GBT算法在拖动滑块辨别人还是机器中的应用
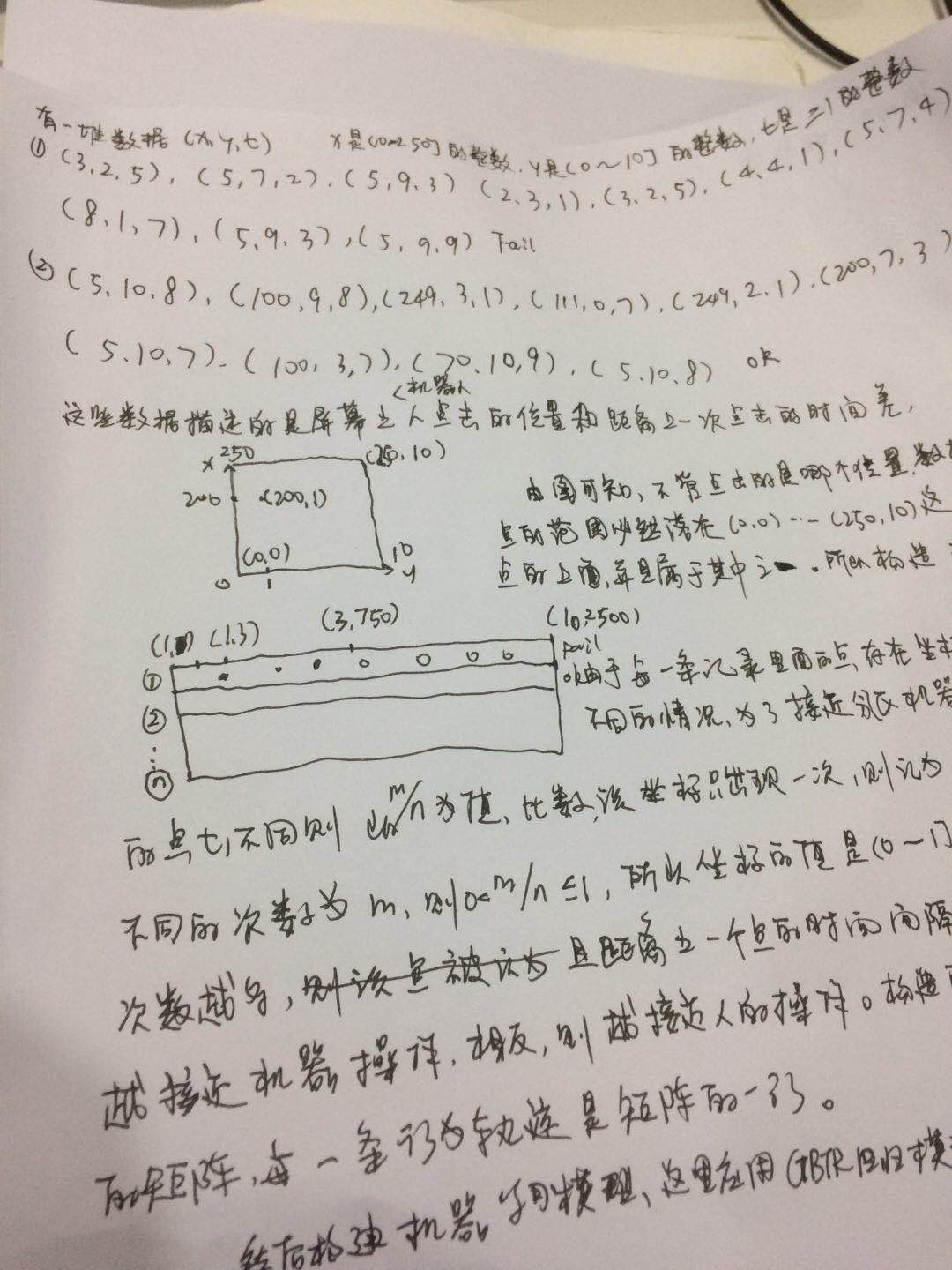
1.数据源格式:(x,y,t),第一个值x是x坐标范围是1-250的整数,y是1-10的整数,t是滑块从上一个坐标到下一个坐标的时间差,ok是判断是人操作的,Fail是判断是机器操作的,数据看的出,同一个记录里面的同一个点,即x,y都相同,但是t不同,以此分析,如果同一个点只出现一次,则该点记录为1,如果出现n次,重复次数为m次,则设计该点的值为m/n,如该点在该条记录出现的总次数是5,t不同的次数是3,则该点的值是=3、5=0.6,分析的依据是,如果该点重复的次数越多,而且距离上一个时间差越近,说明越接近机器人的轨迹,因为人的轨迹是变化较大的。将模型设计为一个大表,以1-2500这2500个数字为字段,这个表在scala 程序中是一个数组,数组长度为2500,1...250分别对应坐标点中的(0,0,)....(0,250),2-500分别对应坐标点中的(1,0)...(1,250)...所以必然,在每条记录里面的所有点必然在这个数组中能找到,在表中就是一行,这些点必然是在这行中能找到一个列属于该点,如果不存在,则设为0.
[[25,27,0],[6,-1,470],[8,2,20],[14,-1,38],[10,1,28],[3,0,9],[10,-2,28],[9,1,27],[12,-1,38],[12,0,39],[3,2,10],[10,0,35],[3,-1,8],[6,-1,25],[8,1,31],[5,0,18],[2,1,11],[7,0,29],[2,-2,11],[4,2,20],[4,-2,18],[2,1,13],[1,-1,7],[6,2,32],[3,-1,17],[5,0,37],[4,-1,32],[3,0,24],[4,1,32],[4,-1,39],[4,0,40],[3,2,35],[1,0,12],[2,-2,28],[0,1,229]];FAIL
[[27,24,0],[4,1,467],[8,-1,40],[2,-1,7],[2,2,9],[3,-2,15],[6,2,32],[4,-1,20],[7,1,35],[5,-2,26],[2,1,10],[5,1,27],[1,-1,6],[2,0,15],[5,1,26],[4,-2,28],[3,0,23],[1,2,7],[4,-1,26],[3,-1,19],[1,0,7],[3,2,24],[0,0,6],[5,-1,40],[4,-1,39],[1,1,8],[0,0,7],[3,0,35],[3,0,26],[2,-1,32],[2,0,32],[2,2,33],[1,-2,8],[1,1,25],[1,1,14],[1,-1,22],[2,-1,40],[0,0,22],[1,0,1],[0,1,219]];FAIL
[[25,28,0],[8,1,524],[7,-1,27],[4,0,16],[3,-1,16],[3,2,10],[8,-1,35],[8,-1,40],[8,2,38],[2,-1,10],[6,-1,29],[4,0,23],[7,2,36],[5,-2,33],[5,2,26],[4,-1,29],[4,0,26],[1,0,9],[5,-1,38],[2,0,25],[4,1,29],[3,0,37],[2,0,19],[0,-1,6],[3,1,34],[2,0,24],[2,0,27],[2,-1,32],[2,0,40],[1,1,6],[1,-1,22],[1,0,33],[1,0,4],[0,1,299]];OK
2.算法构造scala代码如下:
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.feature.VectorIndexer
import org.apache.spark.ml.regression.{GBTRegressionModel, GBTRegressor}
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.sql.types.{DoubleType, StringType, StructField, StructType}
import org.apache.spark.sql.SQLContext
import org.apache.spark.mllib.evaluation.BinaryClassificationMetrics
import org.apache.spark.mllib.regression.LabeledPoint
object GBTForget {
/**
* Created by lkl on 2017/12/14.
*/
def main(args: Array[String]): Unit = {
val cf = new SparkConf().setAppName("ass").setMaster("local")
val sc = new SparkContext(cf)
val sqlContext = new SQLContext(sc)
import sqlContext.implicits._
val File1 = sc.textFile("20171117PP.txt").filter(_.contains("OK")).map(_.replace(",0],","a[").split("a").last).map(_.replace("OK", "1")).map(_.replace("FAIL", "0")).map(line => (line.split(";").last.toDouble, line.split(";").head))
val File2=sc.textFile("20171117PP.txt").filter(_.contains("FAIL")).map(_.replace(",0],","a[").split("a").last).map(_.replace("OK", "1")).map(_.replace("FAIL", "0")).map(line => (line.split(";").last.toDouble, line.split(";").head))
val b=File2.randomSplit(Array(0.1, 0.9))
val (strainingDatas, stestDatas) = (b(0), b(1))
val File=File1 union(strainingDatas)
val ass = File.map { p => {
var str = ""
val l = p._1
val a = p._2.substring(2, p._2.length - 2)
val b = a.replace("],[", "a")
val c = b.split("a")
for (arr <- c) {
val index1 = arr.split(",")(0).toInt + ","
val index2 = arr.split(",")(1).toInt + ","
val index3 = arr.split(",")(2).toInt + " "
val index = index1 + index2 + index3
str += index
}
(l, str.substring(0, str.length - 1))
}
}
val rdd = ass.map( p => {
val l=p._1
val rowall =new Array[Double](2500)
val arr = p._2.split(" ")
var map:Map[Int,List[Double]] = Map()
var vlist:List[Double] = List()
for(a <- arr){
val x = a.split(",")(0).toInt
val y = a.split(",")(1).toInt+5
val t = a.split(",")(2).toInt
val index = (x*10)+(y+1)
val v = t
vlist = v :: map.get(index).getOrElse(List())
map += (index -> vlist) }
map.foreach(p => {
val k = p._1
val v = p._2
val sv = v.toSet.size
val rv = sv.toDouble/v.size.toDouble
val tmp =f"$rv%1.2f".toDouble
rowall(k) = tmp
})
(l.toDouble,Vectors.dense(rowall))
}).toDF("label","features") // val label=row.getInt(0).toDouble
// val no=row.getString(2)
// val feature=Vectors.dense(arr.toArray)
// (label,no,feature)
// Automatically identify categorical features, and index them.
// Set maxCategories so features with > 4 distinct values are treated as continuous.
val featureIndexer = new VectorIndexer().setInputCol("features").setOutputCol("indexedFeatures").setMaxCategories(4).fit(rdd)
// Split the data into training and test sets (30% held out for testing)
val Array(trainingData, testData) = rdd.randomSplit(Array(0.7, 0.3))
// Train a GBT model.
val gbt = new GBTRegressor().setLabelCol("label").setFeaturesCol("indexedFeatures").setMaxIter(10)
// Chain indexer and GBT in a Pipeline
val pipeline = new Pipeline().setStages(Array(featureIndexer, gbt))
// Train model. This also runs the indexer.
val model = pipeline.fit(trainingData)
// Make predictions.
val predictions = model.transform(testData).select("label","prediction").toJavaRDD
predictions.repartition(1).saveAsTextFile("/user/hadoop/20171214") val File0=sc.textFile("001.txt").map(_.replace(",0],","a[").split("a").last).map(_.replace("OK", "1")).map(_.replace("FAIL", "0")).map(line => (line.split(";").last.toDouble, line.split(";").head)) val ass001 = File0.map { p => {
var str = ""
val l = p._1
val a = p._2.substring(2, p._2.length - 2)
val b = a.replace("],[", "a")
val c = b.split("a")
for (arr <- c) {
val index1 = arr.split(",")(0).toInt + ","
val index2 = arr.split(",")(1).toInt + ","
val index3 = arr.split(",")(2).toInt + " "
val index = index1 + index2 + index3
str += index
}
(l, str.substring(0, str.length - 1))
}
}
val rdd001 = ass001.map( p => {
val l=p._1
val rowall =new Array[Double](2500)
val arr = p._2.split(" ")
var map:Map[Int,List[Double]] = Map()
var vlist:List[Double] = List()
for(a <- arr){
val x = a.split(",")(0).toInt
val y = a.split(",")(1).toInt+5
val t = a.split(",")(2).toInt
val index = (x*10)+(y+1)
val v = t
vlist = v :: map.get(index).getOrElse(List())
map += (index -> vlist) }
map.foreach(p => {
val k = p._1
val v = p._2
val sv = v.toSet.size
val rv = sv.toDouble/v.size.toDouble
val tmp =f"$rv%1.2f".toDouble
rowall(k) = tmp
})
(l.toDouble,Vectors.dense(rowall))
}).toDF("label","features") val predicions001=model.transform(rdd001) // predicions001.repartition(1).saveAsTextFile("/user/hadoop/20171214001") } }
GBT算法在拖动滑块辨别人还是机器中的应用的更多相关文章
- jQuery手机触屏拖动滑块验证跳转插件
HTML: <!DOCTYPE html> <html lang="en"> <head> <title>jQuery手机触屏拖动滑 ...
- js+css3+HTML5拖动滑块(type="range")改变值
最近在做一个H5的改版项目,产品和设计给出的效果中有一个拖动滑块可以改变输入值的效果,类似如下图这样: 拿到这样的设计稿后,我有点懵了,自己写一个js?去网上找一个这样的效果?自己写一个可以,只是实现 ...
- 原生js实现拖动滑块验证
拖动滑块验证是现在的网站随处可见的,各式各样的拖动法都有. 下面实现的是某宝的拖动滑块验证: <!DOCTYPE html> <html lang="en"> ...
- [Android实例] 拖动滑块进行图片拼合验证方式的实现
该篇文章从eoeAndroid搬迁过来的,原文地址:[Android实例] 拖动滑块进行图片拼合验证方式的实现 现在网站上有各种各样的验证码验证方式,比如计算大小,输入图片内容等,今天在一家网站上看到 ...
- js 拖动滑块验证
备注:拖动滑块时尽量平移,chrome浏览器上没有卡顿情况,但是搜狗极速模式和360极速模式都遇到了卡顿,拖不动情况,应是浏览器内部对事件响应速度导致吧. JS代码: ;(function ($,wi ...
- html5拖动滑块
html5中input有增加type=range.这为拖动滑块提供了很大的便利.下面是他的属性: <!DOCTYPE html> <html lang="en"& ...
- seekBar拖动滑块
中秋节学习,, 通过拖动滑块,改变图片的透明度 <?xml version="1.0" encoding="utf-8"?> <LinearL ...
- 原生JS实现拖动滑块验证登录效果
♀分享一组利用原生JS实现拖动滑块验证效果 ♀在这个组代码中涉及三个方面的知识: ⑴事件处理 ⑵添加验证标记 ⑶选择器的封装 代码如下: <!DOCTYPE html> <htm ...
- 常见算法合集[java源码+持续更新中...]
一.引子 本文搜集从各种资源上搜集高频面试算法,慢慢填充...每个算法都亲测可运行,原理有注释.Talk is cheap,show me the code! 走你~ 二.常见算法 2.1 判断单向链 ...
随机推荐
- mybatis中的.xml文件总结——mybatis的动态sql
resultMap resultType可以指定pojo将查询结果映射为pojo,但需要pojo的属性名和sql查询的列名一致方可映射成功. 如果sql查询字段名和pojo的属性名不一致,可以通过re ...
- JAVA-JSP内置对象之request对象的其他方法
相关资料:<21天学通Java Web开发> request对象的其他方法1.request对象除了可以用来获得请求参数,还可以用来获得HTTP标头及其他信息. 方法 ...
- 修改zerolog使log输出的文件名可以在goland里自动定位--技巧
如何自动定位文件 最近发现goland会自动识别输出的文件或者url,但是有时候又识别不出来,折腾了一下,发现原来要求文件路径或url两边要有空格 改造zerolog 既然如此,那么让我们来改造一下z ...
- 【转】mybatis连接Oracle做增删改查
原文地址:http://blog.csdn.net/liumengcheng/article/details/34422475 入门请看http://blog.csdn.NET/liumengchen ...
- 如何在CentOS或者RHEL上启用Nux Dextop仓库 安装shutter截图工具
Nux Dextop是一个面对CentOS.RHEL.ScientificLinux的含有许多流行的桌面和多媒体相关的包的第三方RPM仓库(比如:Ardour,Shutter等等).目前,Nux De ...
- <聪明的投资者(第四版点评)>读书笔记
书在这里 企业的内在价值并不依赖于其股票价格 投资者的最大问题甚至最可怕的敌人,很可能就是他们自己 投资者不能指望通过买任何新股或“热门”股,而获得优于平均水平的收益.从长远来看,这几乎无疑会产生相反 ...
- Android——事务
一.什么是事务 事务是应用程序中一系列严密的操作,所有操作必须成功完成,否则在每个操作中所作的所有更改都会被撤消.也就是事务具有原子性,一个事务中的一系列的操作要么全部成功,要么一个都不做. 事务的结 ...
- IE兼容性视图设置
问题: 页面 http://course.upol.cn/lx/jzjjygl/index.html 的课程学习中课程打不开 看了代码是有浏览器版本要求,IE9以上无法访问 解决办法: 1. 在IE设 ...
- JS运动 - 无缝滚动和缓动动画
JS运动 - 无缝滚动和缓动动画 无缝滚动原理:首先先复制两张图片(第一张和第二张)放到最后面;ul绝对定位,如果ul的left值大于等于4张图片的宽度,就应该快速复原为0. html <!DO ...
- Android Studio xcode单步调试 WebRTC Android & iOS
mac环境 如何在 Android Studio 里单步调试 WebRTC Android 的 native 代码. WebRTC 代码下载 depot tools 是 chromium 代码库管理工 ...