Hadoop实战内容摘记
Hadoop 开源分布式计算平台,前身是:Apache Nutch(爬虫),Lucene(中文搜索引擎)子项目之一。
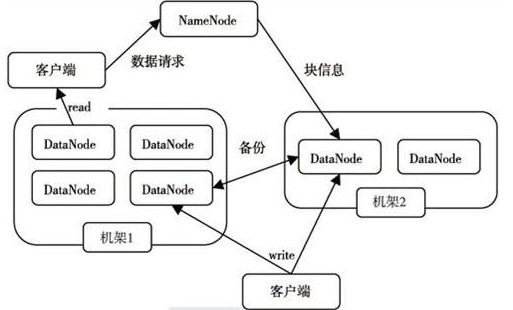
以Hadoop分布式计算文件系统(Hadoop Distributed File System HDFS)和MapReduce(Google MapReduce的开源实现)为核心 的Hadoop基础架构。
HDFS的高容错性、搞伸缩性等优点可以将Hadoop部署在廉价版的硬件上,形成分布式系统;
MapReduce分布式编程模型,利用这种模型软件开发者可以轻松地编写出分布式并行程序。
优势:
1、高可靠性:按位储存和处理数据的能力指的信赖。
2、高扩展性:在可用的计算机集簇间分配数据完成计算任务,这些集簇可以扩展到数以千计的节点中。
3、高效性:能够在节点之间动态的移动数据,已保证各个节点的动态平衡,因此处理速度非常快。
4、高容错性:Hadoop能够自动保存数据的多分副本,并且能够自动将失败的任务重新分配。
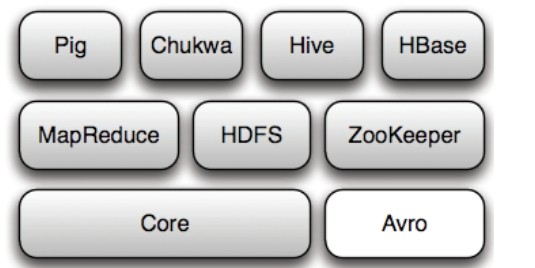
Hadoop项目极其结构
hadoop核心是MapReduce(编程模型)和HDFS(计算系统)

Hadoop实战内容摘记的更多相关文章
- Hadoop on Mac with IntelliJ IDEA - 10 陆喜恒. Hadoop实战(第2版)6.4.1(Shuffle和排序)Map端 内容整理
下午对着源码看陆喜恒. Hadoop实战(第2版)6.4.1 (Shuffle和排序)Map端,发现与Hadoop 1.2.1的源码有些出入.下面作个简单的记录,方便起见,引用自书本的语句都用斜体表 ...
- 云计算分布式大数据Hadoop实战高手之路第八讲Hadoop图文训练课程:Hadoop文件系统的操作实战
本讲通过实验的方式讲解Hadoop文件系统的操作. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发布云 ...
- Hadoop实战实例
Hadoop实战实例 Hadoop实战实例 Hadoop 是Google MapReduce的一个Java实现.MapReduce是一种简化的分布式编程模式,让程序自动分布 ...
- 升级版:深入浅出Hadoop实战开发(云存储、MapReduce、HBase实战微博、Hive应用、Storm应用)
Hadoop是一个分布式系统基础架构,由Apache基金会开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力高速运算和存储.Hadoop实现了一个分布式文件系 ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
- 云计算分布式大数据Hadoop实战高手之路第七讲Hadoop图文训练课程:通过HDFS的心跳来测试replication具体的工作机制和流程
这一讲主要深入使用HDFS命令行工具操作Hadoop分布式集群,主要是通过实验的配置hdfs-site.xml文件的心跳来测试replication具体的工作和流程. 通过HDFS的心跳来测试repl ...
- Hadoop实战之三~ Hello World
本文介绍的是在Ubuntu下安装用三台PC安装完成Hadoop集群并运行好第一个Hello World的过程,软硬件信息如下: Ubuntu:12.04 LTS Master: 1.5G RAM,奔腾 ...
- hadoop基础----hadoop实战(七)-----hadoop管理工具---使用Cloudera Manager安装Hadoop---Cloudera Manager和CDH5.8离线安装
hadoop基础----hadoop实战(六)-----hadoop管理工具---Cloudera Manager---CDH介绍 简介 我们在上篇文章中已经了解了CDH,为了后续的学习,我们本章就来 ...
- 【VS开发】【智能语音处理】MATLAB 与 音频处理 相关内容摘记
MATLAB 与 音频处理 相关内容摘记 MATLAB 与 音频处理 相关内容摘记 1 MATLAB 音频相关函数 1 MATLAB 处理音频信号的流程 2 音量标准化 2 声道分离合并与组合 3 数 ...
随机推荐
- Result window is too large, from + size must be less than or equal to: [10000] but was [78440]. See the scroll api for a more efficient way to request large data sets
{"error":{"root_cause":[{"type":"query_phase_execution_exception& ...
- Dinic最大流 || Luogu P3376 【模板】网络最大流
题面:[模板]网络最大流 代码: #include<cstring> #include<cstdio> #include<iostream> #define min ...
- u-boot makefile $$
define filechk_uboot.release echo "$(UBOOTVERSION)$$($(CONFIG_SHELL) $(srctree)/scripts/setl ...
- Android Studio的安装
下载Android Studio(需要翻墙才能安装得快):直接到官网进行下载就可以了.下载地址:https://developer.android.com/ “Android Virtual Devi ...
- Python----公开课
# 构造函数- 类在实例化的时候,执行一些基础性的初始化的工作- 使用特殊的名称和写法- 在实例化的时候自动执行- 是在实例化的时候第一个被执行的函数- ----------------------- ...
- 【leetcode】410. Split Array Largest Sum
题目如下: Given an array which consists of non-negative integers and an integer m, you can split the arr ...
- DI,依赖注入,给对象赋值 ,get,set
DI,依赖注入,给对象赋值 ,get,set给对象赋值 2种方式:1.get.set默认无参构造方法给对象赋值 2.xml中有参构造器方法给对象赋值
- 对SQL 优化,提升性能!
对SQL 进行优化能够有效提高SQL 语句的执行效率,降低系统资源开销,是开发者提高后端系统处理能力的首选方案. 新产品上线后,随着运营推广活动的开始,业务进入快速增长期,数据库作为后端系统唯一或者主 ...
- HOJ 2315 Time(模拟)
Description Kim是一个掌控时间的大师.不同于一般人,他习惯使用秒来计算时间.如果你问他现在是几点,他会告诉你现在是今天的xxxx秒.Mik想要考考Kim.他想知道从某一天的00:00:0 ...
- k8s从Harbor拉取启动镜像测试
登陆harbor [root@k8s-master ~]# docker login 192.168.180.105:1180 Username: admin Password: WARNING! Y ...