掌握ROMA Compose,报表清单不秃头
摘要:在没有ROMA Compose之前,完成一个跨数据源的关联查询是一个十分艰巨的任务。
1. ROMA Compose为何诞生
试想这样一个场景,主管让刚入职的小沛明天下班前给他发一份报表。小沛兴冲冲的打开需求清单一看,好家伙,报表需要连接各个不同数据源,A部门提供的数据存在MySQL、B部门提供的数据存在Oracle、C部门提供的数据存在Redis、D部门干脆数据库也不是了,直接只提供了一系列API。

考虑到后续更新的需要,小沛还需要每天拉取数据同时进行各种过滤操作。数学专业的萌新小沛写Matlab是相当在行。但是跨源对数据进行关联查询,同时还需要考虑主外键关系、执行效率、数据准确性等问题,着实让小沛头疼不已,迫不得已当场选择放弃。

与上述场景类似的是,实际生产过程中我们需要联通各个不同的数据源(数据库、API等)来获取我们需要的数据。
在这种情况下,我们不仅要要去编写各个不同数据源的连接器,而且数据量大的情况下各个数据之间的关系将会变得非常复杂,关联查询各个数据源并且兼顾好效率问题无疑是一个十分让人头疼的工作。更致命的是,数据不是一成不变的,随时会有新的数据源加入、老的数据源删除,这时候又需要对好不容易理清并优化好的代码进行更改。
上述情况经验老到的程序员死点脑细胞或许也能优雅的解决,但对于一般的业务人员实在是有点强人所难了,偏偏这样的场景又并不少见。

ROMA Compose通过元数据模型驱动,构建业务逻辑关系,可以优雅的解决这一类问题。在用户选择要进行关联的数据源和数据源之间的关系后,ROMA Compose能快速对数据进行编排,以API的形式返回查询接口给用户,用户调用API即可实现数据源之间的关联查询,无需任何代码操作。作为一个NO CODE平台,ROMA Compose秉承着将复杂留给自己,将方便留给用户的理念,对用户屏蔽了上述所有技术细节,整个操作过程通过拖拉拽和点击就能完成。

2. ROMA Compose特性介绍
ROMA Compose除了数据快速编排外,还有许多优雅的特性来帮助用户提升效率,降低使用门槛,下面挑选几个特性做简单的介绍。
2.1 NO CODE
NO CODE,顾名思义,就是让用户从繁琐的代码中解脱出来,将精力更多的专注于业务细节,是目前软件领域的主要趋势之一。
正如上文所说,ROMA Compose对用户屏蔽了所有的技术细节,用户无需编写各个数据源的连接器、无需考虑数据源之间的关联关系、查询效率、以及过滤条件等问题。通过网页的点击与托拉拽,用户就能对自己的数据源进行编排并生成API。用户唯一需要掌握的是这些数据源之间的业务知识,通过业务知识设置各个数据源之间的关联关系然后进行编排。
回到文章一开头的例子,有了ROMA Compose,小沛只用在数据源的展示界面建立各个数据源之间的关系,在API界面选择入参(查询条件),出参(返回的字段),编辑完成后发布API,再对API进行调用,就实现了各个部门不同数据源之间数据的查询操作。短短几分钟就完成了两天的工作量。

2.2 业务关系梳理
在实际工作中,公司各个数据源不仅数量合起来数不胜数,许多表名和字段名更是不讲武德,命名千奇百怪,相信除了DBA外很少有人能厘清这些表与字段的真实含义。

为了解决上述问题,帮用户进一步梳理数据源之间的业务关系,ROMA Compose做了以下两大特性:
- 基于元数据驱动的应用模型,结合ROMA Connect的应用业务模型(Application Business Model,ABM)对数据源进行统一管理。
- 引入应用模型图谱,图谱提供全量数据源展示视图,并支持基于视图的模型关系创建。
2.2.1 ABM
首先是ABM,ABM简单来说就是一个专门为数据源服务的注册中心,如果部门内部有数据要向其他部门开放,那么他们只需要在ABM中注册自己数据源的元数据信息。同时为了避免表名看不懂的可怕现象,ABM还支持用户上传数据源的业务含义,ABM能自动将元数据信息与业务信息进行关联。
除了简单的业务含义关联外,ABM还支持L1到L5级别的模型分层定义,帮助用户进一步从业务的角度对数据源进行梳理。
2.2.2 应用模型图谱
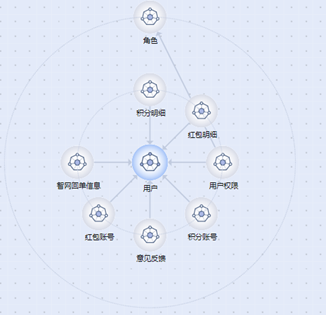
除了简单的列表展示数据源、数据源关系外,ROMA Compose还支持以图表的形势展示当前环境下数据源以及数据源之间的关系,上图中的每个节点表示数据源,节点之间的箭头表示数据源关系,这样做有不少显而易见的优点:
数据可视化,让数据源和关系更加直观的展示给用户。
数据源关系编辑,除了传统的表单操作外,ROMA Compose还支持更加灵活的图形界面操作,在数据源视图上通过鼠标点击、拖拽就能设置数据源之前的关联关系、关联字段。
层次化展示数据,以上图为例,用户节点属于主节点,起作用类似于树的根节点,是数据查询的入口。ROMA Compose按照与主节点距离的不同对数据源进行分类,让用户对API的编排效率有一种更直观的认识,因为距离越远,说明要连接的数据源越多,相应的执行效率也会越慢。
还是以小沛为例,在ROMA Compose出现之前,小沛每天都要跟不同部门的人确认他们是否有自己想要的数据源,这些字段的含义,长度,类型等信息,更致命的是这些信息本身还会随时进行变动,一度让他非常头疼。

2.3 多数据源支持
多数据源支持作为ROMA Compose的核心特性之一,在上文已经出现了多次。实际开发过程中,我们不仅会遇到种类繁多的数据库(不同型号、不同版本),在涉及到对外项目时,更大可能会只提供一个API。编写不同数据源的连接器对技术人员而言属于重复造轮子没什么意义的事情,对业务人员就更不友好了,进一步增加了使用门槛。
因此ROMA Compose底层的查询服务器编写了很多目前主流数据库的连接器,以及API数据源的连接器,目前也在进一步开发消息队列等的连接器,力求尽可能多的支持各种数据源。
2.4 业务规则
让我们继续小沛的例子,小沛之前的工作有相当一部分时间花在了业务规则的梳理上。有些数据来自用户输入,常常会有很多不合理的数据甚至是空数据,还有些数据属于异常信息与错误信息,这些杂乱的数据从业务逻辑上来讲是完全不需要的。小沛在拿到数据后第一时间就是在老板看到之前将这些奇奇怪怪、五花八门的数据消灭掉。

在实际的ETL过程中,类似的场景并不少见,基于业务规则对数据进行梳理往往是我们从源端拿到数据后的第一步操作。考虑这种情况,ROMA Compose也支持通过业务规则对数据进行筛选。在编排数据源定义API阶段,用户能对每个数据源的字段进行业务规则的定义,比如过删除ID为空的字段,保留两天内的数据,保留开头不为test的数据等,尽可能的从源头帮用户进行数据筛选。ROMA Compose目前支持以下业务规则筛选,并且预计在将来还会支持更灵活的业务规则定义。
- 等于、不等于
- 为空、不为空
- 大于、大于等于
- 小于、小于等于
- 包含、不包含
- 开始包含、开始不包含
- 结束包含、结束不包含
同时为了支撑某些特定场合(比如只保留近两天的数据),ROMA Compose还引入了时间和字符串处理函数,支持获取当前系统时间戳和时间加减等基本操作。对于字符串则支持replace,substring等基本操作。
总结
在没有ROMA Compose之前,对于小沛这样的业务人员而言,完成一个跨数据源的关联查询是一个十分艰巨的任务。ROMA Compose让小沛有更多的精力去关注业务细节,摆脱繁琐的代码。
同样的,我们由衷希望ROMA Compose也能帮助屏幕前的大家,让大家有更多的时间去思考,而不是浪费时间在重复造轮子上。
秉承将复杂留给自己,将简单留给用户的设计理念,相信在大家的帮助下我们相信ROMA Compose会越做越好。
本文分享自华为云社区《ROMA新武器上线了-ROMA Compose》,原文作者:中间件小哥 。
掌握ROMA Compose,报表清单不秃头的更多相关文章
- Java匹马行天下之C国程序员的秃头原因
Java帝国的崛起 前言: 分享技术之前先请允许我分享一下黄永玉老先生说过的话:“明确的爱,直接的厌恶,真诚的喜欢.站在太阳下的坦荡,大声无愧地称赞自己.” <编程常识知多少> <走 ...
- winfor应用程序打印报表清单
最近一周竟然有2位以前的同事问我在winfor应用程序里面打印怎么搞,所以才有了写这篇文章的打算,索性现在没事就写出来 在窗体上简单的布局设置一下如图 定义一个Model 我在里面放了属性之外还从写了 ...
- L302 如何避免秃头
Every guy wants to know how to prevent hair loss. Or, every guy wants to cling to the idea that it m ...
- java秀发入门到优雅秃头路线导航【教学视频+博客+书籍整理】
目录 一.Java基础 二.关于JavaWeb基础 三.关于数据库 四.关于ssm框架 五.关于数据结构与算法 六.关于开发工具idea 七.关于项目管理工具Mawen.Git.SVN.Gradle. ...
- SpringBoot+Minio搭建不再爆肝秃头的分布式文件服务器
前言 1).有人一定会问,为什么不用FastDFS?众所周知,FastDFS的原生安装非常复杂,有过安装经验的人大体都明白,虽然可以利用别人做好的docker直接安装,但真正使用过程中也可能出现许多莫 ...
- ActiveReports 报表应用教程 (1)---Hello ActiveReports
在开始专题内容之前,我们还是了解一下 ActiveReports 是一款什么产品:ActiveReports是一款在全球范围内应用非常广泛的报表控件,以提供.NET报表所需的全部报表设计功能领先于同类 ...
- ActiveReports 报表控件官方中文入门教程 (3)-如何选择页面报表和区域报表
本篇文章将介绍区域报表和页面报表的常见使用场景.区别和选择报表类型的一些建议,两种报表的模板设计.数据源(设计时和运行时)设置.和浏览报表的区别. ActiveReports 报表控件官方中文入门教程 ...
- 在Cognos报表中使用钻取特性,参数传递
转载至:http://blog.sina.com.cn/s/blog_6eda1c4e0100mu3t.html Cognos的钻取方式大致可以分为三种: 1.模型固有的->由CUBE和DMR支 ...
- EXT.NET复杂布局(二)——报表
前面提到过工作台(<EXT.NET复杂布局(一)--工作台>)了,不知道各位看过之后有什么感想.这次就介绍介绍使用EXT.NET画几个报表. 看图写作从小学就开始了,如图: 图一 图二 图 ...
- 不用Visual Studio,5分钟轻松实现一张报表
常规的报表设计,如RDLC.水晶报表等,需要安装Visual Studio,通过VS提供的报表设计界面来设计报表,通过VS设计报表对.NET开发者而言非常方便,但是对于非开发人员,要安装4G的一个VS ...
随机推荐
- 【PHP正则表达式】
[PHP正则表达式] 最近写题总是遇到php正则表达式的匹配函数,于是进行一个总结. 1.什么是正则表达式 是php在进行搜索时用于匹配的模式字符串.一般用于php对特定字符序列的替换和搜索. 2.正 ...
- 『STAOI』G - Round 1 半个游记
很刺激. 挂个链接
- 数据类型python
type()语句的用法 运行结果
- 各种flex布局,拿来即用用过的都说好
开发过程中,很多布局,用antd的栅格还是不灵活,flex弹性布局会更好用 Flex 是 Flexible Box 的缩写,意为"弹性布局",用来为盒状模型提供最大的灵活性. 注意 ...
- 容器Cgroup和Namespace特性简介
一般来说,容器技术主要包括Cgroup和Namespace这两个内核特性.Cgroup Cgroup是control group,又称为控制组,它主要是做资源控制.原理是将一组进程放在放在一个控制组里 ...
- Filter入门实例
一.介绍 Filter:Filter是Servlet的"加强版",它主要用于对用户请求进行预处理,也可对HttpServletResponse进行后处理,是个典型的"处理 ...
- 支持C#的开源免费、新手友好的数据结构与算法入门教程
前言 前段时间完成了C#经典十大排序算法(完结)然后有很多小伙伴问想要系统化的学习数据结构和算法,不知道该怎么入门,有无好的教程推荐的.今天给大家推荐一个支持C#的开源免费.新手友好的数据结构与算法入 ...
- Dom 的理解和操作
dom 文本对象模型 12种节点类型 一.node类型 js中所有节点类型都继承自node类型 每个节点都有一个nodeType属性,表明节点类型:判断节点类型,if(somenode.nodeTy ...
- [GitOps] 白嫖神器Github Actions,构建、推送Docker镜像一路畅通无阻
[GitOps] 白嫖神器Github Actions,构建.推送Docker镜像一路畅通无阻 引言 当你没找到合适的基础的Docker镜像时,是否会一时冲动,想去自己构建.然而因为网络问题,各种 ...
- 自学day7 数组
typora-copy-images-to: media 数组 一.概念 对象中可以通过键值对存储多个数据,且数据的类型是没有限制的,所以通常会存储一个商品的信息或一个人的信息: var obj = ...