R-FCN论文理解
一、R-FCN初探
1. R-FCN贡献
- 提出Position-sensitive score maps来解决目标检测的位置敏感性问题;
- 区域为基础的,全卷积网络的二阶段目标检测框架;
- 比Faster-RCNN快2.5-20倍(在K40GPU上面使用ResNet-101网络可以达到 0.17 sec/image);
2. R-FCN与传统二阶段网络的异同点
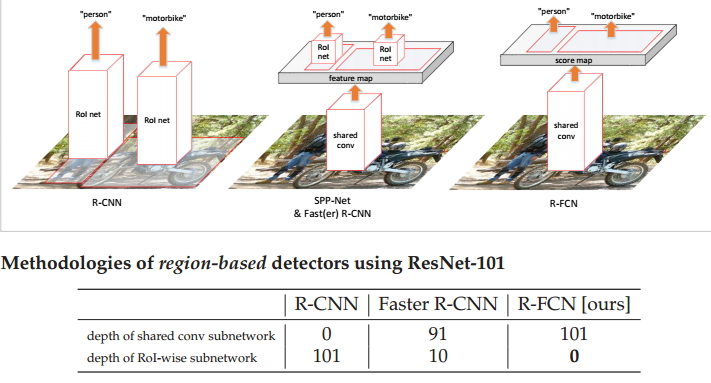
图1 R-FCN与传统二阶段网络的异同点
相同点:首先,两者二阶段的检测框架(全卷积子网络+RoI-wise subnetwork); 其次两者最终输出的结果都是相应的类别和对应的BB;
不同点:如上图所示,我们可以看到和Faster R-CNN相比,R-FCN具有更深的共享卷积网络层,这样可以获得更加抽象的特征;同时,它没有RoI-wise subnetwork,不像Faster R-CNN的feature map左右都有对应的网络层,它是真正的全卷积网络架构;从图中的表格可以看出Faster R-CNN的共享卷积子网络是91层,RoI-wise子网络是10层,而R-FCN只有共享卷积子网络,深度为101层。与R-CNN相比,最大的不同就是直接获得整幅图像的feature map,再提取对应的ROI,而不是直接在不同的ROI上面获得相应的feature map。
3. 分类网络的位置不敏感性和检测网络的位置敏感性

图2 分类网络的位置不敏感性和检测网络的位置敏感性
分类网络的位置不敏感性:简单来讲,对于分类任务而言,我希望我的网络有一个很好地分类性能,随着某个目标在图片中不断的移动,我的网络仍然可以准确的将你区分为对应的类别。如上图左边所示,不管你这只鸟在图片中如何移动,我的分类网络都想要准确的将你分类为鸟。即我的网络有很好地区分能力。实验表明,深的全卷积网络能够具备这个特性,如ResNet-101等。
检测网络的位置敏感性:简单来讲,对于检测任务而言,我希望我的网络有一个好的检测性能,可以准确的输出目标所在的位置值。随着某个目标的移动,我的网络希望能够和它一起移动,仍然能够准确的检测到它,即我对目标位置的移动很敏感。我需要计算对应的偏差值,我需要计算我的预测和GT的重合率等。但是,深的全卷积网路不具备这样的一个特征。
总之,分类网络的位置不敏感性和检测网络的位置敏感性的一个矛盾问题,而我们的目标检测中不仅要分类也要定位,那么如何解决这个问题呢,R-FCN提出了Position-sensitive score maps来解决这个问题;
4. R-FCN网络的设计动机
Faster R-CNN是首个利用CNN来完成proposals预测的,从此之后很多的目标检测网络都开始使用Faster R-CNN的思想。而Faster R-CNN系列的网络都可以分成2个部分:ROI Pooling之前的共享全卷积网络和ROI Pooling之后的ROI-wise子网络(用来对每个ROI进行特征提出,并进行回归和分类)。第1部分就是直接用普通分类网络的卷积层,用来提取共享特征,然后利用ROI Pooling在最后一层网络形成的feature map上面提取针对各个RoIs的特征向量,然后将所有RoIs的特征向量都交给第2部分来处理(即所谓的分类和回归),而第二部分一般都是一些全连接层,在最后有2个并行的loss函数:softmax和smoothL1,分别用来对每一个RoI进行分类和回归,这样就可以得到每个RoI的真实类别和较为精确的坐标信息啦(x, y, w, h)。
需要注意的是第1部分通常使用的都是像VGG、GoogleNet、ResNet之类的基础分类网络,这些网络的计算都是所有RoIs共享的,在一张图片上面进行测试的时候只需要进行一次前向计算即可。而对于第2部分的RoI-wise subnetwork,它却不是所有RoIs共享的,主要的原因是因为这一部分的作用是“对每个RoI进行分类和回归”,所以不能进行共享计算。那么问题就处在这里,首先第1部分的网络具有“位置不敏感性”,而如果我们将一个分类网络比如ResNet的所有卷积层都放置在第1部分用来提取特征,而第2部分则只剩下全连接层,这样的目标检测网络是位置不敏感的translation-invariance,所以其检测精度会较低,而且这样做也会浪费掉分类网络强大的分类能力(does not match the network's superior classification accuracy)。而ResNet论文中为了解决这个问题,做出了一点让步,即将RoI Pooling层不再放置在ResNet-101网络的最后一层卷积层之后而是放置在了“卷积层之间”,这样RoI Pooling Layer之前和之后都有卷积层,并且RoI Pooling Layer之后的卷积层不是共享计算的,它们是针对每个RoI进行特征提取的,所以这种网络设计,其RoI Pooling层之后就具有了位置敏感性translation-variance,但是这样做会牺牲测试速度,因为所有的RoIs都需要经过若干层卷积计算,这样会导致测试速度很慢。R-FCN就是针对这个问题提出了自己的解决方案,在速度和精度之间进行折中。
二、R-FCN详解
1. R-FCN算法步骤
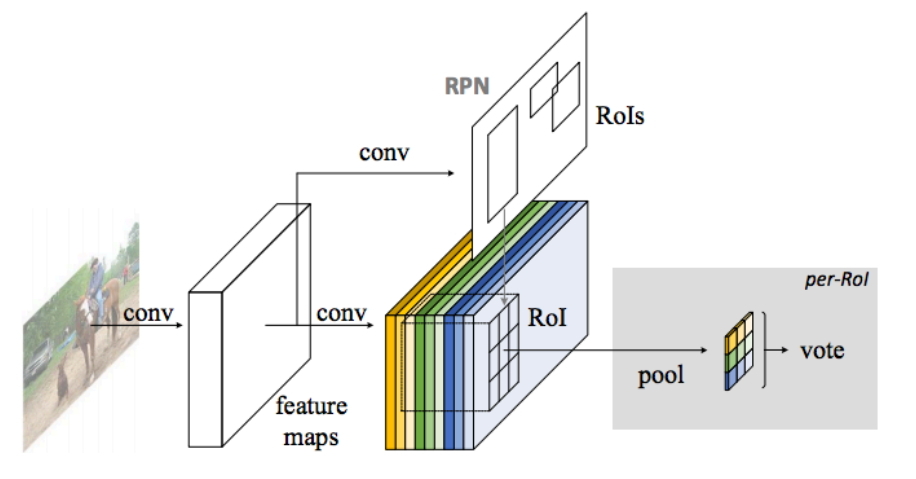
图3 R-FCN算法步骤
如图所示,我们先来分析一下R-FCN算法的整个运行步骤,使得我们对整个算法有一个宏观的理解,接下来再对不同的细节进行详细的分析。
- 首先,我们选择一张需要处理的图片,并对这张图片进行相应的预处理操作;
- 接着,我们将预处理后的图片送入一个预训练好的分类网络中(这里使用了ResNet-101网络的Conv4之前的网络),固定其对应的网络参数;
- 接着,在预训练网络的最后一个卷积层获得的feature map上存在3个分支,第1个分支就是在该feature map上面进行RPN操作,获得相应的ROI;第2个分支就是在该feature map上获得一个K*K*(C+1)维的位置敏感得分映射(position-sensitive score map),用来进行分类;第3个分支就是在该feature map上获得一个4*K*K维的位置敏感得分映射,用来进行回归;
- 最后,在K*K*(C+1)维的位置敏感得分映射和4*K*K维的位置敏感得分映射上面分别执行位置敏感的ROI池化操作(Position-Sensitive Rol Pooling,这里使用的是平均池化操作),获得对应的类别和位置信息。
- 这样,我们就可以在测试图片中获得我们想要的类别信息和位置信息啦。
2. Position-Sensitive Score Map解析
图3是R-FCN的网络结构图,其主要设计思想就是“位置敏感得分图position-sensitive score map”。现在我们来解释一下其设计思路。如果一个RoI中含有一个类别C的物体,我们将该RoI划分为K*K 个区域,其分别表示该物体的各个部位,比如假设该RoI中含有的目标是人,K=3,那么就将“人”划分成了9个子区域,top-center区域毫无疑问应该是人的头部,而bottom-center应该是人的脚部,我们将RoI划分为K*K个子区域是希望这个RoI在其中的每一个子区域都应该含有该类别C的物体的各个部位,即如果是人,那么RoI的top-center区域就应该含有人的头部。当所有的子区域都含有各自对应的该物体的相应部位后,那么分类器才会将该RoI判断为该类别。也就是说物体的各个部位和RoI的这些子区域是“一一映射”的对应关系。
OK,现在我们知道了一个RoI必须是K*K个子区域都含有该物体的相应部位,我们才能判断该RoI属于该物体,如果该物体的很多部位都没有出现在相应的子区域中,那么就该RoI判断为背景类别。那么现在的问题就是网络如何判断一个RoI的 K*K个子区域都含有相应部位呢?前面我们是假设知道每个子区域是否含有物体的相应部位,那么我们就能判断该RoI是否属于该物体还是属于背景。那么现在我们的任务就是判断RoI子区域是否含有物体的相应部位。
这其实就是position-sensitive score map设计的核心思想了。R-FCN会在共享卷积层的最后一层网络上接上一个卷积层,而该卷积层就是位置敏感得分图position-sensitive score map,该score map的含义如下所述,首先它就是一层卷积层,它的height和width和共享卷积层的一样(即具有同样的感受野),但是它的通道个数为K*K*(C+1) 。其中C表示物体类别种数,再加上1个背景类别,所以共有(C+1)类,而每个类别都有 K*K个score maps。现在我们只针对其中的一个类别来进行说明,假设我们的目标属于人这个类别,那么其有 K*K 个score maps,每一个score map表示原始图像中的哪些位置含有人的某个部位,该score map会在含有对应的人体的某个部位的位置有高的响应值,也就是说每一个score map都是用来描述人体的其中一个部位出现在该score map的何处,而在出现的地方就有高响应值”。既然是这样,那么我们只要将RoI的各个子区域对应到属于人的每一个score map上然后获取它的响应值就好了。但是要注意的是,由于一个score map都是只属于一个类别的一个部位的,所以RoI的第 i个子区域一定要到第i张score map上去寻找对应区域的响应值,因为RoI的第i个子区域需要的部位和第i张score map关注的部位是对应的。那么现在该RoI的K*K个子区域都已经分别在属于人的K*K个score maps上找到其响应值了,那么如果这些响应值都很高,那么就证明该RoI是人呀。当然这有点不严谨,因为我们只是在属于人的 K*K个score maps上找响应值,我们还没有到属于其它类别的score maps上找响应值呢,万一该RoI的各个子区域在属于其它类别的上的score maps的响应值也很高,那么该RoI就也有可能属于其它类别呢?是吧,如果2个类别的物体本身就长的很像呢?这就会涉及到一个比较的问题,那个类别的响应值高,我就将它判断为哪一类目标。它们的响应值同样高这个情况发生的几率很小,我们不做讨论。
3. Position-Sensitive Rol Pooling解析
上面我们只是简单的讲解了一下ROl的K*K个子区域在各个类别的score maps上找到其每个子区域的响应值,我们并没有详细的解释这个“找到”是如何找的?这就是位置敏感Rol池化操作(Position-sensitive RoI pooling),其字面意思是池化操作是位置敏感的,下来我们对它进行解释说明。
如图3所示,通过RPN提取出来的RoI区域,其是包含了x,y,w,h的4个值,也就是说不同的RoI区域能够对应到score map的不同位置上,而一个RoI会被划分成K*K个bins(也就是子区域。每个子区域bin的长宽分别是 h/k 和 w/k ),每个bin都对应到score map上的某一个区域。既然该RoI的每个bin都对应到score map上的某一个子区域,那么池化操作就是在该bin对应的score map上的子区域执行,且执行的是平均池化。我们在前面已经讲了,第i个bin应该在第i个score map上寻找响应值,那么也就是在第i个score map上的第i个bin对应的位置上进行平均池化操作。由于我们有(C+1)个类别,所以每个类别都要进行相同方式的池化操作。
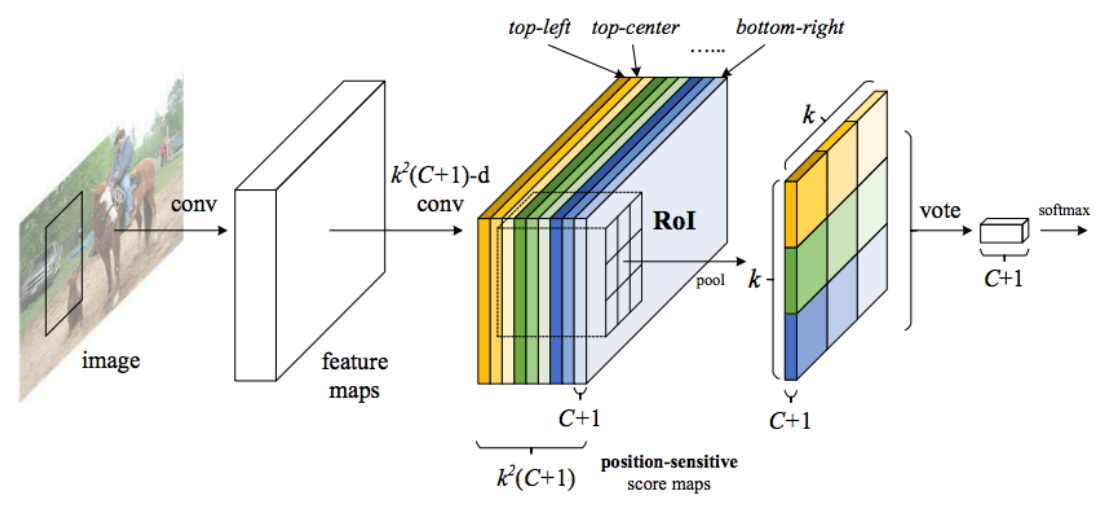
图4 Position-Sensitive Rol Pooling解析
图4已经很明显的画出了池化的方式,对于每个类别,它都有K*K个score maps,那么按照上述的池化方式,ROI可以针对该类别可以获得K*K个值,那么一共有(C+1)个类别,那么一个RoI就可以得到K*K*(C+1)个值,就是上图的特征图。那么对于每个类别,该类别的K*K个值都表示该RoI属于该类别的响应值,那么将这K*K个数相加就得到该类别的score,那么一共有(C+1)个scores,那么在这(C+1)个数上面使用简单的softmax函数就可以得到各个类别的概率了(注意,这里不需要使softmax分类器了,只需要使用简答的softmax函数,因为这里就是通过简单的比大小来判断最终的类别的)。
4. Position-Sensitive Regression解析
前面的position-sensitive score map和Position-sensitive RoI pooling得到的值是用来分类的,那么自然需要相应的操作得到对应的值来进行回归操作。按照position-sensitive score map和Position-sensitive RoI pooling思路,其会让每一个RoI得到(C+1)个数作为每个类别的score,那么现在每个RoI还需要 4个数作为回归偏移量,也就是x,y,w,h的偏移量,所以仿照分类设计的思想,我们还需要一个类似于position-sensitive score map的用于回归的score map。那么应该如何设置这个score map呢,论文中给出了说明:即在ResNet的共享卷积层的最后一层上面连接一个与position-sensitive score map并行的score maps,该score maps用来进行regression操作,我们将其命名为regression score map,而该regression score map的维度应当是 4*K*K ,然后经过Position-sensitive RoI pooling操作后,每一个RoI就能得到4个值作为该RoI的x,y,w,h的偏移量了,其思路和分类完全相同。
5. 为什么position-sensitive score map能够在含有某个类别的物体的某个部位的区域上具有高响应值?
这种有高响应值现在只是作者自己设想的啊,如果网络不满足这一点的话,那么我们前面的所有分析都不成立啦。现在我们就大致解释一下为什么训练该网络能够让网络最终满足这一点。首先根据网络的loss计算公式,如果一个RoI含有人这个物体,那么该RoI通过position-sensitive score map和Position-sensitive RoI pooling得到的(C+1)个值中属于人的那个值必然会在softmax损失函数的驱动下变得尽量的大,那么如何才能使得属于人的这个值尽量的大呢?那么我们需要想想属于人的这个预测值是怎么来的?经过前面的分析,我们已经知道它是通过Position-sensitive RoI pooling这种池化操作获得的,那么也就是说使得(C+1)个值中属于人的那个值尽量大,必然会使得position-sensitive score map中属于人的那个score map上的RoI对应的位置区域的平均值尽量大,从而会使得该score map上在该区域上的响应值尽量大,因为只有该区域的响应值大了,才能使得预测为人的概率大,才会降低softmax的loss,整个训练过程才能进行下去。

图6 位置敏感得分映射表现2
如图5和图6所示,我们同样可以得出以上的结论。如图5所示,我们输入了一张含有一个小孩的图片,图中黄色的BB表示我们的检测到的目标,也就是我们的一个ROI,接下来是9张位置敏感的得分映射图(在这里使用的是3x3的特征映射),这9张图分别表示对人这个目标的top-left、top-center、... bottom-right不同区域敏感的得分映射。对应到图中就是将这个ROI分为9个子区域,每一个子区域其实大致上对应到了小孩的不同部位,而不同的部位一般都会有其独特的特征存在,9个区域敏感得分映射图对不同的区域比较敏感(所谓的敏感就是说如果这个子区域中存在该目标的某个部位特征时,其才会输出较大的响应值,否则的话我会输出较小的响应值)。图5中的9个得分映射对ROI中划分的对应子区域都比较敏感(都有很强的响应值,越白表示响应越大,越黑表示响应越小),即ROI中的9个子区域都有较大的响应值。然后进行位置敏感池化操作,最后进行Vote操作,由于9个区域中基本上都有很高的响应值,最后投票通过,认为这个ROI中的对象是一个person。同理,可以得出图6是一个背景类。(图6的位置敏感ROI池化中有5个区域是黑色的,即表示具有较低的响应值,只有4个区域比较高,即表示具有较高的响应值,根据Vote机制,就将其分类为背景类)。
6. Loss计算及其分析

这个Loss就是两阶段目标检测框架常用的形式。包括一个分类Loss和一个回归Loss。lamdy用来平衡两者的重要性。对于任意一个RoI,我们需要计算它的softmax损失,和当其不属于背景时的回归损失。这很简单,因为每个RoI都被指定属于某一个GT box或者属于背景,即先选择和GT box具有最大重叠率(IOU)的Rol,然后在剩余的Rol中选择与GT box的重叠率值大于0.5Rol进行匹配操作,最后将剩余的Rol都归为背景类。即每个Rol都有了对应的标签,我们就可以根据监督学习常用的方法来训练它啦。
7. online hard example mining
这个方法是目标检测框架中经常会用到的一个tricks,其主要的思路如下所示:首先对RPN获得的候选ROI(正负样本分别进行排序)进行排序操作;然后在含有正样本(目标)的ROI中选择前N个ROI,将正负样本的比例维持在1:3的范围内,基本上保证每次抽取的样本中都会含有一定的正样本,都可以通过训练来提高网络的分类能力。如果不进行此操作的话,很可能会出现抽取的所有样本都是负样本(背景)的情况,这样让网络学习这些负样本,会影响网络的性能。(这完全是我个人的理解,哈哈哈)
8. Atrous algorithm(Dilated Convolutions或者膨胀卷积)
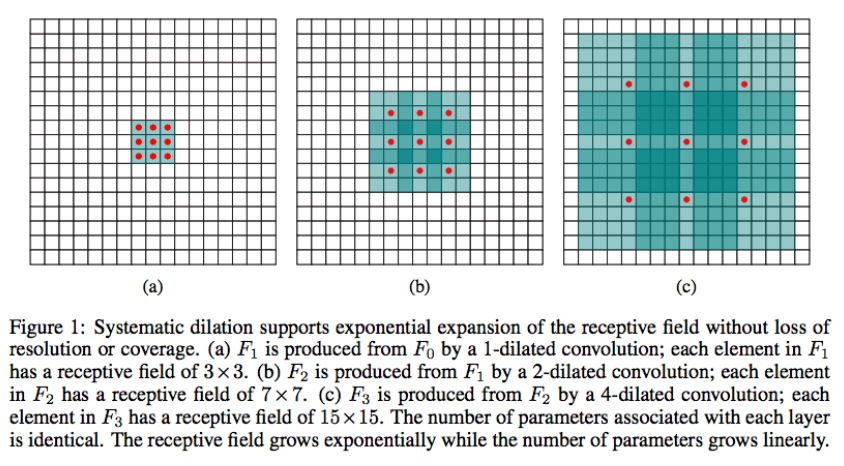
图7 膨胀卷积
这个方法同样也是目标检测中常用的一个tricks,其最主要的目的是可以在减小卷积步长的同时扩大feature map的大小,即同等情况下,通过这个操作,我们可以获得一个更大的feature map,而实验表明,大的feature map会提升检测的性能。具体的解释可以去看这个链接。上图是一个膨胀卷积的操作,通过几次操作,我们可以看到我们的接收场在不断的扩大,具体的解释请看英文吧。
9. 为了过滤背景Rols使用的方法
在测试的时候,为了减少RoIs的数量,作者在RPN提取阶段就对RPN提取的大约2W个proposals进行了过滤,方法如下所示,
- 去除超过图像边界的proposals;
- 使用基于类别概率且阈值IoU=0.7的NMS过滤;
- 按照类别概率选择top-N个proposals;
所以在测试的时候,最后一般只剩下300左右个RoIs,当然这个数量是一个超参数。并且在R-FCN的输出300个预测框之后,仍然要对其使用NMS去除冗余的预测框。
10. 训练细节
R-FCN和Faster R-CNN采取了同样的训练策略,具体的训练策略可以参考这篇博客https://blog.csdn.net/wzz18191171661/article/details/79439212。
11. 图片中的ROI和特征上的ROI之间的映射关系
如果你不清楚它们是如何映射的,请查看这个链接https://blog.csdn.net/wzz18191171661/article/details/79453780。
完全转自:https://blog.csdn.net/WZZ18191171661/article/details/79481135
R-FCN论文理解的更多相关文章
- [论文理解]关于ResNet的进一步理解
[论文理解]关于ResNet的理解 这两天回忆起resnet,感觉残差结构还是不怎么理解(可能当时理解了,时间长了忘了吧),重新梳理一下两点,关于resnet结构的思考. 要解决什么问题 论文的一大贡 ...
- [论文理解] CornerNet: Detecting Objects as Paired Keypoints
[论文理解] CornerNet: Detecting Objects as Paired Keypoints 简介 首先这是一篇anchor free的文章,看了之后觉得方法挺好的,预测左上角和右下 ...
- 深度学习-Wasserstein GAN论文理解笔记
GAN存在问题 训练困难,G和D多次尝试没有稳定性,Loss无法知道能否优化,生成样本单一,改进方案靠暴力尝试 WGAN GAN的Loss函数选择不合适,使模型容易面临梯度消失,梯度不稳定,优化目标不 ...
- [论文理解] Attentional Pooling for Action Recognition
Attentional Pooling for Action Recognition 简介 这是一篇NIPS的文章,文章亮点是对池化进行矩阵表示,使用二阶池的矩阵表示,并将权重矩阵进行低秩分解,从而使 ...
- [论文理解] Squeeze-and-Excitation Networks
Squeeze-and-Excitation Networks 简介 SENet提出了一种更好的特征表示结构,通过支路结构学习作用到input上更好的表示feature.结构上是使用一个支路去学习如何 ...
- learning to Estimate 3D Hand Pose from Single RGB Images论文理解
持续更新...... 概括:以往很多论文借助深度信息将2D上升到3D,这篇论文则是想要用网络训练代替深度数据(设备成本比较高),提高他的泛性,诠释了只要合成数据集足够大和网络足够强,我就可以不用深度信 ...
- FCN的理解
FCN特点 1.卷积化 即是将普通的分类网络丢弃全连接层,换上对应的卷积层即可 2.上采样 方法是双线性上采样差 此处的上采样即是反卷积3.因为如果将全卷积之后的结果直接上采样得到的结果是很粗糙的,所 ...
- YOLO V3论文理解
YOLO3主要的改进有:调整了网络结构:利用多尺度特征进行对象检测:对象分类用Logistic取代了softmax. 1.Darknet-53 network在论文中虽然有给网络的图,但我还是简单说一 ...
- YOLO V2论文理解
概述 YOLO(You Only Look Once: Unified, Real-Time Object Detection)从v1版本进化到了v2版本,作者在darknet主页先行一步放出源代码, ...
随机推荐
- tensorflow显存管理
在运行上面的blog的Tensorflow小程序的时候程序我们会遇到一个问题,当然这个问题不影响我们实际的结果计算,但是会给同样使用这台计算机的人带来麻烦,程序会自动调用所有能调用到的资源,并且全占满 ...
- 使用echo命令清空tomcat日志文件
使用echo命令清空日志文件echo -n "" > /server/tomcat/logs/catalina.out ==>要加上"-n"参数,默 ...
- MySQL数据库----基础操作
一.知识储备 数据库服务器:一台计算机(对内存要求比较高) 数据库管理系统:如mysql,是一个软件 数据库:oldboy_stu,相当于文件夹 表:student,scholl,class_list ...
- 为自己的网站添加Markdown功能 markedjs
Markdown几个简单的标记可以实现轻量级的代替Word方案 不多说,引入开源库js https://github.com/chjj/marked使用方式简单,如下实例代码: <!DOCTYP ...
- scrapy运行方式
1,在cmd 命令行下执行 scrapy crawl demo (爬虫主逻辑的 name= 'demo '的名字) 2, 也可以在spider目录下添加一个py文件,加入以下代码 from scra ...
- 静态编译C/C++程序
静态编译C/C++程序,让程序运行不受平台限制 由于Linux操作系统的特有elf加载顺序. (可以参考此文). 虽然可以很大程度上解决Windows早期版本的dll hell问题, 但是给部署带来了 ...
- 定制django admin页面的跳转
在django admin的 change_view, add_view和delete_view页面,如果想让页面完成操作后跳转到我们想去的url,该怎么做 默认django admin会跳转到ch ...
- 20135234mqy-——信息安全系统设计基础第二周学习总结
Linux基础 1.Linux命令 command [options] [arguments] //中括号代表是可选的,即有些命令不需要选项也不需要参数 选项(options)或参数(argument ...
- 20165310java_blog_week7
2165310 <Java程序设计>第7周学习总结 教材学习内容总结 通过JDBC管理数据库 原理图: 链接数据库方式 - `Connection getConnection(java.l ...
- [c/c++]指针(3)
在指针2中提到了怎么用指针申配内存,但是,指针申配的内存不会无缘无故地 被收回.很多poj上的题都是有多组数据,每次地数组大小会不同,所以要重新申请 一块内存.但是原来的内存却不会被收回,也是说2.3 ...