[论文理解] Receptive Field Block Net for Accurate and Fast Object Detection
Receptive Field Block Net for Accurate and Fast Object Detection
简介
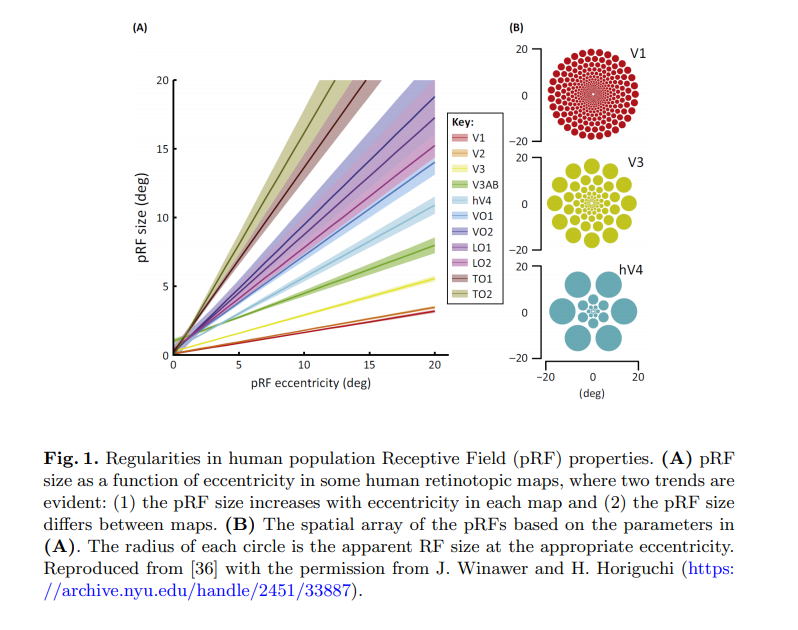
本文在SSD基础上提出了RFB Module,利用神经科学的先验知识来解释这种效果提升。本质上是设计一种新的结构来提升感受野,并表明了人类视网膜的感受野有一个特点,离视线中心越远,其感受野是越大的,越靠近视线中间,感受野越小。基于此,本文提出的RFB Module就是来模拟人类这种视觉特点的。
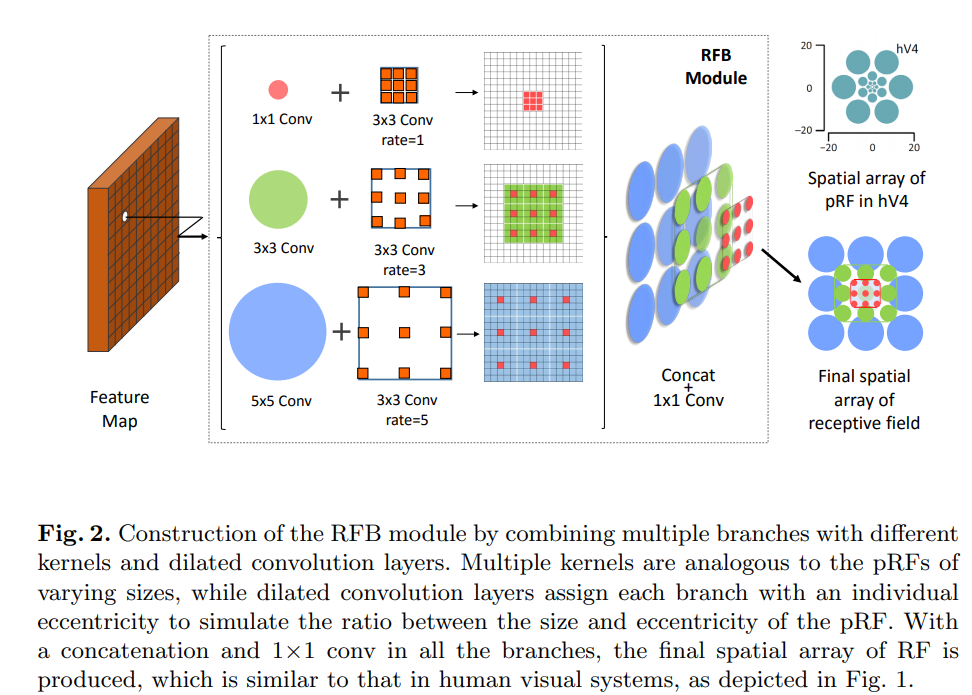
RFB Module
结构如下图所示。
为什么要用空洞卷积呢?
首先要提高感受野,直观的想法就是要么加深层数,要么使用更大的卷积核,要么就是卷积之前使用pooling。加深层数网络参数就会变多,没法完成轻量级的任务;更大的卷积核一样参数也会变多;pooling虽然不会增加参数,但是会使信息损失,不利于后面层的信息传递。所以作者这里很自然的想到用空洞卷积,既不增加参数量,又能够提高感受野。
为什么要用这种多分支结构呢?
这是为了捕捉不同感受野的信息,如前面提到的,人类视野的特点就是距视野中心距离不同感受野不同,所以使用多分支结构,每个分支捕捉一种感受野,最后通过concat来融合感受野信息,就能达到模拟人类视觉的效果了。作者这里也给了一张图来说明。
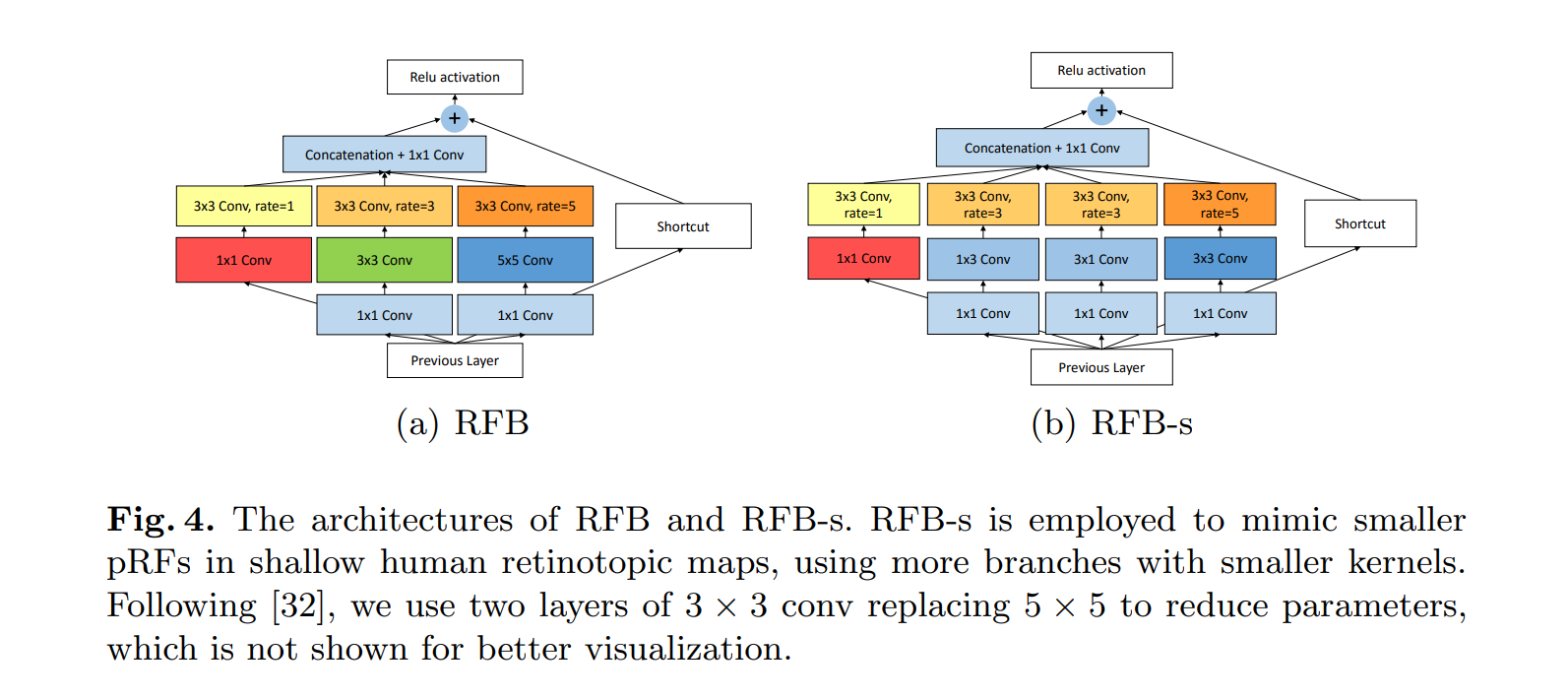
为什么要提出两种版本的RFB呢?
左边的结构是原始的RFB,右边的结构相比RFB把3×3的conv变成了两个1×3和3×1的分支,一是减少了参数量,二是增加了更小的感受野,这样也是在模拟人类视觉系统,捕捉更小的感受野。
网络结构
整体网络结构如下所示,很好理解。
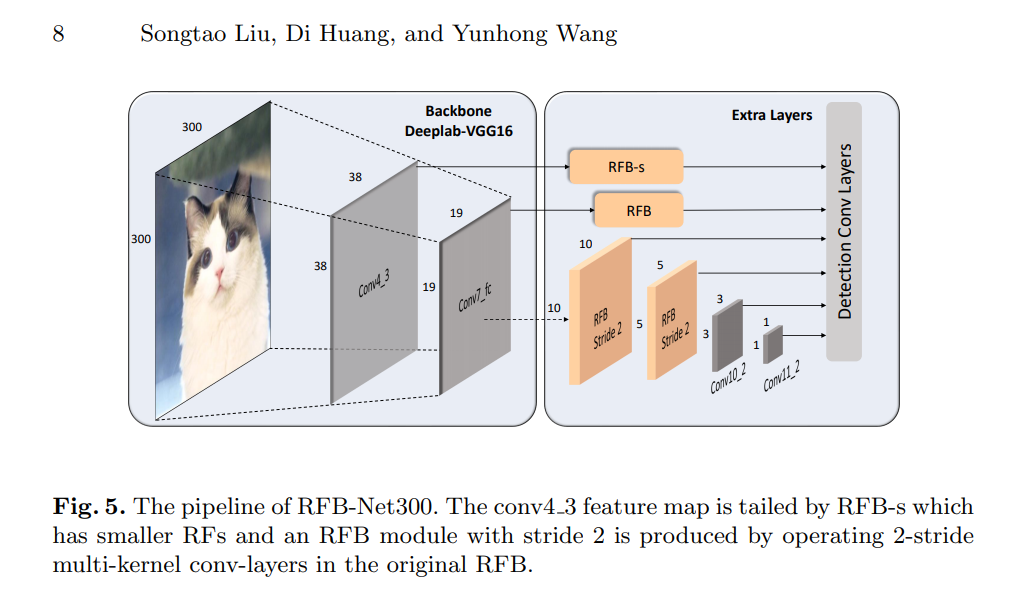
前面就是vgg19,然后从中间的层分出6个预测分支,比较好理解没啥记的。
代码复现
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchsummary import summary
class RFBModule(nn.Module):
def __init__(self,out,stride = 1):
super(RFBModule,self).__init__()
self.s1 = nn.Sequential(
nn.Conv2d(out,out,kernel_size = 1),
nn.Conv2d(out,out,kernel_size=3,dilation = 1,padding = 1,stride = stride)
)
self.s2 = nn.Sequential(
nn.Conv2d(out,out,kernel_size =1),
nn.Conv2d(out,out,kernel_size=3,padding = 1),
nn.Conv2d(out,out,kernel_size=3,dilation = 3,padding = 3,stride = stride)
)
self.s3 = nn.Sequential(
nn.Conv2d(out,out,kernel_size =1),
nn.Conv2d(out,out,kernel_size = 5,padding =2),
nn.Conv2d(out,out,kernel_size=3,dilation=5,padding = 5,stride = stride)
)
self.shortcut = nn.Conv2d(out,out,kernel_size = 1,stride = stride)
self.conv1x1 = nn.Conv2d(out*3,out,kernel_size =1)
def forward(self,x):
s1 = self.s1(x)
s2 = self.s2(x)
s3 = self.s3(x)
#print(s1.size(),s2.size(),s3.size())
mix = torch.cat([s1,s2,s3],dim = 1)
mix = self.conv1x1(mix)
shortcut = self.shortcut(x)
return mix + shortcut
class RFBsModule(nn.Module):
def __init__(self,out,stride = 1):
super(RFBsModule,self).__init__()
self.s1 = nn.Sequential(
nn.Conv2d(out,out,kernel_size = 1),
nn.Conv2d(out,out,kernel_size=3,dilation = 1,padding = 1,stride = stride)
)
self.s2 = nn.Sequential(
nn.Conv2d(out,out,kernel_size =1),
nn.Conv2d(out,out,kernel_size=(1,3),padding = (0,1)),
nn.Conv2d(out,out,kernel_size=3,dilation = 3,padding = 3,stride = stride)
)
self.s3 = nn.Sequential(
nn.Conv2d(out,out,kernel_size =1),
nn.Conv2d(out,out,kernel_size = (3,1),padding =(1,0)),
nn.Conv2d(out,out,kernel_size=3,dilation=3,padding = 3,stride = stride)
)
self.s4 = nn.Sequential(
nn.Conv2d(out,out,kernel_size =1),
nn.Conv2d(out,out,kernel_size=3),
nn.Conv2d(out,out,kernel_size = 3,dilation = 5,stride = stride,padding = 6)
)
self.shortcut = nn.Conv2d(out,out,kernel_size = 1,stride = stride)
self.conv1x1 = nn.Conv2d(out*4,out,kernel_size =1)
def forward(self,x):
s1 = self.s1(x)
s2 = self.s2(x)
s3 = self.s3(x)
s4 = self.s4(x)
#print(s1.size(),s2.size(),s3.size(),s4.size())
#print(s1.size(),s2.size(),s3.size())
mix = torch.cat([s1,s2,s3,s4],dim = 1)
mix = self.conv1x1(mix)
shortcut = self.shortcut(x)
return mix + shortcut
class RFBNet(nn.Module):
def __init__(self):
super(RFBNet,self).__init__()
self.feature_1 = nn.Sequential(
nn.Conv2d(3,64,kernel_size = 3,padding = 1),
nn.ReLU(),
nn.Conv2d(64,64,kernel_size=3,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size = 2,stride = 2),
nn.Conv2d(64,128,kernel_size = 3,padding = 1),
nn.ReLU(),
nn.Conv2d(128,128,kernel_size=3,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size = 2,stride = 2),
nn.Conv2d(128,256,kernel_size = 3,padding = 1),
nn.ReLU(),
nn.Conv2d(256,256,kernel_size=3,padding=1),
nn.ReLU(),
nn.Conv2d(256,256,kernel_size=3,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size = 2,stride = 2),
nn.Conv2d(256,512,kernel_size = 3,padding = 1),
nn.ReLU(),
nn.Conv2d(512,512,kernel_size=3,padding=1),
nn.ReLU(),
nn.Conv2d(512,512,kernel_size=3,padding=1),
nn.ReLU(),
)
self.feature_2 = nn.Sequential(
nn.MaxPool2d(kernel_size = 2,stride = 2),
nn.Conv2d(512,512,kernel_size = 3,padding = 1),
nn.ReLU(),
nn.Conv2d(512,512,kernel_size=3,padding=1),
nn.ReLU(),
nn.Conv2d(512,512,kernel_size=3,padding=1),
nn.ReLU(),
)
self.pre = nn.Conv2d(512,64,kernel_size = 1)
self.fc = nn.Conv2d(512,64,kernel_size = 1)
self.det1 = RFBsModule(out = 64,stride = 1)
self.det2 = RFBModule(out = 64,stride = 1)
self.det3 = RFBModule(out = 64,stride = 2)
self.det4 = RFBModule(out = 64,stride = 2)
self.det5 = nn.Conv2d(64,64,kernel_size = 3)
self.det6 = nn.Conv2d(64,64,kernel_size=3)
def forward(self,x):
x = self.feature_1(x)
det1 = self.det1(self.fc(x))
x = self.feature_2(x)
x = self.pre(x)
det2 = self.det2(x)
det3 = self.det3(det2)
det4 = self.det4(det3)
det5 = self.det5(det4)
det6 = self.det6(det5)
det1 = det1.permute(0,2,3,1).contiguous().view(x.size(0),-1,64)
det2 = det2.permute(0,2,3,1).contiguous().view(x.size(0),-1,64)
det3 = det3.permute(0,2,3,1).contiguous().view(x.size(0),-1,64)
det4 = det4.permute(0,2,3,1).contiguous().view(x.size(0),-1,64)
det5 = det5.permute(0,2,3,1).contiguous().view(x.size(0),-1,64)
det6 = det6.permute(0,2,3,1).contiguous().view(x.size(0),-1,64)
return torch.cat([det1,det2,det3,det4,det5,det6],dim = 1)
if __name__ == "__main__":
net = RFBNet()
x = torch.randn(2,3,300,300)
summary(net,(3,300,300),device = "cpu")
print(net(x).size())
论文原文:https://arxiv.org/pdf/1711.07767.pdf
[论文理解] Receptive Field Block Net for Accurate and Fast Object Detection的更多相关文章
- Paper Reading:Receptive Field Block Net for Accurate and Fast Object Detection
论文:Receptive Field Block Net for Accurate and Fast Object Detection 发表时间:2018 发表作者:(Beihang Universi ...
- Receptive Field Block Net for Accurate and Fast Object Detection
Receptive Field Block Net for Accurate and Fast Object Detection 作者:Songtao Liu, Di Huang*, and Yunh ...
- 论文阅读笔记五十一:CenterNet: Keypoint Triplets for Object Detection(CVPR2019)
论文链接:https://arxiv.org/abs/1904.08189 github:https://github.com/Duankaiwen/CenterNet 摘要 目标检测中,基于关键点的 ...
- [论文理解] Acquisition of Localization Confidence for Accurate Object Detection
Acquisition of Localization Confidence for Accurate Object Detection Intro 目标检测领域的问题有很多,本文的作者捕捉到了这样一 ...
- 论文阅读笔记三十三:Feature Pyramid Networks for Object Detection(FPN CVPR 2017)
论文源址:https://arxiv.org/abs/1612.03144 代码:https://github.com/jwyang/fpn.pytorch 摘要 特征金字塔是用于不同尺寸目标检测中的 ...
- [论文理解] CBAM: Convolutional Block Attention Module
CBAM: Convolutional Block Attention Module 简介 本文利用attention机制,使得针对网络有了更好的特征表示,这种结构通过支路学习到通道间关系的权重和像素 ...
- 【计算机视觉】【神经网络与深度学习】论文阅读笔记:You Only Look Once: Unified, Real-Time Object Detection
尊重原创,转载请注明:http://blog.csdn.net/tangwei2014 这是继RCNN,fast-RCNN 和 faster-RCNN之后,rbg(Ross Girshick)大神挂名 ...
- 论文阅读笔记二十七:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks(CVPR 2016)
论文源址:https://arxiv.org/abs/1506.01497 tensorflow代码:https://github.com/endernewton/tf-faster-rcnn 室友对 ...
- 机器视觉:Convolutional Neural Networks, Receptive Field and Feature Maps
CNN 大概是目前 CV 界最火爆的一款模型了,堪比当年的 SVM.从 2012 年到现在,CNN 已经广泛应用于CV的各个领域,从最初的 classification,到现在的semantic se ...
随机推荐
- ccs之经典布局(三)(等分,等高布局)
接上篇ccs之经典布局(二)(两栏,三栏布局) 七.等分布局 等分布局是指一行被分为若干列,每一列的宽度是相同的值.两列之间有若干的距离. 1.float+padding+background-cli ...
- 第五篇 CSS入门 明白 三种嵌套形式,三种常用控制器
CSS入门 css是 层叠式样式表 css的作用是什么呢?举个抽象的例子啊,HTML是人,CSS则是衣服... css给html穿上衣服,有三种形式: 内嵌.内联.外联. 这三种形式,优先级为 ...
- mybatis postgresql insert后返回自增id
在使用mybatis + postgresql,我们有时在插入数据时需要返回自增id的值,此时在插入时,可以按照以下例子来编写mapper文件 <insert id="insertUs ...
- 使用maven构建dubbo服务的可执行jar包+Dubbo 程序实例
https://blog.csdn.net/zsg88/article/details/76100482 https://blog.csdn.net/zsg88/article/details/762 ...
- monkey基础使用教程,如何安装和monkey分析日志
1.概念 什么是monkey,monkey的作用是什么? Monkey是Android自身提供的,可以通过adb shell模拟用户行为,发送一些伪随机用户事件到目标设备上. Monkey和它的直接意 ...
- vim编辑器学习
vim是一个非常强大的编辑器,看了很多文章能感受到它的强大,不过还需要不断地学习和使用来慢慢感受. 安装vim 在ubuntu 系统中使用 sudo apt-get install vim-gtk 安 ...
- 小黄车ofo法人被限制出境,它究竟还能撑多久?
因为季节的原因,现在正是骑车的好时候,而且北京也开通了一条自行车的专用路.但就是在这么好的时候,我们发现,路边的小黄车却越来越少了,而且它的麻烦还不断! ofo法人被限制出境 6月12日消息,据上海市 ...
- Linux驱动开发之字符设备驱动模型之file_operations
90%的驱动模型都是按照下图开发的 下面来说下设备描述结构是什么东西 打开Linux-2.6.32.2的Source Insight 工程,搜索cdev 比如一个应用程序需要调用read和write这 ...
- django用户投票系统详解
投票系统之详解 1.创建项目(mysite)与应用(polls) django-admin.py startproject mysite python manage.py startapp polls ...
- ffmpeg函数04__v_register_output_format()
注册复用器,编码器等的函数av_register_all() 注册编解码器avcodec_register_all() 注册复用器的函数是av_register_output_format(). 注册 ...