聊聊Llama2-Chinese中文大模型
基本简述
Llama2-Chinese 大模型:由清华、交大以及浙大博士团队领衔开发;基于200B中文语料库结合Llama2基座模型训练。
Llama中文社区:国内最领先的开源大模型中文社区。
Atom大模型:为了区别于原始的Llama2模型,后续中文Llama2大模型,改名为Atom大模型。
模型获取地址:Huggingface
GITHUB地址:GITHUB
模型信息
Huggingface上Llama-Chinese大模型集合:
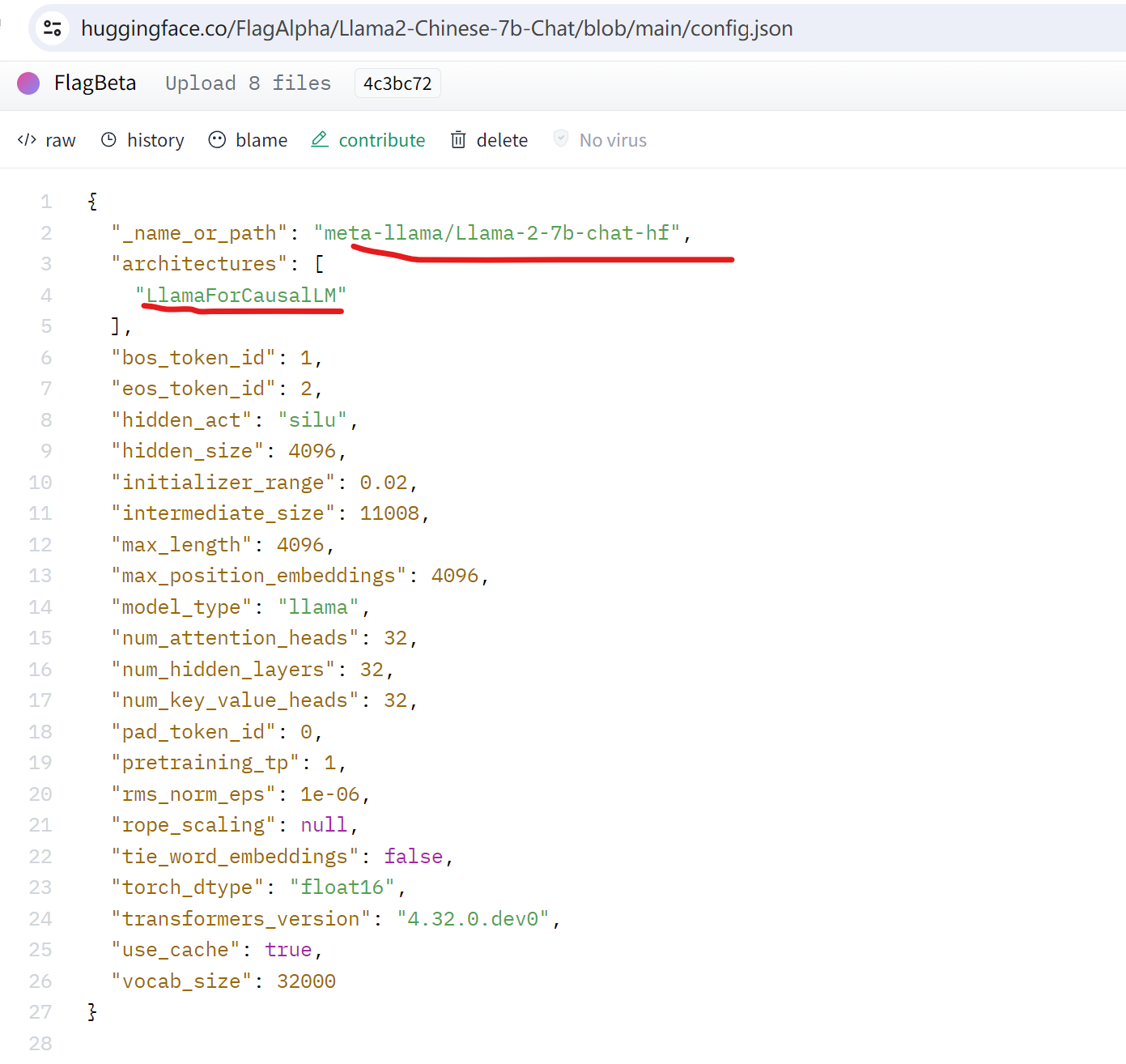
查看下Llama2-Chinese-7b-Chat模型的config.json:
查看下Atom-7B-Chat的config.json:
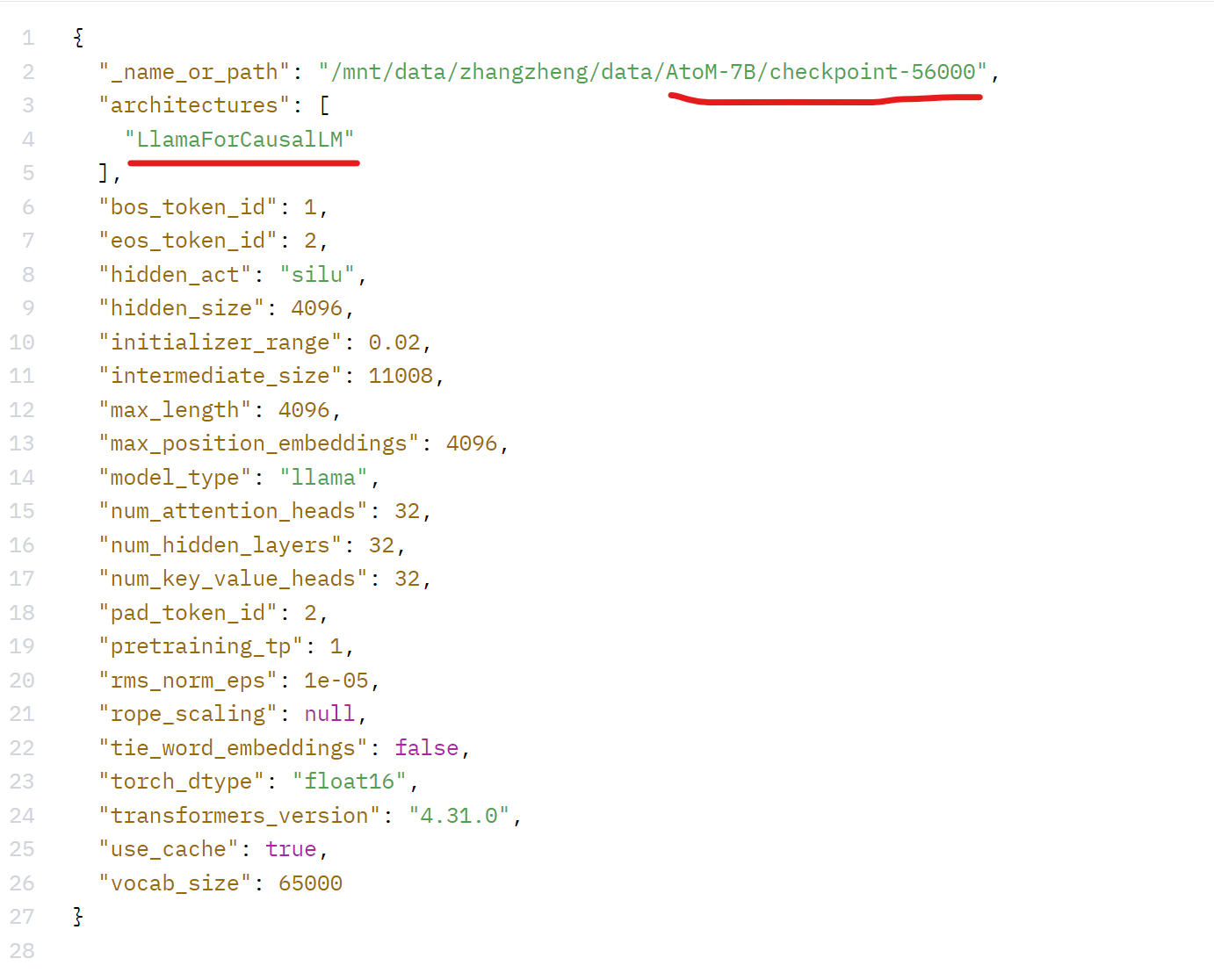
简单看看区别,官方说明:
- Atom模型:基于Llama2-7B采用大规模的中文数据进行了继续预训练。
- Llama2-Chinese:由于Llama2本身的中文对齐较弱,我们采用中文指令集,对meta-llama/Llama-2-7b-chat-hf进行LoRA微调,使其具备较强的中文对话能力。
总结来说,Atom模型时重新预训练的;而Llama2-Chinese模型是微调后的。因此如果想要比较完善更全面的中文模型,建议是用Atom模型。
调用说明
根据 官方文档 在命令行调用API:
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained('meta-llama/Llama-2-7b-chat-hf',device_map='auto',torch_dtype=torch.float16,load_in_8bit=True)
model =model.eval()
tokenizer = AutoTokenizer.from_pretrained('meta-llama/Llama-2-7b-chat-hf',use_fast=False)
input_ids = tokenizer(['<s>Human: 介绍一下中国\n</s><s>Assistant: '], return_tensors="pt",add_special_tokens=False).input_ids.to('cuda')
generate_input = {
"input_ids":input_ids,
"max_new_tokens":512,
"do_sample":True,
"top_k":50,
"top_p":0.95,
"temperature":0.3,
"repetition_penalty":1.3,
"eos_token_id":tokenizer.eos_token_id,
"bos_token_id":tokenizer.bos_token_id,
"pad_token_id":tokenizer.pad_token_id
}
generate_ids = model.generate(**generate_input)
text = tokenizer.decode(generate_ids[0])
print(text)
分析来看,调用的是基于Llama2微调后的模型,而不是预训练的模型。暂时也没有看到Atom预训练模型调用的资料。在这里补一下:
# 转载请注明出处:https://www.cnblogs.com/zhiyong-ITNote
from transformers import AutoTokenizer, LlamaForCausalLM
model = LlamaForCausalLM.from_pretrained('mnt/data/zhangzheng/data/AtoM-7B/checkpoint-56000',device_map='auto',torch_dtype=torch.float16,load_in_8bit=True)
model =model.eval()
tokenizer = AutoTokenizer.from_pretrained('mnt/data/zhangzheng/data/AtoM-7B/checkpoint-56000',use_fast=False)
input_ids = tokenizer(['<s>Human: 介绍一下中国\n</s><s>Assistant: '], return_tensors="pt",add_special_tokens=False).input_ids.to('cuda')
generate_input = {
"input_ids":input_ids,
"max_new_tokens":512,
"do_sample":True,
"top_k":50,
"top_p":0.95,
"temperature":0.3,
"repetition_penalty":1.3,
"eos_token_id":tokenizer.eos_token_id,
"bos_token_id":tokenizer.bos_token_id,
"pad_token_id":tokenizer.pad_token_id
}
generate_ids = model.generate(**generate_input)
text = tokenizer.decode(generate_ids[0])
print(text)
其实就是根据huggingface上的模型config.json文件的_name_or_path属性值重新配置模型名称即可。
LlamaForCausalLM
这个类是Llama2模型对接到transformers库的衔接类。由config.json的architectures属性值指定了。而且在官方文档有API说明.
对应在github上的实现:
从之前ChatGLM-6B的源码结构分析来看,Llama2的关键源码也是这个llama文件夹下的这些文件,尤其是modeling_llama.py文件。
总结
从目前官方提供的文档等信息来看,资料还是比较少的,尤其是Atom模型的信息及示例等。这也需要我们在自身学习的过程中帮助社区不断地完善相关信息,反哺社区和中文大模型的发展。
聊聊Llama2-Chinese中文大模型的更多相关文章
- 无插件的大模型浏览器Autodesk Viewer开发培训-武汉-2014年8月28日 9:00 – 12:00
武汉附近的同学们有福了,这是全球第一次关于Autodesk viewer的教室培训. :) 你可能已经在各种场合听过或看过Autodesk最新推出的大模型浏览器,这是无需插件的浏览器模型,支持几十种数 ...
- 华为高级研究员谢凌曦:下一代AI将走向何方?盘古大模型探路之旅
摘要:为了更深入理解千亿参数的盘古大模型,华为云社区采访到了华为云EI盘古团队高级研究员谢凌曦.谢博士以非常通俗的方式为我们娓娓道来了盘古大模型研发的"前世今生",以及它背后的艰难 ...
- AI大模型学习了解
# 百度文心 上线时间:2019年3月 官方介绍:https://wenxin.baidu.com/ 发布地点: 参考资料: 2600亿!全球最大中文单体模型鹏城-百度·文心发布 # 华为盘古 上线时 ...
- PowerDesigner 学习:十大模型及五大分类
个人认为PowerDesigner 最大的特点和优势就是1)提供了一整套的解决方案,面向了不同的人员提供不同的模型工具,比如有针对企业架构师的模型,有针对需求分析师的模型,有针对系统分析师和软件架构师 ...
- PowerDesigner 15学习笔记:十大模型及五大分类
个人认为PowerDesigner 最大的特点和优势就是1)提供了一整套的解决方案,面向了不同的人员提供不同的模型工具,比如有针对企业架构师的模型,有针对需求分析师的模型,有针对系统分析师和软件架构师 ...
- 文心大模型api使用
文心大模型api使用 首先,我们要获取硅谷社区的连个key 复制两个api备用 获取Access Token 获取access_token示例代码 之后就会输出 作文创作 作文创作:作文创作接口基于文 ...
- 千亿参数开源大模型 BLOOM 背后的技术
假设你现在有了数据,也搞到了预算,一切就绪,准备开始训练一个大模型,一显身手了,"一朝看尽长安花"似乎近在眼前 -- 且慢!训练可不仅仅像这两个字的发音那么简单,看看 BLOOM ...
- DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍
DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍 1. 概述 近日来,ChatGPT及类似模型引发了人工智能(AI)领域的一场风潮. 这场风潮对数字世 ...
- Familia:百度NLP开源的中文主题模型应用工具包
参考:Familia的Github项目地址.百度NLP专栏介绍 Familia 开源项目包含文档主题推断工具.语义匹配计算工具以及基于工业级语料训练的三种主题模型:Latent Dirichlet A ...
- 图神经网络之预训练大模型结合:ERNIESage在链接预测任务应用
1.ERNIESage运行实例介绍(1.8x版本) 本项目原链接:https://aistudio.baidu.com/aistudio/projectdetail/5097085?contribut ...
随机推荐
- LSP 链路状态协议
转载请注明出处: 链路状态协议(Link State Protocol)是一种在计算机网络中用于动态计算路由的协议.它的主要作用是收集网络拓扑信息,为每个节点构建一个准确的网络图,并基于这些信息计算出 ...
- 【最佳实践】MongoDB导入数据时重建索引
MongoDB一个广为诟病的问题是,大量数据resotore时索引重建非常缓慢,实测5000万的集合如果有3个以上的索引需要恢复,几乎没法成功,而且resotore时如果选择创建索引也会存在索引不生效 ...
- Jmeter中使用BeanShell获取接口返回的指定值
第一步:先引入jar包编写代码的时候,引入了一个jar包,是需要把它添加在测试计划中的 第一种:获取data中的paramName和paramVal值 //获取当前请求响应结果 String res ...
- ApiPost发送请求报错UT000036: Connection terminated parsing multipart data
发送请求报错Caused by: java.io.IOException: UT000036: Connection terminated parsing multipart data 这个报错是因为 ...
- UVA908[Re-connecting Computer Sites]题解
原题 1.题意分析 题意就是给你很多组数,对于每组数,有三组小数据.第一组小数据先输入一个n表示顶点数,然后再输入n-1条边表示初始边数.其它组小数据先输入一个数k,表示增加的边的数量,然后再输入k条 ...
- 博弈论(Nim游戏 , 有向图游戏)
博弈论专题 Nim游戏 内容: 有 n 堆石子,每堆石子的石子数给出,甲乙两人回合制取石子,每次可以取任意一堆石子的任意多个(可以直接取完,但不能不取),每个人都按照最优策略来取(抽象),问先手必胜或 ...
- 资源迁移OSS方案记录
视频资源迁移到OSS服务器上,记录一下迁移过程. 搭建流程 在阿里云上购买oss,并获取具有该Bucket访问权限的AccessKey ID和AccessKey Secret信息. 数据迁移方案一 第 ...
- 2023华为杯·第二届中国研究生网络安全创新大赛初赛复盘 Writeup
A_Small_Secret 题目压缩包中有个提示和另一个压缩包On_Zen_with_Buddhism.zip,提示内容如下: 除了base64还有什么编码 MFZWIYLEMFSA==== asd ...
- 一、docker的安装及docker-compose安装
一. 安装docker 1.1安装 curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun # https://get.d ...
- JAVA多线程(3)——如何加锁
1.加锁不正确导致数据不一致:m1执行过程中,m2(未加synchronized)可以执行,因为m2不用获得锁就可以执行 1 public class TT implements Runnable { ...