012-MySQL 索引添加以及优化说明
一、索引概述
数据库的索引可以加快查询速度,原因是索引使用特定的数据结构(B-Tree)对特定的列额外组织存放,加快存储引擎(索引是存储引擎实现)查找记录的速度。
如果查询语句使用索引(通常是where条件匹配索引)就会利用树的结构加快查找,索引会按值查找到要查找的行在表中位置,不需回表查询数据的就是聚簇索引(索引和数据存放在一起)。通常是需要回表再查数据,需要消耗额外的磁盘IO。所以有些时候(如按顺序读取数据)全表扫描会比使用索引快的原因就在于此。
查询条件只有一个字段时,在该字段建立索引即可,可优化的地方是对于text blob字段使用前缀索引。
当查询条件有多个字段时,单列索引和多列索引有很大的区别。如果使用多列索引,where条件中字段的顺序非常重要,需要满足最左前缀列。最左前缀:查询条件中的所有字段需要从左边起按顺序出现在多列索引中,查询条件的字段数要小于等于多列索引的字段数,中间字段不能存在范围查询的字段(<,like等),这样的sql可以使用该多列索引。
1.1、索引类型
mysql索引类型normal,unique,full text
normal:表示普通索引【大部分使用这个】
unique:表示唯一的,不允许重复的索引,如果该字段信息保证不会重复例如身份证号用作索引时,可设置为unique
full textl: 表示 全文搜索的索引。 FULLTEXT 用于搜索很长一篇文章的时候,效果最好。用在比较短的文本,如果就一两行字的,普通的 INDEX 也可以。FULLTEXT索引仅可用于 MyISAM 表
总结,索引的类别由建立索引的字段内容特性来决定,通常normal最常见。
1.2、索引方法:B-Tree,Hash,R-Tree
1.2.1、B-Tree【一般时候使用这个】
B-Tree是最常见的索引类型,所有值(被索引的列)都是排过序的,每个叶节点到跟节点距离相等。所以B-Tree适合用来查找某一范围内的数据,而且可以直接支持数据排序(ORDER BY)
B-Tree在MyISAM里的形式和Innodb稍有不同:
MyISAM表数据文件和索引文件是分离的,索引文件仅保存数据记录的磁盘地址
InnoDB表数据文件本身就是主索引,叶节点data域保存了完整的数据记录
1.2.2、Hash索引
1.仅支持"=","IN"和"<=>"精确查询,不能使用范围查询:
由于Hash索引比较的是进行Hash运算之后的Hash值,所以它只能用于等值的过滤,不能用于基于范围的过滤,因为经过相应的Hash算法处理之后的Hash
2.不支持排序:
由于Hash索引中存放的是经过Hash计算之后的Hash值,而且Hash值的大小关系并不一定和Hash运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算
3.在任何时候都不能避免表扫描:
由于Hash索引比较的是进行Hash运算之后的Hash值,所以即使取满足某个Hash键值的数据的记录条数,也无法从Hash索引中直接完成查询,还是要通过访问表中的实际数据进行相应的比较,并得到相应的结果
4.检索效率高,索引的检索可以一次定位,不像B-Tree索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以Hash索引的查询效率要远高于B-Tree索引
5.只有Memory引擎支持显式的Hash索引,但是它的Hash是nonunique的,冲突太多时也会影响查找性能。Memory引擎默认的索引类型即是Hash索引,虽然它也支持B-Tree索引
1.2.3、R-Tree索引
R-Tree在MySQL很少使用,仅支持geometry数据类型,支持该类型的存储引擎只有MyISAM、BDb、InnoDb、NDb、Archive几种。
二、索引操作
1.1.1、增加索引
1.PRIMARY KEY(主键索引)
mysql>ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )
2.UNIQUE(唯一索引)
mysql>ALTER TABLE `table_name` ADD UNIQUE (`column` )
3.INDEX(普通索引)
mysql>ALTER TABLE `table_name` ADD INDEX index_name ( `column` )
4.FULLTEXT(全文索引)
mysql>ALTER TABLE `table_name` ADD FULLTEXT ( `column` )
5.多列索引
mysql>ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )
1.1.2、删除索引
alter table table_name drop index emp_name;
1.1.3、重建索引
mysql> REPAIR TABLE table_name QUICK;
1.1.4、查看某个数据表的索引
mysql> SHOW INDEX FROM tbl_name;
1.1.5、注意事项
1、创建报错:Specified key was too long; max key length is 767 bytes简单解决办法
数据库表采用utf8编码,其中varchar(255)的column进行了唯一键索引
而mysql默认情况下单个列的索引不能超过767位(不同版本可能存在差异)
方案:如果数据内容允许,直接修改数据类型:table_name 表里的column_name 字段 原来长度是 150个字符,现长度要改成64个字符
alter table table_name modify column column_name varchar(64) COMMENT '注释' ;
1.2、列索引、多列索引
列索引就是单列创建一个索引。多列索引是多列创建一个索引。
1.2.1、多列索引适合的场景
1.全字段匹配
2.匹配部分最左前缀
3.匹配第一列
4.匹配第一列范围查询(可用用like a%,但不能使用like %b)
5.精确匹配某一列和和范围匹配另外一列
order by操作中出现的字段同样适用于按值查找的规则,where+order by中出现的字段需可以建立满足如上五种规则多列索引。使用多列所需需要按照最左索引列查找;不能跳过中间列;如果某一列是范围查询,那么其右边所有列无法使用索引。
IN什么情况下是范围查询,什么情况下是多个等值查询?如果有order by排序时,多个等于条件查询就是范围查询,没有order by排序就没有限制。
例如,建立多列索引(name, age, id),只能使用索引的前两列。in是范围查询
... where name='nginx.cn' and age in(15,16,17) order by id
可以使用整个索引,in是按值查询
... where name='nginx.cn' and age in(15,16,17) and id ='3'
1.2.2、复合索引的建立以及最左前缀原则
索引字符串值的前缀(prefixe)。如果你需要索引一个字符串数据列,那么最好在任何适当的情况下都应该指定前缀长度。
例如,如果有CHAR(200)数据列,如果前面10个或20个字符都不同,就不要索引整个数据列。索引前面10个或20个字符会节省大量的空间。你可以索引CHAR、VARCHAR、BINARY、VARBINARY、BLOB和TEXT数据列的前缀。
假设你在表的state、city和zip数据列上建立了复合索引。索引中的数据行按照state/city/zip次序排列,因此它们也会自动地按照state/city和state次序排列。这意味着,即使你在查询中只指定了state值,或者指定state和city值,MySQL也可以使用这个索引。因此,这个索引可以被用于搜索如下所示的数据列组合:
state, city, zip
state, city
state
MySQL不能利用这个索引来搜索没有包含在最左前缀的内容。例如,如果你按照city或zip来搜索,就不会使用到这个索引。如果你搜索给定的state和具体的ZIP代码(索引的1和3列),该索引也是不能用于这种组合值的,尽管MySQL可以利用索引来查找匹配的state从而缩小搜索的范围。
如果你考虑给已经索引过的表添加索引,那么就要考虑你将增加的索引是否是已有的多列索引的最左前缀。如果是这样的,不用增加索引,因为已经有了(例如,如果你在state、city和zip上建立了索引,那么没有必要再增加state的索引)。
二、实例
有大数据量的查询,基本查询太耗时,此时需要优化sql,索引是优化查询sql的一个点。
2.1、建表插入数据
参看009-MySQL循环while、repeat、loop使用、 010-MySQL批量插入测试数据
更具上述文章创建表结构,插入100W条数据。
drop table if exists `test_table_idx`;
create table `test_table_idx`(
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`uid` varchar(64) DEFAULT NULL COMMENT '字符主键',
`name` varchar(64) DEFAULT NULL COMMENT '名称',
`age` int(11) DEFAULT NULL COMMENT '年龄',
`type` varchar(64) DEFAULT NULL COMMENT '类型',
`ext_info` text COMMENT '扩展信息',
`created_datetime` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`updated_datetime` datetime DEFAULT null COMMENT '更新时间',
`desc` varchar(300) DEFAULT NULL COMMENT '描述',
primary key (`id`)
) ENGINE=InnoDB charset=utf8 collate=utf8_bin;
说明:年龄 0-100;type 几类:0-20 少年 21-30 青年 31-50 中年 51-70 老年;
如果有测试的可以清除表数据:TRUNCATE table test_table_idx;
delimiter // #定义标识符为双斜杠
DROP PROCEDURE IF EXISTS my_procedure ; #如果存在 my_procedure 存储过程则删除
CREATE PROCEDURE my_procedure () #创建无参存储过程
BEGIN
DECLARE n INT DEFAULT 1 ; # 申明变量
set @execSql='insert into test_table_idx (uid,name,age,type,ext_info,`desc`) values';
set @execdata = ''; WHILE n <= 1000001 DO
set @age=FLOOR(RAND() * 100);
# 类型
set @type='';
if @age<20 THEN
set @type='少年';
elseif @age<30 THEN
set @type='青年';
elseif @age<50 THEN
set @type='中年';
elseif @age<70 THEN
set @type='老年';
ELSE
set @type=concat('高龄',@age);
end if; set @execdata=concat(@execdata,"(",n,",","'name",n,"',",@age,",'",@type,"',","NULL",",'desc'",")"); if n%1000=0
then
set @execSql = concat(@execSql,@execdata,";");
-- select @execSql;
prepare stmt from @execSql;
execute stmt;
DEALLOCATE prepare stmt;
commit; set @execSql='insert into test_table_idx (uid,name,age,type,ext_info,`desc`) values';
set @execdata = '';
ELSE
set @execdata = concat(@execdata,',');
end if; SET n = n + 1 ; #循环一次,i加一
END WHILE ; #结束while循环
#select count(*) from test_table_idx;
END
//
delimiter ;
call my_procedure(); #调用存储过程
DROP PROCEDURE IF EXISTS my_procedure ; #如果存在 my_procedure 存储过程则删除
执行结果:call my_procedure() OK, Time: 33.94sec 靠谱
2.2、可以 根据 业务创建查询sql
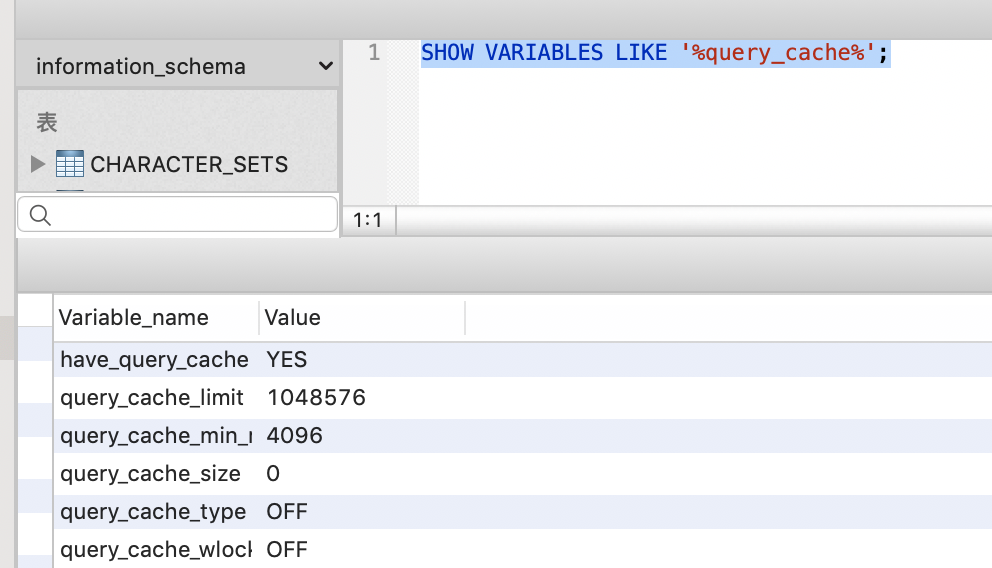
记得参看下【需在调试过程中临时关闭缓存】 :011-MySQL Query Cache 查询缓存设置操作
SHOW VARIABLES LIKE '%query_cache%'; 发现已关闭,无需额外处理
查看索引
-- 查看索引
show index from test_table_idx
可以看到只有主键索引
1、主键查询
使用主键查询数据
Select SQL_NO_CACHE * from test_table_idx where id=1000988
可以看到查询耗时<=10ms
查看执行计划
explain Select SQL_NO_CACHE * from test_table_idx where id=1000988
输出:参看:004-mysql explain详解

2、使用type 以及uid查询
方式一、【无索引,全表扫描】
查询两个记录一个靠前一个靠后,
Select SQL_NO_CACHE * from test_table_idx where type='中年' and uid=''
Select SQL_NO_CACHE * from test_table_idx where type='中年' and uid=''
查询时间为:小于等于580ms
查看执行计划
explain Select SQL_NO_CACHE * from test_table_idx where type='中年' and uid='';
explain Select SQL_NO_CACHE * from test_table_idx where type='中年' and uid='';
输出

查看执行计划一致。type=all 全表扫描数据文件,rows =998185 执行计划中估算的扫描行数,不是精确值
方式二、【创建两个单列索引】
ALTER TABLE `test_table_idx` ADD INDEX idx_type (`type`);
ALTER TABLE `test_table_idx` ADD INDEX idx_uid (`uid`);
-- 查看索引
show index from test_table_idx
输出:

执行查询
Select SQL_NO_CACHE * from test_table_idx where type='中年' and uid=''
Select SQL_NO_CACHE * from test_table_idx where type='中年' and uid=''
可以看到查询耗时:小于10ms
查看执行计划

解读:type=ref 多列索引,prossile_keys 查询 查询可能使用到的索引都会在这里列出来;key 查询真正用到的索引,rows 扫描行数
方式三、【多列索引】
-- 删除 单列索引
alter table test_table_idx drop index idx_type;
alter table test_table_idx drop index idx_uid;
-- 查看索引
show index from test_table_idx ;
-- 创建 多列索引
ALTER TABLE `test_table_idx` ADD INDEX idx_type_uid (`type`,`uid`);
-- 查看索引
show index from test_table_idx ;
explain Select SQL_NO_CACHE * from test_table_idx where type='中年' and uid='';
查看建立的多列索引

通单列索引一致,只是名称不一致,以及seq_in_index标记1 和 2 意思是idx_type_uid 索引同时使用 type和uid两个字段,但是 uid不能单独使用,一般是1 的 能单独使用
输出执行计划:

解读:type=ref 使用了索引,prossile_keys 查询 查询可能使用到的索引都会在这里列出来;key 查询真正用到的索引,rows 扫描行数 1
情况一、增加字段,或调整顺序针对上述可以,调整顺序以及增加搜索条件 ,【使用索引】
explain Select SQL_NO_CACHE * from test_table_idx where age=37 and type='中年' and uid='';
explain Select SQL_NO_CACHE * from test_table_idx where type='中年' and age=37 and uid='';
explain Select SQL_NO_CACHE * from test_table_idx where type='中年' and uid='' and age=37;
explain Select SQL_NO_CACHE * from test_table_idx where uid='' and type='中年';
通过查看执行计划发现与上述一致,故结果以及时间也会一致
情况二、缺少索引字段【如果使用第一个字段索引会起作用,只是用后面的即seq_in_index>1的不会命中索引】
explain Select SQL_NO_CACHE * from test_table_idx where type='中年';
explain Select SQL_NO_CACHE * from test_table_idx where age=37 and type='中年';
英文在索引字段 idx_type_uid 中 type的seq_in_index 是1 所以索引 idx_type_uid能被 type 以及包含type的使用

如果只是用 第二个字段uid 或者更多字段 但是不包括 type
explain Select SQL_NO_CACHE * from test_table_idx where uid='';
结果发现,不会执行任何索引 ,原因是 idx_type_uid索引的 uid的 seq_in_index 是2 不能单独被执行,必须有1 的存在才会被执行到

情况三、尝试更换创建索引顺序,会与上述描述一致
alter table test_table_idx drop index idx_type_uid;
ALTER TABLE `test_table_idx` ADD INDEX idx_uid_type (`uid`,`type`);
通过查看,发现执行计划和上述一致。使用也一致。
方式四、多列索引,单列索引同时存在
ALTER TABLE `test_table_idx` ADD INDEX idx_type (`type`);
ALTER TABLE `test_table_idx` ADD INDEX idx_uid (`uid`);
-- 查看索引
show index from test_table_idx
进行方式三中的尝试,前提是

情况一、会明总 idx_type_uid 索引
情况二、只有type字段条件:命中了idx_type_uid 索引,不会命中 idx_type索引
只有uid字段条件:idx_uid
三、索引创建结论
3.1、基础结论
1、依据实际使用的大部分sql来创建
2、获取慢sql来创建索引
3、索引会增大存储空间、以及降低写入更新速递
4、多列建索引比对每个列分别建索引更有优势,因为索引建立得越多就越占磁盘空间,在更新数据的时候速度会更慢。
5、建立多列索引时,顺序也是需要注意的,应该将严格的索引放在前面,这样筛选的力度会更大,效率更高。
3.1、索引原理
011-数据结构-树形结构-B+树[mysql应用]、B*树
012-MySQL 索引添加以及优化说明的更多相关文章
- MySQL索引分析与优化
1.MySQL能够在name的索引中查找“Mike”值,然后直接转到数据文件中相应的行,准确地返回该行的 peopleid(999).在这个过程中,MySQL只需处理一个行就可以返回结果.如果没有“n ...
- MySQL索引原理及优化
一.各种数据结构介绍 这一小节结合哈希表.完全平衡二叉树.B树以及B+树的优缺点来介绍为什么选择B+树. 假如有这么一张表(表名:sanguo): (1)Hash索引 对name字段建立哈希索引: 根 ...
- MySQL索引类型及优化
索引是快速搜索的关键.MySQL索引的建立对于MySQL的高效运行是很重要的.下面介绍几种常见的MySQL索引类型. 在数据库表中,对字段建立索引可以大大提高查询速度.假如我们创建了一个 mytabl ...
- mysql索引原理及优化(一)
什么是索引 索引用来快速地寻找那些具有特定值的记录,所有MySQL索引都以B-tree的形式保存.如果没有索引,执行查询时MySQL必须从第一个记录开始扫描整个表的所有记录,直至找到符合要求的记录.表 ...
- Mysql 索引原理及优化
本文内容主要来源于互联网上主流文章,只是按照个人理解稍作整合,后面附有参考链接. 一.摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引 ...
- MySQL索引类型,优化,使用数据结构
工欲善其事必先利其器 半藏说道:“若你在路途中遇到上帝,上帝也会被割伤.” 一.mysql 索引分类(默认使用B树结构)在数据库表中,对字段建立索引可以大大提高查询速度.通过善用这些索引,可以令 My ...
- (转)Mysql 索引原理及优化
本文内容主要来源于互联网上主流文章,只是按照个人理解稍作整合,后面附有参考链接. 一.摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引 ...
- mysql索引原理以及优化
一.常见查找算法: 1.顺序查找: 最基础的查找方法,对比每一个元素进行查找.在数据量很大的时候效率相当的慢. 数据结构:有序或者无需的队列 时间复杂度:O(n) 2.二分查找: 二分查找首先要求数组 ...
- MySQL索引使用以及优化
优化后台业主评价服务人员运行缓慢. 案发现场:后台业主评价服务人员列表页以及搜索页运行缓慢.运行时间为24074ms. 排查过程: 1.代码开头加时间,结束加时间.看运行了多少秒. 2.给评价 ...
随机推荐
- 【使用DIV+CSS重写网站首页案例】CSS盒子模型
CSS盒子模型 取值问题: 默认情况,padding.border.margin都为0: 设定区域内容的width和height,是区域内容框的尺寸: 如果设定padding/border/margi ...
- Django如何与JQuery进行数据通信?
index.html: 下面form的action属性表示当提交表单时,向何处发送表单数据 <script src="https://code.jquery.com/jquery-3. ...
- php抽象工厂模式(Abstract factory pattern)
练代码 <?php interface Button { public function render(); } interface GUIFactory { public function c ...
- 王天悦 201671030121 实验十四 团队项目评审&课程学习总结
项目 内容 课程名称 2016级计算机科学与工程学院软件工程(西北师范大学) 作业要求 实验十四 团队项目评审&课程学习总结 课程学习目标 (1)掌握软件项目评审会流程,(2)反思总结课程学习 ...
- php解析xml的几种方式
php提供几种解析xml的类或方法,包括:Xml parser. SimpleXML,.XMLReader,.DOMDocument. XML Expat Parser: XML Parser使用Ex ...
- RemoveError: 'setuptools' is a dependency of conda and cannot be removed from conda's operating environment.
今天用conda install 任何包都会出现这个错误: RemoveError: 'setuptools' is a dependency of conda and cannot be remov ...
- 网络I/O
贴几个超级不错的博客 1.Linux IO模式及 select.poll.epoll详解 2.网络 I/O 模型 3.同步异步阻塞非阻塞 4.三种模式的区别与联系
- leetcode 数据库练习 - 1205 每月交易I和II
每月交易(一) Table: Transactions +---------------+---------+| Column Name | Type |+---------------+------ ...
- Entity Framework Core Query Types
This feature was added in EF Core 2.1 Query types are non-entity types (classes) that form part of t ...
- three.js 加载3DS 404 文件找不到
web.config修改如下: code: <?xml version="1.0" encoding="utf-8"?> <!-- 有关如何配 ...