spark中使用的内存文件系统-Tachyon FS 简介
转自:http://blog.csdn.net/u014252240/article/details/41810849
发布人:南京大学PASA大数据实验室顾荣
1. Tachyon是什么
Tachyon(/'tæki:ˌɒn/ 意为超光速粒子)是以内存为中心的分布式文件系统,拥有高性能和容错能力,能够为集群框架(如Spark、MapReduce)提供可靠的内存级速度的文件共享服务。Tachyon诞生于UC Berkeley的AMPLab,由该实验室的李浩源童鞋初创。2012年12月,Tachyon发布了第一个版本0.1.0。到2014年12月,Tachyon的最新发布版版本为0.5.0,并且正在开发0.6.0版本。目前(2014年12月),已有50多家公司开始使用Tachyon,超过20家公司(如 Intel, Yahoo, Pivotal, Redhat,Baidu等)为Tachyon的开发进行了贡献,在GitHub上Tachyon的贡献者也已上升到55人。南京大学PASALab从早期就开始和Tachyon Community一起从事着该项目的建设和开发工作。
从软件栈的层次来看,Tachyon是位于现有大数据计算框架和大数据存储系统之间的独立的一层。它利用底层文件系统作为备份,对于上层应用来说,Tachyon就是一个分布式文件系统。
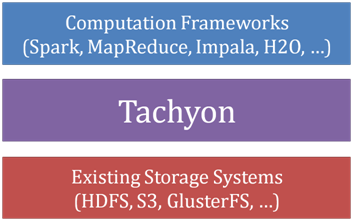
其最初出现是为了解决如下问题:
大数据分析流水线中数据共享通过基于磁盘文件系统(HDFS等)性能比较缓慢;
大数据计算引擎的处理进程(Spark的Executor,MapReduce的Child JVM等)崩溃出错后,缓存的数据也会全部丢失;
基于内存的系统存储数据冗余,对象太多会导致Java GC时间过长;
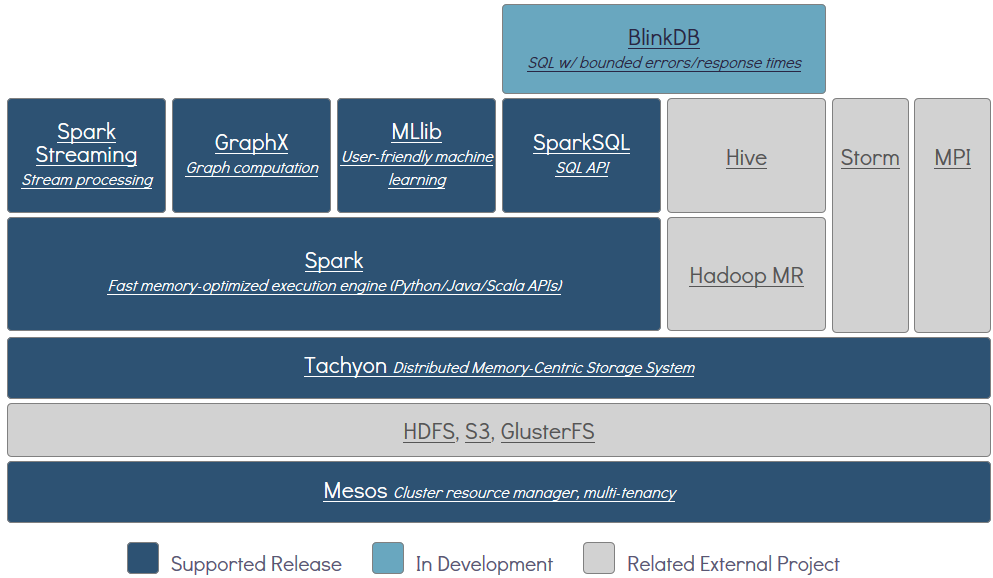
另外,如下图所示,Tachyon属于伯克利大数据分析软件栈(Berkeley Data Analytics Stack)中的存储层软件。
2. 如何使用Tachyon
受益于Tachyon良好的设计和兼用性,用户可以很方便地将现有的利用HDFS进行存储的程序移植至Tachyon,只需要简单的两步:添加配置项,修改文件路径。
2.1 对于MapReduce程序
添加配置项<”fs.tachyon.impl”, ” tachyon.hadoop.TFS”>,可以在core-site.xml文件中添加,也可以在程序中使用Configuration.set()方法添加。将原有的”hdfs://ip:port/path”路径更改为”tachyon://ip:port/path”。
需要注意的是,由于Hadoop默认不依赖于Tachyon,还要将Tachyon的jar包添加至$HADOOP_CLASSPATH中。
2.2 对于Spark程序
同样地,添加配置项<”fs.tachyon.impl”, ” tachyon.hadoop.TFS”>。将原有的”hdfs://ip:port/path”路径更改为”tachyon://ip:port/path”。
额外地,添加配置项<”spark.tachyonStore.url”, “tachyon://ip:port/”>后,能够使用”rdd.persist(StorageLevel.OFF_HEAP)”语句将RDD缓存至Tachyon中以减少Java GC的开销。
2.3 其他使用方式
为了方便用户使用,Tachyon还提供了命令行工具,能够对Tachyon进行简单的交互
tachyon tfs cat|ls|mkdir|rm|copyFromLocal|…
此外,Tachyon也有自己的一套API,使用该API能够很灵活地访问Tachyon文件系统,并充分利用Tachyon的各个特性以获得最佳性能。
TachyonFS.createFile|delete|mkdir|rename|…
TachyonFile.getInStream|getOutStream|getPath|…
3. Tachyon基本工作原理
这里对Tachyon的基本工作原理进行概述性的介绍,包括Tachyon的整体架构、文件组织、读写类型、Tachyon的容错机制和心跳机制等。更新详细的介绍以及Tachyon的其他功能,我会在之后的博客中结合源码分析给出。
3.1 整体架构
Tachyon整体架构如下左图所示,采用了Master-Worker模式,运行中的Tachyon系统由一个Master和多个Worker构成。Tachyon Master支持ZooKeeper进行容错,用于管理全部文件的元数据信息,同时也负责监控各个Tachyon Worker的状态。每个Tachyon Worker启动一个守护进程,管理本地的Ramdisk,Ramdisk中存储了具体的文件数据。这里也可以看出,Ramdisk就是Tachyon“以内存为中心”的内存部分。
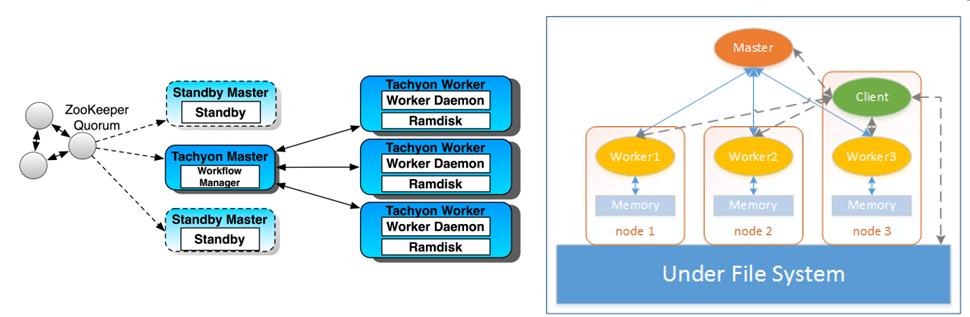
在右图中,添加了Tachyon Client和Under File System(UFS,底层文件系统)部分来说明具体的工作方式。UFS对于Tachyon来说是一个备份,内存中的文件丢失后能够从UFS中恢复。所有上层应用都通过Tachyon Client对Tachyon进行操作,Client对Master进行文件的元数据操作,通过Worker访问内存中的文件数据,若文件不在内存中,Client还能够访问UFS。
3.2 文件组织和读写类型
为了高效地对文件进行管理,Tachyon文件在内存中按块(Block)组织。文件和块信息保存在Master端,每个Worker以块为单位进行存储和管理,一个块可以同时被缓存在不同Worker的内存中。在UFS中,以文件形式对Tachyon文件进行备份。
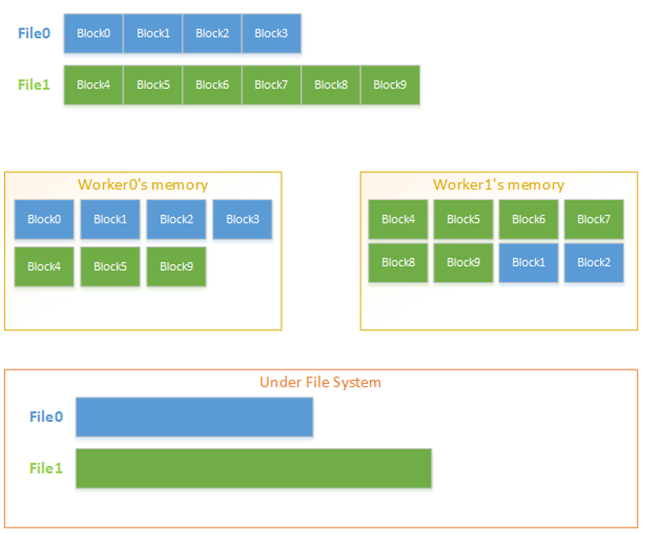
由于Tachyon文件存储位置的多样性(内存,UFS),Tachyon API提供了多种文件读写类型以处理不同情况。
读类型: CACHE – 读取数据并缓存在本地内存
NO_CACHE – 读取数据但不缓存在本地内存
写类型: MUST_CACHE – 只写本地内存,空间不足时报ERROR
TRY_CACHE – 只写本地内存,空间不足时报WARNING
THROUGH – 只写UFS
CACHE_THROUGH – 同时写本地内存和UFS(TRY_CACHE + THROUGH)
ASYNC_THROUGH– 先写本地内存,异步备份到UFS
3.3 容错机制
作为分布式文件系统,Tachyon具有良好的容错机制,Master和Worker都有自己的容错方式。
从之前的系统架构图中也可看出,Master支持使用ZooKeeper进行容错。同时,Master中保存的元数据使用Journal进行容错,具体包括Editlog——记录所有对元数据的操作,以及Image——持久化元数据信息。此外,Master还对各个Worker的状态进行监控,发现Worker失效时会自动重启对应的Worker。
对于具体的文件数据,使用血统关系(Lineage)进行容错。文件元数据中记录了文件之间的依赖关系,当文件丢失时,能够根据依赖关系进行重计算来恢复文件数据。
3.4 心跳机制
在Tachyon中,心跳(HeartBeat)用于两个方面:Master, Worker, Client之间的定期通信;Master, Worker自身的定期状态自检。具体地:
- Client向Master发送心跳信号:表示Client仍处于连接中,Client释放连接后重新连接会获得新的UserId
- Client向Worker发送心跳信号:表示Client仍处于连接中,释放连接后Worker会回收该Client的用户空间
- Worker自检,同时向Master发送心跳信号:Worker将自己的存储空间信息更新给Master(容量,移除的块信息),同时清理超时的用户,回收用户空间
- Master自检:检查所有Worker的状态,若有Worker失效,会统计丢失的文件并尝试重启该Worker
spark中使用的内存文件系统-Tachyon FS 简介的更多相关文章
- Spark入门实战系列--10.分布式内存文件系统Tachyon介绍及安装部署
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Tachyon介绍 1.1 Tachyon简介 随着实时计算的需求日益增多,分布式内存计算 ...
- Tachyon:Spark生态系统中的分布式内存文件系统
转自: http://www.csdn.net/article/2015-06-25/2825056 摘要:Tachyon把内存存储的功能从Spark中分离出来, 使Spark可以更专注计算的本身, ...
- 内存文件系统:tachyon(现在叫Alluxio)
此文于2015 年 8 月 10 日发布 Tachyon 是什么 Tachyon 是 AMPLab 开发的一款内存分布式文件系统.它介于计算层和存储层之间,可以简单的理解为存储层在内存内的一个 Cac ...
- 分布式内存文件系统Tachyon
UCBerkeley研发的Tachyon(超光子['tækiːˌɒn],名字要不要这么太嚣张啊:)是一款为各种集群并发计算框架提供内存数据管理的平台,也可以说是一种内存式的文件系统吧.如下图,它就处于 ...
- Tachyon在Spark中的作用(Tachyon: Reliable, Memory Speed Storage for Cluster Computing Frameworks 论文阅读翻译)
摘要: Tachyon是一种分布式文件系统,能够借助集群计算框架使得数据以内存的速度进行共享.当今的缓存技术优化了read过程,可是,write过程由于须要容错机制,就须要通过网络或者 ...
- Spark中的编程模型
1. Spark中的基本概念 Application:基于Spark的用户程序,包含了一个driver program和集群中多个executor. Driver Program:运行Applicat ...
- Alluxio : 开源分布式内存文件系统
Alluxio : 开源分布式内存文件系统 Alluxio is a memory speed virtual distributed storage system.Alluxio是一个开源的基于内存 ...
- Spark中常用工具类Utils的简明介绍
<深入理解Spark:核心思想与源码分析>一书前言的内容请看链接<深入理解SPARK:核心思想与源码分析>一书正式出版上市 <深入理解Spark:核心思想与源码分析> ...
- Apache Spark Tachyon的简介
Tachyon是一个分布式内存文件系统,可以理解为内存中的HDFS. 为了提供更高的性能,将数据存储剥离Java Heap. 用户可以基于Tachyon实现RDD或者文件的跨应用共享,并提供高容错机制 ...
随机推荐
- Eclipse集成spring-tool-suite(STS)
1.官方下载 sts是spring官方在eclipse基础上加了很多插件之后封装的开发工具.sts与eclipse完全一样,但是多了很多插件,比如maven,使用起来更加方便.如果使用eclipse自 ...
- 织梦DedeCMS栏目列表常见序号的调用标签
我们在制作dedecms模板时,源代码中的[field:global name=autoindex/]标签很好用可以调用数字序号,此标签最简单的用法就是按内容条数来获取数字序号,但有的时候发现使用该标 ...
- Java面试01
一.谈谈你对java的理解 1.平台无关性,一次编译到处运行 2.GC 3.语言特性 4.面向对象 5.类库 6.异常处理 二.Java如何做到一次编译到处运行?(如何做到平台无关性) 首先我们先来编 ...
- xml_dom解析之二
dom解析(二) 通过代码创建一个xml文件 package xml4; import java.io.File; import javax.xml.parsers.DocumentBuilder; ...
- 安装vim自动补全插件
1 安装VIM 2 安装vim插件管理工具.过程见链接.(谢谢) 3 在.vimrc中添加下列代码 Bundle 'Valloric/YouCompleteMe' 保存退出后打开vim,在正常模式下输 ...
- filebeat收集nginx的json格式日志
一.在nginx主机上安装filebeat组件 [root@zabbix_server nginx]# cd /usr/local/src/ [root@zabbix_server src]# wge ...
- crt0.o
crt1.o, crti.o, crtbegin.o, crtend.o, crtn.o 等目标文件和daemon.o(由我们自己的C程序文件产生)链接成一个执行文件.前面这5个目标文件的作用分别是启 ...
- Tableau Sheet中的操作
如果想要给数据排名,例如给饼图中的数据排名 1 创建一个Rank 描述为INDEX()的测度 2.将RANK用Label形式显示并且编辑计算方法选择特定的属性. 属性本身也有可以快速计算的一些方式. ...
- PropertyPlaceholderConfigurer implements BeanFactoryPostProcessor
BeanFactoryPostProcessor的应用 最常用的一个应用就是org.springframework.beans.factory.config.PropertyPlaceholderCo ...
- 多线程-生产者消费者(lock同步)
二.采用Lock锁以及await和signal方法是实现 import java.io.IOException; import java.util.concurrent.locks.Condition ...