如何将Numpy加速700倍?用 CuPy 呀
如何将Numpy加速700倍?用 CuPy 呀
作为 Python 语言的一个扩展程序库,Numpy 支持大量的维度数组与矩阵运算,为 Python 社区带来了很多帮助。借助于 Numpy,数据科学家、机器学习实践者和统计学家能够以一种简单高效的方式处理大量的矩阵数据。那么 Numpy 速度还能提升吗?本文介绍了如何利用 CuPy 库来加速 Numpy 运算速度。
选自towardsdatascience,作者:George Seif,机器之心编译,参与:杜伟、张倩。
就其自身来说,Numpy 的速度已经较 Python 有了很大的提升。当你发现 Python 代码运行较慢,尤其出现大量的 for-loops 循环时,通常可以将数据处理移入 Numpy 并实现其向量化最高速度处理。
但有一点,上述 Numpy 加速只是在 CPU 上实现的。由于消费级 CPU 通常只有 8 个核心或更少,所以并行处理数量以及可以实现的加速是有限的。
这就催生了新的加速工具——CuPy 库。
何为 CuPy?

CuPy 是一个借助 CUDA GPU 库在英伟达 GPU 上实现 Numpy 数组的库。基于 Numpy 数组的实现,GPU 自身具有的多个 CUDA 核心可以促成更好的并行加速。
CuPy 接口是 Numpy 的一个镜像,并且在大多情况下,它可以直接替换 Numpy 使用。只要用兼容的 CuPy 代码替换 Numpy 代码,用户就可以实现 GPU 加速。
CuPy 支持 Numpy 的大多数数组运算,包括索引、广播、数组数学以及各种矩阵变换。
如果遇到一些不支持的特殊情况,用户也可以编写自定义 Python 代码,这些代码会利用到 CUDA 和 GPU 加速。整个过程只需要 C++格式的一小段代码,然后 CuPy 就可以自动进行 GPU 转换,这与使用 Cython 非常相似。
在开始使用 CuPy 之前,用户可以通过 pip 安装 CuPy 库:
pip install cupy
使用 CuPy 在 GPU 上运行
为符合相应基准测试,PC 配置如下:
- i7–8700k CPU
- 1080 Ti GPU
- 32 GB of DDR4 3000MHz RAM
- CUDA 9.0
CuPy 安装之后,用户可以像导入 Numpy 一样导入 CuPy:
import numpy as np
import cupy as cp
import time
在接下来的编码中,Numpy 和 CuPy 之间的切换就像用 CuPy 的 cp 替换 Numpy 的 np 一样简单。如下代码为 Numpy 和 CuPy 创建了一个具有 10 亿 1』s 的 3D 数组。为了测量创建数组的速度,用户可以使用 Python 的原生 time 库:
### Numpy and CPU
s = time.time()
*x_cpu = np.ones((1000,1000,1000))*
e = time.time()
print(e - s)### CuPy and GPU
s = time.time()
*x_gpu = cp.ones((1000,1000,1000))*
e = time.time()
print(e - s)
这很简单!
令人难以置信的是,即使以上只是创建了一个数组,CuPy 的速度依然快得多。Numpy 创建一个具有 10 亿 1』s 的数组用了 1.68 秒,而 CuPy 仅用了 0.16 秒,实现了 10.5 倍的加速。
但 CuPy 能做到的还不止于此。
比如在数组中做一些数学运算。这次将整个数组乘以 5,并再次检查 Numpy 和 CuPy 的速度。
### Numpy and CPU
s = time.time()
*x_cpu *= 5*
e = time.time()
print(e - s)### CuPy and GPU
s = time.time()
*x_gpu *= 5*
e = time.time()
print(e - s)
果不其然,CuPy 再次胜过 Numpy。Numpy 用了 0.507 秒,而 CuPy 仅用了 0.000710 秒,速度整整提升了 714.1 倍。
现在尝试使用更多数组并执行以下三种运算:
- 数组乘以 5
- 数组本身相乘
- 数组添加到其自身
### Numpy and CPU
s = time.time()
*x_cpu *= 5
x_cpu *= x_cpu
x_cpu += x_cpu*
e = time.time()
print(e - s)### CuPy and GPU
s = time.time()
*x_gpu *= 5
x_gpu *= x_gpu
x_gpu += x_gpu*
e = time.time()
print(e - s)
结果显示,Numpy 在 CPU 上执行整个运算过程用了 1.49 秒,而 CuPy 在 GPU 上仅用了 0.0922 秒,速度提升了 16.16 倍。
数组大小(数据点)达到 1000 万,运算速度大幅度提升
使用 CuPy 能够在 GPU 上实现 Numpy 和矩阵运算的多倍加速。值得注意的是,用户所能实现的加速高度依赖于自身正在处理的数组大小。下表显示了不同数组大小(数据点)的加速差异:
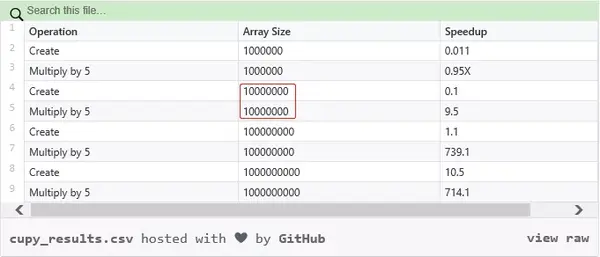
数据点一旦达到 1000 万,速度将会猛然提升;超过 1 亿,速度提升极为明显。Numpy 在数据点低于 1000 万时实际运行更快。此外,GPU 内存越大,处理的数据也就更多。所以用户应当注意,GPU 内存是否足以应对 CuPy 所需要处理的数据。
如何将Numpy加速700倍?用 CuPy 呀的更多相关文章
- Gradient Boosting, Decision Trees and XGBoost with CUDA ——GPU加速5-6倍
xgboost的可以参考:https://xgboost.readthedocs.io/en/latest/gpu/index.html 整体看加速5-6倍的样子. Gradient Boosting ...
- numpy 加速 以及 ipython
先安装openblas, 然后用pip 安装numpy sudo ln -s /usr/lib64/libopenblas-r0.2.14.so /usr/lib64/libopenblas.so 为 ...
- python 多协程异步IO爬取网页加速3倍。
from urllib import request import gevent,time from gevent import monkey#该模块让当前程序所有io操作单独标记,进行异步操作. m ...
- 基于numpy.einsum的张量网络计算
张量与张量网络 张量(Tensor)可以理解为广义的矩阵,其主要特点在于将数字化的矩阵用图形化的方式来表示,这就使得我们可以将一个大型的矩阵运算抽象化成一个具有良好性质的张量图.由一个个张量所共同构成 ...
- 使用numba加速python科学计算
技术背景 python作为一门编程语言,有非常大的生态优势,但是其执行效率一直被人诟病.纯粹的python代码跑起来速度会非常的缓慢,因此很多对性能要求比较高的python库,需要用C++或者Fort ...
- kmplayer加速播放视频(转)
转自微博:http://blog.sina.com.cn/shaguazhu1213 KMPlayer控制播放速度的快捷方式 (2011-11-12 10:51:56) 标签: 杂谈 分类: 编程之旅 ...
- 50倍时空算力提升,阿里云RDS PostgreSQL GPU版本上线
2019年3月19日,阿里云RDS PostgreSQL数据库GPU规格版本正式上线,开启了RDS异构计算并行加速之路.该版本在RDS(关系型数据库服务)的云基础设施层面首次完成了与阿里云异构计算产品 ...
- intel windows caffe加速
网址: https://github.com/BeFreeRoad/intel_caffe_windows 将intel caffe从linux平台移植到windows平台. 性能: 在虚拟机上测试可 ...
- Fluid + GooseFS 助力云原生数据编排与加速快速落地
前言 Fluid 作为基于 Kubernetes 开发的面向云原生存算分离场景下的数据调度和编排加速框架,已于近期完成了 v0.6.0 版本的正式发布.腾讯云容器 TKE 团队一直致力于参与 Flui ...
随机推荐
- tarjan算法 习题
dfs树与tarjan算法 标签(空格分隔): 517coding problem solution dfs树 tarjan Task 1 给出一幅无向图\(G\),在其中给出一个dfs树\(T\), ...
- mongodb php增删改查基本操作
$mongo = new Mongo(); $db = $mongo->selectDB('test'); $collection = $db->selectCollection('foo ...
- POJ 3613 [ Cow Relays ] DP,矩阵乘法
解题思路 首先考虑最暴力的做法.对于每一步,我们都可以枚举每一条边,然后更新每两点之间经过\(k\)条边的最短路径.但是这样复杂度无法接受,我们考虑优化. 由于点数较少(其实最多只有\(200\)个点 ...
- js下拉框选择图片
二种方式:下拉框里面选项有图片与没有图片 1.用下拉框写 下拉框的option没法添加图片如果下拉框里面不需要图片可以用这种方式. <!DOCTYPE html> <html> ...
- java 从txt文本中随机获取名字
代码: /* 获取随机文件文字 */ public static String random(String path) {//路径 String name = null; try { //把文本文件中 ...
- C++入门经典-例5.19-指针的引用与传递参数
1:引用传递参数与指针传递参数能达到同样的目的.指针传递参数也属于一种值传递,其传递的是指针变量的副本.如果使用指针的引用,就可以达到在函数体内改变指针地址的目的.运行代码如下: // 5.19.cp ...
- 查询redis中没有设置过期时间的key
#!/bin/sh ## 该脚本用来查询redis集群中,哪些key是没有设置过期时间,对应只需要修改redis的其中一个实例的 host和port ## 脚本会自动识别出该集群的所有实例,并查出对应 ...
- jquery 四舍五入小数处理总结
一.jquery中对小数进行取整.四舍五入的方法 1.丢弃小数部分,保留整数部分 parseInt(5/2) =2 2.四舍五入. Math.round(5/2) =3 3.向下取整 Math.flo ...
- IDEA里面maven菜单解读
- CSS - 设置 select 元素的样式
注意:option 外面有个框,这个框不同浏览器生成的还不一样,给这个框设置样式的方法也没有找到(有说法是这是浏览器创建的 shadow dom 没法设置).所以要想完全控制还是用列表进行模拟比较好. ...