[转帖]商用数据库之死:Oracle 面临困境
https://news.cnblogs.com/n/644400/ 感觉自己眼光太浅了 这些事情 应该有所感觉的 但是一直没有学习了解到.
作者:John Freeman、Fred McClimans 和 Zach Mitchell
我们预计到 2021 年,年产值 296 亿美元的商业数据库市场会收缩 20% 至 30%,认为 Oracle 无法让收入来源足够快地实现转型(从传统的商业数据库转向基于云的订购产品),以抵消这个市场下滑的颓势,这个市场是 Oracle 收入的一大传统核心。
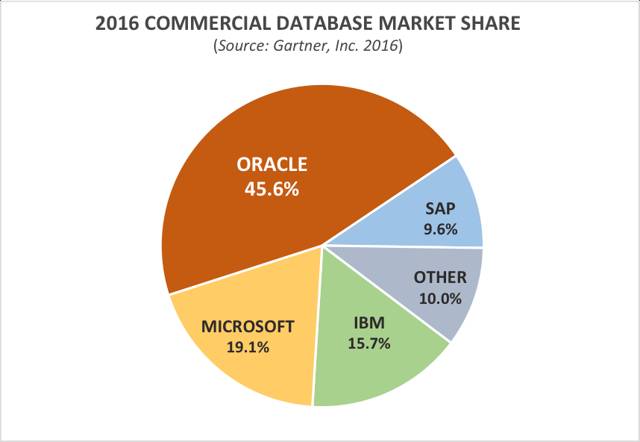
这二十年来,商业数据库市场仍然是 IT 行业最稳定、最具黏性的领域之一,Oracle、IBM 和微软三家厂商瓜分了 80% 的份额。然而,我们认为这个领域衰退的速度和幅度可能会让许多投资者大吃一惊。
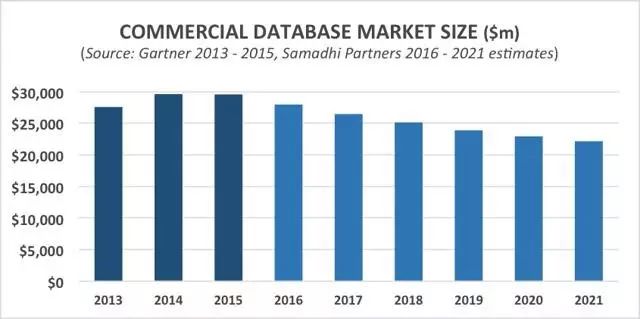
已经影响数据库市场的通货紧缩压力刚刚开始体现,包括:
- 迁移到软件即服务(SaaS),大多数产品使用免费开源数据库;
- 社交媒体、物联网和非结构化/半结构化数据等使用场合迎来更快速的增长,这些使用场合不适合 SQL 标准,而数据库寡头们恰恰有赖于这项标准;
- 众多的免费开放源代码选项日益稳定、功能日益强大,其中大多数选项是“Not Only SQL”(NoSQL),因此极其适合上述使用场合;以及
- 由于摩尔定律带来了处理器、内存、固态存储和网络吞吐量等方面的改进,NoSQL 数据库继续获得异常显著的好处――这些改进提升了同时快速处理 NoSQL 使用场合和 SQL 使用场合的能力,并逐渐使纯 SQL 数据库沦为边缘化,正如纯 SQL 数据库在 80 年代末和 90 年代使基于大型机的数据库沦为边缘化。)
来自数据库软件的收入占 Oracle 2016 财年总收入的约 36%,占其营业利润的约 55%。
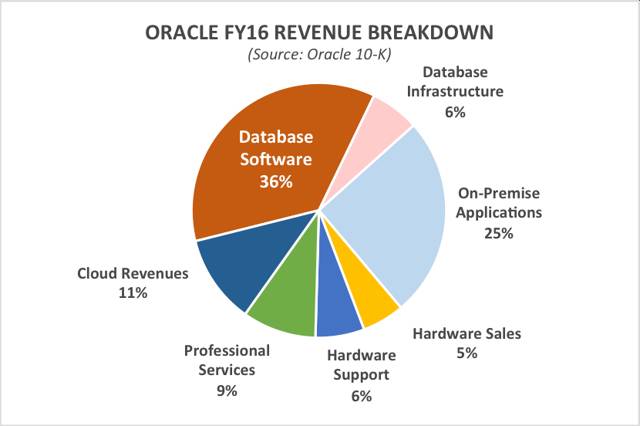
注意:数据库软件和内部部署型应用软件包括许可证收入和维护收入。
该公司预计的数据库收入下降是明摆着的,此外其内部部署型应用软件的收入也在下降,这块收入占 2016 财年总收入的约 25%,占营业利润的约 39%。
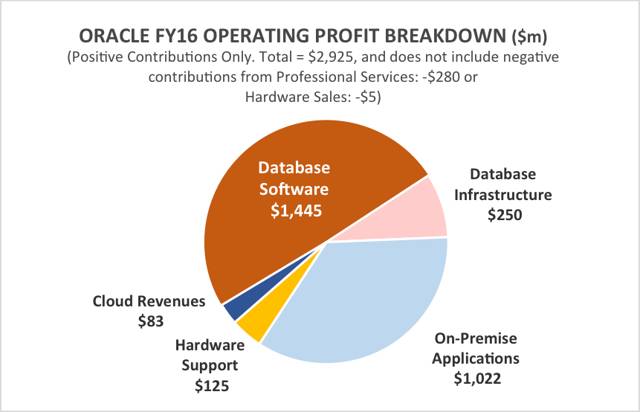
微软和 IBM 将只是略微受到伤害,因为数据库软件只占每家厂商总收入的区区5% 左右。
如果不采取积极的行动来大幅提高非数据库收入,我们认为 Oracle 无法足够快地抵消商业数据库收入即将下降的颓势,以保持其目前的市值。
具体来说,我们认为 Oracle 需要实行更激进、更快速的组织转型和文化转型,变成一家“云优先”的企业,激励销售队伍和客户向云积极迈进。该公司还需要整合各种自家开发和收购而来的云/ SaaS 产品,整合到单个平台,以便将来获得经营杠杆效应。未来几年,这些项目会在几个方面带来痛苦,尤其是财务方面。为了部分抵消痛苦,Oracle 应该剥离剩余的硬件及其他非核心业务。
主题说明
对于那些对技术深究更有兴趣的人来说,下面从历史的角度更深入地解释了五个相互关联的趋势,这些趋势愈演愈烈,将共同导致商业数据库市场到 2021 年收缩 20% 至 30%。
企业继续迁移到 SaaS/云
除了几款建立在 Oracle 数据库基础上的初期 SaaS 产品(即 Salesforce.com、NetSuite 和 Oracle 本身)外,很难找到使用任何商业数据库的 SaaS 提供商。对于 2005 年以后创办的公司而言,这个数字几乎为零。
如今绝大多数的 SaaS 提供商使用开源数据库,或者像 SaaS 人力资本管理(HCM)提供商 Workday 那样,开发自己的数据库。许多用户之前使用内部部署型企业应用软件,包括五个核心客户端/服务器应用软件类别中的一个:ERP(企业资源规划)、CRM(客户关系管理)、HCM(人力资本管理)、SCM(供应链管理)和 BI(商业智能)应用软件,改用 SaaS 模式后,消除了商业数据库席位(seat),因而消除了原本带来的维护/支持收入和未来升级收入。连改用 Salesforce.com 的企业席位给 Oracle 创造的收入也将比当初部署在企业内部环境时少得多。
因此,我们认为企业迁移到 SaaS/云对商业数据库收入而言是非常不利的趋势。此外,我们仍处在从客户端/服务器到 SaaS/云的早期阶段。据不同的研究公司声称,这种迁移只完成了 10% 至 25%,只是刚刚开始影响更重要的关键任务应用软件(比如 ERP),它们更有可能在更高端的 SQL 数据库(包括 Oracle 和 IBM 的那些数据库以及微软的一小部分数据库)上运行。
商业 SQL 数据库不是很适合处理最有吸引力的新兴使用场景
SQL 在 1987 年成为标准后,20 年来它在定义如何组织、搜索和排序数据方面的地位无可撼动。然而,到 2000 年年中,各大科技公司在处理数据的绝对数量和不同结构方面开始遇到了 SQL 数据库存在的限制,它们想按照需要来保留、浏览、分析数据,并将数据提供给用户/客户。
亚马逊、谷歌、LinkedIn 和 Facebook 各自通过开发和实施自己的数据库软件――这种数据库软件打破了 SQL 标准的制约,解决了自己的扩展问题。
此外,不久后每家公司都发布了开源版本的数据库。因此,2008 年和 2009 年它们开发出了众多新的开源数据库,导致了《下一代数据库》的作者盖伊·哈里逊(Guy Harrison)所说的“某种寒武纪大爆炸”现象。由于纷纷远离 SQL,这些数据库都属于“NoSQL”这类数据库――尽管大多数数据库彼此大不相同,就像它们跟 SQL 大不相同那样。
鉴于数据的数量和种类迅猛增长――这归因于更丰富的社交媒体内容、更多的社交媒体用户以及自动获取的物联网数据激剧增多,另外鉴于企业日益渴望分析获取的数据,我们认为,适合 NoSQL 的使用场合其数量很快就会远远超过适合 SQL 的使用场合。
这些新型使用场合的兴起将推动大企业更多地采用开源 NoSQL 解决方案,结果商业 SQL 数据库成了牺牲品。
NoSQL 数据库和读时模式(Schema-on-Read)方法遵循摩尔定律
SQL 数据库和写时模式(Schema-on-Write)未遵循摩尔定律。通常来说,NoSQL 数据库所需的处理器、内存和存储资源比 SQL 数据库密集得多,即使考虑到这一事实:它们放松了 SQL 在数据组织方式方面的许多约束。虽然 NoSQL 数据库架构早在 2005 年就已经存在――至少从理论上来说是这样,但当时根本没有足够的处理能力、内存容量和存储空间,好让它们在学术界之外的领域投入实际应用。
在处理器/内存/带宽资源相对匮乏的 20 世纪 80 年代和 90 年代,遵守更加严格的 SQL 标准实际上是必须的,那样才能确保企业将应用软件从大型机和小型计算机迁移到更加分布式、依赖网络的客户端/服务器架构所需要的那种性能和可靠性,尤其是那些更重要的关键任务应用软件。
获得 SQL 尚可接受的性能和可靠性需要付出代价,这主要是由于:
- 名为模式的数据结构整体上缺乏灵活性;
- 在部署数据库及相关应用程序之前定义该结构带来的繁重要求;
- 随着时间的推移,很难改变该结构,以便获取不同类型的数据,以便更好地体现数据结构和企业组织方面的变化;以及
- 需要写时模式方法,即在输入数据时让数据适合模式,而不是读时模式,只是将数据倒到一只大大的“容器”中,之后将它组织到模式中。
然而,随着时间的推移,摩尔定律促使处理能力、内存容量及速度、存储容量及速度以及网络吞吐量都得到了提升,这使得用户越来越不需要僵硬的 SQL 标准和写时模式方法,这股势头只会延续下去。因此,伴随着每个摩尔定律周期,SQL 及其节省资源的写时模式方法越来越失去竞争优势,而 NoSQL 及其资源相对低效,但极其灵活的读时模式方法变得日益摆脱当初阻碍它得到采用的约束。
内存技术(In-Memory)带来了大好前景,消除了传统硬盘的缺点
SQL 成为标准化时,传统硬盘(HDD)是可以实时访问的唯一具有成本效益的存储介质。因此,写入到 SQL 数据库软件的许多基本代码旨在忍受 HDD 的缺点,比如读取请求的数据并将数据传输到内存中速度很慢,故障率比较高――至少,与系统的主要固态部件(比如 CPU、内存和网络吞吐量)相比是这样。现在由于固态硬盘(SSD)正迅速成为一种具有成本效益的 HDD 替代品,传统 SQL 数据库软件的设计、当然还有大部分代码现在毫无必要了――而当初做出这样的妥协,是为了适应速度慢得多的 HDD。
相比之下,开发的许多 NoSQL 数据库是为了最大限度地利用 SSD 存储介质,这些数据库可能会得到更新,以便充分利用更新颖的非易失性内存技术,比如英特尔/美光联合开发的 3D xPoint,这种内存正在推向市场。我们认为,鉴于继续遵守 SQL 标准、保持自己的向后兼容性方面有着强烈的需求,SQL 数据库厂商无法像许多开源项目那样迅速针对 SSD 优化其代码,这让它们进一步处于竞争劣势――这是克莱顿·克里斯滕森(Clayton Christensen)所说的“创新者的困境”的一个典型例子。
市面上 “SQLMethadone” 解决方案越来越多,让企业可以摆脱昂贵的商业数据库
我们看到越来越多的软件工具和服务旨在帮助企业从商业 SQL 数据库迁移出去。随着时间的推移,连在 Oracle 或 IBM 数据库上运行的最重要的关键任务应用软件也可能日益被包围、“被隔离”、被拆卸,这一幕正如上世纪 90 年代向客户端/服务器架构转型期间许多传统大型机应用软件的遭遇那样。
虽然来自 Oracle、IBM 和微软等巨头的 SQL 数据库会在一些企业存活好多年――再度酷似大型机,但是它们会日益沦为边缘化,并且它们的成本会尽可能被减少。我们看到许多这样的工具已经在 Hadoop 生态系统里面日趋成熟,该生态系统已经有多种方法可以与 SQL 数据库集成起来,及/或将 SQL 接口和查询功能放在 NoSQL 数据库上。在我们看来,这一幕与上世纪 90 年代初出现将大型机应用软件与 PC 和客户端/服务器应用软件集成起来的多种方法何其相似。
[转帖]商用数据库之死:Oracle 面临困境的更多相关文章
- SQL与NoSQL区别--商业SQL数据库衰落--oracle面临困境
转自:商用数据库之死:Oracle 面临困境 这二十年来,商业数据库市场仍然是 IT 行业最稳定.最具黏性的领域之一,Oracle.IBM 和微软三家厂商瓜分了 80% 的份额.然而,我们认为这个领域 ...
- [转帖]如何获得一个Oracle RAC数据库(从Github - oracle/vagrant-boxes) --- 暂时未测试成功 公司网络太差了..
如何获得一个Oracle RAC数据库(从Github - oracle/vagrant-boxes) 2019-11-20 16:40:36 dingdingfish 阅读数 5更多 分类专栏: 如 ...
- [转帖]如何获得一个RAC Oracle数据库(从Github - oracle/docker-images) - 本地版 ---暂时未做实验.
如何获得一个RAC Oracle数据库(从Github - oracle/docker-images) - 本地版 2019-11-09 16:35:30 dingdingfish 阅读数 32更多 ...
- 戏说Linux商用数据库
戏说Linux商用数据库 上一篇文章(http://chenguang.blog.51cto.com/350944/277533)我介绍了Linux下几款开源数据库Mysql,MaxDB.Postgr ...
- .net远程连接oracle数据库不用安装oracle客户端
asp.net远程连接oracle数据库不用安装oracle客户端的方法下面是asp.net连接远程Oracle数据库服务器步骤: 1.asp.net连接oracle服务器需要添加Sytem.Data ...
- .net远程连接oracle数据库不用安装oracle客户端的方法
.net远程连接oracle数据库不用安装oracle客户端的方法步骤: 1.添加Sytem.Data.OracleClient命名空间. 2.连接时需要ConnectionString字符串,出现在 ...
- MSSQL数据库迁移到Oracle
MSSQL数据库迁移到Oracle 最近要把一个MSSQL数据库迁移到Oracle上面,打算借助PowerDesigner这个软件来实现;今天简单研究一下这个软件的运用;把一步简单的操作步骤记录下来: ...
- 在mysql数据库中创建oracle scott用户的四个表及插入初始化数据
在mysql数据库中创建oracle scott用户的四个表及插入初始化数据 /* 功能:创建 scott 数据库中的 dept 表 */ create table dept( deptno int ...
- PowerDesigner15连接Oracle数据库并导出Oracle的表结构
PowerDesigner连接Oracle数据库,根据建立的数据源进行E-R图生成.详细步骤如下: 1.启动PowerDesigner 2.菜单:File->Reverse Engineer - ...
随机推荐
- PHP var_dump() 函数
var_dump() 函数用于输出变量的相关信息 <?php $b = 3.1; $c = true; var_dump($b, $c); ?> 输出 float(3.1) bool(tr ...
- Python中pass语句的作用是什么?
pass语句什么也不做,一般作为占位符或者创建占位程序,pass语句不会执行任何操作.
- mac Understand 安装破解
下载:链接:https://pan.baidu.com/s/1UvxgFnjv9pRVJmZO-J2OrQ 密码:nyd4 启动后,开始激活,点击enter License code 点击“use ...
- CentOS 6.5开放端口方法
lsof -i tcp:80 列出所有端口 netstat -ntlp 1.开启端口(以80端口为例) 方法一: /sbin/iptables -I ...
- 在Typora中使用Latex
https://blog.csdn.net/happyday_d/article/details/83715440 今后可能更多在本地编辑出Markdown之后复制上博客或者上传到GitHub.
- 2018-2019-2 《网络对抗技术》Exp9 WebGoat 20165326
Web安全基础 jar包,密码:9huw 实验问题回答 SQL注入攻击原理,如何防御 原理:恶意用户在提交查询请求的过程中将SQL语句插入到请求内容中,同时程序本身对未对插入的SQL语句进行过滤,导致 ...
- 生产者消费者模型Java实现
生产者消费者模型 生产者消费者模型可以描述为: ①生产者持续生产,直到仓库放满产品,则停止生产进入等待状态:仓库不满后继续生产: ②消费者持续消费,直到仓库空,则停止消费进入等待状态:仓库不空后,继续 ...
- mui openWindow方法详细说明
mui.openWindow({ url: 'xxx.html', //String类型,要打开的界面的地址 id: 'id', //String类型,要打开的界面的id styles: { //We ...
- Python2和Python3共存问题
前提条件:先准备一个新电脑 1.下载Python2和Python3的安装包,直接官网下载:https://www.python.org/download 2.配置环境变量,可以手动配置,也可以安装的时 ...
- JSON HiJacking攻击
JSON劫持类似于CSRF攻击,为了了解这种攻击方式,我们先看一下Web开发中一种常用的跨域获取数据的方式:JSONP. 先说一下JSON吧,JSON是一种数据格式,主要由字典(键值对)和列表两种存在 ...