使用AWS SageMaker进行机器学习项目
使用AWS SageMaker进行机器学习项目
本文主要介绍如何使用AWS SageMaker进行机器学习项目。
1. 题目
使用的题目为阿里天池的“工业蒸汽量预测“,题目地址为:
https://tianchi.aliyun.com/competition/entrance/231693/introduction
给定的数据: 脱敏后的锅炉传感器采集的数据(采集频率为分钟级)
预测目标: 根据锅炉的工况,预测产生的蒸汽量。
数据说明: 数据分成训练数据(train.txt)和测试数据(test.txt),其中字段”V0”-“V37”,这38个字段是作为特征变量,”target”作为目标变量。选手利用训练数据训练出模型,预测测试数据的目标变量,排名结果依据预测结果的MSE(mean square error)。
结果评估: 预测结果以mean square error作为评判标准。
2. AWS SageMaker
AWS SageMaker是亚马逊云科技提供的机器学习服务,它整合了专门为ML可用的功能集,帮助数据科学家和开发人员快速准备、构建、训练和部署高质量的机器学习模型。
我们首先使用的是 AWS SageMaker的Notebook Instance进行数据的探索、清洗以及准备。在Notebook Instance中运行了一个Jupyter notebook server,可以在其上编写代码并做相关测试。例如:

在Jupyter中创建一个conda_python3 的notebook,即可开始对数据进行探索与处理。
3. 数据探索
3.1. 初步探索
先简单查看一下数据:
import pandas as pd
import s3fs
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from scipy import stats plt.style.use('seaborn')
%matplotlib inline train_raw = pd.read_csv(train_data_uri, sep='\t', encoding='utf-8')
test_raw = pd.read_csv(test_data_uri, sep='\t', encoding='utf-8') train_raw.head()

train_raw.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2888 entries, 0 to 2887
Data columns (total 39 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 V0 2888 non-null float64
1 V1 2888 non-null float64
2 V2 2888 non-null float64
…
37 V37 2888 non-null float64
38 target 2888 non-null float64
dtypes: float64(39)
memory usage: 880.1 KB
从训练集 info 信息我们可以知道,在训练集中:
- 一共有2888 个样本, 38个字段(V0 - V37) ,1个 target
- 所有特征均为连续型特征
- Label为连续型,所以我们需要回归函数进行预测
- 所有特征均没有空置
测试集 info():
test_raw.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1925 entries, 0 to 1924
Data columns (total 38 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 V0 1925 non-null float64
1 V1 1925 non-null float64
2 V2 1925 non-null float64
…
36 V36 1925 non-null float64
37 V37 1925 non-null float64
dtypes: float64(38)
memory usage: 571.6 KB
从测试集info() 我们可以了解到,在测试集中:
- 一共有1925个样本,38个字段(V0 - V37)
- 所有特征均为连续型
- 没有缺失值
若是进一步对df 做 describe(),则会有 39 个字段的describe数据,从观察数据的角度来看,比较复杂,所以下一步我们对数据进行可视化。
3.2. 数据可视化
3.2.1. 盒图
首先我们通过boxplot 探索离群点,首先以特征V1为例:
fig = plt.figure(figsize=(4, 6))
sns.boxplot(train_raw[['V1']], orient='v', width=0.5, palette="Set3")
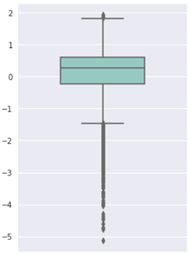
可以看到此特征有非常多的离群点。然后我们将所有特征进行盒图可视化:
# boxplot for all features
columns = train_raw.columns[:-1] fig = plt.figure(figsize=(80, 100), dpi=75)
for i in range(len(columns)):
plt.subplot(7, 6, i+1)
sns.boxplot(train_raw[columns[i]], orient='v', width=0.5, palette="Set3")
plt.ylabel(columns[i])
plt.show()
部分结果如下:
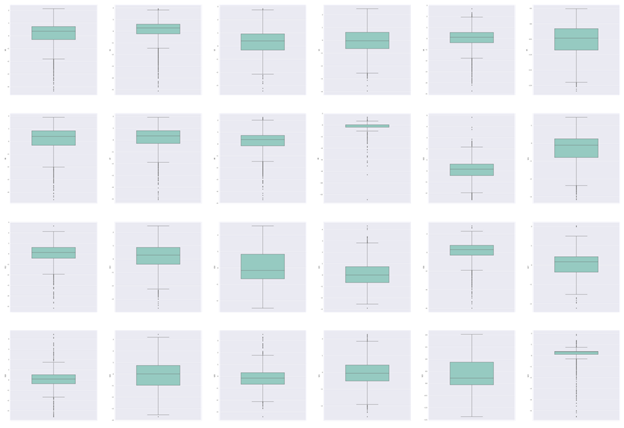
从这个结果来看,大部分特征或多或少均存在离群点,后续在特征工程阶段需要对此进行进一步处理。
3.2.2. 直方图与Q-Q图
接下来探索数据的分布情况,是否为正态分布。通过直方图与Q-Q图进行探索。
先以V0 特征为例:
plt.figure(figsize=(10, 5)) ax1 = plt.subplot(121)
sns.distplot(train_raw['V0'], fit=stats.norm) ax2 = plt.subplot(122)
res = stats.probplot(train_raw['V0'], plot=plt)
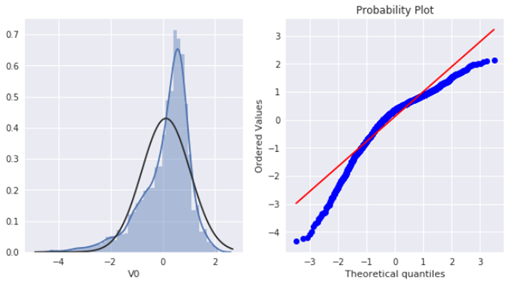
可以看到训练集中V0 特征并非为正态分布。接下来我们绘制所有特征的直方图与Q-Q图:
import warnings
warnings.filterwarnings("ignore")
plt.figure(figsize=(80, 190))
ax_index = 1
for i in range(len(columns)):
ax = plt.subplot(19, 4, ax_index)
sns.distplot(train_raw[columns[i]], fit=stats.norm)
ax_index += 1
ax = plt.subplot(19, 4, ax_index)
res = stats.probplot(train_raw[columns[i]], plot=plt)
ax_index += 1
部分结果如下:
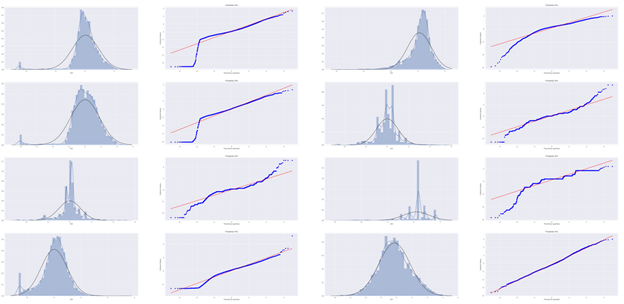
可以看到其中有的特征符合正态分布,但大部分并不符合,数据并不跟随对角线分布。对此,后续可以使用数据变换对其进行处理。
3.2.3. KDE分布图
KDE(Kernel Density Estimation,核密度估计)可以理解为是对直方图的加窗平滑。我们可以通过此图比较直观的看出数据本身的分布特征。
这里我们通过绘制KDE图,查看并对比训练集和测试集中特征变量的分布情况,来发现两个数据集中分布不一致的特征变量。
先仍以特征V0为例:
plt.figure(figsize=(10, 8))
ax = sns.kdeplot(train_raw['V0'], color="Red", shade=True)
ax = sns.kdeplot(test_raw['V0'], color="Blue", shade=True)
ax.set_xlabel("V0")
ax.set_ylabel("Frequency")
ax.legend(['train', 'test'])
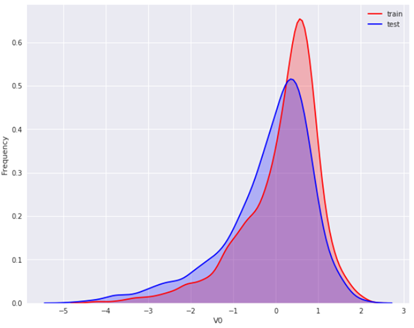
可以看到 V0 在两个数据集中的分布基本一致。然后对所有特征画出训练集与测试集中的KDE分布:
# all features' kde plots plt.figure(figsize=(40, 100))
ax_index = 1 for i in range(len(columns)):
ax = plt.subplot(10, 4, ax_index)
ax = sns.kdeplot(train_raw[columns[i]], color="Red", shade=True)
ax = sns.kdeplot(test_raw[columns[i]], color="Blue", shade=True)
ax.set_xlabel(columns[i])
ax.set_ylabel("Frequency")
ax.legend(['train', 'test'])
ax_index += 1
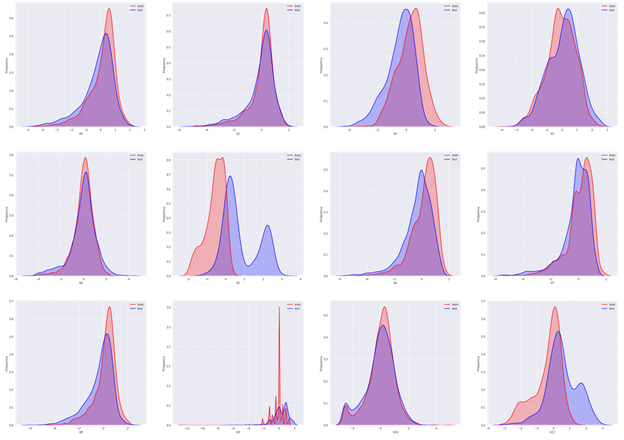
可以看到大部分特征的分布在训练集与测试集中基本一致,但仍有几个特征的分布在两个数据集中不一致(主要为V5、V9、V11、V17、V22、V28),这样会导致模型的泛化能力变差,可以考虑删除这些特征。
3.2.4. 线性回归关系图
线性回归关系图主要用于分析特征与label之间的线性相关性。
先看特征V0 与label的线性相关性:
plt.figure(figsize=(10, 8)) ax = plt.subplot(121)
sns.regplot(x='V0', y='target', data=train_raw, ax=ax, scatter_kws={'marker':'.', 's':4, 'alpha':0.3},
line_kws={'color':'g'})
plt.xlabel('V0')
plt.ylabel('target') plt.show()

从plot结果来看,可以看到V0特征与label是存在一定的相关性。接下来 plot所有特征与label的相关性:
plt.figure(figsize=(16, 32)) for i in range(len(columns)):
ax = plt.subplot(10, 4, i+1)
sns.regplot(x=columns[i], y='target', data=train_raw, ax=ax, scatter_kws={'marker':'.', 's':4, 'alpha':0.3},
line_kws={'color':'g'})
ax.set_xlabel(columns[i])
ax.set_ylabel('target')
部分结果如下所示:
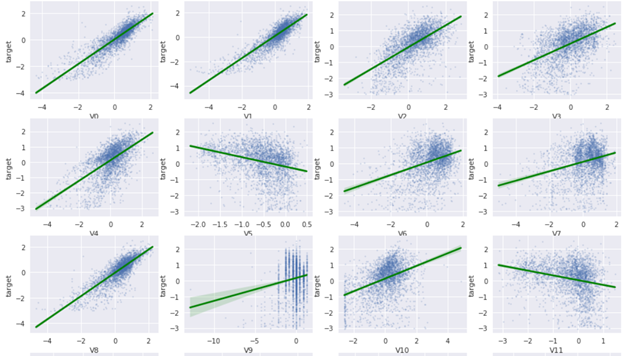
从结果来看,有不少特征与label有较强相关性(例如V0,V1,V8,V27,V31,…等),但是仍有部分特征与label之间基本无相关性(例如V9,V10,V13,V14,…等)。
当然这里只检查的是线性相关,并非表示特征与label之间没有其他相关性(例如非线性相关性)。
3.2.5. 线性相关性与热力图
变量之间的相关性通过协方差矩阵进行衡量,首先计算协方差矩阵并按与target相关性高低进行排序:
train_corr = train_raw.corr()
abs(train_corr['target']).sort_values(ascending=False, inplace=False) target 1.000000
V0 0.873212
V1 0.871846
V8 0.831904
...
V21 0.010063
V14 0.008424
V34 0.006034
Name: target, dtype: float64
可以看到与label的相关性低于0.1 的特征有:V33,V32,V26,V25,V21,V14,V34。
通过热力图可视化:
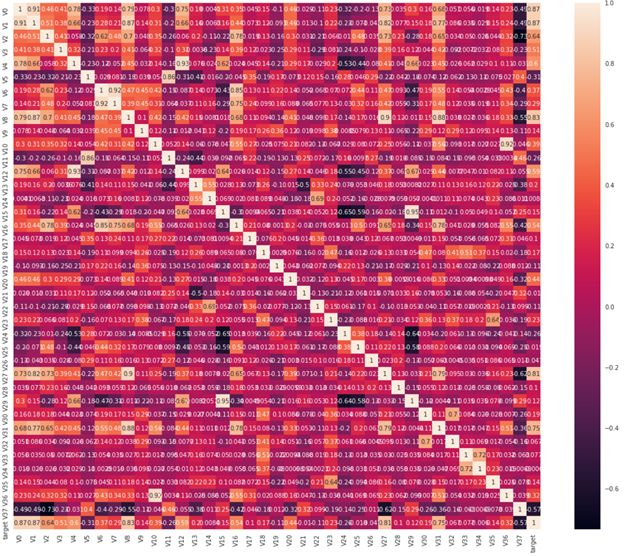
筛选出与label相关性大于0.1的特征:
corr_columns = train_corr[abs(train_corr['target']) > 0.1]['target'].index.tolist()[:-1] ['V0',
'V1',
'V2',
...'V37']
4. 特征工程
根据数据探索过程中观察到的现象,现在对数据做第一次特征处理。
4.1. 离群点
之前在boxplot中可以看到大部分特征存在离群点,一般会对离群点的处理是进行删除。不过在这个数据集中,删除过多的数据条目是不可接受的,所以我们会手动定义一个更大的范围,用于过滤离群点。
首先绘出所有特征的boxplot:
plt.figure(figsize=(36, 20))
green_diamond = dict(markerfacecolor='g', marker='o') plt.boxplot(train_raw.T, labels=train_raw.columns, showbox=True, showfliers=True, patch_artist=True,
flierprops=green_diamond) plt.show()

从图中能看到偏离较大的是V9的特征,这里从保守的角度,保留[-7.5, +7.5] 之间的数据。
train_drop_outlier = train_raw[train_raw['V9'] > -7.5]
test_drop_outlier = test_raw[test_raw['V9'] > -7.5]
4.2. 剔除特征
通过KDE分布图,可以找到几个特征在训练集与测试集中的分布不一致,会导致模型的泛化能力变差,所以删除V5、V9、V11、V17、V22、V28这几个特征。
train_dropped_feature = train_drop_outlier.drop(['V5', 'V9', 'V11', 'V17', 'V22', 'V28'], axis=1)
test_dropped_feature = test_drop_outlier.drop(['V5', 'V9', 'V11', 'V17', 'V22', 'V28'], axis=1)
4.3. 归一化
由于各个特征的取值范围并不一致,需要对所有数值类型做归一化:
# min_max_scaler
from sklearn.preprocessing import MinMaxScaler # target feature does not need to be scaled
train_dropped_target = train_dropped_feature.drop(['target'], axis=1)
feature_columns = train_dropped_target.columns.tolist() # min_max_scale fit on trainging data
min_max_scaler = MinMaxScaler().fit(train_dropped_target) # min_max scale transform on both training and test data
train_scaled = min_max_scaler.transform(train_dropped_target)
test_scaled = min_max_scaler.transform(test_dropped_feature) train_scaled = pd.DataFrame(train_scaled, columns=feature_columns)
train_scaled['target'] = train_dropped_feature['target'] test_scaled = pd.DataFrame(test_scaled, columns=feature_columns)
4.4. PCA降维
PCA降维除了用于减少数据维度外,还能够去除数据的多重性。下面使用PCA处理,保留95%的信息:
# PCA
from sklearn.decomposition import PCA pca = PCA(n_components=0.99) train_pca_99 = pca.fit_transform(train_scaled.iloc[:,0:-1])
test_pca_99 = pca.transform(test_scaled) train_pca_99 = pd.DataFrame(train_pca_99)
train_pca_99['target'] = train_dropped_feature['target'] test_pca_99 = pd.DataFrame(test_pca_99)
5. 模型训练
在数据进行了预处理后,下面即可开始使用模型进行训练。首先切分train_pca_99为训练集、验证集和测试集:
# train test split
from sklearn.model_selection import train_test_split train_pca_99 = train_pca_99.dropna() train_data_fin = train_pca_99.drop(['target'], axis=1)
train_data_fin_target = train_pca_99['target'] train_data, test_data, train_target, test_target = train_test_split(train_data_fin, train_data_fin_target, test_size=0.2) print(train_data.shape, test_data.shape, train_target.shape, test_target.shape) (2307, 25) (577, 25) (2307,) (577,)
6. 集成模型
在完成一个机器学习项目时,一般不会仅使用单个模型完成预测,而是使用多个模型的结果进行集成。当前几个主流的集成方法包括:Bagging,Boosting以及Stacking。在这个例子中,我们会使用Bagging,通过SageMaker分别训练一个XGBoost 和一个LinearLeaner,然后在预测时,使用它们的平均值作为预测输出。
6.1. XGBoost
在SageMaker中,对于XGBoost模型训练的输入规则是:
- 对于训练 ContentType,有效输入是 text/libsvm(默认值)或 text/csv
- 对于 CSV 训练,算法假定目标变量在第一列中,而 CSV 没有标头记录。
所以我们需要先将label列作为训练数据的第一列,并写为一个csv文件,再上传到s3,代码如下:
# put label at the first col
train_data.insert(0, 'target', train_target) # split train_data into data_train and data_val
train_list = np.random.rand(len(train_data)) < 0.8
data_train = train_data[train_list]
data_val = train_data[~train_list] # save them locally
data_train.to_csv("formatted_train.csv", sep=',', header=False, index=False) # save training data
data_val.to_csv("formatted_val.csv", sep=',', header=False, index=False) # save validation data
test_data.to_csv("formatted_test.csv", sep=',', header=False, index=False) # save test data # upload to s3
import os bucket = 'tang-sagemaker'
prefix = 'ZhengQi_data' train_file = 'formatted_train.csv'
val_file = 'formatted_val.csv' boto3.Session().resource('s3').Bucket(bucket).Object(os.path.join(prefix, 'train/', train_file)).upload_file(train_file)
boto3.Session().resource('s3').Bucket(bucket).Object(os.path.join(prefix, 'val/', val_file)).upload_file(val_file)
指定训练参数并进行训练:
# another approach # training
from sagemaker import get_execution_role
import sagemaker role = get_execution_role()
sess = sagemaker.Session() s3_output_location = f's3://{bucket}/{prefix}/output/' train_channel = sagemaker.inputs.TrainingInput(f's3://{bucket}/{prefix}/train/formatted_train.csv', content_type='text/csv')
val_channel = sagemaker.inputs.TrainingInput(f's3://{bucket}/{prefix}/val/formatted_val.csv', content_type='text/csv') container = sagemaker.image_uris.retrieve('xgboost', 'cn-north-1', 'latest') xgb_model = sagemaker.estimator.Estimator(container,
role,
instance_count=1,
instance_type='ml.m4.xlarge',
volume_size = 5,
output_path=s3_output_location,
sagemaker_session=sagemaker.Session(),
enable_sagemaker_metrics=False) xgb_model.set_hyperparameters(
max_depth = 5,
gamma = 1,
min_child_weight = 1,
objective = 'reg:squarederror',
eval_metric = 'rmse',
num_round = 100,
early_stopping_rounds=10
) xgb_model.fit({'train': train_channel, 'validation':val_channel})
以此参数进行训练后的结果为:
[24]#011train-rmse:0.311867#011validation-rmse:0.530562
Stopping. Best iteration:
[14]#011train-rmse:0.32222#011validation-rmse:0.528132
可以看到最低的rmse结果为0.5281。
6.1.1. XGBoost超参数调优
在进行超参数调优时,可以启动一个超参数优化任务。原理与sklearn中的超参数搜索(例如GridSearch,RandomeizedSearch等)类似。这里我们选择随机超参数搜索,代码如下:
from sagemaker.tuner import ContinuousParameter, HyperparameterTuner objective_metric_name = 'validation:rmse'
hyperparameter_ranges = {
'alpha': ContinuousParameter(0.01, 10, scaling_type="Logarithmic"),
'lambda': ContinuousParameter(0.01, 10, scaling_type="Logarithmic")
} tuner_log = HyperparameterTuner(
xgb_model,
objective_metric_name,
hyperparameter_ranges,
objective_type='Minimize',
max_jobs=20,
max_parallel_jobs=10,
strategy='Random'
) tuner_log.fit({'train': train_channel, 'validation': val_channel}, include_cls_metadata=False)
探索结果:
df_log = sagemaker.HyperparameterTuningJobAnalytics(tuner_log.latest_tuning_job.job_name).dataframe()
df_log['FinalObjectiveValue'].sort_values(ascending=True, inplace=False)[:3] 11 0.523109
18 0.524432
10 0.525883
Name: FinalObjectiveValue, dtype: float64 df_log.loc[11]
alpha 0.0187497
lambda 5.70063
TrainingJobName xgboost-210409-1554-009-70f060d0
TrainingJobStatus Completed
FinalObjectiveValue 0.523109
TrainingStartTime 2021-04-09 15:58:27+00:00
TrainingEndTime 2021-04-09 15:59:34+00:00
TrainingElapsedTimeSeconds 67
scaling log
Name: 11, dtype: object
可以看到在这次超参数搜索中,排名最好的alpha和lambda参数组为:
alpha 0.0187497
lambda 5.70063
对应的训练job为:xgboost-210409-1554-009-70f060d0
6.1.2. XGBoost模型部署
创建此训练job对应的模型:
# create model
sm = boto3.client('sagemaker') best_xgboost_model = df_log.loc[df_log['FinalObjectiveValue'].idxmin()]['TrainingJobName']
model_name=best_xgboost_model + '-mdl' xgboost_hosting_container = {
'Image': container,
'ModelDataUrl': sm.describe_training_job(TrainingJobName=best_xgboost_model)['ModelArtifacts']['S3ModelArtifacts']
} create_model_response = sm.create_model(
ModelName=model_name,
ExecutionRoleArn=role,
PrimaryContainer=xgboost_hosting_container)
指定部署模型的配置:
from time import gmtime, strftime
endpoint_config_name = 'XGBoostEndpointConfig-' + strftime("%Y-%m-%d-%H-%M-%S", gmtime())
print(endpoint_config_name)
create_endpoint_config_response = sm.create_endpoint_config(
EndpointConfigName = endpoint_config_name,
ProductionVariants=[{
'InstanceType':'ml.m4.xlarge',
'InitialInstanceCount':1,
'InitialVariantWeight':1,
'ModelName':model_name,
'VariantName':'AllTraffic'}])
print("Endpoint Config Arn: " + create_endpoint_config_response['EndpointConfigArn'])
部署模型到终端节点:
# create endpoint
import time endpoint_name = 'XGBoostEndpoint-' + strftime("%Y-%m-%d-%H-%M-%S", gmtime())
print(endpoint_name)
create_endpoint_response = sm.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name)
print(create_endpoint_response['EndpointArn']) resp = sm.describe_endpoint(EndpointName=endpoint_name)
status = resp['EndpointStatus']
print("Status: " + status) while status=='Creating':
time.sleep(60)
resp = sm.describe_endpoint(EndpointName=endpoint_name)
status = resp['EndpointStatus']
print("Status: " + status) print("Arn: " + resp['EndpointArn'])
print("Status: " + status)
6.1.3. XGBoost模型验证
文件为csv格式,需要转为numpy 数组,然后发送到部署好的终端节点,并获取到模型的预测值:
import io
import sys runtime= boto3.client('runtime.sagemaker') # Simple function to create a csv from our numpy array
def np2csv(arr):
csv = io.BytesIO()
np.savetxt(csv, arr, delimiter=',', fmt='%g')
return csv.getvalue().decode().rstrip() # Function to generate prediction through sample data
def do_predict(data, endpoint_name, content_type):
payload = np2csv(data)
response = runtime.invoke_endpoint(EndpointName=endpoint_name,
ContentType=content_type,
Body=payload)
result = response['Body'].read()
result = result.decode("utf-8")
result = result.split(',')
preds = [float((num)) for num in result]
return preds # Function to iterate through a larger data set and generate batch predictions
def batch_predict(data, batch_size, endpoint_name, content_type):
items = len(data)
arrs = [] for offset in range(0, items, batch_size):
if offset+batch_size < items:
datav = data.iloc[offset:(offset+batch_size),:].values
results = do_predict(datav, endpoint_name, content_type)
arrs.extend(results)
else:
datav = data.iloc[offset:items,:].values
arrs.extend(do_predict(datav, endpoint_name, content_type))
sys.stdout.write('.')
return(arrs)
获得训练数据、预测数据以及测试数据的预测值后,使用均方误差进行评估:
# do prediction
preds_train_xgb = batch_predict(data_train.iloc[:, 1:], 1000, endpoint_name, 'text/csv')
preds_val_xgb = batch_predict(data_val.iloc[:, 1:], 1000, endpoint_name, 'text/csv')
preds_test_xgb = batch_predict(data_test, 1000, endpoint_name, 'text/csv') # evaluation
from sklearn.metrics import mean_squared_error train_labels = data_train.iloc[:,0];
val_labels = data_val.iloc[:,0]; print("Training MSE", mean_squared_error(train_labels, preds_train_xgb))
print("Validation MSE", mean_squared_error(val_labels, preds_val_xgb))
print("Test MSE", mean_squared_error(test_target, preds_test_xgb)) Training MSE 0.10267861046608459
Validation MSE 0.27399804734388417
Test MSE 0.3310241908011309
从这个结果可以看出,模型稍微存在过拟合,在测试集上的误差要比测试集上的误差高0.23左右。
下面我们再训练第二个模型。
6.2. LinearLearner
在SageMaker中,LinearLearner模型训练的输入规则是:
- 输入格式支持recordIO-wrapped protobuf 和 CSV 格式
- 对于 text/csv 输入类型,第一列假定为标签,即预测的目标变量
前面我们已经处理好格式,下面直接指定参数并进行训练:
# train a linear model
s3_output_location_linear = f's3://{bucket}/{prefix}/linear_output/' container = sagemaker.image_uris.retrieve("linear-learner", boto3.Session().region_name, version="1") linear_model = sagemaker.estimator.Estimator(
container,
role,
input_mode="File",
instance_count=1,
instance_type="ml.m4.xlarge",
output_path=s3_output_location_linear,
sagemaker_session=sess,
) linear_model.set_hyperparameters(
feature_dim=8,
epochs=16,
wd=0.01,
loss="absolute_loss",
predictor_type="regressor",
normalize_data=False,
optimizer="adam",
mini_batch_size=100,
lr_scheduler_step=100,
lr_scheduler_factor=0.99,
lr_scheduler_minimum_lr=0.0001,
learning_rate=0.1,
) linear_model.fit({'train': train_channel, 'validation':val_channel})
训练结束后打印的指标为:
#validation_score (algo-1) : ('mse_objective', 0.31672970836480807)
#validation_score (algo-1) : ('mse', 0.31672970836480807)
可以看到在验证集上的均方误差为0.3167
6.2.1. LinearLearner 超参数调优
同样使用HyperparameterTuner 进行调优:
objective_metric_name = 'validation:objective_loss'
hyperparameter_ranges = {
'learning_rate': ContinuousParameter(0.01, 0.1, scaling_type="Logarithmic"),
'l1': ContinuousParameter(0.01, 0.1, scaling_type="Logarithmic"),
'wd': ContinuousParameter(0.01, 0.1, scaling_type="Logarithmic")
} tuner_linear_log = HyperparameterTuner(
linear_model,
objective_metric_name,
hyperparameter_ranges,
objective_type='Minimize',
max_jobs=30,
max_parallel_jobs=10,
strategy='Random'
) tuner_linear_log.fit({'train': train_channel, 'validation': val_channel})
探索结果:
tuner_linear_log = sagemaker.HyperparameterTuningJobAnalytics(tuner_linear_log.latest_tuning_job.job_name).dataframe()
tuner_linear_log['FinalObjectiveValue'].sort_values(ascending=True, inplace=False)[:3] 23 0.315122
17 0.316627
2 0.318820
Name: FinalObjectiveValue, dtype: float64 tuner_linear_log.loc[23] l1 0.013238
learning_rate 0.0322787
wd 0.010156
TrainingJobName linear-learner-210409-1752-007-7c0938e8
TrainingJobStatus Completed
FinalObjectiveValue 0.315122
TrainingStartTime 2021-04-09 17:55:43+00:00
TrainingEndTime 2021-04-09 17:57:01+00:00
TrainingElapsedTimeSeconds 78
Name: 23, dtype: object
可以看到在这次超参数搜索中,排名最好的l1,learning_rate,wd参数组为:
l1 0.013238
learning_rate 0.0322787
wd 0.010156
对应的训练job为:linear-learner-210409-1752-007-7c0938e8
6.2.2 LinearLearner 模型部署
创建此训练job对应的模型:
# create model
best_linear_model = tuner_linear_log.loc[tuner_linear_log['FinalObjectiveValue'].idxmin()]['TrainingJobName']
model_name=best_linear_model + '-lmdl' linear_hosting_container = {
'Image': container,
'ModelDataUrl': sm.describe_training_job(TrainingJobName=best_linear_model)['ModelArtifacts']['S3ModelArtifacts']
} create_model_response = sm.create_model(
ModelName=model_name,
ExecutionRoleArn=role,
PrimaryContainer=linear_hosting_container)
指定部署模型的配置:
from time import gmtime, strftime
endpoint_config_name = 'LinearEndpointConfig-' + strftime("%Y-%m-%d-%H-%M-%S", gmtime())
print(endpoint_config_name)
create_endpoint_config_response = sm.create_endpoint_config(
EndpointConfigName = endpoint_config_name,
ProductionVariants=[{
'InstanceType':'ml.m4.xlarge',
'InitialInstanceCount':1,
'InitialVariantWeight':1,
'ModelName':model_name,
'VariantName':'AllTraffic'}])
print("Endpoint Config Arn: " + create_endpoint_config_response['EndpointConfigArn'])
部署模型到终端节点:
# create endpoint
import time endpoint_name = 'LinearEndpoint-' + strftime("%Y-%m-%d-%H-%M-%S", gmtime())
print(endpoint_name)
create_endpoint_response = sm.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name)
print(create_endpoint_response['EndpointArn']) resp = sm.describe_endpoint(EndpointName=endpoint_name)
status = resp['EndpointStatus']
print("Status: " + status) while status=='Creating':
time.sleep(60)
resp = sm.describe_endpoint(EndpointName=endpoint_name)
status = resp['EndpointStatus']
print("Status: " + status) print("Arn: " + resp['EndpointArn'])
print("Status: " + status)
6.2.3. LinearLearnerr模型验证
import json def np2csv(arr):
csv = io.BytesIO()
np.savetxt(csv, arr, delimiter=',', fmt='%g')
return csv.getvalue().decode().rstrip() # Function to generate prediction through sample data
def do_predict_linear(data, endpoint_name, content_type): payload = np2csv(data)
response = runtime.invoke_endpoint(EndpointName=endpoint_name,
ContentType=content_type,
Body=payload)
result = json.loads(response['Body'].read().decode())
preds = [r['score'] for r in result['predictions']] return preds # Function to iterate through a larger data set and generate batch predictions
def batch_predict_linear(data, batch_size, endpoint_name, content_type):
items = len(data)
arrs = [] for offset in range(0, items, batch_size):
if offset+batch_size < items:
datav = data.iloc[offset:(offset+batch_size),:].values
results = do_predict_linear(datav, endpoint_name, content_type)
arrs.extend(results)
else:
datav = data.iloc[offset:items,:].values
arrs.extend(do_predict_linear(datav, endpoint_name, content_type))
sys.stdout.write('.')
return(arrs) ### Predict
preds_train_lin = batch_predict_linear(data_train.iloc[:,1:], 100, endpoint_name , 'text/csv')
preds_val_lin = batch_predict_linear(data_val.iloc[:,1:], 100, endpoint_name , 'text/csv')
preds_test_lin = batch_predict_linear(data_test, 100, endpoint_name , 'text/csv') print("Training MSE", mean_squared_error(train_labels, preds_train_lin))
print("Validation MSE", mean_squared_error(val_labels, preds_val_lin))
print("Test MSE", mean_squared_error(test_target, preds_test_lin)) Training MSE 0.3205520723200668
Validation MSE 0.3153403808426263
Test MSE 0.37555825359647615
可以看到LinearLearner的泛化性能较好,验证集和测试集上的表现没有出现太大偏差,但是准确度并不优秀。
6.3. 模型融合
最后将两个模型的结果取加权平均:
ens_train = 0.5*np.array(preds_train_xgb) + 0.5*np.array(preds_train_lin);
ens_val = 0.5*np.array(preds_val_xgb) + 0.5*np.array(preds_val_lin);
ens_test = 0.5*np.array(preds_test_xgb) + 0.5*np.array(preds_test_lin); print("Training MSE", mean_squared_error(train_labels, ens_train))
print("Validation MSE", mean_squared_error(val_labels, ens_val))
print("Test MSE", mean_squared_error(test_target, ens_test)) Training MSE 0.1786694748626782
Validation MSE 0.2740073446434298
Test MSE 0.3336424287800188
以上即为使用SageMaker进行模型训练、部署、以及验证的过程。对此结果来看,后续仍需要做部分优化。
从数据方面,还可以考虑:
- 做Box-Cox 变换,使数据更符合正态分布,使其更加符合后面数据挖掘方法对数据分布的假设
- 可以尝试不同的PCA参数
从模型训练方面,还可以考虑:
- 对xgboost增加l2 正则惩罚,缓解过拟合
- 对模型使用更多的参数搜索
- 尝试更优的lightGBM、SVM等算法
- 增加Bagging的模型数目
- 尝试Stacking
使用AWS SageMaker进行机器学习项目的更多相关文章
- 28款GitHub最流行的开源机器学习项目
现在机器学习逐渐成为行业热门,经过二十几年的发展,机器学习目前也有了十分广泛的应用,如:数据挖掘.计算机视觉.自然语言处理.生物特征识别.搜索引擎.医学诊断.DNA序列测序.语音和手写识别.战略游戏和 ...
- 28款GitHub最流行的开源机器学习项目,推荐GitHub上10 个开源深度学习框架
20 个顶尖的 Python 机器学习开源项目 机器学习 2015-06-08 22:44:30 发布 您的评价: 0.0 收藏 1收藏 我们在Github上的贡献者和提交者之中检查了用Python语 ...
- 3.Scikit-Learn实现完整的机器学习项目
1 完整的机器学习项目 完成项目的步骤: (1) 项目概述 (2) 获取数据 (3) 发现并可视化数据,发现规律. (4) 为机器学习算法准备数据. (5) ...
- Sklearn 与 TensorFlow 机器学习实战—一个完整的机器学习项目
本章中,你会假装作为被一家地产公司刚刚雇佣的数据科学家,完整地学习一个案例项目.下面是主要步骤: 项目概述. 获取数据. 发现并可视化数据,发现规律. 为机器学习算法准备数据. 选择模型,进行训练. ...
- DeepLearning.ai学习笔记(三)结构化机器学习项目--week2机器学习策略(2)
一.进行误差分析 很多时候我们发现训练出来的模型有误差后,就会一股脑的想着法子去减少误差.想法固然好,但是有点headlong~ 这节视频中吴大大介绍了一个比较科学的方法,具体的看下面的例子 还是以猫 ...
- ng机器学习视频笔记(十六) ——从图像处理谈机器学习项目流程
ng机器学习视频笔记(十六) --从图像处理谈机器学习项目流程 (转载请附上本文链接--linhxx) 一.概述 这里简单讨论图像处理的机器学习过程,主要讨论的是机器学习的项目流程.采用的业务示例是O ...
- 第24月第30天 scrapy《TensorFlow机器学习项目实战》项目记录
1.Scrapy https://www.imooc.com/learn/1017 https://github.com/pythonsite/spider/tree/master/jobboleSp ...
- Hands on Machine Learning with sklearn and TensorFlow —— 一个完整的机器学习项目(加州房地产)
数据集地址:https://github.com/ageron/handson-ml/tree/master/datasets 先行知识准备:NumPy,Pandas,Matplotlib的模块使用 ...
- GitHub最著名的20个Python机器学习项目
GitHub最著名的20个Python机器学习项目 我们分析了GitHub上的前20名Python机器学习项目,发现scikit-Learn,PyLearn2和NuPic是贡献最积极的项目.让我们一起 ...
- 一个完整的机器学习项目在Python中的演练(二)
大家往往会选择一本数据科学相关书籍或者完成一门在线课程来学习和掌握机器学习.但是,实际情况往往是,学完之后反而并不清楚这些技术怎样才能被用在实际的项目流程中.就像你的脑海中已经有了一块块"拼 ...
随机推荐
- iOS LLVM 中的宏定义
在阅读 Objc 库源码时常常会遇到很多宏定义,比如宏 SUPPORT_INDEXED_ISA.SUPPORT_PACKED_ISA,代码如下所示: // Define SUPPORT_INDEXED ...
- spring-boot集成Quartz-job存储方式二RAM
简单区分: RAM:程序启动从数据库中读取原始job配置(也可以从配置文件中读取),job中间运行过程在RAM内存中,程序停止或重启后,RAM中数据丢失,再次启动的时候会重新读取job配置.适合于单机 ...
- kettle使用1-全表导入
1.新建转换 2.DB连接中,新建数据库连接 3.在输入中,选择表输入 选择连接的数据库和查询的sql的数据 4.再输出中,选择表输出 5.按住shift,建立数据连接 6.匹配数据字段映射
- uniapp底层跨端原理
uniapp底层跨端原理 - 代码编写:开发者使用Vue.js框架编写uniapp的代码,包括页面结构.样式和逻辑等. - 编译过程:在编译过程中,uniapp会将Vue.js的代码转换为各个平台所需 ...
- UE4 C++调用手柄震动
近期封装输入相关逻辑,简单归纳下. 蓝图实现 内容界面右键Miscellaneous->Force Feedback Effect,创建力反馈对象并填写相关参数: 然后在蓝图中用Spawn Fo ...
- 学习c# 7.0-7.3的ref、fixed特性并在Unity下测试
1.ref的一些运用 1.1 ref readonly 关于ref,一个主要应用是防止结构体拷贝,若返回的结构体不需要修改则用ref readonly,类似c++的const标记 : private ...
- Sphinx 自动化文档
目录 文章目录 目录 Sphinx 入门 reStructuredText 语法格式 标题.列表.正文.要点 表格 代码块 引用其他模块文件 引用静态图片 Sphinx Sphinx 是一个工具,它使 ...
- Selenium4自动化测试8--控件获取数据--上传、下载、https和切换分页
10-上传 上传不能模拟用户在页面上选择本地文件,只能先把要上传的文件先准备好在代码里上传 import time from selenium.webdriver.support.select imp ...
- DashVector + DashScope升级多模态检索
本教程在前述教程(DashVector + ModelScope玩转多模态检索)的基础之上,基于DashScope上新推出的ONE-PEACE通用多模态表征模型结合向量检索服务DashVector来对 ...
- Linux下mv和cp命令的区别
1.功能上的区别 mv:用户可以使用mv为文件或目录重命名或将文件由一个目录移入另一个目录中. cp: cp的功能是将给出的文件或目录拷贝到另一文件或目录中. 2.inode上的区别(inod ...