基本的RAID介绍
RAID是一个我们经常能见到的名词。但却因为很少能在实际环境中体验,所以很难对其原理 能有很清楚的认识和掌握。本文将对RAID技术进行介绍和总结,以期能尽量阐明其概念。
RAID全称为独立磁盘冗余阵列(Rdeundant Array of Independent Disks),基本思想就是把 多个相对便宜的硬盘组合起来,成为一个硬盘阵列组,使性能达到甚至超过一个价格昂贵、 容量巨大的硬盘。RAID通常被用在服务器电脑上,使用完全相同的硬盘组成一个逻辑扇区, 因此操作系统只会把它当做一个硬盘。
RAID分为不同的等级,各个不同的等级均在数据可靠性及读写性能上做了不同的权衡。 在实际应用中,可以依据自己的实际需求选择不同的RAID方案。
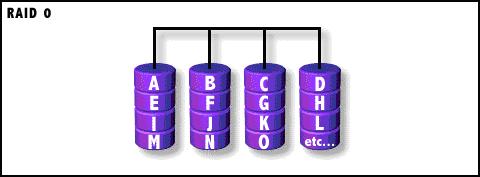
RAID0
条带化(Stripe)存储。理论上说,有N个磁盘组成的RAID0是单个磁盘读写速度的N倍。RAID 0连续以位或字节为单位分割数据,并行读/写于多个磁盘上,因此具有很高的数据传输率,但它没有数据冗余,因此并不能算是真正的RAID结构。
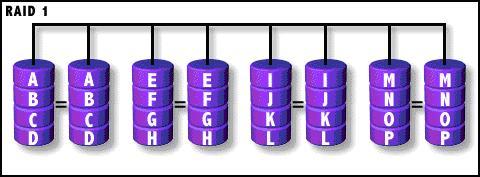
RAID1
镜象(Mirror)存储。它是通过磁盘数据镜像实现数据冗余,在成对的独立磁盘上产生互
为备份的数据。当原始数据繁忙时,可直接从镜像拷贝中读取数据,因此RAID 1可以提高读取性能。RAID
1是磁盘阵列中单位成本最高的,但提供了很高的数据安全性和可用性。当一个磁盘失效时,系统可以自动切换到镜像磁盘上读写,而不需要重组失效的数据。
RAID2
海明码(Hamming Code)校验条带存储。将数据条块化地分布于不同的硬盘上,条块单位为位或字节,使用称为海明码来提供错误检查及恢复。这种编码技术需要多个磁盘存放检查及恢复信息,使得RAID 2技术实施更复杂,因此在商业环境中很少使用。

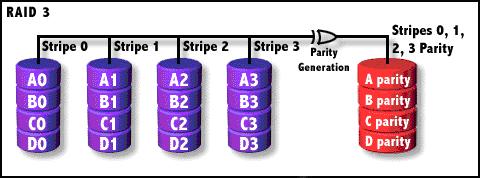
RAID3
奇偶校验(XOR)条带存储,共享校验盘,数据条带存储单位为字节。它同RAID 2非常类似,都是将数据条块化分布于不同的硬盘上,区别在于RAID
3使用简单的奇偶校验,并用单块磁盘存放奇偶校验信息。如果一块磁盘失效,奇偶盘及其他数据盘可以重新产生数据;如果奇偶盘失效则不影响数据使用。RAID
3对于大量的连续数据可提供很好的传输率,但对于随机数据来说,奇偶盘会成为写操作的瓶颈。
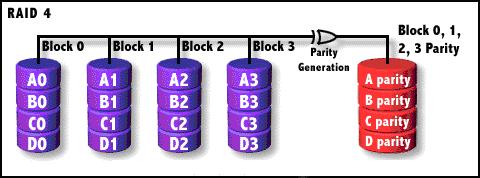
RAID4
奇偶校验(XOR)条带存储,共享校验盘,数据条带存储单位为块。RAID 4同样也将数据条块化并分布于不同的磁盘上,但条块单位为块或记录。RAID
4使用一块磁盘作为奇偶校验盘,每次写操作都需要访问奇偶盘,这时奇偶校验盘会成为写操作的瓶颈,因此RAID 4在商业环境中也很少使用。
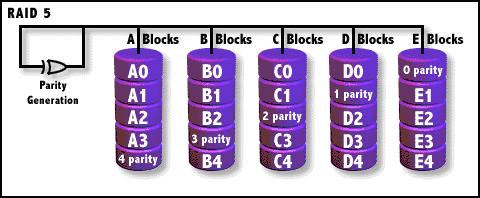
RAID5
奇偶校验(XOR)条带存储,校验数据分布式存储,数据条带存储单位为块。RAID
5不单独指定的奇偶盘,而是在所有磁盘上交叉地存取数据及奇偶校验信息。在RAID
5上,读/写指针可同时对阵列设备进行操作,提供了更高的数据流量。RAID 5更适合于小数据块和随机读写的数据。RAID 3与RAID
5相比,最主要的区别在于RAID 3每进行一次数据传输就需涉及到所有的阵列盘;而对于RAID
5来说,大部分数据传输只对一块磁盘操作,并可进行并行操作。在RAID
5中有“写损失”,即每一次写操作将产生四个实际的读/写操作,其中两次读旧的数据及奇偶信息,两次写新的数据及奇偶信息。
当进行恢复时,比如我们需要需要恢复下图中的A0,这里就必须需要B0、C0、D0加0 parity才能计算并得出A0,进行数据恢复。所以当有两块盘坏掉的时候,整个RAID的数据失效。
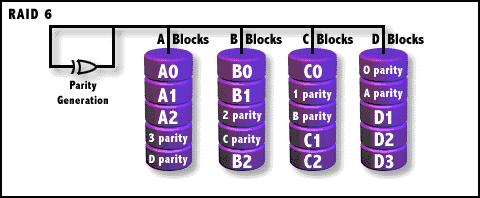
RAID6
奇偶校验(XOR)条带存储,两个分布式存储的校验数据,数据条带存储单位为块。与RAID 5相比,RAID
6增加了第二个独立的奇偶校验信息块。两个独立的奇偶系统使用不同的算法,数据的可靠性非常高,即使两块磁盘同时失效也不会影响数据的使用。但RAID
6需要分配给奇偶校验信息更大的磁盘空间,相对于RAID 5有更大的“写损失”,因此“写性能”非常差。较差的性能和复杂的实施方式使得RAID
6很少得到实际应用。
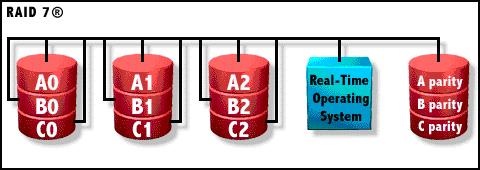
RAID7
这是一种新的RAID标准,其自身带有智能化实时操作系统和用于存储管理的软件工具,可完全独立于主机运行,不占用主机CPU资源。RAID 7可以看作是一种存储计算机(Storage Computer),它与其他RAID标准有明显区别。
RAID
7等级是至今为止,理论上性能最高的RAID模式,因为它从组建方式上就已经和以往的方式有了重大的不同。基本成形式见图,以往一个硬盘是一个组成阵列的“柱子”,而在RAID
7中,多个硬盘组成一个“柱子”,它们都有各自的通道,也正因为如此,你可以把这个图分解成一个个硬盘连接在主通道上,只是比以前的等级更为细分了。这样做的好处就是在读/写某一区域的数据时,可以迅速定位,而不会因为以往因单个硬盘的限制同一时间只能访问该数据区的一部分,在RAID
7中,以前的单个硬盘相当于分割成多个独立的硬盘,有自己的读写通道。
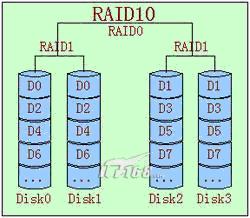
RAID10和RAID01的比较
- RAID10是先做镜象,然后再做条带。
- RAID01则是先做条带,然后再做镜象。
比如以6个盘为例,RAID10就是先将盘分成3组镜象,然后再对这3个RAID1做条带。RAID01则是先利用3块盘做RAID0,然后将另外3块盘做为RAID0的镜象。下面以4块盘为例来介绍安全性方面的差别:
1、RAID10的情况
这种情况中,我们假设当DISK0损坏时,在剩下的3块盘中,只有当DISK1一个盘发生故障时,才会导致整个RAID失效,我们可简单计算故障率为1/3。
2、RAID01的情况
这种情况下,我们仍然假设DISK0损坏,这时左边的条带将无法读取。在剩下的3块盘中,只要DISK2,DISK3两个盘中任何一个损坏,都会导致整个RAID失效,我们可简单计算故障率为2/3。

因此RAID10比RAID01在安全性方面要强。
从数据存储的逻辑位置来看,在正常的情况下RAID01和RAID10是完全一样的,而且每一个读写操作所产生的IO数量也是一样的,所以在读写性能上两者没什么区别。而当有磁盘出现故障时,比如前面假设的DISK0损坏时,我们也可以发现,这两种情况下,在读的性能上面也将不同,RAID10的读性能将优于RAID01。
基本的RAID介绍的更多相关文章
- RAID 介绍
介绍 磁盘阵列(Redundant Arrays of Independent Disks,RAID),有“独立磁盘构成的具有冗余能力的阵列”之意. 磁盘阵列是由很多价格较便宜的磁盘,组合成一个容量巨 ...
- Raid 介绍以及软raid的实现
RAID: old Redundant Arrays of Inexpensive Disks (廉价磁盘冗余阵列) new Redundant Arrays of Independent Disks ...
- 几种RAID介绍(总结)
概念 RAID是Redundent Array of Inexpensive Disks的缩写,简称为“磁盘阵列”.后来RAID中的字母I被改作了Independent,RAID就成了“独立冗余磁盘阵 ...
- Raid介绍
https://wsgzao.github.io/post/raid/ http://www.cnblogs.com/Bob-FD/p/3409221.html
- RAID介绍和实现
RAID的全称是廉价磁盘冗余阵列(Redundant Array of Inexpensive Disks),于1987年由美国Berkeley 大学的两名工程师提出的. RAID出现的,最初目的是将 ...
- 18.RAID介绍和部署磁盘阵列
1.RAID RAID(Redundant Array of Independent Disks,独立冗余磁盘阵列)技术具备的冗余备份机制以及提升了的硬盘吞吐量. 1)RAID 0:把多块物理硬盘设备 ...
- RAID技术介绍
RAID技术介绍 简介 RAID是一个我们经常能见到的名词.但却因为很少能在实际环境中体验,所以很难对其原理 能有很清楚的认识和掌握.本文将对RAID技术进行介绍和总结,以期能尽量阐明其概念. RAI ...
- RAID的简单介绍
该文章全部复制转载于:http://blog.jobbole.com/83808/,只为做笔记供自己查看 简介 RAID是一个我们经常能见到的名词.但却因为很少能在实际环境中体验,所以很难对其原理 能 ...
- [转]RAID技术介绍和总结
以下内容转自伯乐在线:http://blog.jobbole.com/83808/ 原文出处: 涯余(@若东临于沧海) ---------------------------------------- ...
随机推荐
- Axure-Axure RP For Chrome 演示扩展
Axure RP生成的Html原型,其中包含JS文件,在本地进行演示时浏览器IE会弹出安全提醒.谷歌浏览器Chrome则需要在线安装一个Axure的扩展工具才可以演示. Axure RP Extens ...
- Intercepting a 404 in IIS 7 and up
Lately I've been working on a system that needs to serve flat files, which is what IIS is very goo ...
- linux设置开机同步时间
在/etc/init.d/下新建zhjdate脚本,添加如下内容: #!/bin/bash# chkconfig: 345 63 37#chkconfig:345 63 37 (数字345是指在运行级 ...
- 小教程:自己创建一个jQuery长阴影插件
长阴影设计是平面设计的一个变体,添加了阴影,产生了深度的幻觉,并导致了三维的设计.在本教程中,我们将创建一个jQuery插件,通过添加完全可自定义的长阴影图标,我们可以轻松地转换平面图标. 戳我查看效 ...
- Android下雪动画的实现
原文链接 : Snowfall 原文作者 : Styling Android 译文出自 : hanks.xyz 译者 : hanks-zyh 校对者: desmond1121 状态 : 完毕 这本是一 ...
- win10 教育版本变专业版本
输入win10升级产品密匙:VK7JG-NPHTM-C97JM-9MPGT-3V66T.系统自动验证后依次点击下一步.始按钮kms激活
- ReactNative踩坑日志——页面跳转之——Undefined is not an Object(evaluating this2.props.navigation.navigate)
页面跳转时,报 Undefined is not an Object(evaluating this2.props.navigation.navigate) 出错原因:在一个页面组件中调用了另一个组 ...
- JDBC编程之预编译SQL与防注入式攻击以及PreparedStatement的使用教程
转载请注明原文地址: http://www.cnblogs.com/ygj0930/p/5876951.html 在JDBC编程中,常用Statement.PreparedStatement 和 ...
- 下拉列表框select
下拉列表框select CreateTime--2017年5月15日15:39:24 Author:Marydon 三.下拉列表框 (一)语法 <select></select& ...
- SQL Server 2012 无人值守安装(加入新实例)
方法1,通过指定条个參数安装 setup.exe /Q /IACCEPTSQLSERVERLICENSETERMS /ACTION=install /PID=<validpid> /FEA ...