pycharm初爬虫
今天尝试使用pycharm+beautifulsoup进行爬虫测试。我理解的主要分成了自己写的HTML和百度上的网页两种吧。第一种,读自己写的网页(直接上代码):
(主要参考博客:https://blog.csdn.net/Ka_Ka314/article/details/80999803)
from bs4 import BeautifulSoup
file = open('aa.html', 'rb')
html = file.read()
bs = BeautifulSoup(html,"html.parser")
# 缩进格式
print(bs.prettify())
# 获取title标签的所有内容
print(bs.title)
# 获取title标签的名称
print(bs.title.name)
# 获取title标签的文本内容
print(bs.title.string)
# 获取head标签的所有内容
print(bs.head)
# 获取第一个div标签中的所有内容
print(bs.div)
# 获取第一个div标签的id的值
print(bs.div["id"])
# 获取第一个a标签中的所有内容
print(bs.a)
# 获取所有的a标签中的所有内容
print(bs.find_all("a"))
# 获取id="u1"
print(bs.find(id="u1"))
# 获取所有的a标签,并遍历打印a标签中的href的值
for item in bs.find_all("a"):
print(item.get("href"))
# 获取所有的a标签,并遍历打印a标签的文本值
for item in bs.find_all("a"):
print(item.get_text())
HTML代码:
<!DOCTYPE html>
<!--STATUS OK-->
<html>
<head>
<meta content="text/html;charset=utf-8" http-equiv="content-type"/>
<meta content="IE=Edge" http-equiv="X-UA-Compatible"/>
<meta content="always" name="referrer"/>
<link href="https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css" rel="stylesheet" type="text/css"/>
<title>
百度一下,你就知道
</title>
</head>
<body link="#0000cc">
<div id="wrapper">
<div id="head">
<div class="head_wrapper">
<div id="u1">
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">
新闻
</a>
<a class="mnav" href="https://www.hao123.com" name="tj_trhao123">
hao123
</a>
<a class="mnav" href="http://map.baidu.com" name="tj_trmap">
地图
</a>
<a class="mnav" href="http://v.baidu.com" name="tj_trvideo">
视频
</a>
<a class="mnav" href="http://tieba.baidu.com" name="tj_trtieba">
贴吧
</a>
<a class="bri" href="//www.baidu.com/more/" name="tj_briicon" style="display: block;">
更多产品
</a>
</div>
</div>
</div>
</div>
</body>
</html>
项目目录:

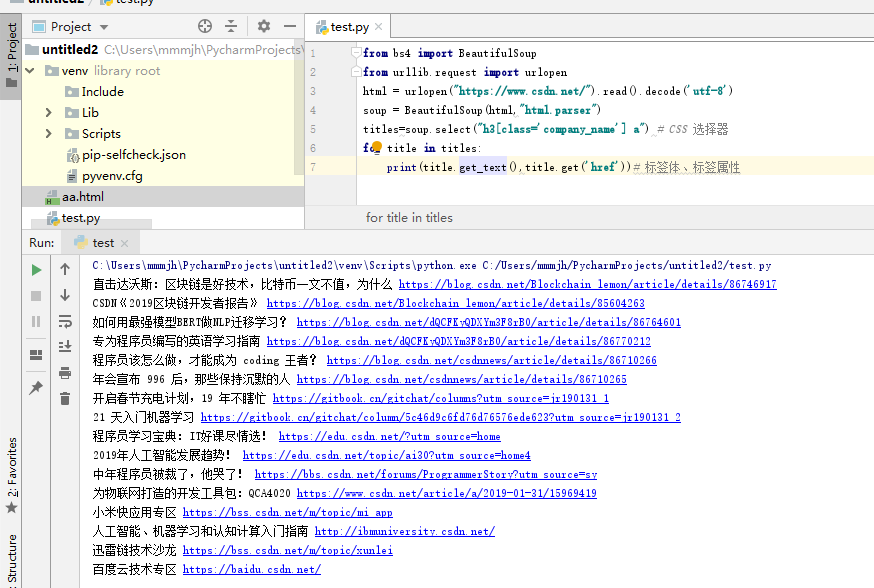
第二种是爬取在线网页内容,使用URL解析,这里我使用时出现了问题,就是URLopen。因为没有找到python27和python36区别,所以这里直接上结果(我用的python36),下载urllib.request的包。网上个别教程直接使用urllib,这里我把urllib3、5进行了下载,会报一个错误,显示连接网页超时。下下载这个urllib没问题
pycharm初爬虫的更多相关文章
- 解决pycharm的爬虫乱码问题(初步了解各种编码格式)
Ascii码(American Standard Code for Information Interchange,美国信息互换标准代码):最初计算机只在美国使用时,只用8位的字节来组合出256(2的 ...
- Python开发之---PyCharm初体验
PyCharm 的初始设置(知道) 目标 恢复 PyCharm 的初始设置 第一次启动 PyCharm 新建一个 Python 项目 设置 PyCharm 的字体显示 PyCharm 的升级以及其他 ...
- 【Django】用pycharm初学习使用Django
开发框架流程 M V C(99%的开发都是这种流程.) 1.URL控制器 2.Views 视图 3.models 库 1.首先创建一个Django 2.创建成功后里面几个模块的功能 用它来 ...
- 爬虫系列----scrapy爬取网页初始
一 基本流程 创建工程,工程名称为(cmd):firstblood: scrapy startproject firstblood 进入工程目录中(cmd):cd :./firstblood 创建爬虫 ...
- scrapy框架修改单个爬虫的配置,包括下载延时,下载超时设置
在一个框架里面有多个爬虫时,每个爬虫的需求不相同,例如,延时的时间,所以可以在这里配置一下custom_settings = {},大括号里面写需要修改的配置,然后就能把settings里面的配置给覆 ...
- Python Scrapy爬虫速成指南
序 本文主要内容:以最短的时间写一个最简单的爬虫,可以抓取论坛的帖子标题和帖子内容. 本文受众:没写过爬虫的萌新. 入门 0.准备工作 需要准备的东西: Python.scrapy.一个IDE或者随便 ...
- python爬虫出现ProxyError: HTTPSConnectionPool错误
在今天刚刚打开pycharm运行爬虫时,发现所有的爬虫都不能运行,会出现如下的错误: 错误出现的主要原因是;代理错误(其实自己根本没有设置代理) 解决方法: 在网上查阅了许多类似的错误解决方法,试过后 ...
- python爬虫1
1 网页结构 html:超文本标记语言------->类似人的鼻子耳朵,长在那里,大体骨架就是那个样子 css:层叠样式表------->这个是外观的深化,比如贴个双眼皮,橙色眼睛... ...
- 附: Python爬虫 数据库保存数据
原文 1.笔记 #-*- codeing = utf-8 -*- #@Time : 2020/7/15 22:49 #@Author : HUGBOY #@File : hello_sqlite3.p ...
随机推荐
- goroutine使用
Goroutine是建立在线程之上的轻量级的抽象.它允许我们以非常低的代价在同一个地址空间中并行地执行多个函数或者方法.相比于线程,它的创建和销毁的代价要小很多,并且它的调度是独立于线程的.在gola ...
- Vue indent eslint缩进webstorm冲突解决
参考教程 官方回复 ESlint设置 rules: { 'no-multiple-empty-lines': [1, {max: 3}], // 控制允许的最多的空行数量 'vue/script-in ...
- [LOJ 2133][UOJ 131][BZOJ 4199][NOI 2015]品酒大会
[LOJ 2133][UOJ 131][BZOJ 4199][NOI 2015]品酒大会 题意 给定一个长度为 \(n\) 的字符串 \(s\), 对于所有 \(r\in[1,n]\) 求出 \(s\ ...
- linux 用du查看硬盘信息
linux 用du查看硬盘信息 <pre>[root@iZ238qupob7Z web]# df -hFilesystem Size Used Avail Use% Mounted on/ ...
- 线程池之ScheduledThreadPoolExecutor线程池源码分析笔记
1.ScheduledThreadPoolExecutor 整体结构剖析. 1.1类图介绍 根据上面类图图可以看到Executor其实是一个工具类,里面提供了好多静态方法,根据用户选择返回不同的线程池 ...
- RSyslog Windows Agent 安装配置
下载地址:https://www.rsyslog.com/windows-agent/windows-agent-download/ 安装过程: 1.双击rsyslogwa安装包,开始进行安装 2.一 ...
- 使用Charles进行HTTPS抓包及常见问题
在渗透过程中,需要对每一个参数,每一个接口,每一个业务逻辑构建测试用例,为此,抓包分析是必不可少的一个过程.在PC端,Burpsuite成为了渗透必备的神器,然而,使用Burpsuite有时候抓取不到 ...
- vue入门案例
1.技术在迭代,有时候你为了生活没有办法,必须掌握一些新的技术,可能你不会或者没有时间造轮子,那么就先把利用轮子吧. <!DOCTYPE html> <html> <he ...
- SQL Server中INSERT EXEC语句不能嵌套使用(转载)
问: I have three stored procedures Sp1, Sp2 and Sp3.The first one (Sp1) will execute the second one ( ...
- Lambda(一)lambda表达式初体验
Lambda(一)lambda表达式初体验 Lambda引入 : 随着需求的不断改变,代码也需要随之变化 需求一:有一个农场主要从一堆苹果中挑选出绿色的苹果 解决方案:常规做法,source code ...