深度学习模型训练的过程理解(训练集、验证集、测试集、batch、iteration、epoch、单步预测、多步预测、kernels、学习率)
呜呜呜呜,感谢大佬学弟给我讲干货.
本来是讨论项目的,后面就跑偏讲论文模型了.
解答了我一直以来的疑问:
数据放模型里训练的过程.
假设我们有一个数据集26304条数据,假设设置模型读入1000条,如果不设置,就是把数据集里的26304条数据全都读进去。
parser.add_argument("--n-rows", default=10000, help="number of rows for experiments", type=int)
就是这一条代码,超参数里面,如果有这个就是设置读多少条数据。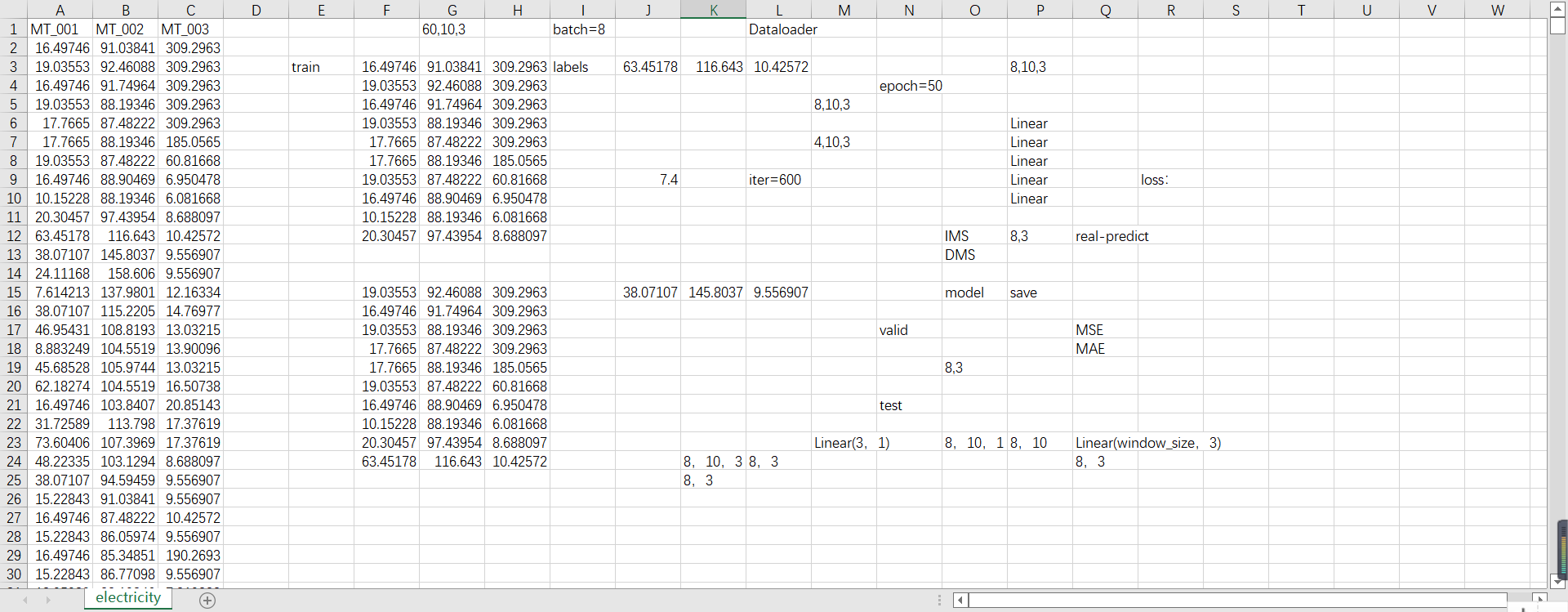
举例这个数据集,这个数据集里有3个特征,MT_001、MT_002、MT_003这3个特征,假设我们读1000条数据。
按照训练集/验证集/测试集=6/2/2来划分。
那么我们训练的就是600条数据。
现在假设是单步预测,以10步预测1步,就是10条预测1条。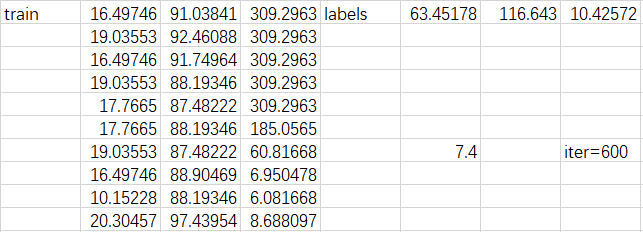
那么就是这样算一坨,就是数据集里的2-11行是train,第12行是标签labels。
就是这样,整个训练集就可以划分成60个这种东西,就是60坨,每一坨里面是10个train和1个labels,训练的时候就是用这10个train来训练,努力得到这1个labels。
所以现在的数据的样子就是(60,10,3)就是60块,每一块里面是10条,每一条里面是3个特征。OK
接下来就是batch的理解。
如果batch不设置,模型就是把这60坨(块)都一次性读进去然后整体跑一遍之后再得出训练的梯度之类的东西,
如果设置batch=8,那么就是我们的模型每次就只放8坨(块)读进去,然后整体跑一遍,然后再把下一个8坨读进去整体跑一遍,然后一直跑7遍,最后发现60/8只能跑7次还多出来4个,所以最后这4坨再读进去跑一遍。这就是batch的作用。就是前7次读进去的都是(8,10,3),最后1次读进去的是(4,10,3)。
batch size是每批样本的大小,即每次训练在训练集中取batch_size个样本进行训练。在这里就是10。
接下来是itera的理解。
1个iteration等于使用batch size个样本训练一次。一个迭代=一个正向通过+一个反向通过。训练一个batch就是一次iteration。就是8坨放进去跑1次就是1个iteration。
iteration=数据集大小/batch_size,在这里就是600/10=60个。
接下来是epoch的理解。
epoch就相当于在batch外面再设置一个循环,相当于跑7.4之后算一个epoch,如果我们epoch=50,那就是每一次都是7次10+1次4跑1次,这算1个epoch,然后一直循环跑50次,
1个epoch等于使用训练集中的全部样本训练一次,所有训练样本在神经网络中都进行了一次正向传播和一次反向传播。(在这里全部样本就是600条)
举个例子就是两个for循环:
for epoch=50{
for batch=8{
600条数据分为10条一坨;
}
}
接下来是放到训练模型里运行的过程。
假设我们训练模型是有5层Linear
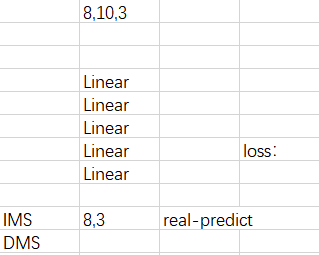
那就是(8,10,3)这样的数据形状放进去跑过这5个Linear层,这算一次,然后就是这样一直循环,epoch=50里面batch=8然后再里面是每一个batch跑5层Linear。
那么是怎么逐步优化训练的呢?就是通过loss,我们的数据(8,10,3)放进去训练学习后,通过一系列矩阵变换,最后把矩阵压扁之后就得到(8,3)得到的这个(8,3)是predict的,再和labels的实际的那个3做处理,用实际的labels-predict然后再除数量(这个就是loss函数的公式)然后得到loss值,然后梯度再返回去这种逐渐调整优化的过程。
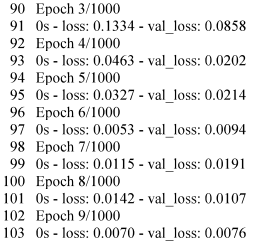
用这个运行结果举例,每一次epoch都会有一个loss值,我们就是看这个loss值,如果loss值一直是减小下降的,那就说明结果越来越好,如果是先下降再上升,比如从0.5降到0.1,然后又从0.1升到了0.3,那就说明局部震荡,这个时候就要去调整超参数或者是优化模型结构。
接下来是IMS和DMS的理解。
IMS 机制主要是训练一个单步预测模型,迭代的将模型产生的预测数据作为模型的输入再读进去,DMS是只用数据集的数据作为输入。
然后就是单步预测和多步预测。
单步预测就是train10条,labels1条。
多步预测就是train10条,labels多条,如果是10步预测3步,那labels就是3条。
接下来就是验证集和测试集的理解。

我们的验证集是200条,测试集也是200条。
我们训练以后的模型之后有一个save_model的操作,这就是把训练好的模型保存下来。
验证就是调用这个保存下来的模型,把这200条数据放进去,验证一下模型的泛化能力如何,在这里用的MSE/MAE等公式进行验证。
验证就只是验证的作用,不会调整优化模型,就是把模型没见过的数据放进来,看看模型在面对没见过的数据时的表现能力如何,结果出来也是(8,3)这种数据形状,如果发现能力不行,那就要重新去调整训练模型的结果或者调整训练模型的超参数,重新训练模型。
一句话,验证集只是验证的。
一个问题:有的模型好像没有用到验证集哦,据大佬说,好像是无监督的模型不用验证集。
就是在验证这一部分才会有什么平均误差啊,什么balabala之类的。
举个例子:

上面是epoch完之后,下面才是出来mae这些结果的。
测试集的话,好像就是可视化用的,就是画图表显示效果时用的,就是最终的学习好坏通过期末考试得到的。
验证集和测试集的数据都是训练时模型没见过的。
接下来就是神奇的问题,模型是怎么训练最后得到想要的东西。

比如上面这个,假设我的模型有个Linear,里面的矩阵形状是(3,1),我(8,10,3)的数据进去之后,得到了(8,10,1)的数据形状,在经过矩阵变化变成(8,10)然后我再经过一个Linear之后,比如是(10,3),那么我的数据形状就变成了(8,3)就是这样。这样最后就是3个特征的结果。
一个小细节,这里面的变化只和超参数10有关,这个10就是batch_size,其实这个10就是窗口size,就是滑窗的大小。如果模型效果不好,调整滑窗大小或者是batch_size其实是有效果的。
就是数据进入模型之后,经过一系列各种矩阵变换操作,最后softmax之后得到想要的结果。
比如我输入数字的图像,最后看是0-9里的哪个数字,那就是这个图像放进去之后经过一系列矩阵变化操作之后,最后在经过一个(X,10)的变化,最后得到一个10的分布结果,比如发现7对应的结果最大,那这个图像很大可能就是7。
比如我输入一个数字的图像,我判断这个图像的数字是大于5还是小于5的,当然我的标签如果大于5给的是1,小于5给的是0,数据经过模型后一系列矩阵操作,最后有一个(X,2)的矩阵变化,得到2个结果,如果是0那就是小于5,如果是1那就是大于5。
可能还有一个问题,如果我判断这个图像数字是大于7还是小于7呢,那就是去改数据的标签,大于7设置1,小于7设置0,这就是去改数据。
还有的比如说是训练一个预测模型,然后再用这个预测模型进行下一步的操作,比如这个预测模型就是训练学习一个预测函数,这就是回归问题,上面那个判断是大于5还是小于5的就是分类问题。回归问题就是学习一个函数,然后再把数据输入到这个函数中看结果,然后再验证测试。
接下来是kernels核的理解。
比如时序预测中的季节趋势,怎么得到这个季节趋势的?春夏秋冬4个趋势,比如kernels=1,那么就是1天,那么每次都是1天是看不出来季节趋势的。如果kernels=90,就是90天,360/4=90,那么就是一个季度的,如果再扩大kernels=180,kernels=360,范围越来越大,就能学习到。春天是上升的,夏天是上升到最高值,秋天是下降的,冬天是下降到最低值的。就是这样,具体的kernels的实现,是封装好的,不了解。
接下来是学习率的理解。
比如有的模型里面有学习率这个东西。
parser.add_argument('--lr', type=float, default=0.001, help='The learning rate (defaults to 0.001)')
这个好像就是和动量有关系,可以改善陷入局部最优的问题,梯度下降中用到的东西。
大概就是这些,其他的就想不起来了。
开溜,吃晚饭去了。
深度学习模型训练的过程理解(训练集、验证集、测试集、batch、iteration、epoch、单步预测、多步预测、kernels、学习率)的更多相关文章
- AI佳作解读系列(一)——深度学习模型训练痛点及解决方法
1 模型训练基本步骤 进入了AI领域,学习了手写字识别等几个demo后,就会发现深度学习模型训练是十分关键和有挑战性的.选定了网络结构后,深度学习训练过程基本大同小异,一般分为如下几个步骤 定义算法公 ...
- 用 Java 训练深度学习模型,原来可以这么简单!
本文适合有 Java 基础的人群 作者:DJL-Keerthan&Lanking HelloGitHub 推出的<讲解开源项目> 系列.这一期是由亚马逊工程师:Keerthan V ...
- 深度学习与CV教程(6) | 神经网络训练技巧 (上)
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/37 本文地址:http://www.showmeai.tech/article-det ...
- 【深度学习的实用层面】(一)训练,验证,测试集(Train/Dev/Test sets)
在配置训练.验证.和测试数据集的过程中做出正确的决策会更好地创建高效的神经网络,所以需要对这三个名词有一个清晰的认识. 训练集:用来训练模型 验证集:用于调整模型的超参数,验证不同算法,检验哪种算法更 ...
- 利用 TFLearn 快速搭建经典深度学习模型
利用 TFLearn 快速搭建经典深度学习模型 使用 TensorFlow 一个最大的好处是可以用各种运算符(Ops)灵活构建计算图,同时可以支持自定义运算符(见本公众号早期文章<Tenso ...
- 深度学习模型调优方法(Deep Learning学习记录)
深度学习模型的调优,首先需要对各方面进行评估,主要包括定义函数.模型在训练集和测试集拟合效果.交叉验证.激活函数和优化算法的选择等. 那如何对我们自己的模型进行判断呢?——通过模型训练跑代码,我们可以 ...
- 『高性能模型』Roofline Model与深度学习模型的性能分析
转载自知乎:Roofline Model与深度学习模型的性能分析 在真实世界中,任何模型(例如 VGG / MobileNet 等)都必须依赖于具体的计算平台(例如CPU / GPU / ASIC 等 ...
- Roofline Model与深度学习模型的性能分析
原文链接: https://zhuanlan.zhihu.com/p/34204282 最近在不同的计算平台上验证几种经典深度学习模型的训练和预测性能时,经常遇到模型的实际测试性能表现和自己计算出的复 ...
- Apple的Core ML3简介——为iPhone构建深度学习模型(附代码)
概述 Apple的Core ML 3是一个为开发人员和程序员设计的工具,帮助程序员进入人工智能生态 你可以使用Core ML 3为iPhone构建机器学习和深度学习模型 在本文中,我们将为iPhone ...
- 斯坦福大学公开课机器学习:advice for applying machine learning | model selection and training/validation/test sets(模型选择以及训练集、交叉验证集和测试集的概念)
怎样选用正确的特征构造学习算法或者如何选择学习算法中的正则化参数lambda?这些问题我们称之为模型选择问题. 在对于这一问题的讨论中,我们不仅将数据分为:训练集和测试集,而是将数据分为三个数据组:也 ...
随机推荐
- CF414B
这道题dp状态表示需要一点思维,而且会卡到时间复杂度 之前题主用的是试除法,时间复杂度为n^2.5,然后被卡了,但是换一种写法就是对的 #include <iostream> #inclu ...
- oeasy教您玩转vim - 58 - # 块可视化
块可视化编辑 回忆上节课内容 上次我们了解到行可视模式 行可视模式 V 也可配合各种motion o切换首尾 选区的开头和结尾是mark标记 开头是 '< 结尾是 '> 可以在选区内进 ...
- 支付宝小程序的级联选择器,对接简单操作,Cascader 级联选择器element_ui
首先,对于element_ui 的动接,由于需要数据格式是 但是支付宝提的接口返回的数据是另一种格式,并且支付宝的三级联动接口是先只有一个列表,点击列表项再发现请求,生成另外一个下拉选择, 需要这个三 ...
- 关于android的图像视图的基本了解
最好直接复制进去而不是拖进去 图片直接导入最好用小写字母命名,数字与字母之间要用_,而且数字好像不可以连用 centerInside,fitCenter,center的区别: centerInside ...
- 【SpringBoot】15 数据访问P3 整合Mybatis
重新建立一个SpringBoot工程 选择依赖组件 然后删除不需要的Maven&Git文件 还是先查看我们的POM文件 整合Mybatis的组件多了这一个,默认的版本是3.5.4 然后再看看整 ...
- 华为显卡已经支持pytorch计算框架
相关链接: https://support.huawei.com/enterprise/zh/doc/EDOC1100079287/a21c08de https://www.zhihu.com/que ...
- Google的TPU的运算数据类型最高为32比特,也就是说TPU不支持double数据类型,浮点数类型最高支持float32
Google的TPU的运算数据类型最高为32比特,也就是说TPU不支持double数据类型,浮点数类型最高支持float32 地址: https://cloud.google.com/tpu/docs ...
- 强化学习入门书籍《DeepReinforcementLearningHands-On-SecondEdition》
前段时间在网上买了本强化学习入门的书籍,即<Deep-Reinforcement-Learning-Hands-On>,虽然是影印版的,但是感觉还是可以看看的,说的也蛮易懂的,感觉比现在市 ...
- gym中所有可以用的模拟环境
python 代码: from gym import envs for env in envs.registry.all(): print(env.id) 打印出可用环境: Copy-v0 Repea ...
- git 如何处理合并时存在的子模块冲突
如果另一个分支的子模块不同于当前分支,那么在拉取下来时,并不会更新本地子模块的版本,而会出现一个.diff文件,表示差异性.那么在合并代码时,可能会因为这个.dff文件冲突无法解决.产生这个问题的原因 ...