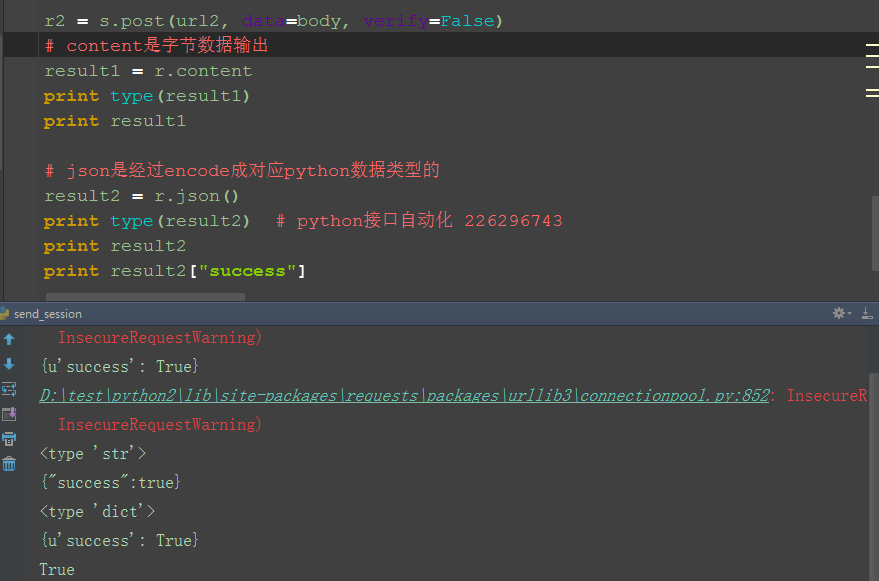
1.以第三篇的登录成功结果:{"success":true}为例,我们其实最想知道的是success这个字段返回的是True还是False
2.如果以content字节输出,返回的是一个字符串:{"success":true},这样获取后面那个结果就不方便了
3.如果经过json解码后,返回的就是一个字典:{u'success': True},这样获取后面那个结果,就用字典的方式去取值:result2["success"]
4.同样json数据转化成python可识别的数据,对应的表关系如下
| +---------------+-------------------+
| | JSON | Python |
| +===============+===================+
| | object | dict |
| +---------------+-------------------+
| | array | list |
| +---------------+-------------------+
| | string | unicode |
| +---------------+-------------------+
| | number (int) | int, long |
| +---------------+-------------------+
| | number (real) | float |
| +---------------+-------------------+
| | true | True |
| +---------------+-------------------+
| | false | False |
| +---------------+-------------------+
| | null | None |
| +---------------+-------------------+
四、案例分析
1.比如打开快递网:http://www.kuaidi.com/,搜索某个单号,判断它的状态是不是已签收
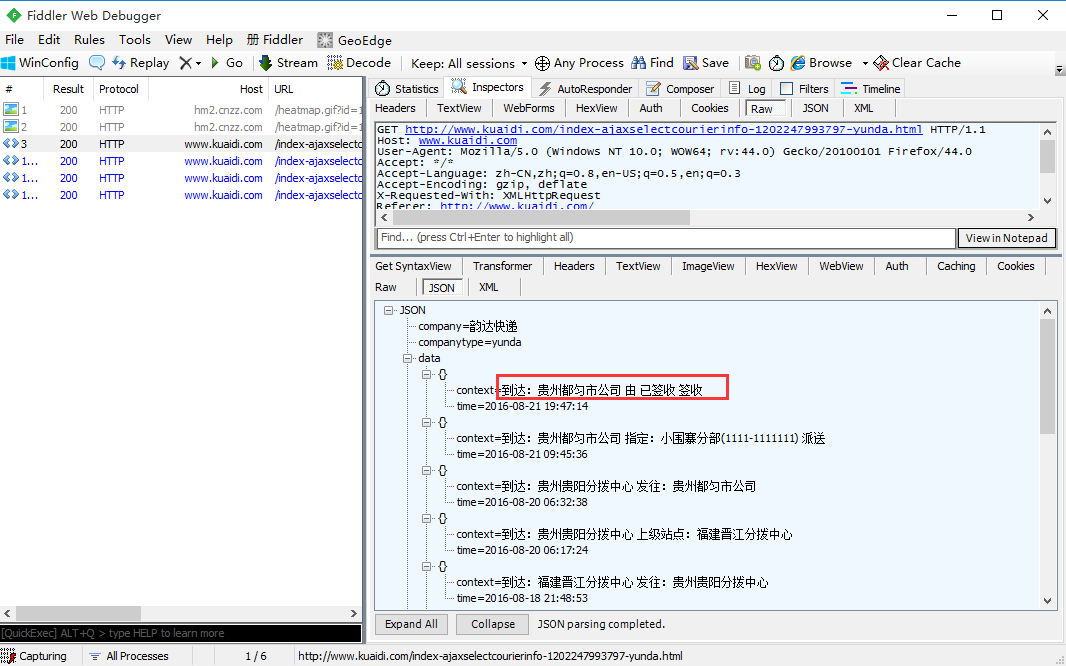
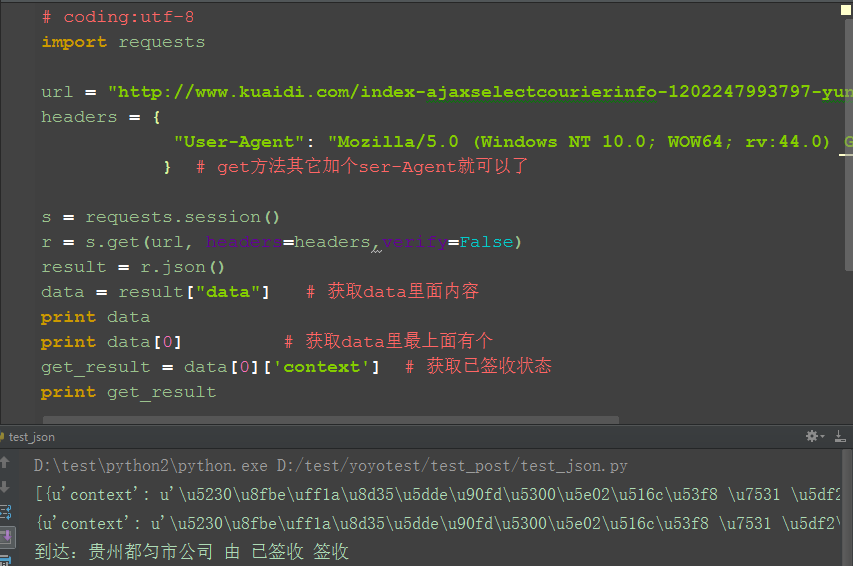
2. 实现代码如下
五、参考代码:
# coding:utf-8
import requests
url = "http://www.kuaidi.com/index-ajaxselectcourierinfo-1202247993797-yunda.html"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0"
} # get方法其它加个User-Agent就可以了
s = requests.session()
r = s.get(url, headers=headers,verify=False)
result = r.json()
data = result["data"] # 获取data里面内容
print data
print data[0] # 获取data里最上面的那个
get_result = data[0]['context'] # 获取已签收状态
print get_result
if u"已签收" in get_result:
print "快递单已签收成功"
else:
print "未签收"
2.9 重定向Location
前言
某屌丝男A鼓起勇气向女神B打电话表白,女神B是个心机婊觉得屌丝男A是好人,不想直接拒绝于是设置呼叫转移给闺蜜C了,最终屌丝男A和女神闺蜜C表白成功了,这种场景其实就是重定向了。
一、重定向
1. (Redirect)就是通过各种方法将各种网络请求重新定个方向转到其它位置,从地址A跳转到地址B了。
2.重定向状态码:
--301 redirect: 301 代表永久性转移(Permanently Moved)
--302 redirect: 302 代表暂时性转移(Temporarily Moved )
3.举个简单的场景案例,先登录博客园打开我的博客首页,进我的随笔编辑界面,记住这个地址:https://i.cnblogs.com/EditPosts.aspx?opt=1
4.退出博客园登录,把刚才我的随笔这个地址输入浏览器回车,抓包会看到这个请求状态码是302,浏览器地址栏瞬间刷新跳到登录首页去了
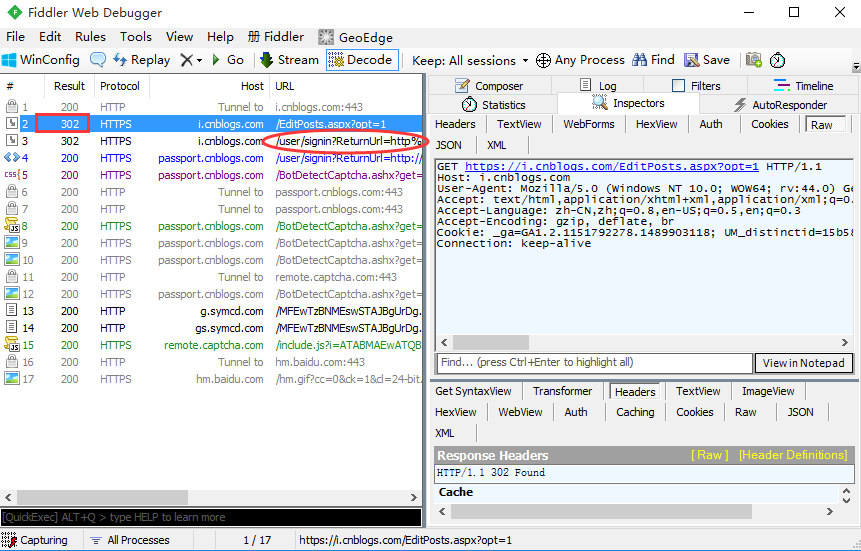
二、禁止重定向(allow_redirects)
1.用get方法请求:https://i.cnblogs.com/EditPosts.aspx?opt=1
2.打印状态码是200,这是因为requets库自动处理了重定向请求了
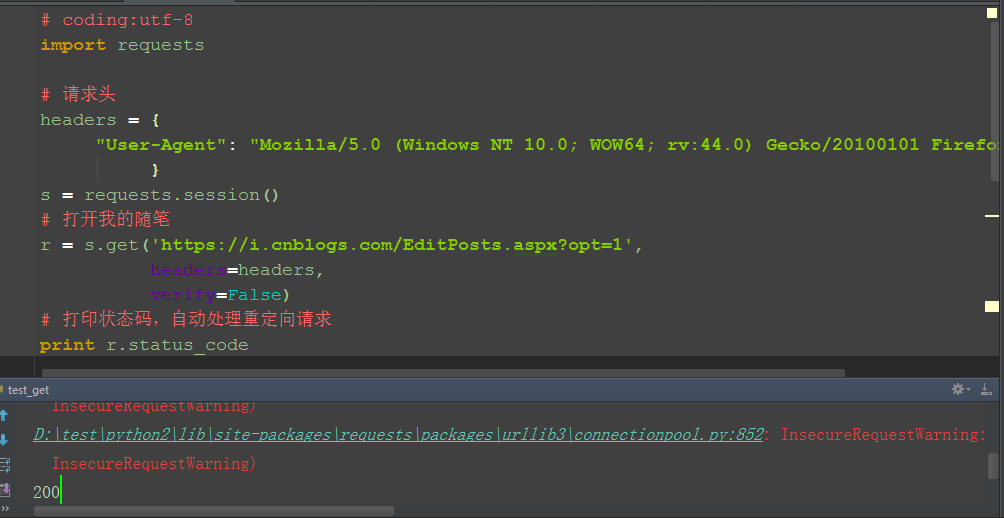
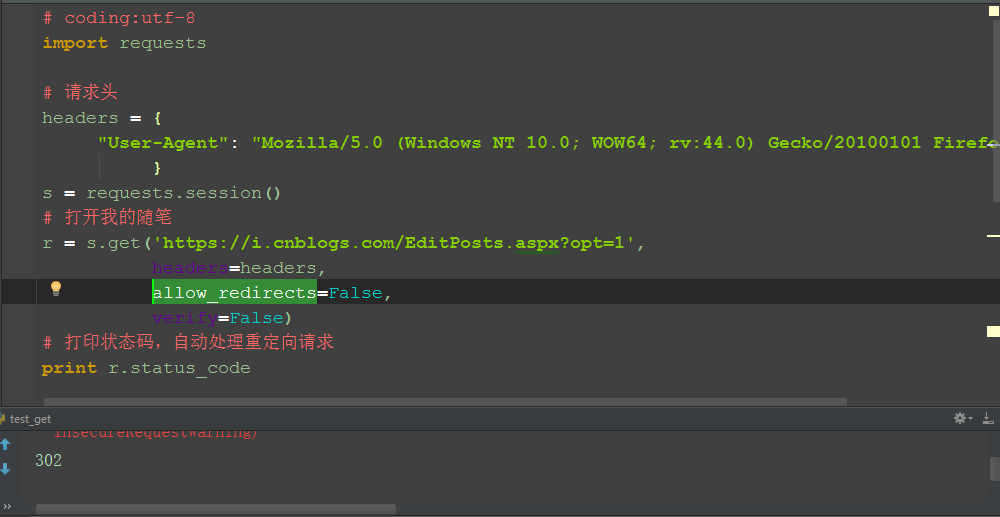
3.自动处理重定向地址后,我们就获取不到重定向后的url了,就无法走下一步,这里我们可以设置一个参数禁止重定向:allow_redirects=False
(allow_redirects=True是启动重定向),然后就可以看到status_code是302了
三、获取重定向后地址
1.在第一个请求后,服务器会下发一个新的请求链接,在response的headers里,如下抓包:Location
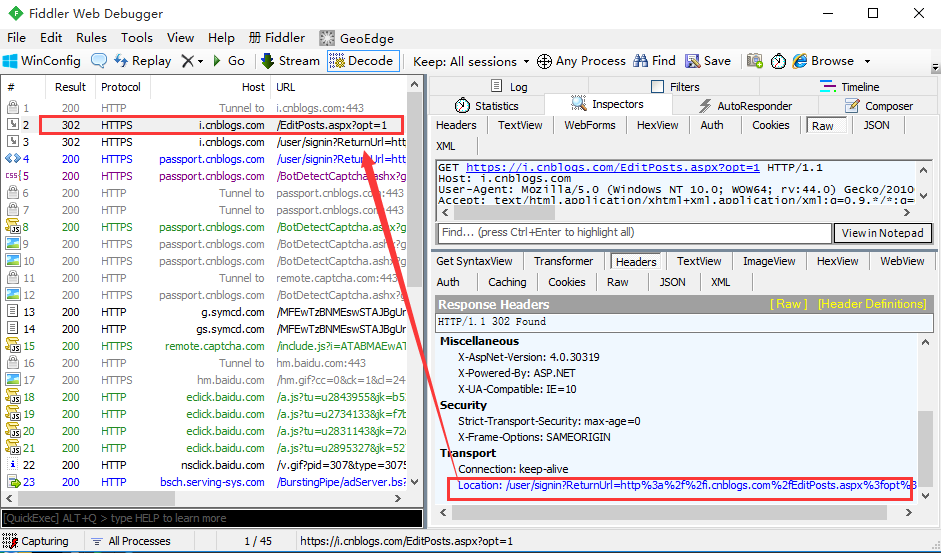
2.用脚本去获取Location地址
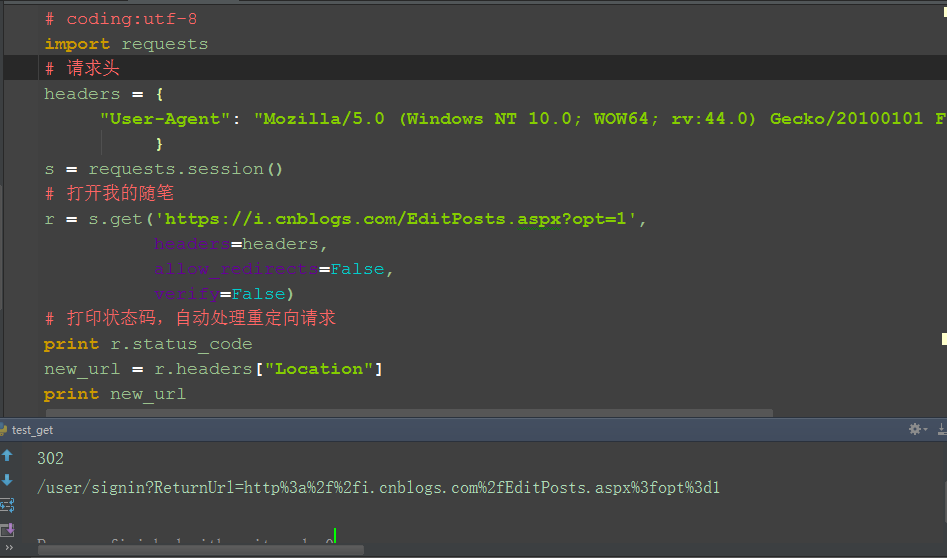
四、参考代码:
# coding:utf-8
import requests
# 请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0"
}
s = requests.session()
# 打开我的随笔
r = s.get('https://i.cnblogs.com/EditPosts.aspx?opt=1',
headers=headers,
allow_redirects=True,
verify=False)
# 打印状态码,自动处理重定向请求
print r.status_code
new_url = r.headers["Location"]
print new_url
2.10 参数关联
前言
我们用自动化发帖之后,要想接着对这篇帖子操作,那就需要用参数关联了,发帖之后会有一个帖子的id,获取到这个id,继续操作传这个帖子id就可以了
一、删除草稿箱
1.我们前面讲过登录后保存草稿箱,那可以继续接着操作:删除刚才保存的草稿
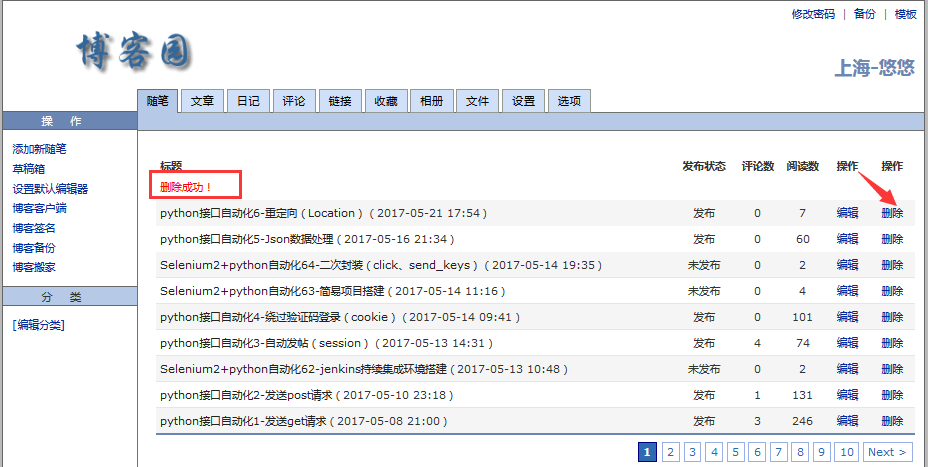
2.用fiddler抓包,抓到删除帖子的请求,从抓包结果可以看出,传的json参数是postId
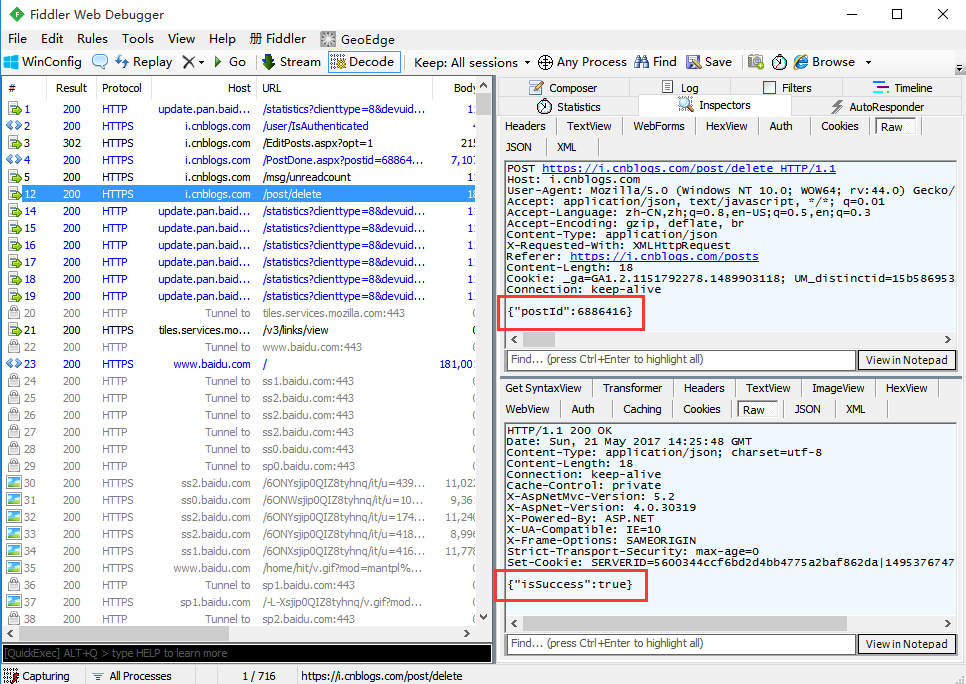
3.这个postId哪里来的呢?可以看上个请求url地址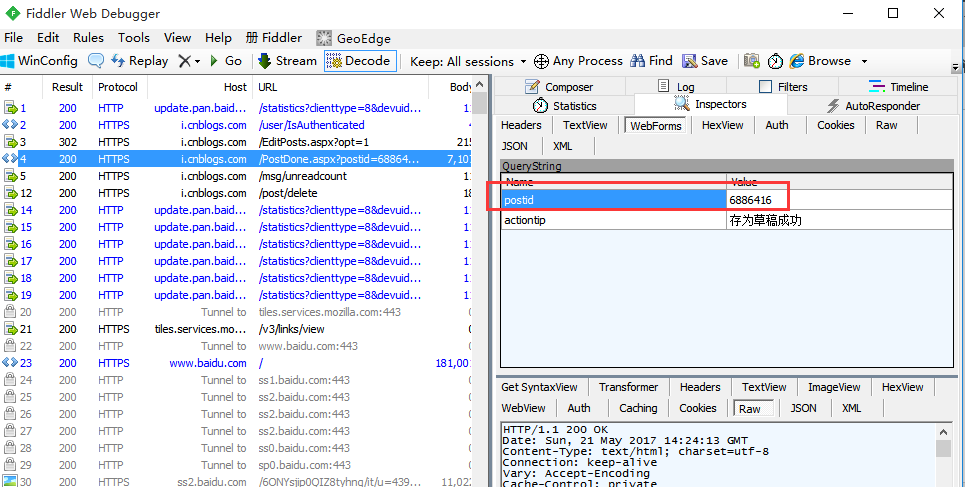
4.也就是说保存草稿箱成功之后,重定向一个url地址,里面带有postId这个参数。那接下来我们提取出来就可以了
二、提取参数
1.我们需要的参数postId是在保存成功后url地址,这时候从url地址提出对应的参数值就行了,先获取保存成功后url
2.通过正则提取需要的字符串,这个参数值前面(postid=)和后面(&)字符串都是固定的
3.这里正则提出来的是list类型,取第一个值就可以是字符串了(注意:每次保存需要修改内容,不能重复)
三,传参
1.删除草稿箱的json参数传上面取到的参数:{"postId": postid[0]}
2.json数据类型post里面填json就行,会自动转json
3.接着前面的保存草稿箱操作,就可以删除成功了
四、参考代码
# coding:utf-8
import requests
url = "https://passport.cnblogs.com/user/signin"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate, br",
"Content-Type": "application/json; charset=utf-8",
"X-Requested-With": "XMLHttpRequest",
"Content-Length": "",
"Cookie": "xxx已省略",
"Connection": "keep-alive"
}
payload = {
"input1": "xxx",
"input2": "xxx",
"remember": True}
# 第一步:session登录
s = requests.session()
r = s.post(url, json=payload, headers=headers, verify=False)
print r.json()
# 第二步:保存草稿
url2 = "https://i.cnblogs.com/EditPosts.aspx?opt=1"
body = {"__VIEWSTATE": "",
"__VIEWSTATEGENERATOR": "FE27D343",
"Editor$Edit$txbTitle": "这是我的标题:上海-悠悠",
"Editor$Edit$EditorBody": "<p>这里是中文内容:http://www.cnblogs.com/yoyoketang/</p>",
"Editor$Edit$Advanced$ckbPublished": "on",
"Editor$Edit$Advanced$chkDisplayHomePage": "on",
"Editor$Edit$Advanced$chkComments": "on",
"Editor$Edit$Advanced$chkMainSyndication": "on",
"Editor$Edit$lkbDraft": "存为草稿",
}
r2 = s.post(url2, data=body, verify=False)
# 获取当前url地址
print r2.url
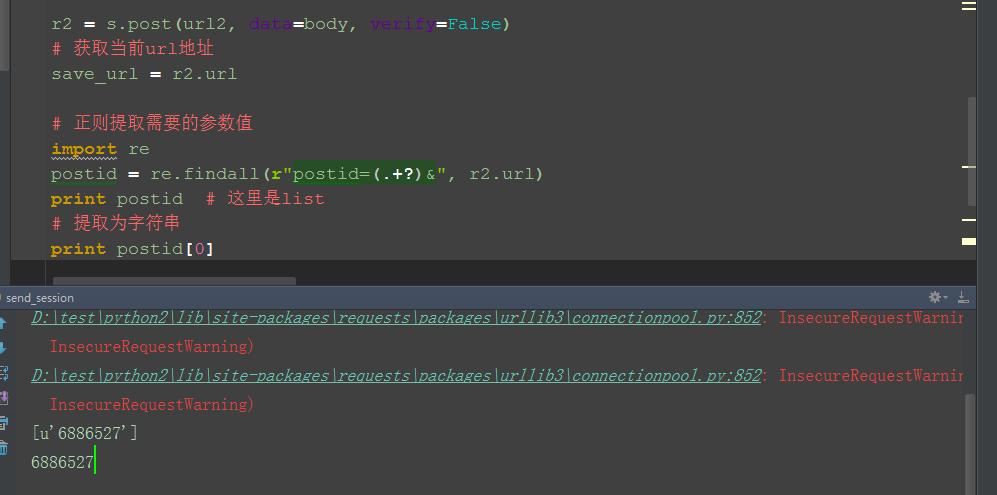
# 第三步:正则提取需要的参数值
import re
postid = re.findall(r"postid=(.+?)&", r2.url)
print postid # 这里是list
# 提取为字符串
print postid[0]
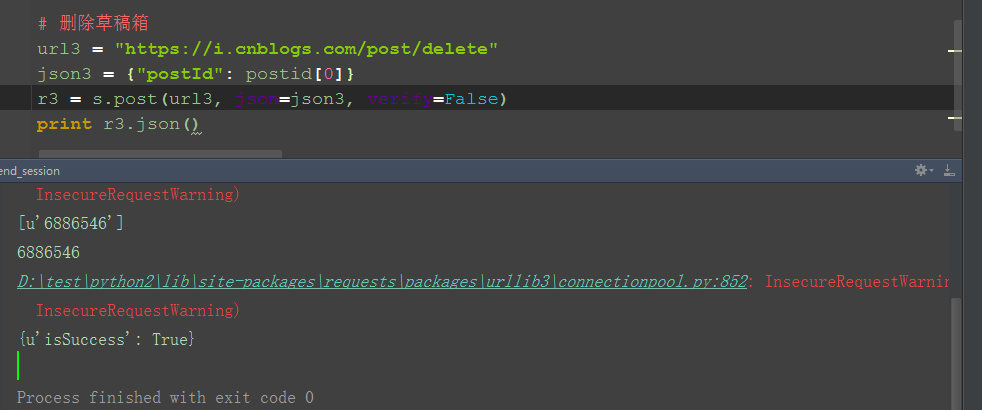
# 第四步:删除草稿箱
url3 = "https://i.cnblogs.com/post/delete"
json3 = {"postId": postid[0]}
r3 = s.post(url3, json=json3, verify=False)
print r3.json()
2.11 token登录
前言
有些登录不是用cookie来验证的,是用token参数来判断是否登录。
token传参有两种一种是放在请求头里,本质上是跟cookie是一样的,只是换个单词而已;另外一种是在url请求参数里,这种更直观。
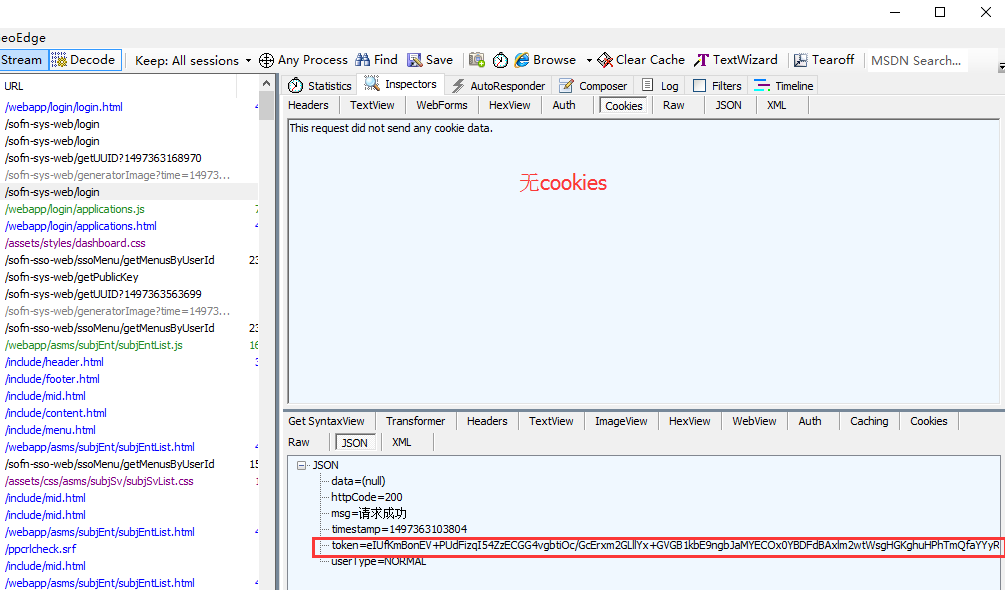
一、登录返回token
1.如下图的这个登录,无cookies
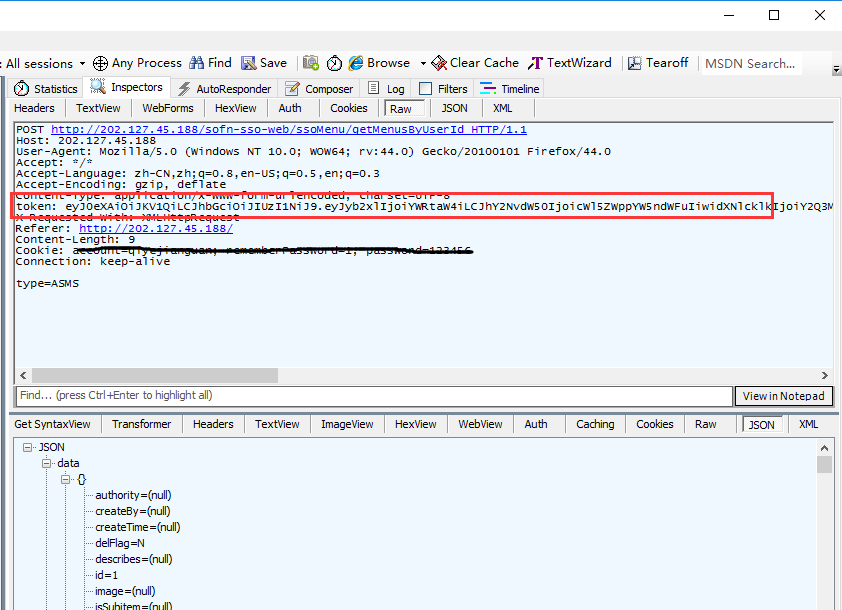
2.但是登录成功后有返回token
二、请求头带token
1.登录成功后继续操作其它页面,发现post请求的请求头,都会带token参数
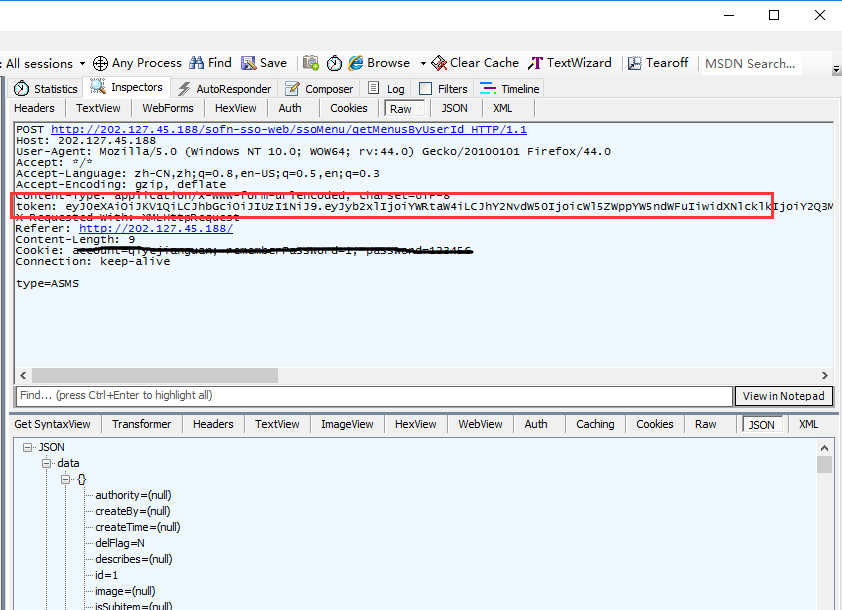
2.这种请求其实比cookie更简单,直接把登录后的token放到头部就行
三、token关联
1.用脚本实现登录,获取token参数,获取后传参到请求头就可以了
2.如果登录有验证码,前面的脚本登录步骤就省略了,自己手动登录后获取token
# coding:utf-8
import requests
header = { # 登录抓包获取的头部
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0",
"Accept": "*/*",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"X-Requested-With": "XMLHttpRequest",
"Content-Length": "",
"Connection": "keep-alive"
}
body = {"key1": "value1",
"key2": "value2"} # 这里账号密码就是抓包的数据
s = requests.session()
login_url = "http://xxx.login" # 自己找带token网址
login_ret = s.post(login_url, headers=header, data=body)
# 这里token在返回的json里,可以直接提取
token = login_ret.json()["token"]
# 这是登录后发的一个post请求
post_url = "http://xxx"
# 添加token到请求头
header["token"] = token
# 如果这个post请求的头部其它参数变了,也可以直接更新
header["Content-Length"]=""
body1 = {
"key": "value"
}
post_ret = s.post(post_url, headers=header, data=body1)
print post_ret.content
2.12登录案例分析(csrfToken)
前言:
有些网站的登录方式跟前面讲的博客园cookies登录和token登录会不一样,把csrfToken放到cookies里,登录前后cookies是没有任何变化的,这种情况下如何绕过前端的验证码登录呢?
一、登录前后对比
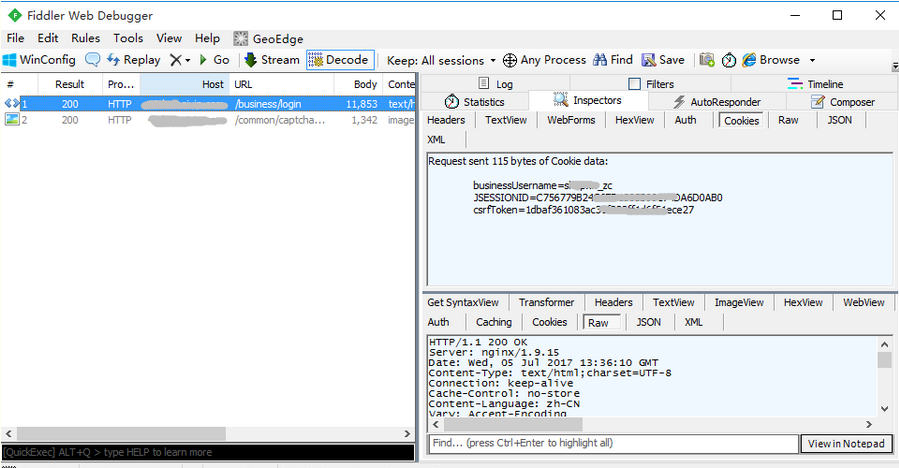
1.如果登录页面有图形验证码,这种我们一般都是绕过登录的方式,如下图通过抓包分析,首先不输入密码,抓包
(由于这个是别人公司内部网站,所以网址不能公开,仅提供解决问题的思路)
2.在登录页面输入账号和密码手动登录后,抓包信息如下
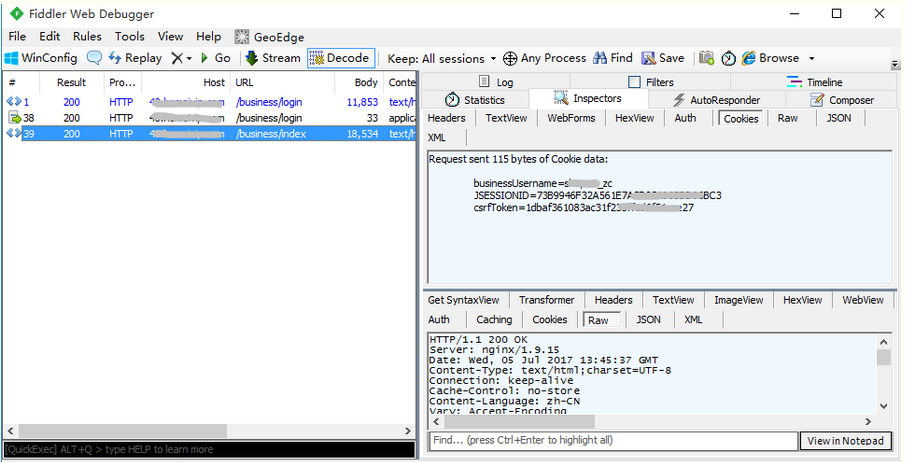
3.抓包后cookies信息在登录前后没任何变化,这里主要有三个参数:
--businessUsername:这个是账号名称
--JSESSIONID: 这个是一串字符串,主要看这个会不会变(一般有有效期)copy出来就行
--csrfToken: 这个是一串字符串,主要看这个会不会变(一般有有效期)copy出来就行
二、get请求
1.像这种登录方式的get请求,请求头部cookie没任何变化,这种可以直接忽略登录,不用管登录过程,直接发请求就行
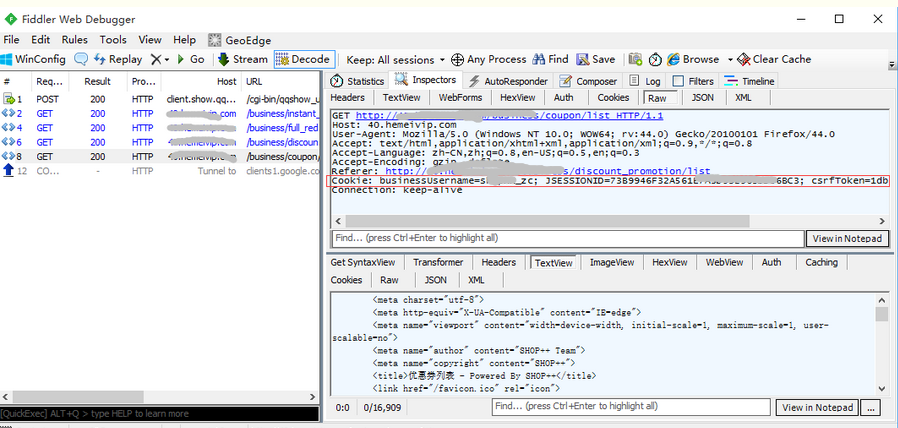
2.代码实现
# coding:utf-8
import requests
# 优惠券列表
url = 'http://xxx/xxx/coupon/list'
h = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate",
"Cookie": "csrfToken=xxx(复制抓包的信息); JSESSIONID=xxx(复制抓包的信息); businessUsername=(用户名)",
"Connection": "keep-alive"
}
r = requests.get(url, headers=h)
print r.content
三、post请求遇到的坑
1.post请求其实也可以忽略登录的过程,直接抓包把cookie里的三个参数(businessUsername、JSESSIONID、csrfToken)加到头部也是可以的。
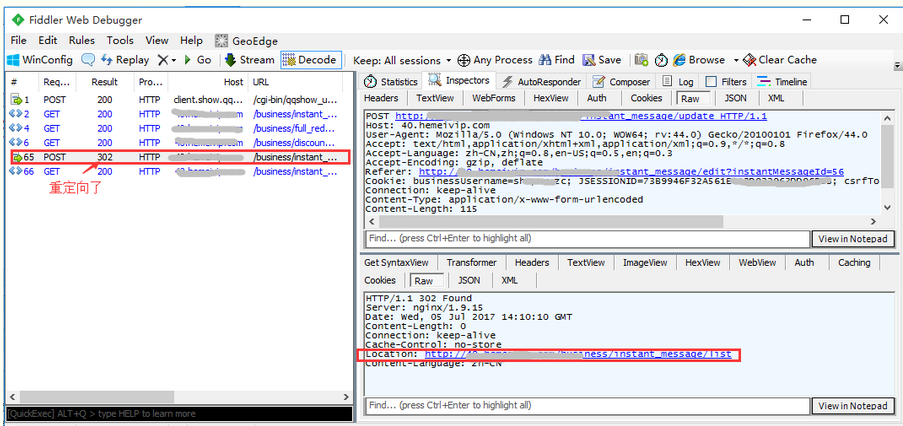
2.但是这里遇到一个坑:用Composer发请求,重定向回到登录页了
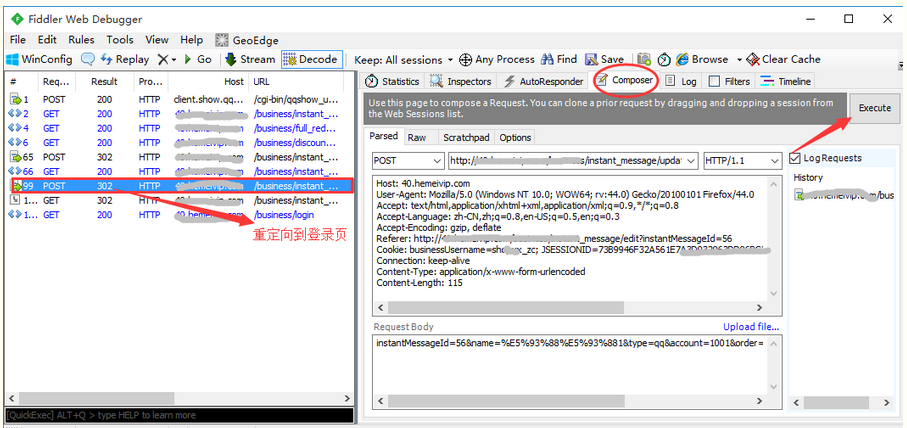
3.主要原因:重定向的请求,cookie参数丢失了
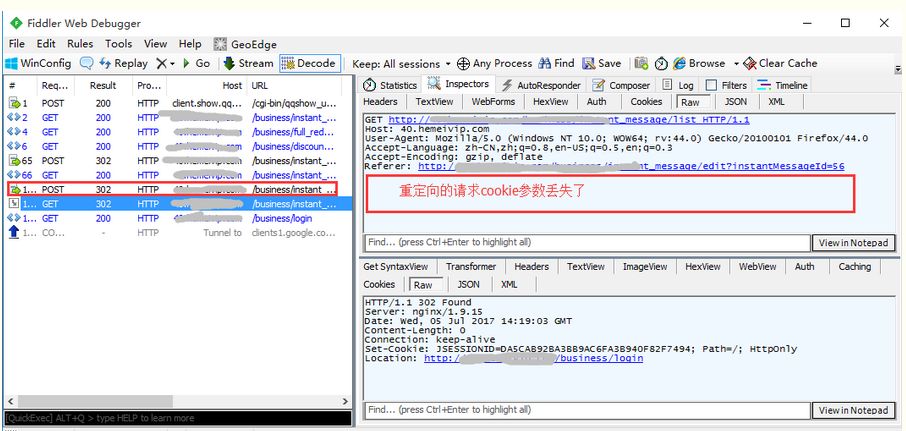
四、重定向
1.解决上面问题,其实很简单,把重定向禁用(具体看2.8重定向Location这篇)后的链接获取到,重新发个get请求,头部带上cookies的三个参数就行了
# coding:utf-8
import requests
# 主要是post请求后重定向,cookie丢失,所以回到登录页面了
# 解决办法,禁止重定向,获取重定向的url后,重新发重定向的url地址请求就行了
# 三个主要参数
csrfToken = '获取到的csrftoken,一般有有效期的'
jsessionId = '获取到的jsessionid'
userName = '用户名'
url = 'http://xxx/xxxx/update'
h1 = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:46.0) Gecko/20100101 Firefox/46.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate",
"Cookie": "csrfToken=%s; JSESSIONID=%s; businessUsername=%s" % (csrfToken, jsessionId, userName),
"Connection": "keep-alive",
"Content-Type": "application/x-www-form-urlencoded",
"Content-Length": ""
}
body = {"instantMessageId":"",
"name": u"哈哈1",
"order": "",
"csrfToken": csrfToken,
"type": "qq",
"account": ""}
s = requests.session()
r1 = s.post(url, headers=h1, data=body, allow_redirects=False)
print r1.status_code
# 获取重定向的url地址
redirect_url = r1.headers["Location"]
print redirect_url
h2 = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:46.0) Gecko/20100101 Firefox/46.0",
"Accept":
"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate",
"Cookie": "csrfToken=%s; JSESSIONID=%s; businessUsername=%s" % (csrfToken, jsessionId, userName),
"Connection": "keep-alive"
}
r2 = s.get(redirect_url, headers=h2)
print r2.content
Python+Requests接口测试教程(2):requests的更多相关文章
- Python+Requests接口测试教程(1):Fiddler抓包工具
本书涵盖内容:fiddler.http协议.json.requests+unittest+报告.bs4.数据相关(mysql/oracle/logging)等内容.刚买须知:本书是针对零基础入门接口测 ...
- Python+Requests接口测试教程(2):
开讲前,告诉大家requests有他自己的官方文档:http://cn.python-requests.org/zh_CN/latest/ 2.1 发get请求 前言requests模块,也就是老污龟 ...
- python WEB接口自动化测试之requests库详解
由于web接口自动化测试需要用到python的第三方库--requests库,运用requests库可以模拟发送http请求,再结合unittest测试框架,就能完成web接口自动化测试. 所以笔者今 ...
- python mysql redis mongodb selneium requests二次封装为什么大都是使用类的原因,一点见解
1.python mysql redis mongodb selneium requests举得这5个库里面的主要被用户使用的东西全都是面向对象的,包括requests.get函数是里面每次都是实例 ...
- Requests接口测试-对cookies的操作处理(一)
大家都对cookie都不陌生,我们本篇文章使用requests结合cookie进行实例演示.我们使用一个接口项目地址,因为接口项目涉及到隐私问题,所以这里接口的地址我暂时不会给大家开放,但是我会给大家 ...
- Requests接口测试(五)
使用python+requests编写接口测试用例 好了,有了前几章的的基础,写下来我把前面的基础整合一下,来一个实际的接口测试练习吧. 接口测试流程 1.拿到接口的URL地址 2.查看接口是用什么方 ...
- 零基础Python接口测试教程
目录 一.Python基础 Python简介.环境搭建及包管理 Python基本语法 基本数据类型(6种) 条件/循环 文件读写(文本文件) 函数/类 模块/包 常见算法 二.接口测试快速实践 简单接 ...
- 【Python爬虫】爬虫利器 requests 库小结
requests库 Requests 是一个 Python 的 HTTP 客户端库. 支持许多 HTTP 特性,可以非常方便地进行网页请求.网页分析和处理网页资源,拥有许多强大的功能. 本文主要介绍 ...
- python爬虫学习(6) —— 神器 Requests
Requests 是使用 Apache2 Licensed 许可证的 HTTP 库.用 Python 编写,真正的为人类着想. Python 标准库中的 urllib2 模块提供了你所需要的大多数 H ...
随机推荐
- java服务突然被挂掉,停止服务处理方案
一.问题背景 该问题出现在我们测试环境.测试环境部署了很多java应用. 其中一个数据服务(主要提供订单交易数据聚合查询),用着用着就服务挂掉了也就是进程没有了. 二.分析过程 1.了解服务器配置 ...
- 20170621xlVBA跨表转换数据
Sub 跨表转置() Dim Wb As Workbook Dim Sht As Worksheet Dim oSht As Worksheet Dim Rng As Range Dim Index ...
- spojPlay on Words
题意:给出几个词语,问能不能接龙. 一开始猜只要所有字母连通,并且只有一个字母出现在开头次数为奇,一个字母末尾为奇,其它偶,就行.后来发现全为偶也行.而且条件也不对,比如ac,ac,ac就不行.实际上 ...
- mac 安装phpunit
大部分内容来自:https://blog.csdn.net/aishangyutian12/article/details/64124536 感谢创作,感谢分享 单元测试的重要性就不说了,postma ...
- UI线程和工作者线程
本文转载于:http://blog.csdn.net/libaineu2004/article/details/40398405 1.线程分为UI线程和工作者线程,UI线程有窗口,窗口自建了消息队列, ...
- Linux 强制安装rpm 包
Linux 强制安装rpm 包 2014年12月12日 10:21 [root@ilearndb1 Server]# rpm -ivh unixODBC-devel-2.* --nodeps -- ...
- dubbo的超时重试
dubbo的超时分为服务端超时 SERVER_TIMEOUT 和客户端超时 CLIENT_TIMEOUT.本文讨论服务端超时的情形: 超时:consumer发送调用请求后,等待服务端的响应,若超过ti ...
- 使用GAN进行异常检测——可以进行网络流量的自学习哇,哥哥,人家是半监督,无监督的话,还是要VAE,SAE。
实验了效果,下面的还是图像的异常检测居多. https://github.com/LeeDoYup/AnoGAN https://github.com/tkwoo/anogan-keras 看了下,本 ...
- elment-ui table组件 -- 远程筛选排序
elment-ui table组件 -- 远程筛选排序 基于 elment-ui table组件 开发,主要请求后台实现筛选 排序的功能. 需求 排序 筛选 是对后台整个数据进行操作,而不是对当前页面 ...
- PHP:第三章——PHP中表达式函数和匿名函数
<?php header("Content-Type:text/html;charset=utf-8"); //表达式函数和匿名函数 /*$A=function(){ ech ...