论文阅读笔记六十五:Enhanced Deep Residual Networks for Single Image Super-Resolution(CVPR2017)

论文原址:https://arxiv.org/abs/1707.02921
代码: https://github.com/LimBee/NTIRE2017
摘要
以DNN进行超分辨的研究比较流行,其中,残差学习较大的提高了性能。本文提出了增强的深度超分辨网络(EDST)其性能超过了当前超分辨最好的模型。本文模型性能的大幅度提升主要是移除卷积网络中不重要的模块进行优化得到的。本文模型可以在固定训练步骤的同时,进一步扩大模型的尺寸来提升模型性能。本文同时提出了一个多尺寸超分辨系统(MDSR)及训练方法,该模型可以根据不同的放大稀疏构建高分辨率的图片。
介绍
单图像超分辨方法(SISR)主要是将低分辨率的单张图片 重构为高分辨率的图像
重构为高分辨率的图像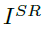 ,一般,低分辨率的图片,与原始的高分辨率图像
,一般,低分辨率的图片,与原始的高分辨率图像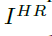 二者之间具有较强的条件限制。许多研究假定为的二三次采样得到的结果。在实际生活中,也可以考虑其他降级因素,比如,模糊,抽取或者噪声等等。
二者之间具有较强的条件限制。许多研究假定为的二三次采样得到的结果。在实际生活中,也可以考虑其他降级因素,比如,模糊,抽取或者噪声等等。
最近,深度网络改进超分辨中信噪比的峰值(PSNR)该值越大越好,参考https://www.jiqizhixin.com/articles/2017-11-06-8 ,然而,这些模型存在一些结构限制,首先,网络模型重建性能对结构的微小变化较为敏感,即相同的模型,通过不同的初始化及训练方法可以得到不同层次的性能。因此,在训练网络时,需要精心设计结构及较为固定的优化方法。
其次,大多数现存的超分辨算法将不同的缩放尺寸看作是独立的问题,并未考虑利用超分辨不同尺寸之间的联系。因此,这些模型针对不同的缩放尺寸需要确定固定的尺寸,然后进行单独的训练。VDSR模型可以在单一网络中处理多尺寸的超分辨问题。通过对多尺寸的VDSR模型进行训练,超过了固定尺寸的训练,表明固定尺寸模型中存在的冗余。但是,VDSR的结构需要对图像进行二三倍插值然后作为模型的输入,因此,需要大量的计算及内存消耗。
虽然,SRResNet解决了计算及内存问题,该模型简单的应用了ResNet,并做了有限的改动。但原始的ResNet是用于处理较高层次的问题,比如目标分类及检测等,因此,直接将ResNet应用到超分辨这种低层次的问题,该模型可能陷入局部最优。
为了解决上述问题,本文在SRResNet的基础上进行优化改进,首先分析并移除其中没有必要的模块来简化网络的结构。网络越负载,其训练越棘手。
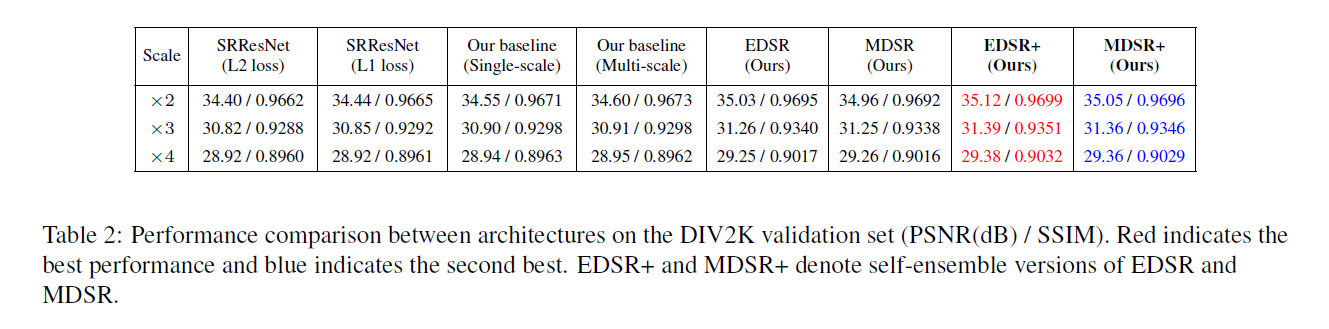
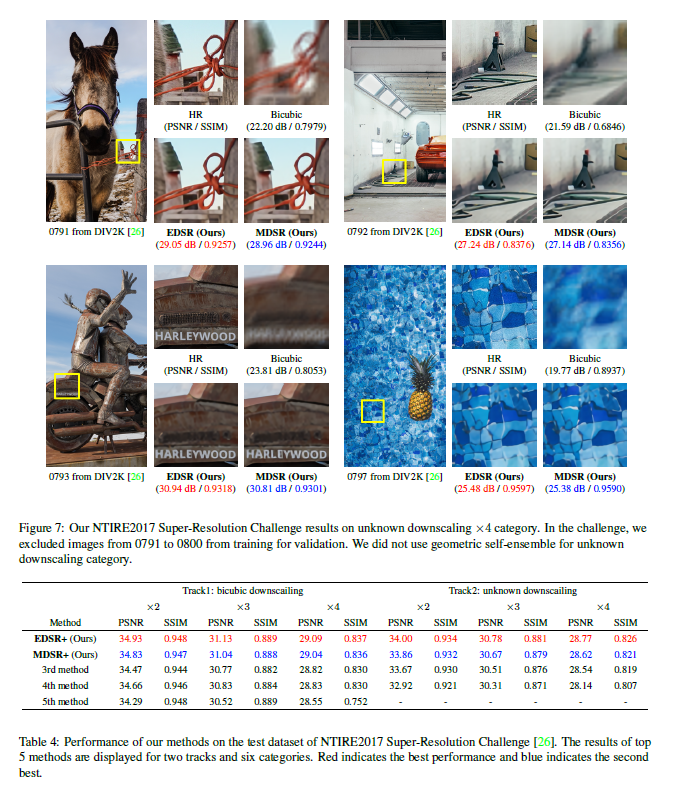
第二,本文研究了模型的训练方法,将在另一个尺寸训练好的模型进行知识迁移。为了利用训练过程中与尺寸无关的信息,在预训练的较低尺寸的模型中训练一个较大尺寸的网络模型。另外,本文提出了一个新的多尺寸模型结构,共享不同尺寸之间的大多数参数。这种多尺寸模型相比多个单一尺寸模型计算量上减少很多,但性能却差不多。本文在DIV2K数据集上进行实验,其PSNR及SSIM性能表现都比较优异。
相关工作
早期基于简单的插值理论来解决超分辨的问题。但在预测精细,纹理问题时上述方法存在限制,通过分析自然图片的分布来重构最好的更高分辨率图像。
较为高级的工作致力于学习 及
及 之间的映射函数。因此,学习方法依赖于邻域嵌入到空间编码等一系列技术。有研究提出通过聚类patch空间并学习相关的函数。一些方法利用图像自身的相似度来排除其他的databases,同时通过对patches进行几何变换来提高内部字典的容量大小。
之间的映射函数。因此,学习方法依赖于邻域嵌入到空间编码等一系列技术。有研究提出通过聚类patch空间并学习相关的函数。一些方法利用图像自身的相似度来排除其他的databases,同时通过对patches进行几何变换来提高内部字典的容量大小。
最近,深度神经网络大幅度地提升了超分辨的性能。跳跃结构及连续的卷积结构减轻超分辨网络传递Identity 信息的负担,有的方法通过编码-解码及对称的跳跃结构来处理图像恢复问题。跳跃结构可以加速收敛效果。
在许多基于深度学习的超分辨算法当中,输入图像首先要经过一个二三次的上采样插值,然后送入网络中。有的并未将输入图片进行上采样,而是在网络的后面增加一个上采样模型,这样也是可取的。由于输入特征尺寸减少了,因此,在不损失模型能力的基础上可以减少大量的计算量。但这类算法存在一个缺点,无法在一个单一模型中处理多尺寸问题。本文权衡了多尺寸训练及计算效率二者。不仅利用学习到的每个尺寸之间的内在特征联系。同时提出了多尺寸模型可以针对不同的尺寸构建高分辨率的图像。另外,本文提出了多尺寸训练方法,结合了单一及多尺寸模型。
一些有关损失函数的研究为了更好的训练网络。在图像恢复问题中,均方差和L2损失用的较为广泛,而且主要用于评估PSNR。但有的人认为L2损失无法保证RSNR及SSIM达到最优,通过实验L1损失也可以达到相同的性能。
本文方法
本文提出了针对确定尺寸的EDSR及在单一模型中处理不同尺寸高分辨率的MDSR模型。
残差Blocks: 参差网络在计算机视觉问题上表现优异,本文在SRResNet的基础上对ResNet结构进行改进,从而获得更好的性能。本文比较了原始的ResNet,SRResNet及本文方法的结构差异,如下图所示。

本文移除了网络中的BN层,这是因为BN层对特征进行正则化,消除了网络的灵活范围。同时,由于移除了BN层因此,减少了GPU的利用率,在训练时,相比SRResNet减少了大约40%的内存占用。因此,在有限的计算资源的基础上可以构建更大的模型从而获得更好的性能。
单尺寸模型: 改进模型性能最简单的方式是增加参数的数量。在卷积网络中,可以叠加更多的层来增加filter的数量。一般卷积网络结构的深度B(网络的层数),宽度F(特征通道数),内存占用大约为O(BF),参数量为O(BF^2),因此,考虑在有限的计算资源下,增加F可以提高模型的能力。但将F增加到一定层次后,网络的训练会变得不稳定。为了解决这个问题,本文将残差scaling调整为0.1,在每个残差block,每个卷积层后接一个固定的常数层。可以使模型在较多的训练时较为稳定。在测试阶段,可以结合以前的卷积层从而提高了计算效率。
本文的单一尺寸模型与SRResNet相似。但在残差块外并没有ReLU激活函数。最后EDSR模型中,将baseline model设置为B=32,F=256,scale factor 0.1。网络结构如图3所示。

当用于x3,x4倍上采样训练模型时,本文用x2的预训练模型作为初始化。这种初始化方法可以加速训练并提升最终性能,如图4所示。

多尺寸模型: 由上图4观察可知,多尺寸的超分辨任务是内在相互关联的。本文提出多尺寸模型利用其内存在的尺寸相关性,设计了一个baseline 其主分支B即网络层数16的残差blocks,因此,不同尺寸中,大多数参数是共享的。如下图所示
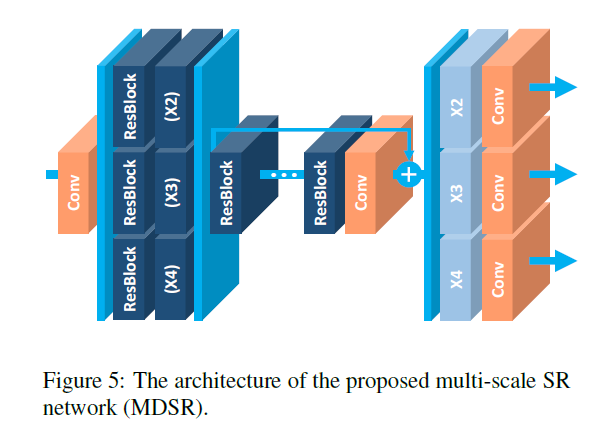
在多尺寸结构中,本文引入了尺寸确定的处理模块,用于处理不同尺寸的超分辨。首先,预处理模块位于网络的开头,用于减少不同输入尺寸图片的差异性。每个预处理模块包含两个残差block,其核大小为5x5。通过选用较大的卷积核,可以保证确定尺寸部分较浅,在网络的前半部分的感受野较大。在网络的最后,不同尺寸对应的上采样模块进行拼接。
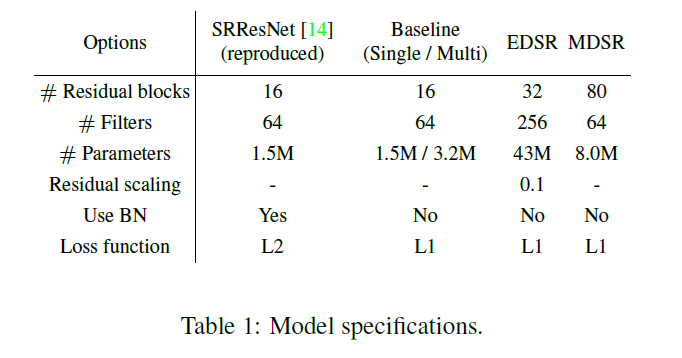
最终WDSR模型的层数为80,通道数64,,每个baseline模型包含1.5M个参数量,总共4.5个。而本文的多尺寸模型只有3.2M的参数量。其性能如下所示。
实验


论文阅读笔记六十五:Enhanced Deep Residual Networks for Single Image Super-Resolution(CVPR2017)的更多相关文章
- 论文阅读笔记三十五:R-FCN:Object Detection via Region-based Fully Convolutional Networks(CVPR2016)
论文源址:https://arxiv.org/abs/1605.06409 开源代码:https://github.com/PureDiors/pytorch_RFCN 摘要 提出了基于区域的全卷积网 ...
- 论文阅读笔记六十二:RePr: Improved Training of Convolutional Filters(CVPR2019)
论文原址:https://arxiv.org/abs/1811.07275 摘要 一个训练好的网络模型由于其模型捕捉的特征中存在大量的重叠,可以在不过多的降低其性能的条件下进行压缩剪枝.一些skip/ ...
- 论文阅读笔记六十:Squeeze-and-Excitation Networks(SENet CVPR2017)
论文原址:https://arxiv.org/abs/1709.01507 github:https://github.com/hujie-frank/SENet 摘要 卷积网络的关键构件是卷积操作, ...
- 论文阅读笔记六:FCN:Fully Convolutional Networks for Semantic Segmentation(CVPR2015)
今天来看一看一个比较经典的语义分割网络,那就是FCN,全称如题,原英文论文网址:https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn ...
- 论文阅读笔记二十五:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPPNet CVPR2014)
论文源址:https://arxiv.org/abs/1406.4729 tensorflow相关代码:https://github.com/peace195/sppnet 摘要 深度卷积网络需要输入 ...
- 论文阅读笔记六十四: Architectures for deep neural network based acoustic models defined over windowed speech waveforms(INTERSPEECH 2015)
论文原址:https://pdfs.semanticscholar.org/eeb7/c037e6685923c76cafc0a14c5e4b00bcf475.pdf 摘要 本文研究了利用深度神经网络 ...
- 论文阅读笔记四十五:Region Proposal by Guided Anchoring(CVPR2019)
论文原址:https://arxiv.org/abs/1901.03278 github:code will be available 摘要 区域anchor是现阶段目标检测方法的重要基石.大多数好的 ...
- 论文阅读笔记六十六:Wide Activation for Efficient and Accurate Image Super-Resolution(CVPR2018)
论文原址:https://arxiv.org/abs/1808.08718 代码:https://github.com/JiahuiYu/wdsr_ntire2018 摘要 本文证明在SISR中在Re ...
- 论文阅读笔记(十五)【CVPR2016】:Top-push Video-based Person Re-identification
Approach 特征由两部分组成:space-time特征和外貌特征.space-time特征由HOG3D[传送门]提取,其包含了空间梯度和时间动态信息:外貌特征采用颜色直方图[传送门]和LBP[传 ...
随机推荐
- DRF--序列化
为什么要用序列化 当我们做前后端分离的项目时,前后端交互一般都是JSON格式的数据,那么我们给前端的数据就要转为JSON格式,就需要我们拿到数据库后的数据进行序列化.在看DRF的序列化之前,先来看看d ...
- 【CF525E】Anya and Cubes(meet in middle)
点此看题面 大致题意: 在\(n\)个数中选任意个数,并使其中至多\(k\)个数\(x_i\)变为\(x_i!\),求使这些数和为\(S\)的方案数. \(meet\ in\ middle\) 这应该 ...
- Node.js和JavaScript的区别与联系
虽然不能说它们一点关系也没有,但它们的确关系不大: 第一,JavaScript是一门编程语言(脚本语言),而Node.js是一个平台,可以简单理解为它是JavaScript的一种执行环境. 第二,Ja ...
- 大话设计模式Python实现-模板方法模式
模板方法模式(Template Method Pattern):定义一个操作中的算法骨架,将一些步骤延迟至子类中.模板方法使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤. 下面是一个模 ...
- tensorflow之tf.to_float
1. tf.to_float() # 将张量转换为float32类型 2. tf.to_int32() # 将张量转换为int32类型 等等, 就是将张量转换成某一种类型.
- [线段树]Luogu P3372 线段树 1【模板】
#include<cstdio> #include<cstring> #include<iostream> #include<algorithm> #d ...
- Kubernetes service 三种类型/NodePort端口固定
Kubernetes service 三种类型 • ClusterIP:默认,分配一个集群内部可以访问的虚拟IP(VIP)• NodePort:在每个Node上分配一个端口作为外部访问入口• Load ...
- IntelliJ IDEA2018激活码
使用前提: 在hosts文件里面添加一行,hosts文件在Windows系统中的路径:C:\Windows\System32\drivers\etc\,Linux系统存放在/etc目录下. 0.0.0 ...
- C 结构体、位域
参考链接:https://www.runoob.com/cprogramming/c-structures.html 结构体是干啥的 例如数组可以用来存储多个相同数据类型的数据项,结构体也是一种数据类 ...
- mask-rcnn的解读(三):batch_slice()
我已用随机生产函数取模拟5张图片各有8个box的坐标值,而后验证batch_slice()函数的意义.由于inputs_slice = [x[i] for x in inputs] output_sl ...