HDFS学习笔记一
一,HDFS是什么,HDFS有什么用,HDFS怎么用
HDFS:Hadoop Distribute File System 分布式文件系统
HDFS可以保证文件存储的可靠性,
二.HDFS的设计原则
------HDFS的设计目标:
1.存储非常大的文件
通常的值的是G,TB级别的文件
2.采用流式的数据访问方式
HDFS基于这样的一个假设,最有限的数据处理模式是一次写入,多次读取,
多次读取数据用于分析数据,分析数据经常用于读取其中的大部分数据,即使不是全部,因此读取整个数据集所需要时间比读取第一条记录
的延时更重要(个人理解:因为要多次读取,而不仅仅是第一次读取)
3.运行于商业硬件上
Hadoop不需要特别贵的,可靠的机器,可运行在普通商用机器上,商用机器不代表低端,但是节点失败率可能较高,HDFS对于
集群中的这类节点失败不会让用户感觉到明显的中断
------HDFS不适合的应用类型:
1.低延时的数据访问
对延时要求较高,例如在毫秒级别的应用不适合使用HDFS,HDFS是为高吞吐数据传输设计的,因此可能牺牲延时时间,
如果期望低延时,可以考虑HBASE
2,大量小文件
文件的元数据(如目录结构,文件块(block)的节点列表,block节点的映射) 保存在NameNode的内存中 整个文件系统的文件数量
会受限于NameNode的内存大小。
经验而言,一个文件/目录/文件块一般占有150字节的元数据内存空间。如果有100万个文件,每个文件占用1个文件块,则需要
大约300M的内存。因此十亿级别的文件数量在现有商用机器上难以支持。
3.多方读写,需要任意的文件修改
HDFS采用追加(append-only)的方式写入数据。不支持文件任意offset的修改。不支持多个写入器(writer)。
三 HDFS的核心概念
------1.Blocks
物理磁盘中有块的概念,磁盘的物理Block是磁盘操作最小的单元,读写操作均以Block为最小单元,一般为512 Byte。文件系统在物理Block之上抽象了另一层概念,文件系统Block物理磁盘Block的整数倍。通常为几KB。Hadoop提供的df、fsck这类运维工具都是在文件系统的Block级别上进行操作。
HDFS的Block块比一般单机文件系统大得多,默认为128M。HDFS的文件被拆分成block-sized的chunk,chunk作为独立单元存储。比Block小的文件不会占用整个Block,只会占据实际大小。例如, 如果一个文件大小为1M,则在HDFS中只会占用1M的空间,而不是128M。
HDFS的Block为什么这么大?
是为了最小化查找(seek)时间,控制定位文件与传输文件所用的时间比例。假设定位到Block所需的时间为10ms,磁盘传输速度为100M/s。如果要将定位到Block所用时间占传输时间的比例控制1%,则Block大小需要约100M。 但是如果Block设置过大,在MapReduce任务中,Map或者Reduce任务的个数 如果小于集群机器数量,会使得作业运行效率很低。
Block抽象的好处
block的拆分使得单个文件大小可以大于整个磁盘的容量,构成文件的Block可以分布在整个集群, 理论上,单个文件可以占据集群中所有机器的磁盘。
Block的抽象也简化了存储系统,对于Block,无需关注其权限,所有者等内容(这些内容都在文件级别上进行控制)。
Block作为容错和高可用机制中的副本单元,即以Block为单位进行复制。
------2.NameNode 和DataNode
整个HDFS集群由Namenode和Datanode构成master-worker(主从)模式。Namenode负责构建命名空间,管理文件的元数据等,而Datanode负责实际存储数据,负责读写工作。
Namenode
Namenode存放文件系统树及所有文件、目录的元数据。元数据持久化为2种形式:
- namespcae image
- edit log
但是持久化数据中不包括Block所在的节点列表,及文件的Block分布在集群中的哪些节点上,这些信息是在系统重启的时候重新构建(通过Datanode汇报的Block信息)。
在HDFS中,Namenode可能成为集群的单点故障,Namenode不可用时,整个文件系统是不可用的。HDFS针对单点故障提供了2种解决机制:
1)备份持久化元数据
将文件系统的元数据同时写到多个文件系统, 例如同时将元数据写到本地文件系统及NFS。这些备份操作都是同步的、原子的。
2)Secondary Namenode
Secondary节点定期合并主Namenode的namespace image和edit log, 避免edit log过大,通过创建检查点checkpoint来合并。它会维护一个合并后的namespace image副本, 可用于在Namenode完全崩溃时恢复数据。下图为Secondary Namenode的管理界面:
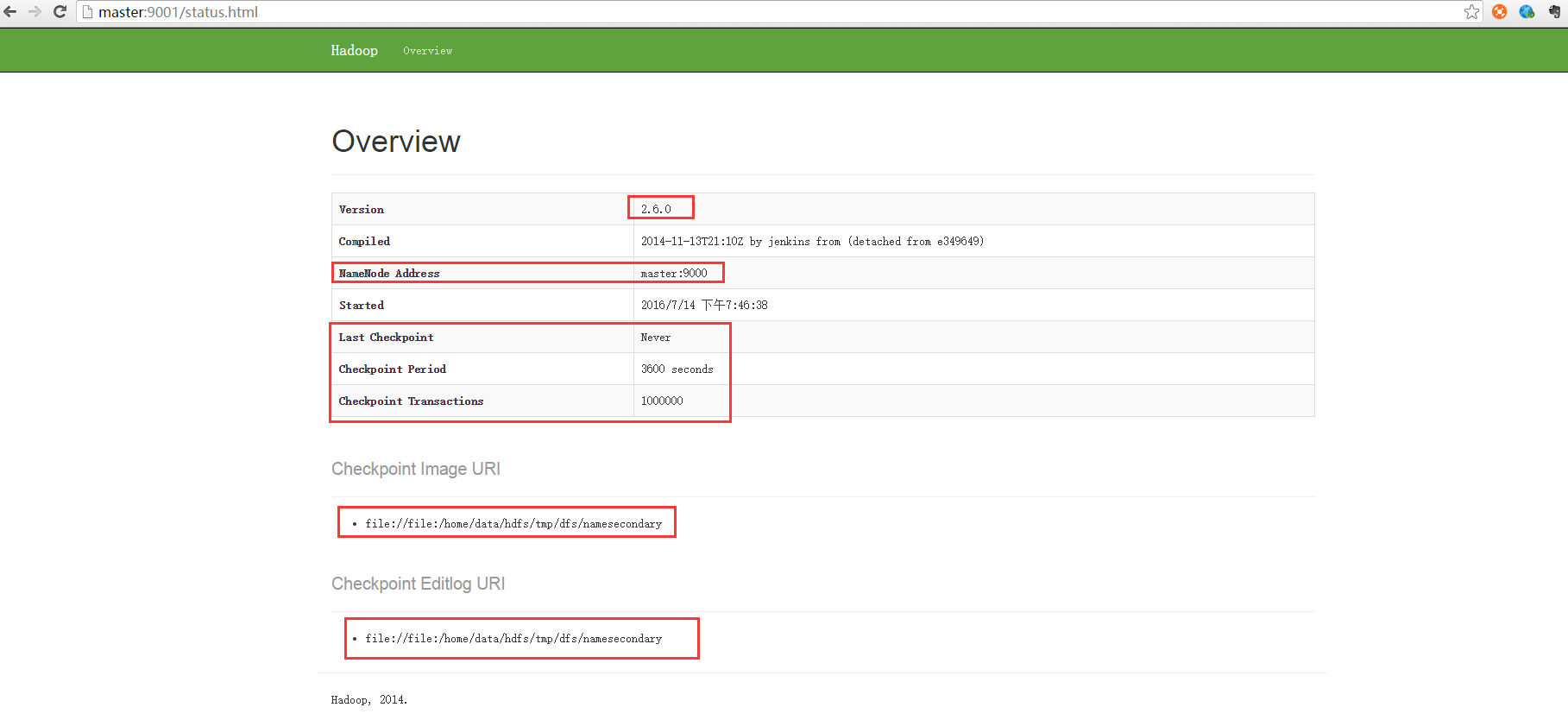
Secondary Namenode通常运行在另一台机器,因为合并操作需要耗费大量的CPU和内存。其数据落后于Namenode,因此当Namenode完全崩溃时,会出现数据丢失。 通常做法是拷贝NFS中的备份元数据到Second,将其作为新的主Namenode。 在HA(High Availability高可用性)中可以运行一个Hot Standby,作为热备份,在Active Namenode故障之后,替代原有Namenode成为Active Namenode。
Datanode
数据节点负责存储和提取Block,读写请求可能来自namenode,也可能直接来自客户端。数据节点周期性向Namenode汇报自己节点上所存储的Block相关信息。
HDFS学习笔记一的更多相关文章
- hadoop之HDFS学习笔记(二)
主要内容:hdfs的核心工作原理:namenode元数据管理机制,checkpoint机制:数据上传下载流程 1.hdfs的核心工作原理 1.1.namenode元数据管理要点 1.什么是元数据? h ...
- hadoop之HDFS学习笔记(一)
主要内容:hdfs的整体运行机制,DATANODE存储文件块的观察,hdfs集群的搭建与配置,hdfs命令行客户端常见命令:业务系统中日志生成机制,HDFS的java客户端api基本使用. 1.什么是 ...
- HDFS学习笔记(2)hdfs_shell & JavaAPI
FileSystem shell指令 官方文档: HDFS Commands Reference appendToFile cat checksum chgrp chmod chown copyFro ...
- HDFS学习笔记(1)初探HDFS
Hadoop分布式文件系统(Hadoop Distributed File System, HDFS) 分布式文件系统是一种同意文件通过网络在多台主机上分享的文件系统.可让多机器上的多用户分享文件和存 ...
- HDFS学习笔记二
文章来源于:https://blog.csdn.net/xuejingfu1/article/details/52554174 文件写入staging(分阶段进行) 一个客户端的创建文件的请求并不直接 ...
- Hadoop - HDFS学习笔记(详细)
第1章 HDFS概述 hdfs背景意义 hdfs是一个分布式文件系统 使用场景:适合一次写入,多次读出的场景,且不支持文件的修改. 优缺点 高容错性,适合处理大数据(数据PB级别,百万规模文件),可部 ...
- Hadoop学习笔记2 - 第一和第二个Map Reduce程序
转载请标注原链接http://www.cnblogs.com/xczyd/p/8608906.html 在Hdfs学习笔记1 - 使用Java API访问远程hdfs集群中,我们已经可以完成了访问hd ...
- hadoop学习笔记(四):HDFS文件权限,安全模式,以及整体注意点总结
本文原创,转载注明作者和原文链接! 一:总结注意点: 到现在为止学习到的角色:三个NameNode.SecondaryNameNode.DataNode 1.存储的是每一个文件分割存储之后的元数据信息 ...
- HDFS v1.0学习笔记
hdfs是一个用于存储大文件的分布式文件系统,是apache下的一个开源项目,使用java实现.它的设计目标是可以运行在廉价的设备上,运行在大多数的系统平台上,高可用,高容错,易于扩展. 适合场景 存 ...
随机推荐
- vue,一路走来(10)--生产环境
生产环境下的一些问题 使用webpack 打包前端应用后,图片和css.js 资源引用会出问题,这源于开发环境的目录和生产环境的路径[url]不同 比如,开发环境的url是:http://localh ...
- 使用macOS苹方替换Windows 10微软雅黑
关于微软雅黑 Windows从Vista开始用到现在的”微软雅黑”十多年以来基本没什么大改动,而大家的显示器从CRT进化到了IPS高分屏,十年前看着还OK的字体现在在绝大多数屏幕上可能就是这个样子的: ...
- hadoop_hdfs_上传文件报错
错误提示: INFO hdfs.DFSClient: Exception in createBlockOutputStream java.io.IOException: Bad connect ack ...
- Flutter-ListView
return Container( child: ListView( children: <Widget>[ Column( children: <Widget>[ Conta ...
- spring boot与ElasticSearch的集成
本文主要介绍Spring boot与ElasticSearch的集成,因为Spring boot的教程以及ElasticSearch的学习其他博客可能更优秀,所以建议再看这篇文章前先学习学习一下Spr ...
- 每天一个linux命令:head(15)
head head命令用于显示文件的开头的内容.在默认情况下,head命令显示文件的头10行内容. 格式 head [参数] [文件] 参数选项 参数 备注 -q 不显示文件名的头信息 -v 总是 ...
- 第二章--k-近邻算法(kNN)
一.k-近邻算法(kNN) 采用测量不同特征值之间的距离方法进行分类 工作原理: 存在一个样本数据集合(训练样本集),并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系.输 ...
- [CSU1806]Toll
题目:Toll 传送门:http://acm.csu.edu.cn/csuoj/problemset/problem?pid=1806 题目简述:给定n个点m条有向边的有向图,每条边的花费是$b_i ...
- inputAccessoryView,inputView
我们在使用UITextView和UITextField的时候,可以通过它们的inputAccessoryView属性给输入时呼出的键盘加一个附属视图,通常是UIToolBar,用于回收键盘. 但是当我 ...
- php7.0 新增运算符??
??是php7 新增符号 其作用近似于三目运算符 ?: 但存在着细微差别 比较示例代码如图: $b = $a?$a:2; 三目运算 <=> $e = $a??'ho ...