使用python识别验证码
公司的登录注册等操作有验证码,测试环境可以让开发屏蔽掉验证码,但是如果到线上的话就要想办法识别验证码或必过验证码了。
识别验证码主要分为三部分,一、对验证码进行二值化。二、将二值化后的图片分割。三、进行识别。理论上在识别之前有一个标准化的操作,是将图片进行旋转等操作,尽量将字符弄成一样的格式,方便识别,避免随进图片的差异。
用这个验证码作为例子: 。下面是代码:
。下面是代码:
一、打开图片,将图片二值化。
图片是由RGB三个通道组成的,图片的验证码和他的干扰,比如点或横线等,RGB的阙值有很大的区别,我们可以使用PS工具查看,选取一个大概的临界点,在代码中进行判断,判断属于验证码部分的阙值,赋值为(255,255,255,255)黑色。如果不是在这个阙值范围内的赋值为(0,0,0,255)白色。从而将噪点去掉。
#coding=utf-8
from PIL import Image
from operator import itemgetter
import os
img=Image.open('code.jpg')
print img.format,img.size,img.mode
img=img.convert("RGBA")
pixdata=img.load()
for y in xrange(img.size[1]):
for x in xrange(img.size[0]):
if pixdata[x,y][0]<140 or pixdata[x,y][1]<140 or pixdata[x,y][2]<140:
pixdata[x,y]=(0,0,0,255)
else:
pixdata[x,y]=(255,255,255,255)
说明:对像素pixdata[x,y]的阙值判断,前文中说明过[0],[1],[2]分别代表了RGB,140是用PS看出来的,验证码位置的像素,RGB都比较低,而噪点的RGB值比较高。可以适当的调一下。
下图是取验证码一点的像素点:
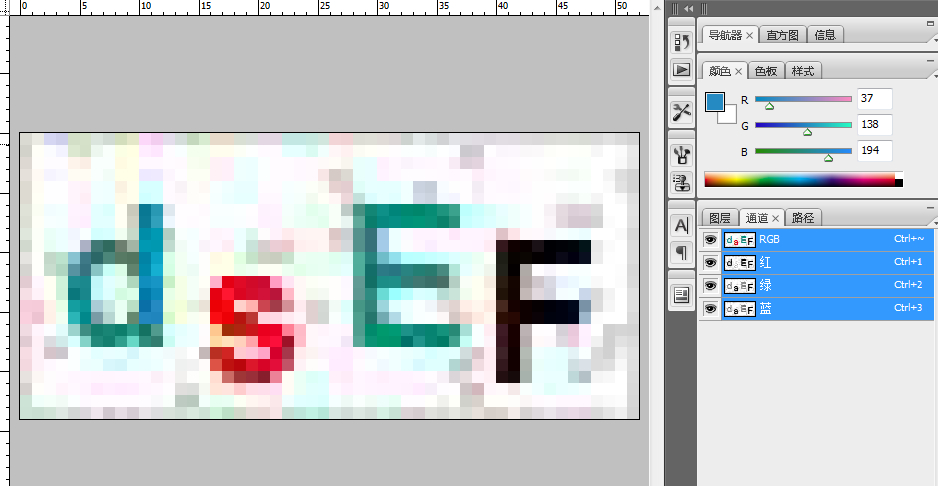
下面是噪点的RGB:

二、将二值化后的图片进行分割,分割成独立字符
#存为字库
j = 1
for i in range(4):
x = 0 + i*13
y = 6
img.crop((x, y, x+13, y+18)).save("%d.jpg" % j)
j += 1
分割后的结果如下图:
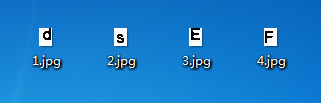
说明:验证码图片的大小是固定的,一个验证码4个字符,将他分成等大小的四个图片,13为一个字符所占的宽度,18为一个字符所占的高度,但是这样截出来的图片不是很精确。
三、识别验证码,这步也是最关键的。
#识别
fontMods = []#fontMods,图片库,文件名,带后缀
mode=[]#mode,图片库,去掉后缀的文件名
font=[]#font,分割后的四个图片
s=os.sep
root="C:\Users\min.sun\Desktop"+s+"num"+s#文件路径,s区分在linux或windows系统下的分割符"/"或"\"
sname=os.listdir("C:\Users\min.sun\Desktop/num")#获取文件夹下文件或文件夹的名称,带后缀
#fname,存储文件名区分名和后缀的元组,例(5,jpg)。mode存储文件名,不带后缀
#分割文件名和后缀名
#遍历文件,将库中的文件名存入
for rt, dirs, files in os.walk(root):
for f in files:
fname = os.path.splitext(f)
mode.append(fname[0])
for i in range(0,4):
fontMods.append(Image.open(root+s+sname[i]))
result=[]
for i in range(1,5):
font.append(Image.open("%d.jpg" % i))
for i in font:
points ={}
d=0
for mod in fontMods:
diffs = 0
for yi in range(18):
for xi in range(13):
if i.getpixel((xi, yi))!=mod.getpixel((xi, yi)):
diffs=diffs+1
#print "diffs:" + str(diffs)
#points[diffs]=mode
points[diffs]=mode[d]
d=d+1
points=sorted(points.iteritems(), cmp=lambda x,y:cmp(x[0],y[0]), reverse = False )
result.append(points[0][1])
a="".join(result)
print "The result is:",a
print "over"
说明:做识别首先要有一个库,来比对,这里做的方法是取像素点,判断和库中的图片是否一样,取不同个数最少的一个图片作为结果。
以上步骤就是验证码识别的一个简单过程,不过识别率很低,只是作为一个学习,还是可以了考虑用其他方法来识别验证码。
使用python识别验证码的更多相关文章
- python识别验证码——PIL,pytesser,pytesseract的安装
1.使用Python识别验证码需要安装Python的图像处理模块(PIL.pytesser.pytesseract) (安装过程需要pip,在我的Python中已经安装pip了,pip的安装就不在赘述 ...
- Python爬虫入门教程 60-100 python识别验证码,阿里、腾讯、百度、聚合数据等大公司都这么干
常见验证码 之前的博客中已经解决了一些常见验证码的问题,但是验证码是层出不穷的,目前解决验证码除了通过常规手段解决以外,还可以通过人工智能领域的深度学习去解决 深度学习?! 无疑对爬虫coder提高了 ...
- python 识别验证码自动登陆
# python 3.5.0 # 通过Chrom浏览器访问发起请求 # 需要对应版本的Chrom和chromdriver # 作者:linyouyi from selenium import webd ...
- python识别验证码——一般的数字加字母验证码识别
1.验证码的识别是有针对性的,不同的系统.应用的验证码区别有大有小,只要处理好图片,利用好pytesseract,一般的验证码都可以识别 2.我在识别验证码的路上走了很多弯路,重点应该放在怎么把图片处 ...
- python识别验证码
1.tesseract-ocr安装 tesseract-ocr windows下载地址 http://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr- ...
- Python识别验证码,基于Tesseract实现图片文字识别
一.简介 Tesseract是一个开源的文本识别[OCR]引擎,可通过Apache 2.0许可获得.它可以直接使用,或者使用API从图像中提取打印的文本,支持多种语言.该软件包包含一个ORC引擎[li ...
- python 识别验证码
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/instal ...
- Python识别网站验证码
http://drops.wooyun.org/tips/6313 Python识别网站验证码 Manning · 2015/05/28 10:57 0x00 识别涉及技术 验证码识别涉及很多方面的内 ...
- python 基于机器学习识别验证码
1.背景 验证码自动识别在模拟登陆上使用的较为广泛,一直有耳闻好多人在使用机器学习来识别验证码,最近因为刚好接触这方面的知识,所以特定研究了一番.发现网上已有很多基于machine learni ...
随机推荐
- 邮件服务器fixpost服务(1)
发邮件所用的协议,SMTP协议,端口TCP25 收邮件所用的协议,pop3.imap协议 邮件客户端(MUA):foxmail.闪电邮.邮件大师.outlook 搭建邮件服务器所用到的软件(MTA邮件 ...
- Android logcat命令详解
一.logcat命令介绍 1.android log系统 2.logcat介绍 logcat是android中的一个命令行工具,可以用于得到程序的log信息 log类是一个日志类,可以在代码中使用lo ...
- [UE4]roll pitch yaw
UE4中的定义: 一.Roll,绕着X轴旋转的角度 二.Pitch,绕着Y轴旋转的角度 三.Yaw,绕着Z轴旋转的角度 Rotator 一.(Roll,Pitch,Yaw) 二.Rotator(0,0 ...
- VLC在web系统中应用(x-vlc-plugin 即如何把VLC嵌入HTML中)第一篇
VLC毫无疑问是优秀的一款播放软件,子B/S机构的web项目中,如果能把它嵌入页面,做页面预览或者其他,是非常棒的. 第一步:下载VLC安装程序:(推荐1.0.3或者是1.0.5版本,比较稳定) ht ...
- ubuntu 16.04 LTS 安装 teamviewer 13
背景介绍 由于需要做现场的远程支持,经协商后在现场的服务器上安装TeamViewer 以便后续操作. 本来以为很简单的一件事,谁知却稍微费了一番周折 :( 记录下来,希望提醒自己的同时也希望能够帮到 ...
- UML类图的画法
http://blog.csdn.net/kevin_darkelf/article/details/11371353
- Python模块之shelve
shelve是python的自带model. 可以直接通过import shelve来引用. shelve类似于一个存储持久化对象的持久化字典,即字典文件. 使用方法也类似于字典. 保存对象至shel ...
- 配置IIS,以在局域网内访问发布的web站点
在windows 7或win8 中 配置IIS, 以在局域网内访问自己发布的web 网站或应用程序.主要配置步骤如下: 1. 打开 win7 或 win8 控制面板,选择: 打开或关闭windws 功 ...
- mysql级联删除
一个building对应多个rooms,building删除----级联删除相关的rooms 第一步, 创建buildings表,如下创建语句: USE testdb; CREATE TABLE bu ...
- 生产案例、Linux出现假死,怎么回事?
1.什么是假死 所谓假死,就是能ping通,但是ssh不上去:任何其他操作也都没反应,包括上面部署的nginx也打不开页面. 2.假死其实很难出现一次 作为一个多任务操作系统,要把系统忙死,忙到ssh ...