【转】python基础-编码与解码
【转自:https://www.cnblogs.com/OldJack/p/6658779.html】
一、什么是编码
编码是指信息从一种形式或格式转换为另一种形式或格式的过程。
在计算机中,编码,简而言之,就是将人能够读懂的信息(通常称为明文)转换为计算机能够读懂的信息。众所周知,计算机能够读懂的是高低电平,也就是二进制位(0,1组合)。
而解码,就是指将计算机的能够读懂的信息转换为人能够读懂的信息。
二、 编码的发展渊源
之前的博客中已经提过,由于计算机最早在美国发明和使用,所以一开始人们使用的是ASCII编码。ASCII编码占用1个字节,8个二进制位,最多能够表示2**8=256个字符。
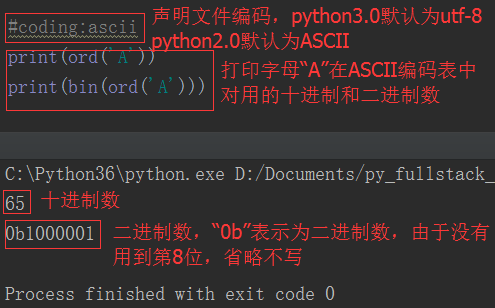
随着计算机的发展,ASCII码已经不能满足世界人民的需求。因为世界各国语言繁多,字符远远超过256个。所以各个国家都在ASCII基础上搞自己国家的编码。
例如中国,为了处理汉字,设计了GB2312编码,一共收录了7445个字符,包括6763个汉字和682个其它符号。1995年的汉字扩展规范GBK1.0收录了21886个符号。2000年的 GB18030是取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。

但是,在编码上,各国”各自为政“,很难互相交流。于是出现了Unicode编码。Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。
Unicode规定字符最少使用2个字节表示,所以最少能够表示2**16=65536个字符。这样看来,问题似乎解决了,各国人民都能够将自己的文字和符号加入Unicode,从此就可以轻松交流了。
然而,在当时,计算机的内存容量可是寸土寸金的情况下,美国等北美洲国家是不接受这个编码的。因为这凭空增加了他们文件的体积,进而影响了内存使用率,影响工作效率。这就尴尬了。
显然国际标准在美国这边不受待见,所以应运而生产生了utf-8编码。
UTF-8,是对Unicode编码的压缩和优化,它不再要求最少使用2个字节,而是将所有的字符和符号进行分类:ASCII码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存。
这样,大家各取所需,皆大欢喜。
三、utf-8是如何节省存储空间和流量的
当计算机在工作时,内存中的数据一直是以Unicode的编码方式表示的,当数据要保存到磁盘或者网络传输时,才会使用utf-8编码进行操作。
在计算机中,”I'm 杰克"的unicode字符集是这样的编码表:
I 0x49
' 0x27
m 0x6d
0x20
杰 0x6770
克 0x514b
每个字符对应一个十六进制数(方便人们阅读,0x代表十六进制数),但是计算机只能读懂二进制数,所以,实际在计算机内表示如下:
I 0b1001001
' 0b100111
m 0b1101101
0b100000
杰 0b110011101110000
克 0b101000101001011
I 00000000 01001001
' 00000000 00100111
m 00000000 01101101
00000000 00100000
杰 01100111 01110000
克 01010001 01001011
这串字符总共占用了12个字节,但是对比中英文的二进制码,可以发现,英文的前9位都是0,非常的浪费空间和流量。
看看utf-8是怎么解决的:
I 01001001
'
m 01101101
00100000
杰 11100110 10011101 10110000
克 11100101 10000101 10001011
utf-8用了10个字节,对比Unicode,少了2个字节。但是,我们的程序中很少用到中文,如果我们程序中90%的内容都是英文,那么可以节省45%的存储空间或者流量。
所以,在存储和传输时,大部分时候遵循utf-8编码

四、Python2.x与Python3.x中的编解码
1. 在Python2.x中,有两种字符串类型:str和unicode类型。str存bytes数据,unicode类型存unicode数据
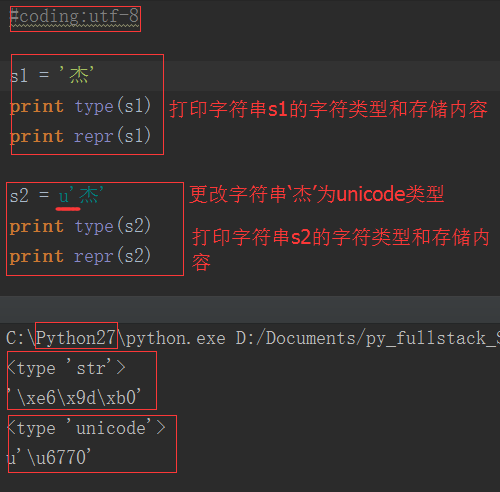
由上图可以看出,str类型存储的是十六进制字节数据;unicode类型存储的是unicode数据。utf-8编码的中文占3个字节,unicode编码的中文占2个字节。
字节数据常用来存储和传输,unicode数据用来显示明文,那如何转换两种数据类型呢:
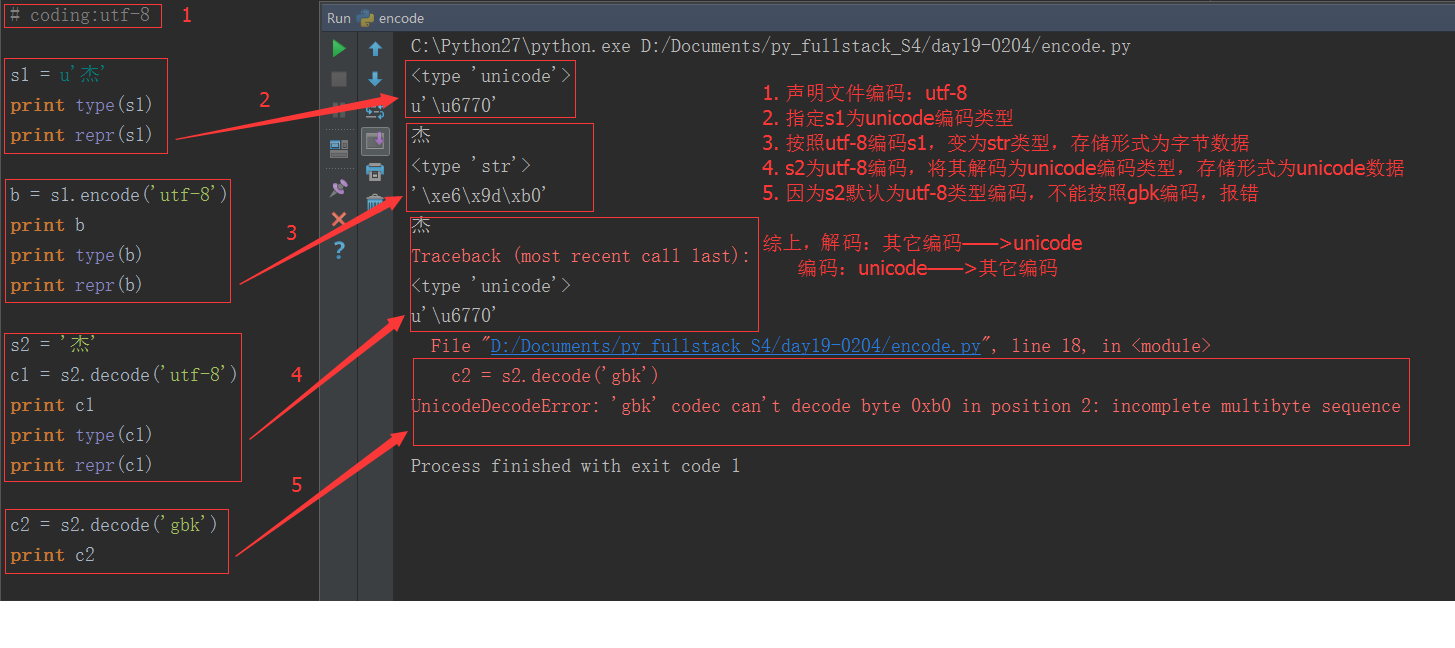
无论是utf-8还是gbk都只是一种编码规则,一种把unicode数据编码成字节数据的规则,所以utf-8编码的字节一定要用utf-8的规则解码,否则就会出现乱码或者报错的情况。
python2.x编码的特色:
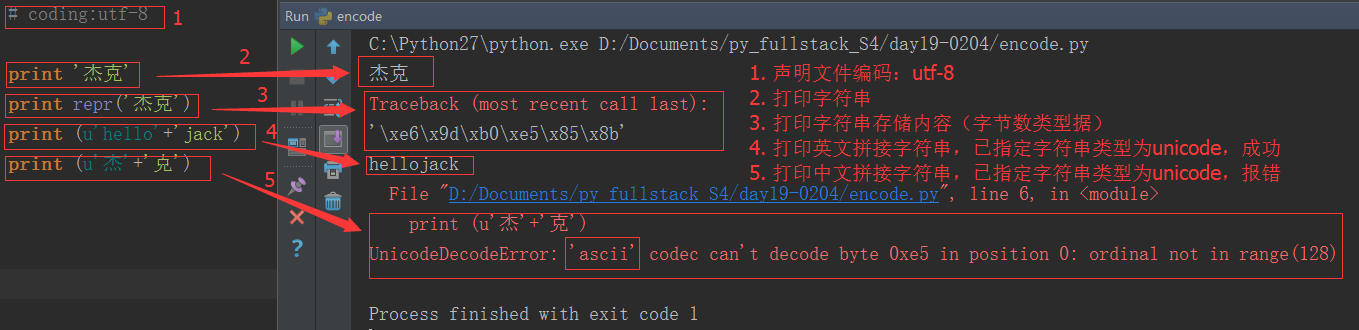
为什么英文拼接成功了,而中文拼接就报错了?
这是因为在python2.x中,python解释器悄悄掩盖掉了 byte 到 unicode 的转换,只要数据全部是 ASCII 的话,所有的转换都是正确的,一旦一个非 ASCII 字符偷偷进入你的程序,那么默认的解码将会失效,从而造成 UnicodeDecodeError 的错误。python2.x编码让程序在处理 ASCII 的时候更加简单。你付出的代价就是在处理非 ASCII 的时候将会失败。
2. 在Python3.x中,也只有两种字符串类型:str和bytes类型。
str类型存unicode数据,bytse类型存bytes数据,与python2.x比只是换了一下名字而已。
还记得之前博文中提到的这句话吗?ALL IS UNICODE NOW
python3 renamed the unicode type to str ,the old str type has been replaced by bytes.

Python 3最重要的新特性大概要算是对文本和二进制数据作了更为清晰的区分,不再会对bytes字节串进行自动解码。文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。Python 3不会以任意隐式的方式混用str和bytes,正是这使得两者的区分特别清晰。你不能拼接字符串和字节包,也无法在字节包里搜索字符串(反之亦然),也不能将字符串传入参数为字节包的函数(反之亦然)。
注意:无论python2,还是python3,与明文直接对应的就是unicode数据,打印unicode数据就会显示相应的明文(包括英文和中文)
五、文件从磁盘到内存的编码
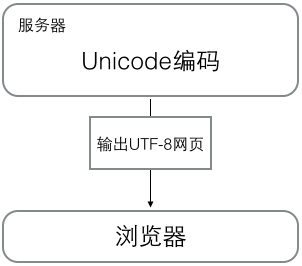
当我们在编辑文本的时候,字符在内存对应的是unicode编码的,这是因为unicode覆盖范围最广,几乎所有字符都可以显示。但是,当我们将文本等保存在磁盘时,数据是怎么变化的?
答案是通过某种编码方式编码的bytes字节串。比如utf-8,一种可变长编码,很好的节省了空间;当然还有历史产物的gbk编码等等。于是,在我们的文本编辑器软件都有默认的保存文件的编码方式,比如utf-8,比如gbk。当我们点击保存的时候,这些编辑软件已经"默默地"帮我们做了编码工作。
那当我们再打开这个文件时,软件又默默地给我们做了解码的工作,将数据再解码成unicode,然后就可以呈现明文给用户了!所以,unicode是离用户更近的数据,bytes是离计算机更近的数据。
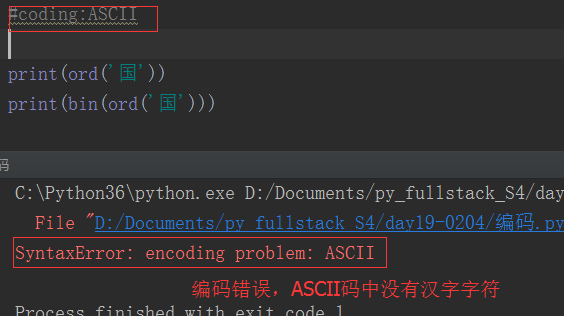
其实,python解释器也类似于一个文本编辑器,它也有自己默认的编码方式。python2.x默认ASCII码,python3.x默认的utf-8,可以通过如下方式查询:
import sys
print(sys.getdefaultencoding()) 输出:ascii
如果我们不想使用默认的解释器编码,就得需要用户在文件开头声明了。还记得我们经常在python2.x中的声明吗?
#coding:utf-8
如果python2解释器去执行一个utf-8编码的文件,就会以默认的ASCII去解码utf-8,一旦程序中有中文,自然就解码错误了,所以我们在文件开头位置声明 #coding:utf-8,其实就是告诉解释器,你不要以默认的编码方式去解码这个文件,而是以utf-8来解码。而python3的解释器因为默认utf-8编码,所以就方便很多了。
参考资料
1. http://www.cnblogs.com/yuanchenqi/articles/5956943.html
2. http://www.cnblogs.com/284628487a/p/5584714.html
以下为实验的示例代码:
#coding:utf-8
s = "杰"
print type(s)
print repr(s) n = u"杰"
print type(n)
print repr(n) m = u"123456asdsfdf"
print type(m)
print repr(m) p = m.encode('unicode-escape').decode('string_escape')
print type(p)
print repr(p) p1 = m.encode('utf-8')
print type(p1)
print repr(p1) p2 = m.encode('gbk')
print type(p2)
print repr(p2) p3= m.encode('ascii')
print type(p3)
print repr(p3) print "****************************" pn =n.encode('unicode-escape').decode('string_escape')
print type(pn)
print repr(pn) pn1 = n.encode('utf-8')
print type(pn1)
print repr(pn1) pn2 = n.encode('gbk')
print type(pn2)
print repr(pn2) pn3= n.encode('ascii')
print type(pn3)
print repr(pn3)
输出为:
<type 'str'>
'\xe6\x9d\xb0'
<type 'unicode'>
u'\u6770'
<type 'unicode'>
u'123456asdsfdf'
<type 'str'>
'123456asdsfdf'
<type 'str'>
'123456asdsfdf'
<type 'str'>
'123456asdsfdf'
<type 'str'>
'123456asdsfdf'
****************************
<type 'str'>
'\\u6770'
<type 'str'>
'\xe6\x9d\xb0'
<type 'str'>
'\xbd\xdc'
Traceback (most recent call last):
File "D:/python/face1N/src/encode_decode.py", line 45, in <module>
pn3= n.encode('ascii')
UnicodeEncodeError: 'ascii' codec can't encode character u'\u6770' in position 0: ordinal not in range(128)
import os
import MySQLdb
import shutil path ="D:\\renzhengzhaopian\\face_card_2\\"
new_path = "D:\\renzhengzhaopian\\face_card_2_fushu\\"
result_txt = "D:\\renzhengzhaopian\\result2_chuli.txt" ip = "*.*.*.*"
username = "username "
password = "password "
dbname = "dbname " def selectFromMysql():
conn = MySQLdb.connect(host=ip, port=3306, user=username, passwd=password, charset='utf-8')
cur = conn.cursor()
try:
cur.execute("use openwrt_ng;")
sqltext = "select facename from test0509 where result < 0;"
cur.execute(sqltext)
result = cur.fetchall()
resultlist = []
for i in range(len(result)):
#sql查出来的结果是元组,其中元素是unicode编码的(type类型打印为unicode,要转变成str类型(str和unicode类型。str存bytes数据,unicode类型存unicode数据))
#当对str进行编码时,python会先用默认编码将自己解码为unicode,然后在将unicode编码为你指定编码
#resultlist.append(result[i][0].encode('unicode-escape').decode('string_escape')) ??这里的编解码还是不懂。。。。 resultlist.append(result[i][0].encode('utf-8'))
return resultlist
except Exception as e:
print e
finally:
cur.close()
conn.close()
def fileIntersection(path):
resultlist = selectFromMysql()
filelist = os.listdir(path)
lists = list(set(resultlist).intersection(filelist)) #取交集
return lists
def copyfile(path,new_path):
for filename in fileIntersection(path):
shutil.copytree(path + os.sep + filename,new_path + os.sep + filename)
if __name__ == "__main__":
findfile(path, new_path)
#rmfromtxt(result_txt)
【转】python基础-编码与解码的更多相关文章
- Python基础-编码与解码
一.什么是编码 编码是指信息从一种形式或格式转换为另一种形式或格式的过程. 在计算机中,编码,简而言之,就是将人能够读懂的信息(通常称为明文)转换为计算机能够读懂的信息.众所周知,计算机能够读懂的 ...
- Python的编码和解码
Python的编码和解码 在不同的国家,存在不同的文字,由于现在的软件都要做到国际化通用,所以必须要有一种语言或编码方式,来实现各种编码的解码,然后重新编码. 在西方国家,没有汉字,只有英文,所以最开 ...
- Python 基础 编码
Python 基础 编码 咱们的电脑,存储和发送文件,发送的是什么?电脑里面是不是有成千上万个二极管,亮的代表是1,不亮的代表是0,这样实际上电脑的存储和发送是不是都是010101啊 我们发送的内容都 ...
- 【转】python 字符编码与解码——unicode、str和中文:UnicodeDecodeError: 'ascii' codec can't decode
原文网址:http://blog.csdn.net/trochiluses/article/details/16825269 摘要:在进行python脚本的编写时,如果我们用python来处理网页数据 ...
- python base64编码和解码图片
简介 在实际项目中,可能需要对图片进行大小的压缩,较为常见的方法则是将图片转换为base64的编码,本文就python编码和解码图片做出一定的介绍. 代码 import base64 import o ...
- python之编码与解码、is 与==的区别
一.编码与解码 编码的过程其实就是采用一定的编码格式将unicode字符转换成str字符的过程 非ASCII码字符按字节为单位被编码成十六进制转义字符 解码采用的编码格式跟设置和环境有关 ascii ...
- python之编码与解码
编码 字符串被当作url提交时会被自动进行url编码处理,在python里也有个urllib.urlencode的方法,可以很方便的把字典形式的参数进行url编码.当url地址含有中文或者“/”的时候 ...
- python基础 (编码进阶,文件操作和深浅copy)
1.编码的进阶 字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码. 即先将其他编码的字符串解码(decode)成unicode,再从uni ...
- Python基础—编码(Day2)
一.字符编码 1.ASCII码:包含英文.数字.特殊字符,8位=1字节byte =1个字符,如: 0010 1010 ASCII码表里的字符总共有256个,前128个为常用的字符如运算符,后128个称 ...
随机推荐
- CentOS配置iptables规则并使其永久生效
1. 目的 最近为了使用nginx,配置远程连接的使用需要使用iptable是设置允许外部访问80端口,但是设置完成后重启总是失效.因此百度了一下如何设置永久生效,并记录. 2. 设置 2.1 添加 ...
- vsftpd配置手册(实用)
作者: 木頭 来源: PHPChina 开源社区门户1.vsftpd配置参数详细整理 #接受匿名用户 anonymous_enable=YES #匿名用户login时不询问口令 no_anon_ ...
- 雷林鹏分享:C# 多线程
C# 多线程 线程 被定义为程序的执行路径.每个线程都定义了一个独特的控制流.如果您的应用程序涉及到复杂的和耗时的操作,那么设置不同的线程执行路径往往是有益的,每个线程执行特定的工作. 线程是轻量级进 ...
- Python递归遍历《指定目录》下的所有《文件》
https://www.cnblogs.com/dreamer-fish/p/3820625.html
- 『OpenCV3』Harris角点特征_API调用及python手动实现
一.OpenCV接口调用示意 介绍了OpenCV3中提取图像角点特征的函数: # coding=utf- import cv2 import numpy as np '''Harris算法角点特征提取 ...
- kubectl管理多个k8s集群
#把每个k8s集群的json配置文件放到/root/.kube/目录下,改为不同名字,通过--kubeconfig实现不同集群操作 kubectl --kubeconfig=/root/.kube/m ...
- ORACLE11G内存管理参数
今天,对ORACLE11G的几个内存参数看了一下,记录如下,大家可以参考: 1.首先,在ORACLE11G的INIT.ORA里,有“__”开头的参数,也就是以两个下划线开头的参数,这种参数应该是系统自 ...
- CachedThreadPool里的线程是如何被回收的?
线程池创建线程的逻辑图: 我们分析CachedThreadPool线程池里的线程是如何被回收的. //Executors public static ExecutorService newCached ...
- Pycharm(一)下载安装
https://www.python.org/downloads/windows/ 这里下载python,建议2.7,3.6都下载 Download Windows x86 web-based ins ...
- android开源项目集合
ZXing http://code.google.com/p/zxing/ 条形码.二维码 K-9 Mail http://code.google.com/p/k9mail/ 邮件客户端 Sipdro ...