Flink 物理分区
Flink还通过以下函数对转换后的数据精确流分区进行低级控制(如果需要)。
1、自定义分区
使用用户定义的分区程序为每个元素选择目标任务。
dataStream.partitionCustom(partitioner, "someKey")
dataStream.partitionCustom(partitioner, 0)
如简单的hash 分区(下面的实例不是官网):
val input = env.addSource(source)
.map(json => {
// json : {"id" : 0, "createTime" : "2019-08-24 11:13:14.942", "amt" : "9.8"}
val id = json.get("id").asText()
val createTime = json.get("createTime").asText()
val amt = json.get("amt").asText()
LateDataEvent("key", id, createTime, amt)
})
.setParallelism(1)
.partitionCustom(new Partitioner[String] {
override def partition(key: String, numPartitions: Int): Int = {
// numPartitions 是下游算子的并发数
key.hashCode % numPartitions
}
}, "id")
.map(l => {
LateDataEvent(l.key, l.id, l.amt, l.createTime)
})
.setParallelism(3)
注:key 是传入的field 的类型
2、随机分区
根据均匀分布随机分配元素(类似于: random.nextInt(5),0 - 5 在概率上是均匀的)
dataStream.shuffle()
源码:
@Internal
public class ShufflePartitioner<T> extends StreamPartitioner<T> {
private static final long serialVersionUID = 1L; private Random random = new Random(); @Override
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
// 传入下游分区数
return random.nextInt(numberOfChannels);
} @Override
public StreamPartitioner<T> copy() {
return new ShufflePartitioner<T>();
} @Override
public String toString() {
return "SHUFFLE";
}
}
3、均匀分区 rebalance
分区元素循环,每个分区创建相等的负载。在存在数据偏斜时用于性能优化。
dataStream.rebalance()
源码:
public class RebalancePartitioner<T> extends StreamPartitioner<T> {
private static final long serialVersionUID = 1L;
private int nextChannelToSendTo;
@Override
public void setup(int numberOfChannels) {
super.setup(numberOfChannels);
nextChannelToSendTo = ThreadLocalRandom.current().nextInt(numberOfChannels);
}
@Override
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
// 轮训的发往下游分区
nextChannelToSendTo = (nextChannelToSendTo + 1) % numberOfChannels;
return nextChannelToSendTo;
}
public StreamPartitioner<T> copy() {
return this;
}
@Override
public String toString() {
return "REBALANCE";
}
}
4、rescale
分区元素循环到下游操作的子集。如果您希望拥有管道,例如,从源的每个并行实例扇出到多个映射器的子集以分配负载但又不希望发生rebalance()会产生完全重新平衡,那么这非常有用。这将仅需要本地数据传输而不是通过网络传输数据,具体取决于其他配置值,例如TaskManagers的插槽数。
上游操作发送元素的下游操作的子集取决于上游和下游操作的并行度。例如,如果上游操作具有并行性2并且下游操作具有并行性4,则一个上游操作将元素分配给两个下游操作,而另一个上游操作将分配给另外两个下游操作。另一方面,如果下游操作具有并行性2而上游操作具有并行性4,那么两个上游操作将分配到一个下游操作,而另外两个上游操作将分配到其他下游操作。在不同并行度不是彼此的倍数的情况下,一个或多个下游操作将具有来自上游操作的不同数量的输入。
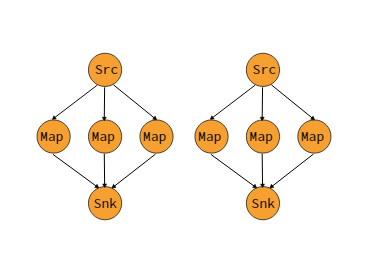
dataStream.rescale()
源码:
public class RescalePartitioner<T> extends StreamPartitioner<T> {
private static final long serialVersionUID = 1L;
private int nextChannelToSendTo = -1;
@Override
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
if (++nextChannelToSendTo >= numberOfChannels) {
nextChannelToSendTo = 0;
}
return nextChannelToSendTo;
}
public StreamPartitioner<T> copy() {
return this;
}
@Override
public String toString() {
return "RESCALE";
}
}
很遗憾这段代码只能看出,上游分区往下游分区发的时候,每个上游分区内部的数据是轮训发到下游分区的(没找到具体分配的地方,从这段代码debug,一直往上,找到分区出现在 RuntimeEnvironment 的对象里面,找不具体分配的地方)。
5、广播
向每个分区广播元素。
dataStream.broadcast()
Flink 物理分区的更多相关文章
- linux下vmware的安装、物理分区使用及卸载
1.安装 先下载安装文件VMware-Workstation-Full-12 在命令行下执行下载的文件安装即可(需要root权限) wget https://download3.vmware.com/ ...
- 扩大缩小Linux物理分区大小
由于产品在不同的标段,设备硬盘也不同, 有些500G,有些320G有些200G,开始在大硬盘上做的配置,想把自己定制好的Linux克隆到小硬盘上,再生龙会纠结空间大小的问题, 因此需要做一些分区的改变 ...
- ubuntu下挂载物理分区到openmediavault4
准备弄个NAS,但还没想好直接买现成,还是自己组装一台,先在虚拟机上体验下OpenMediaVault4和黑群晖.主系统是ubuntu,但刚买的时候这笔记本是装windows的,除了ubuntu的系统 ...
- aliyun添加数据盘后的物理分区和lvm逻辑卷两种挂载方式
一.普通磁盘分区管理方式 1.对磁盘进行分区 列出磁盘 # fdisk -l # fdisk /dev/vdb Welcome to fdisk (util-linux 2.23.2). Change ...
- linux 分区 物理卷 逻辑卷
今天我们主要说说分区.格式化.SWAP.LVM.软件RAID的创建哈~ 格式化 查看当前分区:fdisk -l 这个命令我们以前是讲过的,我现在问下,ID那项是什么意思? 83 是代表EXT2和E ...
- linux磁盘 分区 物理卷 卷组 逻辑卷 文件系统加载点操作案例
转自:truemylife.linux磁盘 分区 物理卷 卷组 逻辑卷 文件系统加载点操作案例 基本概念: 磁盘.分区.物理卷[物理部分] 卷组[中间部分] 逻辑卷.文件系统[虚拟化后可控制部分] 磁 ...
- Flink学习笔记:Operators串烧
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- <译>Flink编程指南
Flink 的流数据 API 编程指南 Flink 的流数据处理程序是常规的程序 ,通过再流数据上,实现了各种转换 (比如 过滤, 更新中间状态, 定义窗口, 聚合).流数据可以来之多种数据源 (比如 ...
- flink学习笔记-split & select(拆分流)
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
随机推荐
- 什么是好的产品——Diet Rams的十大设计原则
博朗(BRAUN)的首席设计师Diet Rams的十大设计原则 第一条,好的产品是有创意的,它必须是一个创新的东西: 第二条,好的产品是有用的,一定要对人有用: 第三条,好的产品是优美的,它必须有美感 ...
- 1-html基本结构与编写规范
<!DOCTYPE html> <html> <!-- #前端开发系统化学习教程, #包括html.css.pc端及移动端布局技巧.javascript. #jquery ...
- HDU - 3555 - Bomb(数位DP)
链接: https://vjudge.net/problem/HDU-3555 题意: The counter-terrorists found a time bomb in the dust. Bu ...
- python中的一切皆对象
python中一切皆对象是这个语言灵活的根本.函数和类也是对象,属于python的一等公民.包括代码包和模块也都是对象.python的面向对象更加彻底. 可以赋值给一个变量可以添加到集合对象中可以作为 ...
- 学习Spring-Data-Jpa(五)---可嵌入对象和元素集合的使用
1.场景一:地址信息(省.市.县.详细地址)在很多实体中都需要,比如说作者有地址,订单也有地址,但是他们的地址并不能独立与他们存在,所以地址不能映射为实体,那么我们就需要在作者实体和订单实体中都添加这 ...
- 基于Python3+Requests的贴吧签到助手
因为总是忘记签到,所以尝试写了一个签到脚本,因为使用的是Python3,所以没法使用Urllib2,于是选择了Requests,事实证明,Requests比Urllib2好用.整体思路比较简单,就是模 ...
- debug错误总结
1, 2,就是一个大括号的问题..让你总是得不了满分..明明和别人的代码差不多. 3,就比如P1914,这种藏坑的题,或者说这一类藏坑的题. 坑是什么呢?就是位数不够往后推的时候.. 你不填坑你就得不 ...
- LOJ P10065 北极通讯网络 题解
每日一题 day39 打卡 Analysis 1.当正向思考受阻时,逆向思维可能有奇效. 2.问题转化为:找到最小的d,使去掉所有权值>d的边之后,连通支的个数<k; 3.定理:如果去掉所 ...
- centos7.3 安装 mysql-5.7.13
系统环境: [root@localhost ~]# cat /etc/RedHat-release CentOS release 6.7 (Final)[root@localhost tools]# ...
- Qt智能指针QPointer, QSharedDataPointer ,QSharedPointer,QWeakPointer和QScopedPointer
QPointer (4.0) 已经过时,可以被QWeakPointer所替代,它不是线程安全的. QSharedDataPointer (4.0) -- 提供对数据的COPY-ON-WRITE以及浅拷 ...