分析fastcache和freecache(一)
分析fastcache和freecache(一)
fastcache和freecache是两个比较简单的缓存实现,下面分析一下各自的实现,并学习一下其实现中比较好的方式。
fastcache
概述
fastcache是一个简单库,核心文件也就两个:fastcache.go和bigcache.go。其中后者是对前者场景的扩展,其实就是将大于64KB 的数据分段存储。参见下面Limitations的第二条。
Limitations
- Keys and values must be byte slices. Other types must be marshaled before storing them in the cache.
- Big entries with sizes exceeding 64KB must be stored via distinct API.
- There is no cache expiration. Entries are evicted from the cache only on cache size overflow. Entry deadline may be stored inside the value in order to implement cache expiration.
根据官方的性能测试报告,其读写性能比较均衡,远好于标准的Go map和sync.Map:
GOMAXPROCS=4 go test github.com/VictoriaMetrics/fastcache -bench='Set|Get' -benchtime=10s
goos: linux
goarch: amd64
pkg: github.com/VictoriaMetrics/fastcache
BenchmarkBigCacheSet-4 2000 10566656 ns/op 6.20 MB/s 4660369 B/op 6 allocs/op
BenchmarkBigCacheGet-4 2000 6902694 ns/op 9.49 MB/s 684169 B/op 131076 allocs/op
BenchmarkBigCacheSetGet-4 1000 17579118 ns/op 7.46 MB/s 5046744 B/op 131083 allocs/op
BenchmarkCacheSet-4 5000 3808874 ns/op 17.21 MB/s 1142 B/op 2 allocs/op
BenchmarkCacheGet-4 5000 3293849 ns/op 19.90 MB/s 1140 B/op 2 allocs/op
BenchmarkCacheSetGet-4 2000 8456061 ns/op 15.50 MB/s 2857 B/op 5 allocs/op
BenchmarkStdMapSet-4 2000 10559382 ns/op 6.21 MB/s 268413 B/op 65537 allocs/op
BenchmarkStdMapGet-4 5000 2687404 ns/op 24.39 MB/s 2558 B/op 13 allocs/op
BenchmarkStdMapSetGet-4 100 154641257 ns/op 0.85 MB/s 387405 B/op 65558 allocs/op
BenchmarkSyncMapSet-4 500 24703219 ns/op 2.65 MB/s 3426543 B/op 262411 allocs/op
BenchmarkSyncMapGet-4 5000 2265892 ns/op 28.92 MB/s 2545 B/op 79 allocs/op
BenchmarkSyncMapSetGet-4 1000 14595535 ns/op 8.98 MB/s 3417190 B/op 262277 allocs/op
fastcache.go分析
fastcache的数据结构相对比较简单,主要内容如下(省去了统计相关的结构体成员):
type Cache struct {
buckets [bucketsCount]bucket
...
}
type bucket struct {
mu sync.RWMutex
// chunks is a ring buffer with encoded (k, v) pairs.
// It consists of 64KB chunks.
chunks [][]byte
// m maps hash(k) to idx of (k, v) pair in chunks.
m map[uint64]uint64
// idx points to chunks for writing the next (k, v) pair.
idx uint64
// gen is the generation of chunks.
gen uint64
...
}
Cache结构体中包含长度为512的buckets,bucket中包含存储数据的chunks数组。fastcache没有缓存超时机制,chunks为ringbuffer,当chunks满数据之后,新来的数据会放到chunk1中,以此类推。从这方面看,fastcache并没有什么神奇之处,但cache说白了也就2件事:
- 快速检索数据,包括快速确定写入的内存以及快速查找所需的数据
- 高效利用内存,不产生过多的内存碎片
后面看下fastcache如何利用bucket.m、bucket.idx和bucket.gen这三个参数来实现快速检索数据,以及如何使用freeChunks来减少内存预分配。
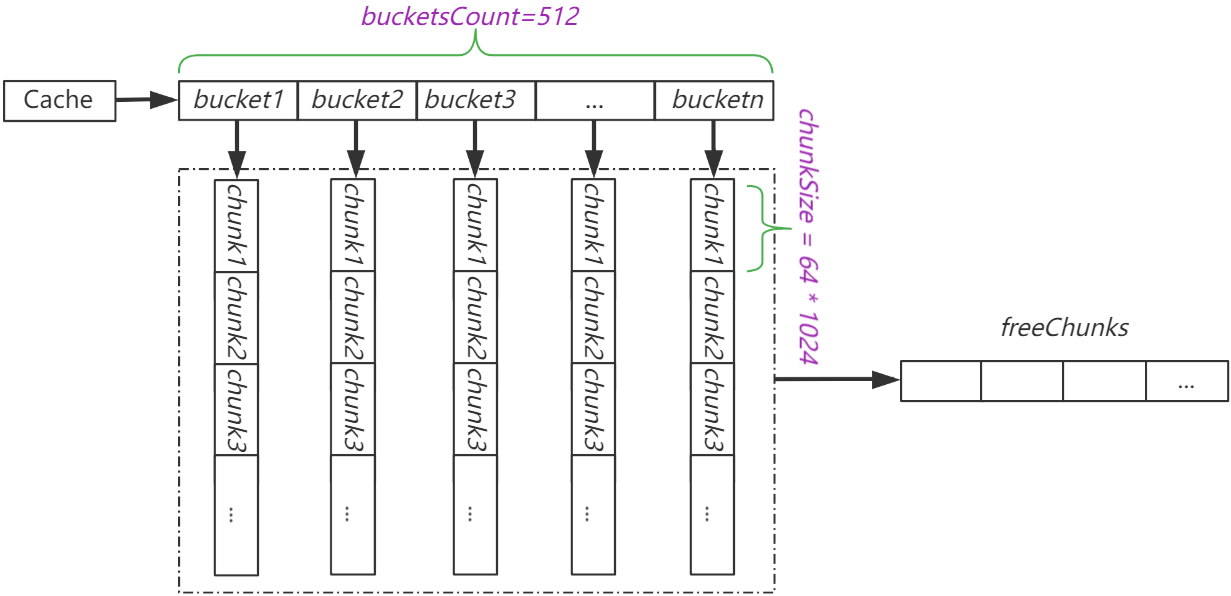
Cache的初始化
Cache中的buckets的长度以及bucket中单个chunk的大小是固定的,入参的maxBytes仅会影响bucket.chunks的长度,即bucket中的chunk数目。从Cache结构体中可以看到其buckets的长度为bucketsCount,即512个。
func New(maxBytes int) *Cache {
if maxBytes <= 0 {
panic(fmt.Errorf("maxBytes must be greater than 0; got %d", maxBytes))
}
var c Cache
maxBucketBytes := uint64((maxBytes + bucketsCount - 1) / bucketsCount)
for i := range c.buckets[:] {
c.buckets[i].Init(maxBucketBytes)
}
return &c
}
下面是bucket的初始化方法,需要注意的是其仅仅初始化了b.chunks的大小,并没有初始化单个chunk的内存空间(即chunkSize字节)。chunk的初始化是在实际使用时从freeChunks申请的,这样可以避免预先分配冗余内存。这种方式有点类似底层的虚拟内存的概念,只有在真正使用的时候才会分配内存。后面会看到freeChunks是如何申请内存的。
func (b *bucket) Init(maxBytes uint64) {
if maxBytes == 0 {
panic(fmt.Errorf("maxBytes cannot be zero"))
}
if maxBytes >= maxBucketSize {
panic(fmt.Errorf("too big maxBytes=%d; should be smaller than %d", maxBytes, maxBucketSize))
}
maxChunks := (maxBytes + chunkSize - 1) / chunkSize
b.chunks = make([][]byte, maxChunks)
b.m = make(map[uint64]uint64)
b.Reset()
}
chunk内存的申请和释放
上面说了在Cache初始化时并没有为chunk申请内存,在实际使用chunk的时候(Set)才会申请内存。下面是chunk的内存初始化方式。可以看到fastcache中使用unix.Mmap来为chunk申请内存,这样作可以避免GC的影响(当前缺点是需要手动维护内存)。当需要为chunk申请内存时,会调用unix.Mmap来一次性申请chunksPerAlloc(即1024)个chunk,将其附加到freeChunks中,并从freeChunks中返回最后一个元素作为初始化后的chunk。当然unix.Mmap需要在unix系统下才能生效。
freeChunks是个全局chunk数组,便于为不同的chunk提供存储。
func getChunk() []byte {
freeChunksLock.Lock()
if len(freeChunks) == 0 {
// Allocate offheap memory, so GOGC won't take into account cache size.
// This should reduce free memory waste.
data, err := unix.Mmap(-1, 0, chunkSize*chunksPerAlloc, unix.PROT_READ|unix.PROT_WRITE, unix.MAP_ANON|unix.MAP_PRIVATE)
if err != nil {
panic(fmt.Errorf("cannot allocate %d bytes via mmap: %s", chunkSize*chunksPerAlloc, err))
}
for len(data) > 0 {
p := (*[chunkSize]byte)(unsafe.Pointer(&data[0]))
freeChunks = append(freeChunks, p)
data = data[chunkSize:]
}
}
n := len(freeChunks) - 1
p := freeChunks[n]
freeChunks[n] = nil
freeChunks = freeChunks[:n]
freeChunksLock.Unlock()
return p[:]
}
下面是trunk的回收方式,比较简单,即将需要回收的trunk附加到freeChunks即可。
func putChunk(chunk []byte) {
if chunk == nil {
return
}
chunk = chunk[:chunkSize]
p := (*[chunkSize]byte)(unsafe.Pointer(&chunk[0]))
freeChunksLock.Lock()
freeChunks = append(freeChunks, p)
freeChunksLock.Unlock()
}
添加kv数据
fastcache使用Set来添加数据,但数据需要是[]byte类型。它首先会对k进行哈希,统一k的长度。并通过哈希的结果找出存放该数据的bucket索引。
func (c *Cache) Set(k, v []byte) {
h := xxhash.Sum64(k)
idx := h % bucketsCount
c.buckets[idx].Set(k, v, h)
}
通过索引找到对应的bucket之后,下一步就是将数据存储到bucket中的chunk中。
该函数是fastcache的核心函数,
有效性校验,确保k、v的长度不超过16bit,即2个字节,在第2步中会保存k、v的长度信息,因此此处是强制限制。
chunk中保存的单个数据的格式如下,使用这种方式主要是为了方便快速检索k、v。
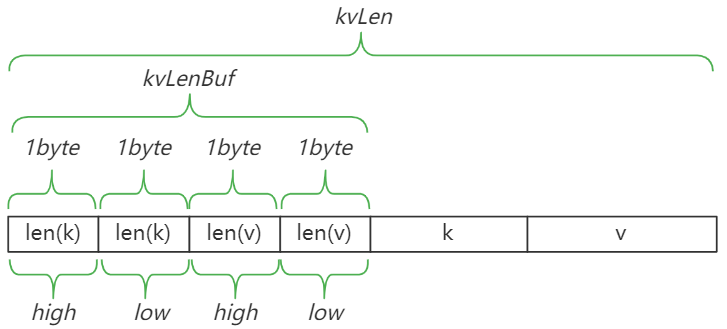
获取该bucket中的
chunks,注意一开始使用的时候chunks中的chunk是没有初始化的b.idx表示当前chunks中的总数据偏移(但并不等于有效数据,如果某个chunk无法容纳下一个数据,则会产生一定的碎片)。chunkIdx为当前chunk的索引,idxNew为添加新数据之后的总数据偏移,chunkIdxNew为添加新数据之后的chunk索引

如果
chunkIdxNew > chunkIdx说明当前chunk的剩余空间无法保存新数据,此时需要一个新的chunk来保存新数据(此时索引为chunkIdx的chunk中会产生内存碎片)。如果该
bucket中的所有chunk都已经被占满,此时没有空余的chunk来保存新数据,此时会采用ringbuffer的方式,将新数据放到第一个chunk中6.1 更新数据偏移量,此时在第一个
chunk中,因此偏移量为0。bucket有一个b.gen成员,保存了当前bucket中chunks的循环使用次数,即第gen代数据。由于chunks是ringbuf,存储空间会被循环利用,因此在查询数据时需要对比数据存储时的gen(存储在b.m中)和当前gen,如果不相同,则说明老的数据已经被后来的数据覆盖了。6.2
b.gen会保存到b.m的高24位,如果此时b.gen&((1<<genSizeBits)-1) == 0,则说明b.gen发生了溢出,此时需要将b.gen置0,重新计数。6.3 当重新使用
chunks时,需要清理b.m中无效的数据如果
chunks中有空余的chunk,则更新chunk索引和总数据偏移量。清空
chunk中的数据获取存储数据的
chunk,如果该chunk没有初始化,则调用getChunk初始化chunk内存。在
chunk中添加该数据,包括数据头(kvLenBuf)和k、vb.m中保存了该元素(索引为k的哈希值)的相关信息,高24位保存了该数据所处的gen,低40位保存了该数据的起始位置(即保存该数据时的总数据偏移量,受限于chunkSize的大小,最多只会占用16bit)。
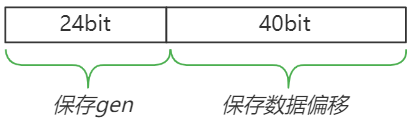
更新bucket中的总数据偏移量
cleanLocked会清理b.m中的无效数据。那么如何判断哪些数据是无效的呢?有效数据有如下两种情况:- 如果数据的偏移量(
idx)大于当前bucket的偏移量(bIdx),则说明该数据是上一代数据,则数据的gen和bucket的gen(bGen)有如下两种关系:gen+1 == bGen- gen == maxGen && bGen == 1
- 如果数据的偏移量(
idx)小于当前bucket的偏移量(bIdx),,则说明该数据是本代数据,则要满足gen == bGen
不满足上述两种场景的数据都是无效数据,需要清理。
func (b *bucket) cleanLocked() {
bGen := b.gen & ((1 << genSizeBits) - 1)
bIdx := b.idx
bm := b.m
for k, v := range bm {
gen := v >> bucketSizeBits
idx := v & ((1 << bucketSizeBits) - 1)
if (gen+1 == bGen || gen == maxGen && bGen == 1) && idx >= bIdx || gen == bGen && idx < bIdx {
continue
}
delete(bm, k)
}
}
- 如果数据的偏移量(
func (b *bucket) Set(k, v []byte, h uint64) {
atomic.AddUint64(&b.setCalls, 1)
if len(k) >= (1<<16) || len(v) >= (1<<16) { //<1>
return
}
var kvLenBuf [4]byte // <2>
kvLenBuf[0] = byte(uint16(len(k)) >> 8)
kvLenBuf[1] = byte(len(k))
kvLenBuf[2] = byte(uint16(len(v)) >> 8)
kvLenBuf[3] = byte(len(v))
kvLen := uint64(len(kvLenBuf) + len(k) + len(v))
if kvLen >= chunkSize {
return
}
chunks := b.chunks // <3>
needClean := false
b.mu.Lock()
idx := b.idx // <4>
idxNew := idx + kvLen
chunkIdx := idx / chunkSize
chunkIdxNew := idxNew / chunkSize
if chunkIdxNew > chunkIdx { // <5>
if chunkIdxNew >= uint64(len(chunks)) { // <6>
idx = 0 // <6.1>
idxNew = kvLen
chunkIdx = 0
b.gen++
if b.gen&((1<<genSizeBits)-1) == 0 { // <6.2>
b.gen++
}
needClean = true // <6.3>
} else {
idx = chunkIdxNew * chunkSize // <7>
idxNew = idx + kvLen
chunkIdx = chunkIdxNew
}
chunks[chunkIdx] = chunks[chunkIdx][:0] // <8>
}
chunk := chunks[chunkIdx] // <9>
if chunk == nil {
chunk = getChunk()
chunk = chunk[:0]
}
chunk = append(chunk, kvLenBuf[:]...) // <10>
chunk = append(chunk, k...)
chunk = append(chunk, v...)
chunks[chunkIdx] = chunk
b.m[h] = idx | (b.gen << bucketSizeBits) // <11>
b.idx = idxNew //12
if needClean { // <13>
b.cleanLocked()
}
b.mu.Unlock()
}
获取kv数据
有了Set的基础,Get就相对简单很多。
- 首先从
b.m中获取该k对应的元数据 - 校验该数据是否合法,逻辑跟
cleanLocked一样 - 如果合法,则通过偏移量找到对应的
chunk - 获取数据在其所在的
chunk中的偏移量 - 找到
kvLenBuf中保存的k、v长度 - 校验数据中的k是不是跟所需要的k一样,这么做的目的是防止哈希冲突的情况下获取到异常数值。如果合法则返回对应的v即可
func (b *bucket) Get(dst, k []byte, h uint64, returnDst bool) ([]byte, bool) {
atomic.AddUint64(&b.getCalls, 1)
found := false
chunks := b.chunks
b.mu.RLock()
v := b.m[h] // <1>
bGen := b.gen & ((1 << genSizeBits) - 1)
if v > 0 {
gen := v >> bucketSizeBits
idx := v & ((1 << bucketSizeBits) - 1)
if gen == bGen && idx < b.idx || gen+1 == bGen && idx >= b.idx || gen == maxGen && bGen == 1 && idx >= b.idx { // <2>
chunkIdx := idx / chunkSize // <3>
if chunkIdx >= uint64(len(chunks)) {
// Corrupted data during the load from file. Just skip it.
atomic.AddUint64(&b.corruptions, 1)
goto end
}
chunk := chunks[chunkIdx]
idx %= chunkSize // <4>
if idx+4 >= chunkSize {
// Corrupted data during the load from file. Just skip it.
atomic.AddUint64(&b.corruptions, 1)
goto end
}
kvLenBuf := chunk[idx : idx+4] // <4>
keyLen := (uint64(kvLenBuf[0]) << 8) | uint64(kvLenBuf[1])
valLen := (uint64(kvLenBuf[2]) << 8) | uint64(kvLenBuf[3])
idx += 4
if idx+keyLen+valLen >= chunkSize {
// Corrupted data during the load from file. Just skip it.
atomic.AddUint64(&b.corruptions, 1)
goto end
}
if string(k) == string(chunk[idx:idx+keyLen]) { // <5>
idx += keyLen
if returnDst {
dst = append(dst, chunk[idx:idx+valLen]...)
}
found = true
} else {
atomic.AddUint64(&b.collisions, 1)
}
}
}
end:
b.mu.RUnlock()
if !found {
atomic.AddUint64(&b.misses, 1)
}
return dst, found
}
总结
- fastcache的chunk内存分配方式比较好,它没有预先分配大量内存,而是动态申请的方式。其次内存申请使用了手动申请系统内存的方式(
mmap),以此避免GC的影响。 - fastcache的数据存储时包含了一个元数据头,元数据里面保存了该数据的数据偏移量以及k、v长度等数据,通过这种方式可以快速定位数据所在的位置。像大部分存储的WAL存储方式也是采用的这种TLV或LV方式。
- fastcache的缓存采用的是ringbuffer的方式,并没有超时机制。数据的存储和查找都是通过哈希的方式进行的,因此检索速度很快。
- fastcache的代码比较少,可以直接移植
分析fastcache和freecache(一)的更多相关文章
- 20155312 张竞予 Exp4 恶意代码分析
Exp4 恶意代码分析 目录 基础问题回答 (1)如果在工作中怀疑一台主机上有恶意代码,但只是猜想,所有想监控下系统一天天的到底在干些什么.请设计下你想监控的操作有哪些,用什么方法来监控. (2)如果 ...
- 2018-2019-2 网络对抗技术 20165230 Exp4 恶意代码分析
目录 1.实验内容 2.实验过程 任务一:系统运行监控 每隔五分钟记录自己的电脑,并进行分析 安装配置sysinternals里的sysmon工具 任务二:恶意软件分析 静态分析工具 ViruScan ...
- Android中应用安装分析
#1 安装方式 1 安装系统APK和预制APK时,通过PMS的构造函数中安装,即第一次开机时安装应用,没有安装界面. 2 网络下载安装,通过应用商店等,即调用PackageManager.instal ...
- alias导致virtualenv异常的分析和解法
title: alias导致virtualenv异常的分析和解法 toc: true comments: true date: 2016-06-27 23:40:56 tags: [OS X, ZSH ...
- 火焰图分析openresty性能瓶颈
注:本文操作基于CentOS 系统 准备工作 用wget从https://sourceware.org/systemtap/ftp/releases/下载最新版的systemtap.tar.gz压缩包 ...
- 一起来玩echarts系列(一)------箱线图的分析与绘制
一.箱线图 Box-plot 箱线图一般被用作显示数据分散情况.具体是计算一组数据的中位数.25%分位数.75%分位数.上边界.下边界,来将数据从大到小排列,直观展示数据整体的分布情况. 大部分正常数 ...
- 应用工具 .NET Portability Analyzer 分析迁移dotnet core
大多数开发人员更喜欢一次性编写好业务逻辑代码,以后再重用这些代码.与构建不同的应用以面向多个平台相比,这种方法更加容易.如果您创建与 .NET Core 兼容的.NET 标准库,那么现在比以往任何时候 ...
- UWP中新加的数据绑定方式x:Bind分析总结
UWP中新加的数据绑定方式x:Bind分析总结 0x00 UWP中的x:Bind 由之前有过WPF开发经验,所以在学习UWP的时候直接省略了XAML.数据绑定等几个看着十分眼熟的主题.学习过程中倒是也 ...
- 查看w3wp进程占用的内存及.NET内存泄露,死锁分析
一 基础知识 在分析之前,先上一张图: 从上面可以看到,这个w3wp进程占用了376M内存,启动了54个线程. 在使用windbg查看之前,看到的进程含有 *32 字样,意思是在64位机器上已32位方 ...
- ZIP压缩算法详细分析及解压实例解释
最近自己实现了一个ZIP压缩数据的解压程序,觉得有必要把ZIP压缩格式进行一下详细总结,数据压缩是一门通信原理和计算机科学都会涉及到的学科,在通信原理中,一般称为信源编码,在计算机科学里,一般称为数据 ...
随机推荐
- KAFKA EAGLE 监控MRS kafka之操作实践
本文分享自华为云社区<KAFKA EAGLE 监控MRS kafka之操作实践>,作者: 啊喔YeYe . 1.Kafka Eagle简介 Kafka eagle 是一款分布式.高可用的k ...
- 云原生数据库风起云涌,华为云GaussDB破浪前行
摘要:云原生数据库,实现多云协同.混合云解决方案.边云协同等能力的数据库. Gartner预测,2021年云数据库在整个数据库市场中的占比将首次达到50%:2023年75%的数据库将基于云的技术来构建 ...
- 实践案例丨Pt-osc工具连接rds for mysql 数据库失败
[现象] 主机可以telent 通rds 端口,并且使用mysql-client 连接正常: 如下图所示:使用pt-osc工具连接时,一直没有响应,一直卡在哪里 等了4-5分钟左右后,会有响应,如下图 ...
- Koa、koa-router、koa-jwt 鉴权详解:分模块鉴权实践总结
首先看koa-router koa-router use 熟悉Koa的同学都知道use是用来注册中间件的方法,相比较Koa中的全局中间件,koa-router的中间件则是路由级别的. koa-rout ...
- React Native 打包 App 发布 iOS 及加固混淆过程
React Native 打包 App 发布 iOS 及加固混淆过程 摘要 本文将介绍如何使用 React Native 打包并发布 iOS 应用到 App Store,并介绍了如何进行应用的加固和混 ...
- Mindjet MindManager 拖动页面
常规的软件是按住空格建+鼠标左健 进行拖放,但 MindManager 不支持,如何对Mindjet MindManager 拖动页面? 按住 鼠标右键 直接拖拽 配合 Ctrl+滚轮 放大缩小,一起 ...
- linux 实时刷新显示当前时间
同步阿里云时间 ntpdate ntp1.aliyun.com 使用watch命令:周期性的执行一个命令,并全屏显示. watch -n 1 date 即可:每1秒刷新date命令. # 格式 wat ...
- JSP常见错误以及解决方案
原作者为 RioTian@cnblogs, 本作品采用 CC 4.0 BY 进行许可,转载请注明出处. 本节我们分析一下常见的 JSP 错误信息,并给出解决方案.这些错误在实际开发中会经常遇到,所以有 ...
- POJ - 1190 生日蛋糕(深搜+神奇的剪枝)
链接:https://ac.nowcoder.com/acm/contest/1015/B 题目描述 7月17日是Mr.W的生日,ACM-THU为此要制作一个体积为Nπ的M层生日蛋糕,每层都是一个圆柱 ...
- Python数据可视化-动态柱状图可视化
Python数据可视化-动态柱状图可视化 一.基础柱状图 通过Bar构建基础柱状图 """ 演示基础柱状图的开发 """ from pyec ...