4.kafka API producer
1.Producer流程
首先构建待发送的消息对象ProducerRecord,然后调用KafkaProducer.send方法进行发送。KafkaProducer接收到消息后首先对其进行序列化,然后结合本地缓存的元数据信息一起发送给partitioner去确定目标分区,最后追加写入到内存中的消息缓冲池(accumulator)。此时KafkaProducer.send方法成功返回。同时,KafkaProducer中还有一个专门的Sender IO线程负责将缓冲池中的消息分批次发送给对应的broker,完成真正的消息发送逻辑。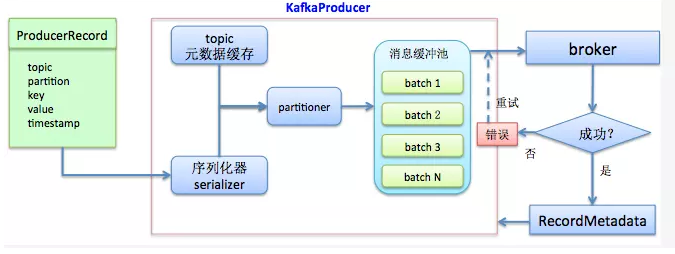
2.API 实现
2.1创建topic
bin/kafka-topics.sh --create --zookeeper h201:2181,h202:2181,h203:2181 --replication-factor 2 --partitions 3 --topic topic11
2.2创建 producer
[hadoop@h201 kkk]$ vi cp.java
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class cp {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers", "h201:9092,h202:9092,h203:9093");//kafka集群,broker-list
props.put("acks", "all");
props.put("retries", 1);//重试次数
props.put("batch.size", 16384);//批次大小
props.put("linger.ms", 1);//等待时间
props.put("buffer.memory", 33554432);//RecordAccumulator缓冲区大小
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++) {
producer.send(new ProducerRecord<String, String>("topic11", Integer.toString(i), Integer.toString(i)));
}
producer.close();
}
}
[hadoop@h201 kkk]$ /usr/jdk1.8.0_144/bin/javac -classpath /home/hadoop/kafka_2.12-0.10.2.1/libs/kafka-clients-0.10.2.1.jar cp.java
[hadoop@h201 kkk]$ /usr/jdk1.8.0_144/bin/java cp
代码解释:
3.1Properties类
继承于 Hashtable.表示一个持久的属性集.属性列表中每个键及其对应值都是一个字符串。
类中properties是配置文件,主要的作用是通过修改配置文件可以方便的修改代码中的参数,实现不用改class文件即可灵活变更参数。
3.2KafkaProducer类
用于向kafka集群发布消息记录,其中<K, V>为泛型,指明发送的消息记录key/value对的类型。
kafka producer(生产者)是线程安全的,多个线程共享一个producer实例,相比于多个producer实例,这样做的效率更高、更快。
从上述构造函数可以看出,可以通过Map和Properties两种形式传递配置信息,用于构造Producer对象,配置信息均为key/value对。
kafka的包org.apache.kafka.common.serialization中,提供了许多已经实现好的序列化和反序列化的类,可以直接使用。你也可以实现自己的序列化和反序列化类(实现Serializer接口),选择合适的构造函数构造你的Producer类。
方法: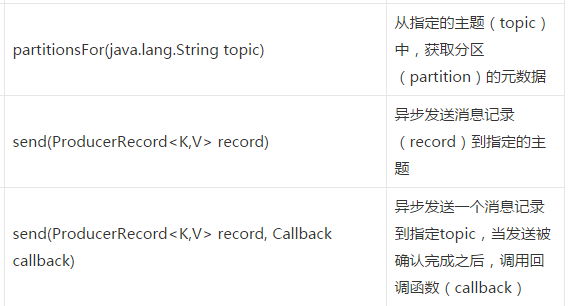
3.3 ProducerRecord
消息记录,记录了要发送给kafka集群的消息、分区等信息
topic:必须字段,表示该消息记录record发送到那个topic。
value:必须字段,表示消息内容。
partition:可选字段,要发送到哪个分区partition。
key:可选字段,消息记录的key,可用于计算选定partition。
timestamp:可选字段,时间戳;表示该条消息记录的创建时间createtime,如果不指定,则默认使用producer的当前时间。
headers:可选字段,(作用暂时不明,待再查证补充)。
4.kafka API producer的更多相关文章
- 【Kafka】Producer API
Producer API Kafka官网文档给了基本格式 地址:http://kafka.apachecn.org/10/javadoc/index.html?org/apache/kafka/cli ...
- Kafka实战系列--Kafka API使用体验
前言: kafka是linkedin开源的消息队列, 淘宝的metaq就是基于kafka而研发. 而消息队列作为一个分布式组件, 在服务解耦/异步化, 扮演非常重要的角色. 本系列主要研究kafka的 ...
- Kafka学习-Producer和Customer
在上一篇kafka入门的基础之上,本篇主要介绍Kafka的生产者和消费者. Kafka 生产者 kafka Producer发布消息记录到Kakfa集群.生产者是线程安全的,可以在多个线程之间共享生产 ...
- Kafka: Producer (0.10.0.0)
转自:http://www.cnblogs.com/f1194361820/p/6048429.html 通过前面的架构简述,知道了Producer是用来产生消息记录,并将消息以异步的方式发送给指定的 ...
- Kafka生产者producer简要总结
Kafka producer在设计上要比consumer简单,不涉及复杂的组管理操作,每个producer都是独立进行工作的,与其他producer实例之间没有关联.Producer的主要功能就是向某 ...
- [Kafka] - Kafka Java Producer代码实现
根据业务需要可以使用Kafka提供的Java Producer API进行产生数据,并将产生的数据发送到Kafka对应Topic的对应分区中,入口类为:Producer Kafka的Producer ...
- Kafka API操作
Kafka API实战 环境准备 在eclipse中创建一个java工程 在工程的根目录创建一个lib文件夹 解压kafka安装包,将安装包libs目录下的jar包拷贝到工程的lib目录下,并buil ...
- kafka api的基本使用
kafka API kafka Consumer提供两套Java API:高级Consumer API.和低级Consumer API. 高级Consumer API 优点: 高级API写起来简单,易 ...
- 一文详解Kafka API
摘要:Kafka的API有Producer API,Consumer API还有自定义Interceptor (自定义拦截器),以及处理的流使用的Streams API和构建连接器的Kafka Con ...
随机推荐
- java算法 -- 基数排序
基数排序(英语:Radix sort)是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较.由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排 ...
- springboot 整合mongodb
Mongodb Mongodb是为快速开发互联网Web应用而构建的数据库系统,其数据模型和持久化策略就是为了构建高读/写吞吐量和高自动灾备伸缩性的系统. 在pom.xml中添加相关依赖 <!-- ...
- ubuntu下MySQL忘记密码重置方法
方法一: 1):编辑mysqld.cnf文件 sudo vi /etc/mysql/mysql.conf.d/mysqld.cnf 2):在文件中的skip-external-locking一行的下面 ...
- tensorflow2.0手写数字识别
import tensorflow as tf import matplotlib.pyplot as plt import numpy as np datapath = r'D:\data\ml\m ...
- 使用 Fiddler 代理调试本地手机页面
文件下载:http://files.cnblogs.com/files/dtdxrk/fiddler4_4.6.2.0_setup.rar 从事前端开发的同学一定对 Fiddler 不陌生,它是一个非 ...
- python json dumps datetime类型报错
# -*- coding: utf-8 -*- import json from datetime import date, datetime class MyEncoder(json.JSONEnc ...
- AOP+Redis锁防止表单重复提交
确保分布式锁同时满足以下四个条件 1.互斥性.在任意时刻,只有一个客户端能持有锁 2.不会发生死锁.即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁 3.具有容错性.只要 ...
- [转帖]Linux教程(14)- Linux中的查找和替换
Linux教程(14)- Linux中的查找和替换 2018-08-22 07:03:58 钱婷婷 阅读数 46更多 分类专栏: Linux教程与操作 Linux教程与使用 版权声明:本文为博主原 ...
- Docker部署ELK 7.0.1集群之Elasticsearch安装介绍
elk介绍这里不再赘述,本系列教程多以实战干货为主,关于elk工作原理介绍,详情查看官方文档. 一.环境规划 主机名 IP 角色 节点名 centos01 10.10.0.10 es node-10 ...
- RabbitMQ延迟消息队列实现定时任务完整代码示例