人工智能头条(公开课笔记)+AI科技大本营——一拨微信公众号文章
不错的 Tutorial:
从零到一学习计算机视觉:朋友圈爆款背后的计算机视觉技术与应用 | 公开课笔记
分享人 | 叶聪(腾讯云 AI 和大数据中心高级研发工程师)
整 理 | Leo
出 品 | 人工智能头条(公众号ID:AI_Thinker)
刚刚过去的五四青年节,你的朋友圈是否被这样的民国风照片刷屏?用户只需要在 H5 页面上提交自己的头像照片,就可以自动生成诸如此类风格的人脸比对照片,简洁操作的背后离不开计算机视觉技术和腾讯云技术的支持。
那么这个爆款应用的背后用到了哪些计算机视觉技术?掌握这些技术需要通过哪些学习路径?
5 月 17 日,人工智能头条邀请到腾讯云 AI 和大数据中心高级研发工程师叶聪,他以直播公开课的形式为大家解答了这些问题,
人工智能头条将主要内容整理如下:
▌一、朋友圈爆款活动介绍
大家经常在朋友圈看到一些很有趣的跟图像相关的小游戏,包括以前的军装照以及今年五四青年节的活动。这个活动非常有意思,大家可以选择一张自己觉得拍的最美的照片,然后上传到 H5 的应用里面,我们就会帮你匹配一张近现代比较优秀的青年照片。那张照片是老照片,而大家上传的是新照片,这就产生了一些比较有意思的对比,这个活动今年也是得到了强烈的反响,大家非常喜欢。
所有的这些算法构建完以后,我们把它上传到了腾讯云的 AI 大平台上去。因为我们参照了去年军装照的流量,所以这次活动我们预估了 5 万 QPS,这其实是很高的一个要求。该活动 5 月 4 日上线,截止 5 月 5 日下线,在短短两天内,在线 H5 页面的 PV 达到了 252.6 万,UV 111.3 万,服务调用量 420 万,还是比较惊人的。
▌二、计算机视觉基础知识
首先计算机视觉是什么?计算机视觉研究如何让计算机从图像和视频中获取高级和抽象信息。从工程角度来讲,计算机视觉可以使模仿视觉任务自动化。
一般来说计算机视觉包含以下分支:
物体识别
对象检测
语义分割
运动和跟踪
三维重建
视觉问答
动作识别
这边额外提一下语义分割,为什么要提这个呢?因为语义分割这个词也会在包括 NLP、语音等领域里出现,但是实际上在图像里面分割的意思跟在语音和 NLP 里面都很不一样,它其实是对图像中间的不同的元素进行像素级别的分割。比如最右下角这张图片,我们可以看到行人、车辆、路,还有后面的树,他们都用不同的颜色标注,其实每一种颜色就代表了一种语义。左边和中间的两幅图,可能我不用介绍,大家也应该能猜到了,一个是人脸识别,一个是无人驾驶,都是现在使用非常广泛和热门的应用。
如何让机器可以像人一样读懂图片?人在处理图像的时候,我们是按照生物学的角度,从图像到视网膜然后再存储到大脑。但机器没有这套机制,那机器如何把图片装载到内存里面?这个就牵扯到一个叫 RGB-alpha 的格式。
顾名思义,就是红绿蓝三色,然后,alpha 是什么?如果大家在早期的时候玩过一些电脑硬件,你可能会发现,最早期的显卡是 24 位彩色,后来出现一个叫 32 位真彩色,都是彩色的,有什么不同吗?因为在计算机领域,我们用 8 位的二进制去表示一种颜色,红绿蓝加在一起就是 24 位,基本上我们把所有颜色都表示出来了。
为什么还出现 alpha?alpha 是用来表示一个像素点是不是透明的,但并不是说 alpha 是 1 的时候它就是透明,是 0 的时候就不透明。只是说阿尔法通道相当于也是一个矩阵,这个矩阵会跟 RGB 的其他的矩阵进行一种运算,如果 alpha 的这个点上是 1,它就不会影响 RGB 矩阵上那个点的数值,它就是以前原来的颜色,如果是 0,这个点就变成透明的。这也是我们怎么用 RGB 加 alpha 通道去描述世界上所有的图片的原理。
比如右上角,这张图片是黑白图,中间是彩色图,下面一张是有些透明效果,右下角基本上没有像素点,这就是一个很好的例子,去理解 RGB 是怎么一回事。
除了 RGB-alpha 这种表达方式,我们还有很多不同的颜色表达方式。包括如果我们搞印刷的话,大家可能接触到另外一种色系,叫 CMYK,这个也是一种颜色的表示方式。这边还会有一些其他类型的图片,包括红外线图片,X 光拍摄的图片,红外热成像图,还有显微镜拍摄的细胞图,这些加在一起都是我们计算机可以处理的图像的范围,不仅仅是我们之前看到,用手机、摄像机拍摄的图片。
我们在计算机视觉中经常会提到 stages,为什么叫 stages?
这边我们看到,有 Low level,Mid level,High level,这里澄清一下,并不是说 Low Level 这些应用就比较低级,High level 就比较高端,这个描述的维度其实是从我们看问题的视野上来说的,Low level 代表我们离这个问题非常近,High level 代表比较远。
举一个简单例子,比如 Low Level 上面我们可以做图像的降噪、优化、压缩、包括边缘检测,不管是哪一条,我们都是可以想象一下,我们是离这个图片非常近的去看这个细节。High level 是什么?包括情景理解、人脸识别、自动驾驶,它基本上是从一个比较远的角度来看这个大局。
所以其实大家可以这么想,在解决问题的时候,我们要离图片的视觉大概保持多远的距离,High 代表比较远,Low 代表比较近,并不是说 High 比 Low 要难,或者说要高端。
Mid level 介于 High 跟 Low 之间的,包括分类、分割、对象检测,后面还有情景分割,这边的情境分割跟分割还不太一样,应该说是更深度的分割问题,后面我会详细解释。
这边有一些例子是帮大家去理解 Low level Processing。比如左上那张是我们拍 X 光会看到的图,上面那张图是原始的 X 光的图片,大家可以看到,非常的不清晰,很难去理解到里面的骨骼,血管在什么位置。但通过 Low Level Processing 的降噪和优化,就能非常清晰的看到这个病人的所有的骨骼及内脏的位置。
中间这个是一个 PCB 板,一些工业领域为了检测 PCB 板就会拍摄照片,做图像处理,并用这种方式去找到板上的一些问题,然后去修复它。有的时候也为了质量品控,看到中间这张的 PCB 板原始的图片上面充满了噪音,经过优化、降噪以后就得到一张很清晰的照片。
这个是 Mid level Processing,目前这块的技术比较成熟。这块的应用包括分类、分割、目标检测,也包括情景检测、情景分割,甚至还有意图检测,就是通过看图片里面的一些物体和他们目前在做的一些行为来判断他们的意图。
底下有几张小猫咪和小狗的图,从左到右是一个进阶的方向。首先最容易想到的一个应用,就是怎么能用机器学习的方法读懂一张图片里面的内容,那这个方法如何去实现它呢?其实就是用了一个分类,因为左边那张图片如果给了机器,分类算法会告诉你里面有一只猫,但是仅此而已。
那如果我们想知道,这里面有只猫,但这只猫在哪里呢?这个问题,我们就需要在这个基础上加上定位,也就是第二张图片,那我们就可以定位到,原来这里是猫咪所在的范围,只是在这个方框范围内,并没有精确到像素级别。
再进一步,如果这张图片里面不仅仅有猫,可能会有很多其他的东西,我希望把所有的东西都标识出来,应该怎么办?这个任务叫做叫对象检测,就是把图片里面所有的这些对象全部标注检测出来。
再进一步,我不但想把里面的对象全部标注出来,我还要精确的知道,它们在图像的什么位置,这种情况下我可能想把它们剥离出来,把背景去掉。一般情况下,这种被我们框出来的对象叫做前景,其他的这些部分叫做后景。我们如果想把前景弄出来,那我们就需要这种对象分割的技术,从左到右,我们就完成了分类、定位、检测、对象分割的全部流程,从头到尾也是一个慢慢晋升的过程。因为定位是需要分类的基础的,对象检测是需要有分类基础的,情景分割也需要有检测的基础,它是一个由浅入深的一个过程。
最右边就是一个情景分割的例子,之前我也简单介绍过,现在的技术已经可以精确的把我们这张图片上的几乎所有的元素很精确的给分出来,包括什么是人、车、路、景色、植物、大楼等全部都能分出来,我们的技术目前在 Mid level Processing 这块已经很成熟了。
接下来简单介绍一下 High level Processing,也是目前非常热门和有前景,但是应该说远远还未达到成熟的技术。可能目前,大家做最好的 High level Processing 就是人脸检测。
左下角那张是无人驾驶,也可以叫做高智能的辅助驾驶,不同的车厂,不同的定义,基本上就是对象检测的一个复杂应用,包括检测到路上的所有情况,包括不同的地上标识,周围的建筑,还有在你前面的所有车辆,甚至行人,各种信息,还包括跟他们的距离,它是一个相对来说多维度的,是个复杂的对象检测的应用。
中间的是两个小朋友在打网球,这张图片也是两个人物,跟之前Mid level Processing有什么区别吗?其实从右边那个对象树上,我们就能判断,它是对这个图片理解的深度有了非常本质的区别。前一个那个例子,我们知道图片上有猫有狗,仅此而已。而这张图片上,我们除了判断到,图片上有两个孩子以外,还对他们的各种穿着,都进行了精确的分割和定义,包括他们手上的这些持有的球拍,我们都有个非常详细的描述,所以High level图像的理解并不是简单的说有哪些东西,而是他们之间的联系、细节。High level本身不仅能识别我们的图上有什么东西,它还能识别,应该做什么,他们的关系是什么。
右边那张图片是一个医学的应用,一个心血管的虚拟图。它是英国皇家医学院跟某个大学合作的一个项目,我们通过计算机视觉去模拟一个病人的心血管,帮助医生做判断,是否要做手术,应该怎么去做手术方案,这个应该是计算机视觉在医学上的很好的一个应用的例子。
这里有一些比较常见的计算机视觉的应用,平时我们也会用到,包括多重的人脸识别,现在有些比较流行的照片应用,不知道大家平时会不会用到,包括比如像 Google photos,基本上传一张照片上去,它就会对同样的照片同样的人物进行归类,这个也是目前非常常见的一个应用。
中间那个叫 OCR,就是对文本进行扫描和识别,这个技术目前已经比较成熟了。照片上这张是比较老的技术,当时我记得有公司做这个应用,有个扫描笔,扫描一下就变成文字,现在的话,基本上已经不需要这么近的去扫描了,大家只要拍一张照片,如果这张照片是比较清晰的,经过一两秒钟,一般我们现在算法就可以直接把它转换成文字,而且准确率相当高,所以图片上的这种 OCR 是一个过时的技术。
右下角是车牌检测,开车的时候不小心压到线了,闯红灯了,收到一张罚单,这个怎么做到呢?也是计算机视觉的功劳,它们可以很容易的就去识别这个照片里的车牌,甚至车牌有一定的污损,经过计算机视觉的增强都是可以把它给可以优化回来的,所以这个技术也是比较实用的。
下面聊几个比较有挑战性的计算机视觉的任务。首先是目标跟踪,目标跟踪就是我们在连续的图片或者视频流里面,想要去追踪某一个指定的对象,这个听起来对人来说是一个非常容易的任务,大家只要目不转睛盯着一个东西,没有人能逃脱我们的视野。
实际上对机器来说,这是一个很有挑战性的任务,为什么呢?因为机器在追踪对象的时候,大部分会使用最原始的一些方法,采取一些对目标图片进行形变的匹配,就是比较早期的计算机识别的方法,而这个方法在实际应用中间是非常难以实现的,为什么?因为需要跟踪的对象,它由于角度、光照、遮挡的原因包括运动的时候,它会变得模糊,还有相似背景的干扰,所以我们很难利用模板匹配这种方法去追踪这个对象。一个人他面对你、背对你、侧对你,可能景象完全不一样,这种情况下,同样一个模板是无法匹配的,所以说,很有潜力但也很有挑战性,因为目前对象追踪的算法完全没有达到人脸识别的准确率,还有很多的人在不断的努力去寻找新的方法去提升。
右边也是一个例子,就是简单的一个对我们头部的追踪,也是非常有挑战性的,因为我们头可以旋转,尺度也可能发生变化,用手去遮挡,这都给匹配造成很大的难度。
后面还有一些比较有挑战性的计算机视觉任务,我们归类把它们叫做多模态问题,其中包括 VQA,这是什么意思?这个就是说给定一张图片,我们可以任意的去问它一些问题,一般是比较直接的一些问题,Who、Where、How,类似这些问题,或者这个多模态的模型,要能够根据图片的真实信息去回答我们的问题。
举个例子,比如底下图片中间有两张是小朋友的,计算机视觉看到这张图片的时候它要把其中所有的对象全部分割出来,要了解每个对象是什么,知道它们其中的联系。比如左边的小朋友在喝奶,如果把他的奶瓶分出来以后,它必须要知道这个小朋友在喝奶,这个关系也是很重要的。
屏幕上的问题是“Where is the child sitting?”,这个问题的复杂度就比单纯的只是解析图像要复杂的多。他需要把里面所有信息的全部解析出来,并且能准确的去关联他们的关系,同时这个模型还要能够理解我们问这个问题到底是什么个用意,他要知道问的是位置,而且这个对象是这个小孩,所以这个是包含着计算机视觉加上自然语言识别,两种这种技术的相结合,所以才叫多模态问题,模态指的是像语音,文字,图像,语音,这种几种模态放在一起就叫多模态问题。
右边一个例子是 Caption Generation,现在非常流行的研究的领域,给定一张图片,然后对图片里面的东西进行描述,这个还有一些更有趣的应用,待会我会详细介绍一下。
▌三、曾经的图像处理——传统方法
接下来我们聊一聊,过去了很多年,大家积累的传统的计算机视觉的图像处理的方法。
首先提到几个滤波器,包括空间滤波器,傅里叶、小波滤波器等等,这些都是我们经常对图像进行初期的处理使用的滤波器。一般情况下,经过滤波以后,我们会对图像进行 Feature Design,就是我们要从图片中提取一些我们觉得比较重要的,可以用来做进一步的处理的一些参照的一个信息,然后利用信息进行分类,或者分割等等,这些应用,其中一些比较经典的一些方法,包括 SIFT、Symmetry、HOG,还有一些就是我们分类会经常用到的一个算法,包括 SVM,AdaBoost,还有 Bayesian 等等。
进一步的分割还有对象检测还有一些经典算法,包括 Water-shed、Level-set、Active shape 等。
首先我们做 Feature Design,提取一个图片中间对象的特点,最简单能想到的方法,就是把这个对象的边缘给分离出来,Edge Detection 也确实是很早期的图像信息提取方法。
举个例子,硬币包括上面的图案,都会经过简单的 Edge Detection 全部提取出来,但实际上Edge Detection 在一些比较复杂的情况上面,包括背景复杂的情况下,它是会损失很多信息的,很多情况下我们看不到边缘。
这样情况下大家还想出另外一个方法叫 Local Symmetry,这种方法是看对象重心点,利用重心点去代表着这个图像的一些特征。
这个叫 Haar Feature,相当于结合了前面边缘特征,还有一些其他的一些特征的信息。Haar Feature 一般分为三类
边缘特征
线性特征
中心对角线特征
通过处理,把图片中所有的边缘信息提取出来以后,就会对图片整理获得一个特征模板,这个特征模板由白色和黑色两种矩形组成,一般情况下定义模板的特征值为白色的矩形像素和减去黑色像素矩形像素和。Haar Feature 其实是反映了图像的一个灰度变化的情况,所以脸部的一些特征,就可以用矩形的模板来进行表述,比如眼睛要比脸颊颜色要深,鼻梁两侧比鼻梁颜色要深,嘴巴比周围颜色深等等。我们利用这些矩形就对图像的一些细节进行了提取。
SIFT 尺度不变特征变换,当对象有角度、特征位置的变化时,我们如何去持续的能够知道它们是同样的一个东西,这个就要利用到 SIFT。SIFT 是一种局部检测的特征算法,这个算法是通过求图片中的一些特征点,对图像进行匹配,这是非常老的一个算法,大概在 2000 年时候就提出来了,目前已经是一个常用的非深度学习的一个图像的一种匹配的算法。
另外一个比较流行的方法叫 HOG 方向梯度直方图,比如像这张图片上显示,在图像中间,局部目标的表象和形状能够对灰度的梯度、还有边缘方向的密度有很好的表示。比如像这张图像,人身上的梯度就是向着上下方向。而对于背景,由于背景光的原因,如果我们做灰度的分析,会发现它的梯度是偏水平方向的,利用这种方式我们就很容易的可以把背景跟前景进行分割。另外如果很多小框里的梯度方向几乎一致的话,我们就可以认为它是一个对象,这个方法是很好的可以塑造一个分割的效果。实际上很早期的目标检测就是 Feature Design,所以说检测是基于分类的,也是这个意思。现在深度学习引入以后,很多理论也发生了一些变化,待会详细介绍一下。
这个也是一个非常经典的分割方法,叫分水岭算法,就是把这个图像想象成一个地理上的地形图,然后我们对其中的各个山谷非常无差别的统一往里面放水,总会有一些山谷先被填满漫出来,那我们为了阻隔他们水流的流动就要建一些这种堤坝,这也是分水岭算法的名字的由来。利用这种方式,我们建坝的地方就是很好的一个图像的分割的这种界线,大家可以想象一下,把左边这张图和右边的边界联系起来,就会理解到这个算法是个非常巧妙的事。
常规的分水岭算法还是有些缺点的,比如由于图像上的一个噪音,经常会造成局部的一些过度分割,也会有一些图像中的部分元素因为颜色相近不会被分割出来,所以经常会出现一些误判,这也是分水岭算法的一些局限性。
ASM,中文名叫可变模板匹配,或者叫主观形状模型。这个翻译听起来都怪怪的,其实很好理解,它是对人脸上的一些特征进行提取,采用的方式是在人脸上寻找一些边角的地方进行绘点,一般绘制大概 68 个关键特征点。然后利用这些特征点,我们去抽取一个原始的模型出来。
原始的模型抽出来之后,是不是能直接用呢?没有那么简单,因为人脸有可能会由于角度变化会发生一些形变,如果只是单纯的对比这 68 个点,是不是在新的图片上面还有同样的位置,大部分情况都是 No。这时我们要对这些特征点进行一些向量的构建,我们把那 68 个点提取出来,把它向量化,同时我们对我们需要比对的点,比对的那个脸部也进行同样的工作,也把它向量化。然后我们对原始图片上的这种向量点和新图片上的点进行简单化匹配,可以通过旋转缩放水平位移,还有垂直位移这种方式,寻找到一个等式,让它们尽量的相等,最后优化的不能再优化的时候,就去比较阈值的大小,如果它小于某个阈值,这样人脸就能匹配上,这个想法还是比较有意思的。
另外,在这里由于 68 个点可能比较多,很久以前我们的这种计算机的性能可能没有那么好,也没有 GPU,我们如果写的时候为了提高匹配的速度,就要想个办法去降低需要比对特征点的量,这个时候引出一个比较著名的算法叫主成分分析,利用这个 PC,我们会做降维,比如一些没有太大意义的点可以去掉,减少数据量,减少运算量,提高效果,当然这并不是必须的,它只是一个提升 ASM 实际效能的加分办法。
▌四、图像处理的爆发——深度学习方法
然后接下来我们就聊一聊现在非常热门,未来也会更加热门的图形学的深度学习方法。下面有两个深度学习的网络,所谓的深度学习实际就是深度神经网络,叫深度神经网络大家更容易理解。左边那个是一个两层的神经网络,这里要解释一下,我们一般说神经网络的层数是不算输入层的,两层就是包括一个输入层,一个隐层,和一个输出层。所以有的时候,如果我们提到了一个单层网络,其实就是只有输入层和输出层,大家知道这种情况下面的浅度神经网络是什么?它就是我们传统的机器学习里非常经典的逻辑回归和支持向量机。
这时候你会发现,深度学习并没有那么遥不可及,它其实跟我们传统的一些方法是有联系的。它只是多重的一种包装,或者组合强化,然后反复利用,最后打包成了一个新的机器学习的方法。
图上有两个神经网络,其中有些共同点,首先他们都有一个输入层,一个输出层。这个就是所有的神经网络必须的,中间的隐层才是真正的不同的地方,不同的网络为了解决不同的问题,它就会有不同的隐层。
这个是对多重人脸识别设计的一个深度神经网络,我们可以看到输入层中间会做一些预处理,包括把图片转换成一些对比度图。第一个隐层是 Face Features,从人脸上提取关键的特征值。第二个隐层就是开始做特征值匹配,最后的输出层就是对结果进行输出,一般就是分类。
除了刚才我们看到的典型神经网络,还会有其他各式各样的网络?有三角形,也有矩形的,矩形中间还有菱形的。神经网络出现了以后,改变了大家的一些工作方式。之前,大部分机器学习的科学家是去选择模型,然后选择模型优化的方式。到了深度学习领域,大家考虑的是我们使用什么网络来实现我们的目的,实际上还是区别比较大的。
CNN,也就是卷积神经网络,它是目前应用最广泛的图像识别网络,了解 CNN 会对了解其他网络有很大的帮助,所以把这个作为例子。
这个例子中我们做了一个手写识别,这里包含输入层、输出层,还有卷积层、池化层。一般情况下,不仅仅做一次卷积,我们还会多次的做卷积,池化然后再卷积,利用这种方式去多次的降维,池化层其实在这个卷积神经网络中起一个作用,就是降低我们数据的维度。
最后会有一个叫全连接层,它是个历史遗留物,现在大家其实慢慢的也在减少使用全连接层,全连接层一般情况下,它的作用就是对前面的各种池化卷积最后的结果进行一个归类。而实际上现在深度学习比较讲究端对端学习,又讲究效率比较高,这种情况下面,有的时候全连接层的意义就不是那么大,因为这个分类有可能在卷积的时候就把它做了,其实这个里面还是有很多的可以提升的地方。
再举一个例子,目前比较流行的做图像分割的还有很多基于 CNN 的新网络。比如在 CNN 基础上大家又加入了一个叫 Region Proposal Network 的东西,利用它们可以去优化传统 CNN 中间的一些数据的走向。Faster-RCNN 不是一蹴而就的,它是从RCNN中借鉴了 SPPNET 的一些特性,然后发明了 Fast-RCNN,又在 Fast-RCNN 的基础上进一步的优化变成了 Faster-RCNN。
大家能看到,神经网络也不是一成不变的,它也是不断在进化的,而我们最开始想到用神经网络去解决图像问题的时候,是由于什么原因?是由于当时我们在尝试去用 CNN 去做图像检测的时候发现了很大的困难,效果不好,这时就有非常厉害的科学家想了,我们可不可以把一个非常典型的检测问题变为分类问题,因为 CNN 用来解决分类问题是非常有效的,所以就会出现很多的这样的转换应用。我上面写的每一个网络都是一篇非常伟大的论文,所以大家如果有兴趣,我课后可以分享一下。
目前除了 Faster-RCNN,还有一个应用效果非常好的一个网络结构,叫 YOLO,它也是在 Faster-RCNN 上面,已经不仅仅是进行了优化,而是改变了它的思维模式。最开始,我们觉得检测如果转化成分类会效果更好,后来发明 Faster-RCNN 的这个科学家觉得,有的时候可能还是用回归的方式去解决目标检测的问题效果会更好,他最后就搬出了 YOLO 这种新的神经网络框架,从而重新返回到了用回归的方式去解决目标检测问题的方式上来。
有的时候也并不是说解决同样一个问题是有不同方法,也并不是说在一条路上一直走到黑是最好,换个思维方式,在硬件和软件条件达到一个新的层次的时候,有些已经用不了的技术现在就能用了,深度学习就是这么来的。
我们再聊一聊深度学习图像应用的案例,比如说我们提到的这个五四青年节活动,它是怎么样去设计的。首先呢,我们会有一些图片的训练数据,然后在进入模型之前,我们会对数据进行向量化,通过数据向量化,我们就可以得到一个模型,然后得到一个分类,和一个 score,这边的 score 只是模型对这种结果一个相对的分析,一般我们会选择 score 最高的一个分类,然后前端会从这个分类中间选择图片,生成H5的这个结果,大家就可以看到跟哪位历史上的有名的青年相似了。
第二个也是多模态的例子,根据一张图片去讲一个浪漫的故事,当时我们有这个想法的原因是,我们知道现在已经有看图出文字描述的技术,那我们能不能进一步的,让图片可以讲故事。这样的话,这个应用就可以帮助家里有小宝宝的人群。除了图像识别以外,我们还进行了一些意图的分析。
在另一方面,我们会使用一个浪漫小说的数据库,对另外一个模型进行训练。最后,我们根据这个图片里面这些关健词和它的意图去匹配浪漫小说中间的文段,把有关的文段全部拿出来,拿出来这些文段有的是不成文章的,所以要进行下一轮的匹配,把这些文段中间的关键词再去进一步的在小说库里面去匹配,成段的文字,这就实现了一个 storyteller。
这个项目除了最先我们对图像里面的对象识别过程使用的是监督学习,其他的都是非监督学习。这个系统是可以自然的去套用到很多不同的地方,只要换个不同的文章数据库,它就可以讲不同的故事。一些例子就是根据不同的图片,比如左上角这张是我觉得分数最高的:有一个女性在沙滩上面走路,经过我们的模型就输出了一个非常浪漫的故事,基本上符合这个情景。
▌五、解析云端AI能力支撑
我们聊了很多计算机视觉图像处理的一些算法,我们是不是下一步还要考虑怎么样把这个算法落地,变成一个有趣的产品或者活动呢?如果是这样,我们需要一些什么样的能力呢?
我们需要一个这样的架构,比如像这次军装照活动,我们会有非常高的访问量,同时呢,它会有遍布全国的用户,整体上来说,我们首先要保证这个系统能稳定和弹性伸缩,然而由于所有的机器都是有成本的,这里我们就要考虑到一个平衡,如何很好的高效承载服务的同时,又要保证这个系统能够足够的稳定?
在这个活动背后,我们使用了很多的腾讯云的一些服务,包括静态加速、负载均衡、云服务器、对象存储,还有一些 GPU 计算。后来发现 CPU 的性能是能够满足我们的需求的,所以之后我们 GPU 就没有上,因为 CPU 的承载还是比较高的,但实际上这一套流程是完全都是可以这么运行的。一般情况下,我们会先用 SCD,里面的 CDM 去做一个静态的缓存,到离用户最近的节点,这样大家在访问 H5 页面的时候就不会等着图片慢慢加载,因为它会在离你家最近的某一个数据中心里一次性的把它给到手机的客户端上。
然后就到负载均衡器,就是把流量负载到背后海量的虚拟机上面。在不同的区域,比如北京会有,成都会有多个 ELB……这个 ELB 会挂载着很多个不同的 CVM,就是虚拟机,所有这些大家上传的照片,匹配运算都是在每个 CVM 上面去产生结果的,然后有些过程的信息,我们也会存在 COS 上,这个 COS 存储是没有大小限制的,这样多种需求都可以得到满足。
这套机制目前证明是非常有效的,我们将来的很多的活动会继续在架构上面做一些优化。如果你有一个很好的想法或模型要去实现,也是可以尝试使用一下云服务,这样是最经济和高效的。
腾讯云人工智能产品方案矩阵
▌六、技能进阶建议
最后我们聊一聊技能进阶的一些建议,如果我们在 AI 这个方向上想有所进步的话,我们应该怎么做?右边有个金字塔,它表示我们要完成一个 AI 的产品,我们需要的人力的数量,AI 算法这块可能是很核心的,但它需要的人数相对来说比较少一点。共同实现是中间的,你需要多一些的底层开发。由于同样一个算法模型,你可能会海量的应用,产品开发应用这个需要的人力的数量是最大的。
算法研究方面我们要做什么?首先是要打好比较强的数学基础。因为机器学习中间大量的用到了比大学高等数学更复杂的数学知识,这些知识需要大家早做研究打好基础,这就需要读很多论文。同时还要锻炼自己对新的学术成果的理解和吸收能力,像刚才提到了一个神经网络图像的分类问题,实际上,短短的十年时间实现了那么多不同网络的进化,每一个新的网络提出了,甚至还没有发表,只是在预发表库里面,大家就要很快的去吸收理解它,想把它转化成可以运行的模型,这个是要反复锻炼的。
第二块是工程实现方面,如果想从事这方面首先要加强自己逻辑算法封装的能力,尽量锻炼自己对模型的训练和优化能力,这块会需要大家把一个设计好的算法给落实到代码上,不断的去调整优化实现最好的结果,这个过程也是需要反复磨炼的。
最后一个方向是产品应用,这个首先大家要有一定的开发能力,不管是移动开发还是 Web 开发,同时要提升自己 AI 产品场景的理解和应用。实际上很多AI产品跟传统的产品是有很大的理解上的区别,大家可能要更新自己的这种想法,多去看一些 AI 产品目前是怎么做的,有没有好的点子,多去试用体会。同时如果我们想把一个 AI 的模型变成百万级、千万级用户使用的流行产品,我们还需要有系统构建能力和优化能力。
云从科技资深算法研究员:详解跨镜追踪(ReID)技术实现及难点
作者 | 袁余锋(云从科技研究院资深算法研究员)
编辑 | 明 明
出品 | 人工智能头条(公众号ID:AI_Thinker)
【导读】跨镜追踪(Person Re-Identification,简称 ReID)技术是现在计算机视觉研究的热门方向,主要解决跨摄像头跨场景下行人的识别与检索。该技术能够根据行人的穿着、体态、发型等信息认知行人,与人脸识别结合能够适用于更多新的应用场景,将人工智能的认知水平提高到一个新阶段。
本期大本营公开课,我们邀请到了云从科技资深算法研究员袁余锋老师,他将通过以下四个方面来讲解本次课题:
1、ReID 的定义及技术难点;
2、常用数据集与评价指标简介;
3、多粒度网络(MGN)的结构设计与技术实现;
4、ReID 在行人跟踪中的应用分析与技术展望
以下是公开课文字版整理内容
ReID 是行人智能认知的其中一个研究方向,行人智能认知是人脸识别之后比较重要的一个研究方向,特别是计算机视觉行业里面,我们首先简单介绍 ReID 里比较热门的几项内容:
1、行人检测。任务是在给定图片中检测出行人位置的矩形框,这个跟之前的人脸检测、汽车检测比较类似,是较为基础的技术,也是很多行人技术的一个前置技术。
2、行人分割以及背景替换。行人分割比行人检测更精准,预估每个行人在图片里的像素概率,把这个像素分割出来是人或是背景,这时用到很多 P 图的场景,比如背景替换。举一个例子,一些网红在做直播时,可以把直播的背景替换成外景,让体验得到提升。
3、骨架关键点检测及姿态识别。一般识别出人体的几个关键点,比如头部、肩部、手掌、脚掌,用到行人姿态识别的任务中,这些技术可以应用在互动娱乐的场景中,类似于 Kinnect 人机互动方面,关键点检测技术是非常有价值的。

4、行人跟踪“ MOT ”的技术。主要是研究人在单个摄像头里行进的轨迹,每个人后面拖了一根线,这根线表示这个人在摄像头里行进的轨迹,和 ReID 技术结合在一起可以形成跨镜头的细粒度的轨迹跟踪。
5、动作识别。动作识别是基于视频的内容理解做的,技术更加复杂一点,但是它与人类的认知更加接近,应用场景会更多,这个技术目前并不成熟。动作识别可以有非常多的应用,比如闯红灯,还有公共场合突发事件的智能认知,像偷窃、聚众斗殴,摄像头识别出这样的行为之后可以采取智能措施,比如自动报警,这有非常大的社会价值。

6、行人属性结构化。把行人的属性提炼出来,比如他衣服的颜色、裤子的类型、背包的颜色。
7、跨境追踪及行人再识别 ReID 技术。

一、ReID 定义及技术难点
▌(一)ReID 定义
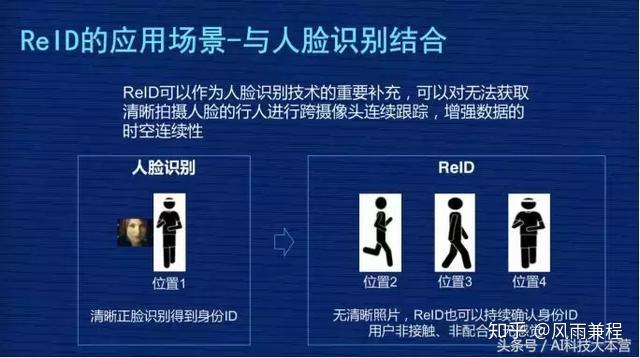
我们把 ReID 叫“跨镜追踪技术”,它是现在计算机视觉研究的热门方向,主要解决跨摄像头跨场景下行人的识别与检索。该技术可以作为人脸识别技术的重要补充,可以对无法获取清晰拍摄人脸的行人进行跨摄像头连续跟踪,增强数据的时空连续性。

给大家举个例子,右图由四张图片构成,黄色这个人是之前新闻报道中的偷小孩事件的人,这个人会出现在多个摄像头里,现在警察刑侦时会人工去检索视频里这个人出现的视频段。这就是 ReID 可以应用的场景,ReID 技术可以根据行人的穿着、体貌,在各个摄像头中去检索,把这个人在各个不同摄像头出现的视频段关联起来,然后形成轨迹,这个轨迹对警察刑侦破案有一定帮助。这是一个应用场景。

▌(二)ReID 技术难点
右边是 ReID 的技术特点:首先,ReID 是属于行人识别,是继人脸识别后的一个重要研究方向。另外,研究的对象是人的整体特征,包括衣着、体形、发行、姿态等等。它的特点是跨摄像头,跟人脸识别做补充。
二、常用数据集与评价指标简介
很多人都说过深度学习其实也不难,为什么?只要有很多数据,基本深度学习的数据都能解决,这是一个类似于通用的解法。那我们就要反问,ReID 是一个深度认知问题,是不是用这种逻辑去解决就应该能够迎刃而解?准备了很多数据,ReID 是不是就可以解决?根据我个人的经验回答一下:“在 ReID 中,也行!但仅仅是理论上的,实际操作上非常不行!”
为什么?第一,ReID 有很多技术难点。比如 ReID 在实际应用场景下的数据非常复杂,会受到各种因素的影响,这些因素是客观存在的,ReID 必须要尝试去解决。

第一组图,无正脸照。最大的问题是这个人完全看不到正脸,特别是左图是个背面照,右图戴个帽子,没有正面照。
第二组图,姿态。绿色衣服男子,左边这张图在走路,右图在骑车,而且右图还戴了口罩。
第三组图,配饰。左图是正面照,但右图背面照出现了非常大的背包,左图只能看到两个肩带,根本不知道背包长什么样子,但右图的背包非常大,这张图片有很多背包的信息。
第四组图,遮挡。左图这个人打了遮阳伞,把肩部以上的地方全部挡住了,这是很大的问题。
图片上只列举了四种情况,还有更多情况,比如:
1、相机拍摄角度差异大;
2、监控图片模糊不清;
3、室内室外环境变化;
4、行人更换服装配饰,如之前穿了一件小外套,过一会儿把外套脱掉了;
5、季节性穿衣风格,冬季、夏季穿衣风格差别非常大,但从行人认知来讲他很可能是同一个人;
6、白天晚上的光线差异等。
从刚才列举的情况应该能够理解 ReID 的技术难点,要解决实际问题是非常复杂的。
ReID 常用的数据情况如何?右图列举了 ReID 学术界最常用的三个公开数据集:
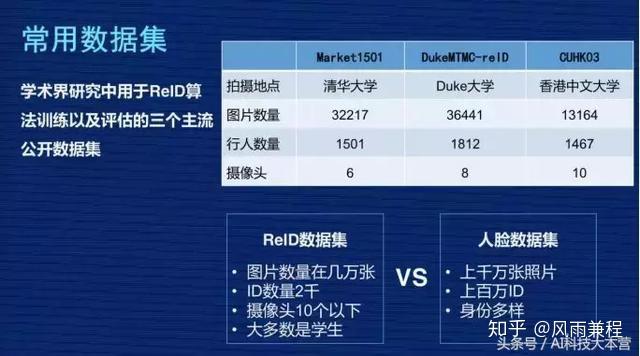
第一列,Market1501。用得比较多,拍摄地点在清华大学,图片数量有 32000 张左右,行人数量是 1500 个,相当于每个人差不多有 20 张照片,它是用 6 个摄像头拍的。
第二列,DukeMTMC-reID,拍摄地点是在 Duke 大学,有 36000 张照片,1800 个人,是 8 个摄像头拍的。
第三列,CUHK03,香港中文大学,13000 张照片,1467 个 ID,10 个摄像头拍的。
看了这几个数据集之后,应该能有一个直观的感受,就是在 ReID 研究里,现在图片的数量集大概在几万张左右,而 ID 数量基本小于 2000,摄像头大概在 10 个以下,而且这些照片大部分都来自于学校,所以他们的身份大部分是学生。
这可以跟现在人脸数据集比较一下,人脸数据集动辄都是百万张或者千万张照片,一个人脸的 ID 多的数据集可以上百万,而且身份非常多样。这个其实就是 ReID 面对前面那么复杂的问题,但是数据又那么少的一个比较现实的情况。

这里放三个数据集的照片在这里,上面是 Market1501 的数据集,比如紫色这个人有一些照片检测得并不好,像第二张照片的人只占图片的五分之三左右,并不是一个完整的人。还有些照片只检测到了局部,这是现在数据集比较现实的情况。
总结一下 ReID 数据采集的特点:
1、必须跨摄像头采集,给数据采集的研发团队和公司提出了比较高的要求;
2、公开数据集的数据规模非常小;
3、影响因素复杂多样;
4、数据一般都是视频的连续截图;
5、同一个人最好有多张全身照片;
6、互联网提供的照片基本无法用在 ReID;
7、监控大规模搜集涉及到数据,涉及到用户的隐私问题。

这些都是 ReID 数据采集的特点,可以归结为一句话:“数据获取难度大,会对算法提出比较大的挑战。”问题很复杂,数据很难获取,那怎么办?现在业内尽量在算法层面做更多的工作,提高 ReID 的效果。
这里讲一下评价指标,在 ReID 用得比较多的评价指标有两个:
- 第一个是 Rank1
- 第二个是 mAP
ReID 终归还是排序问题,Rank 是排序命中率核心指标。Rank1 是首位命中率,就是排在第一位的图有没有命中他本人,Rank5 是 1-5 张图有没有至少一张命中他本人。更能全面评价ReID 技术的指标是 mAP 平均精度均值。

这里我放了三个图片的检索结果,是 MGN 多粒度网络产生的结果,第一组图 10 张,从左到右是第 1 张到第 10 张,全是他本人图片。第二组图在第 9 张图片模型判断错了,不是同一个人。第三组图,第 1 张到第 6 张图是对的,后面 4 张图检索错了,不是我们模型检索错了,是这个人在底库中总共就 6 张图,把前 6 张检索出来了,其实第三个人是百分之百检索对的。
详细介绍评价指标 mAP。因为 Rank1 只要第一张命中就可以了,有一系列偶然因素在里面,模型训练或者测试时有一些波动。但是 mAP 衡量 ReID 更加全面,为什么?因为它要求被检索人在底库中所有的图片都排在最前面,这时候 mAP 的指标才会高。

给大家举个例子,这里放了两组图,图片 1 和图片 2 是检索图,第一组图在底库中有 5 张图,下面有 5 个数字,我们假设它的检索位置,排在第 1 位、第 3 位、第 4 位、第 8 位,第 20 位,第二张图第 1 位、第 3 位、第 5 位。
它的 mAP 是怎么算的?对于第一张图平均精度有一个公式在下面,就是 0.63 这个位置。第一张是 1 除以 1,第二张是除以排序实际位置,2 除以 3,第三个位置是 3 除以 4,第四个是 4 除以 8,第五张图是 5 除以 20,然后把它们的值求平均,再总除以总的图片量,最后得出的 mAP 值大概是 0.63。
同样的算法,算出图片 2 的精度是 0.756。最后把所有图片的 mAP 求一个平均值,最后得到的 mAP 大概是 69.45。从这个公式可以看到,这个检索图在底库中所有的图片都会去计算 mAP,所以最好的情况是这个人在底库中所有的图片都排在前面,没有任何其他人的照片插到他前面来,就相当于同一个人所有的照片距离都是最近的,这种情况最好,这种要求是非常高的,所以 mAP 是比较能够综合体现这个模型真实水平的指标。
再来看一下 ReID 实现思路与常见方案。ReID 从完整的过程分三个步骤:
- 第一步,从摄像头的监控视频获得原始图片;
- 第二步,基于这些原始图片把行人的位置检测出来;
- 第三步,基于检测出来的行人图片,用 ReID 技术计算图片的距离,但是我们现在做研究是基于常用数据集,把前面图像的采集以及行人检测的两个工作做过了,我们 ReID 的课题主要研究第三个阶段。
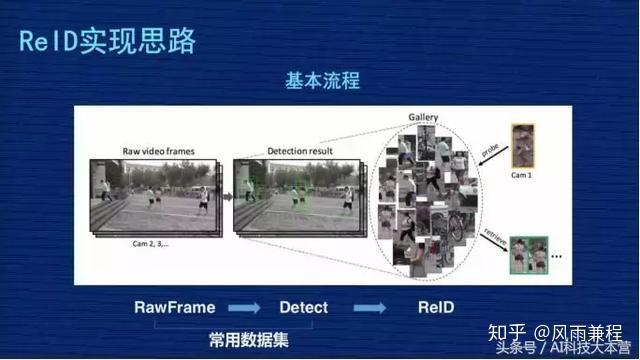
ReID 研究某种意义上来讲,如果抽象得比较高,也是比较清晰的。比如大家看下图,假设黄色衣服的人是检索图,后面密密麻麻很多小图组成的相当于底库,从检索图和底库都抽出表征图像的特征,特征一般都抽象为一个向量,比如 256 维或者 2048 维,这个 Match 会用距离去计算检索图跟库里所有人的距离,然后对距离做排序,距离小的排在前面,距离大的排在后面,我们理解距离小的这些人是同一个人的相似度更高一点,这是一个比较抽象的思维。
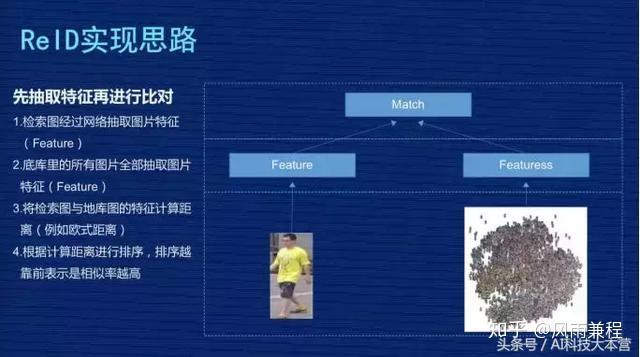
刚才讲到核心是把图像抽象成特征的过程,我再稍微详细的画一个流程,左图的这些图片会经过 CNN 网络,CNN 是卷积神经网络,不同的研究机构会设计自己不同的网络结构,这些图片抽象成特征 Feature,一般是向量表示。
然后分两个阶段,在训练时,我们一般会设计一定的损失函数,在训练阶段尽量让损失函数最小化,最小化过程反向把特征训练得更加有意义,在评估阶段时不会考虑损失函数,直接把特征抽象出来,用这个特征代表这张图片,放到前面那张 PPT 里讲的,去计算它们的距离。
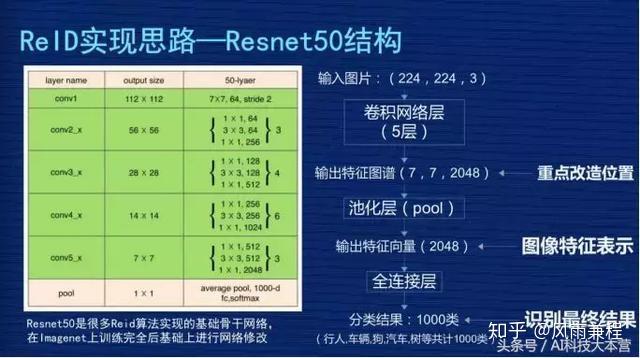
因为现在 ReID 的很多研究课题都是基于 Resnet50 结构去修改的。Resnet 一般会分为五层,图像输入是 (224,224,3),3 是 3 个通道,每层输出的特征图谱长宽都会比上一层缩小一半,比如从 224 到 112,112 到 56,56 到 28,最后第五层输出的特征图谱是 (7,7,2048)。
最后进行池化,变成 2048 向量,这个池化比较形象的解释,就是每个特征图谱里取一个最大值或者平均值。最后基于这个特征做分类,识别它是行人、车辆、汽车。我们网络改造主要是在特征位置(7,7,2048)这个地方,像我们的网络是 384×128,所以我们输出的特征图谱应该是 (12,4,2048)的过程。
下面,我讲一下 ReID 里面常用的算法实现:
▌第一种,表征学习。
给大家介绍一下技术方案,图片上有两行,上面一行、下面一行,这两行网络结构基本是一样的,但是两行中间这个地方会把两行的输出特征进行比较,因为这个网络是用了 4096 的向量,两个特征有一个对比 Loss,这个网络用了两种 Loss,第一个 Loss 是 4096 做分类问题,然后两个 4096 之间会有一个对比 Loss。
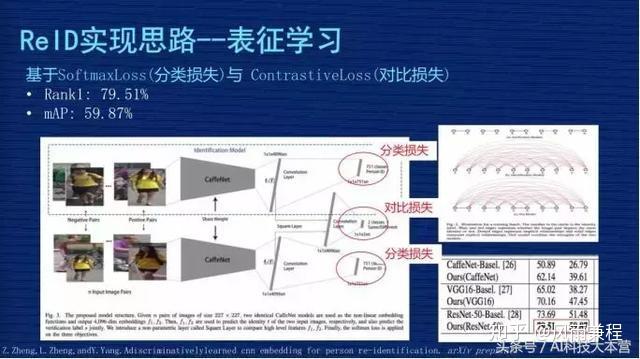
这个分类的问题是怎么定义的?在我们数据集像 mark1501 上有 751 个人的照片组成,这个分类相当于一张图片输入这个网络之后,判断这个人是其中某一个人的概率,要把这个图片分类成 751 个 ID 中其中一个的概率,这个地方的 Loss 一般都用 SoftmaxLoss。机器视觉的同学应该非常熟悉这个,这是非常基本的一个 Loss,对非机器视觉的同学,这个可能要你们自己去理解,它可以作为分类的实现。
这个方案是通过设计分类损失与对比损失,来实现对网络的监督学习。它测试时取的是 4096 这个向量来表征图片本人。这个文章应该是发在 2016 年,作者当时报告的效果在当时的时间点是有一定竞争力的,它的 Rank1 到了 79.51%,mAP 是 59.87%
▌第二种,度量学习方案。
基于TripletLoss 三元损失的 ReID 方案。TripletLoss 是计算机视觉里另外一个常用的 Loss。

它的设计思路是左图下面有三个点,目的是从数据里面选择三个图片,这三个图片由两个人构成,其中两张图片是同一个人,另外一张图片不是同一个人,当这个网络在没有训练的时候,我们假设这同一个人的两张照片距离要大于这个人跟不是同一个人两张图片的距离。
它强制模型训练,使得同一个人两张图片的距离小于第三张图片,就是刚才那张图片上箭头表示的过程。它真正的目的是让同类的距离更近,不同类的距离更远。这是TripletLoss的定义,大家可以去网上搜一下更详细的解释。
在 ReID 方案里面我给大家介绍一个 Batchhard的策略,因为 TripletLoss 在设计时怎么选这三张图是有很多文章在实现不同算法,我们的文章里用的是 Batchhard算法,就是我们从数据集随机抽取 P 个人,每个人 K 张图片形成一个 Batch,每个人的 K 张图片之间形成一个 K×(K-1)个 ap 对,再在剩下其他人里取一个与该 ap 距离最近的 negtive,组成 apn 组,然后我们这个模型使得 apn 组成的 Loss 尽量小。
这个 Loss 怎么定义?右上角有一个公式,就是 ap 距离减 an距离,m 是一个gap,这个值尽量小,使得同类之间尽量靠在一起,异类尽量拉开。右图是 TripletLoss 的实验方案,当时这个作者报告了一个成果,Rank1 到了 84.92%,mAP 到了 69%,这个成果在他发文章的那个阶段是很有竞争力的结果。
▌第三种,局部特征学习。
1、基于局部区域调整的 ReID 解决方案。多粒度网络也是解决局部特征和全局特征的方案。这是作者发的一篇文章,他解释了三种方案。
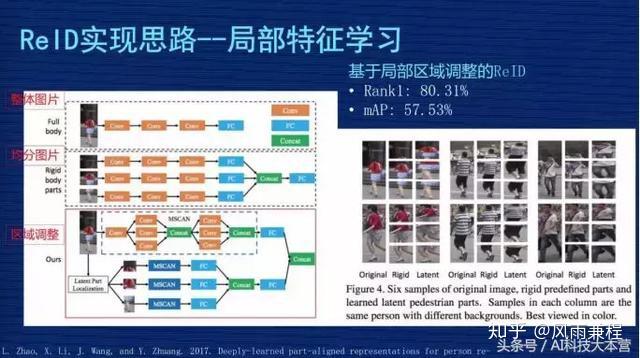
- 左图第一种方案是把整张图输进网络,取整张图的特征;
- 第二种方案是把图从上到下均分为三等,三分之一均分,每个部分输入到网络,去提出一个特征,把这三个特征又串连起来;
- 第三种方案是文章的核心,因为他觉得第二种均分可能出现问题,就是有些图片检测时,因为检测技术不到位,检测的可能不是完整人,可能是人的一部分,或者是人在图里面只占一部分,这种情况如果三分之一均分出来的东西互相比较时就会有问题。
所以他设计一个模型,使得这个模型动态调整不同区域在图片中的占比,把调整的信息跟原来三分的信息结合在一起进行预估。作者当时报告的成果是 Rank1为80% 左右,mAP为57%,用现在的眼光来讲,这个成果不是那么显著,但他把图片切分成细粒度的思路给后面的研究者提供了启发,我们的成果也受助于他们的经验。
2、基于姿态估计局部特征调整。局部切割是基于图片的,但对里面的语义不了解,是基于姿态估计局部位置的调整怎么做?先通过人体关键点的模型,把这个图片里面人的关节位置取出来,然后按照人类对人体结构的理解,把头跟头比较,手跟手比较,按照人类的语义分割做一些调整,这相对于刚才的硬分割更加容易理解。基于这个调整再去做局部特征的优化,这个文章是发表在 2017 年,当时作者报告的成果 Rank1为84.14%,mAP为63.41%。

3、PCB。发表在 2018 年 1 月份左右的文章,我们简称为 PCB,它的指标效果在现在来看还是可以的,我们多粒度网络有一部分也是受它的启发。下图左边这个特征图较为复杂,可以看一下右边这张图,右图上部分蓝色衣服女孩这张图片输入网络后有一个特征图谱,大概个矩形体组成在这个地方,这是特征图谱。这个图谱位置的尺寸应该是 24×8×2048,就是前面讲的那个特征图谱的位置。

它的优化主要是在这个位置,它干了个什么事?它沿着纵向将24 平均分成 6 份,纵向就是 4,而横向是 8,单个特征图谱变为 4×8×2048,但它从上到下有 6 个局部特征图谱。6个特征图谱变为6个向量后做分类,它是同时针对每个局部独立做一个分类,这是这篇文章的精髓。这个方式看起来非常简单,但这个方法跑起来非常有效。作者报告的成果在 2018 年 1 月份时 Rank1 达到了 93.8%,mAP 达到了 81.6%,这在当时是非常好的指标了。
三、多粒度网络(MGN)的结构设计与技术实现
刚才讲了 ReID 研究方面的 5 个方案。接下来要讲的是多粒度网络的结构设计与实现。有人问 MGN 的名字叫什么,英文名字比较长,中文名字是对英文的一个翻译,就是“学习多粒度显著特征用于跨境追踪技术(行人在识别)”,这个文章是发表于 4 月初。

▌(一)多粒度网络(MGN)设计思路。
设计思想是这样子的,一开始是全局特征,把整张图片输入,我们提取它的特征,用这种特征比较 Loss 或比较图片距离。但这时我们发现有一些不显著的细节,还有出现频率比较低的特征会被忽略。比如衣服上有个 LOGO,但不是所有衣服上有 LOGO,只有部分人衣服上有 LOGO。全局特征会做特征均匀化,LOGO 的细节被忽略掉了。
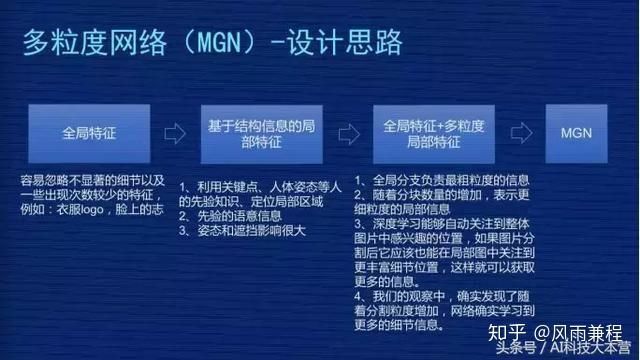
我们基于局部特征也去尝试过,用关键点、人体姿态等。但这种有一些先验知识在里面,比如遮挡、姿态大范围的变化对这种方案有一些影响,效果并不是那么强。
后来我们想到全局特征跟多粒度局部特征结合在一起搞,思路比较简单,全局特征负责整体的宏观上大家共有的特征的提取,然后我们把图像切分成不同块,每一块不同粒度,它去负责不同层次或者不同级别特征的提取。
相信把全局和局部的特征结合在一起,能够有丰富的信息和细节去表征输入图片的完整情况。在观察中发现,确实是随着分割粒度的增加,模型能够学到更详细的细节信息,最终产生 MGN 的网络结构。
下面演示一下多粒度特征,演示两张图,左边第一列有 3 张图,中间这列把这3张图用二分之一上下均分,你可以看到同一个人有上半身、下半身,第三列是把人从上到下分成三块——头部、腹胸、腿部,它有 3 个粒度,每个粒度做独立的引导,使得模型尽量对每个粒度学习更多信息。

右图表示的是注意力的呈现效果,这不是基于我们模型产生的,是基于之前的算法看到的。左边是整张图在输入时网络在关注什么,整个人看着比较均匀,范围比较广一点。第三栏从上到下相当于把它切成 3 块,每一块看的时候它的关注点会更加集中一点,亮度分布不会像左边那么均匀,更关注局部的亮点,我们可以理解为网络在关注不同粒度的信息。
▌(二)多粒度网络(MGN)——网络结构
这是 MGN 的网络架构完整的图,这个网络图比较复杂,第一个,网络从结构上比较直观,从效果来讲是比较有效的,如果想复现我们的方案还是比较容易的。如果你是做深度学习其他方向的,我们这个方案也有一定的普适性,特别是关注细粒度特征时,因为我们不是只针对 ReID 做的。我们设计的结构是有一定普适性,我把它理解为“易迁移”,大家可以作为参考。
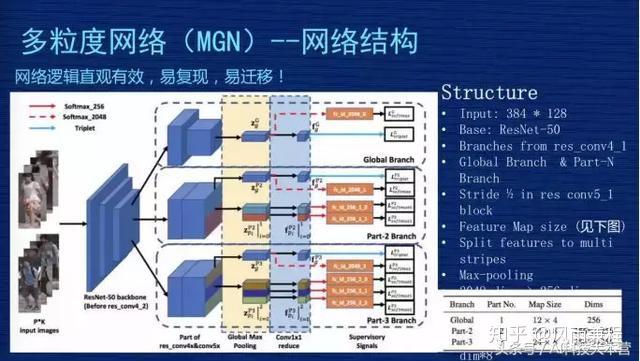
首先,输入图的尺寸是 384×128,我们用的是 Resnet50,如果在不做任何改变的情况下,它的特征图谱输出尺寸,从右下角表格可以看到,global 这个地方就相当于对 Resnet 50不做任何的改变,特征图谱输出是 12×4。
下面有一个 part-2 跟 part-3,这是在 Res4_1 的位置,本来是有一个stride 等于 2 的下采样的操作,我们把 2 改成 1,没有下采样,这个地方的尺寸就不会缩小 2,所以 part-2 跟 part-3 比 global 大一倍的尺寸,它的尺寸是 24×8。为什么要这么操作?因为我们会强制分配 part-2 跟 part-3 去学习细粒度特征,如果把特征尺寸做得大一点,相当于信息更多一点,更利于网络学到更细节的特征。
网络结构从左到右,先是两个人的图片输入,这边有 3 个模块。3 个模块的意思是表示 3 个分支共享网络,前三层这三个分支是共享的,到第四层时分成三个支路,第一个支路是 global 的分支,第二个是 part-2 的分支,第三个是 part-3 的分支。在 global 的地方有两块,右边这个方块比左边的方块大概缩小了一倍,因为做了个下采样,下面两个分支没有做下采样,所以第四层和第五层特征图是一样大小的。
接下来我们对 part-2 跟 part-3 做一个从上到下的纵向分割,part-2 在第五层特征图谱分成两块,part-3 对特征图谱从上到下分成三块。在分割完成后,我们做一个 pooling,相当于求一个最值,我们用的是 Max-pooling,得到一个 2048 的向量,这个是长条形的、横向的、黄色区域这个地方。
但是 part-2 跟 part-3 的操作跟 global 是不一样的,part-2 有两个 pooling,第一个是蓝色的,两个 part 合在一起做一个 global-pooling,我们强制 part-2 去学习细节的联合信息,part-2 有两个细的长条形,就是我们刚才引导它去学细节型的信息。淡蓝色这个地方变成小方体一样,是做降维,从 2048 维做成 256 维,这个主要方便特征计算,因为可以降维,更快更有效。我们在测试的时候会在淡蓝色的地方,小方块从上到下应该是 8 个,我们把这 8 个 256 维的特征串连一个 2048 的特征,用这个特征替代前面输入的图片。
▌(三)多粒度网络(MGN)——Loss设计
Loss 说简单也简单,说复杂也复杂也复杂,为什么?简单是因为整个模型里只用了两种Loss,是机器学习里最常见的,一个是 SoftmaxLoss 一个是 TripletLoss。复杂是因为分支比较多,包括 global 的,包括刚才 local 的分支,而且在各个分支的 Loss 设计上不是完全均等的。我们当时做了些实验和思考去想 Loss 的设计。现在这个方案,第一,从实践上证明是比较好的,第二,从理解上也是容易理解的。
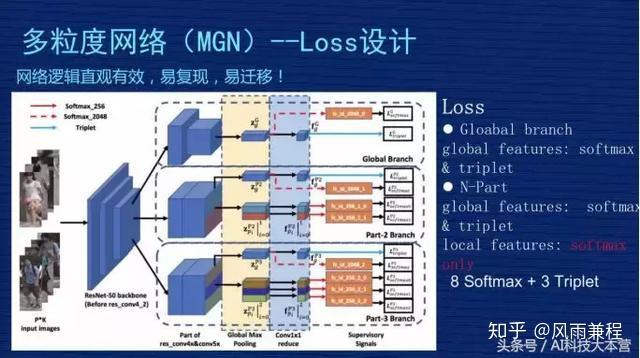
首先,看一下 global 分支。上面第一块的 Loss 设计。这个地方对 2048 维做了SoftmaxLoss,对 256 维做了一个 TripletLoss,这是对 global 信息通用的方法。下面两个部分 global 的处理方式也是一样的,都是对 2048 做一个 SoftmaxLoss,对 256 维做一个 TripletLoss。中间 part-2 地方有一个全局信息,有 global 特征,做 SoftmaxLoss+TripletLoss。
但是,下面两个 Local 特征看不到 TripletLoss,只用了 SoftmaxLoss,这个在文章里也有讨论,我们当时做了实验,如果对细节当和分支做 TripletLoss,效果会变差。为什么效果会变差?
一张图片分成从上到下两部分的时候,最完美的情况当然是上面部分是上半身,下面部分是下半身,但是在实际的图片中,有可能整个人都在上半部分,下半部分全是背景,这种情况用上、下部分来区分,假设下半部分都是背景,把这个背景放到 TripletLoss 三元损失里去算这个 Loss,就会使得这个模型学到莫名其妙的特征。
比如背景图是个树,另外一张图是某个人的下半身,比如一个女生的下半身是一个裙子,你让裙子跟另外图的树去算距离,无论是同类还是不同类,算出来的距离是没有任何物理意义或实际意义的。从模型的角度来讲,它属于污点数据,这个污点数据会引导整个模型崩溃掉或者学到错误信息,使得预测的时候引起错误。所以以后有同学想复现我们方法的时候要注意一下, Part-2、part-3 的 Local 特征千万不要加 TripletLoss。
▌(四)多粒度网络(MGN)——实验参数
图片展示的是一些实验参数,因为很多同学对复现我们的方案有一定兴趣,也好奇到底这个东西为什么可以做那么好。其实我们在文章里把很多参数说得非常透,大家可以按照我们的参数去尝试一下。
我们当时用的框架是 Pytorch。TripletLoss 复现是怎么选择的?我们这个 batch是选 P=16,K=4,16×4,64 张图作为 batch,是随机选择16 个人,每个人随机选择 4 张图。

然后用 SGD 去训练,我们的参数用的是 0.9。另外,我们做了weight decay,参数是万分之五。像 Market1501 是训练 80epochs,是基于 Resnet50 微调了。我们之前实验过,如果不基于 Resnet50,用随机初始化去训练的话效果很差,很感谢 Resnet50 的作者,对这个模型训练得 非常有意义。
初始学习率是百分之一,到 40 个 epoch 降为千分之一,60 个 epoch 时降为万分之一。我们评估时会对评估图片做左右翻转后提取两个特征,这两个特征求一个平均值,代表这张图片的特征。刚才有人问到我们用了什么硬件,我们用了 2 张的 TITAN 的 GPU。
在 Market1501 上训练 80 epoch的时间大概差不多是 2 小时左右,这个时间是可以接受的,一天训练得快一点可以做出 5-10 组实验。
▌(五)多粒度网络(MGN)——实验结果
我们发表成果时,这个结果是属于三个数据集上最好的。
1、Market1501。我们不做 ReRank 的时候,原始的 Rank1 是 95.7%,mAP 是 86.9%,跟刚才讲的业内比较好的 PCB 那个文章相比,我们的 Rank1 提高差不多 1.9 个点,mAP 整整提高 5.3 个点,得到非常大的提升。
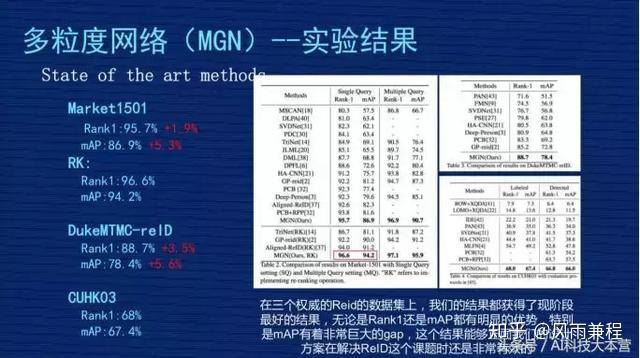
2、RK。Rank1 达到 96.6%,mAP 是 94.2%。RK 是 ReRank 重新排序的简称, ReID 有一篇文章是专门讲 ReRank 技术的,不是从事 ReID 的同学对 ReRank 的技术可能有一定迷惑,大家就理解为这是某种技术,这种技术是用在测试结果重新排列的结果,它会用到测试集本身的信息。因为在现实意义中很有可能这个测试集是开放的,没有办法用到测试集信息,就没有办法做ReRank,前面那个原始的 Rank1 和 mAP 比较有用。
但是对一些已知道测试集数据分布情况下,可以用 ReRank 技术把这个指标有很大的提高,特别是 mAP,像我们方案里从 86.9% 提升到 94.2%,这其中差不多 7.3% 的提升,是非常显著的。
3、DukeMTMC-reID 和 CUHKO3 这两个结果在我们公布研究成果时算是最好的,我们是4月份公布的成果,现在是 6 月份了,最近 2 个月 CEPR 对关于 ReID 的文章出了差不多 30 几篇,我们也在关注结果。现在除了我们以外最好的成果,原始 Rank1 在 93.5%-94% 之间,mAP 在83.5%-84% 之间,很少看到 mAP 超过 84% 或者 85% 的关于。
▌(六)多粒度网络(MGN)——有趣的对比实验
因为网络结构很复杂,这么复杂的事情能说得清楚吗?里面各个分支到底有没有效?我们在文章里做了几组比较有意思的实验,这里跟大家对比一下。
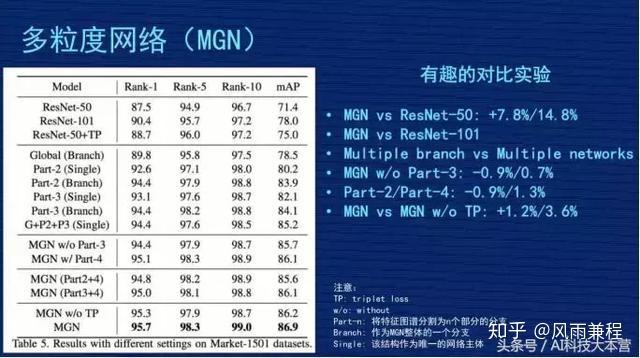
第一个对比,对比 MGN 跟 Resnet50,这倒数第二行,就是那个 MGN w/o TP,跟第一行对比,发现我们的多粒度网络比 Resnet50 水平,Rank1 提高了 7.8%,mAP 提高了 14.8%,整体效果是不错的。
第二个对比,因为我们的网络有三个分支,里面参数量肯定会增加,增加的幅度跟 Resnet101的水平差不多,是不是我们网络成果来自于参数增加?我们做了一组实验,第二行有一个 Resnet101,它的 rank1 是 90.4%,mAP 是 78%,这个比 Resnet50 确实好了很多,但是跟我们的工作成果有差距,说明我们的网络也不是纯粹堆参数堆出来的结果,应该是有网络设计的合理性在。
第三个对比,表格第二个大块,搞了三个分支,把这三个分支做成三个独立的网络,同时独立训练,然后把结果结合在一起,是不是效果跟我们差不多,或者比我们好?我们做了实验,最后的结果是“G+P2+P3(single)”,Rank1 有 94.4%,mAP85.2%,效果也不错,但跟我们三个网络联合的网络结构比起来,还是我们的结构更合理。我们的解释是不同分支在学习的时候,会互相去督促或者互相共享有价值的信息,使得大家即使在独立运作时也会更好。
▌(七)多粒度网络(MGN)——多粒度网络效果示例
这是排序图片的呈现效果,左图是排序位置,4 个人的检索结果,前 2 个人可以看到我们的模型是很强的,无论这个人是侧身、背身还是模糊的,都能够检测出来。尤其是第 3 个人,这张图是非常模糊的,整个人是比较黑的,但是我们这个模型根据他的绿色衣服、白色包的信息,还是能够找出来,尽管在第 9 位有一个判断失误。第 4 个人用了一张背面的图,背个包去检索,可以发现结果里正脸照基本被搜出来了。

右边是我们的网络注意力模型,比较有意思的一个结果,左边是原图,右边从左到右有三列,是 global、part2、part3 的特征组,可以看到 global 的时候分布是比较均匀的,说明它没有特别看细节。
越到右边的时候,发现亮点越小,越关注在局部点上,并不是完整的整个人的识别。第 4 个人我用红圈圈出来了,这个人左胸有一个 LOGO,看 part3 右边这张图的时候,整个人只有在 LOGO 地方有一个亮点或者亮点最明显,说明我们网络在 part3 专门针对这个 LOGO 学到非常强的信息,检索结果里肯定是有这个 LOGO 的人排列位置比较靠前。
四、应用场景与技术展望
▌(一)ReID 的应用场景
第一个,与人脸识别结合。
之前人脸识别技术比较成熟,但是人脸识别技术有一个明显的要求,就是必须看到相对清晰的人脸照,如果是一个背面照,完全没有人脸的情况下,人脸识别技术是失效的。
但 ReID 技术和人脸的技术可以做一个补充,当能看到人脸的时候用人脸的技术去识别,当看不到人脸的时候用 ReID 技术去识别,可以延长行人在摄像头连续跟踪的时空延续性。右边位置2、位置3、位置4 的地方可以用 ReID 技术去持续跟踪。跟人脸识别结合是大的 ReID 的应用方向,不是具象的应用场景。
第二个,智能安防。
它的应用场景是这样子的,比如我已经知道某个嫌疑犯的照片,警察想知道嫌疑犯在监控视频里的照片,但监控视频是 24 小时不间断在监控,所以数据量非常大,监控摄像头非常多,比如有几百个、几十个摄像头,但人来对摄像头每秒每秒去看的话非常费时,这时可以用 ReID 技术。
ReID 根据嫌疑犯照片,去监控视频库里去收集嫌疑犯出现的视频段。这样可以把嫌疑犯在各个摄像头的轨迹串连起来,这个轨迹一旦串连起来之后,相信对警察的破案刑侦有非常大的帮助。这是在智能安防的具象应用场景。

第三个,智能寻人系统。
比如大型公共场所,像迪斯尼乐园,爸爸妈妈带着小朋友去玩,小朋友在玩的过程中不小心与爸爸妈妈走散了,现在走散时是在广播里播一下“某某小朋友,你爸爸妈妈在找你”,但小朋友也不是非常懂,父母非常着急。
这时可以用 ReID 技术,爸爸妈妈提供一张小朋友拍的照片,因为游乐园里肯定拍了小朋友拍的照片,比如今天穿得什么衣服、背得什么包,把这个照片输入到 ReID 系统里,实时的在所有监控摄像头寻找这个小朋友的照片,ReID 有这个技术能力,它可以很快的找到跟爸爸妈妈提供的照片最相似的人,相信对立马找到这个小朋友有非常大的帮助。
这种大型公共场所还有更多,比如超市、火车站、展览馆,人流密度比较大的公共场所。智能寻人系统也是比较具象的 ReID 应用场景。

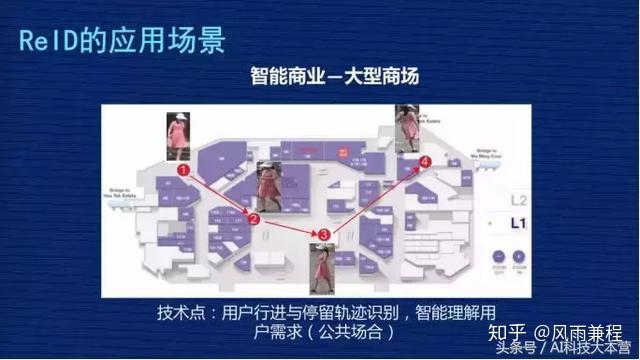
第四个,智能商业-大型商场。
想通过了解用户在商场里的行为轨迹,通过行为轨迹了解用户的兴趣,以便优化用户体验。ReID 可以根据行人外观的照片,实时动态跟踪用户轨迹,把轨迹转化成管理员能够理解的信息,以帮助大家去优化商业体验。
这个过程中会涉及到用户隐私之类的,但从 ReID 的角度来讲,我们比较提倡数据源来自于哪个商场,那就应用到哪个商场。因为 ReID 的数据很复杂,数据的迁移能力是比较弱的,这个上场的数据不见得在另外一个商场里能用,所以我们提倡 ReID 的数据应用在本商场。
第五个,智能商业-无人超市。
无人超市也有类似的需求,无人超市不只是体验优化,它还要了解用户的购物行为,因为如果只基于人脸来做,很多时候是拍不到客户的正面,ReID 这个技术在无人超市的场景下有非常大的应用帮助。

第六个,相册聚类。
现在拍照时,可以把相同人的照片聚在一起,方便大家去管理,这也是一个具象的应用场景。

第七个,家庭机器人。
家庭机器人通过衣着或者姿态去认知主人,做一些智能跟随等动作,因为家庭机器人很难实时看到主人的人脸,用人脸识别的技术去做跟踪的话,我觉得还是有一些局限性的。但是整个人体的照片比较容易获得,比如家里有一个小的机器人,它能够看到主人的照片,无论是上半年还是下半年,ReID 可以基于背影或者局部服饰去识别。

▌(二)ReID 的技术展望
第一个,ReID 的数据比较难获取,如果用应用无监督学习去提高 ReID 效果,可以降低数据采集的依赖性,这也是一个研究方向。右边可以看到,GAN生成数据来帮助 ReID 数据增强,现在也是一个很大的分支,但这只是应用无监督学习的一个方向。
第二个,基于视频的 ReID。因为刚才几个数据集是基于对视频切好的单个图片而已,但实际应用场景中还存在着视频的连续帧,连续帧可以获取更多信息,跟实际应用更贴近,很多研究者也在进行基于视频 ReID 的技术。

第三个,跨模态的 ReID。刚才讲到白天和黑夜的问题,黑夜时可以用红外的摄像头拍出来的跟白色采样摄像头做匹配。
第四个,跨场景的迁移学习。就是在一个场景比如 market1501 上学到的 ReID,怎样在 Duke数据集上提高效果。
第五个,应用系统设计。相当于设计一套系统让 ReID 这个技术实际应用到行人检索等技术上去。
——【完】——
身份采集、活体检测、人脸比对...旷视是如何做FaceID的? | 公开课笔记

作者 | 彭建宏(旷视科技产品总监彭建宏)
整理 | Just
出品 | 人工智能头条(公众号ID:AI_Thinker)
“刷脸”曾一度是人们互相调侃时的用语,如今早已深深地融入我们的生活。从可以人脸解锁的手机,到人脸识别打卡机,甚至地铁“刷脸”进站……
人脸识别技术越来越多地应用在了各种身份验证场景,在这种看起来发生在电光火石之间的应用背后,又有哪些不易察觉的技术在做精准判别?算法又是通过何种方式来抵御各种欺诈式攻击?
我们近期邀请到旷视科技产品总监彭建宏,他负责 FaceID 在线身份验证云服务的产品设计。在本次公开课上,他讲述了深度学习在互联网身份验证服务中的应用以及人脸识别活体检测(动作、炫彩、视频、静默)技术应用场景及实现方式。
(视频地址:https://v.qq.com/x/page/k0678hscngd.html)
以下为彭建宏公开课演讲内容实录:
今天我们主要说的是 FaceID,它在我们产品矩阵里更像是一套解决方案,是身份验证的金融级解决方案。我们在生活中有很多场景是想验证,证明你是你。
基本所有的互联网金融公司都会在我们借贷的时候要去验证你是你,这就需要做一个你是你这样一个证明,所以如何提供一套可靠的方案去验证你是你这件事情就已经变得非常重要,大家可能很容易想到验证的方法有很多,包括之前大量使用的指纹识别,还有一些电影里边经常出现的虹膜识别,还有最近特别火的人脸识别。
下面我说一下技术特点。关于人脸识别,大家很容易想到第一个特点就是体验非常好,非常自然、便利,但它的缺点也很多,首先隐私性更差,我们要想获得别人的指纹和虹膜的代价非常大,但是要获得别人面部的照片这个代价就非常的小了。第二是由于光照、年龄、胡须、还有眼镜等等因素,人脸识别的稳定性会比较低。第三是指纹识别、虹膜识别都有主动性,人脸识别具有被动性,这也是之前 iPhoneX 刚出来的时候,很多人担心不经意被人错刷,或者去误刷支付或者检索等等——弱阴私性,弱稳定性还有被动性,就对人脸识别的商业化应用提出了更高的技术要求。
深度学习技术的迅猛发展,使得图像识别、分类跟检测的准确率大幅提高,但真正要做成一套金融级解决方案还不是那么简单的,这张图就展示了一个整体的 FaceID 提供的金融级整体的解决方案。
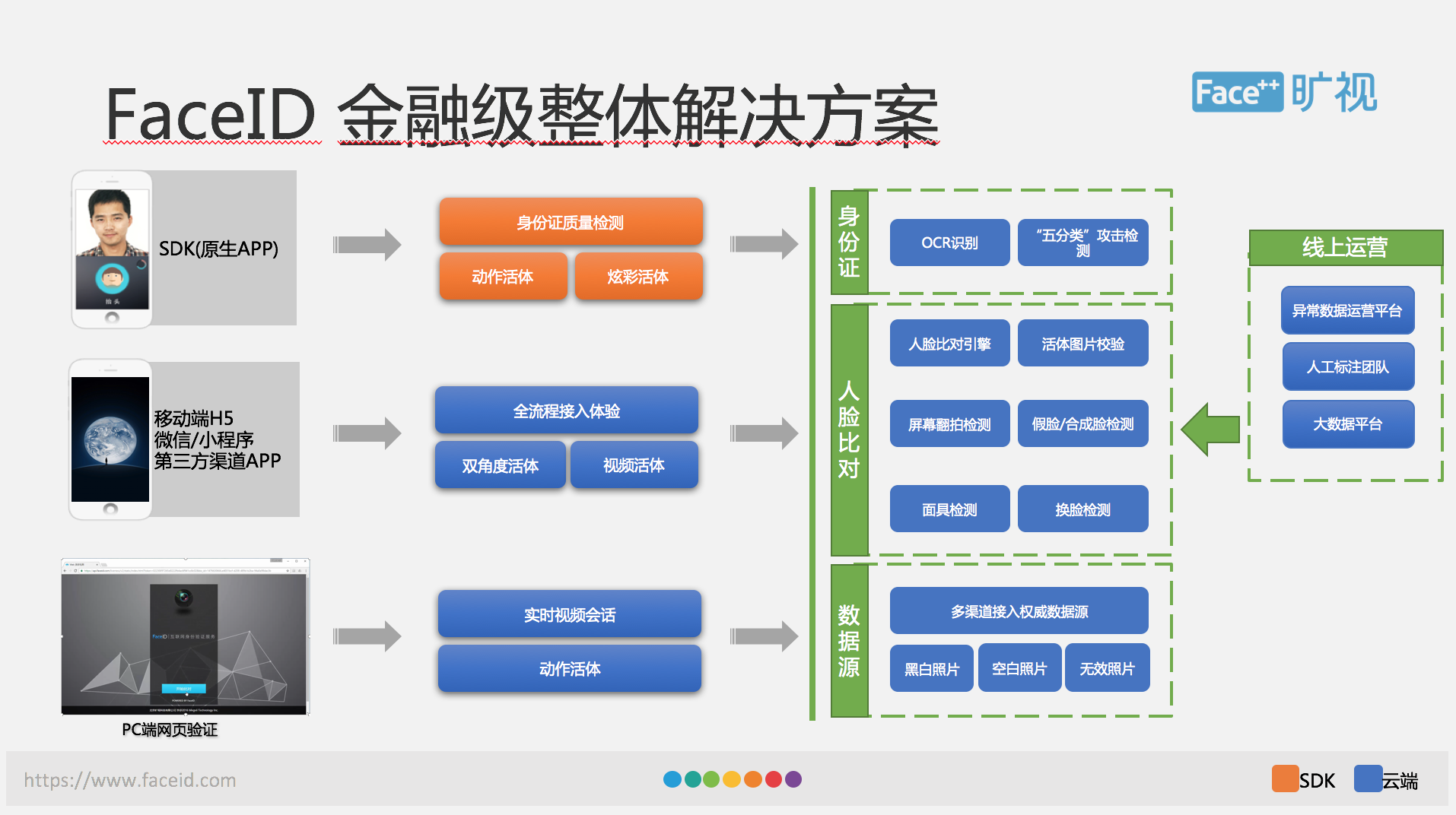
在这个架构图中,我们可以看到,FaceID 的用户提供了多种产品形态,包括移动端的 SDK,H5,微信/小程序、第三方渠道 APP 以及 PC 端。从功能上来说呢,我们的产品包括身份证的质量检测、身份证 OCR 识别、活体检测、攻击检测以及人脸比对,整个解决方案可以看出是建立在云跟端两个基础上,我们在端上提供了 UI 解决方案,就提供 UI 界面可以方便集成,如果觉得我们的 UI 做得不符合大家的要求,也可以去做一些定制化开发,整个核心功能里有活体检测,在端上跟云上分别有自己的实现。
同时针对不同的活体攻击方案,还会采用不同的活体策略。我们在现实中的活体检测中,线上运营会实时收集各种图片做标注,及时把算法进行更新,可以确保最新的攻击可以在第一时间内进行响应和返馈,这也是为我们整个深度学习算法不断注入新血液。
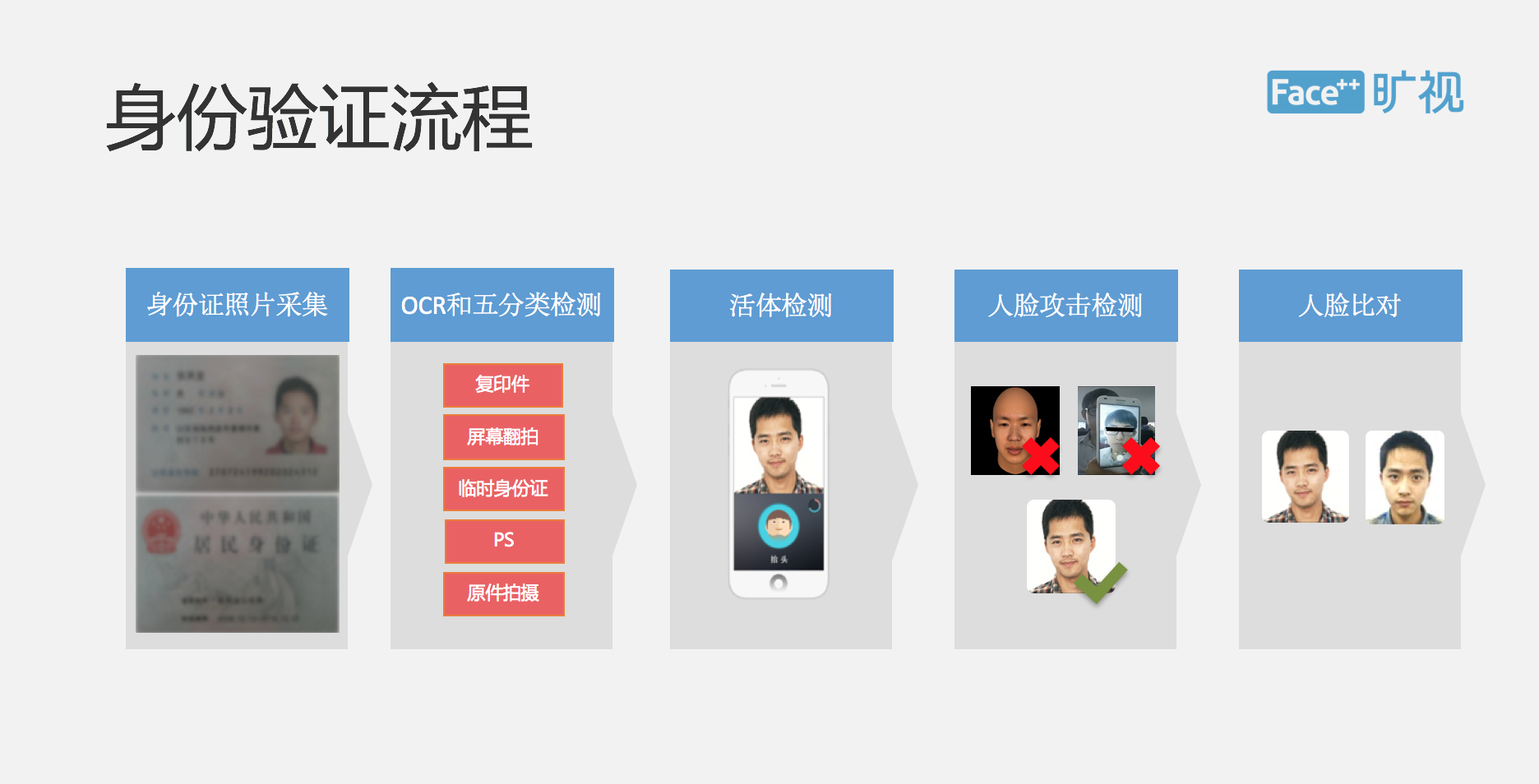
▌身份证采集

整个流程是这样的,用户会先进行身份证采集,系统其实会要求用户先去拍一张身份证的正面跟反面,这个过程是在端上进行完成的。拍摄以后,我们会在云上进行,OCR 识别是在云上完成的,我们不仅会去识别身份证上面的信息,还会去识别这个身份证的一些分类。由于不同的业务场景不同,这个分类信息会反馈给用户,用户来判断是否接受。在很多严肃的场景下,很多客户可能只能接受身份证原件,识别出来的文字我们也会根据用户的业务不同做相应不同的处理,因为有些客户就要我们识别出来的文字,用户是不能去修改身份证号和姓名的。

我们在 OCR 里面还加入了很多逻辑判断,例如大家知道在身份证号里面是可以看出来用户生日还有性别信息,如果我们发现身份证上的生日跟身份证号判断出来的信息不一样,我们就会在 API 的结果里面给用户返回逻辑错误,这是用户可以根据业务逻辑可以自行进行处理的。
这个展示就是我们身份证采集以及身份证 OCR 的一些场景。先通过手机的摄像头去采集,在我们的云端去完成 OCR 识别以及物体分类,可以去判断是不是真实的身份证。有一个需要讨论的问题是,为什么我们把 OCR 放在了云端,而不是放在手机的 SDK 端呢?这个主要是安全方面的考虑,如果信息被黑客攻破,这在端上是相当危险的事。
▌活体攻击检测方案
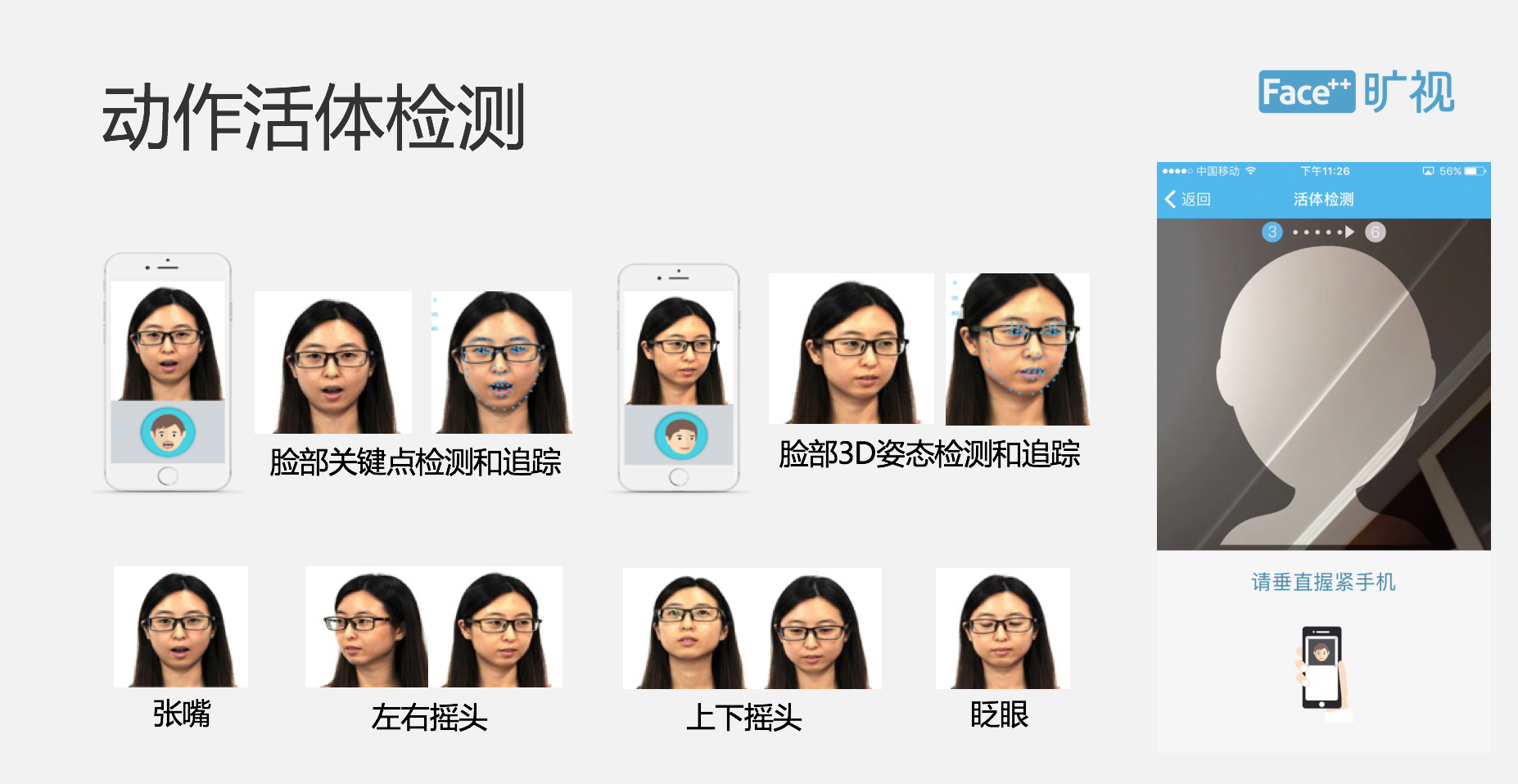
下面我们来去讨论一下最重要的活体攻击。在我们的产品里面提供了多种活体攻击的检测方案,包括随机、动态的活体,包括视频活体、炫彩活体等等。活体检测是我们整个 Face ID 最重要的一环,也是我们最重要的核心优势。这个 PPT 展示的是我们的动作活体,用户可以根据我们的 UI 提示进行点头、摇头这样的随机动作,所以我们每次随机动作都是 Serves 端去发出的,这样也保证我们整个动作的安全性。这里面有些技术细节,包括人脸质量检测,人脸关键点的感测跟跟踪,脸部的 3D 姿态的检测。这是我们整个技术的一些核心竞争力。然后我们会帮助用户定义一套 UI 界面,如果用户觉得我们 UI 界面不好也可以直接去修改。
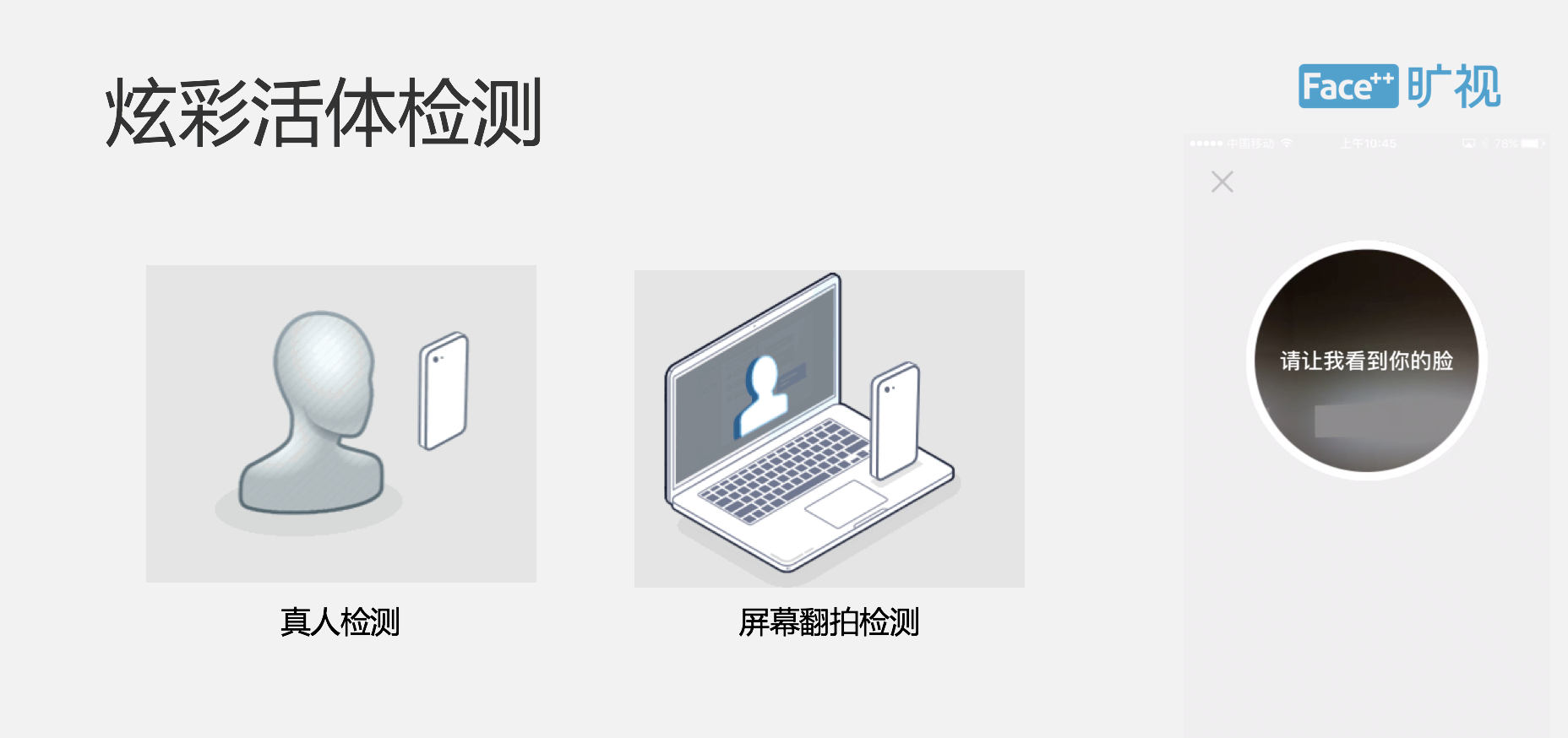
我们提供一种叫炫彩活体的检测方法,这个是 Face++ 独特独创的一种根据反射光三维成像的原理进行活体检测,从原理上杜绝了各种用 3D 软件合成的视频、屏幕翻拍等等的攻击。从产品形态上来说本身又是一个视频,现在可能看不到,就是屏幕会发出一种特定图案进行活体判断。
现在活体有一个比较大的问题是当在强光下它的质量检测方法,效果不太好,我们在最后会配合一个简单的点图动作,这样就提高了整个攻击的门槛,然后针对移动 H5 的场景我们主要推出了一个视频活体的检测方法,用户会根据 UI 提供的一个数字去读这样一个四位数字,同时我们会去判断,不仅会去做云方面的识别,还会做传统方面的识别,以及两者之间的语音跟声音同步检测。
这样通过这三种方案去判断就是活体检测,除了刚才我们介绍的一些比较典型的方法之外,我们也在去尝试一些新的包括双角度活体跟静默活体。双角度活体是用户拍一张正脸的自拍照与侧面自拍照,通过这种 3D 建模重建的方式来判断是不是真人,我们的双角度活体,静默活体,为用户提供一种非常好的用户体验,相当于用户拍一个两秒钟的视频。

我们会将这个视频传到云端,这样我们不仅会去做单帧的活体检测,还会去做多帧之间的这种关联性活体检测,这样通过两种动静结合的方法去判断受测人是不是真人。
除了活体检测之外,我们还提供了一套叫做 FMP 的攻击检测,可以有效去识别翻拍,面具攻击,这是在我们的云端完成的。这是我们基于大量的人脸数据训练出一套叫 FMP 的深度神经网络,并且根据线上的数据进行实时返回和调整,不断去识别准确率,这也是我们整个活体检测里一个最重要的技术难点。

▌人脸比对
活体检验之后,我们就可以进行人脸比对的环节。我先简单跟大家介绍一下人脸识别的一个基本原理:首先我们会从一幅图片里面去做人脸检测并做出标识,相当于在一张图片里面找到这张人脸,并且表示出整个人脸上的一些基本关键点,如眼睛、眉毛等等。
下面要做的是将一些人脸关键点进行对齐,作用是为之后的人脸识别算法提供数据预处理,可以提高整个算法准确度。然后,我们会把整个人脸的那部分抠出来,这样就可以避免周围物体对它的影响,抠完之后的人脸会经过深度学习网络,最终生成一个叫做表示的东西,可以把表示理解为这张图片生成的一张向量,认为是在机器认知里面这张图片就是通过这样的向量来进行表示的。但这个怎么样去衡量这个标识能够真实的刻画出这张真实的人脸?
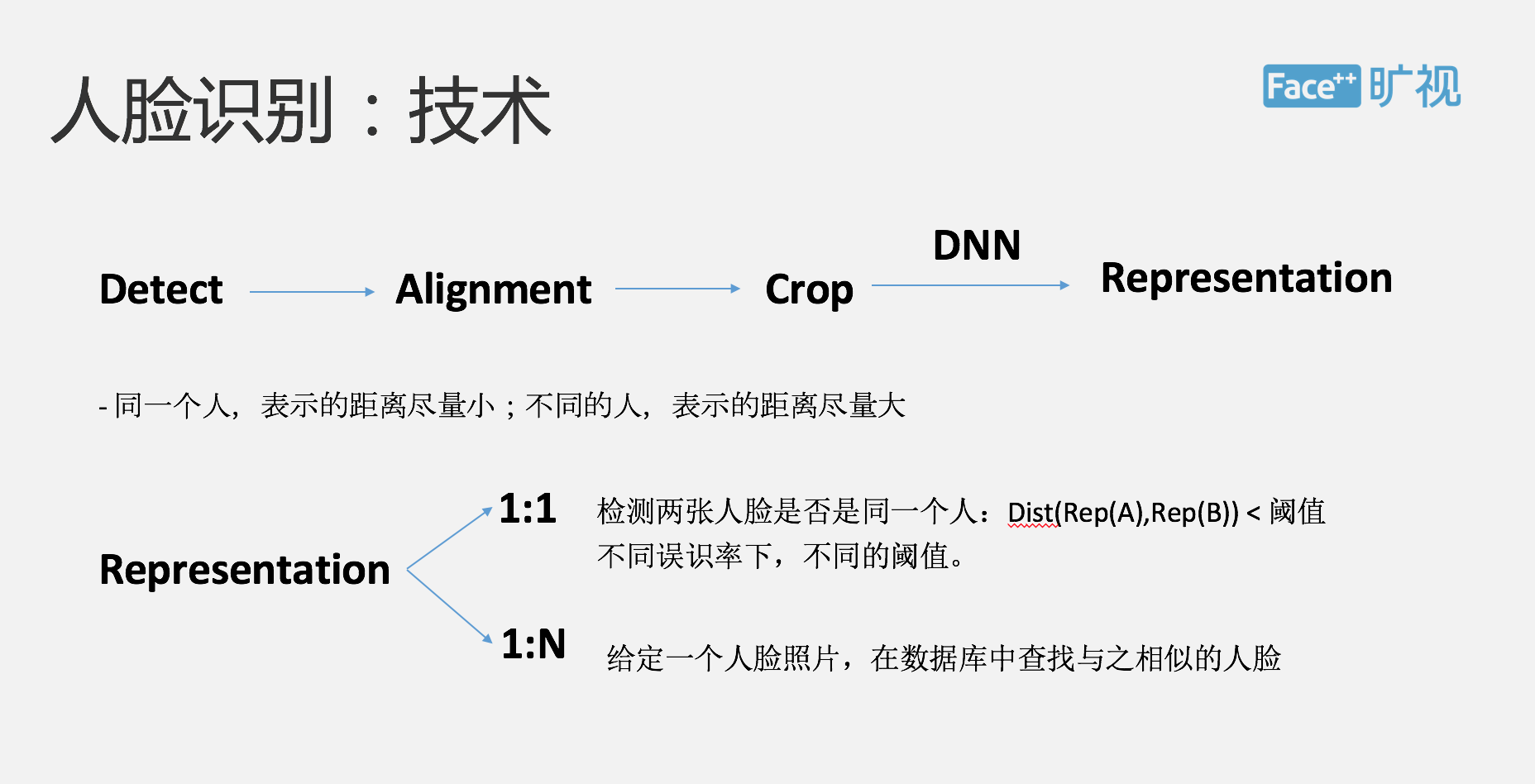
我们现在有个原则:如果同一个人,我们希望表示之间的距离要尽量的近,如果是不同的人,我们希望表示的距离尽量的远,这就是我们去评价一个深度学习出来的一个表示好坏。然后基于这样的表示,在人脸识别里边有两个比较大的应用,我们分别叫做 1:1 与 1:N 的识别。
前者主要是比较两张人脸识别是不是同一个人,它的原理是我们去计算两张人脸表示的距离,如果这个距离小于一个域值,我们就会认为这个是同一个人,如果是大于某一域值,我们就认为它不是同一个人,在不同的误识率下,我们会提供不同的域值。第二个 1:N 的应用,主要应用场景是安防,也就是说我们提供一张人脸照片,在数据库里面去查找已知,最相似的这样一个人脸是 1:7 的应用,FaceID 主要应用的技术场景是 1:1。
当我们通过 OCR 去识别出来用户姓名、身份证号,并通过活体检测之后,我们会从公安部的权威数据库里面去获得一张权威照片,会跟用户视频采集到的一张高质量照片进行比对,会返回给用户是不是一致,当然我们不会去直接告诉用户是不是一致,而是会通过这种近似度的方式告知。
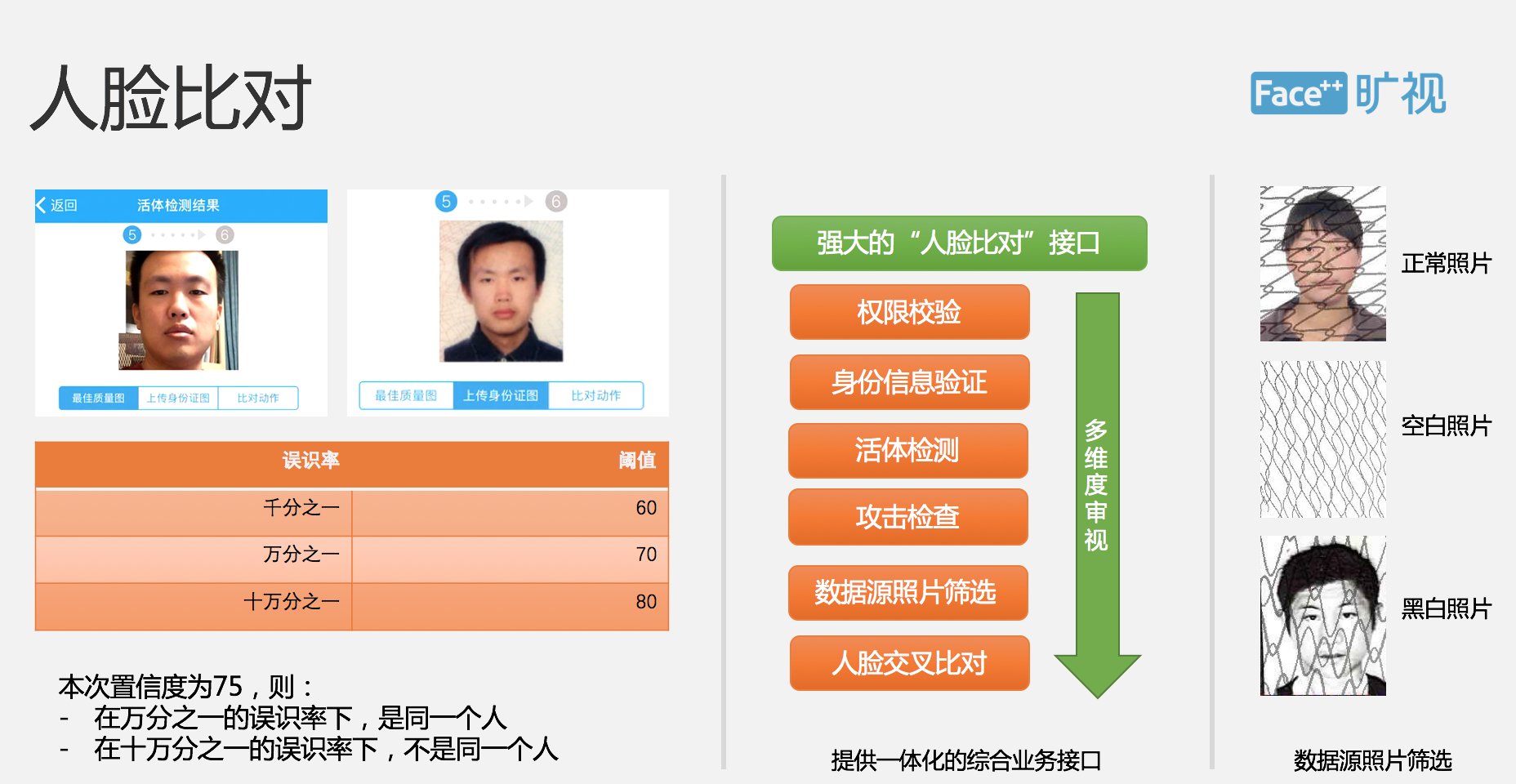
大家可以看一下左侧的这张表,然后这边的返回值里面提供了千分之一、万分之一、十万分之一不同的近似度,这些表示的是误识率,在不同的误识率下会有一个域值,假设我们认为在千分之一误识率下,如果分数大于 60 分,我们就会认为是同一个人,所以这两张照片,我发现他们的这个近似度是 75,我们会说在万分之一的误识率下是同一个人,但是在十万分之一这种误识率下可能他们不是同一个人。
这里有一个细节是我们的照片数据源可能会提供不同的整个时间造成不同的障碍,正常的话,我们会有一个不同的这种纹理图案,但是有时我们会获得一张空白照片,或者获得一张黑白照片,这也需要我们去做一些后台方面的处理。
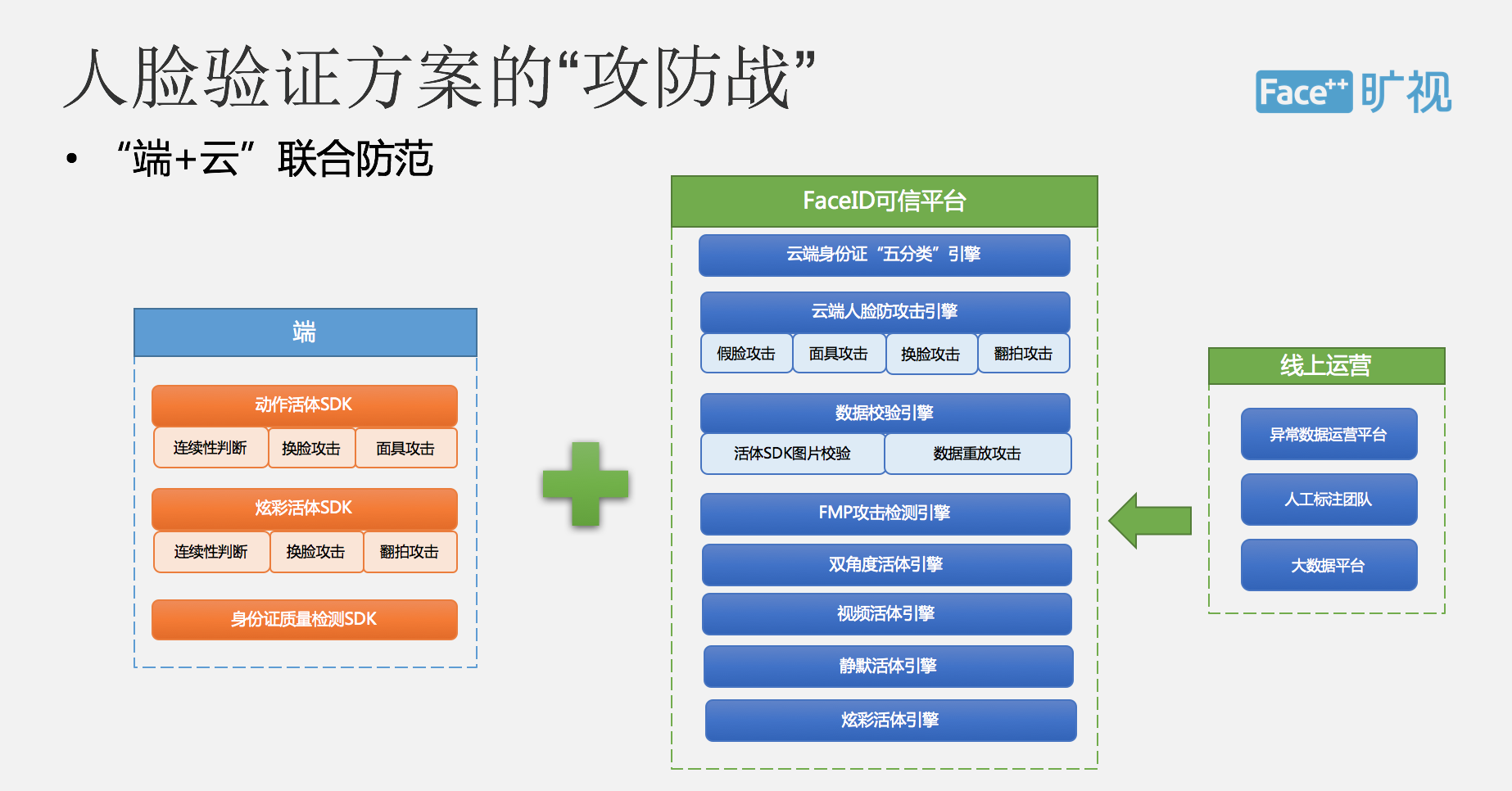
所以总结一下就是 Face ID 会为大家提供一整套的这种身份验证解决方案,整个方案涵盖了质量检测、身份证识别、活体检测、攻击检测和人脸比对等一系列的功能,其中在活体检测方面,我们采用了云加端的这种联合防范方式,通过不同的活体检测方案,包括动作活体、视频活体、静默活体等一系列的检测方法,可以有效的预防假脸攻击。
在线上我们每天都会遇到各种各样的攻击方式,整个人脸验证的方案是一套长期攻防战,我们现在通过线上运营的方式不断去收集攻击的异常数据,进行人工标注、训练、分析,然后可以不断提升整个模型的防范能力,在这方面我们已经形成了一套闭环系统,发现任何的攻击我们都可以在很短的时间内去更新线上的一些模型,做到充分防范。
▌工业化AI算法生产
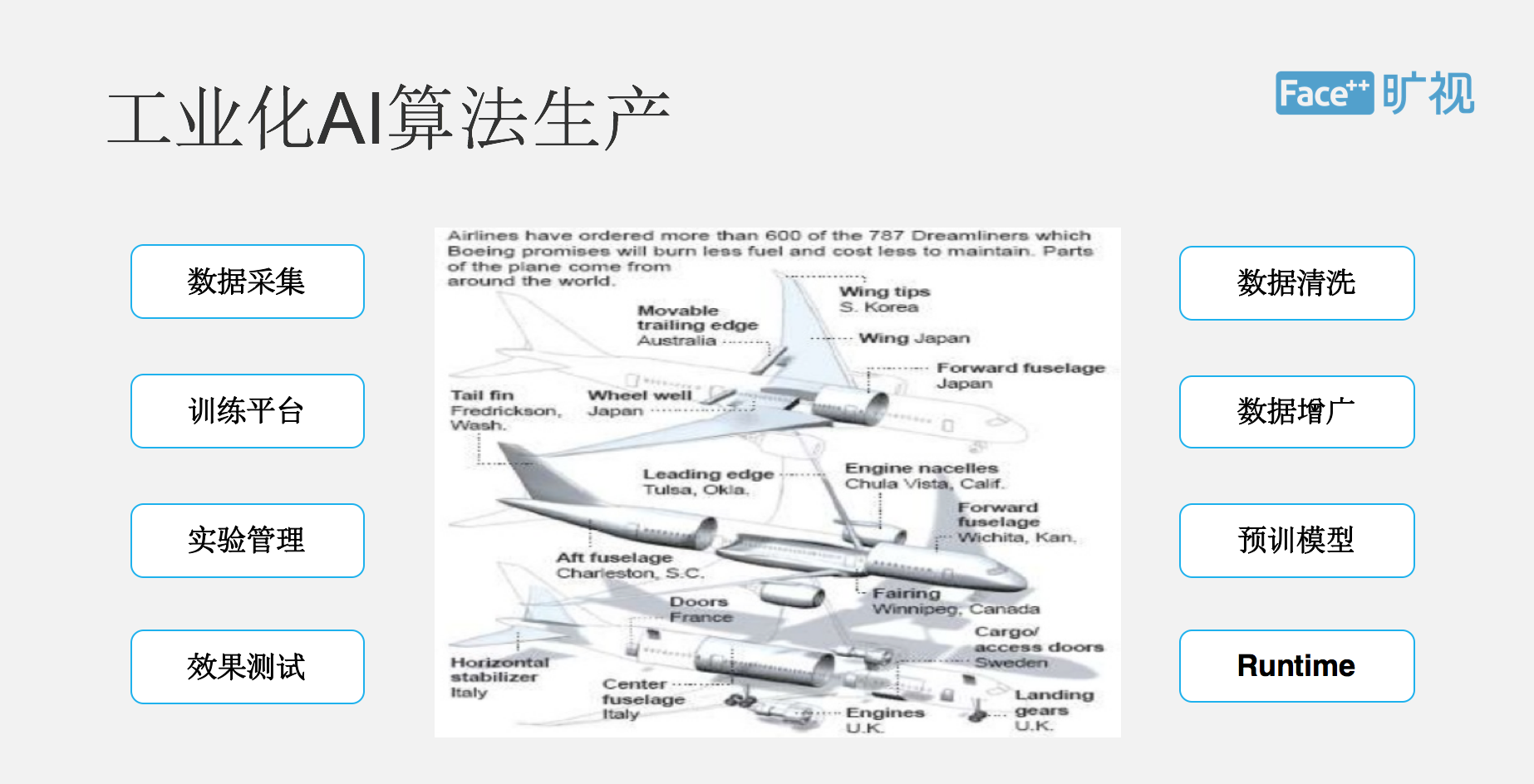
下面我简单介绍一下整个工业化 AI 算法的一个产生过程,其实整个流程可以看成是数据驱动,包括数据采集、清洗、标注,包括数据增广、数据的域训练模型、时间管理,还有 SDK 封装等等。
介绍一些核心关键点,第一个是数据采集,我们是通过一个叫做 Data++ 的 Team 去负责数据采集跟标注,我们会通过线下采集,或者是通过重包标注和网络爬虫几种方式去获取整个的 AI 训练原材料。
有了数据之后,我们一个叫 Brain++的平台可以把它看成是整个 AI 芯片的一个炼丹炉,它会提供整个计算存储网络等 IaaS 层的一些管理,这样我们整个算法工程师训练的时候相当于在单机上面去跑,但在不同分布式的底层调度是在多台机器上面,已经通过 Brain++ 的平台把我们屏蔽掉了,所以如果我们可以去写类似于的语句,需要 20 个 CPU、 4 个 GPU、8G 的内存去跑这样一个训练脚本,底下是通过分布式方法去训练的,但我们提供单向运行脚本就可以了。
然后除了数据,IaaS 层的这种资源,我们研发了一套类似于 TensorFlow 的并行计算框架和引擎 Megbrain,跟 TensorFlow 相比,很多地方都做了不同优化。
下面说一下我们的域训练模型,我们的团队去训练出成千上万这种域训练的模型,这张图展示的部分域训练模型,后面这张图的每个点都是一次实验,如果是好的实验,我们就会放在一个网站上供其他算法工程师使用,我们希望通过一套时间管理的平台去帮他们去整理整个时间思路,以及整个实验的循环关系。
有了前面的这些 Face Model, IaaS 层资源,还有数据、时间管理,剩下的就要发挥各个算法工程师的想象力了,大家每天都会去读各种 Paper,去想各种复杂精要的这种网络设计的方案,从而创造出性能非常好的网络模型。所以工业化的 AI 生产现在已经是团体作战了,我们会有各种的体系支持,大家去这些已有资源上面去创作,生成一套完整的 AI 体系。
(文章题图来自于pixabay)
人脸识别中的活体检测
早在指纹识别应用中就有针对于活体手指的检测技术,即使机器只对真人活体指纹产生识别反应,对其他一切物质不作识别,用于指纹识别产品如考勤机、门禁系统等。活体指纹识别的原理比较简单:如识别皮肤的温度、人体皮肤的电容值等。
本文主要是针对人脸识别应用中出现的人脸活体检测做简要调研及论述。有关人脸检测相关内容可以参考我的另一篇文章——人脸检测与深度学习 传送门~知乎专栏
引言——人脸识别技术迈向更高层次的一大障碍:活体检测
随着线上支付的不断普及,相关的人脸识别等技术正在中国不断进步。近日,麻省理工科技评论评出全球十大突破技术,其中由“刷脸支付——Paying with Your Face”榜上有名。
技术突破:人脸识别技术如今已经可以十分精确,在网络交易等相关领域已被广泛使用。
重大意义:该技术提供了一种安全并且十分方便的支付方式,但是或许仍存在隐私泄露问题
目前基于深度学习的发展,我认为还有一个问题就是存在被伪造合法用户人脸的攻击的风险。
——————————————- 更新补充分割线 ————————————————
评论区有问到这方面的开源代码,我这边没有仔细找过,在github找了一些相关代码,没有验证过,汇总了一下希望对大家有帮助:
1.C++代码 https://github.com/allenyangyl/Face_Liveness_Detection
2.https://github.com/rienheuver/face-antispoofing-LBP
3.https://github.com/OeslleLucena/FASNet
4.论文Person Specific Face Anti-Spoofing with Subject Domain Adaptation 对应的代码——https://github.com/jwyang/Person-Specific-Face-Anti-Spoofing
6.论文Face anti-spoofing based on color texture analysis基于颜色纹理分析的代码——https://github.com/zboulkenafet/Face-anti-spoofing-based-on-color-texture-analysis
7.https://github.com/pp21/Guided-Scale-Texture-for-Face-Presentation-Attack-Detection
8.3d头套的https://github.com/Marco-Z/Spoofing-Face-Recognition-With-3D-Masks
9.https://github.com/number9473/nn-algorithm/issues/37
10.下文中提到的几个数据库的下载链接:https://github.com/number9473/nn-algorithm/issues/36
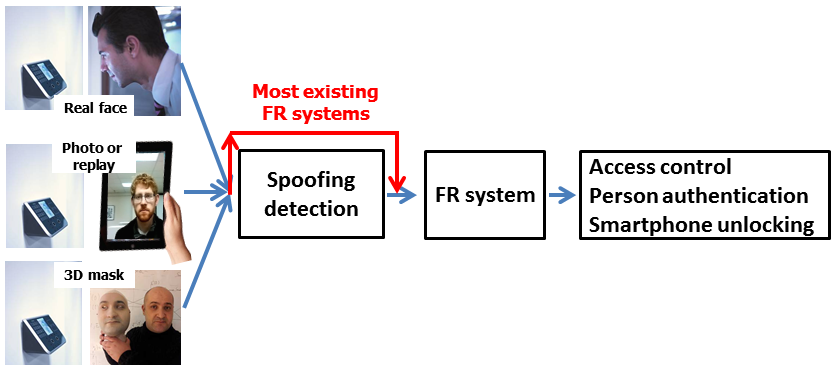
11.活体检测在人脸识别系统中处于的位置,大部分现有的系统是没有活体检测的:
 12.文中文献[11]的基于图像失真特征提取分析的活体检测的整体框架图:
12.文中文献[11]的基于图像失真特征提取分析的活体检测的整体框架图:
(15年4月TIFS的提出一种基于图像失真分析(IDA)的人脸活体检测方法。IDA特征向量分别由镜面反射(打印纸张或者LCD屏幕3维)、模糊程度(重采集—散焦2维)、图像色度和对比度退化(对比度失真15维)、颜色多样性(打印机或LCD颜色分辨率有限等101维)四种典型特征组成(121维向量),通过输入基于SVM的集成分类器(ensemble classfier),训练分类出二值真伪结果(voting scheme——用于判断视频攻击的情况,超过50%帧数为真即认定为活体))
其他一些有意思的参考
1.https://github.com/4x7y/FakeImageKiller
2.https://github.com/waghaoxg/whx-temp/tree/c2801685b3188492b6693de1e361db3c52b9b7d6
——————————————— 以下正文 ——————————————————
和指纹、虹膜等生物特征相比,人脸特征是最容易获取的。人脸识别系统逐渐开始商用,并向着自动化、无人监督化的趋势发展,然而目前人脸识别技术能识别人脸图像的身份但无法准确辨别所输入人脸的真伪。那么如何自动地、高效地辨别图像真伪抵抗欺骗攻击以确保系统安全已成为人脸识别技术中一个迫切需要解决的问题。
通常意义上的活体检测是当生物特征信息从合法用户那里取得时,判断该生物信息是否从具有生物活体的合法用户身上取的。活体检测的方法主要是通过识别活体上的生理信息来进行,它把生理信息作为生命特征来区分用照片、硅胶、塑料等非生命物质伪造的生物特征。

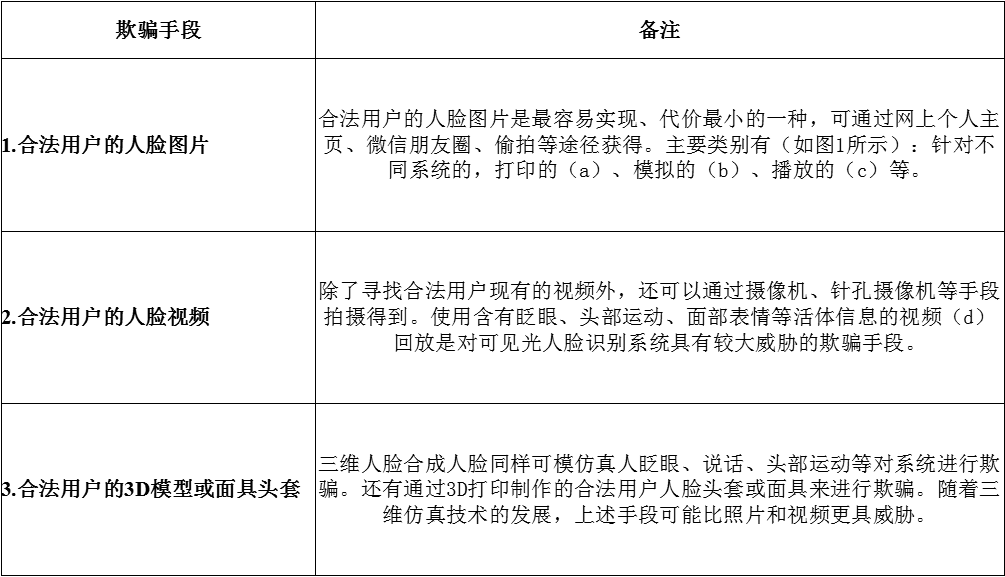
人脸识别技术面临着三种欺诈手段:
下面通过学术论文、专利发明和企业研发等三方面进行调查:
(一) 学术论文方面
人脸活体检测的学术研究机构主要有中科院自动化所李子青团队、瑞士IDAIP研究室高级研究员Sebastien Marcel主导的Biometrics group、英国南安普顿大学机器视觉系教授Mark S. Nixon所属的视觉学习与控制研究组和国际生物特征识别著名专家Anil K. Jain所在的密歇根州立大学生物特征识别研究组。近些年上述机构所著的关于活体检测的高质量文章陆续发表在IEEE TIFS/TIP等一些顶级期刊,同时Springer于2014年出版了由Sebastien Marcel等编著的《Handbook of Biometric Anti-Spoofing》,书中深入介绍了指纹、人脸、声音、虹膜、步态等生物特征识别反欺骗的方法,还对涉及的性能评估指标、国际标准、法律层面、道德问题等作了阐述,为生物特征识别反欺骗技术的进一步发展作出重要贡献。
1. 综述文献[1]将活体检测技术分为运动信息分析、纹理信息分析、活体部位分析三种,文中讨论了基于真伪图像存在的非刚性运动、噪声差异、人脸背景依赖等特性形成的分类器性能。
2. 文献[2]介绍了一个公开的人脸活体检测验证数据库(PHOTO-ATTACK),在数据库(PRINT-ATTACK)的基础上进行了扩展,添加移动手机拍摄照片和高分辨率屏幕照片。同时文中提出了一种基于光流法的前后景相关性分析来辨别影像真伪,取得较好的性能。
3. 文献[3]针对多生物识别欺骗稳健性的提高,提出一种异常检测新技术,首先通过中值滤波器来提高传统集成方法中求和准则的容差,再通过一种基于bagging策略的检测算法提高检测拒绝度,该算法融合了2D-Gabor特征、灰度共生矩阵(GLCM)多种特征、傅里叶变换的频域信息,特征提取后得到3种特征向量,使用主成分分析(PCA)降维选取形成混合特征,输入bagging分类器并获得检测结果,实验表明算法具有较高准确性。
4. 文献[4]提出一种基于颜色纹理分析的活体检测算法,通过LBP描述子提取联合颜色(RGB、HSV和YCbCr)纹理信息来表征图像,将信息输入SVM分类器进行真伪辨别。
5. 14年TIP的文献[5]提出一种基于图像质量评价的方法来增强生物特征识别的安全性,使用25种图像质量分析指标(列出较关键的几个有:像素差异性分析、相关性分析、边缘特征分析、光谱差异性、结构相似性、失真程度分析、自然影像估计),该方法只需要一张图片就可以区别真伪,适用于多种生物特征识别场合,速度快,实时性强,且不需要附近设备及交互信息。
6. 14年12月发表在TIFS的文献[6]提出一种反欺骗能力评估框架—Expected Performance and Spoofability (EPS)Framework,针对现有反欺骗系统作性能评估,创新性地指出在一定条件下验证系统将失去二值特性转变为三类:活体合法用户、无用攻击者(zero-effort)和欺骗攻击者,EPS框架主要通过测量系统期望达到的FAR(错误接受无用率)和SFAR(错误接受欺骗率)及两者之间的范围,同时考虑系统被欺骗的成本和系统存在的弱点,并量化为单一的值用来评价系统优劣。
7. 15年5月发表在TIFS的文章[7]针对视频回放攻击提出一种基于visual rhythm analysis的活体检测方法,文中指出:由于静态背景易获得,基于背景的方法显得容易被破解;利用照片的旋转和扭曲也可以轻易模拟并欺骗基于光流法的活体检测系统;当攻击视频包含头部、嘴唇、眼睛等动作可以容易通过基于运动交互的系统;文中对傅里叶变换后的视频计算水平和垂直的视觉节奏,采用三种特征(LBP、灰度共生矩阵GCLM、HOG)来对visual rhythm表征与降维,利用SVM分类器和PLS(偏最小二乘)来辨别视频真伪。
8. 15年4月TIFS的文章[8]提出一种基于局部纹理特征描述子的活体检测方法,文中将现有的活体检测方法分为三类:动态特征分析(眨眼)、全局特征分析(图像质量)和局部特征分析(LBP、LBQ、Dense SIFT)。提出的方法对一系列特征向量进行独立量化或联合量化并编码得到对应的图像标量描述子,文中实验部分给出不同局部特征对应的性能。
9. 15年8月TIP的文章[9]在面向手机端的人脸识别活体检测的需求,根据伪造照片相对于活体照片有光照反射特性呈现出更加均衡扩散缓慢的特点,提出一种基于图像扩散(反射)速度模型(Diffusion Speed Model)的活体检测方法,通过引入全变差流(TV)来获得扩散速度,在得到的扩散速度图基础上利用LSP编码(类似LBP)获取的局部速度特征向量作为线性SVM分类器的输入,经分类区分输入影像的真伪。
10. 15年12月TIP文献[10]提出一种基于码本(codebook)算法的新型人脸活体检测方法,根据重采样导致伪造影像出现的条带效应和摩尔纹等噪声现象,文中通过三个步骤来完成分类,第一步:计算视频噪声残差,通过将原始视频和经高斯滤波以后的视频作残差得到噪声视频,再对其作二维傅里叶变换得到频域信息,可以看到伪造视频的幅度谱和相位谱中呈现出明显的摩尔纹及模糊等区别,计算得到相关时频描述子。第二步通过码本算法迭代选取最能表示的descriptor,经过编码将这些描述子转化成新的矩阵表示(矩阵不能直接拿来分类),故用池化(pooling)方法(列求和或取最大值)得到输入向量。第三步利用SVM分类器或PLS(偏最小二乘)对输入向量分类判断其真伪。
11. 15年4月TIFS的文献[11]提出一种基于图像失真分析(IDA)的人脸活体检测方法,同时给出了一个由多种设备采集的人脸活体检测数据库(MSU-MFSD)。IDA特征向量分别由镜面反射(打印纸张或者LCD屏幕3维)、模糊程度(重采集—散焦2维)、图像色度和对比度退化(对比度失真15维)、颜色多样性(打印机或LCD颜色分辨率有限等101维)四种典型特征组成(121维向量),通过输入基于SVM的集成分类器(ensemble classfier),训练分类出二值真伪结果(voting scheme——用于判断视频攻击的情况,超过50%帧数为真即认定为活体)。
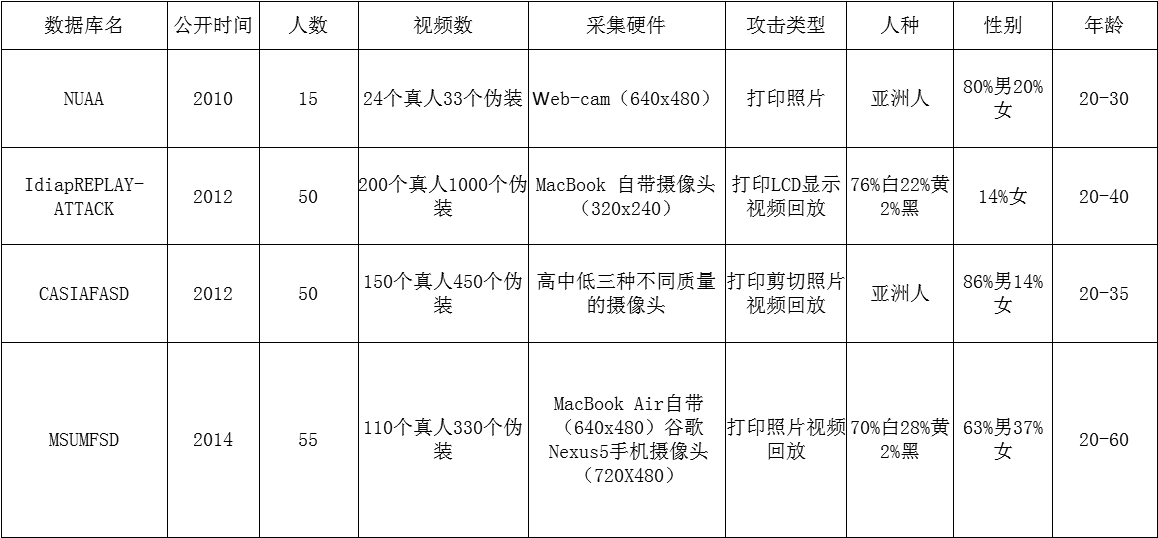
12. 几种公开的人脸活体检测数据库:
(二)专利发明方面
对于以研发产品为主的公司来说,用户的体验是检验产品成功的最重要的标准之一。下面从用户的配合程度来分类人脸活体检测技术。
(1) 根据真人图像是一次成像的原理,其比照片包含更多的中频细节信息,专利1[12]首先采用DoG滤波器获取图像信息中的中频带信息,然后通过傅里叶变换提取关键特征,最后通过logistic回归分类器对提取和处理后的特征信息辨析和分类,已达到所识别的图像为真实人脸还是照片人脸的目的。优点:不添加额外的复制设备、不需要用户的主动配合、实现简单、计算量小且功能独立;缺点:采集的正反样本要全面,只针对照片。
(2) 专利2[13]是通过检测人脸的眼睛区域是否存在亮瞳效应来区分真实人脸和照片视频中的人脸。亮瞳效应的判断是利用亮暗瞳差分图像的眼睛区域是否存在圆形亮斑而定。另外,采集亮瞳图像所涉及的设备包括红外摄像头和由LED灯做成的红外光源。优点:照片和视频都可以,使可靠性增加;缺点:需额外的设备。
(3) 专利3[14]利用共生矩阵和小波分析进行活体人脸检测。该方案将人脸区域的灰度图像首先进行16级灰度压缩,之后分别计算4个灰度共生矩阵(取矩阵为1,角度分别为0。、45。、90。、135。),然后在灰度共生矩阵的基础上再提取能量、熵、惯性矩和相关性四个纹理特征量,再次分别对四个灰度共生矩阵的4个纹理特征量求均值和方差;同时对原始图像利用Haar小波基进行二级分解,提取子带HH1,HH2的系数矩阵后求均值和方差;最后将所有的特征值作为待检测样本送入训练后的支持向量机中进行检测,分类识别真实和假冒人脸图像。优点:不需添加额外的辅助设备、不需要用户降低了计算复杂度,提高了检测准确率;缺点:只针对照片欺骗。
(4) 专利4[15]是一种基于HSV颜色空间统计特征的人脸活体检测方法,该方案将人脸图像从RGB颜色空间转换到YCrCb;然后进行预处理(肤色分割处理、去噪处理、数学形态学处理和标定连通区域边界处理)后获取人脸矩形区域的坐标;再对待检测的人脸图像分图像块,并获取待检测的人脸图像中的左右图像块的三个颜色分量的特征值;最后将归一化的特征值作为待检测样本送入训练好的支持向量中进行检测,确定包含人脸的图像是否为活体真实人脸图像。优点:不需添加额外的辅助设备和用户的主动配合,降低了人脸认证系统延时和计算复杂度,提高了检测准确率;缺点:只针对照片欺骗,阈值的设置为经验值。
(5) 专利5[16]使用的活体识别方法为通过摄像头在一定时间内拍摄多张人脸照片,预处理后提取每张照片的面部本特征信息,将先后得到的面部特征信息进行对比分析获取特征相似度,设置合理阈值,若相似度在阈值范围内,则认为有微表情产生,识别为活体,否则为非活体。优点:不需要人脸部做大量的表情配合动作;缺点:只针对照片欺骗。
(6) 专利6[17]主要基于人脸3D模型对所述人脸形状进行归一化处理,并获得所述人脸形状相对于人脸3D模型的旋转角度,将连续多帧图像的旋转角度连成一条曲线,判断该曲线是否满足设定要求,若满足,判断角度最大的一帧图像中人脸肤色区域面积比例是否大于K,若是,则判断为真实人脸,否则为虚假人脸。优点:误报率降低,速度快,用户体验好;缺点:需较大的计算时间和空间开销。
(7) 专利7[18]公开一种基于背景比对的视频和活体人脸的鉴别方法。首先对输入视频的每一帧图像进行人脸位置检测,很据检测出的人脸位置确定背景比对区域;然后选取输入视频中和背景比对区域在尺度空间上的极致点作为背景比对区域的特征点,得到背景特征点集Pt;再用Gabor小波变换描述图像I在背景特征点集Pt的特征,根据此结果定义活体度量L;如果活体度量L大于阈值θ,判断为活体,否则视为假冒视频。优点:解决仅通过单个摄像头进行视频人脸和活体人脸的计算机自动鉴别问题,不需用户配合,实时性较好;缺点:只针对视频欺骗。
(8) 专利8[19]提供了一种具有活体检测功能的双模态人脸认证方法。首先建立存储有已知身份人脸的可见光训练图像和近红外外训练图像的数据库;然后通过图像采集模块同时采集待认证人头部的可见光图像和近红外图像;采用人的脸部的人脸近红外图像与人脸可见光图像双模态特征的联合识别。优点:提高了识别认证精度,有效避免人脸存在较大变化情况下识别失败的问题,避免照片或者模型欺骗;缺点:需红外设备。
(9) 为更好地防止活体检测中的照片和视频剪辑方式等欺诈行为,专利9[20]不同之处在于,用户并不知道系统发出何种指令,要求用户做出何种动作,而且用户实现也并不知晓系统要求的动作完成次数。原因在于,预先定义了一个动作集(包括眨眼、扬眉、闭眼、瞪眼、微笑等),用户在进行活体检测时,系统每次都从动作集中选择一种或若干种动作,随机指定完成动作的次数,要求用户在规定的时间内完成它们。优点:更好地防止活体检测中的照片和视频剪辑方式等欺骗行为,活性检测的可靠性和安全性更高;缺点:需用户主动配合,容易受外部环境影响。
(10) 专利10[21]主要利用人脸面部运动和生理性运动来判断是照片还是真实人脸。人脸检测结果框内的人脸面部运动是在眼睛和嘴附近进行判断,依据运动区域中心坐标和人脸的眼睛的位置坐标之间,以及和嘴的位置坐标之间的欧式距离是否小于预定阈值。确定人脸生理性运动是根据运动区域内的运动方向为垂直方向的原理。优点:可靠性提高;缺点:只针对照片欺骗。
(11) 专利11[22]根据光流场对物体运动比较敏感,而真实人脸的眼部在姿势校正和眨眼过程中又比照片产生更大的光流,利用LK算法计算输入视频序列中相邻两帧的光流场,求得光流幅值,得到幅值较大的像素点数所占的比重,若比例足够大则标定为眼部发生了运动,从而判定为真实人脸。优点:系统的隐蔽性和安全性增强。缺点:只针对照片欺骗。
(12) 专利12[23]也是定位眼睛和嘴巴区域。根据采集的图片帧数(包含面部中眼睛和嘴巴等关键点)和特征平均差异值(由采集的两帧图片对应的特征值的加权欧式距离获得)的计算次数与预设值的比较,以及平均差异值与阈值的比较来判定是否为真实人脸。优点:解决了采用三维深度信息进行人脸活体检测时,计算量大的问题,以及应用场景约束的情况。
(13) 专利13[24]公开一种活体人脸的快速识别方法,其方案为:首先输入连续的人脸图像(若相邻两幅人脸图像不为同一状态则予以丢弃,重新多幅连续的人脸图像),对每幅人脸图像确定瞳孔位置并裁出人眼区域;然后通过支持向量机训练方法和AdaBoost训练方法对睁眼和闭眼样本进行训练,最后判断眼珠睁闭状态,若存在眨眼过程则通过活体判别。优点:有效拒绝非真实人脸欺骗识别,计算速度提高,不受应用场景的约束;缺点:需用户主动配合。
(14) 专利14[25]通过判断连续多帧图像中所获的眼睛或嘴巴区域的属性变化值(上眼皮的距离变化值或上下嘴唇间的距离变化值)的规律是否符合真实人脸的变化规律,若是,则判断为真实人脸,否则为虚假人脸。所采用的技术核心:将当前帧与前t帧的眼睛或嘴巴区域合并成一张图,采用基于深度学习的回归方法输出两帧图像中属性变化值,重复该步骤直至获得每帧图像的属性变化值;将所有属性变化值按帧时间顺序组成一向量,对各向量的长度进行设定,然后利用SVM分类器对所述向量进行分类,再判断分类结果是否满足设定动作下的真实人脸的变化规律。优点:检测精度高、速度快,针对照片和视频欺骗;缺点:需用户主动配合。
(15) 专利15[26]是通过眨眼动作进行活体检测。首先对人脸检测与眼睛定位;然后眼部区域截取,从归一化处理后的图像中图像中计算眼睛的开合程度;运用条件随机场理论建立用于判断眨眼动作的模型。优点:可仅通过单个摄像头进行鉴别;缺点:需用户主动配合,只针对照片欺骗。
(三)企业研发应用方面

对支付宝人脸登陆系统的活体检测功能进行了实际测试(iphone5S,支付宝最新版本9.5.1,人脸识别和活体检测模块是独立的,其活体检测只有采用了眨眼模式,之前还有点头),检测结果如下:

结论:
1.根据调查结果的实际应用技术,针对三种主要的欺骗手段,目前有以下几种应用广泛的活体检测方法:

2.从用户配合、对光照影响、是否需要附加设备、抵挡攻击、用户体验等方面对比了人脸识别系统中活体检测应用较多的7类具体方法,形成下表:
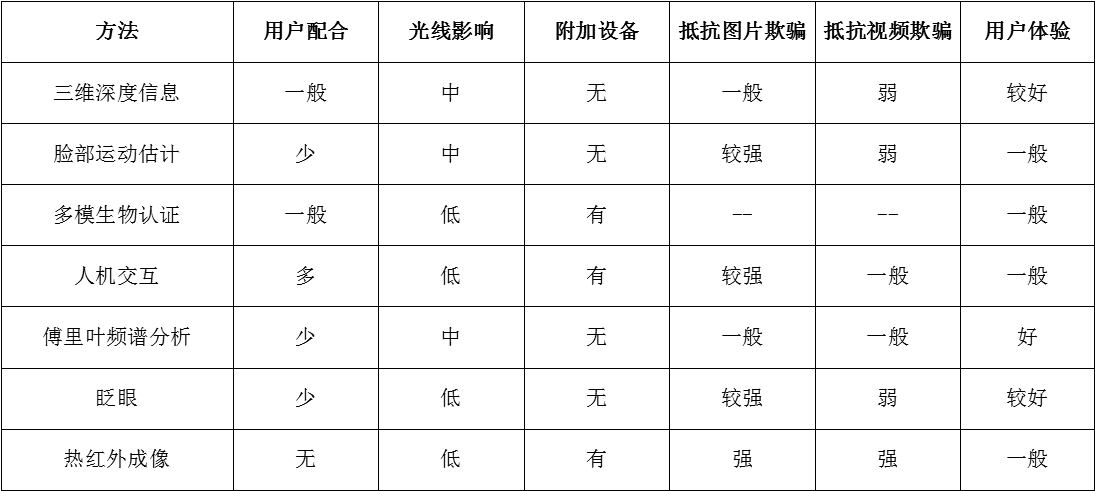
3.随着人脸识别系统的发展和演进,综上所述,研究开发一种新型高效鲁棒性好的人脸活体检测技术应该满足以下几个条件:
①在线实时处理。活体检测过程应与人脸识别同时进行,越来越多的移动端需求给实时性提出越来越高的要求;
②受光照等外界影响小。人脸识别验证系统的应用面临着许多场景,活体检测技术应满足多场景、多终端应用的要求,鲁棒性强;
③用户界面自然,交互少,欺骗代价高。基于运动等的检测方法对用户来说,增加一系列的交互操作,不仅复杂度增加,可能需要附加的硬件设备支撑,所以新型的活体检测技术应该具有良好的用户体验,同时使得欺骗攻击的代价尽可能的高,保证安全性;
④对欺骗有着优异的检测能力,同时对人脸识别特征提取起辅助作用。基于纹理或图像特征的活体检测方法是未来的主要趋势,那么这些特征的提取和分类同样能给人脸识别带来益处。
4.一种可行的人脸活体检测框架:根据总结发现,纯粹的基于和(sum-rule)的理念可能并不适合活体检测,就好比“木桶效应”,伪造攻击只要抓住了短板,一样可以破解大部分基于sum-rule的方法。一种较好的方法是与此对应的多层次结合的概念,结合文献5、8、10、11所述的相关图像特性,可以着眼于图像全局特性分析(质量)和局部特性分析(LBP等)相结合。
参考文献
[1] O. Kahm and N. Damer, “2d face liveness detection: An overview,” inb Biometrics Special Interest Group (BIOSIG), 2012 BIOSIG-Proceedings of the International Conference of the. IEEE, 2012, pp. 1–12.
[2] A. Anjos, M. M. Chakka, and S. Marcel, “Motion-based countermeasures to photo attacks in face recognition,” IET Biometrics, vol. 3,no. 3, pp. 147–158, 2013.
[3] Wild P, Radu P, Chen L, et al. Robust multimodal face and fingerprint fusion in the presence of spoofing attacks[J]. Pattern Recognition, 2016, 50: 17-25.
[4] Boulkenafet Z, Komulainen J, Hadid A. face anti-spoofing based on color texture analysis[C]//Image Processing (ICIP), 2015 IEEE International Conference on. IEEE, 2015: 2636-2640.
[5] Galbally J, Marcel S, Fierrez J. Image quality assessment for fake biometric detection: Application to iris, fingerprint, and face recognition[J]. Image Processing, IEEE Transactions on, 2014, 23(2): 710-724.
[6] Chingovska I, Rabello dos Anjos A, Marcel S. Biometrics evaluation under spoofing attacks[J]. Information Forensics and Security, IEEE Transactions on, 2014, 9(12): 2264-2276.
[7] Pinto A, Robson Schwartz W, Pedrini H, et al. Using visual rhythms for detecting video-based facial spoof attacks[J]. Information Forensics and Security, IEEE Transactions on, 2015, 10(5): 1025-1038.
[8] Gragnaniello D, Poggi G, Sansone C, et al. An investigation of local descriptors for biometric spoofing detection[J]. Information Forensics and Security, IEEE Transactions on, 2015, 10(4): 849-863.
[9] Kim W, Suh S, Han J J. Face Liveness Detection From a Single Image via Diffusion Speed Model[J]. Image Processing, IEEE Transactions on, 2015, 24(8): 2456-2465.
[10] Pinto A, Pedrini H, Robson Schwartz W, et al. Face Spoofing Detection Through Visual Codebooks of Spectral Temporal Cubes[J]. Image Processing, IEEE Transactions on, 2015, 24(12): 4726-4740.
[11] Wen D, Han H, Jain A K. Face spoof detection with image distortion analysis[J]. Information Forensics and Security, IEEE Transactions on, 2015, 10(4): 746-761.
[12] 李冀,石燕,谭晓阳.一种应用于人脸识别的活体检测方法及系统:中国,101999900.2013-04-17.
[13] 秦华标,钟启标.基于亮瞳效应的人脸活体检测方法:中国,103106397.2013-05-15.
[14] 毋立芳,曹瑜,叶澄灿等.一种基于灰度共生矩阵和小波分析的活体人脸检测方法:中国,103605958.2014-02-26.
[15] 严迪群,王让定,刘华成等.一种基于HSV颜色空间特征的活体人脸检测方法:中国,103116763.2013-05-22.
[16] 傅常顺,杨文涛,徐明亮等.一种判别活体人脸的方法:中国,104361326.2014-02-18.
[17] 陈远浩.一种基于姿态信息的活体检测方法:中国,104794465.2015-07-22.
[18] 潘纲,吴朝晖,孙霖.基于背景比对的视频和活体人脸的鉴别方法:中国,101702198.2011-11-23.
[19] 徐勇,文嘉俊,徐佳杰等.一种活体检测功能的双模态人脸认证方法和系统:中国,101964056.2012-06-27.
[20] 王先基,陈友斌.一种活体人脸检测方法与系统:中国,103440479.2013-12-11.
[21] 丁晓青,王丽婷,方驰等.一种基于人脸生理性运动的活体检测方法及系统:中国,101159016.2008-04-09.
[22] 马争鸣,李静,刘金葵等. 一种在人脸识别中应用的活体检测方法:中国,101908140.2010-12-08.
[23] 黄磊,任智杰. 一种人脸活体检测方法及系统:中国,103679118.2014-03-26.
[24] 彭飞. 一种活体人脸的快速识别方法:中国,103400122.2013-11-20.
[25] 陈元浩. 一种基于相对属性的活体检测方法:中国,104794464.2015-07-22.
[26] 吴朝晖,潘纲,孙霖. 照片人脸与活体人脸的计算机自动鉴别方法:中国,100592322.2010-02-24.
微软资深研究员详解基于交错组卷积的高效DNN | 公开课笔记
作者 | 王井东
整理 | 阿司匹林
出品 | 人工智能头条(公众号ID:AI_Thinker)
卷积神经网络在近几年获得了跨越式的发展,虽然它们在诸如图像识别任务上的效果越来越好,但是随之而来的则是模型复杂度的不断提升。越来越深、越来越复杂的卷积神经网络需要大量存储与计算资源,因此设计高效的卷积神经网络是非常重要和基础的问题,而消除卷积的冗余性是该问题主要的解决方案之一。
如何消除消除卷积的冗余性?我们邀请到了微软亚洲研究院视觉计算组资深研究员王井东博士,为大家讲解发表在 ICCV 2017 和 CVPR 2018 上基于交错组卷积的方法。
观看回放:
基于交错组卷积的高效深度神经网络 - 直播课 - CSDN学院 - 在线学习教程 - 会员免费-CSDN学院edu.csdn.net
以下是公开课内容,AI科技大本营整理,略有删减:

▌深度学习大获成功的原因
2006年《Science》上的一篇文章——Reducing the Dimensionality of Data with Neural Networks,是近十多年来促进深度学习发展非常重要的一篇文章。当时这篇文章出来的时候,很多机器学习领域的人都在关注这个工作,但是它在计算机视觉领域里并没有取得非常好的效果,所以并没有引起计算机视觉领域的人的关注。
深度学习的方法在计算机视觉领域真正得到关注是因为 2012 年的一篇文章——ImageNet Classification with Deep Convolutional Neural Networks。这个文章用深度卷积神经网络的方法赢得了计算机视觉领域里一个非常重要的 ImageNet 比赛的冠军。在 2012 年之前的冠军都是基于 SVM(支持向量机)或者随机森林的方法。
2012年 Hinton 和他的团队通过深度网络取得了非常大的成功,这个成功大到什么程度?比前一年的结果提高了十几个百分点,这是非常可观、非常了不起的提高。因为在 ImageNet 比赛上的成功,计算机视觉领域开始接受深度学习的方法。
比较这两篇文章,虽然我们都称之为深度学习,但实际上相差还挺大的。特别是 2012 年这篇文章叫“深度卷积神经网络”,简写成 “CNN”。CNN 不是 2012 年这篇文章新提出来的,在九十年代,Yann LeCun 已经把 CNN 用在数字识别里,而且取得非常大的成功,但是在很长的时间里,大家都没有拿 CNN 做 ImageNet 比赛,直到这篇文章。今天大家发现深度学习已经统治了计算机视觉领域。
为什么 2012 年深度学习能够成功?其实除了深度学习或者 CNN 的方法以外,还有两个东西,一个是 GPU,还有一个就是 ImageNet。
这个网络结构是 2012 年 Hinton 跟他学生提出的,其实这个网络结构也就8层,好像没有那么深,但当时训练这个网络非常困难,需要一个星期才训练出来,而且当时别人想复现它的结果也没有那么容易。
这篇文章以后,大家都相信神经网络越深,性能就会变得越好。这里面有几个代表性的工作,简单回顾一下。
深度网络结构的两个发展方向
▌越来越深

2014 年的 VGG,这个网络结构非常简单,就是一层一层堆积起来的,而且层与层之间非常相似。
同一年,Google 有一个网络结构,称之为“GoogLeNet”,这个网络结构看起来比 VGG 的结构复杂一点。这个网络结构刚出来的时候看起来比较复杂,今天看起来就是多分支的一个结构。刚开始,大家普遍的观点是这个网络结构是人工调出来的,没有很强的推广性。尽管 GoogLeNet 是一个人工设计的网络结构,其实这里面有非常值得借鉴的东西,包括有长有短多分支结构。
2015 年时出了一个网络结构叫 Highway。Highway 这篇文章主要是说,我们可以把 100 层的网络甚至 100 多层的网络训练得非常好。它为什么能够训练得非常好?这里面有一个概念是信息流,它通过 SkipConnection 可以把信息很快的从最前面传递到后面层去,在反向传播的时候也可以把后面的梯度很快传到前面去。这里面有一个问题,就是这个 Skip Connection 使用了 gate function,使得深度网络训练困难仍然没有真正解决。
同一年,微软的同事发明了一个网络,叫“ResNet”,这个网络跟 Highway 在某种意义上很相像,相像在什么地方?它同样用了 Skip Connection,从某一层的 output 直接跳到后面层的 output 去。这个跟 Highway 相比,它把 gate function 扔掉了,原因在于在训练非常深的网络里 gate 不是一个特别好的东西。通过这个设计,它可以把 100 多层的网络训练得非常好。后来发现,通过这招 1000 层的网络也可以训练得非常好,非常了不起。
2016年,GoogLeNet、Highway、ResNet出现以后,我们发现这里面的有长有短的多分支结构非常重要,比如我们的工作 deeply-fused nets,在多个 Branch 里面,每个分支深度是不一样的这样的好处在于,如果我们把从这个结构看成一个图的话,发现从这个输入点到那个输出点有多条路径,有的路径长,有的路径短,从这个意义上来讲,我们认为有长有短的路径可以把深度神经网络训练好。
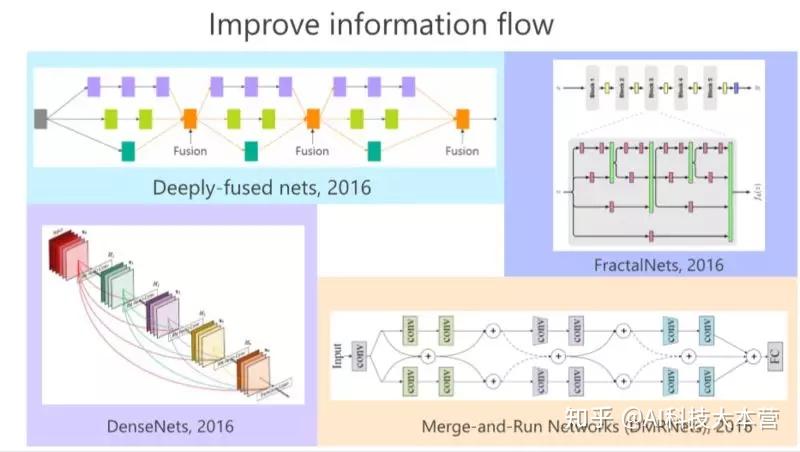
同年,我们发现有个类似的工作,叫 FractalNets,它跟我们的 deeply-fused nets 非常相像。
这条路都是通过变深,希望把网络结构训练得非常好,使它的性能非常好,加上 Skip Connection 等等形式来使得信息流非常好。尽管我们通过 Skip Connection 把深度网络训练得很不错,但深度还是带来一些问题,就是并没有把性能发挥得很好,所以有另外一个维度,大家希望变得更宽一点。
除此之外,大的网络用在实际中会遇到一些问题。比如部署到手机上时希望计算量不要太大,模型也不要太大,性能仍然要很好,所以识别率做的非常高的但是很庞大的网络结构在实际应用里面临一些困难。
▌简化结构的几种方法

另外一条路是简化网络结构,消除里面的冗余性。因为大家都认为现在深度神经网络结构里有很强的冗余性,消除冗余性是我近几年发现非常值得做的一个领域,因为它的实际用处很大。
卷积操作
CNN 里面的卷积操作实际上对应的就是矩阵向量相乘,大家做的基本就是消除卷积里的冗余性。
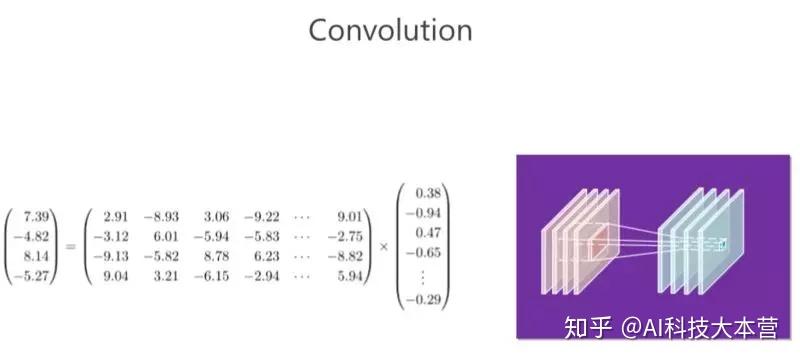
我们回顾一下卷积。右边的图:在 CNN 里面有若干个通道,每个通道实际上是一个二维的数组,每个位置都有一个数值,在这里面我们称为“响应值”。这里面有四个通道,实际上就相当于三维的数组一样。以这里(每个位置)为中心,取一个 3×3 的小块出来,3×34 个通道,那就有 3×3×4 这么多个数值,然后我们把这么多个数值拉成一个 3×3×4=36 维向量。卷积有个卷积核,卷积核对应一个横向量,这个横向量和列向量一相乘,就会得到响应的值,这是第一个卷积核。通过第二个卷积核又会得到第二个值,类似地可以得到第三个第四个值。
总结起来,卷积操作就是是矩阵和向量相乘,矩阵对应的是若干个卷积核,向量对应的是周围方块的响应值(ResponseValue)。
大家都知道矩阵跟向量相乘占了很大的计算量。我在这里举的例子并没有那么大,但大家想一想,如果输入输出 100个 通道,,假如这个卷积核是3×3×100,那就是 100×900 的计算量,这个计算量非常大,所以有大部分工作集中在解决这里面(卷积操作)冗余性的问题。
Low-precision kernels(低精度卷积核)
有什么办法解决冗余性的问题呢?

因为卷积核通常是浮点型的数,浮点型的数计算复杂度要大一点,同时它占得空间也会大一点。最简单的一招是什么?假设把卷积核变成二值的,比如 1、-1,我们看看 1、-1转成以后有什么好处?这个向量 1、-1(使得)本来相乘的操作变成加减了,这样一来计算量就减少了很多。除此以外,模型和存储量也减少很多。

也有类似相关的工作,就是把浮点型的变成整型的,比如以前 32 位浮点数的变成 16 位的整型数,同样存储量会小,或者模型会小。除了卷积核进行二值化化以外或者进行整数化以外,也可以把 Response 变成二值数或者整数。

还有一类研究得比较多的是量化。比如把这个矩阵聚类,比如 2.91、3.06、3.21,聚成一类,我用 3 来代替它量化有什么好处?首先,你的存储量减少了,不需要存储原来的数值,只需要存量化以后的每个中心的索引值就可以了。除此之外,计算量也变小了,你可以想办法让它减少乘的次数,这样就模型大小就会减少了。
Low-rank kernels(低秩卷积核)


另外一条路,矩阵大怎么办?把矩阵变小一点,所以很多人做了这件事情, 100 个(输出)通道,我把它变成 50 个,这是一招。另外一招, input(输入)很多, 100 个通道,变成了 50 个。
低秩卷积核的组合

把通道变少会不会降低性能?所以有人做了这件事情:把这个矩阵变成两个小矩阵相乘,假如这个矩阵是 100×100 的,我把它变成 100×10 和10×100 两个矩阵相乘,(相乘得到的矩阵)也变成 100×100 的矩阵,近似原来 100×100 那个矩阵。这样想想,100×100 变成 100×10 跟 10×100,显然模型变小了,变成五分之一。此外计算量也降到五分之一。
稀疏卷积核
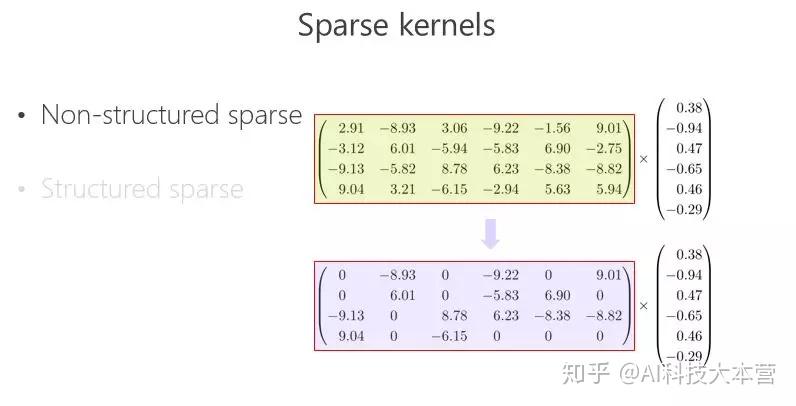
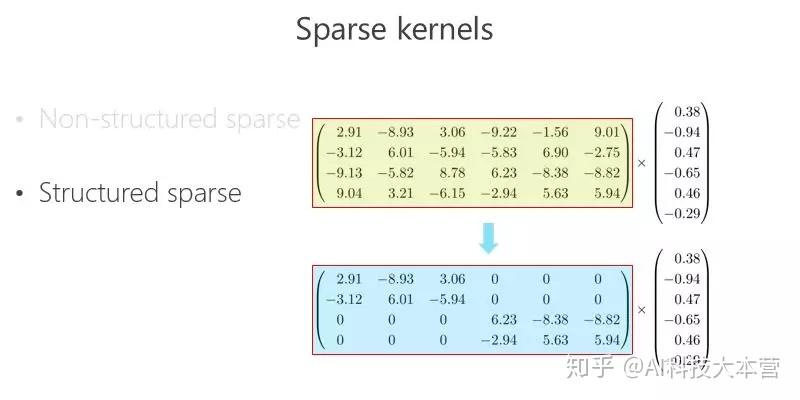
另外一条路,怎么把矩阵跟向量相乘变得快一点、模型的参数少一点?可以把里面的有些数变成 0,比如 2.91 变成 0,3.06 变成 0,变成 0 以后就成了稀疏的矩阵,这个稀疏矩阵存储量会变小,如果你足够稀疏的话,计算量会小,因为直接是 0 就不用乘了。还有一种 Structured sparse(结构化稀疏),比如这种对角形式,矩阵跟向量相乘,可以优化得很好。这里 Structured sparse 对应我后面将要讲的组卷积(Groupconvolution)。
稀疏卷积核的组合
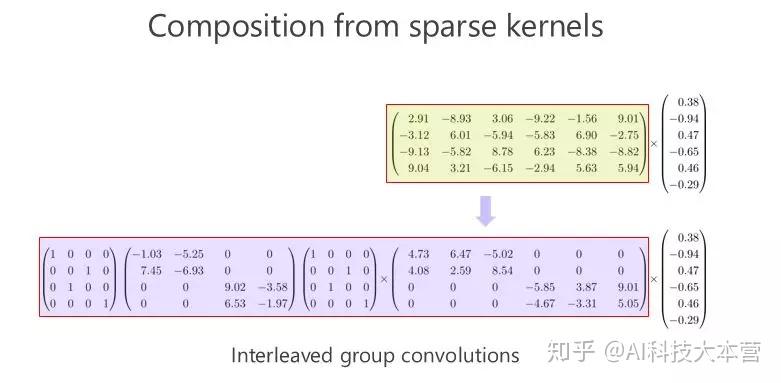
我们来看看这个矩阵能不能通过多个稀疏矩阵相乘来近似,这是我今天要讲的重点,我们的工作也是围绕这一点在往前走。在我们做这个方向之前,大家并没有意识到一个矩阵可以变成两个稀疏矩阵相乘甚至多个稀疏矩阵相乘,来达到模型小跟计算量小的目标。
从IGCV1到IGCV3
▌IGCV1
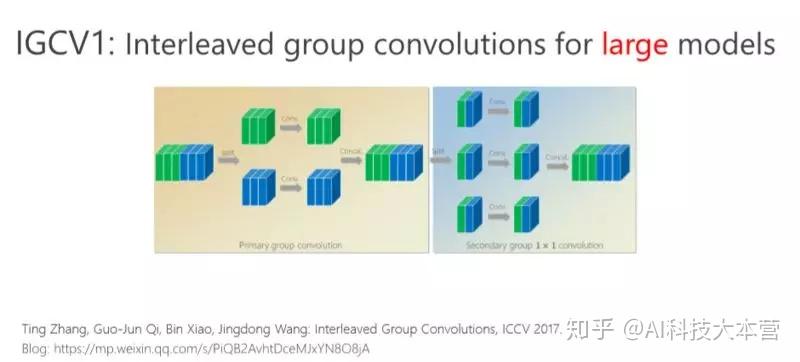
首先我给大家介绍一下我们去年在 ICCV 2017 年会议上的文章,交错组卷积的方法。
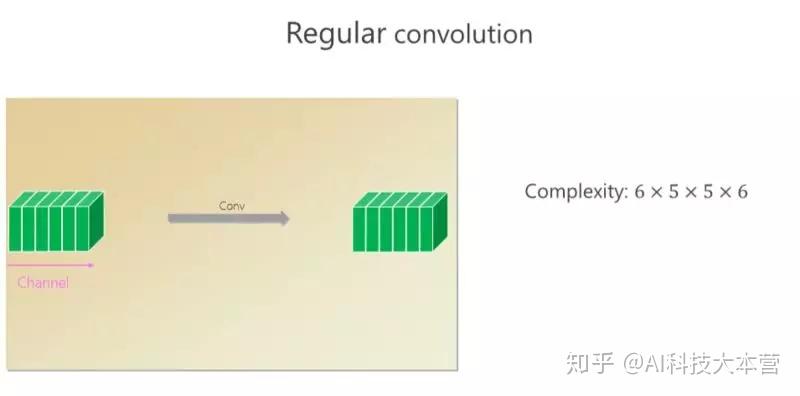
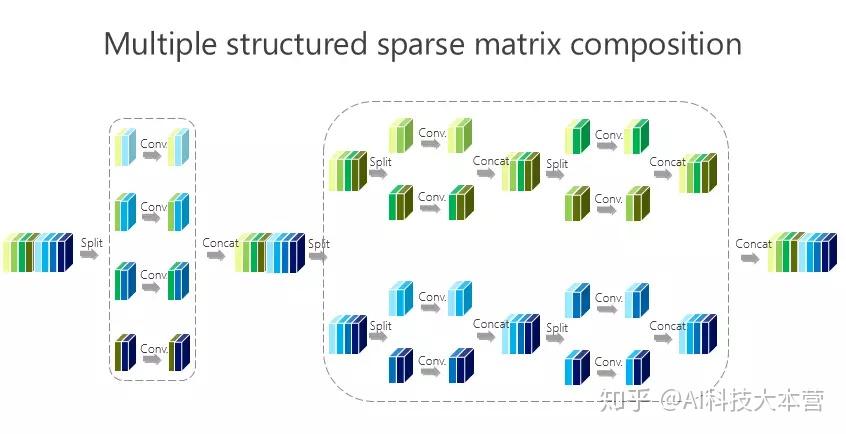
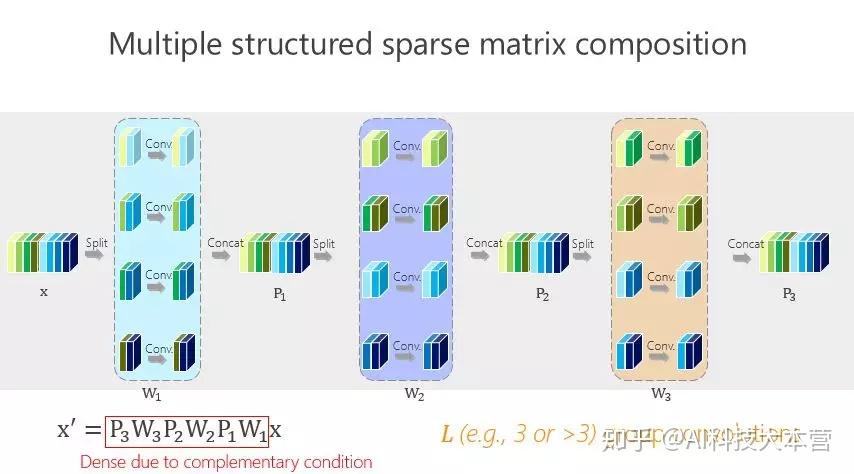
这个卷积里面有六个通道,通过卷积出来的也是六个小方块(通道),假如 spatial kernel 的尺寸是5×5,对每个位置来讲,它的计算量是6×5×5×6。
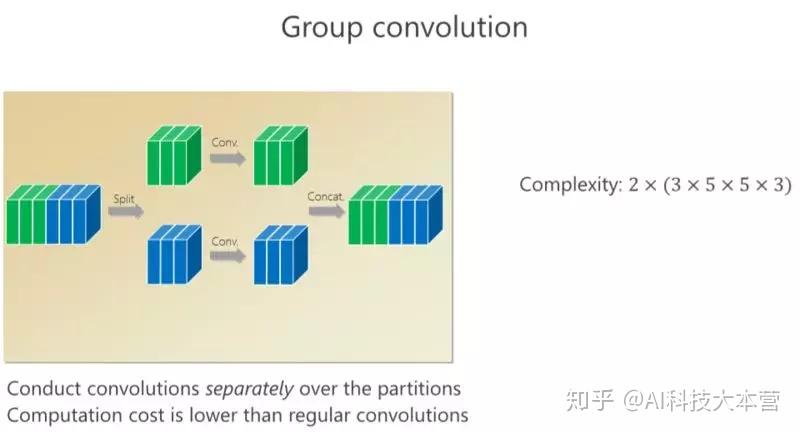
我刚才讲了(一种结构化)稀疏的形式,对应的就是组卷积的形式,组卷积是什么意思?我把这 6 个通道分成上面 3 个通道和下面 3 个通道,分别做卷积,做完以后把它们拼在一起,最后得到的是6个通道。看看计算量,上面是 3×5×5×3,下面也是一样的,整个计算复杂度跟前面的 6×5×5×6 相比就小了一半,但问题是参数利用率可能不够。
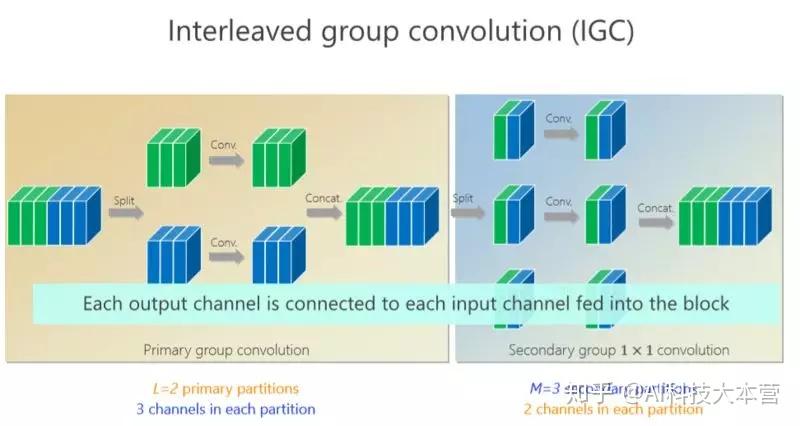
我们的工作是基于组卷积的,刚才提到了上面的三个通道和这三个通道不相关,那有没有办法让它们相关?所以我们又引进了第二个组卷积,我们把这6个通道重新排了序,1、4 放到这(第一个分支),2、5 放到这(第二个分支),3、6 放到那(第三个分支),这样每一分支再做一次 1×1 的convolution,得出新的两个通道、两个通道、两个通道,拼在一起。通过交错的方式,我们希望达到每个 output(输出)的通道(绿色的通道或者蓝色的通道)跟前面6个通道都相连。
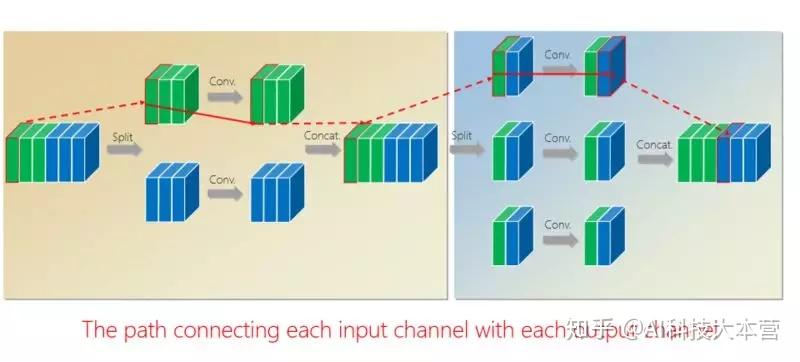
有什么好处?通过第二组的组卷积可以达到互补的条件,或者使得任何一个 output(输出通道)和任何一个 input(输入通道)连起来。

这里面我们引进了一个严格的互补条件,直观来讲就是,如果有两个通道在第一组卷积里面,落在同一个 Branch(分支),我希望在第二组里面落在不同的 Branch(分支)。第二组里面比如一个 Branch(分支)里面的若干个通道,要来自于第一个组卷积里面的所有 Branches(分支),这个称为互补条件。这个互补条件带来什么?它会带来(任何一对输入输出通道之间存在) path,也就是说相乘矩阵是密集矩阵。为什么称之为“严格的”?就是任何一个 input 和 output 之间有一条 path,而且有且只有一条path。

严格的准则引进来以后,参数量变小了、模型变小了,带来什么好处?这里我给一个结论,L 是(第)一个组卷积里面的 partitions(分支)的数目或者卷积的数目,M是第二组组卷积卷积的数目,S 是卷积核的大小,通常都是大于 1 的。这样的不等式几乎是恒成立的,这个不等式意味着什么?结论是:如果跟普通标准的卷积去比,通过我们的设计方式可以让网络变宽。跟网络变深相比起来,网络变宽是另外一个维度,变宽有什么好处?会不会让结果变好?我们做了一些实验。
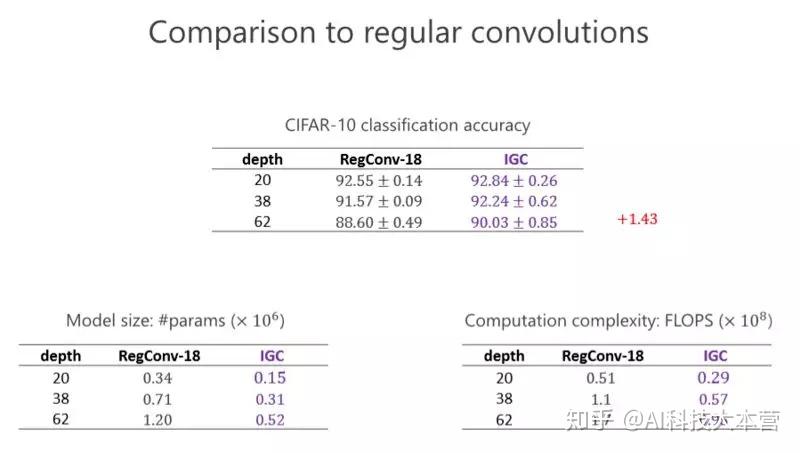
这个实验是跟标准的卷积去比,大家看看左下角的表格,这个表格是参数量,我们设计的网络几乎是标准(卷积)参数量的一半。然后看看右下角这个网络,我们的的计算量几乎也是一半。在 CIFAR-10 标准的图像分类数据集里(上面的表格),我们的结果比前面的一种好。我们甚至会发现越深越好,在 20 层有些提升并没有那么明显,但深的时候可以达到 1.43 的提高量。
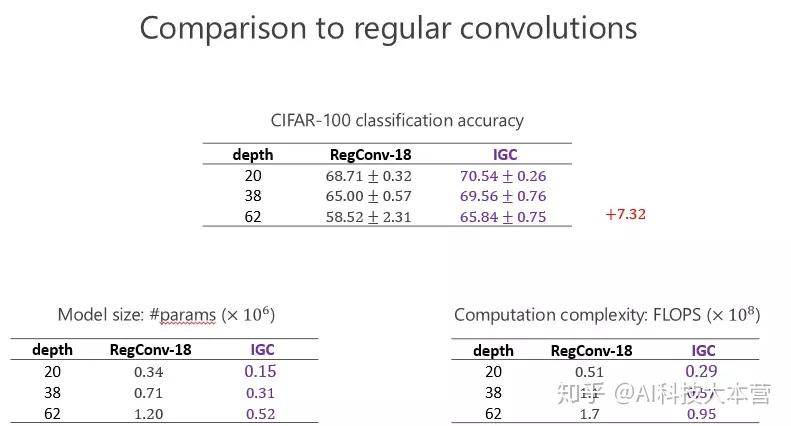
后来 CIFRA-100 我们也做了同样的实验,发现我们提升仍然是一致的,甚至跟前面的比起来提高得更大,因为分 100 类比分 10 类困难一点,说明越困难的任务,我们的优势越明显。这个变宽了以后(性能)的确变好了,通过 IGC 实现,网络结构变宽的确会带来好处。

这是两个小的数据集,其实在计算机视觉领域里小数据集上的结果是不能(完全)说明问题的,一定要做非常大的数据集。所以我们当时也做了 ImageNet 数据集,跟 ResNet 比较了一下,参数量少了近五分之二,计算量小了将近一半了,错误率也降低了,这证明通过 IGC 的实现,让模型变宽,在大的网络模型上取得非常不错的效果。
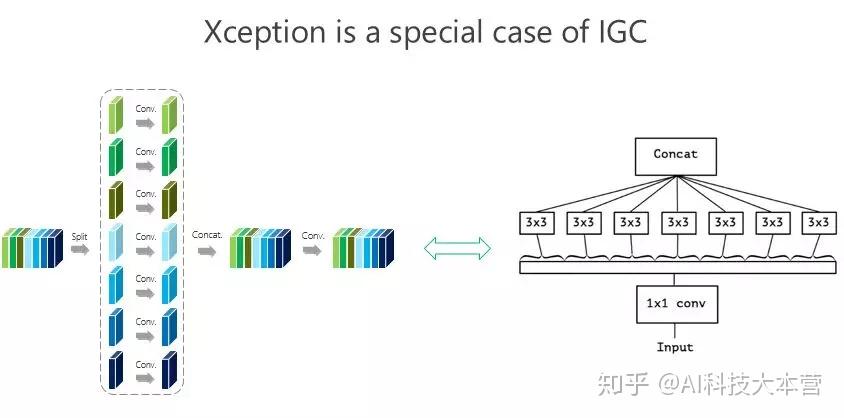
我们大概是前年 8、9 月份开始做这个事情,10 月份发现 Google 有一个工作是 Xception,这个是它的结构图,这个形式非常接近(我们的结构),跟我们前面所谓的 IGC 结构非常像,实际上就是我们的一个特例。当时我们觉得这个特例有没有可能结果最好,所以我们做了些验证,整体上我们结构好一点。
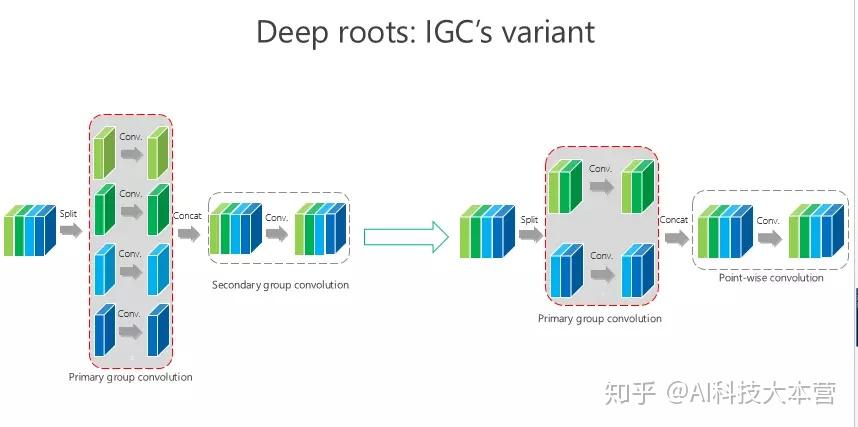
IGC 可能还有变体,比如我要是把这个 channel-wise 也变成组卷积,第二个是 1×1 的,这样的结果会怎样?我们做了类似同样的实验,仍然发现我们的方法是最好的。
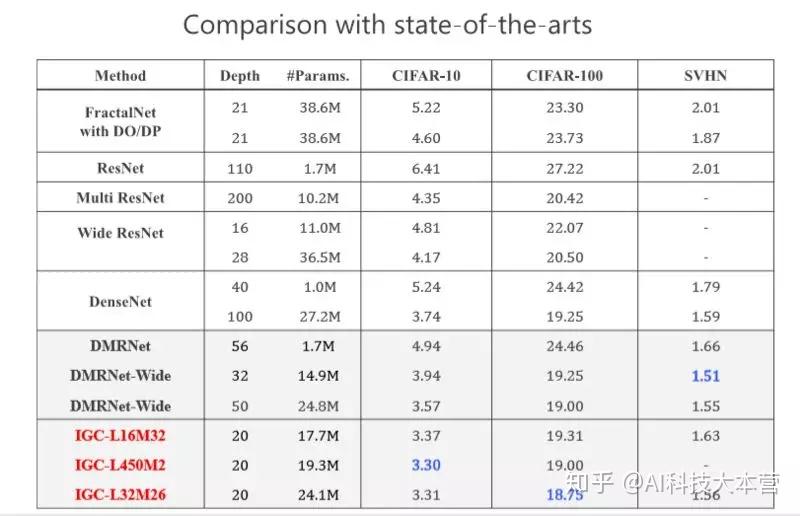
当时我们做的时候,希望在网络结构上跟 state-of-the-arts 的方法去比较,我们取得了非常不错的结果,当时我们的工作是希望通过消除冗余性提高模型性能或者准确率。
▌IGCV2
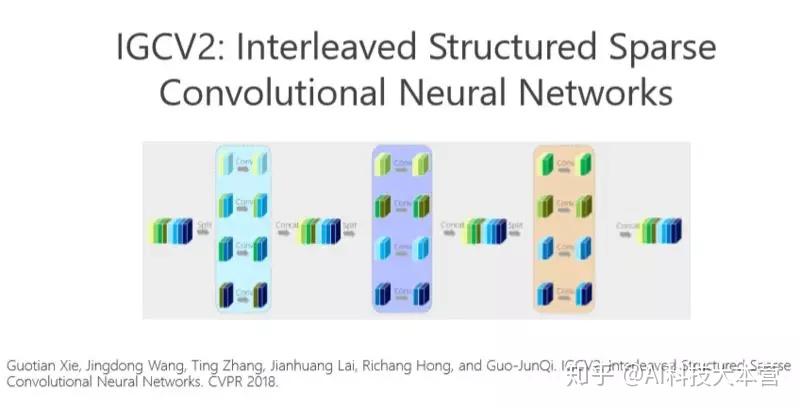
后来我们尝试利用消除冗余性带来的好处,把这个模型部署到手机上去。我们去年又沿着这个方向继续往前走,把这个问题理解得更深,希望进一步消除冗余性。
这个讲起来比较直接或简单一点,前面的网络结构是两个组卷积或者两个矩阵相乘得到的,我们有没有办法变得多一点?实际上很简单,如上图所示。

这种方法带来的好处很直接,就是希望参数量尽量小,那怎么才能(使)参数量尽量小?我们引进了所谓的平衡条件。虽然这里面我们有 L-1 个 1×1 的组卷积,但 L-1 个 1×1 的组卷积之间有区别吗?谁重要一点、谁不重要一点?其实我们也不知道。不知道怎么办?就让它一样。一样了以后,我们通过简单的数学推导就会得出上面的数学结果。
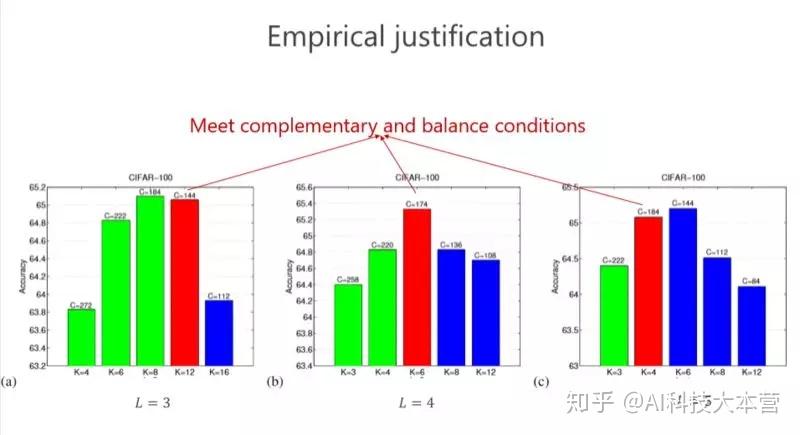
现在再验证一下,前面讲了互补条件、平衡条件,那这个结果是不是最好的?或者是不是有足够的优势?我们做了些实验,这个红色的是对应满足我们条件的,发现这个情况下(L=4)结果是最好的。其实是不是总是最好?不见得,因为实际问题跟理论分析还是有点距离。但我们总体发现基本上红色的不是最好也排在第二,说明这种设计至少给了我们很好的准则来帮助设计网络结构。这个虽然不总是最好的,但和最好的是差不多的。

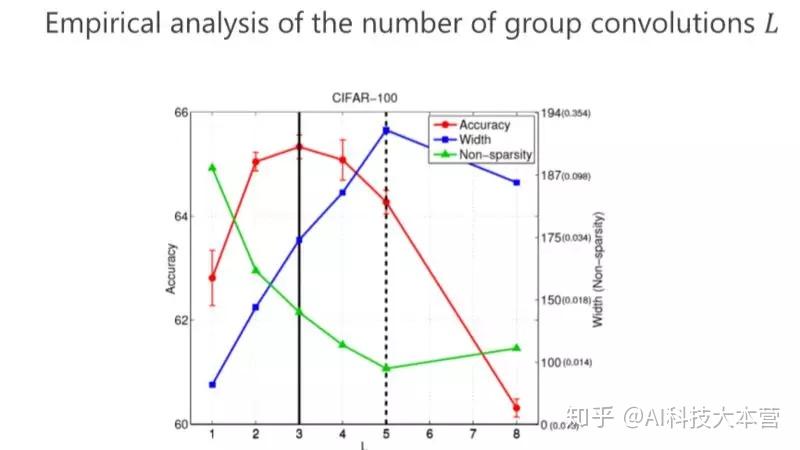
第二个问题,我们究竟要设计多少个组卷积(L 设成多少)?同样我们的准则也是通过参数量最小来进行分析,以前是两个组卷积,我们可以通过 3 个、4 个达到参数量更小,但其实最终的结论发现,并不是参数量最优的情况下性能是最好的。
▌IGCV3

后来我们发现,如果遵循严格互补条件,模型的结构变得非常稀疏、非常宽,结果不见得是最好的。所以我们变成了 Loose。Loose 是什么意思?以前 output(输出通道)和 input (输入通道)之间是有且只有一个 path,我们改得非常简单,能不能多个path?多个 path 就没那么稀疏了,它好处在于每个 output (输出通道)可以多条路径从 input (输入通道)那里拿到信息,所以我们设计了 Loose condition。

实际上非常简单,我们就定义两个超级通道(super-channels)只能在一个 Branch 里面同时出现,不能在两个 Branch 里同时出现,来达到 Loose condition。
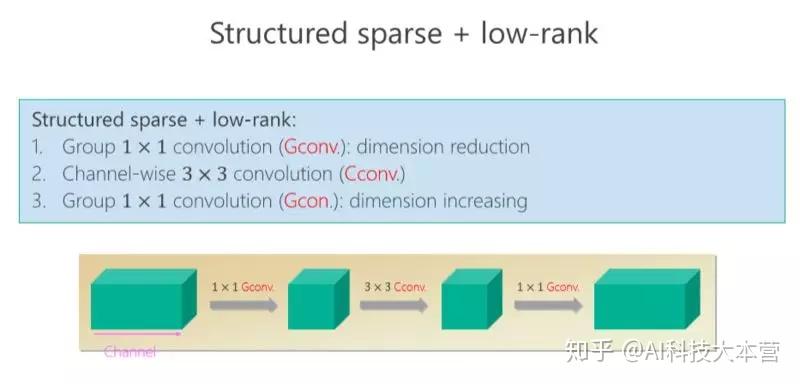
后来我们进一步往前走,把 structured sparse 和 low-rank 两个组起来。我们在 ImageNet 上比较,同时跟 MobileV2 去比,在小的模型我们优势是越来越明显的。比较结果,见下图。

这就是今天的主要内容,这个工作是我跟很多学生和同事一起做的,前面这5个是我的学生,Ting Zhang现在在微软研究院工作,Bin Xiao 是我的同事,Guojun Qi 是美国的教授,我们一起合作了这篇文章。
讲师简介
王井东,微软亚洲研究院视觉计算组资深研究员,国际模式识别学会会士,曾担任CVPR、ICCV、ECCV、AAAI 等计算机视觉和人工智能会议的领域主席和高级程序委员会委员。在视觉、机器学习以及多媒体领域里发表论文 100 余篇,个人专著一本。
另外,AI科技大本营已经有多门公开课上线啦~~☟☟☟
计算机视觉专场:
格灵深瞳:一亿ID的人脸识别训练和万亿人脸对(Trillion Pairs)的人脸识别评测
一亿ID的人脸识别训练和万亿人脸对(Trillion Pairs)的人脸识别评测edu.csdn.net
云从科技:详解跨镜追踪(ReID)技术实现及应用场景
云从科技:详解跨镜追踪(ReID)技术实现及应用场景 - 直播课 - CSDN学院 - 在线学习教程 - 会员免费-CSDN学院edu.csdn.net
微软:基于交错组卷积的高效深度神经网络
基于交错组卷积的高效深度神经网络 - 直播课 - CSDN学院 - 在线学习教程 - 会员免费-CSDN学院edu.csdn.net
腾讯:朋友圈爆款背后的计算机视觉技术与应用
朋友圈爆款背后的计算机视觉技术与应用 - 直播课 - CSDN学院 - 在线学习教程 - 会员免费-CSDN学院edu.csdn.net
旷视科技:计算机视觉如何赋能身份验证场景
旷视科技:计算机视觉如何赋能身份验证场景 - 直播课 - CSDN学院 - 在线学习教程 - 会员免费-CSDN学院edu.csdn.net
NLP专场
启发式对话中的知识管(7.12)
嘉宾:葛付江,思必驰北京研发院自然语言处理负责人。毕业于哈尔滨工业大学,拥有12年自然语言处理研究和行业经验。
报名:
启发式对话中的知识管理 - 直播课 - CSDN学院 - 在线学习教程 - 会员免费-CSDN学院edu.csdn.net
NLP概述和文本自动分类算法详解(7.17)
嘉宾:张健,达观数据联合创始人,文本应用组负责人。
报名:
NLP概述和文本自动分类算法详解 - 直播课 - CSDN学院 - 在线学习教程 - 会员免费-CSDN学院edu.csdn.net
Transformer新型神经网络在机器翻译中的应用(7.26)
嘉宾:于恒,中科院计算所博士,现为阿里巴巴-翻译平台-翻译模型组负责人
Transformer新型神经网络在机器翻译中的应用 - 直播课 - CSDN学院 - 在线学习教程 - 会员免费-CSDN学院edu.csdn.net
微信高级研究员解析深度学习在NLP中的发展和应用
微信高级研究员解析深度学习在NLP中的发展和应用 - 直播课 - CSDN学院 - 在线学习教程 - 会员免费-CSDN学院edu.csdn.net
刘铁岩谈机器学习:随波逐流的太多,我们需要反思
嘉宾 | 刘铁岩
整理 | 阿司匹林
来源 | AI科技大本营在线公开课(更多公开课)
人工智能正受到越来越多的关注,而这波人工智能浪潮背后的最大推手就是“机器学习”。机器学习从业者在当下需要掌握哪些前沿技术?展望未来,又会有哪些技术趋势值得期待?
近期,AI科技大本营联合华章科技特别邀请到了微软亚洲研究院副院长刘铁岩博士进行在线公开课分享,为我们带来微软研究院最新的研究成果,以及对机器学习领域未来发展趋势的展望。

以下是本次公开课的精彩内容,AI科技大本营整理。
大家好,我是刘铁岩,来自微软亚洲研究院。今天非常荣幸,能跟大家一起分享一下微软研究院在机器学习领域取得的一些最新研究成果。
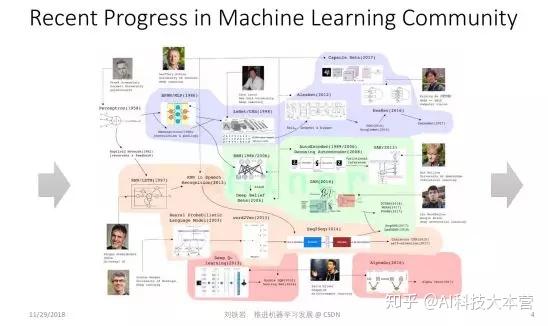
大家都知道,最近这几年机器学习非常火,也取得了很多进展。这张图总结了机器学习领域的最新工作,比如 ResNet、胶囊网络、Seq2Seq Model、Attention Mechanism 、GAN、Deep Reinforcement Learning 等等。

这些成果推动了机器学习领域的飞速发展,但这并不意味着机器学习领域已经非常成熟,事实上仍然存在非常大的技术挑战。比如现在主流机器学习算法需要依赖大量的训练数据和计算资源,才能训练出性能比较好的机器学习模型。同时,虽然深度学习大行其道,但我们对深度学习的理解,尤其是理论方面的理解还非常有限。深度学习为什么会有效,深度学习优化的损失函数曲面是什么样子?经典优化算法的优化路径如何?最近一段时间,学者们在这个方向做了很多有益的尝试,比如讨论随机梯度下降法在什么条件下可以找到全局最优解,或者它所得到的局部最优解跟全局最优解之间存在何种关系。
再比如,最近很多学者开始用自动化的方式帮助机器学习尤其是深度学习来调节超参数、搜寻神经网络的结构,相关领域称为元学习。其基本思想是用一个机器学习算法去自动地指导另一个机器学习算法的训练过程。但是我们必须要承认,元学习其实并没有走出机器学习的基本框架。更有趣的问题是,如何能够让一个机器学习算法去帮助另一个算法突破机器学习的现有边界,让机器学习的效果更好呢?这都是我们需要去回答的问题。沿着这些挑战,在过去的这几年里,微软亚洲研究院做了一些非常有探索性的学术研究。
对偶学习解决机器学习对大量有标签数据的依赖
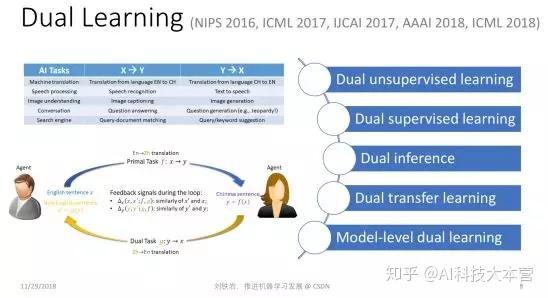
首先,我们看看对偶学习。对偶学习主要是为了解决现有深度学习方法对训练数据过度依赖的问题。当我们没有标注好的训练数据时,是否还能做有意义的机器学习?在过去的几年里,人们做了很多尝试,比如无监督学习、半监督学习等等。但是无论如何,大家心里要清楚,只有有信号、有反馈、才能实现有效的学习,如果我们对这个世界一无所知,我们是不能进行有效的学习的。
沿着这个思路,我们在思考:除了人为提供的标签以外,是不是存在其他有效的反馈信号,能够形成学习的闭环?我们发现很多机器学习任务其实天然有结构对偶性,可以形成天然的闭环。
比如机器翻译。一方面我们会关心从英文翻译到中文,另一方面我们一定也关心从中文翻译到英文,否则就无法实现两个语种人群之间的无缝交流。再比如语音处理。我们关心语音识别的同时一定也关心语音合成,否则人和机器之间就没有办法实现真正的双向对话。还有图像理解、对话引擎、搜索引擎等等,其实它们都包含具有对偶结构的一对任务。
如何更加准确地界定人工智能的结构对偶性呢?我们说:如果第一个任务的输入恰好是第二个任务的输出,而第一个任务的输出恰好是第二个任务的输入,那么这两个任务之间就形成了某种结构的“对偶性”。把它们放在一起就会形成学习的闭环 ,这就是“对偶学习”的基本思想。
有了这样的思想以后,我们可以把两个对偶任务放到一起学,提供有效的反馈信号。这样即便没有非常多的标注样本,我们仍然可以提取出有效的信号进行学习。
对偶学习背后其实有着严格的数学解释。当两个任务互为对偶时,我们可以建立如下的概率联系:

这里 X 和 Y 分别对应某个任务的输入空间和输出空间,在计算 X 和 Y 的联合概率分布时有两种分解方法,既可以分解成 P(x)P(y|x; f) ,也可以分解成 P(y)P(x|y; g)。这里,P(y|x; f) 对应了一个机器学习模型,当我们知道输入 x 时,通过这个模型可以预测输出 y 的概率,我们把这个模型叫主任务的机器学习模型,P(x|y; g) 则是反过来,称之为对偶任务的机器学习模型。
有了这个数学联系以后,我们既可以做有效的无监督学习,也可以做更好的有监督学习和推断。比如我们利用这个联系可以定义一个正则项,使得有监督学习有更好的泛化能力。再比如,根据 P(x)P(y|x; f) 我们可以得到一个推断的结果,反过来利用贝叶斯公式,我们还可以得到用反向模型 g 做的推断,综合两种推断,我们可以得到更准确的结果。我们把以上提到的对偶学习技术应用在了机器翻译上,取得了非常好的效果,在中英新闻翻译任务上超过了普通人类的水平。
解决机器学习对大计算量的依赖
轻量级机器学习
最近一段时间,在机器学习领域有一些不好的风气。有些论文里会使用非常多的计算资源,比如动辄就会用到几百块 GPU卡 甚至更多的计算资源。这样的结果很难复现,而且在一定程度上导致了学术研究的垄断和马太效应。
那么人们可能会问这样的问题:是不是机器学习一定要用到那么多的计算资源?我们能不能在计算资源少几个数量级的情况下,仍然训练出有意义的机器学习模型?这就是轻量级机器学习的研究目标。

在过去的几年里,我们的研究组做了几个非常有趣的轻量级机器学习模型。比如在 2015 发表的 lightLDA 模型,它是一个非常高效的主题模型。在此之前,世界上已有的大规模主题模型一般会用到什么样的计算资源?比如 Google 的 LDA 使用上万个 CPU cores,才能够通过几十个小时的训练获得 10 万个主题。为了降低对计算资源的需求,我们设计了一个基于乘性分解的全新采样算法,把每一个 token 的平均采样复杂度降低到 O(1),也就是说采样复杂度不随着主题数的变化而变化。因此即便我们使用这个主题模型去做非常大规模的主题分析,它的运算复杂度也是很低的。例如,我们只使用了 300 多个 CPU cores,也就是大概 8 台主流的机器,就可以实现超过 100 万个主题的主题分析。
这个例子告诉大家,其实有时我们不需要使用蛮力去解决问题,如果我们可以仔细分析这些算法背后的机理,做算法方面的创新,就可以在节省几个数量级计算资源的情况下做出更大、更有效的模型。
同样的思想我们应用到了神经网络上面,2016 年发表的 LightRNN算法是迄今为止循环神经网络里面最高效的实现。当我们用 LigthtRNN 做大规模的语言模型时,得到的模型规模比传统的 RNN 模型小好几个数量级。比如传统模型大小在100GB 时,LightRNN 模型只有50MB,并且训练时间大幅缩短 。不仅如此,LightRNN模型的 perplexity比传统RNN还要更好。
可能有些同学会产生疑问:怎么可能又小又好呢?其实,这来源于我们在循环神经网络语言模型的算法上所做的创新设计。我们把对 vocabulary 的表达从一维变到了两维,并且允许不同的词之间共享某一部分的 embedding 。至于哪些部分共享、哪些不共享,我们使用了一个二分图匹配的算法来确定。
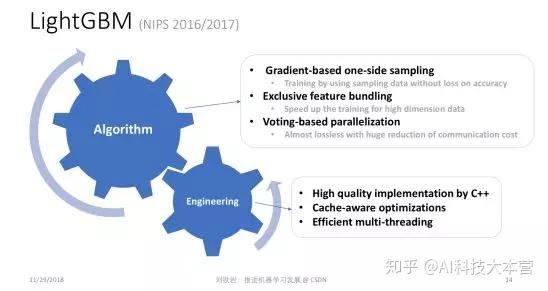
第三个轻量型机器学习的算法叫 LightGBM,这个工具是 GBDT 算法迄今为止最高效的实现。LightGBM的背后是两篇 NIPS 论文,其中同样包含了很多技术创新,比如 Gradient-based one-side sampling,可以有效减少对样本的依赖; Exclusive feature bundling,可以在特征非常多的情况下,把一些不会发生冲突的特征粘合成比较 dense 的少数特征,使得建立特征直方图非常高效。同时我们还提出了 Voting-based parallelization 机制,可以实现非常好的加速比。所有这些技巧合在一起,就成就了LightGBM的高效率和高精度。
分布式机器学习
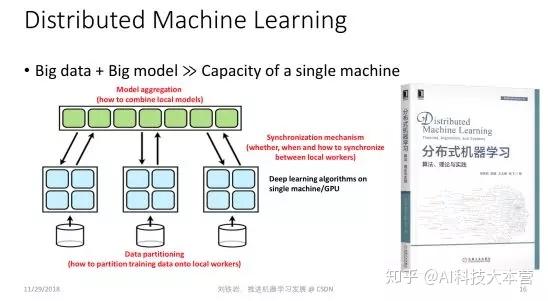
虽然我们做了很多轻量级的机器学习算法,但是当训练数据和机器学习模型特别大的时候,可能还不能完全解决问题,这时我们需要研究怎样利用更多的计算节点实现分布式的机器学习。
我们刚刚出版了一本新书——《分布式机器学习:算法、理论与实践》,对分布式机器学习做了非常好的总结,也把我们很多研究成果在这本书里做了详尽的描述。下面,我挑其中几个点,跟大家分享。
分布式机器学习的关键是怎样把要处理的大数据或大模型进行切分,在多个机器上做并行训练。一旦把这些数据和模型放到多个计算节点之后就会涉及到两个基本问题:首先,怎样实现不同机器之间的通信和同步,使得它们可以协作把机器学习模型训练好。其次,当每个计算节点都能够训练出一个局部模型之后,怎样把这些局部模型做聚合,最终形成一个统一的机器学习模型。
数据切分
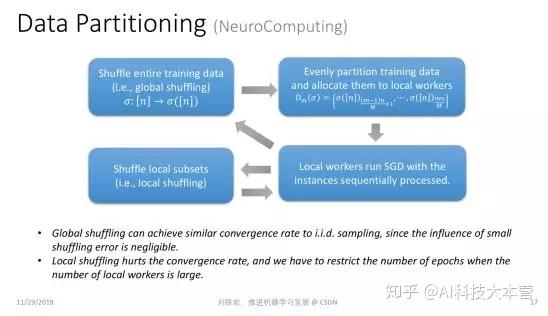
数据切分听起来很简单,其实有很多门道。举个例子,一个常见的方式就是把数据做随机切分。比如我们有很多训练数据,随机切分成 N 份,并且把其中一份放到某个局部的工作节点上去训练。这种切分到底有没有理论保证?
我们知道机器学习有一个基本的假设,就是学习过程中的数据是独立同分布采样得来的,才有理论保证。但是前面提到的数据切分其实并不是随机的数据采样。从某种意义上讲,独立同分布采样是有放回抽样,而数据切分对应于无放回抽样。一个很有趣的理论问题是,我们在做数据切分时,是不是可以像有放回抽样一样,对学习过程有一定的理论保证呢?这个问题在我们的研究发表之前,学术界是没有完整答案的。
我们证明了:如果我先对数据进行全局置乱,然后再做数据切分,那么它和有放回的随机采样在收敛率上是基本一致的。但是如果我们只能做局部的数据打乱,二者之间的收敛率是有差距的。所以如果我们只能做局部的数据打乱,就不能训练太多 epoch,否则就会与原来的分布偏离过远,使得最后的学习效果不好。
异步通信
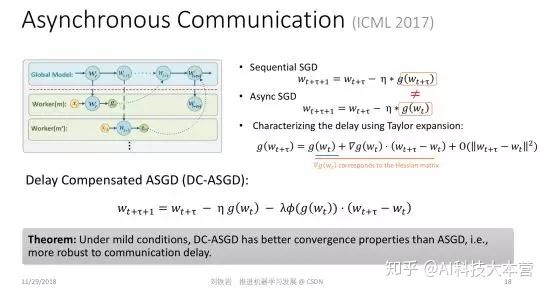
说完数据切分,我们再讲讲各个工作节点之间的通信问题。大家知道,有很多流行的分布式框架,比如 MapReduce,可以实现不同工作节点之间的同步计算。但在机器学习过程中,如果不同机器之间要做同步通信,就会出现瓶颈:有的机器训练速度比较快,有的机器训练速度比较慢,而整个集群会被这个集群里最慢的机器拖垮。因为其他机器都要跟它完成同步之后,才能往前继续训练。
为了实现高效的分布式机器学习,人们越来越关注异步通信,从而避免整个集群被最慢的机器拖垮。在异步通信过程中,每台机器完成本地训练之后就把局部模型、局部梯度或模型更新推送到全局模型上去,并继续本地的训练过程,而不去等待其他的机器。
但是人们一直对异步通信心有余悸。因为做异步通信的时候,同样有一些机器运算比较快,有一些机器运算比较慢,当运算比较快的机器将其局部梯度或者模型更新叠加到全局模型上以后,全局模型的版本就被更新了,变成了很好的模型。但是过了一段时间,运算比较慢的机器又把陈旧的梯度或者模型更新,叠加到全局模型上,这就会把原来做得比较好的模型给毁掉。人们把这个问题称为“延迟更新”。不过在我们的研究之前,没有人定量地刻画这个延迟会带来多大的影响。
在去年 ICML 上我们发表了一篇论文,用泰勒展开式定量刻画了标准的随机梯度下降法和异步并行随机梯队下降法的差距,这个差距主要是由于延迟更新带来的。如果我们简单粗暴地使用异步 SGD,不去处理延迟更新,其实就是使用泰勒展开里零阶项作为真实的近似。既然它们之间的差距在于高阶项的缺失,如果我们有能力把这些高阶项通过某种算法补偿回来,就可以使那些看起来陈旧的延迟梯度焕发青春。这就是我们提出的带有延迟补偿的随机梯度下降法。
这件事说起来很简单,但实操起来有很大的难度。因为在梯度函数的泰勒展开中的一阶项其实对应于原损失函数的二阶项,也就是所谓的海森矩阵(Hessian Matrix)。当模型很大时,计算海森矩阵要使用的内存和计算量都会非常大,使得这个算法并不实用。在我们的论文里,提出了一个非常高效的对海森矩阵的近似。我们并不需要真正去计算非常高维的海森矩阵并存储它,只需要比较小的计算和存储代价就可以实现对海参矩阵相当精确的近似。 在此基础上,我们就可以利用泰勒展开,实现对原来的延迟梯度的补偿。我们证明了有延迟补偿的异步随机梯度下降法的收敛率比普通的异步随机梯度下降法要好很多,而且各种实验也表明它的效果确实达到了我们的预期。
模型聚合
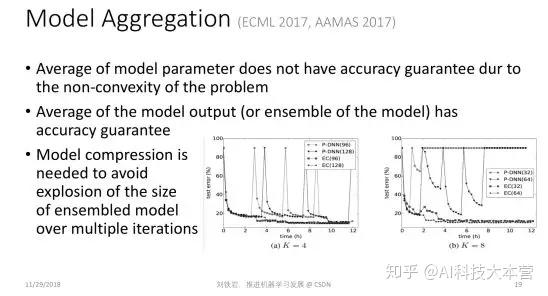
除了异步通信以外,每个局部节点计算出一个局部模型之后,怎样聚合在一起也是一个值得思考的问题。在业界里最常用的方式是把各个不同的局部模型做简单的参数平均。但是,从理论上讲,参数平均仅在凸问题上是合理的。如果大家对凸函数的性质有一些了解,就知道如果模型是凸的,那么我们对凸模型参数进行平均后得到的模型的性能,不会比每个模型性能的平均值差。
但是当我们用这样的方式去处理深层神经网络这类严重非凸的模型时,就不再有理论保证了。我们在 2017 年这几篇论文里指出了这个理论的缺失,并指出我们不应该做模型参数的平均,而是应该做模型输出的平均,这样才能获得性能的保障,因为虽然神经网络模型是非凸的,但是常用的损失函数本身是凸的。
但是模型输出的平均相当于做了模型的集成,它会使模型的尺寸变大很多倍。当机器学习不断迭代时,这种模型的集成就会导致模型尺寸爆炸的现象。为了保持凸性带来的好处,同时又不会受到模型尺寸爆炸的困扰,我们需要在整个机器学习流程里不仅做模型集成,还要做有效的模型压缩。
这就是我们提出的模型集成-压缩环路。通过模型集成,我们保持了凸性带来的好处,通过模型压缩,我们避免了模型尺寸的爆炸,所以最终会取得一个非常好的折中效果。
深度学习理论探索
接下来我们讲讲如何探索深度学习的理论边界。我们都知道深度学习很高效,任意一个连续函数,只要一个足够复杂的深度神经网络都可以逼近得很好。但是这并不表示机器就真能学到好的模型。因为当目标函数的界面太复杂时,我们可能掉入局部极小值的陷阱,无法得到我们想要的最好模型。当模型太复杂时,还容易出现过拟合,在优化过程中可能做的不错,可是当你把学到的模型应用到未知的测试数据上时,效果不一定很好。因此对于深度学习的优化过程进行深入研究是很有必要的。
g-Space


这个方向上,今年我们做了一个蛮有趣的工作,叫 g-Space Deep Learning。
这个工作研究的对象是图像处理任务里常用的一大类深度神经网络,这类网络的激活函数是ReLU函数。ReLU是一个分段线性函数,在负半轴取值为0,在正半轴则是一个线性函数。ReLU Network 有一个众所周知的特点,就是正尺度不变性,但我们对于这个特点对神经网络优化影响的理解非常有限。
那么什么是正尺度不变性呢?我们来举个例子。这是一个神经网络的局部,假设中间隐节点的激活函数是ReLU函数。当我们把这个神经元两条输入边上面的权重都乘以一个正常数 c,同时把输出边上的权重除以同样的正常数 c,就得到一个新的神经网络,因为它的参数发生了变化。但是如果我们把整个神经网络当成一个整体的黑盒子来看待,这个函数其实没有发生任何变化,也就是无论什么样的输入,输出结果都不变。这就是正尺度不变性。
这个不变性其实很麻烦,当激活函数是 ReLu函数时,很多参数完全不一样的神经网络,其实对应了同一个函数。这说明当我们用神经网络的原始参数来表达神经网络时,参数空间是高度冗余的空间,因为不同的参数可能对应了同一个网络。这种冗余的空间是不能准确表达神经网络的。同时在这样的冗余空间里可能存在很多假的极值点,它们是由空间冗余带来的,并不是原问题真实的极值点。我们平时在神经网络优化过程中遇到的梯度消减、梯度爆炸的现象,很多都跟冗余的表达有关系。
既然参数空间冗余有这么多缺点,我们能不能解决这个问题?如果不在参数空间里做梯度下降法,而是在一个更紧致的表达空间里进行优化,是不是就可以解决这些问题呢?这个愿望听起来很美好,但实际上做起来非常困难。因为深度神经网络是一个非常复杂的函数,想对它做精确的紧致表达,需要非常强的数学基础和几何表达能力。我们组里的研究员们做了非常多的努力,经过了一年多的时间,才对这个紧致的空间做了一个完整的描述,我们称其为 g-Space 。
g-Space 其实是由神经网络中一组线性无关的通路组成的,所谓通路就是从输入到输出所走过的一条不回头的通路,也就是其中一些边的连接集合。我们可以证明,如果把神经网络里的这些通路组成一个空间,这个空间里的基所组成的表达,其实就是对神经网络的紧致表达。
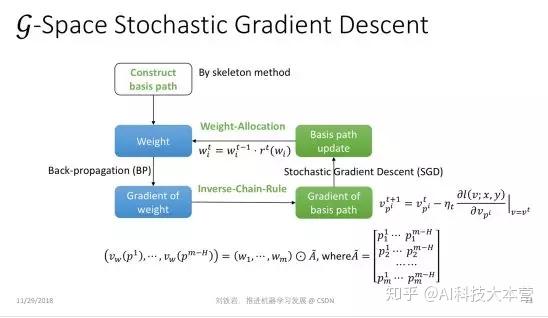
有了 g-Space 之后,我们就可以在其中计算梯度,同时也可以在 g-Space 里计算距离。有了这个距离之后,我们还可以在 g-Space 里定义一些正则项,防止神经网络过拟合。
我们的论文表明,在新的紧致空间里做梯度下降的计算复杂度并不高,跟在参数空间里面做典型的 BP 操作复杂度几乎是一样的。换言之,我们设计了一个巧妙的算法,它的复杂度并没有增加,但却回避了原来参数空间里的很多问题,获得了对于 ReLU Network 的紧致表达,并且计算了正确的梯度,实现了更好的模型优化。
有了这些东西之后,我们形成了一套新的深度学习优化框架。这个方法非常 general,它并没有改变目标函数,也没改变神经网络的结构,仅仅是换了一套优化方法,相当于整个机器学习工具包里面只换了底层,就可以训练出效果更好的模型来。
元学习的限制
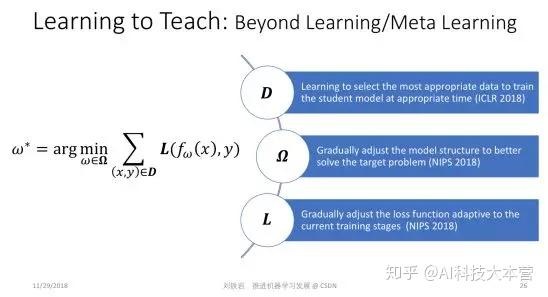
第四个研究方向也非常有趣,我们管它叫 Learning to Teach,中文我没想到特别好的翻译,现在权且叫做“教学相长”。
我们提出 Learning to Teach 这个研究方向,是基于对现在机器学习框架的局限性的反思。这个式子虽然看起来很简单,但它可以描述一大类的或者说绝大部分机器学习问题。这个式子是什么意思?首先 (x, y) 是训练样本,它是从训练数据集 D 里采样出来的。 f(ω) 是模型,比如它可能代表了某一个神经网络。我们把 f(ω)作用在输入样本 x 上,就会得到一个对输入样本的预测。然后,我们把预测结果跟真值标签 y 进行比较,就可以定义一个损失函数 L。
现在绝大部分机器学习都是在模型空间里最小化损失函数。所以这个式子里有三个量,分别是训练数据 D,损失函数 L,还有模型空间 Ω。 这三个量都是超参数,它们是人为设计好的,是不变的。绝大部分机器学习过程,是在这三样给定的情况下去做优化,找到最好的 ω,使得我们在训练数据集上能够最小化人为定义的损失函数。即便是这几年提出的 meta learning 或者 learning2learn,其实也没有跳出这个框架。因为机器学习框架本身从来就没有规定最小化过程只能用梯度下降的方法,你可以用任何方法,都超不出这个这个式子所表达的框架。
但是为什么训练数据集 D、损失函数 L 和模型参数空间 Ω 必须人为预先给定?如果不实现给定,而是在机器学习过程中动态调整,会变成什么样子?这就是所谓的 Learning to Teach。我们希望通过自动化的手段,自动调节训练数据集 D、损失函数 L 和模型参数空间 Ω,以期拓展现有机器学习的边界,帮助我们训练出更加强大的机器学习模型。
要实现这件事情其实并不简单,我们需要用全新的思路和视角。我们在今年连续发表了三篇文章,对于用自动化的方式去确定训练数据、函数空间和损失函数,做了非常系统的研究。
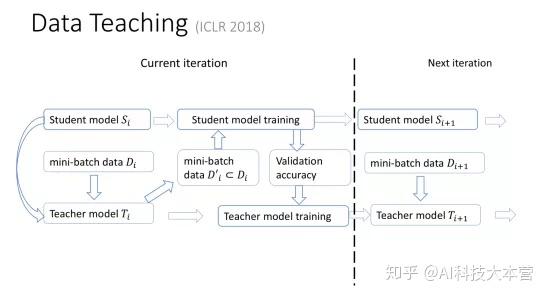
我给大家形象地描述一下我们的研究。 比如我们怎么用自动化的方式去选择合适的数据?其实很简单。除了原来的机器学习的模型以外,我们还有一个教学模型 teacher model。这个模型会把原来的机器学习的过程、所处的阶段、效果好坏等作为输入,输出对下一阶段训练数据的选择。这个 teacher model 会根据原来的机器学习模型的进展过程,动态选择最适合的训练数据,最大限度提高性能。同时teacher model也会把机器学习在交叉验证集上的效果作为反馈,自我学习,自我提高。
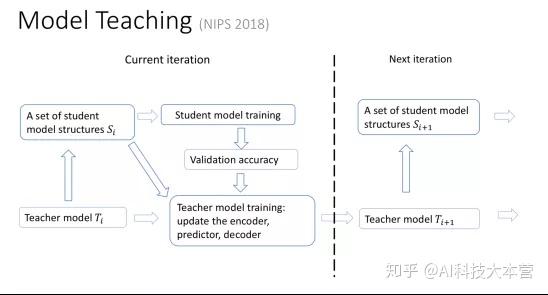
同样 model teaching 的环路中也存在一个 teacher model ,它会根据原来的机器学习过程所处的阶段、训练的效果,选择合适的函数空间,让原来的机器学习扩大自己的搜索范围,这个过程也是自适应的、动态的。原来的机器学习模型我们叫 student model,和我们引入的教学模型 teacher model 之间进行互动,就可以将学习过程推向一个新的高度。
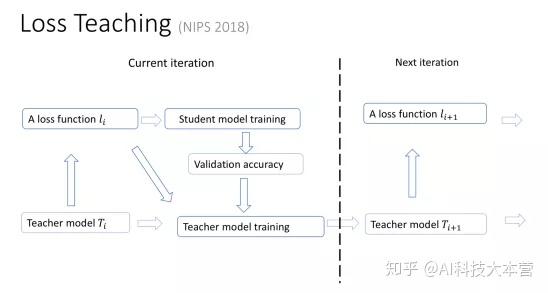
同样,teacher model也可以动态调整原来student model 所要优化的目标。 比如,我们的学习目标可以从简到难,最开始的时候,一个简单的学习目标会让我们很快学到一些东西,但是这个学习目标可能和我们最终问题的评价准则相差很远。我们不断把简单平滑的目标,向着问题评价的复杂的非连续函数逼近,就会引导 student model 不断提高自己的能力,最后实现很好的学习效果。
总结一下,当我们有一个 teacher model,它可以动态地设计训练数据集、改变模型空间、调整目标函数时,就会使得原来“student model”的训练更宽泛、更有效,它的边界就会被放大。 我们在三篇论文里面分别展示了很多不同数据集上的实验结果。
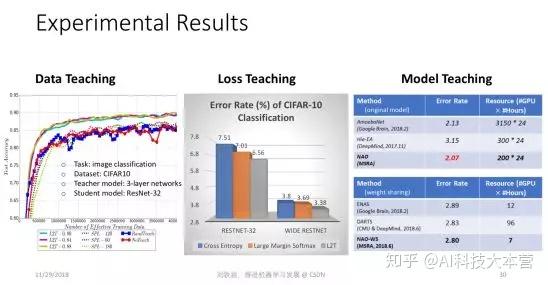
我自己认为 Learning to Teach 非常有潜力,它扩大了传统机器学习的边界。我们的三篇论文仅仅是抛砖引玉,告诉大家这件事情可以做,但前面路还很长。
到此为止,我把最近这一两年微软亚洲研究院在机器学习领域所做的一些研究成果跟大家做了分享,它们只是我们研究成果的一个小小的子集,但是我觉得这几个方向非常有趣,希望能够启发大家去做更有意义的研究。
展望未来
现在机器学习领域的会议越来越膨胀,有一点点不理智。每一年那么多论文,甚至都不知道该读哪些。人们在写论文、做研究的时候,有时也不知道重点该放在哪里。比如,如果整个学术界都在做 learning2learn,是不是我应该做一篇 learning2learn 的论文?大家都在用自动化的方式做 neural architecture search,我是不是也要做一篇呢?现在这种随波逐流、人云亦云的心态非常多。
我们其实应该反思:现在大家关注的热点是不是涵盖了所有值得研究的问题?有哪些重要的方向其实是被忽略的?我举个例子,比如轻量级的机器学习,比如 Learning to Teach,比如对于深度学习的一些理论探索,这些方面在如今火热的研究领域里面涉及的并不多,但这些方向其实非常重要。只有对这些方向有非常深刻的认识,我们才能真正推动机器学习的发展。希望大家能够把心思放到那些你坚信重要的研究方向上,即便当下它还不是学术界关注的主流。
接下来我们对机器学习未来的发展做一些展望,这些展望可能有些天马行空,但是却包含了一些有意义的哲学思考,希望对大家有所启发。
量子计算
第一个方面涉及机器学习和量子计算之间的关系。量子计算也是一个非常火的研究热点,但是当机器学习碰到量子计算,会产生什么样的火花?其实这是一个非常值得我们思考的问题。
目前学术界关注的问题之一是如何利用量子计算的计算力去加速机器学习的优化过程,这就是所谓的quantum speedup。但是,这是否是故事的全部呢?大家应该想一想,反过来作为一名机器学习的学者,我们是不是有可能帮助量子计算呢?或者当机器学习和量子计算各自往前走,碰到一起的时候会迸发出怎样的新火花?
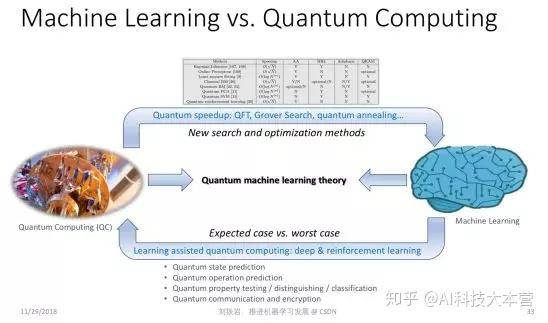
其实在量子计算里有一些非常重要的核心问题,比如我们要去评估或者或者预测 quantum state(量子态),然后才能把量子计算的结果取出来。这个过程在传统理论里面已经证明,在最坏情况下,我们就需要指数级的采样,才能对 quantum state 做比较好的估计。但这件事情会带来负面影响,量子计算虽然很快,但是如果探测量子态耗费了大量时间来做采样,就会拖垮原来的加速效果,最后合在一起,并没有实现任何加速。
我们知道很多最坏情况下非常复杂的问题,比如 NP Complete问题,用机器学习的方法去解,其实可以在平均意义上取得非常好的效果。我们今年在ACML上获得最佳论文的工作就是用机器学习的方法来解travelling salesman问题,取得了比传统组合优化更高效的结果。沿着这个思路,我们是不是可以用机器学习帮助处理量子计算里的问题,比如quantum state prediction,是不是根本不需要指数级的采样,就可以得到一个相当好的估计?在线学习、强化学习等都能在这方面有所帮助。
同时,量子和机器学习理论相互碰撞时,会发生一些非常有趣的现象。我们知道,量子有不确定性,这种不确定性有的时候不见得是件坏事,因为在机器学习领域,我们通常希望有不确定性,甚至有时我们还会故意在数据里加噪声,在模型训练的过程中加噪声,以期获得更好的泛化性能。
从这个意义上讲,量子计算的不确定性是不是反而可以帮助机器学习获得更好的泛化性能?如果我们把量子计算的不确定性和机器学习的泛化放在一起,形成一个统一的理论框架,是不是可以告诉我们它的 Trade-off 在哪里?是不是我们对量子态的探测就不需要那么狠?因为探测得越狠可能越容易 overfit。是不是有一个比较好的折中?其实这些都是非常有趣的问题,也值得量子计算的研究人员和机器学习的研究人员共同花很多年的时间去探索。
以简治繁
第二个方向也很有趣,它涉及到我们应该以何种方式来看待训练数据。深度学习是一个以繁治繁的过程,为了去处理非常复杂的训练数据,它使用了一个几乎更复杂的模型。但这样做真的值得吗?跟我们过去几十年甚至上百年做基础科学的思路是不是一致的?

在物理、化学、生物这些领域,人们追求的是世界简单而美的规律。不管是量子物理,还是化学键,甚至经济学、遗传学,很多复杂的现象背后其实都是一个二阶偏微分方程,比如薛定谔方程,比如麦克斯韦方程组,等等。这些方程都告诉我们,看起来很复杂的世界,其实背后的数学模型都是简单而美的。这些以简治繁的思路,跟深度学习是大相径庭的。
机器学习的学者也要思考一下,以繁治繁的深度学习真的是对的吗?我们把数据看成上帝,用那么复杂的模型去拟合它,这样的思路真的对吗?是不是有一点舍本逐末了?以前的这种以简治繁的思路,从来都不认为数据是上帝,他们认为背后的规律是上帝,数据只是一个表象。
我们要学的是生成数据的规律,而不是数据本身,这个方向其实非常值得大家去思考。要想沿着这个方向做很好的研究,我们需要机器学习的学者扩大自己的知识面,更多地去了解动态系统或者是偏微分方程等,以及传统科学里的各种数学工具,而不是简单地使用一个非线性的模型去做数据拟合。
Improvisational Learning

第三个方向关乎的是我们人类到底是如何学习的。到今天为止,深度学习在很多领域的成功,其实都是做模式识别。模式识别听起来很神奇,其实是很简单的一件事情。几乎所有的动物都会模式识别。人之所以有高的智能,并不是因为我们会做模式识别,而是因为我们有知识,有常识。基于这个理念,Yann LeCun 一个新的研究方向叫 Predictive Learning(预测学习)。它的思想是什么?就是即便我们没有看到事物的全貌,因为我们有常识,有知识,我们仍然可以做一定程度的预测,并且基于这个预测去做决策。这件事情已经比传统的模式识别高明很多,它会涉及到人利用知识和常识去做预测的问题。
但是,反过来想一想,我们的世界真的是可以预测的吗?可能一些平凡的规律是可以预测的,但是我们每个人都可以体会到,我们的生活、我们的生命、我们的世界大部分都是不可预测的。所以这句名言很好,The only thing predictable about life is its unpredictability(人生中唯一能预测的就是其不可预测性)。

我们既然活在一个不可预测的世界里,那么我们到底是怎样从这个世界里学习,并且越来越强大?以下只是一家之言,我们猜测人类其实在做一件事情,叫 Improvisation,什么意思?就是我们每个人其实是为了生存在跟这个世界抗争。我们每天从世界里面学习的东西,都是为了应付将来未知的异常。当一件不幸的事情发生的时候,我们如何才能生存下来?其实是因为我们对这个世界有足够的了解,于是会利用已有的知识,即兴制定出一个方案,让我们规避风险,走过这个坎。
我们希望在我们的眼里,世界的熵在降低。我们对它了解越多,它在我们的眼里的熵越低。同时,我们希望当环境发生变化时,比如意外发生时,我们有能力即兴地去处理。这张PPT 里面描述的即兴学习框架就是我们在跟环境互动,以及在做各种思想实验,通过无监督的方式自我学习应对未知异常的能力。
从这个意义上讲,这个过程其实跟 Predictive Learning 不一样,跟强化学习也不一样,因为它没有既定的学习规律和学习目标,并且它是跟环境做交互,希望能够处理未来的未知环境。这其实就跟我们每个人积累一身本事一样,为的就是养兵千日用兵一时。当某件事情发生时,我怎么能够把一身的本事使出来,活下去。这个过程能不能用数学的语言描述? Improvisational Learning 能不能变成一个新的机器学习研究方向?非常值得我们思考。
群体智慧
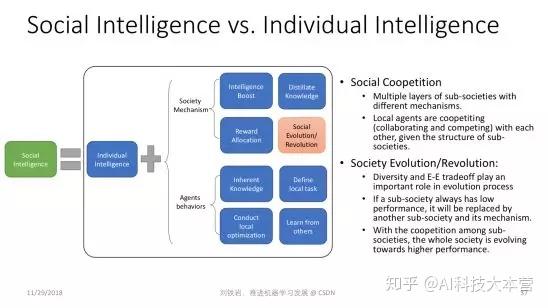
最后一个展望涉及到一个更哲学的思辨:人类的智能之所以这么高,到底是因为我们个体非常强大,还是因为我们群体非常强大?今天绝大部分的人工智能研究,包括深度学习,其实都在模仿人类个体的大脑,希望学会人类个体的学习能力。可是扪心自问,人类个体的学习能力真的比大猩猩等人类近亲高几个数量级吗?答案显然不是,但是今天人类文明发展的程度,跟猴子、跟大猩猩他们所处社区的文明的发展程度相比却有天壤之别。
所以我们坚信人类除了个体聪明以外,还有一些更加特殊的东西,那就是社会结构和社会机制,使得我们的智能突飞猛进。比如文字的产生,书籍的产生,它变成了知识的载体,使得某一个人获得的对世界的认知,可以迅速传播给全世界其他人,这个社会机制非常重要,会加速我们的进化。
再者,社会分工不同会使得每个人只要优化自己的目标,让自己变强大就可以了。各个领域里有各自的大师,而这些大师的互补作用,使得我们社会蓬勃发展。
所以社会的多样性,社会竞争、进化、革命、革新,这些可能都是人类有今天这种高智能的原因。而这些东西在今天的机器学习领域,鲜有人去做非常好的建模。我们坚信只有对这些事情做了非常深入的研究,我们才能真正了解了人的智能,真的了解了机器学习,把我们的研究推向新的高度。
(*本文由AI科技大本营整理,转载请联系微信1092722531)
人机交互如何改变人类生活 | 公开课笔记
作者 | 翁嘉颀
编译 | 姗姗
出品 | 人工智能头条(公众号ID:AI_Thinker)
【导读】在人机交互过程中,人通过和计算机系统进行信息交换,信息可以是语音、文本、图像等一种模态或多种模态。对人来说,采用自然语言与机器进行智能对话交互是最自然的交互方式之一,但这条路充满了挑战,如何机器人更好的理解人的语言,从而更明确人的意图?如何给出用户更精准和不反感的回复?都是在人机交互对话过程中最为关注的问题。对话系统作为NLP的一个重要研究领域受到大家越来越多的关注,被应用于多个领域,有着很大的价值。
本期大本营公开课,我们邀请到了竹间智能的 CTO 翁嘉颀老师,他将通过对技术方法通俗易懂的讲解和Demo 演示相结合的方式为大家讲解本次课题,本次课题主要包含一些几个内容:
1.上下文理解技术——补全与指代消解
2.上下文理解技术——对话主题式补全
3.NLU的模块架构及如何利用NLU的基础信息
4.Live Demo 演示
5.人机交互的案例分享与研究发展趋势
6. Q & A
观看回放:
人机交互未来如何改变人类生活 - 直播课 - CSDN学院 - 在线学习教程 - 会员免费-CSDN学院edu.csdn.net
以下是公开课文字版整理内容
▌前言
我从1982年开始坐在电脑前面,一直到现在。上一次做人工智能是27年前,大概1991年的时候,那个时候做人工智能的人非常可怜 ,因为做什么东西都注定做不出来,随便一个机器学习的训练、神经网络训练需要20天,调个参数再重新训练又是20天,非常非常慢。电脑棋类我除了围棋没做以外,其他都做了,本来这辈子看不到围棋下赢人,结果两年前看到了。后来做语音识别,语音识别那个年代也都是玩具,所以那个年代做人工智能的人最后四分五裂,因为根本活不下去,后来就跑去做搜索引擎、跑去做金融、跑去做其他的行业。
这次人工智能卷土重来,真的开始进入人类生活,在周边地方帮上我们的忙。今天我来分享这些人机交互的技术到底有哪些变化。

先讲“一个手环的故事”,这是一个真实的故事,我们在两年前的4月份曾经想要做这个,假设有一个用户戴着手环,“快到周末了,跟女朋友约会,给个建议吧”。背后机器人记得我的一些事情,知道我过去的约会习惯是看电影,还是去爬山,还是在家打游戏、看视频。如果要外出的话,周末的天气到底怎样,如果下大雨的话那可能不适合。

而且它知道我喜欢看什么电影、不喜欢看什么电影、我的女朋友喜欢看什么、不喜欢看什么,它甚至知道我跟哪一个女朋友出去,喜欢吃什么,不喜欢吃什么,餐厅的价位是吃2000块一顿,还是200块一顿,还是30块一顿的餐馆,然后跟女朋友认识多久了,刚认识的可能去高档一点的地方,认识6年了吃顿便饭就和了,还有约会习惯。
有了这些东西之后,机器人给我一个回应,说有《失落 的世界2》在某某电影院,这是我们习惯去的地方,看完电影,附近某家餐馆的价位和口味 是符合我们的需要。我跟它说“OK,没问题”,机器人就帮我执行这个命令,帮我买电影票、帮我订餐馆、周末时帮我打车,甚至女朋友刚认识,买一束花放在餐馆的桌上。
我们当时想象是做这个。这个牵扯到哪些技术?第一,有记忆力,你跟我讲过什么东西,我能记得。还包括人机交互,我今天跟它讲“周末是女朋友生日 ,订个好一点的吧。”它能帮我换个餐馆,能理解我的意思。
如果手环能够做到这个样子,你会觉得这个手环应该是够聪明的,这个机器人是够聪明的,能够当成 你的助手陪伴你。最后,我们并没有做出来,我们做到了一部分,但是有一部分并没有做到。
我们公司的老板叫Kenny,他之前是 微软亚洲互联网工程院副院长,负责小冰及cortana的,老板是做搜索引擎出身的,我以前也是做搜索引擎的,做了11年。左下角的曹川在微软做搜索引擎。右上角在微软做搜索引擎。右下角在谷歌做搜索引擎。目前的人工智能很多是 搜索引擎跑回来的,因为搜索引擎也是做语义理解、文本 分析,和人工智能的文本 分析有一定的相关度。
▌人机交互的发展
一开始都是一些关键词跟模板的方式,我最常举的例子,我桌上有一个音箱,非常有名的一家公司做的,我今天跟这个音箱说“我不喜欢吃牛肉面”,音箱会抓到关键词“牛肉面”,它就跟我说“好的,为您推荐附近的餐馆”,推荐给我的第一个搞不好就是牛肉面。我如果跟它说“我刚刚吃饭吃很饱”,关键词是“吃饭”,然后它又说“好的,为您推荐附近的餐馆”,所以用关键词的方式并不是不能做,它对语义意图理解的准确率可能在七成、七成五左右,也许到八成,但有些东西它是解不了的,因为它并不是真的理解你这句话是什么意思。所以要做得好的话,必须用自然语言理解的方式,用深度学习、强化学习,模板也用得上,把这些技术混搭在一起,比较有办法理解你到底要做什么事情。
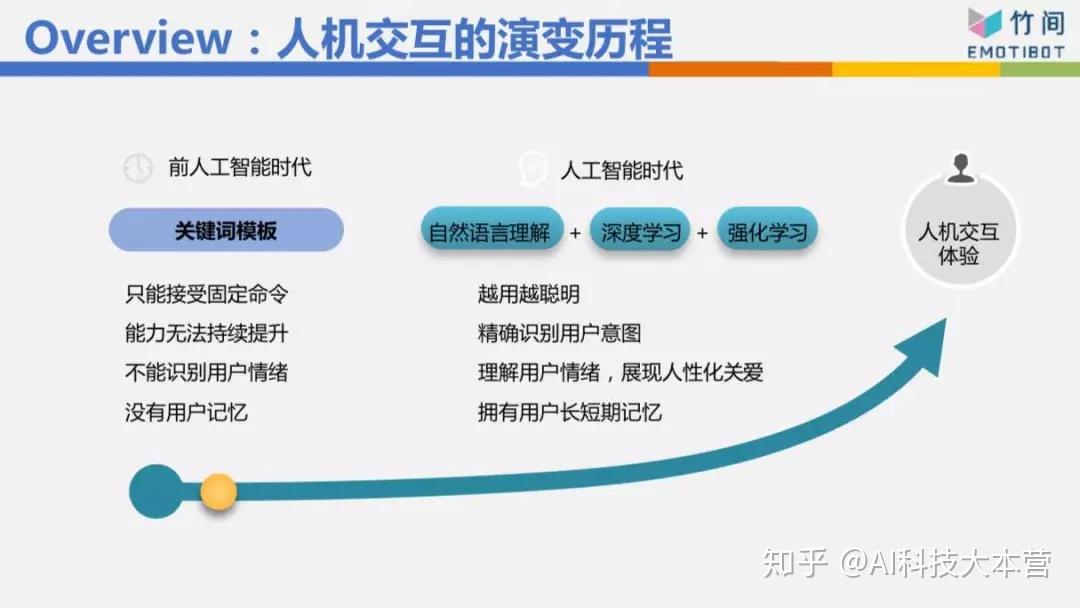
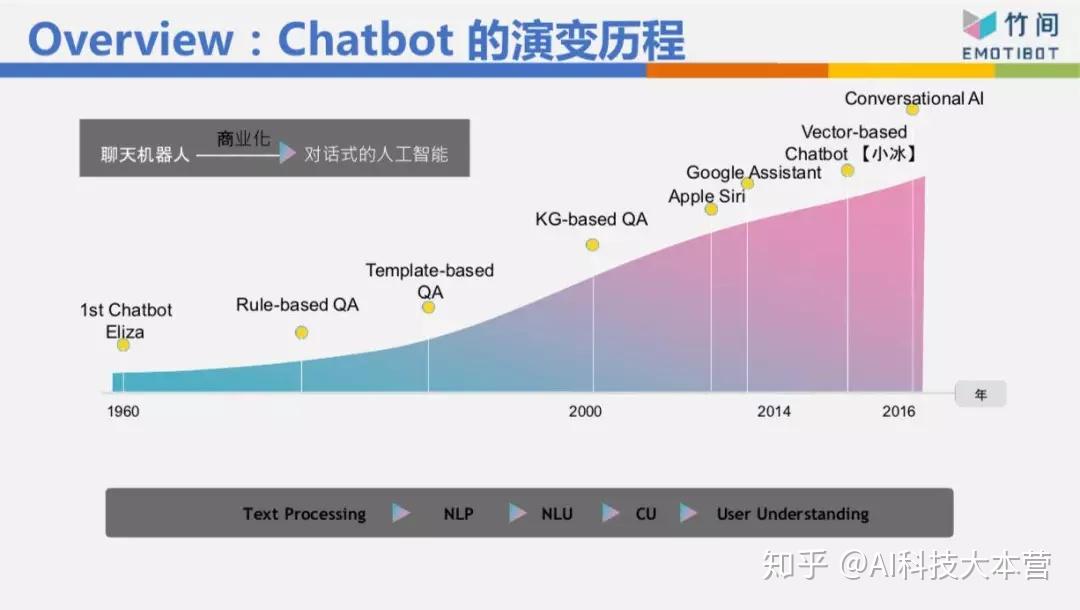
这个Chatbot的演变历程我们不细讲,但我今天要表达,在人机交互里面或者语义理解上面,我们分成三个层次。
最底层的叫自然语言理解,举例来说,我现在想说“我肚子饿”跟“我想吃东西”这两句话的句法、句型不太一样,所以分析的结果也不太一样,这是最底层的。
第二层叫“意图的理解”,这两句话虽然不一样,但它们的意图是一致的,“我肚子饿”跟“我想吃东西”可能代表我想知道附近有什么餐馆,或者帮我点个外卖,这是第二层。目前大家做的是第一层跟第二层。
其实还有第三层,第三层就是这一句话背后真正的意思是什么,比如我们在八点上这个公开课,我突然当着大家的面说“我肚子饿”跟“我想吃东西”,你们心里会有什么感受?你们心理是不是会觉得我是不是不耐烦、是不是不想讲了。你的感受肯定是负面的。今天如果我对着一个女生说“我肚子饿”,女生心里怎么想?会想我是不是要约她吃饭,是不是对她有不良企图。目前大家离第三层非常遥远,要走到那一步才是我们心目中真正要的AI,要走到那一步不可避免有情绪 、情感的识别、情境的识别、场景的识别、上下文的识别。
我们公司的名字叫“EMOTIBOT”,情感机器人,我们一开始创立时就试着把情绪 情感 的识别做好。我们情绪情感识别,光文字做了22种情绪 ,这非常变态 ,大部分公司做的是“正、负、中”三种,但是你看负面的情绪 ,有反感、愤怒、难过、悲伤、害怕、不喜欢、不高兴,这些情绪 都是负面的,但是它不太一样,我害怕、我悲伤、 我愤怒,机器人的反馈方式应该是不一样的。
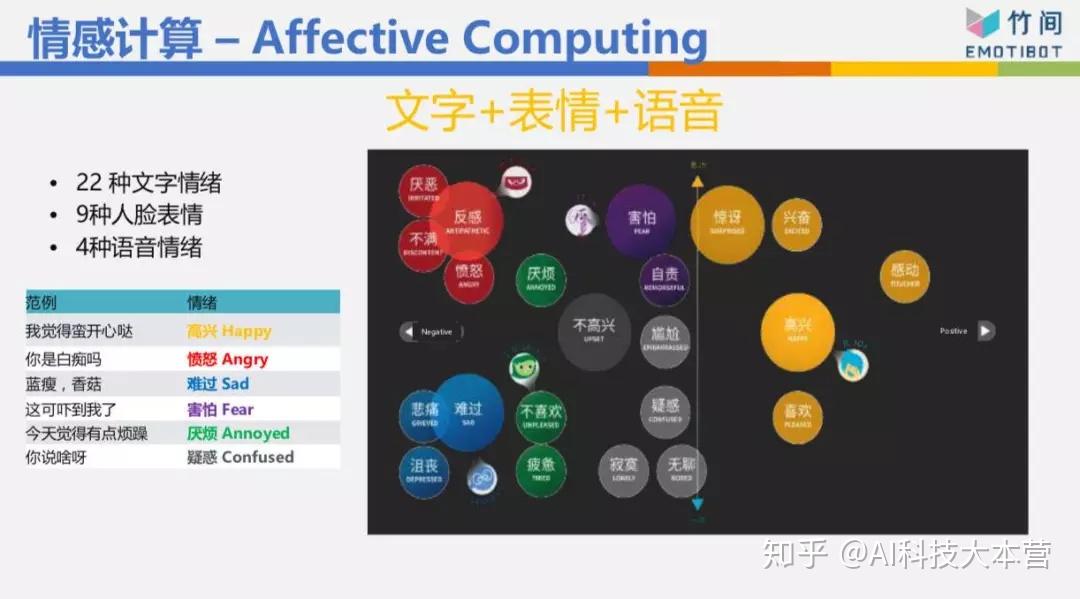
人脸表情我们做了9种,语言情绪 我们做了4种。而且我们做最多的是把这些情绪混合在一起做了多模态的情感。举个例子,像高考光结束,我今天看了一段文字:“我高考考了500分”,你看了这段文字不知道该恭喜我还是安慰我。这时要看讲话的语气,如果我的语气是说“哦,我高考考了500分。”你一听就知道我是悲伤的,所以会安慰我。所以通常语音情感 比文字情感 来得更直接。
然后人脸表情加进来,三个加在一起,又更麻烦了。我们来看一段视频,我用桌面 共享。(视频播放)“鬼知道我经历了什么”,文字上是匹配的——我已经要死了、生不如死,我的文字是愤怒的,但我的语音情绪跟脸表情是开心的,所以我的总情绪 仍然是开心的。这是把人脸表情、语音情绪 、文字情绪 混搭在一起做出来的多模态情感。

▌上下文理解技术
接下来进入比较技术面的部分,讲话聊天时,任务型的机器人一定牵扯到上下文的理解技术。
什么叫上下文理解技术?
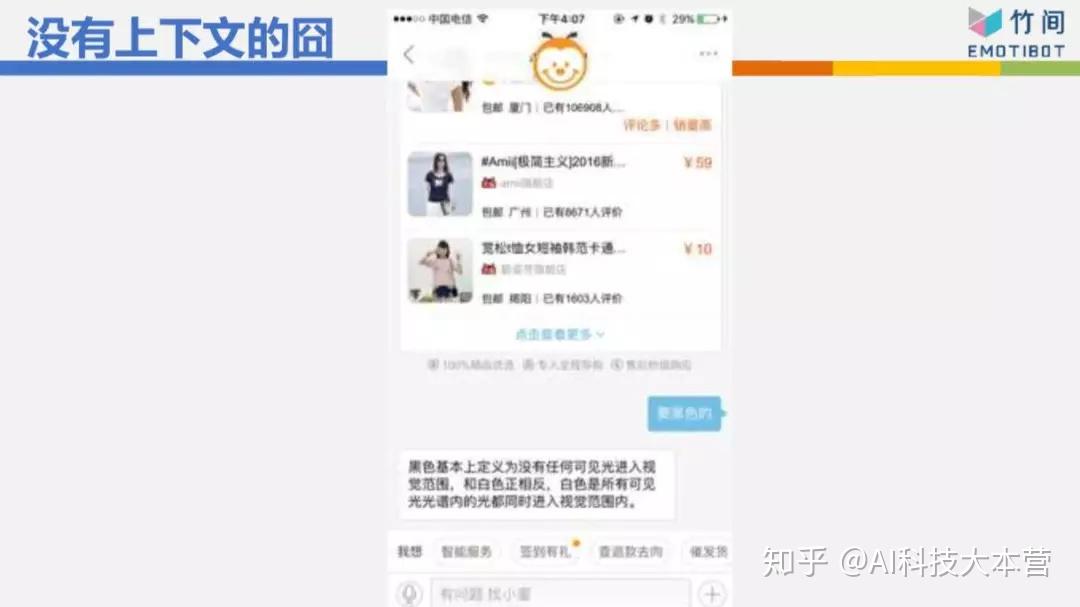
这是某个电商网站,我前面一句话跟它说“我要买T恤”,它给我3件T恤,我跟它说“要黑色的”,意思是我要黑色的那件T恤,但它完全不理解我的意思,因为没有上下文。所以它居然在跟我解释黑色的基本定义是什么,是因为不返色,所以你看不到光,所以它是黑色的。这完全不是我要的东西,所以没有上下文时,它的反应常常啼笑皆非。
我们来看看上下文怎么做,上下文有几种做法。第一种是补全与指代消解,像说“明天上海会不会下雨”,回答了“明天上海小雨”,“那后天呢”缺了主谓宾等一些东西,所以往上去找,把它补全,把“那后天呢”改成“后天上海会不会下雨”,然后机器人就有办法处理。

指代消解也是“我喜欢大张伟”,然后机器人回答说“我也喜欢他”,“他”是谁?这个代名词,我知道“他”是大张伟,所以把“我也喜欢他”改成“我也喜欢大张伟”,这样才有办法去理解。然后那个人就说“最喜欢他唱得《倍儿爽》”,那他是谁?要把它改成写“最喜欢大张伟唱的《倍儿爽》”。这两个是基本的东西,基本上每家公司都能够做得到。

然后我们看难一点的东西,可以不可以做对话主题式补全?这个开始有一些上下文在里面,“我喜欢大张伟”,第一句话目前的对话主题是大张伟,然后它回答说“对啊,我也喜欢他”改成“我也喜欢大张伟”,这没问题。
第二句话是“喉咙痛怎么办?”这有两种可能,因为我现在的对话主题是大张伟,所以可能是“喉咙痛怎么办”,也可能是“大张伟喉咙痛怎么办”,这时候怎么办?我到底应该选哪一个?先试第一个“喉咙痛怎么办”,居然就可以找到答案了,我知道能够找到好的答案,我就回答了“喉咙痛就多喝开水”,目前的对话主题也变成喉咙痛。
第三个是“他唱过什么歌?”这个他到底是谁?有两个对话主题,一个是喉咙痛,一个是大张伟,有可能是“喉咙痛他唱过什么歌”或者“大张伟他唱过什么歌”。因为优先,最近的对话主题是喉咙痛,所以我先看第一个,但是一找不到答案,所以我再去看第二个“大张伟唱过什么歌”,那我知道大张伟唱过歌,所以他唱过《倍儿爽》,我就可以回答,这是对话主题式补全。

另外,利用主题做上下文对话控制。像现在在世界杯,我问你“你喜欢英超哪支球队?”我的主题是“运动”底下的“足球”底下的“五大联赛”底样。的“英超”,我可以回答“我喜欢巴萨”,你问我英超,我回答西甲,这没有什么太大的毛病,虽然最底下的对话主题不太一样,但是前面是一样的。或者你问我足球,我可不可以回答篮球,“我比较喜欢看NBA”,这可能不太好,但是也不至于完全不行。如果我回答说“我喜欢吃蛋炒饭”这肯定是不对的,因为你问我的是运动体育里面的东西,我居然回答美食。

这个对话主题我可不可以根据上下文主题,去生成等一下那句回答应该是什么主题?我可以根据上下文去猜测等一下你的下一句回答应该有哪些关键词,我可以根据上下文猜出你下一句是什么句型,是肯定句还是正反问句。我有了关键词、有了句型、有了主题,我可以造句,造出一句回答,这也是上下文解法的一种。或者我什么东西都不管,我直接根据上下文用生成式的方式回你一句话。这个目前大家还在研究发展之中,目前的准确度还不是很高,但这是一个未来的发展方向。
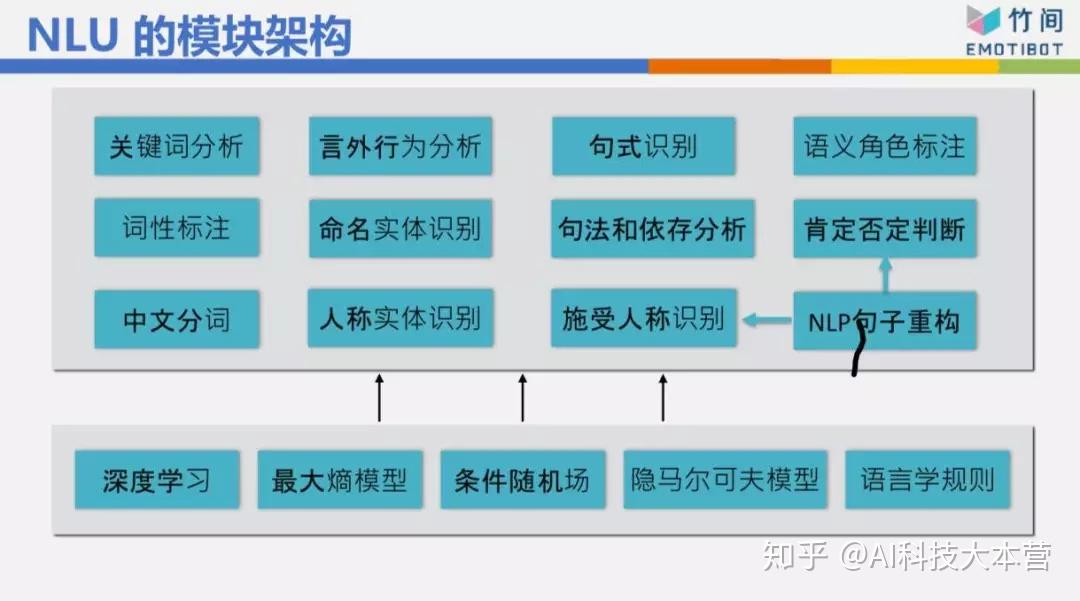
▌NLU的重要性
NLU我们做了12个模块,最基本的当然是分词,然后词性标注,是主词还是动词、形容词称、第二人称、第三人称,然后命名实体,北京有什么好玩的跟上海有什么好玩的,一个是北京,一个是上海,两个不太一样。然后我如果问“你喜欢吃苹果吗?”“等一下我们去吃麦当劳好不好?”这是一个问句,而且我在问你的个人意见,所以你的回答可能是一个肯定的,可能是一个否定的,也可能反问我一个问句说“等一下几点去吃”,无论如何,你的回答不会跟我讲“早安”或“晚安”,因为我问的是“等一下我们去吃麦当劳好不好。”我们还做了一些奇怪的东西,例如语义角色的标注 ,后面可以看到一些例子。
以这个句子来说,“我明天飞上海,住两天,要如家”整个句子的句法结构拆出来,核心动词是“飞、住、要”,把它分出来“我飞”、“飞上海”、“住两天”、“要如家”,有了这些核心动词,我知道我的意图不是订机票,如果只有“我明天飞上海”,我的意图可能是订机票,但是因为有后面的“住两天”跟“要如家”,所以根据这些东西判断出来我的意图是订酒店,根据这些东西算出来:明天入住,3天后离店,都市是上海,酒店名称叫如家酒店。整个东西就可以把它解析出来。
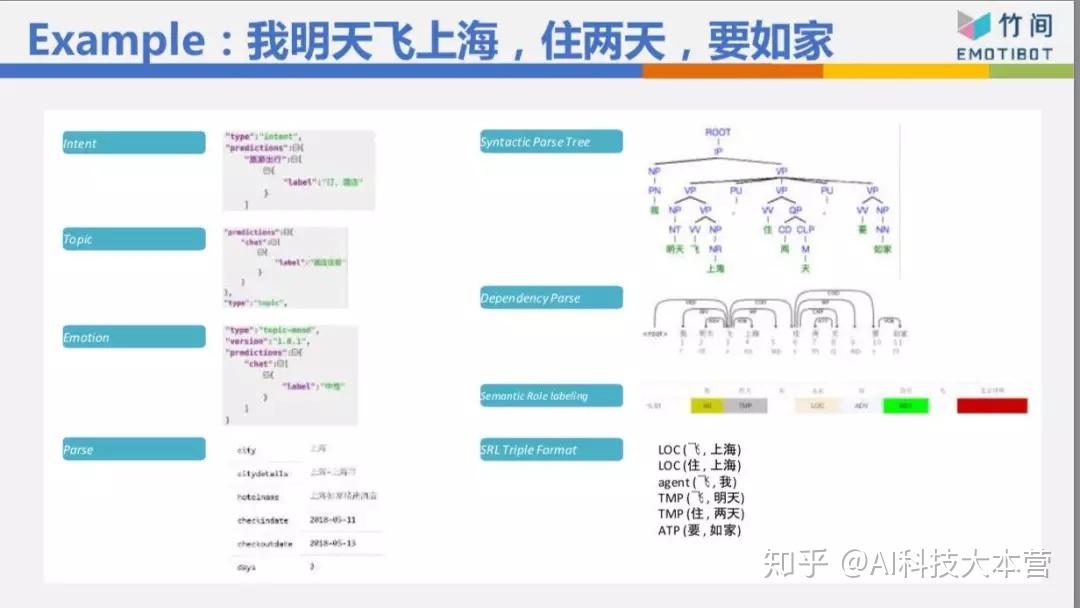
这样的解法跟深度学习黑盒子最大的差别是,这样的解法先把句子拆成一些零件,拆成一些基本的信息,我再根据这些信息,可能以深度学习的方式判断你的意图、对话主题,这样我的数据量可以小很多。如果整个大黑盒子,数据量要五十万比、一百万比、两百万比,才能够有一定的准确率。今天我做了足够的拆解,所以我的数据量三万比、五万比就够了,就可以训练出一个还不错的模型。
再介绍一下我如何利用NLU的基础信息,像“上周买衣服多少钱”这句话,我从Speach Act知道这是一个问句,是一个question-info,你不是说“上周买衣服花了好多钱”,这不是一个问句,就不需要处理。是一个问句的话,再看它是一个数量问句,还是地点的问句,还是时间的问句,“我什么时候买了这件衣服?”“我在哪里买了这件衣服?”问句不一样,后面知道查哪个数据库的哪张表。根据核心动词“花钱”跟“买衣服”,知道类别 是衣服饰品,不是吃饭、不是交通,由时间知道是“上周”,整个东西就可以帮你算出来。这等于是我一句话先经过NLU的解析,再判断你的意图和细节信息。

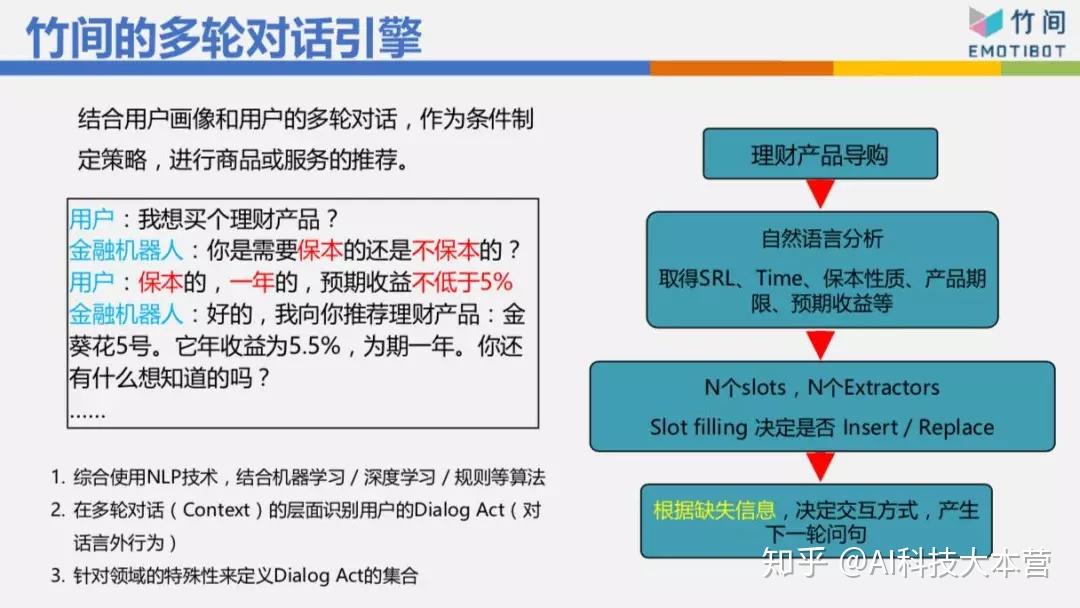
▌多轮对话与机器人平台
像刚刚订酒店那个例子,如果表明“我要订酒店”,订酒店有8个信息要抽取,这时机器人要跟你交流:你要订哪里的酒店、几号入住、几号离店、酒店名称、星级、价格等等这一堆东西。今天我们的用户不会乖乖回答。“你要订哪里的酒店?”他可能乖乖跟你说“上海的”、“北京的”,它也可能跟你说“我明天飞上海,住两天,要如家”,他一句话就告诉我四个信息,所以基本用填槽的方式,有N个槽要填。然后看看这句话里面有哪些信息,把它抽取出来,填到相对应的槽,再根据哪几个槽缺失信息决定下一轮的问句该问什么问题,这样比较聪明。举例来说,“我想要买一个理财产品”,“您需要是保本还是不保本?”我只问你保本还是不保本,结果他一次回答“保本的,一年的,预期收益不低于5个点。”他一次告诉我3个 信息,而且3个信息已经够了,我就直接帮你推荐,不用再问你“你要一年、半年还是两年的?”这样的机器人看起来就很傻。

我们来看一些Live Demo的东西


第一个是对话机器人的定制,如何快速定制自己的机器人。
我们先切到共享桌面。在这里,假设我现在创建一个机器人,我的名字“小竹子”,然后我是什么机器人?是一个聊天 的、电商的还是金融机器人?我是一个聊天机器人好了,两个步骤创建完了。然后可以做一些设置,机器人有形象,每个人拿到机器人会说:你是男生还是女生?你晚上睡觉吗?你有没有长脚?你今年几岁?你爸爸是谁?你妈妈是谁?你住在哪里?你问“你是男生是女生”时我回答“我是女生”,可不可以修改?我修改“我是精灵”或者“我没有性别”,保存。保存以后我还没有修改,因为我没有重新建模,我们先来问问看,“你是男生,还是女生?”它还是说“我是女生”。然后“你叫什么名字?”它说“叫小竹子”。我开始问它“明天上海会不会下雨?”“那北京呢?”这上下文代表北京明天会不会下雨,“北京明天有雨”,我再问“那后天呢?”这个上下文,是北京的后天还是上海的后天?应该是北京的后天,因为离北京最近。
然后再来问它一些知识类的“姚明有多高?”它告诉我是“226厘米”,我再问它“姚明的老婆有多高”,“190厘米”,还可以做些推论,例如像“谢霆锋跟陈小春有什么关系?”这个很少有人知道,谢霆锋的前妻是张柏芝,陈小春的前女友也是张柏芝,所以陈小春是谢霆锋前妻的前男友。这是知识推论。还有一些该有的功能,如果很无聊,机器会跟你聊天。你可以更改任何你想要的回答,你可以更改知识图谱,你可以建立自己的意图。
来看第二个demo,像多轮对话场景要怎么做?
我先创建一个新的场景,场景的名称叫“竹间订餐厅”,触发条件,什么样的语句会触发这个场景?我要新建一个意图,意图的名称叫“订餐厅”,使用者说“我要订位”,或者“我要吃饭”。现在有一个订餐厅的意图,我只要讲“我要吃饭”或者类似的讲法,它就知道我要进入这个场景。下一步,订餐厅有两个信息,至少要知道时间跟人数,我打算怎么问?我可以有默认的问句“你要选择的时间是什么?你要选择的人数是什么?”但这看起来很死板,我可以自定义“请问 您要订位的时间?请问总共有几位?”这两个问句分别抽取时间跟抽取人数,然后再下一步。抽取之后可以有一个外部的链接,链接到某个地方去帮你订位。现在选择回复的方式,“订位成功,您的订位时间是**,总共人数是**,谢谢”,储存,我一行代码都没有写,然后开始测试。
再来看下一个demo,直接用桌面来讲,demo订餐馆。为什么订餐馆?因为上个月谷歌demo就是订餐馆,有个机器人帮你到餐馆订位置。我说“我要订位”,它问我“是什么时间?”我这时候可以回答一个句子给它,可以跟它说“国庆节,我们有大概7、8个人,还带2个孩子。要是可以的话,帮我订一个包间,我们7点半左右到,预定8点”“好的”,它只问我一个时间,我回答了这么多东西,有没有办法理解?7、8个人是8个人,不是78个人,还带2个小孩,要是可以的话帮我订一个包间,所以是包厢,7点半左右到,所以预定8点好了,它有办法理解。“好的”,我没有跟它讲时间是早上8点还是晚上8点,“晚上8点”,“需要宝宝椅吗?”“因为我有小孩,所以一张宝宝椅”,问我“贵姓”,我说“富翁”,它帮我订好了,但没位置“要不要排号?”“好啊”,我说我有老人,它帮我排了比较方便出入的位置。“信息是否正确”“没错”,订位完成。
我们再试另外一个,“我要订位”“什么时间?”“后天晚上9点,8个人。”“要包间还是大堂?”“大堂太吵了,包间好了。”我不是用关键词做的,如果用关键词,有大堂 ,有包间,到底是哪一个?还有预定都包厢贵姓,“李”,排号。“有没有人过生日?是否有误?”“没问题”,它就帮我订好了。一个机器人如果能够做到这个地步,随便你怎么讲,你不按照顺序讲,甚至你还可以修正,说“我有8个人,不对,是9个人”,它可以知道你是9个人而不是8个人。
▌人机交互下一步
有几个案例可以分享:

第一个AIOT的平台,这个东西目前有一些公司有一些企业在做,举例来说,我跟我的手环、跟我的音箱、跟我的耳机说我在家里,我跟它说太暗了,太暗了是什么意思?假设今天我家里有很多盏智能灯都已经接到我的平台上面,所以我跟我的平台讲太暗了,有哪些东西是跟光线有关?我发现窗帘跟光线有关,电灯跟光线有关,我就跑去问说你要开客厅的灯还是厕所的灯还是厨房的灯?这样问其实非常傻,因为我可能人现在是在客厅,你干吗要问我这个东西?但是我没办法人你到底在哪里?这有几个解法,我在家里到处都装摄像头,我就知道你在哪里,但是这是一件非常可怕的事情,家里装摄像头相信里心里不太舒服。
当然过去的技术我多装几个WIFI,我装三个WIFI在你家里三个不同的地方,我利用三角定位知道你人在哪里,我知道你在客厅,你说太暗了,我就把客厅的灯打开,我只要背后都是一个同样的ALOT的中控中心帮我做这件事情。
另外一个我可能有多种选择,我说太热了,太热了到底要开窗、开空调还是开电风扇?机器问你说我要帮你开电扇还是帮你开空调?你说空调吧,现在太热,OK,机器人帮你执行,有些时候人的意图有多种可能性,多个AIOT的家居设备都跟温度控制有关,机器人可以掌握。当然他会聪明一点,不会有18个跟温度有关,他一个一个问,最后人会晕倒,这个东西不会太遥远,我认为在一年半到两年之内这些东西会出来,甚至一年会出来。慢慢你家里会变成用ALOT的整个平台跟LOT的设备来帮你管理这些东西,你会生活变得更方便。

第二个人机交互的下一步是人脸+语音的加入,我可不可以根据你人脸知道你是男生女生,你现在的情绪是什么?是长头发短头发,有没有戴眼镜,有没有胡子?语音识别当然是最基本的,这个已经非常非常成熟了,可不可以知道这句话到底代表什么意思?语音把它转变成文本,如果可以的话还可以知道你的语气,你的语音情绪是愤怒还是悲伤,还是高兴?我可以做一些参考,语音的情绪是非常重要的。

这个东西可以使用,我从人脸表情特征可以做什么,特征做了22种,性别、年龄、肤色、头发、眉头、颜值,长得漂不漂亮,脸形,特征是给人负面印象是冷酷无情,还是有正面印象你是有一个魅力值信赖的人,这第一印象这东西说不准。表情我们做了九种,喜怒哀乐、惊、惧、厌恶、藐视、困惑、中性。还有人脸的行为分析,我的视线目前是专注还是一直这样低头,显得不自信,还是眼神飘忽不定,这东西是什么意思?
我们来讲一个真实的应用的案例。

现在一些新零售,包括无人店,包含一些智慧门店,举例来说,我们在帮某个电视的大厂在某个卖场刚开业,把我们的技术放进去,同时有五家公司都是在卖电视,包括竞争对手索尼,其他知名的品牌,那个卖场开幕三天,我们做了那家夏普收入是90万,另外四家加起来40多万,光夏普一家干掉四家的总和还一倍多。这个怎么做到?第一个可不可以吸引人流?在我的店的门口摆一个屏幕,摆一些东西,你摄像头,你人经过的时候可以抓住你是男生女生,你的颜值怎么样?你的情绪怎么样?非常有趣,所有人经过停下来看,停下来看你是一个四十几岁的男生,推荐里面有什么优惠活动,你是喜欢的,你是一个20岁的女生,推荐另外的优惠活动。你是一对情侣,是一个家庭带着小孩,推荐给你的东西不一样。
大家看到这个东西之后,我进店的人就会有机会比别人多,再来我可以主动式的交互,你走到货架前面,我看到是一个长头发的女生主动跟你聊天,一个机器人,一个屏幕,一个平板,这位长头发的女士你的头发很漂亮,我这里有一些洗发水,有一些润发你有什么兴趣了解,我根据你的属性,因为你是女生长头发,给你推荐某些东西跟你对话,我会跟你说脸上有一些黑斑,我有一些遮瑕膏你要不要?在对话的过程中发现这个人的脸色越来越难看,我赶快停止这个话题,这个东西不应该继续讲下去,是人脸的特征,人脸的情绪跟整个人机交互综合的应用。
我们也可以做到,我在一些过道上面,这个商场的过道,我知道你的人进到店里面你是怎么走动,我发现你在某一台电视前面停了五分钟,停了特别久,你离开了什么都没有买。两天后你带着一家大小来了,这是什么意思?你带着老婆、带着小孩上门,这可能代表你要来做决定你是要花钱的,而且我根据你上次的线上购买记录,因为我知道你的脸部,知道你是谁,知道你的会员编号,我知道你上次买了一台2万多块的冰箱,所以我知道你的消费能力不是那种一两千块钱,你可能是两三万,我马上通知销售员跟他说,这个人来了买电视,因为他两天前看过某一些电视,而且他的消费能力是以万来计算的,是万等级,所以你上去不要推荐他四千块的电视,你就是往高往贵推荐。也是因为这样子,我们的卖场,我们的销售的业绩能够比别人好。这些东西我相信在半年一年内,大家在各种各样的商场会大量看到。
最后我们举个例子。今天你们可能说我每个人都有一个机器人,我戴一个手环,手环的背后接我的机器人,我到每个店家也都有一套机器人,麦当劳有一套机器人,肯德基有一套机器人,今天我走进麦当劳,对着我的手环说我喜欢吃巨无霸,大杯可乐去冰,我的机器人听到以后,我机器人主动去找麦当劳机器人,跟它说我要什么东西,两个机器人之间的对话,不需要用中文,不需要用人类的语言,他们直接数据格式的交换,机器人有机器人的语言,他们自己交换,交换完以后麦当劳机器人接到这个订单通知后面,告诉我三分钟之后过来拿,可不可以这样子?我的手环告诉我说,三分钟之后可以过去拿。所以未来真的变成一个机器人世界,每个人都有一个代语,机器人跟机器人去沟通,把这个东西做好。

▌Q&A 时间
今天是我的分享,再下来是交互的时间,各位有什么问题想要问的?有人问一下提一下相关技术,看一下什么相关的技术?如果是图像的话,图像最顶尖的公司各位都可以查得到,当然目前比较以安防为主,不管是刷脸门禁,慢慢做到情绪情感的部分。如果是平台的部分,目前全国做的也差不多有一二十家公司,大家各有它的优缺点,看你是一个封闭的平台或者是开放的平台,你找人工智能平台,语意理解平台,人工智能机器学习训练平台都可以找得到。
1.有人问说出现设定外的情绪机器人能处理吗?
例如说我的语音情绪做了四种,高兴、中性、愤怒跟悲伤,那突然出现一个害怕,语音出现害怕作为分类是分不出来,这是没办法处理的。
2.有人问到表情的理解,我大概讲一下我们怎么做的?
我们人脸表情光标注,标注了200万张的照片以上,每张照片三个人标注,三个人都说他是高兴,OK,他是高兴,三个人说他是悲伤,他是悲伤,三个人意见不一致,我找心理学家来做最后的判断,你去算一算,200万张的照片三个人标注,总共600万人次,你需要多少时间?多少钱?
3.多模态情绪怎么做?
通过人脸表情算出一个分数,语音情绪算出一个分数,文字的情绪算出一个分数,我们背后有两种模型,第一个规则,人脸表情就是多少分,语音情绪多少分以上,我加成上一个比重,或者说文字情绪算出来,这是一种方式。
另外一种,我们后面用的一个深度学习的模型,我们把这些所有的值标进去算出一个总情绪,当然一样需要大量的标注数据。
4.有人问对话的答案是能机器人自动合成组合出来吗?
这是自动生成的范围,目前来说我认为,我实际上看到正确率大概在3—5成之间,它回答好的大概在3成—5成,有一半的概率不靠谱。
5.知识图谱学习多少可用?
这个东西看你的领域,如果你是金融领域,金融知识可能12万、18万就够了,如果你是一个医疗领域,可能是几十万,但是如果你是聊天的领域,衣食住行、电影、电视这些东西,加起来要800万—1200万知识图谱的数据量。有些公司大企业做搜索引擎的,天生的数据量特别大,知识图谱可能有8亿,有20亿,非常非常大量的数据。
6.有人问到说交流的过程中打错字怎么办?语音转文字效果不好,如何提高意图识别准确率?
在有限的场景之下,这个有办法做到,像电视就68个意图,100个意图,可以做的非常准,真的可以转成拼音去做,或者真的用一些模糊匹配的方式,可以把匹配的阈值放大一点可以做得好。在一个聊天的场景,有限的场景这个是不可能做得好的。
这其实是包含语音识别在内的,语音识别大家的普通话不一定很标准,像我也是有口音的,所以我语音转转文字,可不可以把它转成拼音,我把平舌、翘舌、前鼻音、后鼻音把它去掉,这样ch就跟c是一样的,zh就跟z是一样的,我用这些方法是做正规化。这些东西尤其在找歌曲的名字、电影的名字、视频的名字非常有用,因为你歌曲的名字那么长,视频的名字那么长,电视剧的名字那么长,你不一定讲对,我要看《春娇志明明》,没有春娇志明,是《志明与春娇》,我要看《三生三世》,我知道三生三世十里桃花,我要看半月传,芈月传传那个芈我不会念,我念成半月传找不到,但是我发现用户查字典,问了人,下句话他讲对了我要看芈月传,我发现你上面这句话跟下面这句话句型非常非常类似,你上面那句话找不到,下面那句话居然找到了,我可不可以说可能半月传就是等于芈月传,自动把它抓出来,做得好由人工判断,人工做最后的判断,这些东西就打勾打勾,这些东西是同义词,一样就把它输入进去重新训练就好了。
7.有人问到对话主题怎么建立?
我这个屏幕有限都是跳着回答,对话主题不算很庞大了,你的主题看你做到几百种几、几千种,主题是有阶层次的关系。就是说你的对话主题做出来之后你如何确定这句话是什么主题?当然有关键词,也有机器学习、深度学习的方式都可以去做,而且准确度不会太低。
8.有人说在交流的过程中出现场景之外,怎么做到多轮?
就像刚刚那个我订酒店机票订到一半突然说我失恋了,机器人可以怎么回答?机器人可以开始跟你聊失恋的话题,订酒店就算了,这是一种解法。列另外一种解法,我订酒店订到一半失恋了,我跟你说你失恋了好可怜,敷衍你一下,继续问你说刚刚酒店还没有订,你要不要订?你要不要继续?我先把前一个场景处理掉,确定你场景已经结束,我才让你到下一个场景。
9.有人问怎么判断哪个答案更好?
假设我背后有18个模块,有20个模块,有20个模块都可以出答案,天气、讲笑话、知识图谱的聊天、各种各样的场景、订酒店、订机票,一样我一句话进来,我可不可以让每个模块举手,这个模块说这句话我可以回答,别的模块说这句话我可以回答,当然每个模块都会回答,而且每个模块除了回答以外会有一个信心分数,当然有些模块我都是100分,跑来抢答案,这个时候就要看你到底靠不靠谱?当然我在我的中控中心,我根据上下文判断我的情绪,我的意图,我的主题,我发现说你的对话主题是体育、运动,回答的对话主题是美食,我把这个答案直接丢掉,我发现你的问句是快乐的,回答居然是一句悲伤的句子,直接把它丢掉。我可以利用我的中控中心做这样的事情,还是没办法,有些模块是乱回答的话,我把它分数降低,它以后宣称它自己是100分,我都打个八折,以证明它不靠谱。
10.一语双关的语句可以理解多少?
这个非常难,这个是目前解不了的,现在世界杯,我们举例,中国乒乓球谁都打不赢,中国足球谁都踢不赢,这两句话的句型完全一模一样,但是意思可能是相反的,那这个东西怎么理解?老实话目前还做不到这个地步,不知道五年后、十年后可能有机会,刚刚两句话你去问一个小学生,其实小学生也搞不懂,你要足够的社会知识,你有足够的社会历练你才知道这句话什么意思。
11.怎么知道机器的回答对不对?
有几种方法了,有一种还是看人工,我今天机器人回答,这个用户就生气了,用户说你这个机器人好笨,我都听不懂你在讲什么,显然这个机器人回答不好,我就可以反馈回去说这个回答不对。另外一种,我发现我回答以后,这个用户决定直接转人工,假设我是一个智能客服,回答完以后用户决定转人工,代表我刚刚的回答肯定是有问题的。第三种是说,我同样的问题问了第三次,我开户该带哪些证件?机器人回答我不满意,我再问我到底该怎么开户?再问说开户到底应该怎么办?我三个句子不太一样,其实意思是一样的,所以今天当问了第三句话,代表我前面的回答一定不对,用户会问到第三句,基本上靠人的反馈来做。
12.有人问对于学生有什么建议?
在校的学生我的建议是说,你要先想,你现在有很多(01:00:35英文)各式各样的框架,数据网络上也都能拿得到,甚至这些代码都可以直接下载,你就可以做一些基本的东西,这是练习,你最后要解决仍然是真实的问题,你到底要解决什么问题?解决那些问题你打算怎么解?你要设定一个目标,解到使什么地步才是人类可以用的,而不是做一个模型,做一个PPT,这个是不够的,你越早能够知道人工智能实际的技术边界在哪里,什么东西只是一个花俏的东西,什么是东西是真的可以用的,这个对你未来进入职场会有帮助,或者对你未来研究的方向有帮助,毕竟人工智能帮助人,帮助各种各样的行业,才能够帮上忙。
13.有人问什么时候机器人可以写一本中文小说,或者机器人什么时候可以思考?
我觉得还非常非常遥远,也许十年,也许十五年,机器人的思考方式一定跟人是不一样的,但是现在机器人都是一大堆的规则,我不觉得机器人是可以思考,甚至有创造力。
14.五年内人工智能的实际应用场景结合最好的方向?
这个我无法预测,人工智能目前都在摸索,我大概可以猜到一年后会有哪些东西?哪些东西是假的,哪些东西不可能实现的,哪些东西是有机会的,一年内我大概可以猜得出来,五年内我猜不出来,因为技术的发展超过我的控制范围。但是我觉得深度学习、机器学习没办法解决NLP,NLP的复杂度不是可以解决的,而且没有这样的数据链,NLP要解决好也许还出现更新的科技能够出来。
15.如何断句,如何分词?
这样说好了这其实是一个大的难题,我在黄浦江边,我是分成黄浦跟江边,还是黄浦江跟边,你好可爱,是你好、可爱还是你好加可爱,我们先不要讲长句,光这个短句分可能分错,有时候你好在一起,有时候你好要分开,这个东西只能说我拿现在的东西,我再去不断不断优化,而且有可能说,我们累积好几万的bug,我去看这些bug我可能用新的模型来解,新的bug可能用新的算法来解,一群一群去解这些问题,才能慢慢前进,这个没有什么快速的方法。
我们今天的分享就到这里。谢谢各位!
NLP概述和文本自动分类算法详解
自然语言处理一直是人工智能领域的重要话题,更是 18 年的热度话题,为了在海量文本中及时准确地获得有效信息,文本分类技术获得广泛关注,也给大家带来了更多应用和想象的空间。
本文根据达观数据联合创始人张健的直播内容《NLP 概述及文本自动分类算法详解》整理而成。
一、 NLP 概述
1.文本挖掘任务类型的划分
文本挖掘任务大致分为四个类型:类别到序列、序列到类别、同步的(每个输入位置都要产生输出)序列到序列、异步的序列到序列。
同步的序列到序列的例子包括中文分词,命名实体识别和词性标注。异步的序列到序列包括机器翻译和自动摘要。序列到类别的例子包括文本分类和情感分析。类别(对象)到序列的例子包括文本生成和形象描述。
这个分类总结挺好的
2.文本挖掘系统整体方案
达观数据一直专注于文本语义,文本挖掘系统整体方案包含了 NLP 处理的各个环节,从处理的文本粒度上来分,可以分为篇章级应用、短串级应用和词汇级应用。
篇章级应用有六个方面,已经有成熟的产品支持企业在不同方面的文本挖掘需求:
- 垃圾评论:精准识别广告、不文明用语及低质量文本。
- 黄反识别:准确定位文本中所含涉黄、涉政及反动内容。
- 标签提取:提取文本中的核心词语生成标签。
- 文章分类:依据预设分类体系对文本进行自动归类。
- 情感分析:准确分析用户透过文本表达出的情感倾向。
- 文章主题模型:抽取出文章的隐含主题。
为了实现这些顶层应用,达观数据掌握从词语短串分析个层面的分析技术,开发了包括中文分词、专名识别、语义分析和词串分析等模块。
达观数据文本挖掘架构图
3.序列标注应用:中文分词
同步的序列到序列,其实就是序列标注问题,应该说是自然语言处理中最常见的问题。序列标注的应用包括中文分词、命名实体识别和词性标注等。序列标注问题的输入是一个观测序列,输出的是一个标记序列或状态序列。
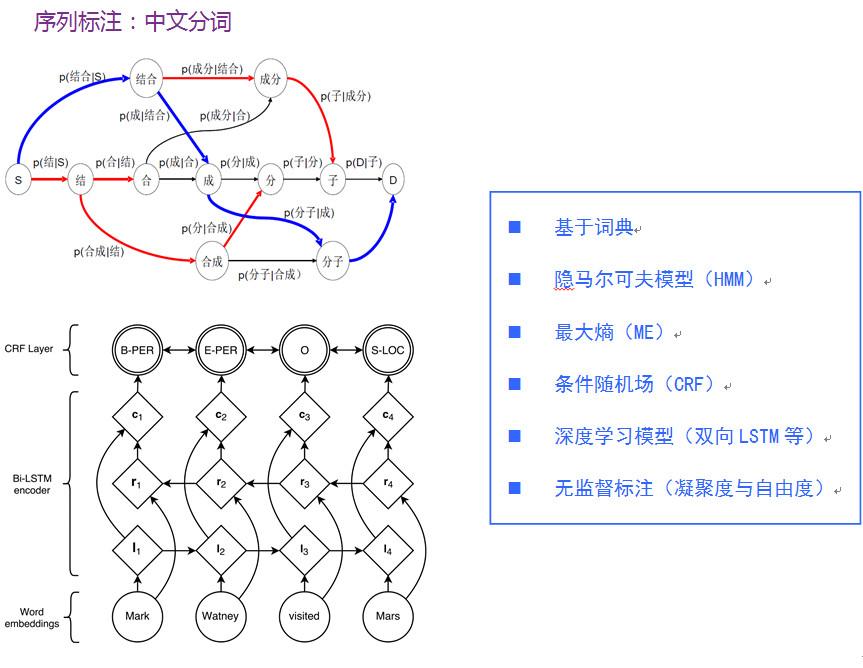
举中文分词为例,处理「结合成分子」的观测序列,输出「结合/成/分子」的分词标记序列。针对中文分词的这个应用,有多种处理方法,包括基于词典的方法、隐马尔可夫模型(HMM)、最大熵模型、条件随机场(CRF)、深度学习模型(双向 LSTM 等)和一些无监督学习的方法(基于凝聚度与自由度)。
4.序列标注应用:NER
命名实体识别:Named Entity Recognition,简称 NER,又称作「专名识别」,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。通常包括实体边界识别和确定实体类别。

对与命名实体识别,采取不同的标记方式,常见的标签方式包括 IO、BIO、BMEWO 和 BMEWO+。其中一些标签含义是:
- B:begin
- I:一个词的后续成分
- M:中间
- E:结束
- W:单个词作为实体
大部分情况下,标签体系越复杂准确度也越高,但相应的训练时间也会增加。因此需要根据实际情况选择合适的标签体系。通常我们实际应用过程中,最难解决的还是标注问题。所以在做命名实体识别时,要考虑人工成本问题。
5.英文处理
在 NLP 领域,中文和英文的处理在大的方面都是相通的,不过在细节方面会有所差别。其中一个方面,就是中文需要解决分词的问题,而英文天然的就没有这个烦恼;另外一个方面,英文处理会面临词形还原和词根提取的问题,英文中会有时态变换(made==>make),单复数变换(cats==>cat),词根提取(arabic==>arab)。
在处理上面的问题过程中,不得不提到的一个工具是 WordNet。WordNet 是一个由普林斯顿大学认识科学实验室在心理学教授乔治•A•米勒的指导下建立和维护的英语字典。在 WordNet 中,名词、动词、形容词和副词各自被组织成一个同义词的网络,每个同义词集合都代表一个基本的语义概念,并且这些集合之间也由各种关系连接。我们可以通过 WordNet 来获取同义词和上位词。
6.词嵌入
在处理文本过程中,我们需要将文本转化成数字可表示的方式。词向量要做的事就是将语言数学化表示。词向量有两种实现方式:One-hot 表示,即通过向量中的一维 0/1 值来表示某个词;词嵌入,将词转变为固定维数的向量。
word2vec 是使用浅层和双层神经网络产生生词向量的模型,产生的词嵌入实际上是语言模型的一个副产品,网络以词表现,并且需猜测相邻位置的输入词。word2vec 中词向量的训练方式有两种,cbow(continuous bags of word)和 skip-gram。cbow 和 skip-gram 的区别在于,cbow 是通过输入单词的上下文(周围的词的向量和)来预测中间的单词,而 skip-gram 是输入中间的单词来预测它周围的词。
7.文档建模
要使计算机能够高效地处理真实文本,就必须找到一种理想的形式化表示方法,这个过程就是文档建模。文档建模一方面要能够真实地反映文档的内容,另一方面又要对不同文档具有区分能力。文档建模比较通用的方法包括布尔模型、向量空间模型(VSM)和概率模型。其中最为广泛使用的是向量空间模型。
二、文本分类的关键技术与重要方法
1.利用机器学习进行模型训练
文本分类的流程包括训练、文本语义、文本特征处理、训练模型、模型评估和输出模型等几个主要环节。其中介绍一下一些主要的概念。
- 文档建模:概率模型,布尔模型,VSM;
- 文本语义:分词,命名实体识别,词性标注等;
- 文本特征处理:特征降维,包括使用评估函数(TF-IDF,互信息方法,期望交叉熵,QEMI,统计量方法,遗传算法等);特征向量权值计算;
- 样本分类训练:朴素贝叶斯分类器,SVM,神经网络算法,决策树,Ensemble 算法等;
- 模型评估:召回率,正确率,F-测度值;
2.向量空间模型
向量空间模型是常用来处理文本挖掘的文档建模方法。VSM 概念非常直观——把对文本内容的处理简化为向量空间中的向量运算,并且它以空间上的相似度表达语义的相似度,直观易懂。
当文档被表示为文档空间的向量时,就可以通过计算向量之间的相似性来度量文档间的相似性。它的一些实现方式包括:
1)N-gram 模型:基于一定的语料库,可以利用 N-Gram 来预计或者评估一个句子是否合理;
2)TF-IDF 模型:若某个词在一篇文档中出现频率 TF 高,却在其他文章中很少出现,则认为此词具有很好的类别区分能力;
3)Paragraph Vector 模型:其实是 word vector 的一种扩展。Gensim 中的 Doc2Vec 以及 Facebook 开源的 Fasttext 工具也是采取了这么一种思路,它们将文本的词向量进行相加/求平均的结果作为 Paragraph Vector。
3.文本特征提取算法
目前大多数中文文本分类系统都采用词作为特征项,作为特征项的词称作特征词。这些特征词作为文档的中间表示形式,用来实现文档与文档、文档与用户目标之间的相似度计算。如果把所有的词都作为特征项,那么特征向量的维数将过于巨大。有效的特征提取算法,不仅能降低运算复杂度,还能提高分类的效率和精度。
文本特征提取的算法包含下面三个方面:
1)从原始特征中挑选出一些最具代表文本信息的特征,例如词频、TF-IDF 方法;
2)基于数学方法找出对分类信息共现比较大的特征,主要例子包括互信息法、信息增益、期望交叉熵和统计量方法;
3)以特征量分析多元统计分布,例如主成分分析(PCA)。
4.文本权重计算方法
特征权重用于衡量某个特征项在文档表示中的重要程度或区分能力的强弱。选择合适的权重计算方法,对文本分类系统的分类效果能有较大的提升作用。
特征权重的计算方法包括:
1)TF-IDF;
2)词性;
3)标题;
4)位置;
5)句法结构;
6)专业词库;
7)信息熵;
8)文档、词语长度;
9)词语间关联;
10)词语直径;
11)词语分布偏差。
其中提几点,词语直径是指词语在文本中首次出现的位置和末次出现的位置之间的距离。词语分布偏差所考虑的是词语在文章中的统计分布。在整篇文章中分布均匀的词语通常是重要的词汇。
5.分类器设计
由于文本分类本身是一个分类问题,所以一般的模式分类方法都可以用于文本分类应用中。
常用分类算法的思路包括下面四种:
1)朴素贝叶斯分类器:利用特征项和类别的联合概率来估计文本的类别概率;
2)支持向量机分类器:在向量空间中找到一个决策平面,这个平面能够最好的切割两个分类的数据点,主要用于解决二分类问题;
3)KNN 方法:在训练集中找到离它最近的 k 个临近文本,并根据这些文本的分类来给测试文档分类;
4)决策树方法:将文本处理过程看作是一个等级分层且分解完成的复杂任务。
6.分类算法融合
聚合多个分类器,提高分类准确率称为 Ensemble 方法。
利用不同分类器的优势,取长补短,最后综合多个分类器的结果。Ensemble 可设定目标函数 (组合多个分类器),通过训练得到多个分类器的组合参数 (并非简单的累加或者多数)。

我们这里提到的 ensemble 可能跟通常说的 ensemble learning 有区别。主要应该是指 stacking。Stacking 是指训练一个模型用于组合其他各个模型。即首先我们先训练多个不同的模型,然后再以之前训练的各个模型的输出为输入来训练一个模型,以得到一个最终的输出。在处理 ensemble 方法的时候,需要注意几个点。基础模型之间的相关性要尽可能的小,并且它们的性能表现不能差距太大。
多个模型分类结果如果差别不大,那么叠加效果也不明显;或者如果单个模型的效果距离其他模型比较差,也是会对整体效果拖后腿。
三、文本分类在深度学习中的应用
1.CNN 文本分类
采取 CNN 方法进行文本分类,相比传统方法会在一些方面有优势。
基于词袋模型的文本分类方法,没有考虑到词的顺序。
基于卷积神经网络(CNN)来做文本分类,可以利用到词的顺序包含的信息。如图展示了比较基础的一个用 CNN 进行文本分类的网络结构。CNN 模型把原始文本作为输入,不需要太多的人工特征。CNN 模型的一个实现,共分四层:
- 第一层是词向量层,doc 中的每个词,都将其映射到词向量空间,假设词向量为 k 维,则 n 个词映射后,相当于生成一张 n*k 维的图像;
- 第二层是卷积层,多个滤波器作用于词向量层,不同滤波器生成不同的 feature map;
- 第三层是 pooling 层,取每个 feature map 的最大值,这样操作可以处理变长文档,因为第三层输出只依赖于滤波器的个数;
- 第四层是一个全连接的 softmax 层,输出是每个类目的概率,中间一般加个 dropout,防止过拟合。
有关 CNN 的方法一般都围绕这个基础模型进行,再加上不同层的创新。
比如第一个模型在输入层换成 RNN,去获得文本通过 rnn 处理之后的输出作为卷积层的输入。比如说第二个是在 pooling 层使用了动态 kmax pooling,来解决样本集合文本长度变化较大的问题。比如说第三种是极深网络,在卷积层做多层卷积,以获得长距离的依赖信息。CNN 能够提取不同长度范围的特征,网络的层数越多,意味着能够提取到不同范围的特征越丰富。不过 cnn 层数太多会有梯度弥散、梯度爆炸或者退化等一系列问题。
为了解决这些问题,极深网络就通过 shortcut 连接。残差网络其实是由多种路径组合的一个网络,残差网络其实是很多并行子网络的组合,有些点评评书残差网络就说它其实相当于一个 Ensembling。
2.RNN 与 LSTM 文本分类
CNN 有个问题是卷积时候是固定 filter_size,就是无法建模更长的序列信息,虽然这个可以通过多次卷积获得不同范围的特征,不过要付出增加网络深度的代价。
Rnn 的出现是解决变长序列信息建模的问题,它会将每一步中产生的信息都传递到下一步中。
首先我们在输入层之上,套上一层双向 LSTM 层,LSTM 是 RNN 的改进模型,相比 RNN,能够更有效地处理句子中单词间的长距离影响;而双向 LSTM 就是在隐层同时有一个正向 LSTM 和反向 LSTM,正向 LSTM 捕获了上文的特征信息,而反向 LSTM 捕获了下文的特征信息,这样相对单向 LSTM 来说能够捕获更多的特征信息,所以通常情况下双向 LSTM 表现比单向 LSTM 或者单向 RNN 要好。
如何从物理意义上来理解求平均呢?这其实可以理解为在这一层,两个句子中每个单词都对最终分类结果进行投票,因为每个 BLSTM 的输出可以理解为这个输入单词看到了所有上文和所有下文(包含两个句子)后作出的两者是否语义相同的判断,而通过 Mean Pooling 层投出自己宝贵的一票。
3.Attention Model 与 seq2seq
注意力模型 Attention Model 是传统自编码器的一个升级版本。传统 RNN 的 Encoder-Decoder 模型,它的缺点是不管无论之前的 context 有多长,包含多少信息量,最终都要被压缩成固定的 vector,而且各个维度维度收到每个输入维度的影响都是一致的。为了解决这个问题,它的 idea 其实是赋予不同位置的 context 不同的权重,越大的权重表示对应位置的 context 更加重要。
现实中,举一个翻译问题:jack ma dances very well 翻译成中文是马云跳舞很好。其中,马云应该是和 jack ma 关联的。
Attention Model 是当前的研究热点,它广泛地可应用于文本生成、机器翻译和语言模型等方面。
4.Hierarchical Attention Network
下面介绍层次化注意力网络。
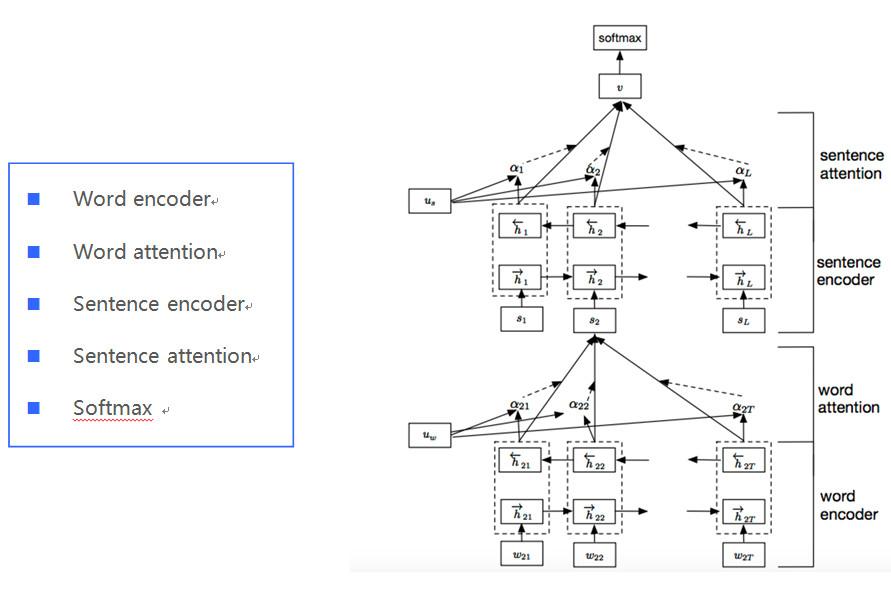
词编码层是首先把词转化成词向量,然后用双向的 GRU 层, 可以将正向和反向的上下文信息结合起来,获得隐藏层输出。第二层是 word attention 层。attention 机制的目的是要把一个句子中,对句子的含义最重要,贡献最大的词语找出来。
为了衡量单词的重要性, 我们用 u_it 和一个随机初始化的上下文向量 u_w 的相似度来表示,然后经过 softmax 操作获得了一个归一化的 attention 权重矩阵 a_it,代表句子 i 中第 t 个词的权重。结合词的权重,句子向量 s_i 看作组成这些句子的词向量的加权求和。
第三层是句子编码层,也是通过双向 GRU 层, 可以将正向和反向的上下文信息结合起来,获得隐藏层输出。
到了第四层是句子的注意力层,同词的注意力层差不多,也是提出了一个句子级别的上下文向量 u_s, 来衡量句子在文中的重要性。输出也是结合句子的权重,全文的向量表示看做是句子向量的加权求和。
到了最后,有了全文的向量表示,我们就直接通过全连接 softmax 来进行分类。
四、案例介绍
1.新闻分类
新闻分类是最常见的一种分类。其处理方法包括:
1)定制行业专业语料,定期更新语料知识库,构建行业垂直语义模型。
2)计算 term 权重,考虑到位置特征,网页特征,以及结合离线统计结果获取到核心的关键词。
3)使用主题模型进行语义扩展
4)监督与半监督方式的文本分类

2.垃圾广告黄反识别
垃圾广告过滤作为文本分类的一个场景有其特殊之处,那就是它作为一种防攻击手段,会经常面临攻击用户采取许多变换手段来绕过检查。
处理这些变换手段有多重方法:
- 一是对变形词进行识别还原,包括要处理间杂特殊符号,同音、简繁变换,和偏旁拆分、形近变换。
- 二是通过语言模型识别干扰文本,如果识别出文本是段不通顺的「胡言乱语」,那么他很可能是一段用于规避关键字审查的垃圾文本。
- 三是通过计算主题和评论的相关度匹配来鉴别。
- 四是基于多种表达特征的分类器模型识别来提高分类的泛化能力。
3.情感分析
情感分析的处理办法包括:
1)基于词典的情感分析,主要是线设置情感词典,然后基于规则匹配(情感词对应的权重进行加权)来识别样本是否是正负面。
2)基于机器学习的情感分析,主要是采取词袋模型作为基础特征,并且将复杂的情感处理规则命中的结果作为一维或者多维特征,以一种更为「柔性」的方法融合到情感分析中,扩充我们的词袋模型。
3)使用 dnn 模型来进行文本分类,解决传统词袋模型难以处理长距离依赖的缺点。
4.NLP 其他应用
NLP 在达观的其他一些应用包括:
1)标签抽取;
2)观点挖掘;
3)应用于推荐系统;
4)应用于搜索引擎。
标签抽取有多种方式:基于聚类的方法实现。此外,现在一些深度学习的算法,通过有监督的手段实现标签抽取功能。
就观点挖掘而言,举例:床很破,睡得不好。我抽取的观点是「床破」,其中涉及到语法句法分析,将有关联成本提取出来。
搜索及推荐,使用到 NLP 的地方也很多,如搜索引擎处理用户查询的纠错,就用到信道噪声模型实行纠错处理。
最后,给喜爱 NLP 的朋友推荐一个赛事活动,也是达观数据主办的「达观杯」文本智能处理挑战赛,此次比赛以文本自动分类为赛题,如果对上文讲到的算法有想练习或者想深入实践,可拿比赛来练习充实一下,目前赛事已有近3000份作品提交。
“达观杯”文本智能处理挑战赛-竞赛信息-DC竞赛www.dcjingsai.com
下周四 7 月 31日晚还为大家准备了关于NLP的分享直播,感兴趣可点击链接入群了解详情。
NLP 笔记 - Spelling, Edit Distance, and Noisy Channels2017-02-02
CMU 11611 的课程笔记。这一篇介绍拼写的检查和更正,主要研究打字者键入的文本,同时这样的算法也可以应用于 OCR 和手写体识别。 这篇博客要解决的三个问题:
拼写错误模式Kukich(1992) 把人的打字错误分为两大类:打字操作错误(typographic error)和 认知错误(cognitive error)。
所以单词的拼写错误其实有两类,Non-word Errors 和 Real-word Errors。前者指那些拼写错误后的词本身就不合法,如错误的将“giraffe”写成“graffe”;后者指那些拼写错误后的词仍然是合法的情况,如将“there”错误拼写为“three”(形近),将“peace”错误拼写为“piece”(同音),这一篇主要讲 Non-word Errors。 补充: OCR 错误分为五类:替代、多重替代、空白脱落、空白插入和识别失败 非词错误的检查与更正非词错误的检查一般有两种方法,一是 使用词典,二是 检查序列 使用词典看键入词是否出现在了词典中。用来做拼写错误检查的词典一般还要包括形态分析模式,来表示能产性的屈折变换和派生词。词典通常是哈希表,用 integer 代替 string,来提高 performance。 检查序列这个方法是自己概括的。类似于 “letter combination” 的思想。截取单词的部分字母,来检查这个字母序列在词典中出现的频率如何,是不是根本不会出现这种排列组合,如 “xy” 这个序列就基本不会出现在单词中,所以判断这个词是错误的。然而截取的长度很难定义,而且也需要使用词典。 非词错误改正查找词典中与 error 最近似的词,常见的方法有 Shortest weighted edit distance 和 Highest noisy channel probability。 编辑距离(edit distance)编辑距离,顾名思义,把一个符号串转换为另一个符号串所需的最小编辑操作的次数(how many letter changes to map A to B)。Leetcode 上有相应的题目。 编辑距离的 4 种转换方式
示例 下图表示如何从 intention 变换到 execution。 由上图可知 intention 变换到 execution 的 Levenshtein 距离是 5。 算法最小编辑距离的算法。用动态规划(dynamic programming)来解决。 加上 transposition 的 Levenshtein 距离: Levenshtein Distanceintention 变换到 execution 的最小编辑距离。 Damerau-Levenshtein(DL) distanceOptimal String Alignment(OSA) distance与 唯一的差别就是多了下面几行: 噪声信道模型(Noisy Channel Model)Noisy Channel Model 即噪声信道模型,或称信源信道模型,这是一个普适性的模型,被用于 语音识别、拼写纠错、机器翻译、中文分词、词性标注、音字转换 等众多应用领域。噪声信道模型本身是一个贝叶斯推理的特殊情况。 其形式很简单,如下图所示: 应用于拼写纠错任务的流程如下: noisy word(即 spelling error)被看作 original word 通过 noisy channel 转换得到。由于在信道中有噪声,我们很难辨认词汇形式的真实单词的面目。我们的目的就是建立一个信道模型,使得能够计算出这个真实单词是如何被噪声改变面目的,从而恢复它的本来面目。噪声就是给正确的拼写戴上假面具的拼写错误,它有很多来源:发音变异、音子实现时的变异以及来自信道的声学方面的变异(扩音器、电话网络等)。 无论单词 separate 是怎样错误拼写了,我们只想把它识别为 separate。也就是,给定 observation,我们的任务是确定这个 observation 属于哪个类别的集合。所以,我们考虑一切可能的类,也就是一切可能的单词,在这些单词中,我们只想选择那些最有可能给出已有的 observation 的单词。也就是,在词汇 V 的所有单词中,我们只想使得 P(Word|Observation)最大的那个单词,也就是我们对单词 W 的正确估计就是 argmaxP(W|O) 现在已知 noisy word(用 O 表示)如何求得最大可能的 original word(用 W 表示),公式如下: argmaxw∈VP(W|O)=argmaxP(W)P(O|W)P(O) (Bayes Rule)=argmaxP(W)∗P(O|W) (denom is constant)
看一下留下的两个 factor:
Bayes 方法应用于拼写的算法分两个步骤:
Generate candidate words举个例子,给定拼写错误“acress”,首先通过词典匹配容易确定为 “Non-word spelling error”;然后通过计算最小编辑距离获取最相似的 candidate correction。下面是通过 insertion, deletion, substitution, transposition 四种操作转化产生且编辑距离为 1 的 candidate words。 此时,我们希望选择概率最大的 W 作为最终的拼写建议,基于噪声信道模型思想,需要进一步计算 P(W) 和 P(O|W)。 Language model probability通过对语料库计数、平滑等处理可以很容易建立语言模型,即可得到 P(w),如下表所示,计算 Unigram Prior Probability(word 总数:404,253,213) Channel model probabilityP(O|W)=probability of the edit
P(O|W)的精确计算至今还是一个没有解决的课题,我们可以进行简单的估算,用 confusion matrix,confusion matrix 是一个 26*26 的矩阵,表示一个字母被另一个字母错误替代的次数,有 4 种 confusion matrix(因为有四种错误)。 基于大量pair 计算 del、ins、sub 和 trans 四种转移矩阵,然后求得转移概率 P(O|W),这里用 P(x|w) 表示:
Calculation计算P(“acress”|w)如下: 计算P(w)P(“acress”|w)如下: “across”相比其他 candidate 可能性更大。 Evaluation一些测试集: Other application噪声信道模型:Y →
Channel →
X 真词错误的检查和更正25%-40% 的错误是真词(Real-word),比如说 Can they lave him my messages? / The study was conducted mainly be John Black. 这类错误。真词错误的检查和更正往往依赖于上下文。 真词(Real-word)的检查和纠正:
对一个句子中的每个单词,都选出与之编辑距离为 1 的所有单词作为候选单词(包括原单词本身),也就是说一个句子 N 个单词,就有 N 个 candidate set,然后从每个单词 set 里各取出一个单词组成一个句子,求 P(W) 最大的单词序列 简化版,就是在所有 candidate words 里,每次只选出一个单词,与其它原词组成句子,然后同样求 P(W) 最大的单词序列。 真词纠正和非词纠正的逻辑相同,都有 language model 概率和 channel model 概率,不同的是对真词纠正,channel model 的概率包含了 p(w|w) 也就是完全没有错误的概率。 拼写错误更正系统为了使人机交互(HCI)的体验更加友好,我们可以根据拼写检查的 confidence 来决定对其进行哪种操作
Phone’c error model
噪声信道模型的改进可以改进/思考的方向:
在实际应用中,我们并不会直接把 prior 和 error model probability 相乘,因为我们不能作出独立性假设,所以,我们会用权重来计算: w^=argmaxw∈VP(o|w)P(w)λ
通常从训练集里学习 λ
参数。 有其他的方法对噪声信道模型进行改进,如允许更多的编辑(ph → f, le → al, etc.),把发音特征加入信道等。另外,也可以把 channel model 和 language model 当做特征,并加入其他特征,来训练分类器来进行拼写错误的改正。 根据可能影响 p(misspelling|word) 的因素来提取特征: |
|||||||||||||
NLP Category知识抽取-事件抽取10-15
知识抽取-实体及关系抽取09-15
论文梳理:问题生成(QG)与答案生成(QA)的结合07-08
论文笔记 - Machine Comprehension by Text-to-Text Neural Question Generation06-03
论文笔记 - Making Neural QA as Simple as Possible but not Simpler(FastQA)05-13
论文笔记 - Semi-Supervised QA with Generative Domain-Adaptive Nets04-07
论文笔记 - Bi-Directional Attention Flow for Machine Comprehension04-01
论文笔记 - Fast and Accurate Reading Comprehension by Combining Self-Attention and Convolution03-25
扯扯 Semi-hard Negative Samples03-17
论文笔记 - 基于神经网络的推理03-05
NLP Category论文笔记 - 从神经图灵机 NTM 到可微分神经计算机 DNC01-20
NLP笔记 - 多轮对话之对话管理(Dialog Management)01-03
论文笔记 - Learning to Remember Translation History with a Continuous Cache12-20
论文笔记 - Memory Networks12-04
论文笔记 - HRED 与 VHRED11-17
论文笔记 - Copy or Generate10-25
经典的端到端聊天模型10-05
NLP 笔记 - Discourse Analysis09-20
Neo4j Cypher Cheetsheet09-11
EMNLP 2017 北京论文报告会笔记08-21
NLP Category论文笔记 - A Neural Attention Model for Abstractive Sentence Summarization08-08
NLP 笔记 - Neural Machine Translation07-10
AWS Lambda + API Gateway + DynamoDB 添加 slash command 待办清单07-04
AWS API Gateway + Lambda + Slack App - 新建 slash command06-19
AWS API Gateway + Lambda 教程 - 生成随机数06-18
AWS Lex 创建 Slack Bot - Integrating Lex Bot with Slack06-09
NLP 笔记 - Sentiment Analysis06-01
论文笔记 - Learning to Extract Conditional Knowledge for Question Answering using Dialogue05-24
NLP 笔记 - Text Summarization05-10
NLP 笔记 - Machine Translation05-01
NLP CategoryNLP笔记 - NLU之意图分类04-27
NLP 笔记 - Compositional Semantics04-13
NLP笔记 - Relation Extraction04-10
NLP 笔记 - Knowledge Representation04-07
NLP 笔记 - Meaning Representation Languages04-07
QA system - Question Generation04-06
ParseTree操作若干-Tregex and Stanford CoreNLP03-24
NLP 笔记 - 平滑方法(Smoothing)小结03-24
NLP 笔记 - 再谈词向量03-21
NLP笔记 - Information ExtractionNLP Category论文笔记 - LightRNN - Memory and Computation-Efficient Recurrent Neural Networks03-14
论文笔记 - Wide and Deep Learning for Recommender Systems03-13
NLP 笔记 - Dependency Parsing and Treebank03-09
NLP 笔记 - Question Answering System03-02
NLP 笔记 - Constituency Parsing02-28
NLP 笔记 - Syntax Introduction02-27
NLP 笔记 - Language models and smoothing02-24
推荐系统--隐语义模型LFM02-17
推荐系统--基于邻域(neighborhood-based)的协同过滤算法02-10
推荐系统--用户行为和实验设计02-08
NLP CategoryCMU 11642 Search Engines - 大纲梳理02-06
NLP 笔记 - Spelling, Edit Distance, and Noisy Channels02-02
NLP 笔记 - Words, morphology, and lexicons02-01
推荐系统--开坑01-23
Search Engines笔记 - Federated Search12-07
Search Engines笔记 - Diversity12-07
论文笔记 - ReDDE Algorithm for Resource Selection11-29
Search Engines笔记 - Personalization11-07
Search Engines笔记 - Search logs11-04
Search Engines笔记 - Document Structure11-04
NLP CategorySearch Engines笔记 - Authority Metrics11-04
Search Engines笔记 - Learning to Rank10-25
Search Engines笔记 - Cache10-15
Search Engines笔记 - Index Construction10-14
Search Engines笔记 - Pseudo Relevance Feedback10-10
Search Engines笔记 - Information Needs10-02
Search Engines笔记 - Best-Match09-30
Search Engines笔记 - Document Representations09-25
Search Engines笔记 - Evaluating Search Effectiveness09-20
Search Engines笔记 - Query Processing09-11
NLP CategorySearch Engines笔记 - Exact-match retrieval09-06
聊天机器人和智能客服(笔记)08-20
实习总结之 sentence embedding08-05
Tf-idf 总结笔记07-10
爬虫总结--汇总贴06-27
论文笔记 - Distributed representations of sentences and documents06-22
词向量总结笔记(简洁版)06-21
爬虫总结(五)-- 其他技巧06-20
爬虫总结(四)-- 分布式爬虫06-17
爬虫总结(三)-- cloud scrapyNLP Category爬虫总结(二)-- scrapy06-12
爬虫总结(一)-- 爬虫基础 & python实现06-11
gensim-doc2vec实战06-01
gensim - word2vec实战05-30
word2vec详解之六 -- 若干源码细节05-29
word2vec详解之五 -- 基于 Negative Sampling 的模型05-29
word2vec详解之四 -- 基于Hierarchical Softmax 的模型05-29
word2vec详解之三 -- 背景知识05-29
word2vec详解之二 -- 预备知识05-29
word2vec详解之一 -- 目录和前言05-28
NLP Category短句归一化--LSI模型05-25
LDA 以及 Gensim 实现05-18
Gensim-用Python做主题模型05-18
JGibbLDA实战05-16
python-jieba-分词----官方文档截取04-01
|















人工智能头条(公开课笔记)+AI科技大本营——一拨微信公众号文章的更多相关文章
- 【AI科技大本营】
从AutoML.机器学习新算法.底层计算.对抗性攻击.模型应用与底层理解,到开源数据集.Tensorflow和TPU,Google Brain 负责人Jeff Dean发长文来总结他们2017年所做的 ...
- 斯坦福ML公开课笔记15—隐含语义索引、神秘值分解、独立成分分析
斯坦福ML公开课笔记15 我们在上一篇笔记中讲到了PCA(主成分分析). PCA是一种直接的降维方法.通过求解特征值与特征向量,并选取特征值较大的一些特征向量来达到降维的效果. 本文继续PCA的话题, ...
- Coursera公开课笔记: 斯坦福大学机器学习第六课“逻辑回归(Logistic Regression)” 清晰讲解logistic-good!!!!!!
原文:http://52opencourse.com/125/coursera%E5%85%AC%E5%BC%80%E8%AF%BE%E7%AC%94%E8%AE%B0-%E6%96%AF%E5%9D ...
- 微信公众号开发笔记(C#)
这篇文章还不错,使用 .net , 对微信用户的想公众号发送的文字进行回复.比较简单,自己可以修改更复杂的回复. 微信公众号开发笔记(C#) 原文地址 需求分析 根据用户在微信上发送至价值中国公众号 ...
- 微信公众号开发笔记1(nodejs开发的)
本篇记录了微信公众号开发的一些笔记 一.微信服务器与我们服务器的交流 微信开发者拥有自己的服务器,在我们服务器上可以与微信服务器进行交流.既然可以交流,那就必定需要前提条件(微信认证),也就是说,只有 ...
- Node.js+Koa开发微信公众号个人笔记(一)准备工作
本人也是在学习过程中,所以文章只作为学习笔记,如果能帮到你,那就更好啦~当然也难免会有错误,请不吝指出~ 一.准备工作 1.本人学习教程:慕课网Scott老师的<Node.js七天搞定微信公众号 ...
- 笔记:《机器学习训练秘籍》——吴恩达deeplearningai微信公众号推送文章
说明 该文为笔者在微信公众号:吴恩达deeplearningai 所推送<机器学习训练秘籍>系列文章的学习笔记,公众号二维码如下,1到15课课程链接点这里 该系列文章主要是吴恩达先生在机器 ...
- 微信公众号开发笔记1(nodejs开发)
本篇记录了微信公众号开发的一些笔记 一.微信服务器与我们服务器的交流 微信开发者拥有自己的服务器,在我们服务器上可以与微信服务器进行交流.既然可以交流,那就必定需要前提条件(微信认证),也就是说,只有 ...
- Andrew Ng机器学习公开课笔记 – Factor Analysis
网易公开课,第13,14课 notes,9 本质上因子分析是一种降维算法 参考,http://www.douban.com/note/225942377/,浅谈主成分分析和因子分析 把大量的原始变量, ...
随机推荐
- sqlserver deadlock
当时系统测试的时候,由于使用了自动化测试跑脚本,一下子出了很多sqlserver deadlock的问题. 都处于system test阶段了,哪儿还有时间仔细分析这些死锁是怎么出来的,直接上retr ...
- vue 使用watch监听实现类似百度搜索功能
watch监听方法,watch可以监听多个变量,具体使用方法看代码: HTML: <!doctype html> <html lang="en"> < ...
- 01 学习数据分析的python库
网页爬取 1.requests 2.BeautifulSoup 3.Scrapy 科学计算与数据分析 1.scipy 2.numpy 3.pandas 机器学习和深度学习 1.Scikit-learn ...
- Paper | Fast image processing with fully-convolutional networks
目录 故事 方法 实验 发表在2017年ICCV. 核心任务:加速图像处理算子(accelerate image processing operators). 核心方法:将算子处理前.后的图像,训练一 ...
- JAVA 运行springboot jar包设置classpath
Java 命令行提供了如何扩展bootStrap 级别class的简单方法. -Xbootclasspath: 完全取代基本核心的Java class 搜索路径.不常用,否则要重新写所有Java 核心 ...
- python接口自动化3-发送post及其他请求
前言 发过get请求相信学习post请求也很快学会,无非就是多了传参时的类型与参数格式.在我常见的post请求中用到最多的是json格式,但也有用其它,下面将介绍常用的参数类型格式. 一.Post请求 ...
- pycharm报错:ImportError: libcusolver.so.8.0: cannot open shared object file: No such file or directory
pycharm报错:ImportError: libcusolver.so.8.0: cannot open shared object file: No such file or directory ...
- NRF24L01双向无线通信
最近闲来无事,利用手头资源研究了一下基于nrf24L01的双向通信实验,整个系统如下图所示. 原理: nrf24L01本身是一种单向通信的无线模块,但是,当nrf24L01工作在增强型的 ShockB ...
- Java生鲜电商平台-提现模块的设计与架构
Java生鲜电商平台-提现模块的设计与架构 补充说明:生鲜电商平台-提现模块的设计与架构,提现功能指的卖家把在平台挣的钱提现到自己的支付宝或者银行卡的一个过程. 功能相对而言不算复杂,有以下几个功能需 ...
- Android探索之百度地图开发
目录 前言 地图图层介绍 地图覆盖物介绍 地图事件 POI检索 公交线路查询 线路规划 地理编码 @ 前言 之前自己在做一个小项目时涉及到了百度地图的一些内容,当时因为对百度地图的开发流程不是很了解, ...