SQL Server 调优系列基础篇 - 联合运算符总
前言
上两篇文章我们介绍了查看查询计划的方式,以及一些常用的连接运算符的优化技巧,本篇我们总结联合运算符的使用方式和优化技巧。
废话少说,直接进入本篇的主题。
技术准备
基于SQL Server2008R2版本,利用微软的一个更简洁的案例库(Northwind)进行解析。
一、联合运算符
所谓的联合运算符,其实应用最多的就两种:UNION ALL和UNION。
这两个运算符用法很简单,前者是将两个数据集结果合并,后者则是合并后进行去重操作,如果有过写T-SQL语句的码农都不会陌生。
我们来分析下这两个运算符在执行计划中的显示,举个例子
SELECT FirstName+N''+LastName,City,Country FROM Employees
UNION ALL
SELECT ContactName,City,Country FROM Customers
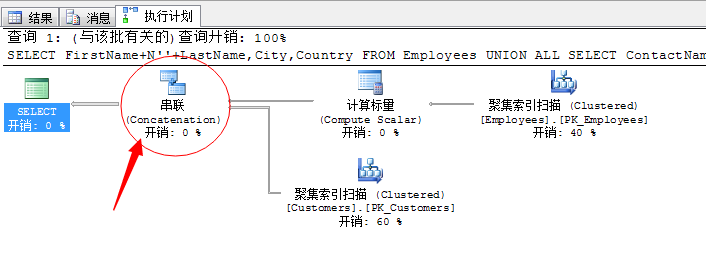
就是上面这个图标了,这就是UNION ALL联合运算符的图标。

这个联合运算符很简单的操作,将两个数据集合扫描完通过联合将结果汇总。
我们来看一下UNION 这个运算符,例子如下
select City,Country from Employees
UNION
SELECT City,Country FROM Customers
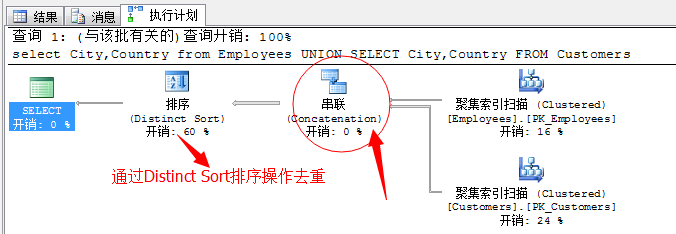
我们可以看到,UNION 运算符是在串联运算符之后发生了一个Distinct Sort排序操作,经过这个操作会将结果集合中的重复值去掉。
我们一直强调:大数据表的排序是一个非常耗资源的动作!
所以,到这里我们已经找到了可优化的选项,去掉排序,或者更改排序方式。
替换掉Distinct Sort排序操作的方式就是哈序聚合。Distinct Sort排序操作需要的内存和去除重复之前数据集合的数据量成正比,而哈希聚合需要的内存则是和去除重复之后的结果集成正比!
所以如果数据行中重复值很多,那么相比而言通过哈希聚合所消耗的内存会少。
我们来举个例子
select ShipCountry from Orders
UNION
SELECT ShipCountry FROM Orders
这个例子其实没啥用处,这里就是为了演示,我们来看一下结果
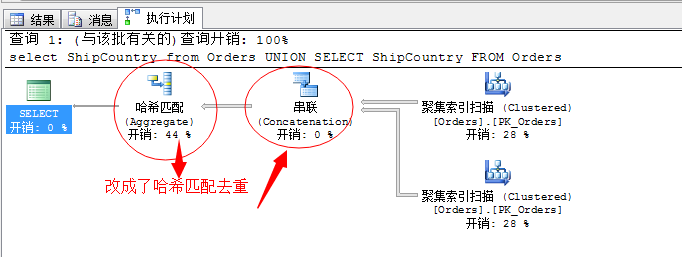
我们知道,这张表里这个ShipCountry是存在大面积重复值的,所以采用了哈希匹配来去重操作是最优的方式。
其实,相比哈希匹配连接还有一种更轻量级的去重的连接方式:合并连接
上一篇我已经分析了这个连接方法,用于两个数据集的连接方式,这里其实类似,应用前都必须先将原结果集合排序!
我们知道优化的方式可以采用建立索引来提高排序速度。
我们来重现这种去重方式,我们新建一个表,然后建立索引,代码如下

--新建表
SELECT EmployeeID,FirstName+N' '+LastName AS ContactName,City,Country
INTO NewEmployees
FROM Employees
GO
--添加索引
ALTER TABLE NewEmployees ADD CONSTRAINT PK_NewEmployees PRIMARY KEY(EmployeeID)
CREATE INDEX ContactName ON NewEmployees(ContactName)
CREATE INDEX ContactName ON CUSTOMERS(ContactName)
GO
--新建查询,这里一定要加上一个显示的Order by才能出现合并连接去重
SELECT ContactName FROM NewEmployees
UNION ALL
SELECT ContactName FROM Customers
ORDER BY ContactName
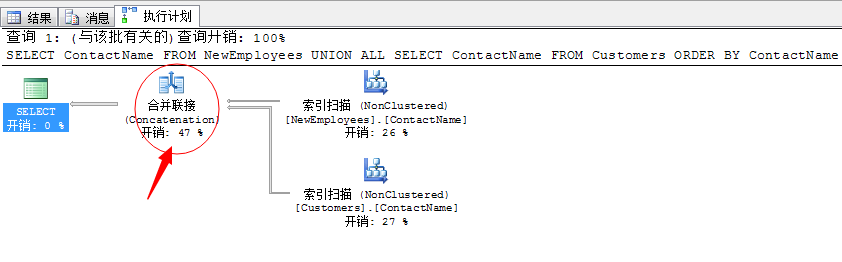
我们采用索引扫描的方式可以避免显式的排序操作。
我们将UNION ALL改成UNION,该操作将会对两个数据集进行去重操作。
--新建查询,这里一定要加上一个显示的Order by才能出现合并连接去重
SELECT ContactName FROM NewEmployees
UNION
SELECT ContactName FROM Customers
ORDER BY ContactName

这里我们知道UNION操作会对结果进行去重操作,上面应用了流聚合操作,流聚合一般应用于分组操作中,当然这里用它进行了分组去重。
在我们实际的应用环境中,最常用的方式还是合并连接,但是有一种情况最适合哈希连接,那就是一个小表和大表进行联合操作,尤其适合哪种大表中存在大量重复值的情况下。
哈希算法真是个好东西!
参考文献
- 微软联机丛书逻辑运算符和物理运算符引用
- 参照书籍《SQL.Server.2005.技术内幕》系列
结语
此篇文章先到此吧,简短一点,便于理解掌握,本篇主要介绍了查询计划中的联合操作运算符,下一篇我们分析SQL Server中的并行运算,在多核超线程云集的今天,来看SQL Server如何利用并行运算来最大化的利用现有硬件资源提升性能,有兴趣可提前关注,关于SQL Server性能调优的内容涉及面很广,后续文章中依次展开分析。
SQL Server这个软件一旦深入进去,你会发现它真的非常深,基本可以用深不见底来描述,如果想研究里面的性能调优这块,可以关注本系列内容,我们一起研究!
而且到现在还有很多人对SQL Server这套产品有误解,或者说观点有待纠正,以前就遇到过客户直接当我面大谈神马SQL Server导入数据一多就宕机了....
神马SQL Server只能做小数据量的应用...神马不如Oracle云云....!!!
还有一部分童鞋单纯的认为SQL Server是小儿科,没啥技术含量...简单的很....
关于这些观点,我不想吐槽啥,我只想让那些真正了解SQL Server的朋友一起来为SQL Server证明点什么。
SQL Server 调优系列基础篇 - 联合运算符总的更多相关文章
- SQL Server调优系列基础篇 - 联合运算符总
前言 上两篇文章我们介绍了查看查询计划的方式,以及一些常用的连接运算符的优化技巧,本篇我们总结联合运算符的使用方式和优化技巧. 废话少说,直接进入本篇的主题. 技术准备 基于SQL Server200 ...
- SQL Server调优系列基础篇 - 常用运算符总结
前言 上一篇我们介绍了如何查看查询计划,本篇将介绍在我们查看的查询计划时的分析技巧,以及几种我们常用的运算符优化技巧,同样侧重基础知识的掌握. 通过本篇可以了解我们平常所写的T-SQL语句,在SQL ...
- SQL Server 调优系列基础篇 - 常用运算符总结
前言 上一篇我们介绍了如何查看查询计划,本篇将介绍在我们查看的查询计划时的分析技巧,以及几种我们常用的运算符优化技巧,同样侧重基础知识的掌握. 通过本篇可以了解我们平常所写的T-SQL语句,在SQL ...
- SQL Server调优系列基础篇(联合运算符总结)
前言 上两篇文章我们介绍了查看查询计划的方式,以及一些常用的连接运算符的优化技巧,本篇我们总结联合运算符的使用方式和优化技巧. 废话少说,直接进入本篇的主题. 技术准备 基于SQL Server200 ...
- SQL Server调优系列基础篇(常用运算符总结——三种物理连接方式剖析)
前言 上一篇我们介绍了如何查看查询计划,本篇将介绍在我们查看的查询计划时的分析技巧,以及几种我们常用的运算符优化技巧,同样侧重基础知识的掌握. 通过本篇可以了解我们平常所写的T-SQL语句,在SQL ...
- SQL Server调优系列基础篇(并行运算总结)
前言 上三篇文章我们介绍了查看查询计划的方式,以及一些常用的连接运算符.联合运算符的优化技巧. 本篇我们分析SQL Server的并行运算,作为多核计算机盛行的今天,SQL Server也会适时调整自 ...
- SQL Server调优系列基础篇(并行运算总结篇二)
前言 上一篇文章我们介绍了查看查询计划的并行运行方式. 本篇我们接着分析SQL Server的并行运算. 闲言少叙,直接进入本篇的正题. 技术准备 同前几篇一样,基于SQL Server2008R2版 ...
- SQL Server调优系列基础篇(索引运算总结)
前言 上几篇文章我们介绍了如何查看查询计划.常用运算符的介绍.并行运算的方式,有兴趣的可以点击查看. 本篇将分析在SQL Server中,如何利用先有索引项进行查询性能优化,通过了解这些索引项的应用方 ...
- SQL Server调优系列基础篇(子查询运算总结)
前言 前面我们的几篇文章介绍了一系列关于运算符的介绍,以及各个运算符的优化方式和技巧.其中涵盖:查看执行计划的方式.几种数据集常用的连接方式.联合运算符方式.并行运算符等一系列的我们常见的运算符.有兴 ...
随机推荐
- NOIP Mayan游戏 - 搜索
Mayan puzzle是最近流行起来的一个游戏.游戏界面是一个7行5列的棋盘,上面堆放着一些方块,方块不能悬空堆放,即方块必须放在最下面一行,或者放在其他方块之上.游戏通关是指在规定的步数内消除所有 ...
- [noip模拟题]合理种植
[问题描述] 大COS在氯铯石料场干了半年,受尽了劳苦,终于决定辞职.他来到表弟小cos的寒树中学,找到方克顺校长,希望寻个活干. 于是他如愿以偿接到了一个任务…… 美丽寒树中学种有许多寒树.方克顺希 ...
- Pycharm 2017 激活码
Pycharm 2017 激活码 server选项里边输入: http://idea.liyang.io 我是通过这个成功的
- VC++ PathFindFileName函数,由文件路径获得文件名
1.PathFindFileName函数的作用是返回路径中的文件名. PTSTR PathFindFileName( __in PTSTR pPath ); pPath是指向文件路径字符串的指针,函数 ...
- Adobe Reader 2019 Offline Installer, Free Download - Best PDF Reader
https://ridnt-b.blogspot.com/2018/01/adobe-reader-2018-free-download.html http://ardownload.adobe.co ...
- Educational Codeforces Round 27 A B C
A. Chess Tourney Berland annual chess tournament is coming! Organizers have gathered 2·n chess pla ...
- BZOJ1045 [HAOI2008]糖果传递 && BZOJ3293 [Cqoi2011]分金币
Description 有n个小朋友坐成一圈,每人有ai个糖果.每人只能给左右两人传递糖果.每人每次传递一个糖果代价为1. Input 第一行一个正整数nn<=1'000'000,表示小朋友的个 ...
- Python简单做二维统计图
先上一张效果图: 以上图是一段时间内黄金价格的波动图. 代码如下: import datetime as DT from matplotlib import pyplot as plt from ma ...
- 数据库与hadoop与分布式文件系统的区别和联系
转载一篇关系数据库与Hadoop的关系的文章 1. 用向外扩展代替向上扩展 扩展商用关系型数据库的代价是非常昂贵的.它们的设计更容易向上扩展.要运行一个更大的数据库,就需要买一个更大的机器.事实上,往 ...
- OpenVPN Windows 平台安装部署教程
一.环境准备: 操作系统Windows 服务器IP:192.168.88.123 VPN:192.168.89.1 客户端IP:192.168.78.3 客户端服务端单网卡,路由器做好端口映射 安装 ...