FastDFS 海量小文件存储解决之道
作者:vivo互联网服务器团队-Zhou Changqing
一、FastDFS原理介绍
FastDFS是一个C语言实现的开源轻量级分布式文件系统 。
支持 Linux、FreeBSD、AID 等Unix系统,解决了大容量的文件存储和高并发访问问题,文件存取实现了负载均衡,适合存储 4KB~500MB 之间的小文件,特别适合以文件为载体的在线服务,如图片、视频、文档等等。
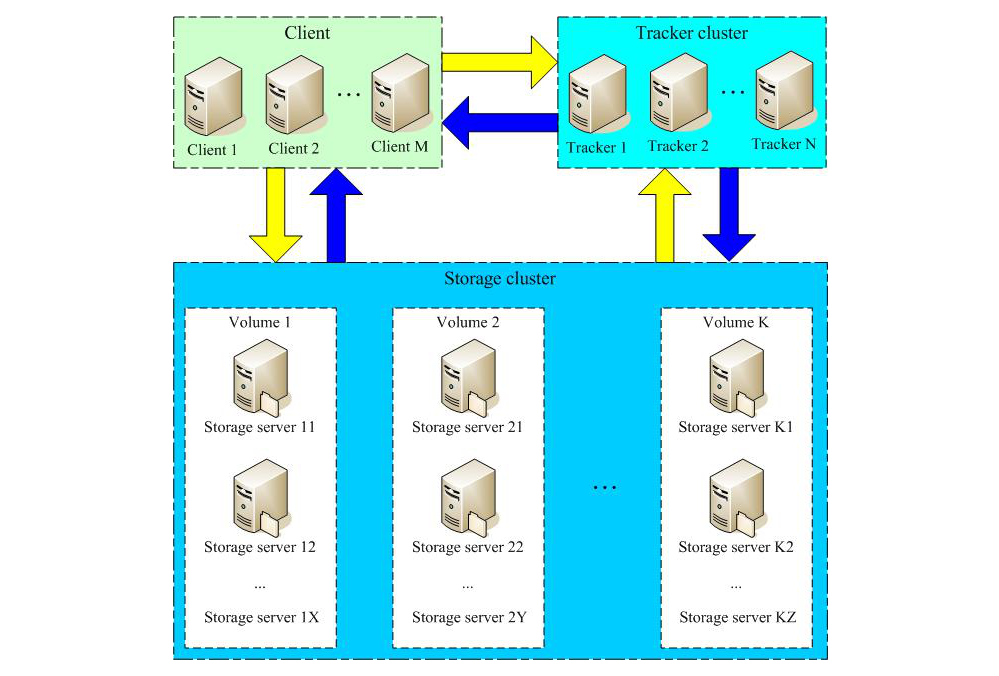
二、FastDFS 架构
FastDFS 由三个部分构成:
客户端(Client)
跟踪服务器(TrackerServer)
存储服务器(StorageServer)
2.1 Tracker Server (跟踪服务器)
Tracker Server (跟踪服务器) 主要是做调度工作,起到负载均衡的作用。
(1)【服务注册】管理StorageServer存储集群,StorageServer启动时,会把自己注册到TrackerServer上,并且定期报告自身状态信息,包括磁盘剩余空间、文件同步状况、文件上传下载次数等统计信息。
(2)【服务发现】Client访问StorageServer之前,必须先访问TrackerServer,动态获取到StorageServer的连接信息,最终数据是和一个可用的StorageServer进行传输。
(3)【负载均衡】
- store group分配策略:
0:轮询方式
1:指定组
2:平衡负载(选择最大剩余空间的组(卷)上传)
- store server分配策略:
0:轮询方式
1:根据 IP 地址进行排序选择第一个服务器( IP 地址最小者)
2:根据优先级进行排序(上传优先级由storage server来设置,参数名为upload_priority)
- stroe path分配 :
0:轮流方式,多个目录依次存放文件
2:选择剩余空间最大的目录存放文件(注意:剩余磁盘空间是动态的,因此存储到的目录或磁盘可能也是变化的)
2.2 Tracker Server (跟踪服务器)
Tracker Server (跟踪服务器) 主要提供容量和备份服务。
【分组管理】以Group为单位,每个Group包含多台Storage Server,数据互为备份,存储容量以Group内容量最小的 storage 为准,已 Group 为单位组织存储方便应用隔离、负载均衡和副本数据定制。
缺点:Group容量受单机存储容量的限制,数据恢复只能依赖Group其他机器重新同步。
【数据同步】文件同步只能在 Group 内的Storage Server之间进行,采用push方式,即源服务器同步给目标服务器。源服务器读取 binlog 文件,将文件内容解析后,按操作命令发送给目标服务器,有目标服务按命令进行操作。
三、上传下载流程
3.1 上传流程解析
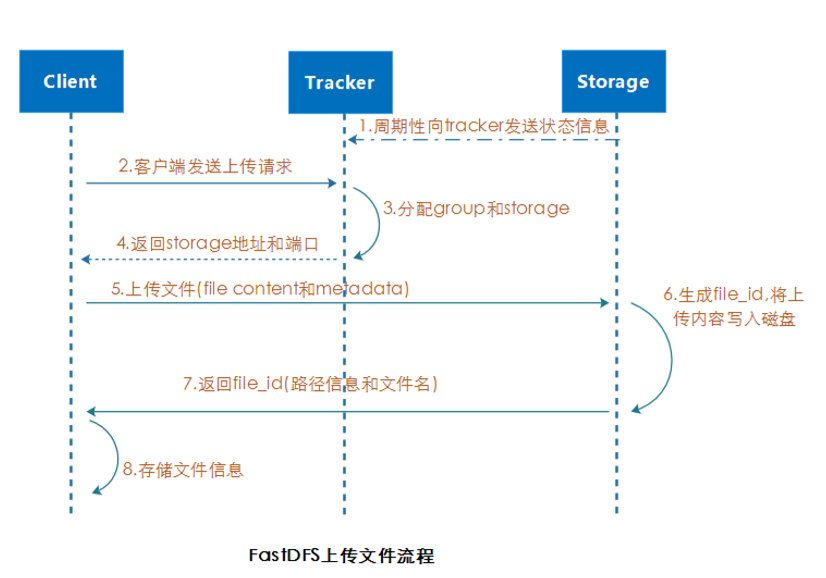
3.1.1 选择Tracker Server
集群中的 tracker 之间都是对等的,客户端在上传文件时可任意选择一个 tracker 即可。
3.1.2 分配Group、Stroage Server 和storage path(磁盘或者挂载点)
tracker 接收到上传请求时会先给该文件分配一个可以存储的 Group ,然后在Group中分配一个Storage Server给客户端,最后在接收到客户端写文件请求时,Storage Server 会分配一个数据存储目录并写入。
(该过程中的分配策略详见:【负载均衡】)
3.1.3 生成file_id写入并返回
Storage 会生成一个 file_id 来作为当前文件名,file_id 采用 base64 编码,包含:源 storage server ip、文件创建时间、文件大小、文件CRC32校验码 和 随机数。每个存储目录下 有两个256*256个子目录。
Storage 会根据 file_id 进行两次 hash 路由到其中一个子目录中。
最后以file_id为文件名存储文件到该子目录下并返回文件路径给客户端。
最终文件存储路径:
**分组 |磁盘|子目录| 文件名 **
group1/M00/00/89/eQ6h3FKJf_PRl8p4AUz4wO8tqaA688.apk
【分组】:文件上传时分配 Group。
【磁盘路径】:存储服务器配置的虚拟路径,对应配置参数 store_path 例如:M00对应store_path0,M01对应store_path1。
【两级目录】:存储服务器在每个虚拟磁盘路径下创建的两级目录,用于存储文件。
3.2 下载流程解析
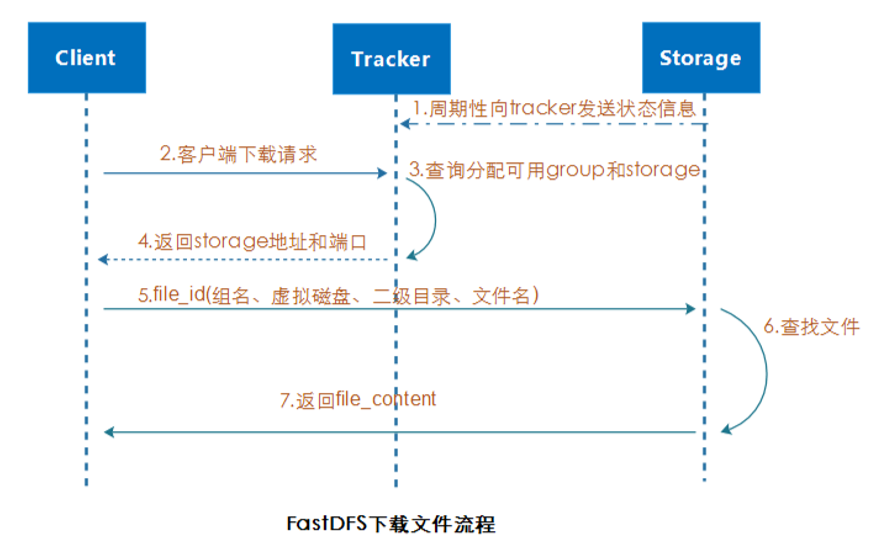
3.2.1 解析路径并路由
tracker 接收 client 发送的下载请求时,tracker 从文件名中解析出 Group、大小、创建时间等信息,然后根据Group 选择一个 storage server 返回。
3.2.2 校验读取并返回
客户端和 Storage Server 建立链接,校验文件是否存在,最终返回文件数据。
缺点:Group之间文件同步是异步进行的,可能上传的文件还未同步到当前访问的 Storage Server 这台机器上或者延迟原因,将导致下载文件出现404。所以引入nginx_fastdfs_module 可以很好的解决同步和延迟问题。
3.3 引入fastdfs_nginx_module组件后的下载架构
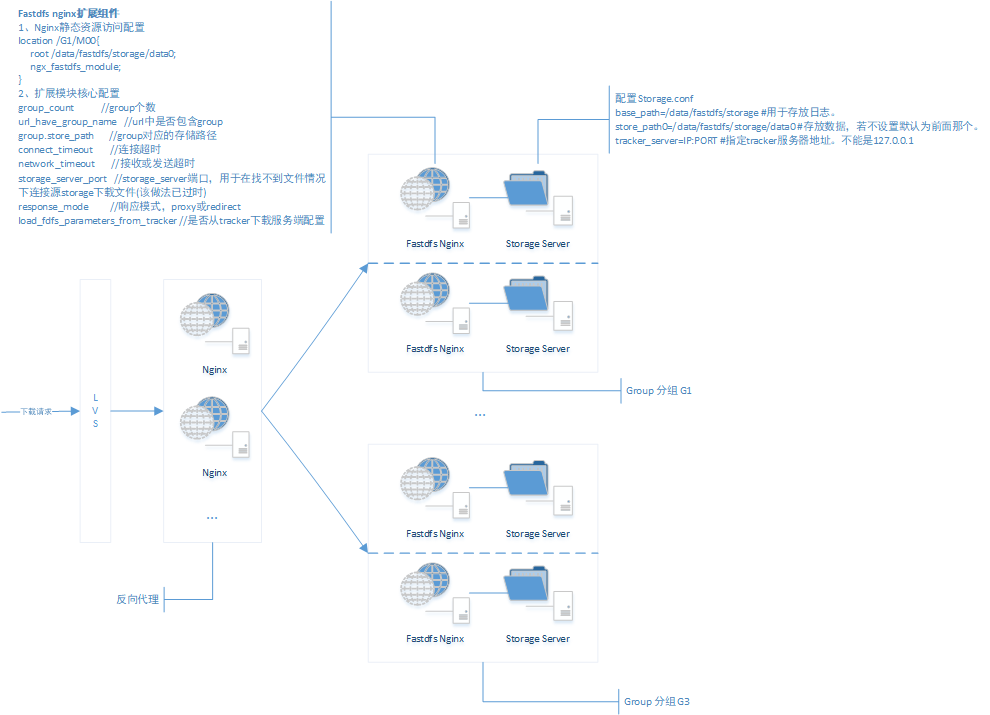
FastDFS Nginx Module功能介绍
(1)【防盗链检查】
利用 FastDFS nginx 扩展功能动态生成token,设置http.conf 配置。
- 开启防盗链功能
http.default_content_type =
application/octet-stream
http.mime_types_filename=mime.types
- 开启token防盗链功能
http.anti_steal.check_token=true
token过期时间
http.anti_steal.token_ttl=900
- 密钥
http.anti_steal.secret_key=xxx
token 过期后返回的内容
http.anti_steal.token_check_fail=/etc/fdfs/anti-steal.jpg
【token 生成算法】:md5(fileid_without_group + privKey + ts) 同时ts没有超过 ttl 范围。
服务器会自动根据token,st 以及设置的秘钥来验证合法性。访问链接形式如:
{kind=link}
(2)【文件元数据解析】
根据 file_id 获取元数据信息, 包括:源storage ip,文件路径,名称,大小 等。
(3)【文件访问路由】
因文件的file_Id 包含了上传文件时的源 Storage Server IP ,所以在获取不到本机下的文件时(未同步或者延迟情况下)FastDFS 扩展组件,会根据源服务器IP 来重定向或者代理方式获取文件。
- 重定向模式
配置项response_mode = redirect,服务器返回302,重定向url
http://源storage ip:port/文件路径?redirect=1
- 代理模式
配置项response_mode = proxy,使用源storage 地址作为代理proxy的host,其他部分不变
四、同步机制
4.1 同步规则
同步只发生在本组的 Storage Server 之间。
源头数据才需要同步,备份数据不需要再次同步。
新增 Storage Server 时,会由已有一台 Storage Server 将已有的所有数据(源头数据和备份数据)同步给新增服务器。
4.2 Binlog 复制
FastDFS 文件同步采用binlog异步复制方式,Storage Server 使用binlog文件记录文件上传、删除等操作,根据Binlog进行文件同步。Binlog中只记录文件ID和操作,不记录文件内容 .binlog 格式如下:
时间戳 | 操作类型 | 文件名
1490251373 C M02/52/CB/CtAqWVjTbm2AIqTkAAACd_nIZ7M797.jpg
操作类型(部分):
C表示源创建、c表示副本创建
A表示源追加、a表示副本追加
D表示源删除、d表示副本删除
. . . . . . .
4.3 同步流程
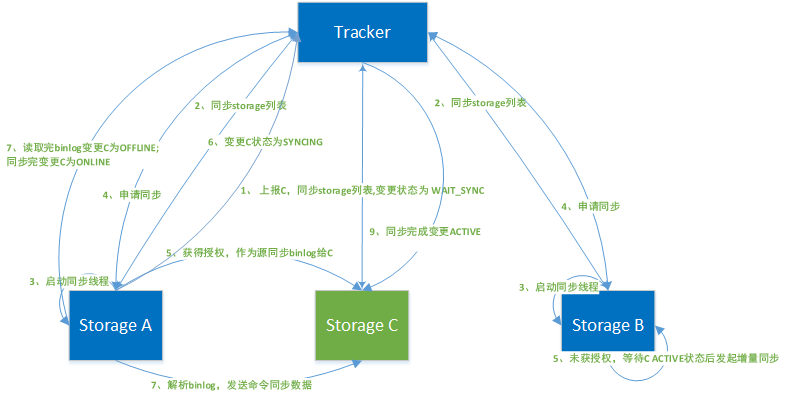
新增 Storage Server 后,组内其他 Storage Server 服务器会启动同步线程,在 tracker的协调下向新增服务器发起全量和增量同步操作。
(1)Storage C启动后向tracker 上报所属group、ip、port、版本号、存储目录数、子目录数、启动时间、老数据是否同步完成,当前状态等信息。
(2)tracker 收到Storage C 加入申请请求后,更新本地storage list,返回给C,并适时同步给A、B。
(3)storage C向tracker 申请同步请求,响应后变更自身状态为WAIT_SYNC。
(4)storage A 和B 在心跳周期内从同步到的新storage list 发现没有C,则启动同步线程,先向tracker发起同步申请(TRACKER_PROTO_CMD_STORAGE_SYNC_SRC_REQ),tracker会把同步源IP级同步时间戳返回给A和B,如果源IP和自己本地IP一致,则标记自己作为同步源用来做老数据同步(全量同步源),如果不一致,则标记自己作为增量同步源(只有在C节点状态为Active时才同步)。该决策是由tracker 选择产生的,不可A、B同时作为同步源,同时同步给C。
(5)同步源(假设是storage A)以 .mark为后缀的文件记录目标机器同步信息,并上报变更storage C状态为SYNCING。
(6)从/data.sync目录下读取binlog.index 中的,binlog文件Id,binlog.000读取逐行读取,进行解析.(详见上面binlog 内格式) 发送数据给storage C ,C接收并保存。
(7)数据同步过程中 storage C 的状态变更过程OFFLINE->ONLINE->ACTIVE。ACTIVE 是最终状态,表示storage C 已对外提供服务。
五、文件存储
5.1 LOSF问题
小文件存储(LOSF)面临的问题:
本地文件系统innode梳理优先,存储小文件数量受限。
目录层级和目录中文件数量会导致访问文件开销很大(IO次数多)。
小文件存储,备份和恢复效率低。
针对小文件存储问题,FastDFS 提供了文件合并解决方案。FastDFS 默认创建大文件为 64M,大文件可以存储很多小文件,容纳一个小文件的空间叫slot,solt 最小256字节,最大16M。小于256字节当256字节存储,超过16M文件单独存储。
5.2 存储方式
(1)【默认存储方式】未开启合并 ,FastDFS生成的file_id 和磁盘上实际存储的文件一一对应。
(2)【合并存储方式】多个file_id对应文件被存储成了一个大文件 。trunk文件名格式:/fastdfs/data/00/000001 文件名从1开始递增。而生成的file_id 更长,会新增16个字节额外内容用来保存偏移量等信息。
如下:
【file_size】:占用大文件的空间(注意按照最小slot-256字节进行对齐)
【mtime】:文件修改时间
【crc32】:文件内容的crc32码
【formatted_ext_name】:文件扩展名
【alloc_size】:文件大小与size相等
【id】:大文件ID如000001
【offset】:文件内容在trunk文件中的偏移量
【size】:文件大小。
5.3 存储空间管理
(1)【Trunk Server】由tracker leader 在一组Storage Server 选择出来的,并通知给该组内所有Storage Server,负责为该组内所有upload操作分配空间。
(2)【空闲平衡树】trunk server 会为每个store_path构造一个空闲平衡树,相同大小的空闲块保存在链表中,每次上传请求时会到根据上传的文件大小到平衡树中查找获取大于或者接近的空闲块,然后从空闲块中分割出多余的作为新的空闲块,重新加入平衡树。如果找不到则会重建一个新的trunk文件,并加入到平衡树中。该分配过程即是一个维护空闲平衡树的过程。
(3)【Trunk Binlog】开启了合并存储后,Trunk Server 会多出一个TrunkBinlog同步。TrunkBinlog记录了TrunkServer 所有分配与回收的空闲块操作,并由Trunk Server同步给同组中其他storage server。
TrunkBinlog格式如下:
时间戳 | 操作类型 | store_path_index | sub_path_high| sub_path_low | file.id| offset | size 1410750754 A 0 0 0 1 0 67108864
各字段含义如下:
【file.id】:TrunkFile文件名,比如 000001
【offset】:在TrunkFile文件中的偏移量
【size】:占用的大小,按照slot对齐
六、文件去重
FastDFS不具备文件去重能力,必须引入FastDHT 来配合完成。FastDHT 是一个键值对的高效分布式hash系统,底层采用Berkeley DB 来做数据库持久化,同步方式使用binlog复制方式。在FastDFS去重场景中,对文件内容做hash,然后判断文件是否一致。
在文件上传成功后,查看 Storage存储对应存储路径,会发现返回的是一个软链接,之后每次重复上传都是返回一个指向第一次上传的文件的软链接。也就保证了文件只保存了一份。
(注意:FastDFS不会返回原始文件的索引,返回的全部都是软链接,当所有的软链接都被删除的时候,原始文件也会从FastDFS中被删除)。
七、总结
FastDFS 真正意义上只是一个管理文件的系统(应用级文件系统),比如管理上传文件、图片等。并不像系统磁盘文件系统NTFS或者FAT 等这种系统级文件系统。
FastDFS 海量小文件存储解决之道的更多相关文章
- 海量小文件存储与Ceph实践
海量小文件存储(简称LOSF,lots of small files)出现后,就一直是业界的难题,众多博文(如[1])对此问题进行了阐述与分析,许多互联网公司也针对自己的具体场景研发了自己的存储方案( ...
- LOSF海量小文件问题解决思路及开源库
"+++++++++++++++ LOSF 海量小文件存储和优化方案 +++++++++++++++++++++++++++++++++++++++++++++"一.问题产生原因以 ...
- 百亿级小文件存储,JuiceFS 在自动驾驶行业的最佳实践
自动驾驶是最近几年的热门领域,专注于自动驾驶技术的创业公司.新造车企业.传统车厂都在这个领域投入了大量的资源,推动着 L4.L5 级别自动驾驶体验能尽早进入我们的日常生活. 自动驾驶技术实现的核心环节 ...
- Hadoop对小文件的解决方式
小文件指的是那些size比HDFS的block size(默认64M)小的多的文件.不论什么一个文件,文件夹和block,在HDFS中都会被表示为一个object存储在namenode的内存中, 每一 ...
- Hadoop小文件存储方案
原文地址:https://www.cnblogs.com/ballwql/p/8944025.html HDFS总体架构 在介绍文件存储方案之前,我觉得有必要先介绍下关于HDFS存储架构方面的一些知识 ...
- 大数据学习——有两个海量日志文件存储在hdfs
有两个海量日志文件存储在hdfs上, 其中登陆日志格式:user,ip,time,oper(枚举值:1为上线,2为下线):访问之日格式为:ip,time,url,假设登陆日志中上下线信息完整,切同一上 ...
- Java小对象的解决之道——对象池(Object Pool)的设计与应用
一.概述 面向对象编程是软件开发中的一项利器,现已经成为大多数编程人员的编程思路.很多高级计算机语言也对这种编程模式提供了很好的支持,例如C++.Object Pascal.Java等.曾经有大量的软 ...
- 转:wcf大文件传输解决之道(2)
此篇文章主要是基于http协议应用于大文件传输中的应用,现在我们先解析下wcf中编码器的定义,编码器实现了类的编码,并负责将Message内存中消息转变为网络发送的字节流或者字节缓冲区(对于发送方而言 ...
- 转:wcf大文件传输解决之道(1)
首先声明,文章思路源于MSDN中徐长龙老师的课程整理,加上自己的一些心得体会,先总结如下: 在应对与大文件传输的情况下,因为wcf默认采用的是缓存加载对象,也就是说将文件包一次性接受至缓存中,然后生成 ...
- 如何利用Hadoop存储小文件
**************************************************************************************************** ...
随机推荐
- DataGridView合并单元格,重绘后选中内容被覆盖的解决办法
DataGridView合并单元格只能进行重绘,网上基本上使用的是下面的方法: 1 /// <summary> 2 /// 说明:纵向合并单元格 3 /// 参数:dgv DataGrid ...
- Python给exe添加以管理员运行的属性
需求 有些应用每次启动都需要用管理员权限运行,比如Python注入dll时,编辑器或cmd就需要以管理员权限运行,不然注入就会失败. 这篇文章用编程怎么修改配置实现打开某个软件都是使用管理员运行,就不 ...
- 神经网络优化篇:为什么正则化有利于预防过拟合呢?(Why regularization reduces overfitting?)
为什么正则化有利于预防过拟合呢? 通过两个例子来直观体会一下. 左图是高偏差,右图是高方差,中间是Just Right. 现在来看下这个庞大的深度拟合神经网络.知道这张图不够大,深度也不够,但可以想象 ...
- Java中“100==100”为true,而"1000==1000"为false?
前言 今天跟大家聊一个有趣的话题,在Java中两个Integer对象做比较时,会产生意想不到的结果. 例如: Integer a = 100; Integer b = 100; System.out. ...
- 数字孪生系统为何需要将GIS系统进行融合?
数字孪生是一种通过数字模型实时仿真现实世界的技术,而GIS(地理信息系统)则是用于收集.存储.处理和展示地理数据的工具.将数字孪生系统与GIS系统进行融合,可以为各行业带来诸多优势和创新.那么数字孪生 ...
- Confluence OGNL表达式注入命令执行漏洞(CVE-2022-26134)
Confluence OGNL表达式注入命令执行漏洞(CVE-2022-26134) 简介 Atlassian Confluence是企业广泛使用的wiki系统.2022年6月2日Atlassian官 ...
- 1.elasticsearch运行
在docker中运行elasticsearch.kibana 一.MacOs 首先需要安装doceker,提供两种方式,选一种方便的就好 1.命令行安装方式 安装命令行 xcode-select -- ...
- Pikachu漏洞靶场 XXE(xml外部实体注入漏洞)
XXE(xml外部实体注入漏洞) 概述 XXE -"xml external entity injection" 既"xml外部实体注入漏洞". 概括一下就是& ...
- Pikachu漏洞靶场 Sql Inject(SQL注入)
SQLi 哦,SQL注入漏洞,可怕的漏洞. 文章目录 SQLi 数字型注入(post) 字符型注入(get) 搜索型注入 xx型注入 "insert/update"注入 inser ...
- Http 编码格式简介
Http 格式简介 Http 是用于在客户端和服务端之间进行通信的一种消息格式,一般由以下几个部分组成: 起始行:这部分在 Http 响应中也被称为状态行,针对不同的 Http 类型,其中包含的内容也 ...