利用csv文件信息,将图片名信息保存到csv文件当中
我们可以利用train.csv文件信息, 再结合给定的文件路径(path)信息,可以将给定字目录下的图片名信息整合到scv文件当中。
train.csv文件格式:
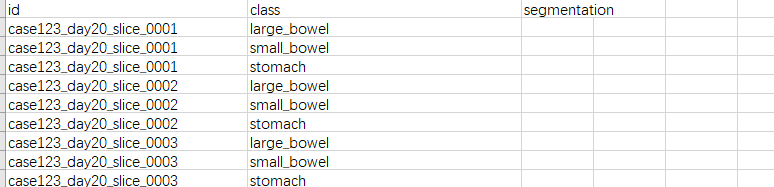
图片名信息:
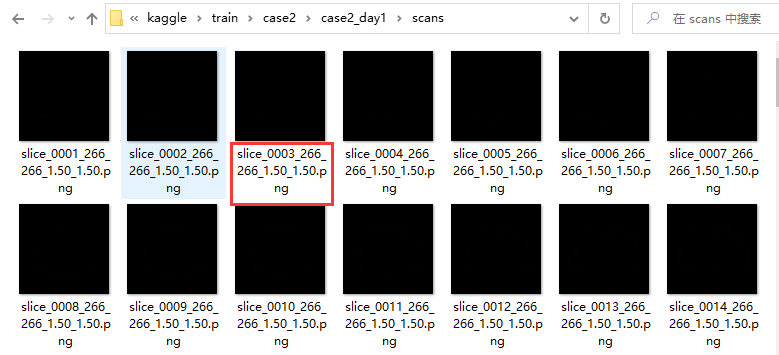
代码如下:
from glob import glob
import pandas as pd
import os def enrich_data(df, sdir="train"):
imgs = glob(os.path.join(DATASET_FOLDER, sdir, "case*", "case*_day*", "scans", "*.png"))
img_folders = [os.path.dirname(p).split(os.path.sep) for p in imgs]
img_names = [os.path.splitext(os.path.basename(p))[0].split("_") for p in imgs]
img_keys = [f"{f[-2]}_slice_{n[1]}" for f, n in zip(img_folders, img_names)] # print(img_keys[:5])
df["img_path"] = df["id"].map({k: p for k, p in zip(img_keys, imgs)})
df["Case_Day"] = df["id"].map({k: f[-2] for k, f in zip(img_keys, img_folders)})
df["Case"] = df["id"].apply(lambda x: int(x.split("_")[0].replace("case", "")))
df["Day"] = df["id"].apply(lambda x: int(x.split("_")[1].replace("day", "")))
df["Slice"] = df["id"].map({k: int(n[1]) for k, n in zip(img_keys, img_names)})
df["width"] = df["id"].map({k: int(n[2]) for k, n in zip(img_keys, img_names)})
df["height"] = df["id"].map({k: int(n[3]) for k, n in zip(img_keys, img_names)})
df["spacing1"] = df["id"].map({k: float(n[4]) for k, n in zip(img_keys, img_names)})
df["spacing2"] = df["id"].map({k: float(n[5]) for k, n in zip(img_keys, img_names)}) if __name__ == "__main__":
# df_ssub = pd.read_csv(os.path.join(DATASET_FOLDER, "sample_submission.csv"))
DATASET_FOLDER = "D:\compation\kaggle"
df_ssub = pd.read_csv(os.path.join(DATASET_FOLDER, "train.csv","traines.csv"))
enrich_data(df_ssub,"traines")
df_ssub.to_csv("df.csv")
print(df_ssub["Case_Day"][4])
结果:
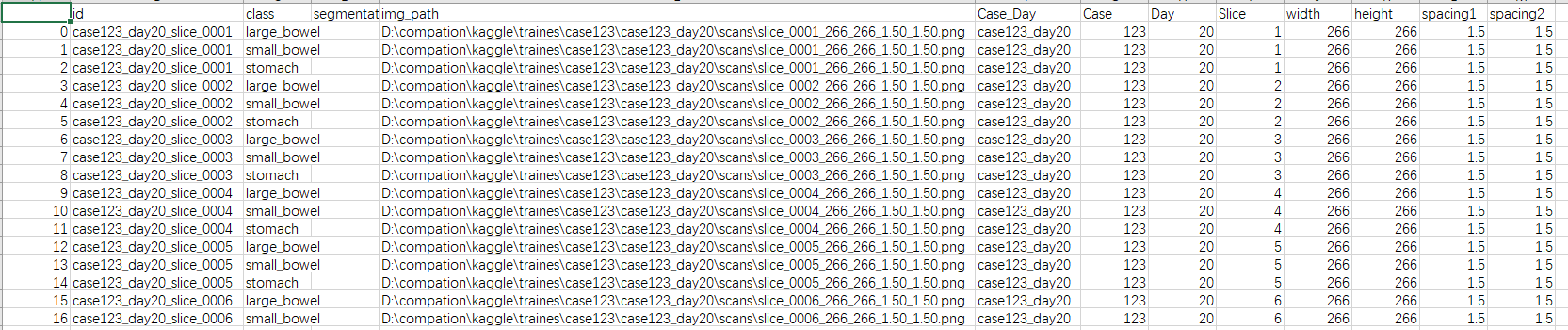
利用csv文件信息,将图片名信息保存到csv文件当中的更多相关文章
- python爬取当当网的书籍信息并保存到csv文件
python爬取当当网的书籍信息并保存到csv文件 依赖的库: requests #用来获取页面内容 BeautifulSoup #opython3不能安装BeautifulSoup,但可以安装Bea ...
- 记录python爬取猫眼票房排行榜(带stonefont字体网页),保存到text文件,csv文件和MongoDB数据库中
猫眼票房排行榜页面显示如下: 注意右边的票房数据显示,爬下来的数据是这样显示的: 网页源代码中是这样显示的: 这是因为网页中使用了某种字体的缘故,分析源代码可知: 亲测可行: 代码中获取的是国内票房榜 ...
- 使用pandas中的raad_html函数爬取TOP500超级计算机表格数据并保存到csv文件和mysql数据库中
参考链接:https://www.makcyun.top/web_scraping_withpython2.html #!/usr/bin/env python # -*- coding: utf-8 ...
- 使用scrapy爬取的数据保存到CSV文件中,不使用命令
pipelines.py文件中 import codecs import csv # 保存到CSV文件中 class CsvPipeline(object): def __init__(self): ...
- ffmpeg学习(二) 通过rtsp获取H264裸流并保存到mp4文件
本篇将使用上节http://www.cnblogs.com/wenjingu/p/3977015.html中编译好的库文件通过rtsp获取网络上的h264裸流并保存到mp4文件中. 1.VS2010建 ...
- python scrapy实战糗事百科保存到json文件里
编写qsbk_spider.py爬虫文件 # -*- coding: utf-8 -*- import scrapy from qsbk.items import QsbkItem from scra ...
- php将图片以二进制保存到mysql数据库并显示
一.存储图片的数据表结构: -- -- 表的结构 `image` -- CREATE TABLE IF NOT EXISTS `image` ( `id` int(3) NOT NULL AUTO_I ...
- Android相机、相册获取图片显示并保存到SD卡
Android相机.相册获取图片显示并保存到SD卡 [复制链接] 电梯直达 楼主 发表于 2013-3-13 19:51:43 | 只看该作者 |只看大图 本帖最后由 happy小妖同学 ...
- iOS开发——数据持久化&本地数据的存储(使用NSCoder将对象保存到.plist文件)
本地数据的存储(使用NSCoder将对象保存到.plist文件) 下面通过一个例子将联系人数据保存到沙盒的“documents”目录中.(联系人是一个数组集合,内部为自定义对象). 功能如下: ...
- np.savetxt()——将array保存到txt文件,并保持原格式
问题:1.如何将array保存到txt文件中?2.如何将存到txt文件中的数据读出为ndarray类型? 需求:科学计算中,往往需要将运算结果(array类型)保存到本地,以便进行后续的数据分析. 解 ...
随机推荐
- 【WSDL】03 使用注解自定义服务信息
对原来的自定义WebService设置注解: package cn.cloud9.jax_ws.server.intf; import javax.jws.WebMethod; import java ...
- 【DataBase】MySQL 04 图形化用户界面管理工具
参考至视频:P16 - P18 https://www.bilibili.com/video/BV1xW411u7ax?p=82 SQL图形化界面管理工具 - SQLyog 随便找的一个下载地址[安装 ...
- OSS简单文件上传和本地存储上传
网站的文件上传方法 本地存储上传 // 本地存储方式 MultipartFile接受文件 @PostMapping("/save") public Result save(Stri ...
- 人形机器人 —— NVIDIA公司给出的操作算法(动态操作任务,dynamic manipulation tasks)(机械手臂/灵巧手)框架示意图 —— NVIDIA Isaac Manipulator
原文: https://developer.nvidia.com/isaac/manipulator#foundation-models NVIDIA公司准备针对人形机器人的各部分操作分别推出一个AI ...
- Linux系统下使用pytorch多进程读取图片数据时的注意事项——DataLoader的多进程使用注意事项
原文: PEP 703 – Making the Global Interpreter Lock Optional in CPython 相关内容: The GIL Affects Python Li ...
- baselines算法库common/retro_wrappers.py模块分析
retro_wrappers.py模块代码: from collections import deque import cv2 cv2.ocl.setUseOpenCL(False) from .at ...
- 必看!S3File Sink Connector 使用文档
S3File 是一个用于管理 Amazon S3(Simple Storage Service)的 Python 模块.当前,Apache SeaTunnel 已经支持 S3File Sink Con ...
- 在线flex布局----自己写的一个flex布局的小玩意,需要的私聊加关注0.0
- [简单] 树上的dfs & bfs_洛谷P5908 猫猫和企鹅
题目链接https://www.luogu.com.cn/problem/P5908 题目大意: \[\begin{align*} & 给定n个点构成一颗树 每条边val=1\\ & ...
- quartz执行卡死--强制中断线程
在quartz中经常会碰到由于网络问题或者一些其他不稳定因素导致的线程卡死问题,这往往会导致数据处理的延时.而有时候一时无法定位到卡死的原因,为了降低系统风险,我们就会希望有一个超时机制,当执行超时时 ...