数据分析与挖掘 - R语言:K-means聚类算法
一个简单的例子!
环境:CentOS6.5
Hadoop集群、Hive、R、RHive,具体安装及调试方法见博客内文档。
1、分析题目
--有一个用户点击数据样本(husercollect)
--按用户访问的时间(时)统计
--要求:分析时间和点击次数的聚类情况
2、数据准备
--创建临时表
DROP TABLE if exists tmp.t2_collect;
CREATE TABLE tmp.t2_collect(
h int,
cnt int
) COMMENT '用户点击数据临时表'; --插入临时表
insert overwrite table tmp.t2_collect
--分组
select a1.h, count(1) as cnt from(
--取出时
select hour(createtime) as h from bdm.husercollect
)a1
group by a1.h;
3、评估K值
#!/usr/bin/Rscript
library(RHive)
rhive.connect(host ='192.168.107.82')
data <- rhive.query('select h,cnt from tmp.t2_collect limit 6000')
x <- data$h
y <- data$cnt --组合成数据框
df <- data.frame(x, y)
--添加列名
colnames(df) <- c("hour", "cnt") --cluster.stats函数需要使用fpc库
library(fpc) --k取2到8评估K
K <- 2:8
--每次迭代30次,避免局部最优
round <- 30
rst <- sapply(K, function(i){
print(paste("K=",i))
mean(sapply(1:round,function(r){
print(paste("Round",r))
result <- kmeans(df, i)
stats <- cluster.stats(dist(df), result$cluster)
stats$avg.silwidth
}))
}) --加载图形库
library(Cairo)
png("k-points-pic.png", width=800, height=600)
plot(K, rst, type='l', main='outline & R relation', ylab='outline coefficient') dev.off()
rhive.close()
评估结果:
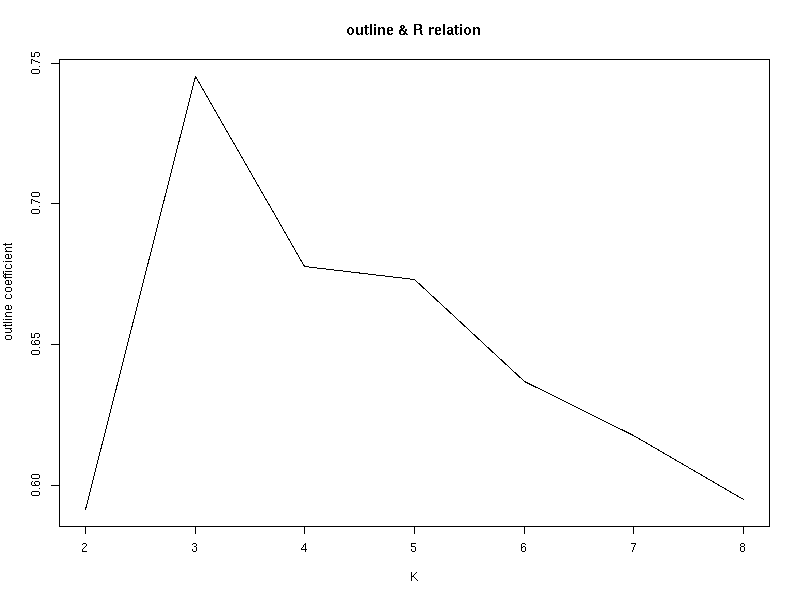
由上图可见当K=3时,轮廓系数最大。
4、聚类分析
#!/usr/bin/Rscript
library(RHive)
rhive.connect(host ='192.168.107.82')
data <- rhive.query('select h,cnt from tmp.t2_collect limit 6000')
x <- data$h
y <- data$cnt --组合成数据框
df <- data.frame(x, y)
--添加列名
colnames(df) <- c("hour", "cnt") --Kmeans
kc <- kmeans(df, 3); --具体分类情况
--fitted(kc); library(Cairo)
png("k-means-pic.png", width=800, height=600)
plot(df[c("hour", "cnt")], col = kc$cluster, pch = 8);
points(kc$centers[,c("hour", "cnt")], col = 1:3, pch = 8, cex=2); dev.off()
rhive.close()
聚类结果:

至此,一个简单的K-means聚类算法实例完成!
数据分析与挖掘 - R语言:K-means聚类算法的更多相关文章
- 零基础数据分析与挖掘R语言实战课程(R语言)
随着大数据在各行业的落地生根和蓬勃发展,能从数据中挖金子的数据分析人员越来越宝贝,于是很多的程序员都想转行到数据分析, 挖掘技术哪家强?当然是R语言了,R语言的火热程度,从TIOBE上编程语言排名情况 ...
- 数据分析与挖掘 - R语言:贝叶斯分类算法(案例一)
一个简单的例子!环境:CentOS6.5Hadoop集群.Hive.R.RHive,具体安装及调试方法见博客内文档. 名词解释: 先验概率:由以往的数据分析得到的概率, 叫做先验概率. 后验概率:而在 ...
- 数据分析与挖掘 - R语言:KNN算法
一个简单的例子!环境:CentOS6.5Hadoop集群.Hive.R.RHive,具体安装及调试方法见博客内文档. KNN算法步骤:需对所有样本点(已知分类+未知分类)进行归一化处理.然后,对未知分 ...
- 数据分析与挖掘 - R语言:多元线性回归
一个简单的例子!环境:CentOS6.5Hadoop集群.Hive.R.RHive,具体安装及调试方法见博客内文档. 线性回归主要用来做预测模型. 1.准备数据集: X Y 0.10 42.0 0.1 ...
- 数据分析与挖掘 - R语言:贝叶斯分类算法(案例三)
案例三比较简单,不需要自己写公式算法,使用了R自带的naiveBayes函数. 代码如下: > library(e1071)> classifier<-naiveBayes(iris ...
- 数据分析与挖掘 - R语言:贝叶斯分类算法(案例二)
接着案例一,我们再使用另一种方法实例一个案例 直接上代码: #!/usr/bin/Rscript library(plyr) library(reshape2) #1.根据训练集创建朴素贝叶斯分类器 ...
- 【机器学习与R语言】11- Kmeans聚类
目录 1.理解Kmeans聚类 1)基本概念 2)kmeans运作的基本原理 2.Kmeans聚类应用示例 1)收集数据 2)探索和准备数据 3)训练模型 4)评估性能 5)提高模型性能 1.理解Km ...
- 机器学习实战---K均值聚类算法
一:一般K均值聚类算法实现 (一)导入数据 import numpy as np import matplotlib.pyplot as plt def loadDataSet(filename): ...
- 基于R语言的梯度推进算法介绍
通常来说,我们可以从两个方面来提高一个预测模型的准确性:完善特征工程(feature engineering)或是直接使用Boosting算法.通过大量数据科学竞赛的试炼,我们可以发现人们更钟爱于Bo ...
随机推荐
- 深入理解 Neutron -- OpenStack 网络实现(2):VLAN 模式
问题导读 1.br-int.br-ethx的作用是什么?2.安全组策略是如何实现的?3.VLAN 模式与GRE模式有哪些不同点?流量上有哪些不同?4.L3 agent实现了什么功能? 接上篇深入理解 ...
- 【线程】Volatile关键字
Volatile变量具有 synchronized 的可见性特性,但是不具备原子特性.这就是说线程能够自动发现 volatile变量的最新值.Volatile变量可用于提供线程安全,但是只能应用于非常 ...
- 解决:SqlDateTime 溢出。必须介于 1/1/1753 12:00:00 AM 和 12/31/9999 11:59:59 PM 之间提示问题
提示信息如下 “/”应用程序中的服务器错误. SqlDateTime 溢出.必须介于 1/1/1753 12:00:00 AM 和 12/31/9999 11:59:59 PM 之间. 问题现象: 问 ...
- 用Android Studio导出jar给Unity3D用
1.新建一个Android Studio工程,选择空Activity 2.创建一个Module 3.将Unity的依赖jar包拷贝到工程的libs下 4.增加Java代码 内容修改如下 package ...
- Windows Phone Bing lock screen doesn't change解决方法
之前一直用的Lumia 925,Bing lock screen每天都会更换.这几天换了Lumia 930,同步了账号相关的设置,发现Bing lock screen不再每天更换.尝试重启.使用cel ...
- 【CQgame】[幸运方块 v1.1.3] [Lucky_Block v1.1.3]
搬家首发!!! 其实从初一我就写过一些小型战斗的游戏,但是画面都太粗糙,代码也比较乱,也就是和两三个同学瞎玩,但自从观摩了PoPoQQQ大神的游戏,顿时产生了重新写一部游戏的冲动,于是各种上网查找各种 ...
- 【转】Hudson插件Email-Ext邮件模板时间格式化的解决方法
原文地址:http://www.cnblogs.com/haycco/archive/2012/03/20/3031397.html 最近因对Hudson版本进行了升级为2.2.0,所以各方面都在搞项 ...
- "will you marry me" vs "would you marry me"
will you marry me 表示我现在问你,能不能嫁给我,我现在就需要答案. 如果回答是yes,那么对方就算是同意嫁给你了. would you marry me 表示你能不能考虑嫁给我. w ...
- TFS二次开发11——标签(Label)
下图是在VS2010里创建Label的界面 可以看出创建Label 需要如下参数:Name.Comment.Path.Version .下面是代码实现: using Microsoft.TeamFou ...
- POJ-2081 Terrible Sets(暴力,单调栈)
Terrible Sets Time Limit: 1000MS Memory Limit: 30000K Total Submissions: 4113 Accepted: 2122 Descrip ...