大数据笔记(九)——Mapreduce的高级特性(B)
二.排序
对象排序
员工数据 Employee.java ----> 作为key2输出
需求:按照部门和薪水升序排列
Employee.java
package mr.object; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable; //Ա����: 7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30
public class Employee implements WritableComparable<Employee>{ private int empno;
private String ename;
private String job;
private int mgr;
private String hiredate;
private int sal;
private int comm;
private int deptno;// @Override
// public int compareTo(Employee o) {
// // 一个列的排序规则:按照员工的薪水排序
// if(this.sal >= o.getSal()){
// return 1;
// }else{
// return -1;
// }
// } @Override
public int compareTo(Employee o) {
// 两个列排序规则:部门
if(this.deptno > o.getDeptno()){
return 1;
}else if(this.deptno < o.getDeptno()){
return -1;
} //薪水
if(this.sal >= o.getSal()){
return 1;
}else{
return -1;
} } @Override
public String toString() {
return "["+this.empno+"\t"+this.ename+"\t"+this.sal+"\t"+this.deptno+"]";
} @Override
public void write(DataOutput output) throws IOException {
output.writeInt(this.empno);
output.writeUTF(this.ename);
output.writeUTF(this.job);
output.writeInt(this.mgr);
output.writeUTF(this.hiredate);
output.writeInt(this.sal);
output.writeInt(this.comm);
output.writeInt(this.deptno);
} @Override
public void readFields(DataInput input) throws IOException {
this.empno = input.readInt();
this.ename = input.readUTF();
this.job = input.readUTF();
this.mgr = input.readInt();
this.hiredate = input.readUTF();
this.sal = input.readInt();
this.comm = input.readInt();
this.deptno = input.readInt();
} public int getEmpno() {
return empno;
}
public void setEmpno(int empno) {
this.empno = empno;
}
public String getEname() {
return ename;
}
public void setEname(String ename) {
this.ename = ename;
}
public String getJob() {
return job;
}
public void setJob(String job) {
this.job = job;
}
public int getMgr() {
return mgr;
}
public void setMgr(int mgr) {
this.mgr = mgr;
}
public String getHiredate() {
return hiredate;
}
public void setHiredate(String hiredate) {
this.hiredate = hiredate;
}
public int getSal() {
return sal;
}
public void setSal(int sal) {
this.sal = sal;
}
public int getComm() {
return comm;
}
public void setComm(int comm) {
this.comm = comm;
}
public int getDeptno() {
return deptno;
}
public void setDeptno(int deptno) {
this.deptno = deptno;
}
}
EmployeeSortMapper.java
package mr.object; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; // Key2
public class EmployeeSortMapper extends Mapper<LongWritable, Text, Employee, NullWritable> { @Override
protected void map(LongWritable key1, Text value1,Context context)
throws IOException, InterruptedException {
// ���ݣ�7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30
String data = value1.toString(); //分词
String[] words = data.split(","); //创建员工对象
Employee e = new Employee(); //员工号
e.setEmpno(Integer.parseInt(words[0]));
//员工姓名
e.setEname(words[1]); //job
e.setJob(words[2]); //经理号:注意 有些员工没有经理
try{
e.setMgr(Integer.parseInt(words[3]));
}catch(Exception ex){
//null
e.setMgr(0);
} //入职日期
e.setHiredate(words[4]); //薪水
e.setSal(Integer.parseInt(words[5])); //奖金
try{
e.setComm(Integer.parseInt(words[6]));
}catch(Exception ex){
//无奖金
e.setComm(0);
} //部门
e.setDeptno(Integer.parseInt(words[7])); //输出key2
context.write(e, NullWritable.get());
}
}
EmployeeSortMain.java
package mr.object; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class EmployeeSortMain { public static void main(String[] args) throws Exception {
// job = map + reduce
Job job = Job.getInstance(new Configuration());
//ָ任务入口
job.setJarByClass(EmployeeSortMain.class); job.setMapperClass(EmployeeSortMapper.class);
job.setMapOutputKeyClass(Employee.class);
job.setMapOutputValueClass(NullWritable.class); job.setReducerClass(EmployeeSortReducer.class);
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(Employee.class); FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1])); //执行任务
job.waitForCompletion(true);
} }
结果:
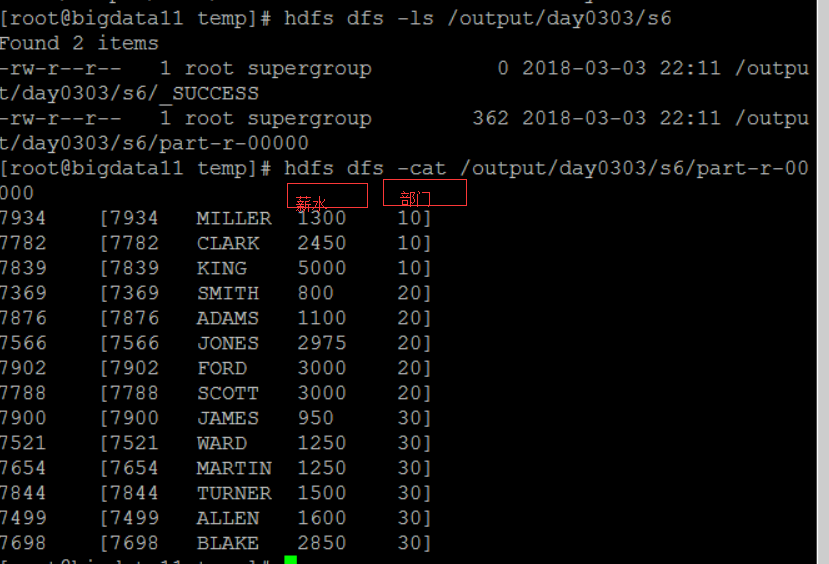
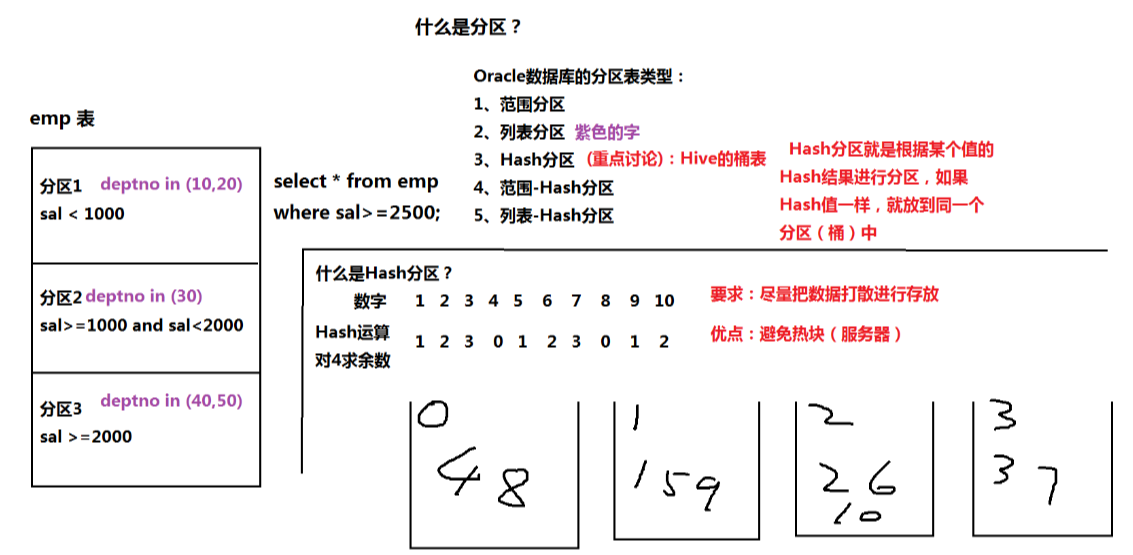
三.分区分区:Partition:
根据Map的输出(k2 v2)进行分区
默认情况下,MapReduce只有一个分区(只有一个输出文件)
作用:提高查询的效率
建立分区:根据条件的不同
需求:按照员工的部门号进行分区,相同部门号的员工输出到一个分区中
EmpPartionMapper.java
package demo.partion; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; //k2部门号 v2 员工对象
public class EmpPartionMapper extends Mapper<LongWritable, Text, LongWritable, Employee> { @Override
protected void map(LongWritable key1, Text value1, Context context)
throws IOException, InterruptedException { // ���ݣ�7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30
String data = value1.toString(); String[] words = data.split(","); Employee e = new Employee(); e.setEmpno(Integer.parseInt(words[0])); e.setEname(words[1]); e.setJob(words[2]); try{
e.setMgr(Integer.parseInt(words[3]));
}catch(Exception ex){
//null
e.setMgr(0);
} e.setHiredate(words[4]); e.setSal(Integer.parseInt(words[5])); try{
e.setComm(Integer.parseInt(words[6]));
}catch(Exception ex){
e.setComm(0);
} e.setDeptno(Integer.parseInt(words[7])); //输出 k2是部门号 v2是员工对象
context.write(new LongWritable(e.getDeptno()), e);
}
}
EmpPartionReducer.java
package demo.partion; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Reducer; //把相同部门的员工输出到HDFS K4: 部门号 v4: 员工对象
public class EmpPartionReducer extends Reducer<LongWritable, Employee, LongWritable, Employee>{ @Override
protected void reduce(LongWritable k3, Iterable<Employee> v3, Context context)
throws IOException, InterruptedException {
for (Employee e : v3) {
context.write(k3, e);
}
} }
MyEmployeePartitioner.java
package demo.partion; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Partitioner;
//分区规则:根据Map的输出建立分区 k2 v2
public class MyEmployeePartitioner extends Partitioner<LongWritable, Employee>{ /*
* numParts 分区个数
*/
@Override
public int getPartition(LongWritable k2, Employee v2, int numParts) {
//分区规则
int deptno = v2.getDeptno();
if (deptno == 10) {
//放入一号分区
return 1%numParts;
}else if (deptno == 20) {
//放入二号分区
return 2%numParts;
}else {
//放入0号分区
return 3%numParts;
}
}
}
EmpPartitionMain.java
package demo.partion; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class EmpPartitionMain { public static void main(String[] args) throws Exception { Job job = Job.getInstance(new Configuration()); job.setJarByClass(EmpPartitionMain.class); job.setMapperClass(EmpPartionMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Employee.class); //指定分区规则
job.setPartitionerClass(MyEmployeePartitioner.class);
//指定分区的个数
job.setNumReduceTasks(3); job.setReducerClass(EmpPartionReducer.class);
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(Employee.class); FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); } }
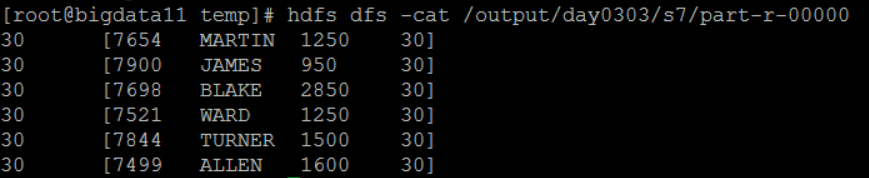
结果:建立了三个分区
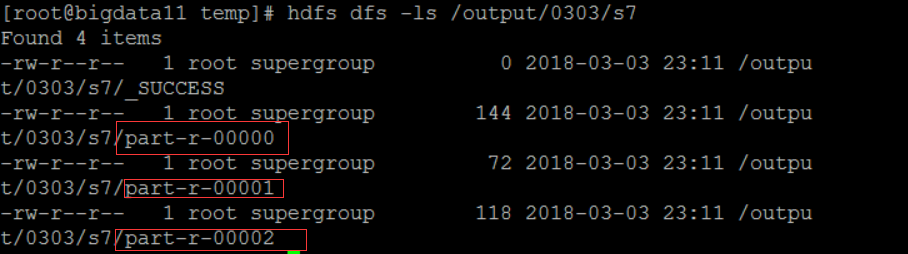
一号分区:

二号分区:

0号分区:
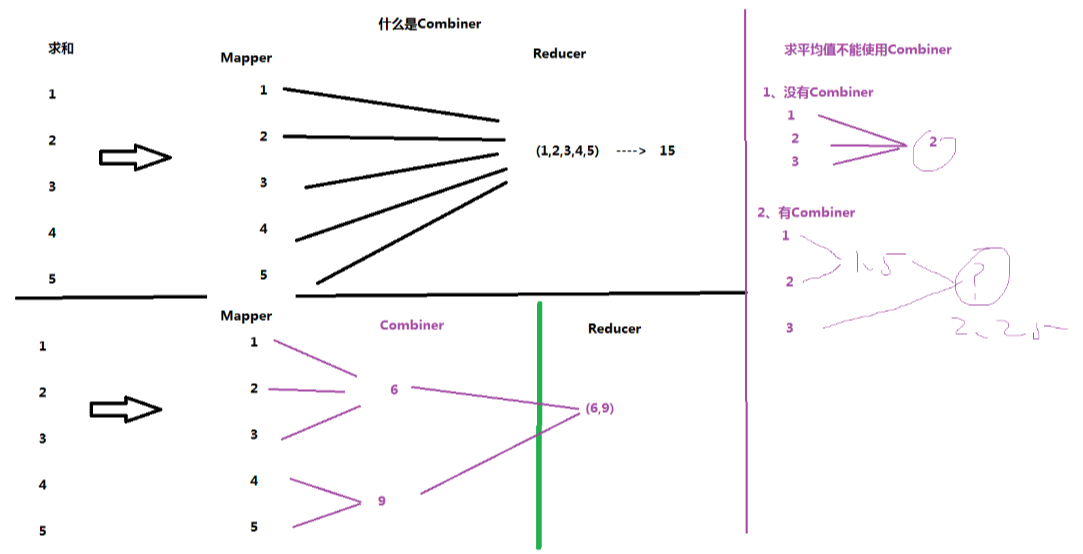
四.合并:Combiner
1、MapReduce的任务中,可以没有Combiner
2、Combiner是一种特殊的Reducer,是在Mapper端先做一次Reducer,用来减少Map的输出,从而提高的效率。
3、注意事项:
(1)有些情况,不能使用Combiner -----> 求平均值
(2)引入Combiner,不引人Combiner,一定不能改变原理的逻辑。(MapReduce编程案例:实现倒排索引)
WordCountMapper.java
package demo.combiner; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable>{ @Override
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException { //取出数据: I love beijing
String data = v1.toString(); //分词
String[] words = data.split(" "); //输出K2:单词 V2:记一次数
for (String w : words) {
context.write(new Text(w), new LongWritable(1));
} } }
WordCountReducer.java
package demo.combiner; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable>{ @Override
protected void reduce(Text k3, Iterable<LongWritable> v3,
Context context) throws IOException, InterruptedException {
long total = 0;
for (LongWritable l : v3) {
total = total + l.get();
} //输出K4 V4
context.write(k3, new LongWritable(total));
} }
WordCountMain.java:增加Combiner
package demo.combiner; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCountMain { public static void main(String[] args) throws Exception {
Job job = Job.getInstance(new Configuration()); job.setJarByClass(WordCountMain.class); //Mapper
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);//指定k2
job.setMapOutputValueClass(LongWritable.class);//指定v2 //Combiner
job.setCombinerClass(WordCountReducer.class); //ָreducer
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//ָmapper/reducer路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//ִ执行任务
job.waitForCompletion(true);
}
}
大数据笔记(九)——Mapreduce的高级特性(B)的更多相关文章
- 大数据运算模型 MapReduce 原理
大数据运算模型 MapReduce 原理 2016-01-24 杜亦舒 MapReduce 是一个大数据集合的并行运算模型,由google提出,现在流行的hadoop中也使用了MapReduce作为计 ...
- 大数据篇:MapReduce
MapReduce MapReduce是什么? MapReduce源自于Google发表于2004年12月的MapReduce论文,是面向大数据并行处理的计算模型.框架和平台,而Hadoop MapR ...
- 大数据笔记(二十六)——Scala语言的高级特性
===================== Scala语言的高级特性 ========================一.Scala的集合 1.可变集合mutable 不可变集合immutable / ...
- 【大数据作业九】安装关系型数据库MySQL 安装大数据处理框架Hadoop
作业要求:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161 4.简述Hadoop平台的起源.发展历史与应用现状. 列举发展过程中 ...
- 《OD大数据实战》MapReduce实战
一.github使用手册 1. 我也用github(2)——关联本地工程到github 2. Git错误non-fast-forward后的冲突解决 3. Git中从远程的分支获取最新的版本到本地 4 ...
- 大数据笔记01:大数据之Hadoop简介
1. 背景 随着大数据时代来临,人们发现数据越来越多.但是如何对大数据进行存储与分析呢? 单机PC存储和分析数据存在很多瓶颈,包括存储容量.读写速率.计算效率等等,这些单机PC无法满足要求. 2. ...
- 【大数据系列】MapReduce详解
MapReduce是hadoop中的一个计算框架,用来处理大数据.所谓大数据处理,即以价值为导向,对大数据加工,挖掘和优化等各种处理. MapReduce擅长处理大数据,这是由MapReduce的设计 ...
- 大数据小白系列 —— MapReduce流程的深入说明
上一期我们介绍了MR的基本流程与概念,本期稍微深入了解一下这个流程,尤其是比较重要但相对较少被提及的Shuffling过程. Mapping 上期我们说过,每一个mapper进程接收并处理一块数据,这 ...
- 大数据笔记(一)——Hadoop的起源与背景知识
一.大数据的5个特征(IBM提出): Volume(大量) Velocity(高速) Variety(多样) Value(价值) Varacity(真实性) 二.OLTP与OLAP 1.OLTP:联机 ...
随机推荐
- 多线程14-Barrier
, b => Console.WriteLine()); ; i <= ; i++) { Console.Write ...
- 1000行基本SQL
/* Windows服务 */ -- 启动MySQL net start mysql -- 创建Windows服务 sc create mysql binPath= mysqld_bin_path(注 ...
- [BZOJ4444] [Luogu 4155] [LOJ 2007] [SCOI2015]国旗计划(倍增)
[BZOJ4444] [Luogu 4155] [LOJ 2007] [SCOI2015]国旗计划(倍增) 题面 题面较长,略 分析 首先套路的断环为链.对于从l到r的环上区间,若l<=r,我们 ...
- checkbox的全选、全消的使用
jquery的选择器的使用 //全选,全消 $("#check_all").click(function () { state = $(this).prop("check ...
- 一分钟搭建 Web 版的 PHP 代码调试利器
一.背景 俗话说:"工欲善其事,必先利其器".作为一门程序员,我们在工作中,经常需要调试某一片段的代码,但是又不想打开繁重的 IDE (代码编辑器).使用在线工具调试代码有时有 ...
- 【转】Hadoop 1.x中fsimage和edits合并实现
在NameNode运行期间,HDFS的所有更新操作都是直接写到edits中,久而久之edits文件将会变得很大:虽然这对NameNode运行时候是没有什么影响的,但是我们知道当NameNode重启的时 ...
- Jpa-Spec oracle函数bitand,instr等扩展
jpa-spec github: https://github.com/wenhao/jpa-spec 使用这个框架可以简化我们拼条件的复杂度,如下代码: public Page<Person& ...
- C# Excel数据验重及Table数据验重
http://blog.csdn.net/jiankunking/article/details/38398087 最近在做导入Excel数据的时候,要检验数据是否重复: 1.要检验Excel数据本身 ...
- div和span互换
div是块级元素,它不论大小默认占一行,而且可以设置宽高以及外边距span是行内元素,它占它自身大小的位置,而且不能设置宽高以及边距同时div也可以变为span (display:inline),这样 ...
- 利用 TCMalloc 优化 Nginx 的性能
TCMalloc 全称为 Thread-Caching Malloc,是谷歌的开源工具 google-perftools 的成员,它可以 在内存分配效率和速度上高很多,可以很大程度提高服务器在高并发情 ...