有助于改善性能的Java代码技巧
前言
程序的性能受到代码质量的直接影响。这次主要介绍一些代码编写的小技巧和惯例。虽然看起来有些是微不足道的编程技巧,却可能为系统性能带来成倍的提升,因此还是值得关注的。
慎用异常
在Java开发中,经常使用try-catch进行错误捕获,但是try-catch语句对系统性能而言是非常糟糕的。虽然一次try-catch中,无法察觉到她对性能带来的损失,但是一旦try-catch语句被应用于循环或是遍历体内,就会给系统性能带来极大的伤害。
以下是一段将try-catch应用于循环体内的示例代码:
@Test
public void test11() { long start = System.currentTimeMillis();
int a = 0;
for(int i=0;i<1000000000;i++){
try {
a++;
}catch (Exception e){
e.printStackTrace();
}
}
long useTime = System.currentTimeMillis()-start;
System.out.println("useTime:"+useTime); }
上面这段代码运行结果是:
useTime:10
下面是一段将try-catch移到循环体外的代码,那么性能就提升了将近一半。如下:
@Test
public void test(){
long start = System.currentTimeMillis();
int a = 0;
try {
for (int i=0;i<1000000000;i++){
a++;
}
}catch (Exception e){
e.printStackTrace();
}
long useTime = System.currentTimeMillis()-start;
System.out.println(useTime);
}
运行结果:
useTime:6
使用局部变量
调用方法时传递的参数以及在调用中创建的临时变量都保存在栈(Stack)中,速度快。其他变量,如静态变量、实例变量等,都在堆(Heap)中创建,速度较慢。
下面是一段使用局部变量进行计算的代码:
@Test
public void test11() { long start = System.currentTimeMillis();
int a = 0;
for(int i=0;i<1000000000;i++){
a++;
}
long useTime = System.currentTimeMillis()-start;
System.out.println("useTime:"+useTime); }
运行结果:
useTime:5
将局部变量替换为类的静态变量:
static int aa = 0;
@Test
public void test(){
long start = System.currentTimeMillis(); for (int i=0;i<1000000000;i++){
aa++;
}
long useTime = System.currentTimeMillis()-start;
System.out.println("useTime:"+useTime);
}
运行结果:
useTime:94
通过上面两次的运行结果,可以看出来局部变量的访问速度远远高于类成员变量。
位运算代替乘除法
在所有的运算中,位运算是最为高效的。因此,可以尝试使用位运算代替部分算术运算,来提高系统的运行速度。最典型的就是对于整数的乘除运算优化。
下面是一段使用算术运算的代码:
@Test
public void test11() { long start = System.currentTimeMillis();
int a = 0;
for(int i=0;i<1000000000;i++){
a*=2;
a/=2;
}
long useTime = System.currentTimeMillis()-start;
System.out.println("useTime:"+useTime);
}
运行结果:
useTime:1451
将循环体中的乘除运算改为等价的位运算,代码如下:
@Test
public void test(){
long start = System.currentTimeMillis();
int aa = 0;
for (int i=0;i<1000000000;i++){
aa<<=1;
aa>>=1;
}
long useTime = System.currentTimeMillis()-start;
System.out.println("useTime:"+useTime);
}
运行结果:
useTime:10
上两段代码执行了完全相同的功能,在每次循环中,都将整数乘以2,并除以2。但是运行结果耗时相差非常大,所以位运算的效率还是显而易见的。
提取表达式
在软件开发过程中,程序员很容易有意无意地让代码做一些“重复劳动”,在大部分情况下,由于计算机的高速运行,这些“重复劳动”并不会对性能构成太大的威胁,但若希望将系统性能发挥到极致,提取这些“重复劳动”相当有意义。
比如以下代码中进行了两次算术计算:
@Test
public void testExpression(){
long start = System.currentTimeMillis();
double d = Math.random();
double a = Math.random();
double b = Math.random();
double e = Math.random(); double x,y;
for(int i=0;i<10000000;i++){
x = d*a*b/3*4*a;
y = e*a*b/3*4*a;
}
long useTime = System.currentTimeMillis()-start;
System.out.println("useTime:"+useTime); }
运行结果:
useTime:21
仔细看能发现,两个计算表达式的后半部分完全相同,这也意味着在每次循环中,相同部分的表达式被重新计算了。
那么改进一下后就变成了下面的样子:
@Test
public void testExpression99(){
long start = System.currentTimeMillis();
double d = Math.random();
double a = Math.random();
double b = Math.random();
double e = Math.random(); double p,x,y;
for(int i=0;i<10000000;i++){
p = a*b/3*4*a;
x = d*p;
y = e*p;
}
long useTime = System.currentTimeMillis()-start;
System.out.println("useTime:"+useTime);
}
运行结果:
useTime:11
通过运行结果我们可以看出来具体的优化效果。
同理,如果在某循环中需要执行一个耗时操作,而在循环体内,其执行结果总是唯一的,也应该提取到循环体外。
例如下面的代码:
for(int i=0;i<100000;i++){
x[i] = Math.PI*Math.sin(y)*i;
}
应该改进成下面的代码:
//提取复杂,固定结果的业务逻辑处理到循环体外
double p = Math.PI*Math.sin(y);
for(int i=0;i<100000;i++){
x[i] = p*i;
}
使用arrayCopy()
数组复制是一项使用频率很高的功能,JDK中提供了一个高效的API来实现它。
/**
* @param src the source array.
* @param srcPos starting position in the source array.
* @param dest the destination array.
* @param destPos starting position in the destination data.
* @param length the number of array elements to be copied.
* @exception IndexOutOfBoundsException if copying would cause
* access of data outside array bounds.
* @exception ArrayStoreException if an element in the <code>src</code>
* array could not be stored into the <code>dest</code> array
* because of a type mismatch.
* @exception NullPointerException if either <code>src</code> or
* <code>dest</code> is <code>null</code>.
*/
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);
如果在应用程序中需要进行数组复制,应该使用这个函数,而不是自己实现。
下面来举例:
@Test
public void testArrayCopy(){
int size = 100000;
int[] array = new int[size];
int[] arraydest = new int[size]; for(int i=0;i<array.length;i++){
array[i] = i;
}
long start = System.currentTimeMillis();
for (int k=0;k<1000;k++){
//进行复制
System.arraycopy(array,0,arraydest,0,size);
}
long useTime = System.currentTimeMillis()-start;
System.out.println("useTime:"+useTime);
}
运行结果:
useTime:59
相对应地,如果在程序中,自己实现数组复制,其等价代码如下:
@Test
public void testArrayCopy99(){
int size = 100000;
int[] array = new int[size];
int[] arraydest = new int[size]; for(int i=0;i<array.length;i++){
array[i] = i;
}
long start = System.currentTimeMillis();
for (int k=0;k<1000;k++){
for(int i=0;i<size;i++){
arraydest[i] = array[i];
}
}
long useTime = System.currentTimeMillis()-start;
System.out.println("useTime:"+useTime);
}
运行结果:
useTime:102
通过运行结果可以看出效果。
因为System.arraycopy()函数是native函数,通常native函数的性能要优于普通函数。仅出于性能考虑,在程序开发时,应尽可能调用native函数。
使用Buffer进行I/O操作
除NIO外,使用Java进行I/O操作有两种基本方式;
1、使用基于InpuStream和OutputStream的方式;
2、使用Writer和Reader;
无论使用哪种方式进行文件I/O,如果能合理地使用缓冲,就能有效地提高I/O的性能。
InputStream、OutputStream、Writer和Reader配套使用的缓冲组件。
如下图:
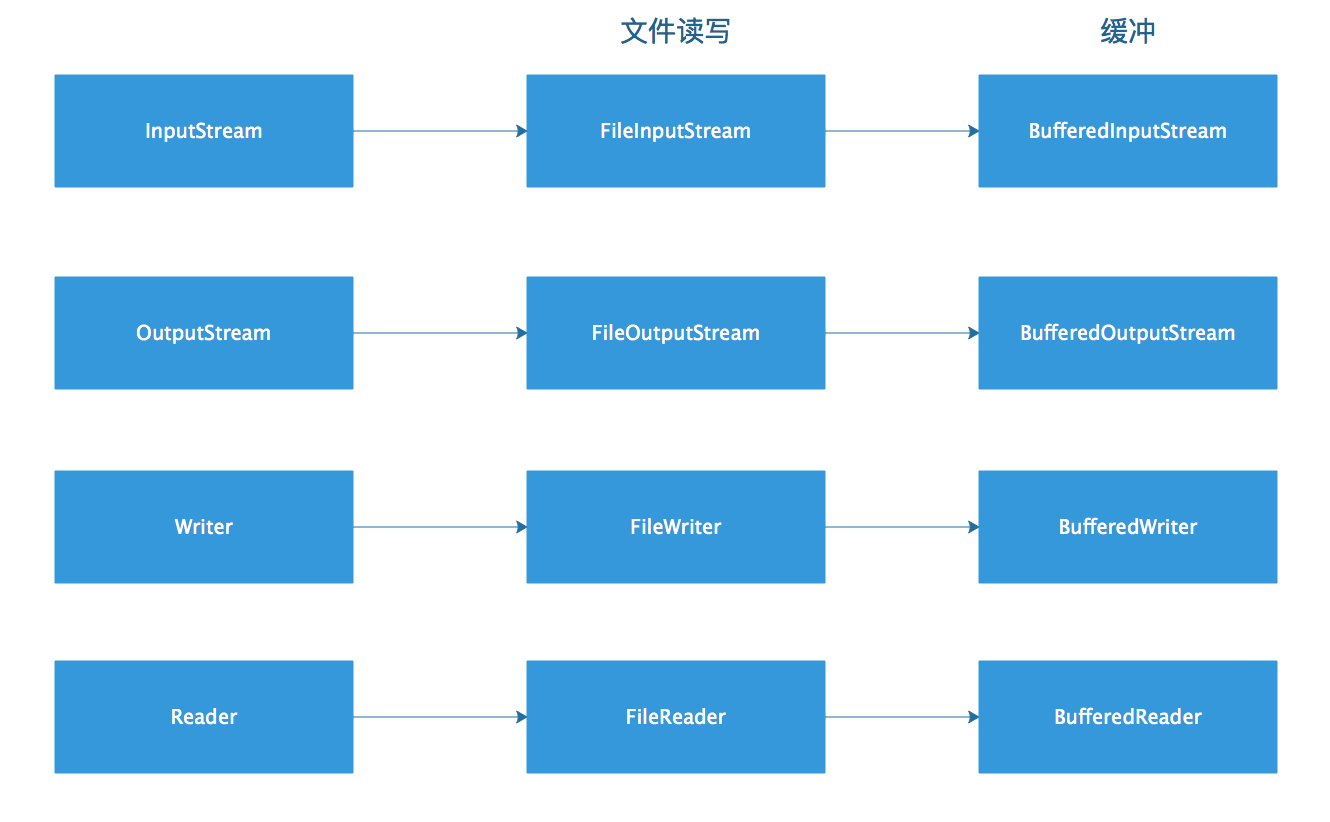
使用缓冲组件对文件I/O进行包装,可以有效提升文件I/O的性能。
下面是一个直接使用InputStream和OutputStream进行文件读写的代码:
@Test
public void testOutAndInputStream(){ try {
DataOutputStream dataOutputStream = new DataOutputStream(new FileOutputStream("/IdeaProjects/client2/src/test/java/com/client2/cnblogtest/teststream.txt"));
long start = System.currentTimeMillis();
for(int i=0;i<10000;i++){
dataOutputStream.writeBytes(Objects.toString(i)+"\r\n");
}
dataOutputStream.close();
long useTime = System.currentTimeMillis()-start;
System.out.println("写入数据--useTime:"+useTime);
//开始读取数据
long startInput = System.currentTimeMillis();
DataInputStream dataInputStream = new DataInputStream(new FileInputStream("/IdeaProjects/client2/src/test/java/com/client2/cnblogtest/teststream.txt")); while (dataInputStream.readLine() != null){
}
dataInputStream.close();
long useTimeInput = System.currentTimeMillis()-startInput;
System.out.println("读取数据--useTimeInput:"+useTimeInput);
}catch (Exception e){
e.printStackTrace();
} }
运行结果:
写入数据--useTime:660
读取数据--useTimeInput:274
使用缓冲的代码如下:
@Test
public void testBufferedStream(){ try {
DataOutputStream dataOutputStream = new DataOutputStream(
new BufferedOutputStream(new FileOutputStream("/IdeaProjects/client2/src/test/java/com/client2/cnblogtest/teststream.txt")));
long start = System.currentTimeMillis();
for(int i=0;i<10000;i++){
dataOutputStream.writeBytes(Objects.toString(i)+"\r\n");
}
dataOutputStream.close();
long useTime = System.currentTimeMillis()-start;
System.out.println("写入数据--useTime:"+useTime);
//开始读取数据
long startInput = System.currentTimeMillis();
DataInputStream dataInputStream = new DataInputStream(
new BufferedInputStream(new FileInputStream("/IdeaProjects/client2/src/test/java/com/client2/cnblogtest/teststream.txt"))); while (dataInputStream.readLine() != null){
}
dataInputStream.close();
long useTimeInput = System.currentTimeMillis()-startInput;
System.out.println("读取数据--useTimeInput:"+useTimeInput);
}catch (Exception e){
e.printStackTrace();
} }
运行结果:
写入数据--useTime:22
读取数据--useTimeInput:12
通过运行结果,我们能很明显的看出来使用缓冲的代码,无论在读取还是写入文件上,性能都有了数量级的提升。
使用Wirter和Reader也有类似的效果。
如下代码:
@Test
public void testWriterAndReader(){ try {
long start = System.currentTimeMillis();
FileWriter fileWriter = new FileWriter("/IdeaProjects/client2/src/test/java/com/client2/cnblogtest/teststream.txt");
for (int i=0;i<100000;i++){
fileWriter.write(Objects.toString(i)+"\r\n");
}
fileWriter.close();
long useTime = System.currentTimeMillis()-start;
System.out.println("写入数据--useTime:"+useTime);
//开始读取数据
long startReader = System.currentTimeMillis();
FileReader fileReader = new FileReader("/IdeaProjects/client2/src/test/java/com/client2/cnblogtest/teststream.txt");
while (fileReader.read() != -1){
}
fileReader.close();
long useTimeInput = System.currentTimeMillis()-startReader;
System.out.println("读取数据--useTimeInput:"+useTimeInput);
}catch (Exception e){
e.printStackTrace();
} }
运行结果:
写入数据--useTime:221
读取数据--useTimeInput:147
对应的使用缓冲的代码:
@Test
public void testBufferedWriterAndReader(){ try {
long start = System.currentTimeMillis();
BufferedWriter fileWriter = new BufferedWriter(
new FileWriter("/IdeaProjects/client2/src/test/java/com/client2/cnblogtest/teststream.txt"));
for (int i=0;i<100000;i++){
fileWriter.write(Objects.toString(i)+"\r\n");
}
fileWriter.close();
long useTime = System.currentTimeMillis()-start;
System.out.println("写入数据--useTime:"+useTime);
//开始读取数据
long startReader = System.currentTimeMillis();
BufferedReader fileReader = new BufferedReader(
new FileReader("/IdeaProjects/client2/src/test/java/com/client2/cnblogtest/teststream.txt"));
while (fileReader.read() != -1){
}
fileReader.close();
long useTimeInput = System.currentTimeMillis()-startReader;
System.out.println("读取数据--useTimeInput:"+useTimeInput);
}catch (Exception e){
e.printStackTrace();
} }
运行结果:
写入数据--useTime:157
读取数据--useTimeInput:59
通过运行结果可以看出,使用了缓冲后,无论是FileReader还是FileWriter的性能都有较为明显的提升。
在上面的例子中,由于FileReader和FilerWriter的性能要优于直接使用FileInputStream和FileOutputStream所以循环次数增加了10倍。
后面会持续更新。。。

文章会同步到我的公众号上面,欢迎关注。
有助于改善性能的Java代码技巧的更多相关文章
- Linux中查找最耗性能的JAVA代码
在这里总结一下查找Linux.Java环境下最耗CPU性能的代码段的方法.基本上原理就是使用top命令查看最耗cpu的进程和线程(子进程).使用jstack把java线程堆栈给dump下来.然后,在堆 ...
- Mongodb 笔记 - 性能及Java代码
性能 以下数据都是在千兆网络下测试的结果 写入 数据量的增大会导致内存占满, 因为mongodb会将数据尽可能地载入内存, 索引占用的空间也很可观非安全模式下, 速度取决于内存是否占满能差一个数量级, ...
- Java 性能优化手册 — 提高 Java 代码性能的各种技巧
转载: Java 性能优化手册 - 提高 Java 代码性能的各种技巧 Java 6,7,8 中的 String.intern - 字符串池 这篇文章将要讨论 Java 6 中是如何实现 String ...
- 写出优质Java代码的4个技巧(转)
http://geek.csdn.net/news/detail/238243 原文:4 More Techniques for Writing Better Java 作者:Justin Alban ...
- Java 性能调优小技巧
1.在知道必要之前不要优化系统 这可能是最重要的性能调整技巧之一.你应该遵循常见的最佳实践做法并尝试高效地实现用例.但是,这并不意味着在你证明必要之前,你应该更换任何标准库或构建复杂的优化. 在大多数 ...
- Java 性能优化的五大技巧
要对你的 Java 代码进行优化,需要理解 Java 不同要素之间的相互作用,以及它是如何与其运行时的操作系统进行交互的.使用下面这五个技巧和资源,开始学习如何分析和优化你的代码吧. 在我们开始之前, ...
- 代码优化:Java编码技巧之高效代码50例
出处: Java编码技巧之高效代码50例 1.常量&变量 1.1.直接赋值常量值,禁止声明新对象 直接赋值常量值,只是创建了一个对象引用,而这个对象引用指向常量值. 反例: Long i = ...
- 改善Azure App Service托管应用程序性能的几个技巧
本文介绍了几个技巧,这些技巧可以改善Azure App Service托管应用程序的性能.其中一些技巧是你现在就可以进行的配置变更, 而其他技巧则可能需要对应用程序进行一些重新设计和重构. 开发者都希 ...
- [大牛翻译系列]Hadoop(15)MapReduce 性能调优:优化MapReduce的用户JAVA代码
6.4.5 优化MapReduce用户JAVA代码 MapReduce执行代码的方式和普通JAVA应用不同.这是由于MapReduce框架为了能够高效地处理海量数据,需要成百万次调用map和reduc ...
随机推荐
- rust-vmm 学习
V0.1.0 feature base knowledge: Architecture of the Kernel-based Virtual Machine (KVM) 用rust-vmm打造未来的 ...
- 【洛谷P5049】旅行(数据加强版)
题目链接 m=n-1是直接按字典序dfs就行, m=n时是一棵基环树,我们发现当一个点在环上时,可以把它和它的一个在环上的儿子之间的边删掉,然后回溯,到达它的第一个有其他儿子的祖先的另一个儿子上,我们 ...
- GoCN每日新闻(2019-10-19)
GoCN每日新闻(2019-10-19) Go 1.13中的错误处理 https://tonybai.com/2019/10/18/errors-handling-in-go-1-13 golang核 ...
- 坑:jmeter部署AWS云服务器时出现连接超时Non HTTP response code: org.apache.http.conn.HttpHostConnectException
背景: jmeter脚本部署到云服务器(AWS EC2)公网上时,启动jmeter脚本运行了5个小时才运行完毕,后面发现脚本报错timeout(如图),找了很久不知道原因,后面进入脚本发现全部在报错. ...
- mysql 字段拼接
mysql> select concat(name,"**",id) as test from test; +----------------+ | test | +---- ...
- python 得到列表的第二大的元素
code #coding=utf- l=[,,,,,,] max1=l[] max2=l[] if(max1>max2): pass else: max1,max2=max2,max1 :]: ...
- 配置nRF52832 的NFC 专用引脚为 GPIO
nRF52832 是支持NFC的,真可惜本码农没用过. NFC的引脚为 P0.09/P0.10,这两个引脚正常情况下是不能直接当做GPIO来用的,要用的时候,需要在编译环境配置一个宏. 下面是Keil ...
- 集合类 collection接口 ArrayList
数组: 存储同一种数据类型的集合容器.数组的特点:1. 只能存储同一种数据类型的数据.2. 一旦初始化,长度固定. 3. 数组中的元素与元素之间的内存地址是连续的. : Object类型的数组可以存储 ...
- docker容器启动后添加端口映射
DOCKER 给运行中的容器添加映射端口 方法1 1.获得容器IP 将container_name 换成实际环境中的容器名 docker inspect `container_name` | grep ...
- Android HIDL学习(2) ---- HelloWorld【转】
本文转载自: 写在前面 程序员有个癖好,无论是学习什么新知识,都喜欢以HelloWorld作为一个简单的例子来开头,咱们也不例外. OK,咱这里都是干货,废话就不多说啦,学习HIDL呢咱们还是需要一些 ...