seaborn教程3——数据集的分布可视化
原文转载:https://segmentfault.com/a/1190000015006667
Seaborn学习大纲
seaborn的学习内容主要包含以下几个部分:
风格管理
- 绘图风格设置
- 颜色风格设置
绘图方法
数据集的分布可视化- 分类数据可视化
- 线性关系可视化
结构网格
- 数据识别网格绘图
本次将主要介绍数据集的分布可视化的使用。
数据集分布可视化
当处理一个数据集的时候,我们经常会想要先看看特征变量是如何分布的。这会让我们对数据特征有个很好的初始认识,同时也会影响后续数据分析以及特征工程的方法。本篇将会介绍如何使用 seaborn 的一些工具来检测单变量和双变量分布情况。
首先还是先导入需要的模块和数据集。
%matplotlib inline
import numpy as np
import pandas as pd
from scipy import stats, integrate
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(color_codes=True)
np.random.seed(sum(map(ord, "distributions")))
注意:这里的数据集是随机产生的分布数据,由 numpy 生成,数据类型是ndarray。当然,pandas 的 Series 数据类型也是可以使用的,比如我们经常需要从 DataFrame 表中提取某一特征(某一列)来查看分布情况。
1、绘制单变量分布
在 seaborn 中,快速观察单变量分布的最方便的方法就是使用 distplot() 函数。
1.1 默认会使用柱状图(histogram)来绘制,并提供一个适配的核密度估计(KDE)。
x = np.random.normal(size=100)
sns.distplot(x);

1.2 直方图(histograms)
直方图是比较常见的,并且在 matplotlib 中已经存在了 hist 函数。直方图在横坐标的数据值范围内均等分的形成一定数量的数据段(bins),并在每个数据段内用矩形条(bars)显示y轴观察数量的方式,完成了对的数据分布的可视化展示。
为了说明这个,我们可以移除 kde plot,然后添加 rug plot(在每个观察点上的垂直小标签)。当然,你也可以使用 rug plot 自带的 rugplot() 函数,但是也同样可以在 distplot 中实现:
sns.distplot(x, kde=False, rug=True);
当绘制直方图时,你最需要确定的参数是矩形条的数目以及如何放置它们。distplot()使用了一个简单的规则推测出默认情况下最合适的数量,但是或多或少的对 bins 数量进行一些尝试也许能找出数据的其它特征
sns.distplot(x, bins=20, kde=False, rug=True);
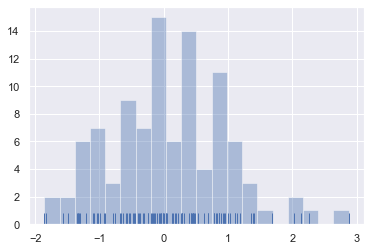
1.3 核密度估计(Kernel density estimation)
核密度估计可能不被大家所熟悉,但它对于绘制分布的形状是一个非常有用的工具。就像直方图那样,KDE plots 会在一个轴上通过高度沿着其它轴将观察的密度编码。
sns.distplot(x, hist=False, rug=True);
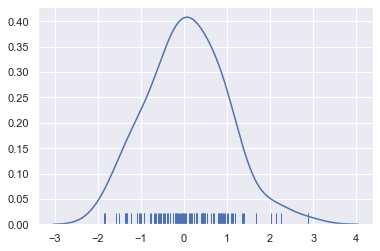
绘制 KDE 比绘制直方图需要更多的计算。它的计算过程是这样的,每个观察点首先都被以这个点为中心的正态分布曲线所替代。
x = np.random.normal(0, 1, size=30)
bandwidth = 1.06 * x.std() * x.size ** (-1 / 5.)
support = np.linspace(-4, 4, 200) kernels = []
for x_i in x: kernel = stats.norm(x_i, bandwidth).pdf(support)
kernels.append(kernel)
plt.plot(support, kernel, color="r") sns.rugplot(x, color=".2", linewidth=3);
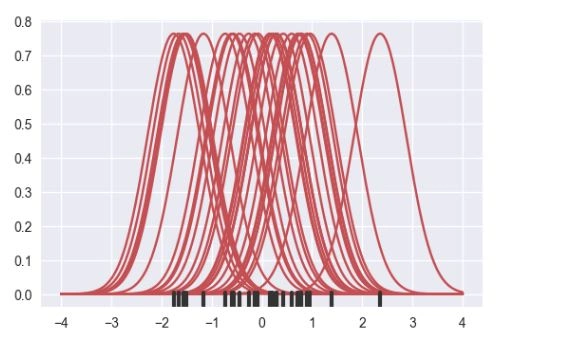
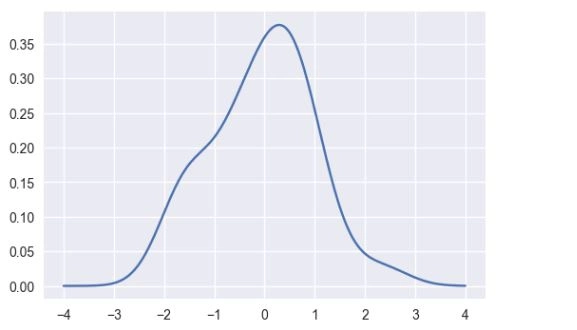
然后,这些替代的曲线进行加和,并计算出在每个点的密度值。最终生成的曲线被归一化,以使得曲线下面包围的面积是1。
density = np.sum(kernels, axis=0)
density /= integrate.trapz(density, support)
plt.plot(support, density);
我们可以看到,如果我们使用 kdeplot() 函数,我们可以得到相同的曲线。这个函数实际上也被 distplot() 所使用,但是如果你就只想要密度估计,那么 kdeplot() 会提供一个直接的接口更简单的操作其它选项。
sns.kdeplot(x, shade=True);
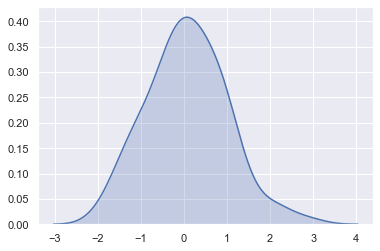
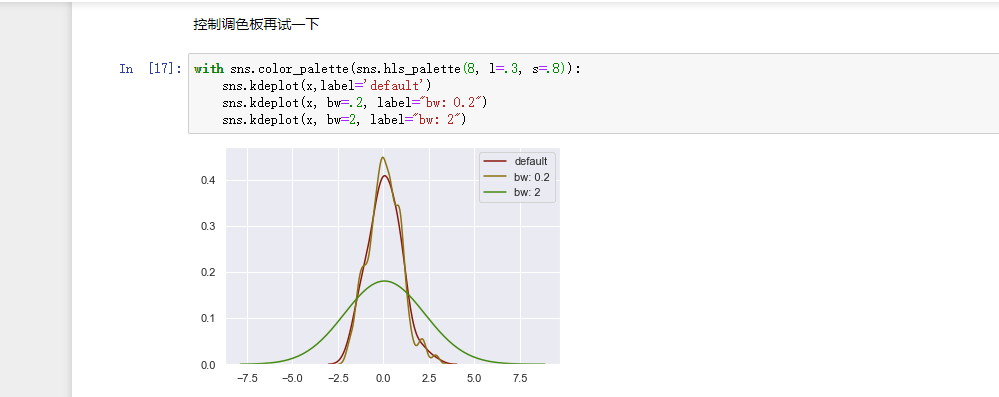
KDE 的带宽参数(bw)控制着密度估计曲线的宽窄形状,有点类似直方图中的 bins 参数的作用。它对应着我们上面绘制的 KDE 的宽度。默认情况下,函数会按照一个通用的参考规则来估算出一个合适的值,但是尝试更大或者更小也可能会有帮助:
sns.kdeplot(x,label='default')
sns.kdeplot(x, bw=.2, label="bw: 0.2")
sns.kdeplot(x, bw=2, label="bw: 2")
plt.legend();

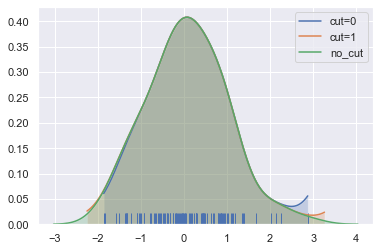
如上所述,高斯KDE过程的意味着估计延续了数据集中最大和最小的值。 可以通过cut参数来控制绘制曲线的极值值的距离; 然而,这只影响曲线的绘制方式,而不是曲线如何拟合:
sns.kdeplot(x, shade=True, cut=0,label='cut=0')
sns.kdeplot(x, shade=True, cut=1,label='cut=1')
sns.kdeplot(x, shade=True,label='no_cut')
sns.rugplot(x);
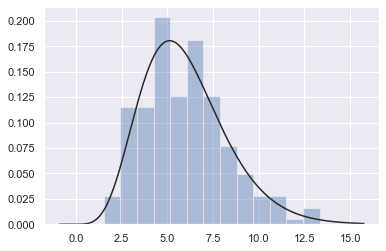
1.4 拟合参数分布
你也可以使用distplot()将参数分布拟合到数据集,并可视化地评估其与观察数据的对应程度:
x = np.random.gamma(6, size=200)
sns.distplot(x, kde=False, fit=stats.gamma);
2、绘制双变量分布
对于双变量分布的可视化也是非常有用的。在 seaborn 中最简单的方法就是使用 joinplot() 函数,它能够创建一个多面板图形来展示两个变量之间的联合关系,以及每个轴上单变量的分布情况。
mean, cov = [0, 1], [(1, .5), (.5, 1)]
data = np.random.multivariate_normal(mean, cov, 200)
df = pd.DataFrame(data, columns=["x", "y"])
2.1 Scatterplots
双变量分布最熟悉的可视化方法无疑是散点图了,在散点图中每个观察结果以x轴和y轴值所对应的点展示。你可以用 matplotlib 的 plt.scatter 函数来绘制一个散点图,它也是jointplot()函数显示的默认方式。
plt.scatter(x="x", y="y", data=df)

sns.jointplot(x="x", y="y", data=df)

2.2 Hexbin plots
直方图 histogram 的双变量类似图被称为 “hexbin” 图,因为它展示了落在六角形箱内的观测量。这种绘图对于相对大的数据集效果最好。它可以通过 matplotlib 的 plt.hexbin 函数使用,也可以作为 jointplot 的一种类型参数使用。它使用白色背景的时候视觉效果最好。
x, y = np.random.multivariate_normal(mean, cov, 1000).T
with sns.axes_style("white"):
sns.jointplot(x=x, y=y, kind="hex", color="k");

2.3 Kernel density estimation
还使用上面描述的核密度估计过程来可视化双变量分布。在 seaborn 中,这种绘图以等高线图展示,并且可以作为 jointplot()的一种类型参数使用。
sns.jointplot(x="x", y="y", data=df, kind="kde");

2.4 你也可以用 kdeplot 函数来绘制一个二维的核密度图形。这可以将这种绘图绘制到一个特定的(可能已经存在的)matplotlib轴上,而jointplot()函数只能管理自己:
f, ax = plt.subplots(figsize=(6, 6))
sns.kdeplot(df.x, df.y, ax=ax)
sns.rugplot(df.x, color="g", ax=ax)
sns.rugplot(df.y, vertical=True, ax=ax);
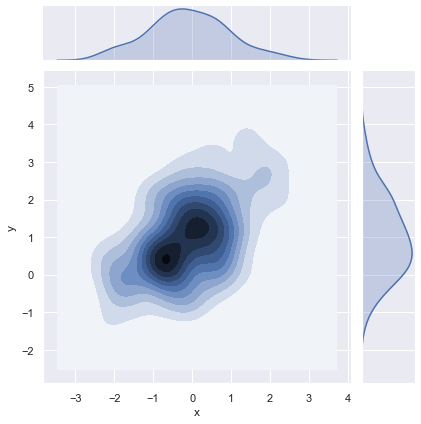
如果你希望让双变量密度看起来更连续,您可以简单地增加 n_levels 参数增加轮廓级数:
f, ax = plt.subplots(figsize=(6, 6))
cmap = sns.cubehelix_palette(as_cmap=True, dark=0, light=1, reverse=True)
sns.kdeplot(df.x, df.y, cmap=cmap, n_levels=60, shade=True);
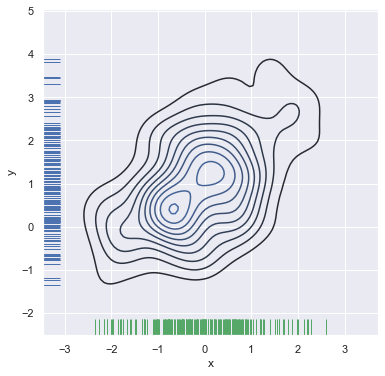
如果你希望让双变量密度看起来更连续,您可以简单地增加 n_levels 参数增加轮廓级数:
f, ax = plt.subplots(figsize=(6, 6))
cmap = sns.cubehelix_palette(as_cmap=True, dark=0, light=1, reverse=True)
sns.kdeplot(df.x, df.y, cmap=cmap, n_levels=60, shade=True);
2.5 jointplot()函数使用JointGrid来管理图形。
为了获得更多的灵活性,您可能需要直接使用JointGrid绘制图形。jointplot()在绘制后返回JointGrid对象,你可以用它来添加更多层或调整可视化的其他方面:
g = sns.jointplot(x="x", y="y", data=df, kind="kde", color="m")
g.plot_joint(plt.scatter, c="w", s=30, linewidth=1, marker="+")
g.ax_joint.collections[0].set_alpha(0)
g.set_axis_labels("$X$", "$Y$");
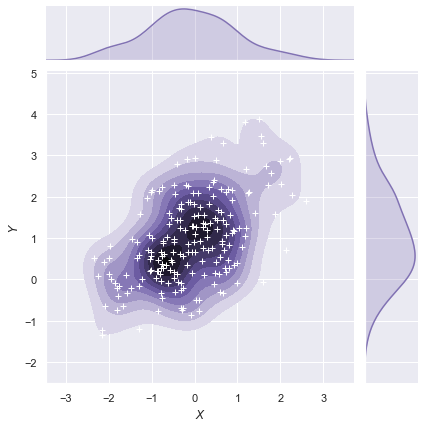
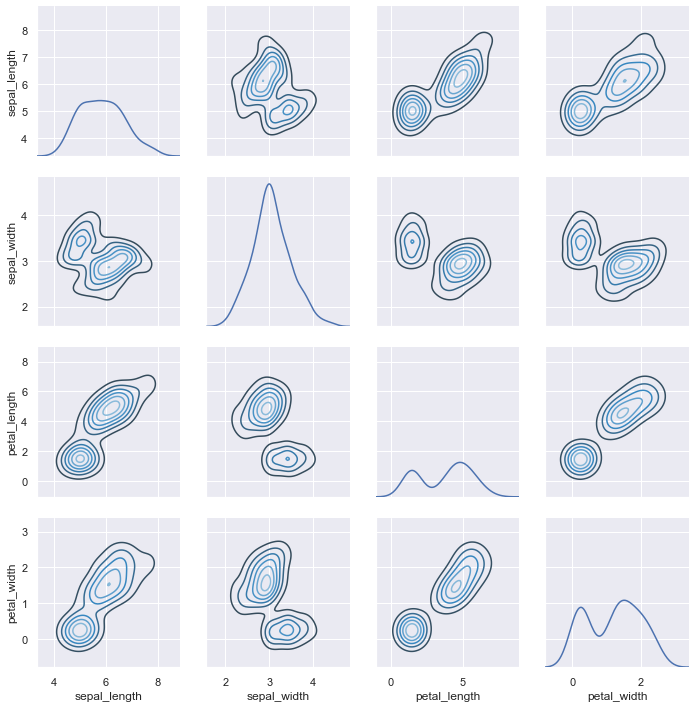
3、可视化数据集成对关系
为了绘制数据集中多个成对的双变量,你可以使用 pairplot() 函数。这创建了一个轴矩阵,并展示了在一个 DataFrame 中每对列的关系。默认情况下,它也绘制每个变量在对角轴上的单变量。
iris = sns.load_dataset("iris")
sns.pairplot(iris);

就像 joinplot() 和 JoinGrid 之间的关系,pairplot() 函数建立在 PairGrid 对象之上,直接使用可以更灵活。
g = sns.PairGrid(iris)
g.map_diag(sns.kdeplot)
g.map_offdiag(sns.kdeplot, cmap="Blues_d", n_levels=6);
seaborn教程3——数据集的分布可视化的更多相关文章
- seaborn教程4——分类数据可视化
https://segmentfault.com/a/1190000015310299 Seaborn学习大纲 seaborn的学习内容主要包含以下几个部分: 风格管理 绘图风格设置 颜色风格设置 绘 ...
- seaborn教程2——颜色调控
原文转载 https://segmentfault.com/a/1190000014966210 Seaborn学习大纲 seaborn的学习内容主要包含以下几个部分: 风格管理 绘图风格设置 颜色风 ...
- seaborn教程1——风格选择
原文链接:https://segmentfault.com/a/1190000014915873 Seaborn学习大纲 seaborn的学习内容主要包含以下几个部分: 风格管理 绘图风格设置 颜色风 ...
- Seaborn(二)之数据集分布可视化
Seaborn(二)之数据集分布可视化 当处理一个数据集的时候,我们经常会想要先看看特征变量是如何分布的.这会让我们对数据特征有个很好的初始认识,同时也会影响后续数据分析以及特征工程的方法.本篇将会介 ...
- Python Seaborn综合指南,成为数据可视化专家
概述 Seaborn是Python流行的数据可视化库 Seaborn结合了美学和技术,这是数据科学项目中的两个关键要素 了解其Seaborn作原理以及使用它生成的不同的图表 介绍 一个精心设计的可视化 ...
- 怎么用Q-Q图验证数据集的分布
样本数据集在构建机器学习模型的过程中具有重要的作用,样本数据集包括训练集.验证集.测试集,其中训练集和验证集的作用是对学习模型进行参数择优,测试集是测试该模型的泛化能力. 正负样本数据集符合独立同分布 ...
- 【观隅】数据集管理与可视化平台-NABCD分析
项目 内容 这个作业属于哪个课程 2021春季软件工程(罗杰 任健) 这个作业的要求在哪里 团队项目-初次邂逅,需求分析 项目介绍 观隅 数据集管理与可视化平台(取"观一隅而知全局" ...
- pyecharts实现星巴克门店分布可视化分析
项目介绍 使用pyecharts对星巴克门店分布进行可视化分析: 全球门店分布/拥有星巴克门店最多的10个国家或地区: 拥有星巴克门店最多的10个城市: 门店所有权占比: 中国地区门店分布热点图. 数 ...
- node.js零基础详细教程(7.5):mongo可视化工具webstorm插件、nodejs自动重启模块Node Supervisor(修改nodejs后不用再手动命令行启动服务了)
第七章 建议学习时间4小时 课程共10章 学习方式:详细阅读,并手动实现相关代码 学习目标:此教程将教会大家 安装Node.搭建服务器.express.mysql.mongodb.编写后台业务逻辑. ...
随机推荐
- [简单到爆]eclipse-jee-neon的下载和安装
Eclipse的下载安装: 访问https://www.eclipse.org/downloads/eclipse-packages/ 选择Eclipse IDE for Java EE Develo ...
- centos7卸载YUM后重装过程 -bash: yum: command not found / -bash: yum: 未找到命令
[root@localhost ~]# rpm -qa |grep yum yum-3.4.3-158.el7.centos.noarch yum-plugin-fastestmirror-1.1.3 ...
- mysql 导出表中数据为excel的xls格式文件
需求: 利用mysql客户端导出数据库中数据,以便进行分析,统计. 解决命令: 在windos命令行(linux同理)下,用如下命令即可: mysql -hlocalhost -uroot -ppas ...
- Git命令——撤销修改
Git命令 1. 撤销修改 (1) 当改乱了工作区(working directory)某个文件的内容,想直接丢弃工作区中的修改时,用命令git checkout -- file. (2) 当不但改乱 ...
- Linux 部署或升级openssh7.5p1
运维Linux系统,部署或升级openssh是经常面临的事,以下已redhat6和redhat7为例. 在redhat6中部署openssh会有什么坑,在编辑openssh源码包时会报一些类似的错误, ...
- CSS3 多列布局——Columns
CSS3 多列布局——Columns 语法: columns:<column-width> || <column-count> 多列布局columns属性参数主要就两个属性参数 ...
- 转Serial,Parallel,CMS,G1四大GC收集器特点小结
转 https://blog.csdn.net/u013812939/article/details/48782343 1.Serial收集器 一个单线程的收集器,在进行垃圾收集时候,必须暂停其他所有 ...
- Web开发中的服务器跳转与客户端跳转
两者比较如下: 跳转类型 客户端请求次数 服务端响应次数 URL变化 站外跳转 作用域 服务器跳转 1 1 无 否 pageContext.request.session.application 客 ...
- CSS中浮动属性float及清除浮动
1.float属性 CSS 的 Float(浮动),会使元素向左或向右移动,由于浮动的元素会脱离文档流,所以它后面的元素会重新排列. 浮动元素之后的那些元素将会围绕它,而浮动元素之前的元素将不会受到影 ...
- 容器宽高不确定,图片宽高不确定,css如何实现图片响应式?
图片响应式 在响应式开发中最烦恼的应该就是图片了,虽然图片设置max-width: 100%;可以让图片宽度占满容器,但是高度就不能自适应了.如果将容器高度限死,那么我们就要使用媒体查询来控制容器的高 ...