HTTP真的很简单(转)
原文:HTTP Made Really Easy因为我本身网络基础就很差,所以看到这篇文章一方面是学习网络知识,另一方面为了锻炼我蹩脚的英语水平,文中如有错误,欢迎浏览指正!
前言
在看这篇文章的时候,推荐使用chrome浏览器查看http请求过程中的相关参数。chrome浏览器,可以通过‘alt+cmd+i’进入开发者模式。进入‘Network’一栏,在‘Name’栏内找到请求的网址。查看Headers一栏,就可以看到‘Response Headers’和‘Request Headers’。并可以选择‘view parsed’和‘view source’。下面以http://www.xuewiehan.com 为例子演示一下。如下图: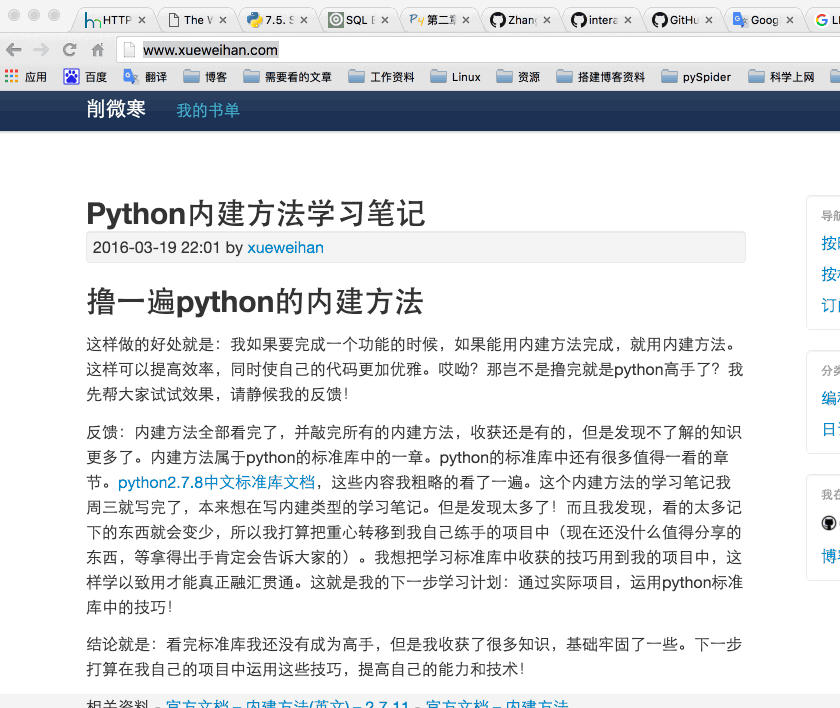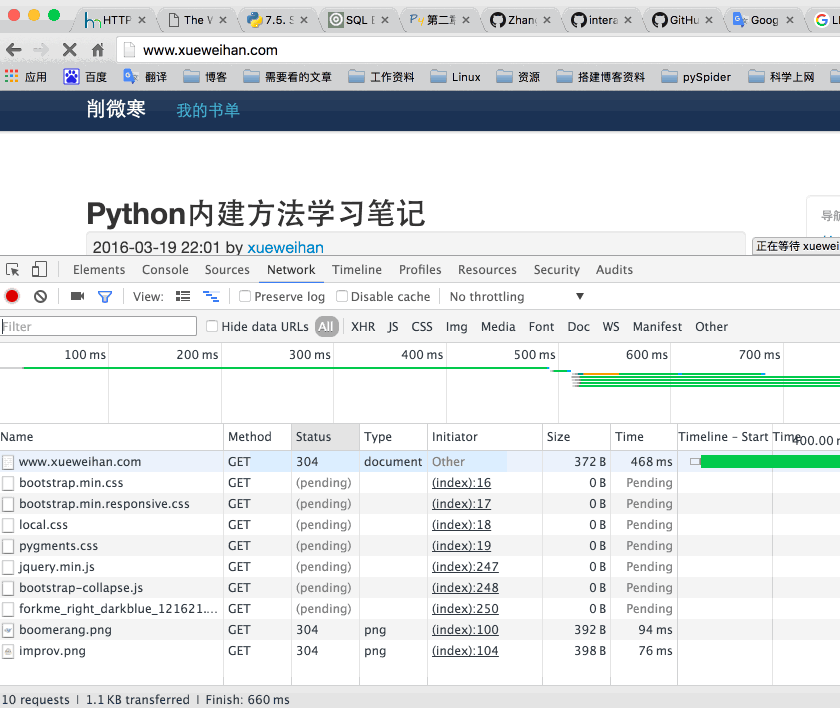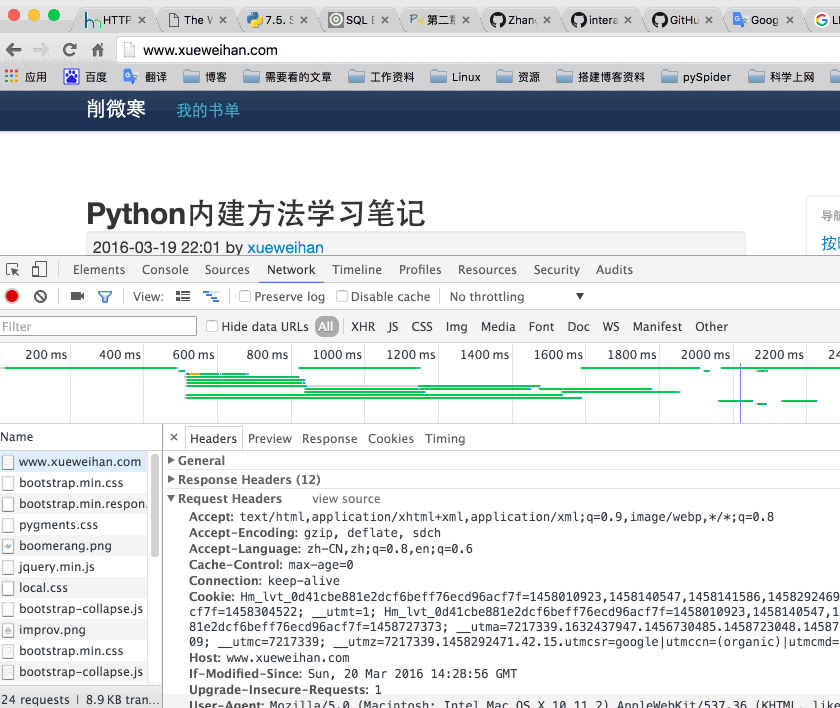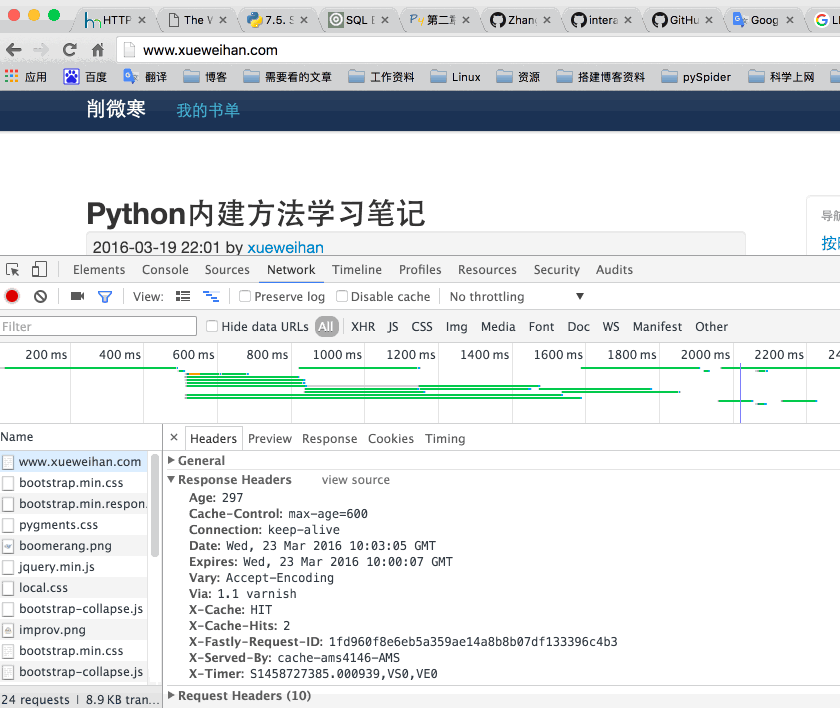
HTTP真的很简单
HTTP是一种网络协议,它十分简单但强大。知晓HTTP协议,使你可以写一个:Web浏览器,Web服务器,爬虫或者其他实用的工具。
这是个通俗易懂,讲解HTTP的文章。教你写HTTP clients和servers。看这篇文章需要你有socket网络编程的基础,HTTP对于会socket编程的程序员来说十分简单。所以请先确保你学会了socket编程(看来我要写一个socket编程的教程了!)同时搞懂了CGI。
这篇文章前半段,是基于HTTP 1.0,下半部分是解释HTTP 1.1的新特性。虽然没有覆盖HTTP所有的点,但是会让你对HTTP有一个基本的框架,之后你可以根据你的需求,再深入全面的学习。
在文章的开始之前,先来看看下面的两段文字:
- 写一个网络应用,需要比写一个单机程序更加小心,考虑的东西要更多!当然你必须要符合标准(也就是协议),否则没人可以能理解你。更加重要的是:你写的垃圾程序,运行在你的机器上,只会浪费你的机器的资源(CPU,带宽,内存)。如果一个垃圾的网络程序,你将会浪费其他人的资源。如果是特别垃圾的程序,那么将会浪费成千上万人的资源。这些情况使得建立更好的,安全的网络协议,对每个人都是有益的!
- 不要盲目的去写爬虫,除非你十分清楚你自己在做什么。爬虫是很实用,但是垃圾的爬虫,不符合规则的爬虫,使得网络环境越来越错综复杂。如果你想要写任何一个‘爬虫机器人’,请遵循robots.txt中的内容。
什么是HTTP?
HTTP是超文本传输协议,是一种用于在万维网,传输文件,无论是HTML文件,还是图片,请求等数据的网络协议。通常HTTP协议是建立在TCP/IP socket通信基础之上的。
HTTP协议是客户端(client)和服务器(servers)通信的协议。浏览器就是一个客户端,因为它发送请求给HTTP服务器(也就是web服务器),web服务器返回响应给客户端。符合HTTP协议的服务器,默认监听80端口,当然也可以重新指定任何一个端口。
什么是资源?
HTTP协议是用来传播资源,而不仅仅只是文件。资源就是一个URL链接所对应的一些信息。我们普遍见到的资源就是文件,同时资源也可能是:通过不同编程语言写的CGI脚本,动态生成,并输出。返回请求结果的文件。
学习HTTP,有助于理解资源类似于文件的概念。实际场景中,HTTP资源不是静态文件,就是服务器端脚本动态生成的结果。
HTTP的传输结构
就像大多数的网络协议,HTTP也是C/S模式:客户端向服务器发送请求连接和请求的信息内容,服务器返回响应信息。通常包含请求的资源。服务器发送完响应后,关闭连接。(HTTP是一个无状态的连接)
请求和响应的格式长得差不多,它们都是由:
- 一条初始行
- 零或多条头信息
- 一个空行
- 一个可选的消息体
组成的,格式如下,:
<initial line, different for request vs. response>Header1: value1Header2: value2Header3: value3<optional message body goes here, like file contents or query data;it can be many lines long, or even binary data $&*%@!^$@>
initial line和headers必须由回车结尾。
Initial Request Line(请求行)
请求的第一行和响应的第一行不一样!请求的第一行有三个部分:方法名,请求资源的路径(也就是/分隔的路径),使用的HTTP协议版本。访问我的博客首页时,请求头如下:
GET / HTTP/1.1
注意:
- GET方法是HTTP中最常用的方法,他的意思是:‘我要得到这个资源’。另外一个常用的方法是:POST后面会在做详细的说明。方法名全部大写。
- 域名后面的部分就是路径,默认是‘/’。
- HTTP版本形如:‘HTTP/x.x’,全部大写。
Initial Response Line(响应声明行或状态行)
响应的初始行,称作‘状态行’。也是由三个部分组成的:HTTP协议版本,状态码,状态码描述。同样以我博客为例子,状态行如下:
HTTP/1.1 304 Not Modified
注意:
- HTTP版本的内容,形式跟上面一样。
- 状态码是三位的整数,第一位通常分为如下几类:
- 1xx 这一类型的状态码,代表请求已被接受,需要继续处理。(消息)
- 2xx 这一类型的状态码,代表请求已成功被服务器接收、理解、并接受。(成功)
- 3xx 这类状态码代表需要客户端采取进一步的操作才能完成请求。(重定向)
- 4xx 这类的状态码代表了客户端看起来可能发生了错误,妨碍了服务器的处理。(客户端错误)
- 5xx 这类状态码代表了服务器在处理请求的过程中有错误或者异常状态发生。(服务器错误)
常见的状态码:
200 OK:请求成功,接收到资源。
404 Not Found:请求失败,未找到资源。
301 Moved Permanently:永久性转移。
302 Moved Temporarily:暂时性转移。
303 See Other:请求的资源已经移到了另外一个URL上了,客户端会自动跳转。这个通常是CGI脚本使用redirect,使得客户端,重定向到另外一个URL。
500 Server Error:一个未知的服务器错误。
Header Lines(请求头)
请求头提供了请求或响应的信息,或者是关于发送的消息体(message body)的信息。
请求头的格式为:每条头信息占一行例如“Header-Name: value”,以回车结尾。这个格式也被用于邮件等,更加详细的说明:
- 请求头是区分大小写的
- 冒号‘:’后面可以有任意多个空格
下面的两种格式,效果是一样的:
Header1: some-long-value-1a, some-long-value-1bHEADER1: some-long-value-1a,some-long-value-1b
HTTP1.0定义了16种头,没有强制要带的。而HTTP1.1定义了46种头,并且请求时必须带(Host:)。请求时,一些约定俗称的规定(不遵守没问题,但是最好遵守)。
- From头:包含谁请求的,或者这个操作做了什么。
- User-Agent:它包含了谁请求的信息(用户身份),例如:
User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.87 Safari/537.36
上面说的这些头,帮助网络管理员分析问题。这些信息也提供了用户的身份(这些信息可以伪造)。
如果你在写一个‘servers’,考虑返回响应时把下面这些头加上:
- Server:类似User-Agent头,表示的是服务的身份。
- Last-Modified:记此文件在服务期端最后被修改的时间。通常用于缓存,节省带宽。例如:
Last-Modified: Fri, 31 Dec 1999 23:59:59 GMT
Message Body(消息实体)
一个HTTP消息,头信息后面可能有一个消息实体。响应的时候,这个消息实体就是:客户端请求的资源,或者是提示的错误信息。请求时,消息实体就是:用户输入的数据,或者上传的文件。
如果一个HTTP消息包含消息实体,那么通常就会下面的几个头,用来描述消息实体,例如:
- Content-type: 用来表示消息实体的数据类型例如:‘text/html’或者‘image/gif’
- Content-Length: 表示消息体的大小(bytes)
HTTP交互的例子
例如请求一个文件:http://www.somehost.com/path/file.html
首先与目标网站:'www.somehost.com'的80端口建立起socket连接。之后通过socket连接发送类似:
GET /path/file.html HTTP/1.0From: someuser@jmarshall.comUser-Agent: HTTPTool/1.0[blank line here]
这时服务器回返回响应,内容格式如下:
HTTP/1.0 200 OKDate: Fri, 31 Dec 1999 23:59:59 GMTContent-Type: text/htmlContent-Length: 1354<html><body><h1>Happy New Millennium!</h1>(more file contents)...</body></html>
发送完响应之后,服务器会关闭这个socket连接。
HTTP代理
HTTP代理就是服务器和客户端的一个中间程序。它从客户端接受请求,然后把这些请求再发送给服务器。响应返回的时候也是同理,需要通过代理。
代理通常用于防火墙,局域网的安全等。
当客户端使用代理,它就会把所有的请求发送给代理,而不是发给服务器。通过代理请求和普通的请求有一点不同:第一行,代理请求使用完整的URL,而不是只有path。例如:
通过代理请求:GET http://www.somehost.com/path/file.html HTTP/1.0普通请求:GET /path/file.html HTTP/1.0
通过这种方式,代理就知道请求的服务器地址了。
‘宽容待人’
就像常说的:“严格的发送,宽容的接收。”你交互信息过程中,其它的客户端和服务器,它们发送的信息都有可能有瑕疵。但是,你应该尝试预料到这些问题,从而使一切正常的运行。下面有些建议:
- 即使规定必须以回车(CRLF)结尾,但是一些人可能只用换行(LF),所以请同时接受这两者。
- 发送的消息内部,每一个部分必须由一个空行进行隔离。但是,其它程序有可能使用几个空行来隔离。所以也一定要考虑接受这种情况。
当然还有一些其他的情况,总之要多兼容。
结尾
这是HTTP的基本知识。如果你想知道更多,你需要查看官方的资料。
到此为止只讲理HTTP1.0的知识,下面会讲HTTP1.1的知识,所以休息一下,让我们升级一下!
HTTP1.1
想很多的协议一样,HTTP是不断升级的。HTTP1.1完善了HTTP1.0的一些缺点。总的来说,改善的地方包括:
- 更快的响应,在一个连接上允许多个HTTP的请求和响应。(叫做:HTTP持久连接)
- 增加缓存的支持,节省了带宽,提高了响应的速度。
- 更快的响应和生成页面,因为支持分块编码,允许发送的数据可以分成多个部分,好处是:发送数据之前,不需要预先知道发送内容的总大小。
- 因为增加了Host头字段,web浏览器可以使用一个IP地址配置多个虚拟web站点。
HTTP1.1需要再服务器和客户端增加一些额外的东西。接下来的两个部分,分别讲:如何编写遵循HTTP1.1协议的客户端和服务器。当然,你如果只写客户端,只需要看客户端的部分。可以根据自己的需求选择阅读。
HTTP1.1 Clients(客户端)
为了符合HTTP1.1,客户端必须:
- 每次请求必须包含Host头。
- 允许响应是chunked data(分块传输编码)。
- 每个请求,必须在头信息中,声明是否支持持久连接。
- 支持响应返回状态码:‘100 Continue’。
Host Header(Host头)
HTTP1.1开始,支持一个IP对应多个虚拟主机。比如:“www.host1.com”和“www.host2.com”可以是同一个服务器(同一IP)。
一个服务器,有多个域名就像:不同的人,共享一个手机。打电话的人知道他们要找谁,但是接电话的人不知道!所以,打来电话的人需要明确的指出他要找谁。同理,每一个HTTP请求必须在Host头中,明确地指出请求的host。例如:
GET /path/file.html HTTP/1.1Host: www.host1.com:80[blank line here]
其中:80不需特别指出,因为默认就是访问80端口。
HTTP1.1协议下的请求,请求头中必须包含Host。没有它,每一个域名需要一个独一无二的IP地址,IP地址的数据量正在急剧减少,而网站(域名)却以爆炸的速度增长。Host可以有效的缓解IP地址紧张的现状。
分块传输编码
如果服务器想要在知道响应数据总量之前,就发送响应(比如特别长的响应内容,这样计算数据总量会耗费很长的时间),那么就会用到‘分块传输编码’。它把完整的响应数据,分成很多个大小相同的数据块,然后发送。你可以同样接收这样的数据,因为头已经包含了‘Transfer-Encoding: chunked’。所有的HTTP1.1客户端必须可以接收分块的信息。
分块的消息内容需要包含:有一行是‘0’,用于表示内容的结束。有'footers',和一个空行。必须包含两个部分:
- 有一行是用16进制表示这个块的大小,后面的额外参数用分号隔离。
- 数据以回车分割。
例如:
HTTP/1.1 200 OKDate: Fri, 31 Dec 1999 23:59:59 GMTContent-Type: text/plainTransfer-Encoding: chunkeda; ignore-stuff-hereabcdefghijklmnopqrstuvwxyz10234567890abcdef0some-footer: some-valueanother-footer: another-value[blank line here]
不要忘记,最后有一行空行。文本内容的大小是42bytes(1a+10=16+10+16=42),内容是:‘abcdefghijklmnopqrstuvwxyz1234567890abcdef’。
分块数据可以包含任意的二进制数据。下面内容是一样的,但是没有使用‘分块传输编码’的响应。如下:
HTTP/1.1 200 OKDate: Fri, 31 Dec 1999 23:59:59 GMTContent-Type: text/plainContent-Length: 42some-footer: some-valueanother-footer: another-valueabcdefghijklmnopqrstuvwxyz1234567890abcdef
Persistent Connections(持久连接)
在HTTP1.0之前,每个请求和响应完成后都会关闭TCP连接,所以每次获取都是一个单独,独立的链接。创建和关闭TCP连接花费大量的CPU资源,带宽和内存。实际操作中,组成一个网页的多个文件都是在一台服务器上。所以,多个请求和响应都可以通过一个持久连接进行传输。
HTTP1.1默认是持久连接,所以如果没有特殊的需求使用的就是持久连接。只需要建立一个连接,就是可以发送多个请求和读取返回的响应。如果你这么做,一定要注意读取响应返回的长度,以确保正确的区别他们。
如果一个客户端在请求头中声明了“Connection: close”的话,连接会在响应送达后关闭。比如,这种操作的场景:如果你知道这是这个连接的,最后一个请求。同样的,如果响应头包含这个声明,服务器会在发送完响应之后,关闭连接。所以,客户端不能通过这个链接,发送任何请求。
服务器可能在发送任何一个响应之前关闭连接。所以,客户端必须保持时刻检查Persistent Connections头的值。以确保选择的连接是通路。
100 Connections(100状态码)
客户端使用HTTP1.1协议向服务器发送请求,服务器可能返回临时响应:‘100 Coninue’。它表示服务器接收到了请求的第一部分,后面还有一些缓慢的数据传输。所以,无论如何HTTP1.1的客户端必须能正确处理‘100’状态码的响应。
返回的‘100 Continue’状态码,和我们前面说的‘200 OK’都是一样的,符合正常的响应的格式。唯一不同的是,响应的内容。如下:
HTTP/1.1 100 Continue #没有过完整的响应内容。HTTP/1.1 200 OKDate: Fri, 31 Dec 1999 23:59:59 GMTContent-Type: text/plainContent-Length: 42some-footer: some-valueanother-footer: another-valueabcdefghijklmnoprstuvwxyz1234567890abcdef
为了解决上面的这种情况(100 状态码没有数据),一个简单的HTTP1.1客户端可以通过socket读取响应;如果状态码是100,就忽略这次响应,转而读取下个响应。
HTTP1.1服务器
为了遵从HTTP1.1,服务器必须:
- 从客户端的请求中得到host头。
- 接受绝对url的请求。
- 可以接收分块传输编码。
- 支持‘持续连接’。
- 恰当的使用‘100 Continue’。
- 每个响应中包含‘Date’头。
- 能够处理‘If-Modified-Since’和‘If-Unmodified-Since’头。
- 最起码要支持‘GET’和‘HEAD’方法。
- 兼容HTTP1.0的请求。
需要Host头
每个请求,必须包含Host头,否则就会返回‘400 Bad Request’响应,如下:
HTTP/1.1 400 Bad RequestContent-Type: text/htmlContent-Length: 111<html><body><h2>No Host: header received</h2>HTTP 1.1 requests must include the Host: header.</body></html>
接受绝对地址
Host头实际上是一个过渡的解决区别host的办法。以后的HTTP版本,请求将要使用绝对地址代替路径,比如:GET http://www.somehost.com/path/file.html HTTP/1.2
HTTP1.1服务器必须接受这种格式的请求,尽管HTTP1.1客户端不发送这样的请求。如果客户端没有host头,服务器还必须要报告错误。
分块传输编码
就像HTTP1.1客户必须接受分块的响应,服务器必须接受分块的请求。服务器不需要生成,分块的信息。只要能够接受分块请求就可以了。
持久连接
如果HTTP1.1客户端通过一个连接,发送了多个请求。为了支持持久连接,服务器返回响应的顺序应该和请求的顺序是一样的。
如果过一个请求包含‘Connection: close’头,表示这是这个连接的最后一个请求,服务器需要在返回响应后关闭连接。服务器也会关闭超时闲置的连接。(通常设置10s超时)
如果你不想支持持久连接,响应头中包含‘Connection: close’。这就是表示:返回当前这个响应之后,连接就会关闭。正确的支持HTTP1.1客户端能正确的接受这个头信息。
100 Coninue
正如HTTP1.1客户端那段描述的那样,这个响应是为了处理反应慢的连接的。
当一个HTTP1.1服务器收到一个HTTP1.1请求,如果不是返回‘100 Continue’就是错误代码。如果它发送‘100 Continue’响应,那么接下来服务还会发送另外一个响应。‘100 Continue’不需要头,但是必须含有空行。如下:
HTTP/1.1 100 Continue[blank line here][another HTTP response will go here]
不要向HTTP1.0客户端发送‘100 Continue’
Date头
缓存是HTTP1.1的一个重大改善,同时离不开响应的时间戳。所以,服务器返回的每个响应,必须包含Date头,表示当前时间。格式如下:Date: Fri, 31 Dec 1999 23:59:59 GMT
除了‘1xx’的状态码的响应,所有的响应必须包括Date头。时间同一用:格林威治标准时间表示。
If-Modified-Since和If-Unmodified-Since头
避免发送不必要的资源,这样就节省了带宽。HTTP1.1定义了‘If-Modified-Since’和‘If-Unmodified-Since’请求头。用于表示:“只有在这个时间之后修改过的才发送”;客户端不需这些,但是HTTP1.1需要这些信息。
不幸的是,早期的HTTP版本,时间值的格式不统一,例如:
If-Modified-Since: Fri, 31 Dec 1999 23:59:59 GMTIf-Modified-Since: Friday, 31-Dec-99 23:59:59 GMTIf-Modified-Since: Fri Dec 31 23:59:59 1999
所以这次,HTTP统一使用格林威治标准时间表示。
尽管服务器必须接受三种时间格式,HTTP1.1客户端和服务器只能生成一种时间格式。如果没有这个头,请求将返回不成功的状态码。
If-Modified-Since头被用在GET请求上。如果请求资源在给的这段时间修改过,忽略这个头,正常的返回资源。否则返回‘304 Not Modified’响应,包含Date头,同时没有消息实体。比如:
HTTP/1.1 304 Not ModifiedDate: Fri, 31 Dec 1999 23:59:59 GMT[blank line here]
If-Unmodified-Since头和If-Modified-Since头是相似的,但是不能用于任何方法。指定的请求资源只有在字段值内指定的日期时间之后,未发生更新的情况下,才能处理请求。如果在指定日期时间后发生更新,则以状态码412 Precondition Failed作为响应返回。例如:
HTTP/1.1 412 Precondition Failed[blank line here]
支持GET和HEAD方法
HTTP1.1服务器必须支持GET和HEAD方法。如果你正在使用CGI脚本,你需要也支持POST方法。
HTTP1.1定义的其它四个方法(PUT, DELETE, OPTIONS, and TRACE),它们不经常被用到。如果客户端请求的方法,服务器不支持,则返回‘501 Not Implemented’,如下:
HTTP/1.1 501 Not Implemented[blank line here]
支持HTTP1.0请求
为了兼容老的浏览器,HTTP1.1服务器必须支持HTTP1.0请求。当一个请求使用HTTP1.0:
- 不需要Host头
- 不能发‘100 Continue’响应
结尾
这个系列的文章全部翻译完成,分别是:CGI真的很简单和HTTP真的很简单。但是我觉得还是有些欠缺的地方,应该在写一个socket真的很简单的文章,因为这些都是建立在socket通信的基础上的。我接下来的计划是这样的:
- 先通过一个实战,把这两个知识点融会贯通,真正掌握。
- 最后,视情况。补充完成整个系列的文章。我觉得要写的东西还有很多很多!
http://www.cnblogs.com/xueweihan/p/5330189.html
HTTP真的很简单(转)的更多相关文章
- HTTP真的很简单
原文:HTTP Made Really Easy因为我本身网络基础就很差,所以看到这篇文章一方面是学习网络知识,另一方面为了锻炼我蹩脚的英语水平,文中如有错误,欢迎浏览指正! 前言 在看这篇文章的时候 ...
- shell编程其实真的很简单(一)
如今,不会Linux的程序员都不意思说自己是程序员,而不会shell编程就不能说自己会Linux.说起来似乎shell编程很屌啊,然而不用担心,其实shell编程真的很简单. 背景 什么是shell编 ...
- shell编程其实真的很简单(四)
上篇我们学习了shell中条件选择语句的用法.接下来本篇就来学习循环语句.在shell中,循环是通过for, while, until命令来实现的.下面就分别来看看吧. for for循环有两种形式: ...
- zabbix真的很简单 (安装篇)
系统环境: Centos 6.4 一直觉得 zabbix 很简单,但是还是有好多人看了好多文档都搞不明白怎么用,我从2013年使用到现在也小有心得,如果时间允许,很高兴与大家一起分享我在使用过程中的一 ...
- shell编程其实真的很简单(二)
上篇我们学会了如何使用及定义变量.按照尿性,一般接下来就该学基本数据类型的运算了. 没错,本篇就仍是这么俗套的来讲讲这无聊但又必学的基本数据类型的运算了. 基本数据类型运算 操作符 符号 语义 描述 ...
- shell编程其实真的很简单(五)
通过前几篇文章的学习,我们学会了shell的基本语法.在linux的实际操作中,我们经常看到命令会有很多参数,例如:ls -al 等等,那么这个参数是怎么处理的呢? 接下来我们就来看看shell脚本对 ...
- 如果你这么去理解HashMap就会发现它真的很简单
Java中的HashMap相信大家都不陌生,也是大家编程时最常用的数据结构之一,各种面试题更是恨不得掘地三尺的去问HashMap.HashTable.ConcurrentHashMap,无论面试题多么 ...
- shell编程其实真的很简单(三)
通过前两篇文章,我们掌握了shell的一些基本写法和变量的使用,以及基本数据类型的运算.那么,本次就将要学习shell的结构化命令了,也就是我们其它编程语言中的条件选择语句及循环语句. 不过,在学习s ...
- 渗透测试实验(i春秋 真的很简单)
首先利用给的提示: 所以用户名是 ichunqiu 密码是adab29e084ff095ce3eb 可以确定一般密码都是md5的,但是这个20位 应该去掉ada b29e084ff095ce3e才是正 ...
随机推荐
- POJ 2186 Popular Cows (强联通)
id=2186">http://poj.org/problem? id=2186 Popular Cows Time Limit: 2000MS Memory Limit: 655 ...
- 百度地图 javascript相关Bug搜集
一 在手机里用百度地图js版做webapp bug集合 1 之前用2.0版本的时候发现只要地图添加了覆盖物,无论数量多少,当地图放大到很小的范围时候,会卡死 1.1 当时处理办法:将版本降低至1. ...
- (原创)(C#随笔)IEnumerable< ICollection < IList区别
public interface IEnumerable { IEnumerator GetEnumerator(); } 再看ICollection<T> public interfac ...
- Unity3d 4.3.4f1执行项目
今天.本来执行的非常快的一个项目. 忽然打开非常晚.尝试新建一个新的项目,竟然执行速度非常快. 心有不忿的,把整个Unity删除了.又一次安装. 再打开那个执行变慢的项目. 结果.执行速度回来了. 不 ...
- Oracle 验证IOT表数据存储在主键里
iot表测试: 在create table语句后面使用organization index,就指定数据表创建结构是IOT.但是在不指定主键Primary Key的情况下,是不允许建表的. create ...
- Java程序员们最常犯的10个错误(转)
1.将数组转化为列表 将数组转化为一个列表时,程序员们经常这样做: 1 List<String> list = Arrays.asList(arr); Arrays.asList(&quo ...
- What is tradebit?
The Tradebit Fact Sheet What is tradebit?
- 非对称加密RSA、Elgamal、背包算法、Rabin、D-H、ECC(椭圆曲线加密算法)等。使用最广泛的是RSA算法
非对称加密算法需要两个密钥:公开密钥(publickey)和私有密钥(privatekey).公开密钥与私有密钥是一对,如果用公开密钥对数据进行加密,只有用对应的私有密钥才能解密:如果用私 ...
- pygtk手记(1)
GTK+使用C语言开发,但是其设计者使用面向对象技术. 也提供了C++(gtkmm).Perl.Ruby.Java和Python(PyGTK)绑定,其他的绑定有Ada.D.Haskell.PHP和所有 ...
- linux它SQL声明简明教程---WHERE
我们并不一定必须注意,每次格里面的信息是完全陷入了.在很多情况下,我们需要有选择性地捕捞数据.对于我们的样本.我们可以只抓住一个营业额超过 $1,000 轮廓. 做这个事情,我们就须要用到 WHERE ...