PowerDesigner使用:[3]创建索引
PowerDesigner是一款功能非常强大的建模工具软件,足以与Rose比肩,同样是当今最著名的建模软件之一。Rose是专攻UML对象模型的建模工具,之后才向数据库建模发展,而PowerDesigner则与其正好相反,它是以数据库建模起家,后来才发展为一款综合全面的Case工具。
PowerDesigner主要分为7种建模文件:
1. 概念数据模型 (CDM)
对数据和信息进行建模,利用实体-关系图(E-R图)的形式组织数据,检验数据设计的有效性和合理性。
2. 逻辑数据模型 (LDM)
PowerDesigner 15 新增的模型。逻辑模型是概念模型的延伸,表示概念之间的逻辑次序,是一个属于方法层次的模型。具体来说,逻辑模型中一方面显示了实体、实体的属性和实体之间的关系,另一方面又将继承、实体关系中的引用等在实体的属性中进行展示。逻辑模型介于概念模型和物理模型之间,具有物理模型方面的特性,在概念模型中的多对多关系,在逻辑模型中将会以增加中间实体的一对多关系的方式来实现。
逻辑模型主要是使得整个概念模型更易于理解,同时又不依赖于具体的数据库实现,使用逻辑模型可以生成针对具体数据库管理系统的物理模型。逻辑模型并不是在整个步骤中必须的,可以直接通过概念模型来生成物理模型。
3. 物理数据模型 (PDM)
基于特定DBMS,在概念数据模型、逻辑数据模型的基础上进行设计。由物理数据模型生成数据库,或对数据库进行逆向工程得到物理数据模型。
4. 面向对象模型 (OOM)
包含UML常见的所有的图形:类图、对象图、包图、用例图、时序图、协作图、交互图、活动图、状态图、组件图、复合结构图、部署图(配置图)。OOM 本质上是软件系统的一个静态的概念模型。
5. 业务程序模型 (BPM)
BPM 描述业务的各种不同内在任务和内在流程,而且客户如何以这些任务和流程互相影响。 BPM 是从业务合伙人的观点来看业务逻辑和规则的概念模型,使用一个图表描述程序,流程,信息和合作协议之间的交互作用。
6. 信息流模型(ILM)
ILM是一个高层的信息流模型,主要用于分布式数据库之间的数据复制。
7. 企业架构模型(EAM):
从业务层、应用层以及技术层的对企业的体系架构进行全方面的描述。包括:组织结构图、业务通信图、进程图、城市规划图、应用架构图、面向服务图、技术基础框架图。
正所谓“工欲善其事必先利其器”,PowerDesigner就是一把强大的“神器”,若能运用自如,再身怀“绝世武功”,那你基本就遇神杀神遇佛杀佛了!
关于PowerDesigner物理数据模型的基本使用,我这里就不废话了,给出个连接,地球人看完都知道:http://www.cnblogs.com/huangcong/archive/2010/06/14/1757957.html
下面就一些比较高级型的用法和技巧我着重说明下。
1. 生成sql脚本
Database→Generate Database
选择要输出的文件路径,即文件存储路径,并根据需要修改文件名,单击确定后便会生成sql脚本。
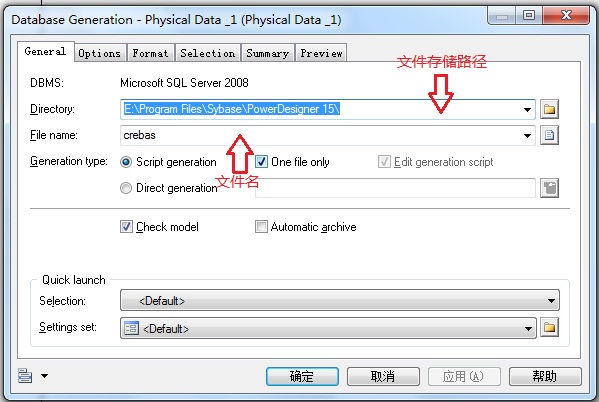
在Options选项卡里,可以个性化选择和配置sql脚本,如取消外键,去除drop语句等。

Selection选项卡中可以选择哪些表要生成sql脚本。
在Preview选项卡可以预览将要生成的sql脚本。
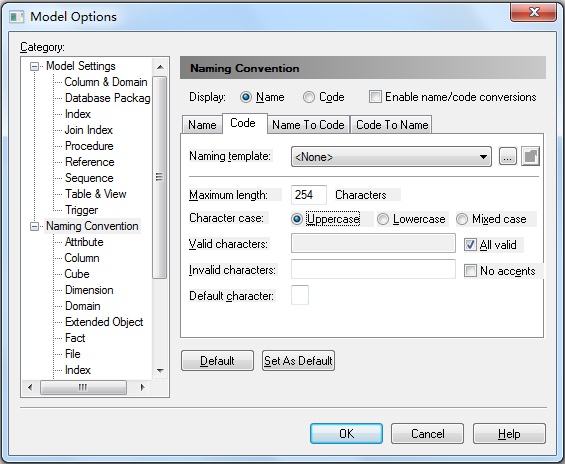
2. 将所有名词转化为大写
tools→Model Options...→Naming Convention→Code→Uppercase。
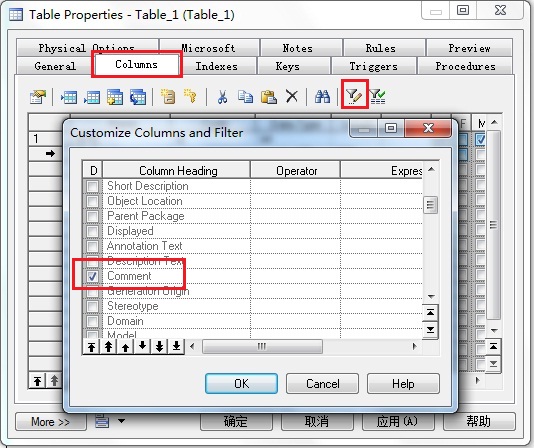
3. 表字段设计窗口显示comment来编写注释
双击表打开表的属性窗口→Columns选项卡→单击上排倒数第二个图标(Customize Columns and Filter)→勾选comment
4. 修改表的字段Name的时候,Code不自动跟着变
tools→General Options...→Dialog→取消勾选Name to Code mirroring

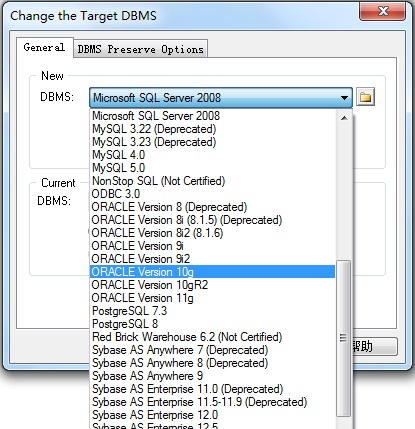
5. 不同数据库之间的转化
Database→Change Current DBMS→选择要转换成的目标数据库
6. 导入sql脚本生成相应的数据库表模型图
File→Reverse Engineer→Database...→修改模块名称并选择DBMS
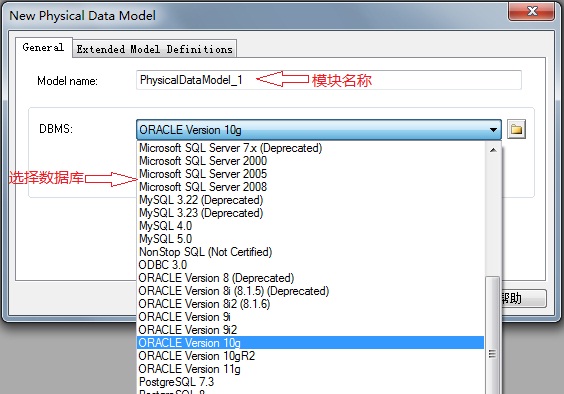
Using script files→点击下方图标(Add Files)来添加sql脚本文件→确定
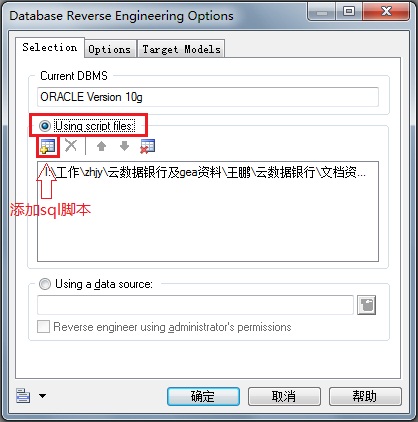
7. 由物理模型生成对象模型,并生成相应的get、set方法
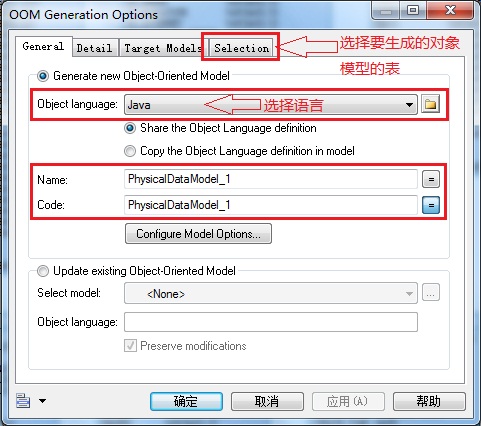
tools→Generate Object-Oriented Model...→选择语言→修改Name和Code→(Selection选项卡→选择要生成对象模型的表)→确定
双击生成的某张表的类图打开属性窗口→选中全部字段→将字段Visibility全部改为private→单击下方Add...按钮→选择Get/Set Operations→确定
之后生成代码即可:Language→Generate Java Code...
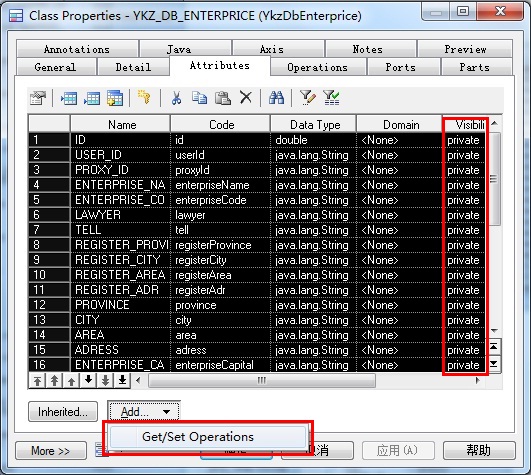
【注意:不同语言Add...按钮下的内容有区别,如C#是Property】
6. 生成数据库文档
Report→Generate Report...→选择Generate RTF→修改Repor namet→语言选择Chinese→选择文件存放位置→确定
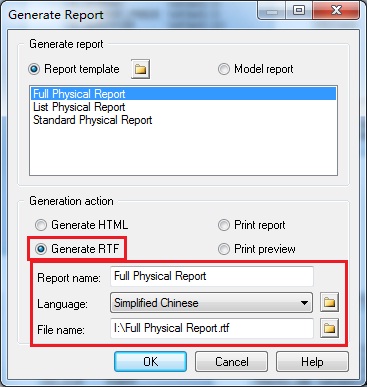
PowerDesigner还提供了文档编辑功能:Report→Reports...→点击New Report图标→修改Repor namet→语言选择Chinese→Report template选择Full Physical Report
之后即可打开文档编辑窗口,不过限于篇幅这里就不再详细说明如何编辑了,大家自己看看吧。
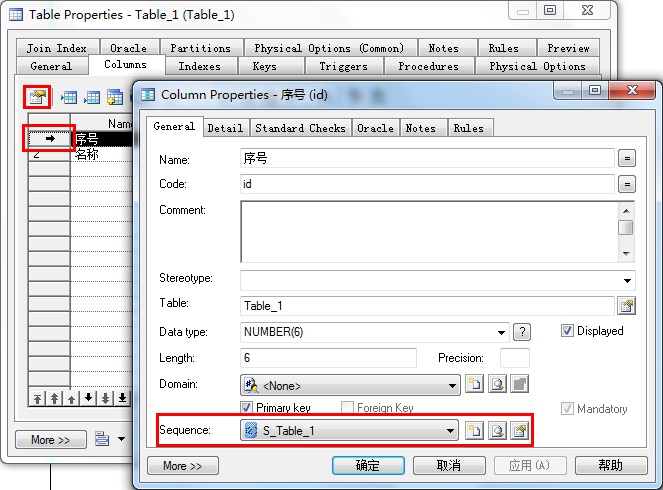
8. 如何建立自增主键
双击表打开属性窗口→勾选P主键复选框→双击设置为主键的字段(在行的头部双击)或者单击上方的属性图标按钮→在打开的窗口下方(注意不同数据库不一样,sql server是identity复选框)选择sequence,如果没有则单击旁边的新建按钮创建一个sequence。
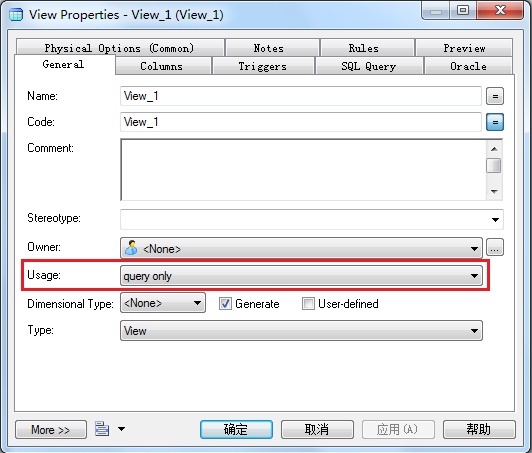
9. 如何建立视图
工具栏中单击视图(view)按钮→创建视图→双击视图打开属性窗口,其中Usage是表示视图是只读的还是可更新的。如果我们只创建一般的视图,那么选择query only选项即可。
切换到SQL Query选项卡,在文本框中可以设置定义视图的sql查询语句,在定义视图时最好不要使用*,而应该使用各个需要的列名,这样在视图属性的Columns中才能看到每个列。单击右下角Edit with SQL Editor按钮,即可弹出SQL Editor编辑器,编写SQL语句。也可采用其他sql语句生成器生成sql语句。

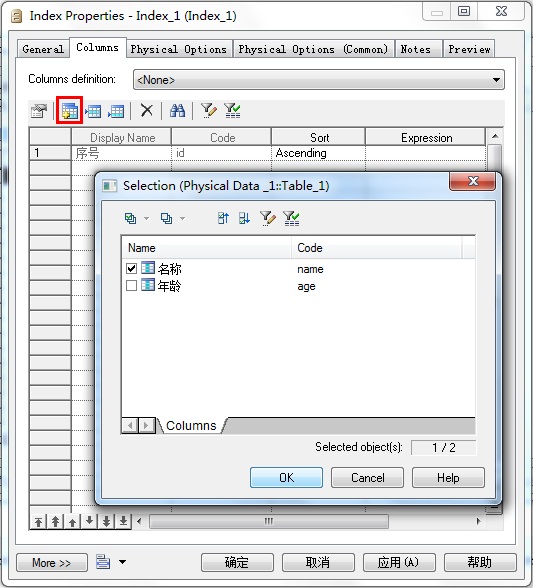
10. 如何建立索引
双击表打开属性窗口→选择Indexes选项卡→新建一索引→双击该索引打开属性窗口
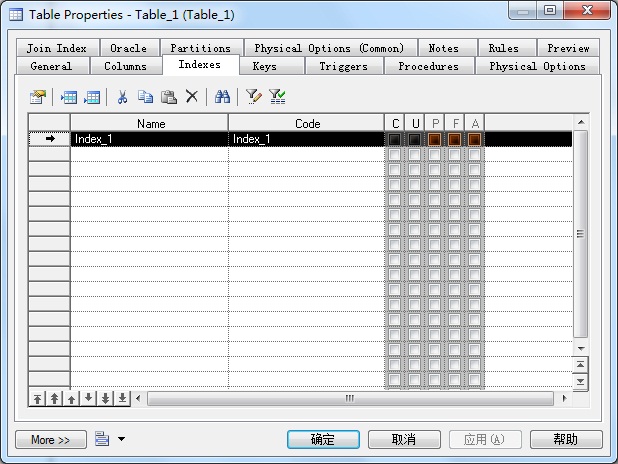
选择Columns选项卡→单击Add Columns图标按钮→选择要建立索引的字段→确定
这里Column definition就不要选了,会与主键冲突。
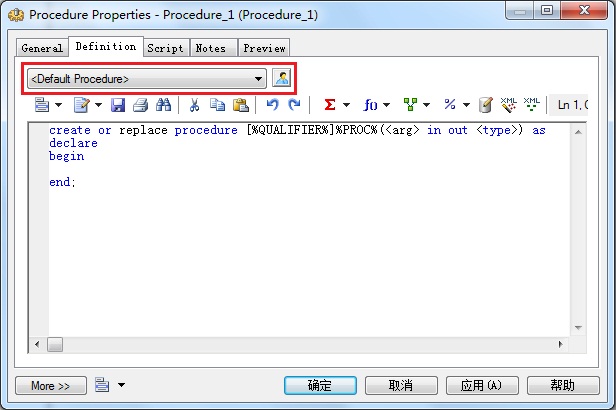
11. 如何建立存储过程
工具栏中单击Procedure按钮→创建存储过程→双击存储过程打开属性窗口→选择Definition选项卡,其中在下拉列表框中,有Default Procedure、Default Function这两个选项,前者是定义过程,后者是定语函数,系统会根据选择的类型创建SQL语句的模板→编辑存储过程脚本。
以上就是PowerDesigner物理模型的最主要内容了,其实这只是沧海一粟罢了,仅仅刚刚涉及到了一个模型,还有其他好多模型值得我们学习,这里要想真的讲全面的话,那一篇博文肯定容不下,需要连载了。
PowerDesigner真的非常强大,用它设计UML同样很牛叉,大家有时间真应该好好学学这个工具怎么使,如果可能,我可能会在今后的博文中介绍下如何用PowerDesigner设计对象模型UML,或者搞不好真的要连载了,呵呵。那么小小期待下吧!
http://blog.csdn.net/wangpeng047/article/details/7164643
PowerDesigner使用:[3]创建索引的更多相关文章
- 【转】使用PowerDesigner的建模创建升级管理数据库
使用PowerDesigner的建模创建升级管理数据库 PowerDesigner是一种著名的CASE建摸工具,最开始为数据库建模设计,即物理模型(Physical Data Model)用于生成数据 ...
- 003--PowerDesigner创建索引与外键
PowerDesigner创建索引与外键 一.创建索引 双击Table->Columns->创建索引 Step1:双击Table Step2:选择Columns->创建索引 弹出如下 ...
- SQL语句-创建索引
语法:CREATE [索引类型] INDEX 索引名称ON 表名(列名)WITH FILLFACTOR = 填充因子值0~100 GO USE 库名GO IF EXISTS (SELECT * FRO ...
- *使用while循环遍历数组创建索引和自增索引值
package com.chongrui.test;/* *使用while循环遍历数组 * * * */public class test { public static void main ...
- 程序员眼中的 SQL Server-执行计划教会我如何创建索引?
先说点废话 以前有 DBA 在身边的时候,从来不曾考虑过数据库性能的问题,但是,当一个应用程序从头到脚都由自己完成,而且数据库面对的是接近百万的数据,看着一个页面加载速度像乌龟一样,自己心里真是有种挫 ...
- SQL Server创建索引(转)
什么是索引 拿汉语字典的目录页(索引)打比方:正如汉语字典中的汉字按页存放一样,SQL Server中的数据记录也是按页存放的,每页容量一般为4K .为了加快查找的速度,汉语字(词)典一般都有按拼音. ...
- hive创建索引
索引是hive0.7之后才有的功能,创建索引需要评估其合理性,因为创建索引也是要磁盘空间,维护起来也是需要代价的 创建索引 hive> create index [index_studentid ...
- MongoDB性能篇之创建索引,组合索引,唯一索引,删除索引和explain执行计划
这篇文章主要介绍了MongoDB性能篇之创建索引,组合索引,唯一索引,删除索引和explain执行计划的相关资料,需要的朋友可以参考下 一.索引 MongoDB 提供了多样性的索引支持,索引信息被保存 ...
- mysql 创建索引和删除索引
索引的创建可以在CREATE TABLE语句中进行,也可以单独用CREATE INDEX或ALTER TABLE来给表增加索引.删除索引可以利用ALTER TABLE或DROP INDEX语句来实现. ...
- Oracle常用操作——创建表空间、临时表空间、创建表分区、创建索引、锁表处理
摘要:Oracle数据库的库表常用操作:创建与添加表空间.临时表空间.创建表分区.创建索引.锁表处理 1.表空间 ■ 详细查看表空间使用状况,包括总大小,使用空间,使用率,剩余空间 --详细查看表空 ...
随机推荐
- List,Set,Map存取元素各有什么特点
一丶存放 List存放元素是有序,可重复 Set存放元素无序,不可重复 Map元素键值对形式存放,键无序不可重复,值可重复 二丶取出 List取出元素for循环,foreach循环,Iterator迭 ...
- 【代码片段】如何使用CSS来快速定义多彩光标
对于web开发中,我们经常都看得到需要输入内容的组件和元素,比如,textarea,或者可编辑的DIV(contenteditable) ,如果你也曾思考过使用相关方式修改一下光标颜色的,那么这篇技术 ...
- windows下根据进程ID强制杀死进程
[windows 进程ID PID]NTSD命令详解 1. ntsd -c q -p PID 2. ntsd -c q -pn ImageName 比如:ntsd -c q -pn qq.exe -c ...
- 使用hadoop eclipse plugin提交Job并添加多个第三方jar
来自:http://heipark.iteye.com/blog/1171923 通过 "conf.set("tmpjars", jars);" 可以设置第三方 ...
- JSP入门实战下
第一部分简单解说:jsp语法的规范,以及三大编译指令,七个动作指令和九大内置对象,生命周期解说等. 这章主要解说el表达式,核心标签库. 所有代码下载:链接 1.核心标签库(JSTL:c)解说: 1. ...
- gdb 小技巧
https://www.gitbook.com/book/wizardforcel/100-gdb-tips/details
- ReactNative踩坑日志——fetch如何向服务器传递参数
一:简单参数 简单的参数,我们可以使用手动拼接的方式传递. 格式为: fetch(url?key1=val1&key2=val2&...).then((response) => ...
- Hibernate学习笔记五:反向工程快速开发
转载请注明原文地址:http://www.cnblogs.com/ygj0930/p/6768513.html 一:反向工程 Myeclipse提供由 数据库表 生成 java pojo 和 hib ...
- Kinect2.0获取关节姿态(Joint Orientation)
Bones Hierarchy 骨骼层次结构从SpineBase作为根节点开始,一直延伸到肢体末端(头.指尖.脚): 层级结构如下图所示: 通过IBody::GetJointOrientations函 ...
- 用html.parser抓网页中的超链接,返回list
#python3 from html.parser import HTMLParser class MyHTMLParser(HTMLParser): """ 1.tag ...