elasticsearch的rest搜索--- 查询
目录: 一、针对这次装B 的解释
四、 查询
四、 查询
1. 查询的官网的文档
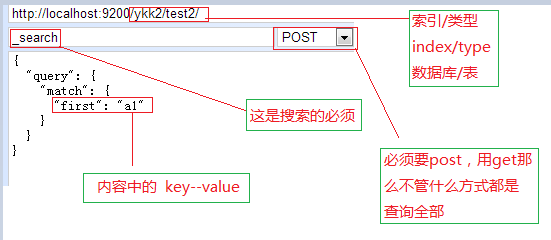
- took —— Elasticsearch执行这个搜索的耗时,以毫秒为单位- timed_out —— 指明这个搜索是否超时
- _shards —— 指出多少个分片被搜索了,同时也指出了成功/失败的被搜索的shards的数量
- hits —— 搜索结果
- hits.total —— 能够匹配我们查询标准的文档的总数目
- hits.hits —— 真正的搜索结果数据(默认只显示前10个文档)- _score和max_score —— 现在先忽略这些字段
"query":{
"match":{
"UserName":"BWH-PC"
}
}
{
"query": {
"match": {
"text": "quick fox"
}
}
}
相当于
{
"query": {
"bool": {
"should": [
{
"term": {
"text": "quick"
}
},
{
"term": {
"text": "fox"
}
}
]
}
}
}
{
"query": {
"multi_match": {
"query": "bbc0641345dd8224ce81bbc79218a16f",
"operator": "or",
"fields": [
"*.machine"
]
}
}
}
{
"bool": {
"must": {
"match": {
"title": "how to make millions"
}
},
"must_not": {
"match": {
"tag": "spam"
}
},
"should": [
{
"match": {
"tag": "starred"
}
},
{
"range": {
"date": {
"gte": "2014-01-01"
}
}
}
]
}
}
"term": {
"CapabilityDescriptions": "aa"
}
{
"query": {
"bool": {
"should": [
{
"constant_score": {
"query": {
"match": {
"description": "wifi"
}
}
}
},
{
"constant_score": {
"query": {
"match": {
"description": "garden"
}
}
}
},
{
"constant_score": {
"boost": {
"query": {
"match": {
"description": "pool"
}
}
}
}
}
]
}
}
}
missing相当于is null【没查到的是null】
{
"query": {
"filtered": {
"query": {
"match": {
"email": "business opportunity"
}
},
"filter": {
"term": {
"folder": "inbox"
}
}
}
}
}
{
"query": {
"filtered": {
"filter": {
"bool": {
"must": {
"term": {
"folder": "inbox"
}
},
"must_not": {
"query": {
"match": {
"email": "urgent business proposal"
}
}
}
}
}
}
}
}
"range": {
"price": {
"gt": 20,
"lt": 40
}
}
{
"query": {
"filtered": {
"filter": {
"range": {
"price": {
"gte": 20,
"lt": 40
}
}
}
}
}
}
{
"range": {
"timestamp": {
"gt": "2014-01-0100: 00: 00",
"lt": "2014-01-0700: 00: 00"
}
}
}
{
"range": {
"timestamp": {
"gt": "now-1h"
}
}
}
后置过滤--post_filter元素是一个顶层元素,只会对搜索结果进行过滤。警告:性能考量
只有当你需要对搜索结果和聚合使用不同的过滤方式时才考虑使用post_filter。有时一些用户会直接在常规搜索中使用post_filter。
不要这样做!post_filter会在查询之后才会被执行,因此会失去过滤在性能上帮助(比如缓存)。
post_filter应该只和聚合一起使用,并且仅当你使用了不同的过滤条件时。
{
"query": {
"query_string": {
"query": "*"
}
},
"post_filter": {
"bool": {
"should": {
"query": {
"bool": {
"should": [
{
"match": {
"machine": "bbc0641345dd8224ce81bbc79218a16f"
}
},
{
"match": {
"machine": "bbc0641345dd8224ce81bbc79218a16f"
}
}
]
}
}
}
}
}
}
当然,在里面的每一个should中,可以去做很多变形,但是should多个子类时,必须用[]
{
"query": {
"query_string": {
"query": "*"
}
},
"post_filter": {
"bool": {
"should": [
{
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "bbc0641345dd8224ce81bbc79218a16f",
"operator": "or",
"fields": [
"*.machine",
""
]
}
},
{
"multi_match": {
"query": "10.10.185.99",
"operator": "or",
"fields": [
"*.IPAddress",
""
]
}
}
]
}
}
},
{
"query": {
"bool": {
"must": [
{
"match": {
"machine": "bbc0641345dd8224ce81bbc79218a16f"
}
},
{
"match": {
"IPAddress": "10.10.11.11"
}
}
]
}
}
}
]
}
}
}


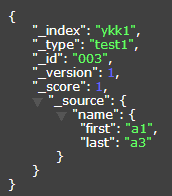
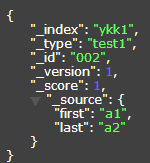
{
"query": {
"filtered": {
"query": {
"query_string": {
"query": "*"
}
},
"filter": {
"bool": {
"should": {
"query": {
"bool": {
"should": [
{
"multi_match": {
"query": "a2",
"operator": "or",
"fields": [
"*.last"
]
}
},
{
"match": {
"last": "a2"
}
}
]
}
}
}
}
}
}
}
}

elasticsearch的rest搜索--- 查询的更多相关文章
- ElasticSearch High Level REST API【2】搜索查询
如下为一段带有分页的简单搜索查询示例 在search搜索中大部分的搜索条件添加都可通过设置SearchSourceBuilder来实现,然后将SearchSourceBuilder RestHighL ...
- ElasticSearch第四步-查询详解
ElasticSearch系列学习 ElasticSearch第一步-环境配置 ElasticSearch第二步-CRUD之Sense ElasticSearch第三步-中文分词 ElasticSea ...
- ElasticSearch中的简单查询
前言 最近修改项目,又看了下ElasticSearch中的搜索,所以简单整理一下其中的查询语句等.都是比较基础的.PS,好久没写博客了..大概就是因为懒吧.闲言少叙书归正传. 查询示例 http:// ...
- ElasticSearch(8)-分布式搜索
分布式搜索的执行方式 在继续之前,我们将绕道讲一下搜索是如何在分布式环境中执行的. 它比我们之前讲的基础的增删改查(create-read-update-delete ,CRUD)请求要复杂一些. 注 ...
- ElasticSearch(6)-结构化查询
引用:ElasticSearch权威指南 一.请求体查询 请求体查询 简单查询语句(lite)是一种有效的命令行_adhoc_查询.但是,如果你想要善用搜索,你必须使用请求体查询(request bo ...
- ElasticSearch改造研报查询实践
背景: 1,系统简介:通过人工解读研报然后获取并录入研报分类及摘要等信息,系统通过摘要等信息来获得该研报的URI 2,现有实现:老系统使用MSSQL存储摘要等信息,并将不同的关键字分解为不同字段来提供 ...
- elasticsearch基本概念与查询语法
序言 后面有大量类似于mysql的sum, group by查询 elk === elk总体架构 https://www.elastic.co/cn/products Beat 基于go语言写的轻量型 ...
- Graylog日志管理系统---搜索查询方法使用简介
Elasticsearch 是一个基于 Lucene 构建的开源.分布式.提供 RESTful 接口的全文搜索引擎 一.Search页面的各位置功能介绍: 1.日志搜索的时间范围 为了使用方便,预设有 ...
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
随机推荐
- 升级iOS8系统后,保险箱Pro、私人保险箱、私密相冊打开就闪退的官方解决方式
升级iOS8系统后,保险箱Pro.私人保险箱.私密相冊打开就闪退的官方解决方式 写在前面的话: 1. 本文适用条件 适用于:您的保险箱Pro.私人保险箱.私密相冊在iPhone或iPad ...
- 【剑指offer】删除字符也出现在一个字符串
转载请注明出处:http://blog.csdn.net/ns_code/article/details/27110873 剑指offer上的字符串相关题目. 题目:输入两个字符串,从第一字符串中删除 ...
- 于win7使用虚拟磁盘隐藏文件
于win7使用虚拟磁盘隐藏文件,我只是win7在验证.其他型号未知. 一.创建虚拟磁盘 1.右键点击"计算机"-----"管理" ------"磁盘管 ...
- 新手学Unity3d的一些网站及相应学习路线
一.unity3d有什么优势 如果您对开发游戏感兴趣,而又没有决定选择哪一个游戏引擎,别犹豫了 unity3d是一个很好的选择! 就我来看unity3d优势主要有以下几方面:首先部署简单,自带了一个I ...
- [渣译文] SignalR 2.0 系列: SignalR 自托管主机
原文:[渣译文] SignalR 2.0 系列: SignalR 自托管主机 英文渣水平,大伙凑合着看吧…… 这是微软官方SignalR 2.0教程Getting Started with ASP.N ...
- 【从翻译mos文章】不再用par file如果是,export or import 包含大写和小写表名称表
不再用par file如果是,export or import 包含大写和小写表名称表 参考原始: How to Export or Import Case Sensitive Tables With ...
- WINDOWS7,8和os x yosemite 10.10.1懒人版双系统安装教程
安装过程 磁盘划分 懒人版如果不是整盘单系统或者双硬盘双系统安装我们需要在当前系统磁盘划分两块磁盘空间,一个用来做安装盘,一个作为系统盘. 我这里是单硬盘,想从最后一个盘符压缩出80GB的空来安装黑苹 ...
- TextView于getCompoundDrawables()使用演示样本的方法
MainActivity例如下列: package cc.testcompounddrawables; import android.app.Activity; import android.grap ...
- port大全及port关闭方法
在网络技术中,port(Port)大致有两种意思:一是物理意义上的port,比方,ADSL Modem.集线器.交换机.路由器用于连接其它网络设备的接口,如RJ-45port.SCport等等.二是逻 ...
- 一个轻量级rest服务器
RestServer直接发布数据库为json格式提供方法 RestSerRestServer直接发布数据库为json格式 支持MySQL,SqlServer,Oracle直接发布为Rest服务, 返回 ...