使用Golang的协程竟然变慢了|100万个协程的归并排序耗时分析
前言
这篇文章将用三个版本的归并排序,为大家分析使用协程排序的时间开销(被排序的切片长度由128到1000w)
本期demo地址:https://github.com/BaiZe1998/go-learning
往期视频讲解 :B站:白泽talk,公众号:白泽talk

认为并发总是更快
- 线程:OS 调度的基本单位,用于调度到 CPU 上执行,线程的切换是一个高昂的操作,因为要求将当前 CPU 中运行态的线程上下文保存,切换到可执行态,同时调度一个可执行态的线程到 CPU 中执行。
- 协程:线程由 OS 上下文切换 CPU 内核,而 Goroutine 则由 Go 运行时上下文切换协程。Go 协程占用内存比线程少(2KB/2MB),协程的上下文切换比线程快80~90%。
GMP 模型:
- G:Goroutine
- 执行态:被调度到 M 上执行
- 可执行态:等待被调度
- 等待态:因为一些原因被阻塞
- M:OS thread
- P:CPU core
- 每个 P 有一个本地 G 队列(任务队列)
- 所有 P 有一个公共 G 队列(任务队列)
协程调度规则:每一个 OS 线程(M)被调度到 P 上执行,然后每一个 G 运行在 M 上。
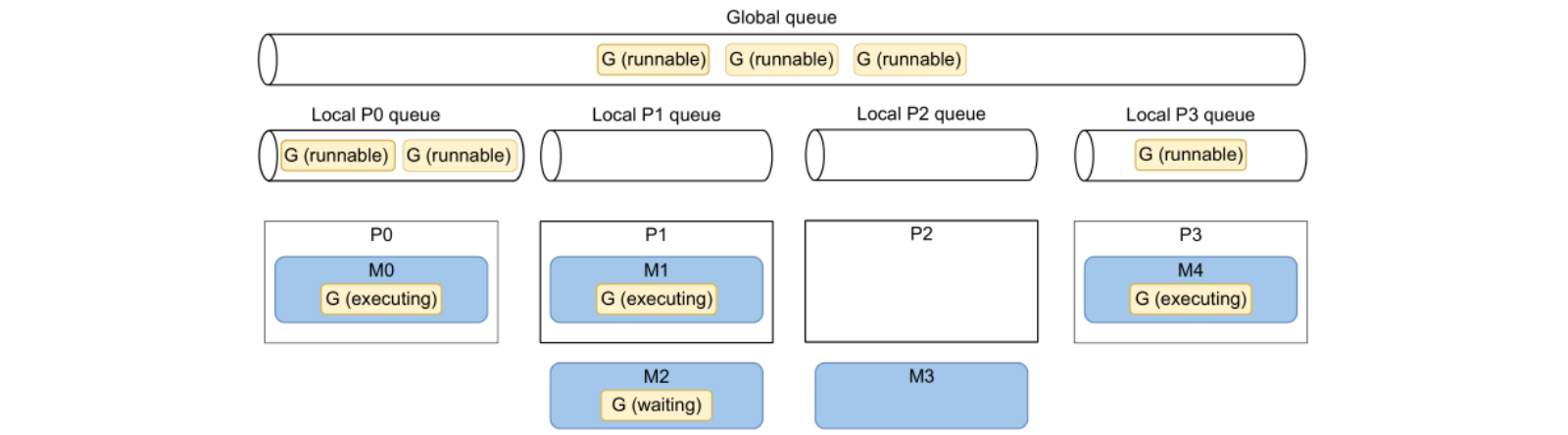
上图中展示了一个4核 CPU 的机器调度 Go 协程的场景:
此时 P2 正在闲置因为 M3 执行完毕释放了对 P2 的占用,虽然 P2 的 Local queue 中已经空了,没有 G 可以调度执行,但是每隔一定时间,Go runtime 会去 Global queue 和其他 P 的 local queue 偷取一些 G 用于调度执行(当前存在6个可执行的G)。
特别的,在 Go1.14 之前,Go 协程的调度是合作形式的,因此 Go 协程发生切换的只会因为阻塞等待(IO/channel/mutex等),但 Go1.14 之后,运行时间超过 10ms 的协程会被标记为可抢占,可以被其他协程抢占 P 的执行。
归并案例
为了印证有时候多协程并不一定会提高性能,这里以归并排序为例举三个例子:
主函数:
func main() {
size := []int{128, 512, 1024, 2048, 100000, 1000000, 10000000}
sortVersion := []struct {
name string
sort func([]int)
}{
{"Mergesort V1", SequentialMergesortV1},
{"Mergesort V2", SequentialMergesortV2},
{"Mergesort V3", SequentialMergesortV3},
}
for _, s := range size {
fmt.Printf("Testing Size: %d\n", s)
o := GenerateSlice(s)
for _, v := range sortVersion {
s := make([]int, len(o))
copy(s, o)
start := time.Now()
v.sort(s)
elapsed := time.Since(start)
fmt.Printf("%s: %s\n", v.name, elapsed)
}
fmt.Println()
}
}
v1的实现:
func sequentialMergesort(s []int) {
if len(s) <= 1 {
return
}
middle := len(s) / 2
sequentialMergesort(s[:middle])
sequentialMergesort(s[middle:])
merge(s, middle)
}
func merge(s []int, middle int) {
// ...
}
v2的实现:
func SequentialMergesortV2(s []int) {
if len(s) <= 1 {
return
}
middle := len(s) / 2
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
SequentialMergesortV2(s[:middle])
}()
go func() {
defer wg.Done()
SequentialMergesortV2(s[middle:])
}()
wg.Wait()
Merge(s, middle)
}
v3的实现:
const max = 2048
func SequentialMergesortV3(s []int) {
if len(s) <= 1 {
return
}
if len(s) < max {
SequentialMergesortV1(s)
} else {
middle := len(s) / 2
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
SequentialMergesortV3(s[:middle])
}()
go func() {
defer wg.Done()
SequentialMergesortV3(s[middle:])
}()
wg.Wait()
Merge(s, middle)
}
}
耗时对比:
Testing Size: 128
Mergesort V1: 10.583µs
Mergesort V2: 211.25µs
Mergesort V3: 7.5µs
Testing Size: 512
Mergesort V1: 34.208µs
Mergesort V2: 500.666µs
Mergesort V3: 60.291µs
Testing Size: 1024
Mergesort V1: 48.666µs
Mergesort V2: 643.583µs
Mergesort V3: 47.084µs
Testing Size: 2048
Mergesort V1: 94.666µs
Mergesort V2: 786.125µs
Mergesort V3: 77.667µs
Testing Size: 100000
Mergesort V1: 6.810917ms
Mergesort V2: 58.148291ms
Mergesort V3: 4.219375ms
Testing Size: 1000000
Mergesort V1: 62.053875ms
Mergesort V2: 558.586458ms
Mergesort V3: 37.99375ms
Testing Size: 10000000
Mergesort V1: 632.3875ms
Mergesort V2: 5.764997041s
Mergesort V3: 388.343584ms
由于创建协程和调度协程本身也有开销,第二种情况无论多少个元素都使用协程去进行并行排序,导致归并很少的元素也需要创建协程和调度,开销比排序更多,导致性能还比不上第一种顺序归并。
特别在切片长度为1000w的时候,基于v2创建的协程数量共计百万。
而在本台电脑上,经过调试第三种方式可以获得比第一种方式更优的性能,因为它在元素大于2048个的时候,选择并行排序,而少于则使用顺序排序。但是2048是一个魔法数,不同电脑上可能不同。这里这是为了证明,完全依赖并发/并行的机制,并不一定会提高性能,需要注意协程本身的开销。
小结
可以克隆项目之后,使用协程池写一个归并排序,进一步比较内存消耗。
使用Golang的协程竟然变慢了|100万个协程的归并排序耗时分析的更多相关文章
- Stackful 协程库 libgo(单机100万协程)
libgo 是一个使用 C++ 编写的协作式调度的stackful协程库, 同时也是一个强大的并行编程库. 设计之初是为高并发分布式Linux服务端程序开发提供底层框架支持,可以让链接进程序的同步的第 ...
- 在C++中使用golang的协程
开源项目cpp_features提供了一个仿golang协程的stackful协程库. 可以在c++中使用golang的协程,大概语法是这样的: #include <iostream> v ...
- asyncio异步模块的21个协程编写实例
启动一个无返回值协程 通过async关键字定义一个协程 import sys import asyncio async def coroutine(): print('运行协程') if sys.ve ...
- Golang 之协程详解
转自:https://www.cnblogs.com/liang1101/p/7285955.html 一.Golang 线程和协程的区别 备注:需要区分进程.线程(内核级线程).协程(用户级线程)三 ...
- GoLang之协程
GoLang之协程 目前,WebServer几种主流的并发模型: 多线程,每个线程一次处理一个请求,在当前请求处理完成之前不会接收其它请求:但在高并发环境下,多线程的开销比较大: 基于回调的异步IO, ...
- Golang 的 协程调度机制 与 GOMAXPROCS 性能调优
作者:林冠宏 / 指尖下的幽灵 掘金:https://juejin.im/user/587f0dfe128fe100570ce2d8 博客:http://www.cnblogs.com/linguan ...
- 『GoLang』协程与通道
作为一门 21 世纪的语言,Go 原生支持应用之间的通信(网络,客户端和服务端,分布式计算)和程序的并发.程序可以在不同的处理器和计算机上同时执行不同的代码段.Go 语言为构建并发程序的基本代码块是 ...
- GoLang 的协程调度和 GMP 模型
GoLang 的协程调度和 GMP 模型 GoLang 是怎么启动的 关于 GoLang 的汇编语言,请查阅 参考文献[1] 和 参考文献[2] 编写一个简单的 GoLang 程序 main.go, ...
- Goroutine并发调度模型深度解析之手撸一个协程池
golanggoroutine协程池Groutine Pool高并发 并发(并行),一直以来都是一个编程语言里的核心主题之一,也是被开发者关注最多的话题:Go语言作为一个出道以来就自带 『高并发』光环 ...
- 实现一个协程版mysql连接池
实现一个协程版的mysql连接池,该连接池支持自动创建最小连接数,自动检测mysql健康:基于swoole的chanel. 最近事情忙,心态也有点不积极.技术倒是没有落下,只是越来越不想写博客了.想到 ...
随机推荐
- “古剑山”初赛Misc 幸运饼干
"古剑山"初赛Misc 幸运饼干 考点:Chrome的Cookies解密 赛中思路 bandzip极限压缩hint.jpg后打明文攻击 压缩包密码:sv@1v3z ┌──(root ...
- 记录荒废了三年的四年.net开发的第一次面试
对象 身在成都小微企业,前两天面试深圳老牌金蝶公司.对我这个荒废了三年光影的人来说,怎一个跨度之大了得?作为人我生第一次面试的,整个面试过程,只能用诡异来形容这次感受.而结尾也是迷迷糊糊中草草收场. ...
- Docker开始收费了,开始转学podman【第一篇podman容器的安装和基本操作】
podman 什么是Podman?Podman是无守护程序容器引擎,用于在Linux系统上开发,管理和运行OCI容器.容器可以以root用户或无根模式运行.简而言之:`alias docker = p ...
- 数据仓库建模工具之一——Hive学习第二天
Hive的概述 1.Hive基本概念 1.1 Hive简介 Hive本质是将SQL转换为MapReduce的任务进行运算,底层由HDFS来提供数据存储,说白了hive可以理解为一个将SQL转换为Map ...
- [oeasy]python0135_变量名与下划线_dunder_声明与赋值
变量定义 回忆上次内容 变量 就是 能变的量 上次研究了 变量标识符的 规则 第一个字符 应该是 字母或下划线 合法的标识符可以包括 大小写字母 数字 下划线 还研究了字符串(str)的函数 ...
- oeasy教您玩转vim - 21 - 状态横条
状态横条 回忆上节课内容 我们上次研究了标尺 标尺 开启 se ru 关闭 se noru 行号 开启 se nu 关闭 se nonu 命令位置 开启 se showcmd 关闭 se noshow ...
- MySQL预处理语句PREPARE、EXECUTE、DEALLOCATE使用大全
说明 MySQL官方将PREPARE.EXECUTE.DEALLOCATE统称为PREPARE STATEMENT,我习惯称其为[预处理语句]. 其语法为: PREPARE stmt_name FRO ...
- 从菜鸟到大牛!嵌入式完整学习路线:STM32单片机-RTOS-Linux(文末领取开发板全套资料)
嵌入式系统是许多现代电子设备和智能系统的核心,掌握嵌入式系统,意味着能够设计和开发更加智能化的产品.本文为所有想进入嵌入式领域的初学者提供一个完整系统学习的路线图,按照 "STM32单片 ...
- hbuilder打包的应用上架appstore屏幕快照的生成方法
当我们使用hbuiderX或apicloud这些打包工具进行打包的时候,我们需要将打包好的ipa文件进行上架,但是你会发现,我们上架的时候需要上传5.5寸的iphone.6.5寸的iphone X和两 ...
- Linux环境 yum,apt-get,rpm,wget 区别
Linux环境 yum,apt-get,rpm,wget 区别 一般来说linux系统基本上分两大类:cat /etc/issue查看linux系统版本RedHat系列:Redhat.Centos.F ...