MMDeploy部署实战系列【第四章】:onnx,tensorrt模型推理
MMDeploy部署实战系列【第四章】:onnx,tensorrt模型推理
这个系列是一个随笔,是我走过的一些路,有些地方可能不太完善。如果有那个地方没看懂,评论区问就可以,我给补充。
目录:
0️⃣ mmdeploy源码安装 (转换faster rcnn r50/yolox为tensorrt,并进行推理)_gy77
内容:一文包含了在Linux系统下安装mmdeploy模型转换环境,模型转换为TensorRT,在Linux,Windows下模型推理,推理结果展示。
1️⃣ MMDeploy部署实战系列【第一章】:Docker,Nvidia-docker安装_gy77
内容:docker/nvidia-docker安装,docker/nvidia-docker国内源,docker/nvidia-docker常用命令。
2️⃣ MMDeploy部署实战系列【第二章】:mmdeploy安装及环境搭建_gy77
内容:mmdeploy环境安装三种方法:源码安装,官方docker安装,自定义Dockerfile安装。
3️⃣ MMDeploy部署实战系列【第三章】:MMdeploy pytorch模型转换onnx,tensorrt_gy77
内容:如何查找pytorch模型对应的部署配置文件,模型转换示例:mmcls:resnext50,mmdet:yolox-s,faster rcnn50。
4️⃣ MMDeploy部署实战系列【第四章】:onnx,tensorrt模型推理_gy77
内容:在linux,windows环境下推理,Windows下推理环境安装,推理速度对比,显存对比,可视化展示。
5️⃣ MMDeploy部署实战系列【第五章】:Windows下Release x64编译mmdeploy(C++),对TensorRT模型进行推理_gy77
内容:Windows下环境安装编译环境,编译c++ mmdeploy,编译c++ mmdeploy demo,运行实例。
6️⃣ MMDeploy部署实战系列【第六章】:将编译好的MMdeploy导入到自己的项目中 (C++)_gy77
内容:Windows下环境导入我们编译好的mmdeploy 静态/动态库。
配置环境变量 约定:
$env:TENSORRT_DIR = "F:\env\TensorRT"
# Windows: 上边命令代表新建一个系统变量,变量名为:TENSORRT_DIR 变量值为:F:\env\TensorRT
# Linux:
vim ~/.bashrc
#在最后一行加入
export TENSORRT_DIR=/home/gy77/TensorRT
source ~/.bashrc
$env:Path = "F:\env\TensorRT\lib"
# Windows: 上边命令代表在系统变量Path下,新加一个值为:F:\env\TensorRT\lib
# Linux:
vim ~/.bashrc
#在最后一行加入, :$PATH代表在原先PATH环境变量基础上添加/home/gy77/TensorRT/lib
export PATH=/home/gy77/TensorRT/lib:$PATH
source ~/.bashrc
下面是正文:
模型推理【linux】
在转换完成后,您既可以使用 Model Converter 进行推理,也可以使用 Inference SDK。前者使用 Python 开发,后者主要使用 C/C++ 开发。
使用 Model Converter 的推理 API
Model Converter 屏蔽了推理后端接口的差异,对其推理 API 进行了统一封装,接口名称为 inference_model。
以上文中 Faster R-CNN 的 TensorRT 模型为例,您可以使用如下方式进行模型推理工作:
创建 inference_api.py 文件,目录结构如下
├── inference_api.py
├── inference_sdk.py
├── mmdetection/
└── mmdeploy/
inference_api.py
from mmdeploy.apis import inference_model
import os
def inf_faster_rcnn_r50():
model_cfg = './mmdetection/configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py'
deploy_cfg = './mmdeploy/configs/mmdet/detection/detection_tensorrt_dynamic-320x320-1344x1344.py'
backend_files = ['./mmdeploy/mmdeploy_models/faster_rcnn/end2end.engine']
img = './mmdetection/demo/demo.jpg'
device = 'cuda:0'
result = inference_model(model_cfg, deploy_cfg, backend_files, img=img, device=device)
print(result)
def inf_yolox():
model_cfg = './mmdetection/configs/yolox/yolox_s_8x8_300e_coco.py'
deploy_cfg = './mmdeploy/configs/mmdet/detection/detection_tensorrt_dynamic-320x320-1344x1344.py'
backend_files = ['./mmdeploy/mmdeploy_models/yolox_s/end2end.engine']
img = './mmdetection/demo/demo.jpg'
device = 'cuda:0'
result = inference_model(model_cfg, deploy_cfg, backend_files, img=img, device=device)
print(result)
if __name__ == '__main__':
# inf_faster_rcnn_r50()
inf_yolox()
inference_model会创建一个对后端模型的封装,通过该封装进行推理。推理的结果会保持与 OpenMMLab 中原模型同样的格式。
MMDeploy 转出的后端模型,您可以直接使用后端 API 进行推理。不过,因为 MMDeploy 拥有 TensorRT、ONNX Runtime 等自定义算子, 您需要先加载对应的自定义算子库,然后再使用后端 API。
使用推理 SDK
您也可以使用 MMDeploy SDK 进行推理。以上文中转出的 Faster R-CNN TensorRT 模型为例,接下来的章节将介绍如何使用 SDK 的 FFI 进行模型推理。
Python
inference_sdk.py
from mmdeploy_python import Detector
import os
import cv2
import time
coco_category = ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant',
'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog',
'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe',
'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat',
'baseball glove', 'skateboard', 'surfboard', 'tennis racket',
'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl',
'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot',
'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop',
'mouse', 'remote', 'keyboard', 'cell phone', 'microwave',
'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock',
'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush']
def inf_model_api(model_path, image_path):
detector = Detector(model_path, 'cuda', 0)
img = cv2.imread(image_path)
model_name = os.path.basename(model_path)
t = time.time()
bboxes, labels, _ = detector([img])[0]
print(f"{model_name} cost time:", time.time() - t)
print(f"{model_name} fps:", 1 / (time.time() - t))
indices = [i for i in range(len(bboxes))]
for index, bbox, label_id in zip(indices, bboxes, labels):
[left, top, right, bottom], score = bbox[0:4].astype(int), bbox[4]
if score < 0.3:
continue
cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0), 2)
cv2.putText(img, coco_category[label_id], (left, top), cv2.FONT_HERSHEY_SIMPLEX, 1.3, (0, 0, 255), 3)
model_name = os.path.basename(model_path)
cv2.imwrite(f'demo_res_trt_{model_name}.png', img)
return bboxes, labels
def inf_faster_rcnn_r50():
model_path = '/home/xbsj/gaoying/mmdeploy/mmdeploy_models/faster_rcnn'
image_path = '/home/xbsj/gaoying/demo.png'
res = inf_model_api(model_path, image_path)
# print(res)
def inf_yolox_s():
model_path = '/home/xbsj/gaoying/mmdeploy/mmdeploy_models/yolox_s'
image_path = '/home/xbsj/gaoying/demo.png'
res = inf_model_api(model_path, image_path)
# print(res)
if __name__ == '__main__':
inf_faster_rcnn_r50()
inf_yolox_s()
# yolox_s cost time: 0.014147043228149414
# yolox_s fps: 70.58859960618658
# faster_rcnn cost time: 0.07103466987609863
# faster_rcnn fps: 14.072153983969509
更多模型的 SDK Python应用样例,请查阅这里。
️ 注解
如果您使用源码安装方式, 请把 ${MMDEPLOY_DIR}/build/lib 加入到环境变量 PYTHONPATH 中。 否则会遇到错误’ModuleNotFoundError: No module named ‘mmdeploy_python’
C API(略)
参考官方文档:操作概述 — mmdeploy 0.6.0 文档
模型推理【windows】
先安装一下windows下的环境,包括
GPU: RTX 2060
Win:10
Cuda driver:
Cuda:11.1
Cudnn:8.2.1
Python:3.7
Pytorch:1.8.0
torchvision:0.9.0
mmdeploy:0.5.0
Tensorrt:8.2.3.0
安装环境
1️⃣ 安装cuda
参考网址:win10+Anaconda+pytorch+CUDA11.1 详细安装指南
cuda11.1下载地址: CUDA Toolkit 11.1.0 | NVIDIA Developer
下载后打开安装,安装的几个步骤截图: 后边没截图的全选下一步就可以了。
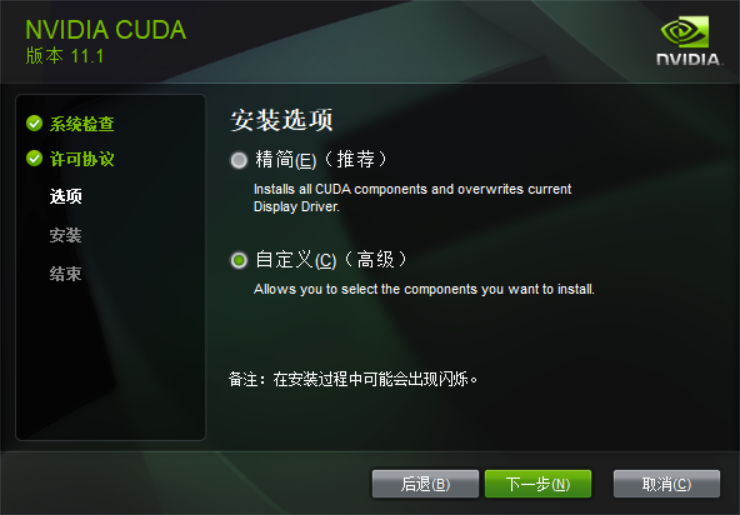 |
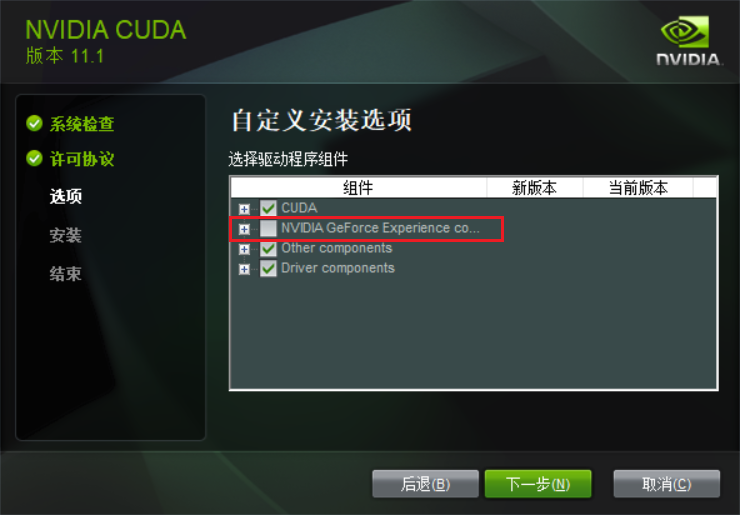 |
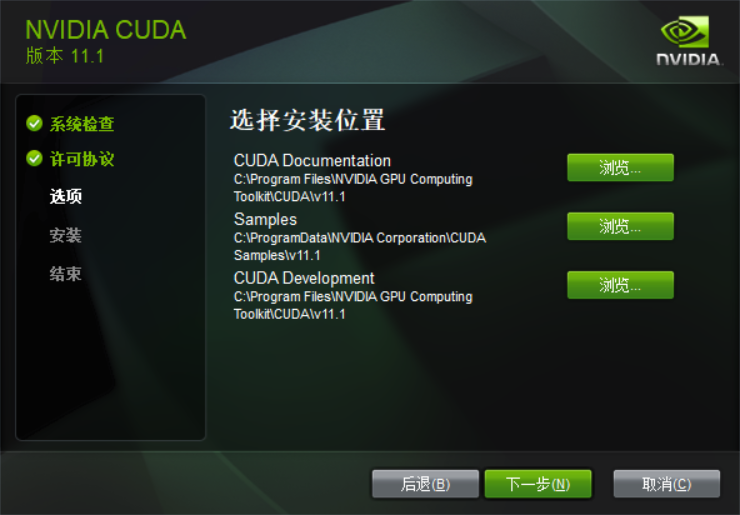 |
|---|
测试是否安装成功:命令行输入nvcc -V,成功结果如下:
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2020 NVIDIA Corporation
Built on Tue_Sep_15_19:12:04_Pacific_Daylight_Time_2020
Cuda compilation tools, release 11.1, V11.1.74
Build cuda_11.1.relgpu_drvr455TC455_06.29069683_0
2️⃣ 安装cudnn
cudnn下载地址:cuDNN Archive | NVIDIA Developer
覆盖cuda目录:分别将cudnn解压后的三个文件夹下的所有内容相对应复制到cuda目录下
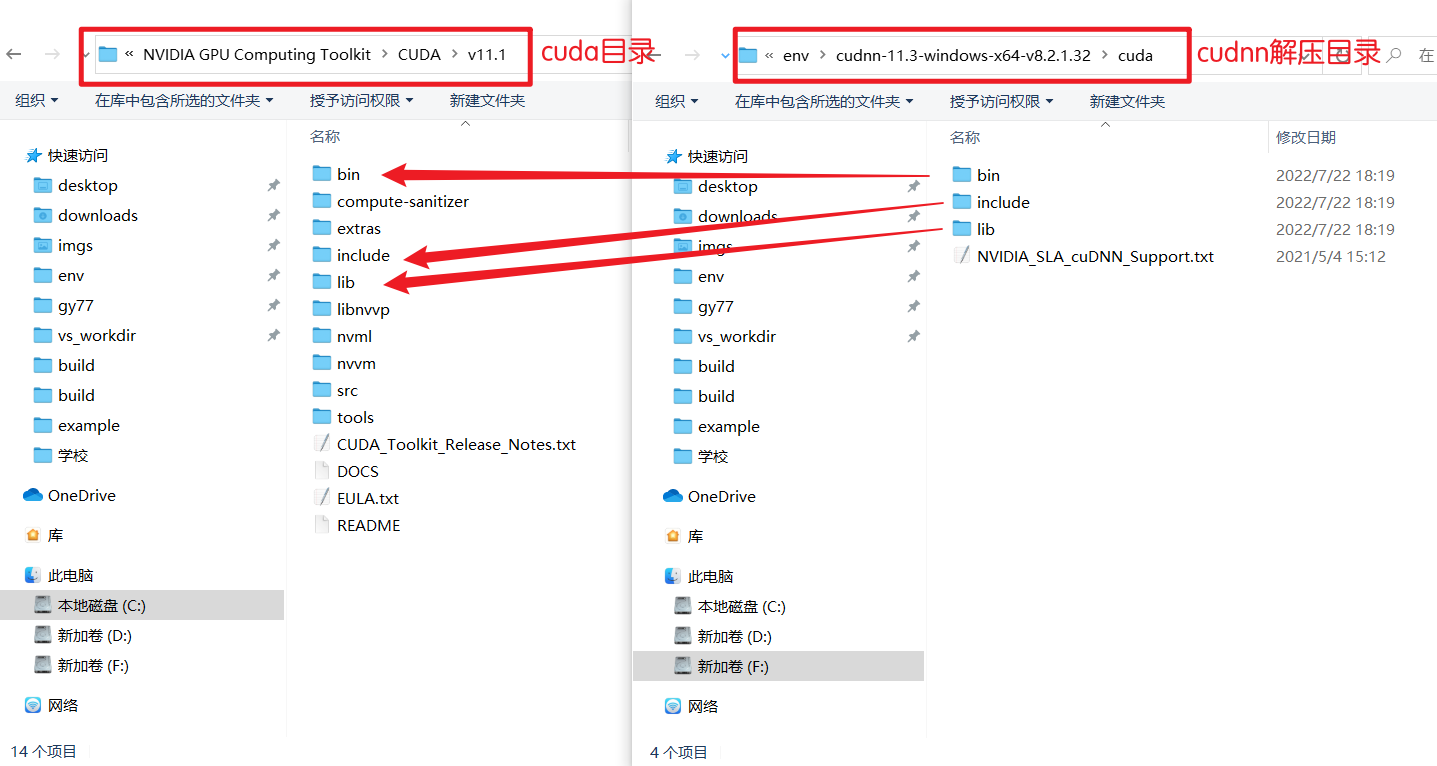
配置系统环境变量:
5个系统变量:
$env:CUDA_SDK_PATH = "C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.1"
$env:CUDA_LIB_PATH = "%CUDA_PATH%\lib\x64"
$env:CUDA_BIN_PATH = "%CUDA_PATH%\bin"
$env:CUDA_SDK_BIN_PATH = "%CUDA_SDK_PATH%\bin\win64"
$env:CUDA_SDK_LIB_PATH = "%CUDA_SDK_PATH%\common\lib\x64"
4个Path系统变量:
$env:Path = "C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.1\common\lib\x64"
$env:Path = "C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\lib\x64"
$env:Path = "C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.1\bin\win64"
$env:Path = "C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\bin"
3️⃣ 安装anaconda
官网下载:Anaconda | The World's Most Popular Data Science Platform
自行安装,记得勾选配置环境变量。
创建conda虚拟环境,进入虚拟环境
conda create -n mmdeploy python=3.7
conda activate mmdeploy
安装pytorch
pip install torch==1.8.0+cu111 torchvision==0.9.0+cu111 torchaudio==0.8.0 -f https://download.pytorch.org/whl/torch_stable.html
4️⃣ 安装 mmcv-full
pip install mmcv-full==1.5.0 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.8.0/index.html
5️⃣ 安装 MMDeploy 和 SDK
从 v0.5.0 之后,MMDeploy 开始提供预编译包。您可以根据目标软硬件平台,从这里选择并下载预编译包。在 NVIDIA 设备上,我们推荐使用 MMDeploy-TensoRT 预编译包:
下载 mmdeploy-0.5.0-windows-amd64-cuda11.1-tensorrt8.2.3.0
解压,用命令行进入到解压目录下:
pip install dist\mmdeploy-0.5.0-py37-none-win_amd64.whl
pip install sdk\python\mmdeploy_python-0.5.0-cp37-none-win_amd64.whl
# 添加环境变量
vim ~/.bashrc
export LD_LIBRARY_PATH=/home/xbsj/gaoying/lib/mmdeploy-0.5.0-linux-x86_64-cuda11.1-tensorrt8.2.3.0/sdk/lib:$LD_LIBRARY_PATH # 改为自己的目录
source ~/.bashrc
cd ..
6️⃣ 安装mmdetction
pip install mmdet
7️⃣ 安装TensorRT
下载地址: NVIDIA TensorRT 8.x Download | NVIDIA Developer
参考网址:windows安装tensorrt - 知乎 (zhihu.com)
下载这个版本:TensorRT-8.2.3.0.Windows10.x86_64.cuda-11.4.cudnn8.2
下载完成后,解压
将 TensorRT-8.2.3.0\include 中所有文件 copy 到 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\include
将 TensorRT-8.2.3.0\lib 中所有.lib文件 copy 到 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\lib\x64
将 TensorRT-8.2.3.0\lib 中所有.dll文件 copy 到 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\bin
进入conda虚拟环境,进入到 TensorRT-8.2.3.0\python\ 目录下:安装tensorrt包
pip install tensorrt-8.2.3.0-cp37-none-win_amd64.whl
使用 Model Converter 的推理 API(略)
参考模型推理Linux
使用推理 SDK(略)
参考模型推理Linux
结果展示:
速度对比
设备:GTX 2060 fp16 image size:1382x1005(image size=640x427 速度差不多):
GPU占用: 2181M
faster_rcnn infer 1000 iter cost time: 71.89654660224915
faster_rcnn infer 1000 iter fps: 13.908873892542662
GPU占用: 1703M
yolox_s infer 1000 iter cost time: 14.963984966278076
yolox_s infer 1000 iter fps: 66.82266306865823
可视化展示:
| 原图 | faster rcnn r50 | yolox s |
|---|---|---|
 |
 |
 |
 |
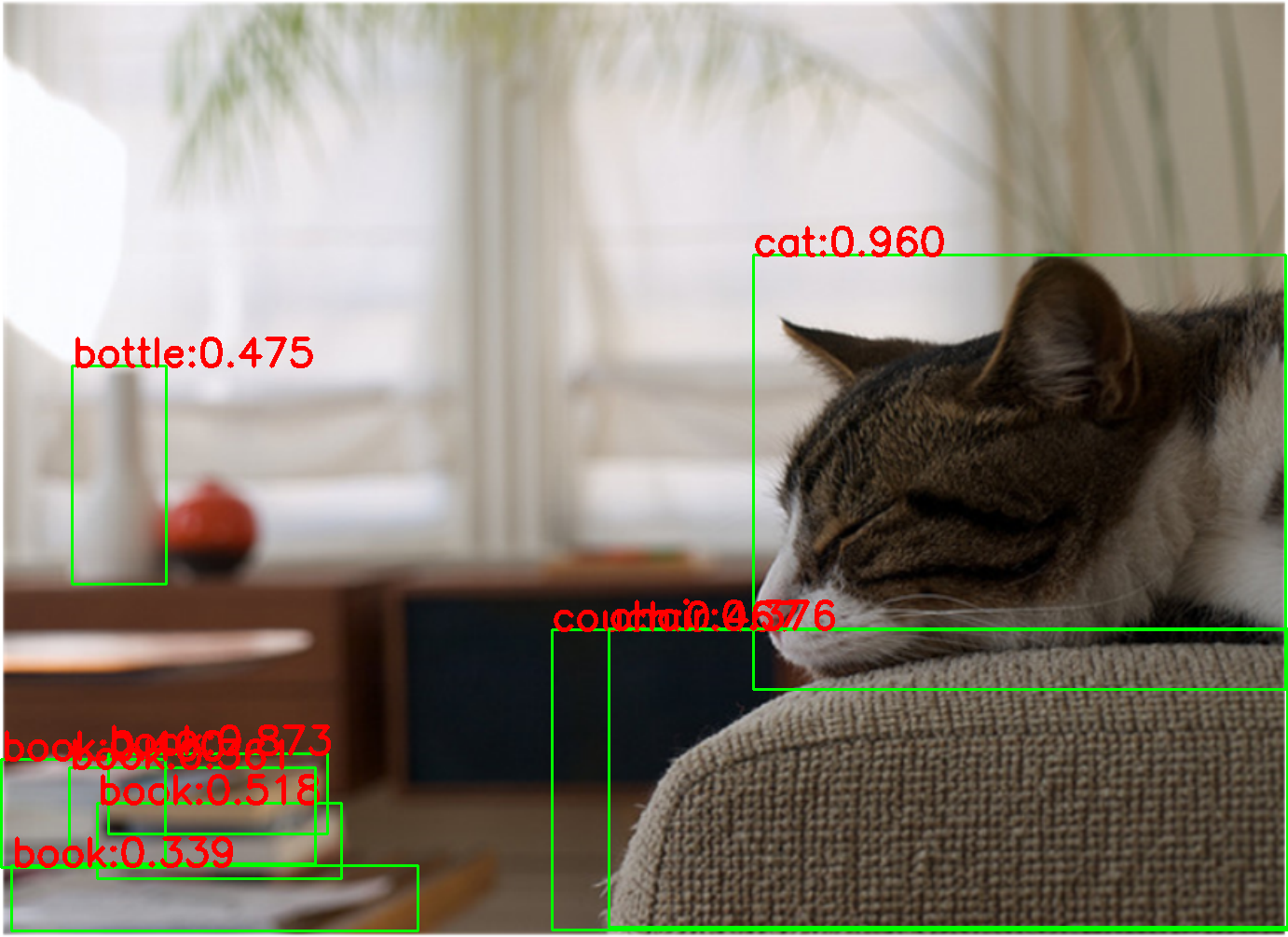 |
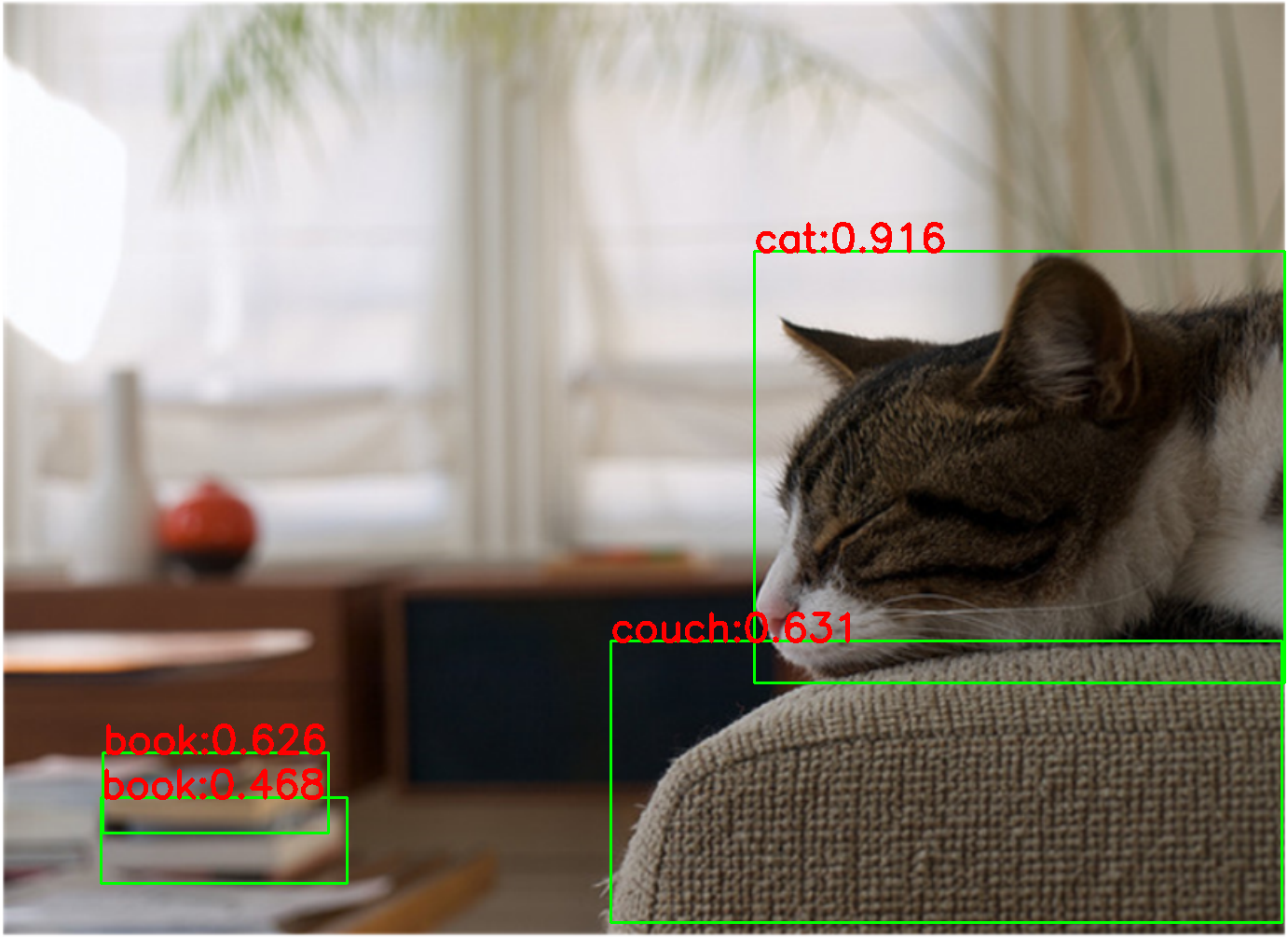 |
MMDeploy部署实战系列【第四章】:onnx,tensorrt模型推理的更多相关文章
- AspNetCore-MVC实战系列(四)之结尾
AspNetCore - MVC实战系列目录 . 爱留图网站诞生 . git源码:https://github.com/shenniubuxing3/LovePicture.Web . AspNetC ...
- Python--Redis实战:第四章:数据安全与性能保障:第7节:非事务型流水线
之前章节首次介绍multi和exec的时候讨论过它们的”事务“性质:被multi和exec包裹的命令在执行时不会被其他客户端打扰.而使用事务的其中一个好处就是底层的客户端会通过使用流水线来提高事务执行 ...
- 基于 abp vNext 和 .NET Core 开发博客项目 - Blazor 实战系列(四)
系列文章 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目 基于 abp vNext 和 .NET Core 开发博客项目 - 给项目瘦身,让它跑起来 ...
- jQuery系列 第四章 jQuery框架的选择器
第四章 jQuery框架的选择器 4.1 jQuery选择器说明 jQuery 最核心的组成部分就是选择器引擎.它完全继承了 CSS 的风格,可以对 DOM 元 素的标签名.属性名.状态等进行快速准确 ...
- MP实战系列(十四)之分页使用
MyBatis Plus的分页,有插件式的,也有其自带了,插件需要配置,说麻烦也不是特别麻烦,不过觉得现有的MyBatis Plus足以解决,就懒得配置插件了. MyBatis Plus的资料不算是太 ...
- 微服务从代码到k8s部署应有尽有系列(四、用户中心)
我们用一个系列来讲解从需求到上线.从代码到k8s部署.从日志到监控等各个方面的微服务完整实践. 整个项目使用了go-zero开发的微服务,基本包含了go-zero以及相关go-zero作者开发的一些中 ...
- 【无私分享:ASP.NET CORE 项目实战(第四章)】Code First 创建数据库和数据表
目录索引 [无私分享:ASP.NET CORE 项目实战]目录索引 简介 本章我们来介绍下Asp.net Core 使用 CodeFirst 创建数据库和表,通过 控制台 和 dotnet ef 两种 ...
- .Net Core 在 Linux-Centos上的部署实战教程(四) ---- 总结
问题: 1.网站部署上访问不了,可能是防火墙/安全组的原因 2.在后台运行这块上 我查了一些类似的部署博客 好多人都是用守护进程搞的,本人也算Linux小白 不懂这样做的好处是啥 有大佬的话 可 ...
- GAN实战笔记——第四章深度卷积生成对抗网络(DCGAN)
深度卷积生成对抗网络(DCGAN) 我们在第3章实现了一个GAN,其生成器和判别器是具有单个隐藏层的简单前馈神经网络.尽管很简单,但GAN的生成器充分训练后得到的手写数字图像的真实性有些还是很具说服力 ...
- [.NET领域驱动设计实战系列]专题四:前期准备之工作单元模式(Unit Of Work)
一.前言 在前一专题中介绍了规约模式的实现,然后在仓储实现中,经常会涉及工作单元模式的实现.然而,在我的网上书店案例中也将引入工作单元模式,所以本专题将详细介绍下该模式,为后面案例的实现做一个铺垫. ...
随机推荐
- vagrant 多个box的操作|共享目录失败
本来机器上已经有一个Ubuntu的box了,今天想在安装一个centos的box,结果还折腾了很长时间. 多个机器的命令 添加box的时候需要使用名称,一个的时候可以忽略名称 vagrant box ...
- weekToDo - 一个本地todo软件 - 软件推荐 先用着试试
https://weektodo.me/ https://github.com/Zuntek/WeekToDoWeb/releases/download/v1.7.0/WeekToDo-Setup-1 ...
- Sub-process /usr/bin/dpkg returned an error code (1)问题
在用apt-get安装软件包的时候遇到E: Sub-process /usr/bin/dpkg returned an error code (1)问题,解决方法如下: cd /var/lib/dpk ...
- 【算法】C和Python实现快速排序-三数中值划分选择主元(非随机)
一.快排基础 1.1 快排的流程 将数组A进行快速排序的基本步骤-quick_sort(A): 递归基础情况:如果A中的元素个数是1或0,则返回. 选取主元:取A中的任意一个元素v,作为主元(pivo ...
- 算法研究之快速排序java版
很早之前就已经接触过快速排序算法了,面试当中也屡屡被问到,虽然明白其原理,但从未真正的用代码敲出来. 写关于算法的代码之前一定要原理想明白,不然就是盲目,在参考有关资料及自己的沉思之后,写出如下代码, ...
- 【VMware vSAN】全新vSAN 8 ESA快速存储架构配置文件服务并创建文件共享。
早在2020年,VMware就发布了vSphere7.vSAN7.VCF4等等产品的更新,当时随着云原生的火热,基于容器技术的现代应用程序快速发展,Docker.Kubernetes这些容器平台被广泛 ...
- Android JNI静态和动态注册 、Java Reflect(C或C++层反射和JAVA层反射)、Java 可变参数(JNI实现)
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文作为本人csdn blog的主站的备份.(Bl ...
- html 本地预览图片 图片上绘制矩形框
效果如图 完整html代码如下 <!DOCTYPE html> <html> <head> <meta charset="UTF-8" / ...
- read IEEE std for verolog(2)
read IEE standard for verilog (2) 1.阅读前言 前面大致地看完了序言,了解了一下verilog的起源以及基本特性.接下来往下读有相关链接和目录,然后是正文.今天暂时阅 ...
- Java获取客户端IP地址进行记录
1.编写工具类IpUtils public class IpUtils { /** * 访问IP:0:0:0:0:0:0:0:1 * 访问IP:192.168.1.10 */ private stat ...