3D CNN for Video Processing
3D CNN for Video Processing
Updated on 2018-08-06 19:53:57
本文主要是总结下当前流行的处理 Video 信息的深度神经网络的处理方法.
参考文献:
1. 3D Convolutional Neural Networks for Human Action Recognition T-PAMI 2013
2. Learning Spatiotemporal Features with 3D Convolutional Networks CVPR 2015
1. 3D Convolutional Neural Networks for Human Action Recognition T-PAMI 2013
Reference:https://blog.csdn.net/auto1993/article/details/70948249
摘要:本文考虑了在监控视频下进行行人动作的识别。大部分当前的方法都是基于从原始输入得到的复杂的手工设计的特征,来构建分类器。CNN是一种深度模型可以直接作用在原始输入上。然而,像这样的模型当前仅仅应用于2D的输入。本文中提出了一种新颖的3D CNN模型来进行动作识别。通过3D卷积可以得到时间和空间上的特征,从而抓住了多帧之间的运动信息。这个模型从输入帧得到多个通道的信息,最终的feature表示是组合所有通道的信息。为了进一步的提升性能,我们提出了正则化高层特征的输出和组合不同模型的预测,利用提出的这个模型来进行人类动作的识别,超过了现有的baseline方法。
本文的主要贡献点是:
(1)提出3D卷积操作得到空间和时序上的feature用来行为识别。
(2)基于3D卷积特征提取器发展了一个3D卷积神经网络结构。
(3)通过用高层运动特征得到的的额外输出来正则化3D CNN models。
(4)取得了较好的实验效果。提出的模型比普通的2D CNN 结构得到了更好的实验结果。
3D 卷积神经网络:
在普通的2D卷积神经网络中,2D卷积操作在上一层得到的feature maps 上的局部近邻提取 feature,然后添加一个额外的偏差(bias),然后将这个结果输入给一个sigmoid函数(激活函数)。从形式上来讲,第 i 层的第 j 个feature map 在位置(x, y)处的值为:

从上式可以看出,tanh(*)是激活函数,$b_{ij}$是这个feature map 的bias,m 表示和当前feature map 相连的第(i-1)层的特征映射的集合索引,W 是和第 k 个feature map 链接的核在位置(p, q) 的值,$P_i, Q_i$ 是核的高和宽。在下采样层,feature maps 的分辨率是通过在上一层的feature maps 上的局部近邻上进行pooling操作而降低。一个卷积神经网络就是通过这样 卷积和pooling的交替而堆叠在一起形成的网络结构。CNN的参数,例如:bias $b_{ij}$ 和 核权重 $W_{ijk}^{pq}$ 通过监督或者非监督的方式进行学习。
3D Convolution:
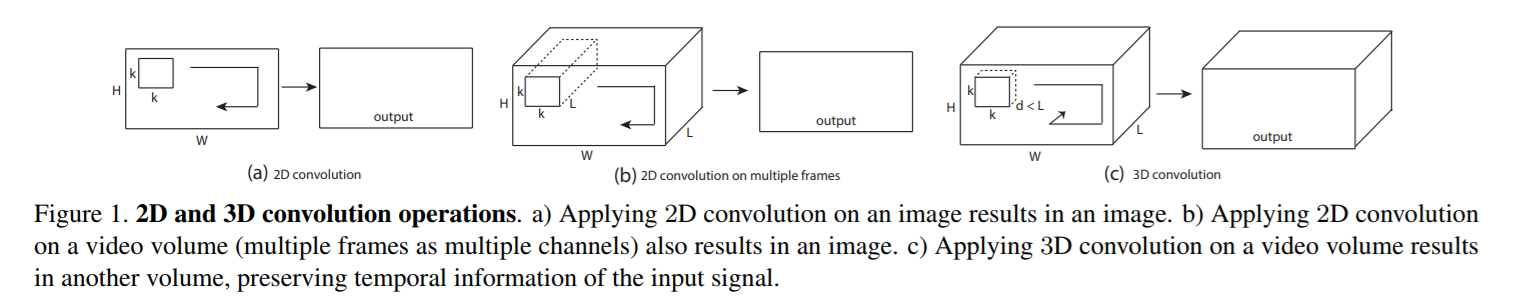
在2D CNNs,卷积都是在2D的feature map上执行,当应用到视频分析问题上时,需要编码运动信息(motion information)从多个连续帧上得到。为了达到这个目的,本文提出了3D卷积操作,在CNN的卷积阶段在时间维度和空间维度都进行特征的提取。3D卷积操作是通过卷积一个3D核在由多帧构成的cube上,通过这个构建,卷积层的feature maps在之前的层上连接成多个连续的帧,所以抓住了运动信息,最终,在第 i 层的第 j 个feature map上在位置(x, y, z)处的值为:

其中,$R_i$ 是3D kernel 沿着时间维度的大小,前一层链接第 m 个feature map 的kernel的(p, q, r)个值是 $w$。关于 2D 和 3D卷积的对比示意图如下所示:

注意到一个 3D卷积核可以从帧立方体(frame cube)中提取一种类型的feature,由于kernel weight在整个 cube上都是复制的。CNNs 一个总的设计原则是:feature maps 的个数在后面的layers 上应该是增加的,通过在同一个底层feature maps 集合上,产生多个类型的feature。和 2D CNNs 类似,我们可以在不同的 kernel 上在上一层的同一个位置应用多个不同 kernel 来进行 3D卷积操作。如图2所示:

A 3D CNN Architecture :

如上图所示,基于3D卷积操作,本文提出了一种不同的 CNN 结构。我们以当前帧为中心,考虑到 7 帧60*40的图像作为输入给 3D CNN model。我们提出采用一组 hardwired kernels 从输入帧上来产生多个通道的信息。这将会导致在第二层产生 33 个 feature maps,由 5 个不同的通道产生,分别是:灰度,梯度-x, 梯度-y, 光流-x,光流-y。灰度通道包括由7个输入帧组成的灰色像素点,梯度-x 和 梯度-y 通道分别是通过 水平和垂直方向的梯度得到的,在7个输入帧的每一个上面,都执行这样的操作,光流-x 和 光流-y 通过包括沿着水平和垂直方向的光流场,从相邻输入帧计算得到。这个 hardwired layer 用来在feature上编码我们的先验知识,这个机制会得到相对比随机初始化更好的性能。
我们然后用 kernel size 为 7*7*3 的kernel 进行3D卷积操作,其中 7*7 是在空间维度,3 是在时间维度,在5个通道分别进行卷积操作。为了增加feature map 的个数,在每一个位置都进行两组不同的操作,得到两组feature maps,每一个都包括 23 个 feature maps。在随后的采样层 S3上,我们在C2层的每一个feature map上都进行 2*2 的下采样操作。就会得到和降低的空间分辨率相同个数的 feature maps。
其余的层,类似的方法就可以推断得到。
关于这其中每一层 feature map 大小变化的原因,参考原文以及相关blog,可知:
输入层(input):连续的大小为60*40的视频帧图像作为输入。.
硬线层(hardwired,H1):每帧提取5个通道信息(灰度gray,横坐标梯度(gradient-x),纵坐标梯度(gradient-y),x光流(optflow-x),y光流(optflow-y))。前面三个通道的信息可以直接对每帧分别操作获取,后面的光流(x,y)则需要利用两帧的信息才能提取,因此
H1层的特征maps数量:(7+7+7+6+6=33),特征maps的大小依然是60* 40;
卷积层(convolution C2):以硬线层的输出作为该层的输入,对输入5个通道信息分别使用大小为7* 7 * 3的3D卷积核进行卷积操作(7* 7表示空间维度,3表示时间维度,也就是每次操作3帧图像),同时,为了增加特征maps的个数,在这一层采用了两种不同的3D卷积核,因此C2层的特征maps数量为:
(((7-3)+1)* 3+((6-3)+1)* 2)* 2=23* 2
这里右乘的2表示两种卷积核。
特征maps的大小为:((60-7)+1)* ((40-7)+1)=54 * 34
降采样层(sub-sampling S3):在该层采用max pooling操作,降采样之后的特征maps数量保持不变,因此S3层的特征maps数量为:23 *2
特征maps的大小为:((54 / 2) * (34 /2)=27 *17
卷积层(convolution C4):对两组特征maps分别采用7 6 3的卷积核进行操作,同样为了增加特征maps的数量,文中采用了三种不同的卷积核分别对两组特征map进行卷积操作。这里的特征maps的数量计算有点复杂,请仔细看清楚了。我们知道,从输入的7帧图像获得了5个通道的信息,因此结合总图S3的上面一组特征maps的数量为((7-3)+1) * 3+((6-3)+1) * 2=23,可以获得各个通道在S3层的数量分布:
前面的乘3表示gray通道maps数量= gradient-x通道maps数量= gradient-y通道maps数量=(7-3)+1)=5;
后面的乘2表示optflow-x通道maps数量=optflow-y通道maps数量=(6-3)+1=4;
假设对总图S3的上面一组特征maps采用一种7 6 3的3D卷积核进行卷积就可以获得:
((5-3)+1)* 3+((4-3)+1)* 2=9+4=13;
三种不同的3D卷积核就可获得13* 3个特征maps,同理对总图S3的下面一组特征maps采用三种不同的卷积核进行卷积操作也可以获得13*3个特征maps,
因此C4层的特征maps数量:13* 3* 2=13* 6
C4层的特征maps的大小为:((27-7)+1)* ((17-6)+1)=21*12
降采样层(sub-sampling S5):对每个特征maps采用3 3的核进行降采样操作,此时每个maps的大小:7* 4
在这个阶段,每个通道的特征maps已经很小,通道maps数量分布情况如下:
gray通道maps数量 = gradient-x通道maps数量 = gradient-y通道maps数量 = 3
optflow-x通道maps数量 = optflow-y通道maps数量 = 2;
Model Regularization:
3D CNN model 的输入限制于一个小的连续视频帧,由于随着输入尺寸的增加,要训练的参数个数也会随着增加。另一方面,许多人类动作涉及到多帧。所以,需要将高层motion information 编码到 3D CNN model中去,为了达到这个目的,我们提出了从许多视频帧计算运动特征 和 正则化 3D CNN models 通过将这些运动特征作为 auxilary outputs。相似的idea可以在其他论文中也可以找到,但是并不知道是否在行为识别上有效。实际上,对于每一个训练action,我们产生一个特征向量编码长期动作信息(long-term action information)超过输入给CNN 的视频帧序列包含的信息。我们接着用CNN 学习特征向量接近这个 feature。这是通过将一些 auxiliary output units 连接到 CNN 最后的 hidden layer,然后在训练的过程中,在auxiliary units 上重复的计算特征向量。这将会使得 hidden layer information 和 高层motion feature相接近。更多的细节具体参考相关文章。在实验中,作者采用了 bag-of-words features,由 dense SIFT 描述子构建的特征,在原始灰度图像和运动边缘历史图像作为 auxiliary features。结果表明这种regularization scheme 将稳定的提升性能。
Model Combination:
模型的组合,没啥好说的,就是用不同的网络结构,最后将各个网络的输出做一个综合,来做出最终的预测。
2. Learning Spatiotemporal Features with 3D Convolutional Networks CVPR 2015
Code:http://vlg.cs.dartmouth.edu/c3d/
本文进一步讨论了 3D CNN 在视频上的特征提取,最终提出一种简单有效的 3D 卷积结构(C3D):

==
3D CNN for Video Processing的更多相关文章
- Video processing systems and methods
BACKGROUND The present invention relates to video processing systems. Advances in imaging technology ...
- Video Processing subsystem例程分析
Video Processing subsystem例程分析 1.memory_ss模块 slave端口: S00: 连接设备: microblaze_ss----M_AXI_DC 时钟来源: S01 ...
- Video Processing and Communications:(视频处理和通信)
https://max.book118.com/html/2017/1010/136711526.shtm Application of (GAN) of AI faceswap in Music V ...
- 视频处理单元Video Processing Unit
视频处理单元Video Processing Unit VPU处理全局视频处理,它包括时钟门.块复位线和电源域的管理. 缺少什么: •完全重置整个视频处理硬件块 •VPU时钟的缩放和设置 •总线时钟门 ...
- GPU
GPU主要是进行计算机图形这种大运算量的图形处理器,包括顶点设置.光影.像素操作.对CPU发出的数据和指令,进行着色,材质填充,渲染. 在没有GPU的系统中,3D游戏中物体移动时的坐标转换与光源处理, ...
- CPU GPU设计工作原理《转》
我知道这非常长,可是,我坚持看完了.希望有幸看到这文章并对图形方面有兴趣的朋友,也能坚持看完.一定大有收获.毕竟知道它们究竟是怎么"私下勾搭"的.会有利于我们用程序来指挥它们... ...
- 【CV】CVPR2015_A Discriminative CNN Video Representation for Event Detection
A Discriminative CNN Video Representation for Event Detection Note here: it's a learning note on the ...
- Automatic Generation of Animated GIFs from Video论文研读及实现
论文地址:Video2GIF: Automatic Generation of Animated GIFs from Video 视频的结构化分析是视频理解相关工作的关键.虽然本文是生成gif图,但是 ...
- 基于3D卷积神经网络的人体行为理解(论文笔记)(转)
基于3D卷积神经网络的人体行为理解(论文笔记) zouxy09@qq.com http://blog.csdn.net/zouxy09 最近看Deep Learning的论文,看到这篇论文:3D Co ...
随机推荐
- 如何批量删除SQL注释?
如何批量删除SQL注释.. 这个,可能是用来干坏事的吧.不过有时候要做一些重构,也还是有用.嘿嘿 使用工具,notepad++,注意要选择正则表达式按钮才行. [1]删除 /* */ /\*{1, ...
- nginx 11个处理阶段 && nginx lua 8个处理阶段
1. nginx 11 个处理阶段 nginx实际把请求处理流程划分为了11个阶段,这样划分的原因是将请求的执行逻辑细分,各阶段按照处理时机定义了清晰的执行语义,开发者可以很容易分辨自己需要开发的模块 ...
- SparkSQL UDF两种注册方式:udf() 和 register()
调用sqlContext.udf.register() 此时注册的方法 只能在sql()中可见,对DataFrame API不可见 用法:sqlContext.udf.register("m ...
- 畅通工程续 (SPFA模板Floy模板)
http://acm.hdu.edu.cn/showproblem.php?pid=1874 SPFA #include <iostream> #include <stdio.h&g ...
- PAT 1027 Colors in Mars[简单][注意]
1027 Colors in Mars (20)(20 分) People in Mars represent the colors in their computers in a similar w ...
- 机器学习理论基础学习5--- PCA
一.预备知识 减少过拟合的方法有:(1)增加数据 (2)正则化(3)降维 维度灾难:从几何角度看会导致数据的稀疏性 举例1:正方形中有一个内切圆,当维度D趋近于无穷大时,圆内的数据几乎为0,所有的数据 ...
- js数组之可变函数
在js的数组中有两个方法为数组添加元素:1.push();2.unshift(),push函数是将元素添加到数组的末尾,现在不用说大家估计也能猜出来,unshift这个函数就是把元素添加到数组的开头的 ...
- zw版【转发·台湾nvp系列Delphi例程】HALCON Roberts2
zw版[转发·台湾nvp系列Delphi例程]HALCON Roberts2 procedure TForm1.Button1Click(Sender: TObject);var op: HOpera ...
- zw版【转发·台湾nvp系列Delphi例程】HALCON MirrorImage2
zw版[转发·台湾nvp系列Delphi例程]HALCON MirrorImage2 procedure TForm1.Button1Click(Sender: TObject);var op: HO ...
- 20155227 2016-2017-2 《Java程序设计》第九周学习总结
20155227 2016-2017-2 <Java程序设计>第九周学习总结 教材学习内容总结 JDBC简介 JDBC全名Java DataBase Connectivity,是java联 ...