力扣275(jav&python)-H 指数 II(中等)
题目:
给你一个整数数组 citations ,其中 citations[i] 表示研究者的第 i 篇论文被引用的次数,citations 已经按照 升序排列 。计算并返回该研究者的 h 指数。
h 指数的定义:h 代表“高引用次数”(high citations),一名科研人员的 h 指数是指他(她)的 (n 篇论文中)总共有 h 篇论文分别被引用了至少 h 次。且其余的 n - h 篇论文每篇被引用次数 不超过 h 次。
提示:如果 h 有多种可能的值,h 指数 是其中最大的那个。
请你设计并实现对数时间复杂度的算法解决此问题。
示例 1:
输入:citations = [0,1,3,5,6]
输出:3
解释:给定数组表示研究者总共有 5 篇论文,每篇论文相应的被引用了 0, 1, 3, 5, 6 次。
由于研究者有 3 篇论文每篇 至少 被引用了 3 次,其余两篇论文每篇被引用 不多于 3 次,所以她的 h 指数是 3 。
示例 2:
输入:citations = [1,2,100]
输出:2
提示:
- n == citations.length
- 1 <= n <= 105
- 0 <= citations[i] <= 1000
- citations 按 升序排列
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/h-index-ii
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解题思路:
【二分查找】
上一个H指数都没明白题目意思,今天再次看到这个题熟悉又陌生,感谢:@【liweiwei1419】https://leetcode.cn/problems/h-index-ii/solution/jian-er-zhi-zhi-er-fen-cha-zhao-by-liweiwei1419-2/,(这个老师的二分查找讲的特别好!强烈推荐)
这里最主要的问题是要理解到:H指数的含义
题目给的含义是:
- n篇论文中总共有h篇论文分别被引用了至少h次;
- 其余的n-h篇论文每篇被引用的次数不超过h次。
例如:h = 20,表示引用次数大于等于20 的论文数量最少是20篇。
h指数指的是 论文数量,不是引用次数!!!
进一步理解题意:
一个人的论文被引用的次数有一个分水岭(就是h),如果引用次数大于等于h,就代表高引用的论文。所以需要将所给数组进行分割,条件是:分割线右边的引用次数 >= 分割线右边的论文篇数

又因为引用次数的有序排列的,故想到使用二分查找:
- left = 0, right = n - 1, mid = left + (right - left) / 2,循环条件是:left < right;
- 如果nums[mid] < n - mid:表示分割右边的最少引用次数小于右边的论文篇数,说明分割线需要往右移动,下一轮搜索区间应该为[mid+1, right]即left = mid +1
- 例如[0,2,3,|5,8,10,13,16,20],猜测有6篇论文最小引用次数为6,但是最小引用次数才5,所以分割处需要向右移动,[0,2,3,5,|8,10,13,16,20],猜测有5篇论文最小引用次数为8,其余的4篇论文被引用的次数不超过8次。此时mid就是答案为5。
- 上面的对立面:如果nums[mid] >= n - mid:表示分割右边的最少引用次数大于等于右边的论文篇数,下一轮搜索区间应该为[left, mid]即right = mid ;
- 退出循环条件:left == right,返回截止left的论文篇数,需要n - left。
- right = n -1:分割线最右只能在n-1的左边。

- 特殊处理:citations[n-1] == 0,表示如果全部文章的引用次数都为0,则 h 指数就为0。
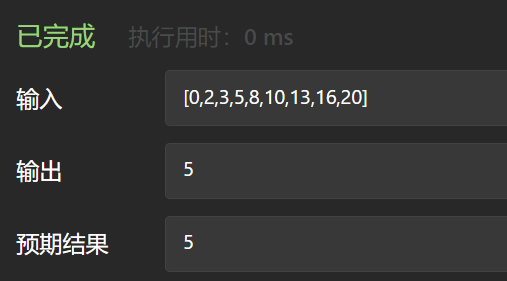
java代码(left < right):
1 class Solution {
2 public int hIndex(int[] citations) {
3 int n = citations.length;
4 if (citations[n-1] == 0) return 0;
5 int left = 0, right = n - 1;
6 while (left < right){
7 int mid = left + (right - left) / 2;
8 //如果论文的数量小于中间引用数, 搜索区间往左走
9 //n - mid:分割处右边的论文数量
10 if (citations[mid] < n - mid){
11 left = mid + 1;
12 }else{
13 right = mid;
14 }
15 }
16 return n - left;
17 }
18 }
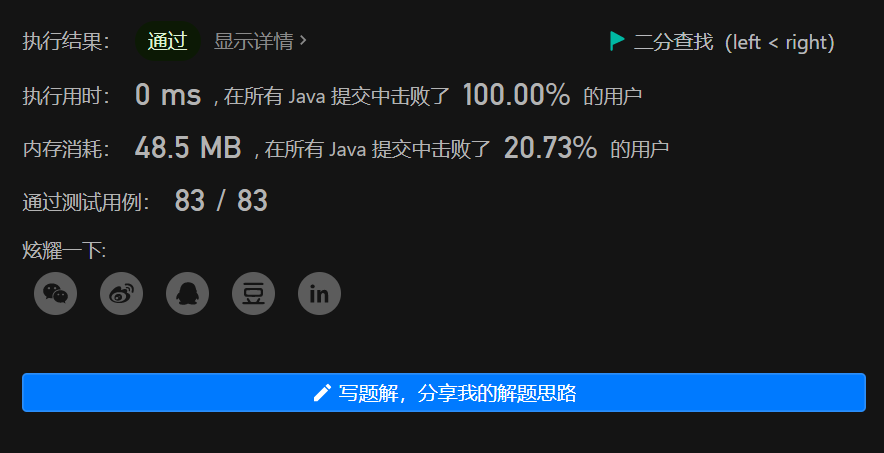
python3代码(left <= right):
1 class Solution:
2 def hIndex(self, citations: List[int]) -> int:
3 n = len(citations)
4 left, right = 0, n - 1
5 if citations[n-1] == 0:
6 return 0
7 while left <= right:
8 mid = left + (right - left) // 2
9 if citations[mid] == n - mid:
10 return citations[mid]
11 elif citations[mid] < n - mid:
12 left = mid + 1
13 else:
14 right = mid - 1
15 # [1,3,5,7,10,13] len-left=4
16 return n - left
力扣275(jav&python)-H 指数 II(中等)的更多相关文章
- Leetcode之二分法专题-275. H指数 II(H-Index II)
Leetcode之二分法专题-275. H指数 II(H-Index II) 给定一位研究者论文被引用次数的数组(被引用次数是非负整数),数组已经按照升序排列.编写一个方法,计算出研究者的 h 指数. ...
- Java实现 LeetCode 275 H指数 II
275. H指数 II 给定一位研究者论文被引用次数的数组(被引用次数是非负整数),数组已经按照升序排列.编写一个方法,计算出研究者的 h 指数. h 指数的定义: "h 代表"高 ...
- 力扣 122 买卖股票的最佳时机II
力扣 122 买卖股票的最佳时机II 思路: 动态规划,表面上是\(O(2^n)\)的搜索空间,实际上该天的选择只与前一天的状态(是否持有股票)有关.从收益的角度来看,确实每一天的不同选择都会产生不同 ...
- [LeetCode] 275. H-Index II H指数 II
Follow up for H-Index: What if the citations array is sorted in ascending order? Could you optimize ...
- 275 H-Index II H指数 II
这是 H指数 进阶问题:如果citations 是升序的会怎样?你可以优化你的算法吗? 详见:https://leetcode.com/problems/h-index-ii/description/ ...
- 力扣 ——Remove Duplicates from Sorted List II(删除排序链表中的重复元素 II)python实现
题目描述: 中文: 给定一个排序链表,删除所有含有重复数字的节点,只保留原始链表中 没有重复出现 的数字. 示例 1: 输入: 1->2->3->3->4->4-> ...
- 刷题-力扣-107. 二叉树的层序遍历 II
107. 二叉树的层序遍历 II 题目链接 来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/binary-tree-level-order-tr ...
- 刷题-力扣-122. 买卖股票的最佳时机 II
122. 买卖股票的最佳时机 II 题目链接 来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/best-time-to-buy-and-sell ...
- [Swift]LeetCode275. H指数 II | H-Index II
Given an array of citations sorted in ascending order (each citation is a non-negative integer) of a ...
- 力扣算法——135Candy【H】
老师想给孩子们分发糖果,有 N 个孩子站成了一条直线,老师会根据每个孩子的表现,预先给他们评分. 你需要按照以下要求,帮助老师给这些孩子分发糖果: 每个孩子至少分配到 1 个糖果.相邻的孩子中,评分高 ...
随机推荐
- 用json画图的画图软件 推荐 Balsamiq
看这个库的时候发现的的这个软件 https://github.com/ironman1987/chinese-developer-roadmap 下载:https://www.zdfans.com/h ...
- MFC动态创建控件并添加消息映射
目录 指定ID 对象指针 建立对象 控件样式 消息映射 按钮单击 组合框选中 指定ID 在类中声明并定义按钮控件的起始ID,以控件的类型和功能对动态控件ID进行分组,每组最好定义一个自己的起始ID方便 ...
- 学习笔记-涛讲F#(中级)
目录 适配器模式 责任链模式 命令模式 策略模式 工厂模式 单例模式 其它内容 这一系列的视频主要讲了F#设计模式的实现,没有太多其它内容,笔记内容主要是转载Snippets tagged desig ...
- WPF之x命名空间
目录 x命名空间内容 x命名空间的Attribute x:Class x:ClassModifier x:Name x:FieldModifier x:Key x:Shared x命名空间的标记扩展 ...
- Uni-App 实现资讯滚动
项目需要实现资讯的滚动,使用了Swiper组件,实现了首页头部的资讯滚动,简单地做下笔记 效果 实现说明 主要是使用了Swiper可以自动滚动的特性来实现,左边是一个图片,右边则是Swpier,且姜S ...
- sqlplus清屏方法
cmd中使用:host cls 或 clear screen或 clear scre或clea scr
- C++自定义比较函数的bug
auto cmp = [] (int x, int y) {return true;}; priority_queue<int, vector<int> , cmp> q; 报 ...
- LinuxDNS分析从入门到放弃(记一次有趣的dns问题排查记录,ping 源码分析,getaddrinfo源码分析)
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 环境说明 ubuntu 18.04 前言 我们这里有一块 ...
- hadoop集群实现分发文件命令xsync脚本文件
1 #!/bin/bash 2 3 #1. 判断参数个数 4 if [ $# -lt 1 ] 5 then 6 echo Not Enough Arguement! 7 exit; 8 fi 9 10 ...
- C++设计模式 - 抽象工厂(Abstract Factory)
对象创建模式 通过"对象创建" 模式绕开new,来避免对象创建(new)过程中所导致的紧耦合(依赖具体类),从而支持对象创建的稳定.它是接口抽象之后的第一步工作. 典型模式 Fac ...