BP算法演示
本文转载自https://mattmazur.com/2015/03/17/a-step-by-step-backpropagation-example/
Background
Backpropagation is a common method for training a neural network. There is no shortage of papers online that attempt to explain how backpropagation works, but few that include an example with actual numbers. This post is my attempt to explain how it works with a concrete example that folks can compare their own calculations to in order to ensure they understand backpropagation correctly.
If this kind of thing interests you, you should sign up for my newsletter where I post about AI-related projects that I’m working on.
Backpropagation in Python
You can play around with a Python script that I wrote that implements the backpropagation algorithm in this Github repo.
Backpropagation Visualization
For an interactive visualization showing a neural network as it learns, check out my Neural Network visualization.
Additional Resources
If you find this tutorial useful and want to continue learning about neural networks and their applications, I highly recommend checking out Adrian Rosebrock’s excellent tutorial on Getting Started with Deep Learning and Python.
Overview
For this tutorial, we’re going to use a neural network with two inputs, two hidden neurons, two output neurons. Additionally, the hidden and output neurons will include a bias.
Here’s the basic structure:

In order to have some numbers to work with, here are the initial weights, the biases, and training inputs/outputs:
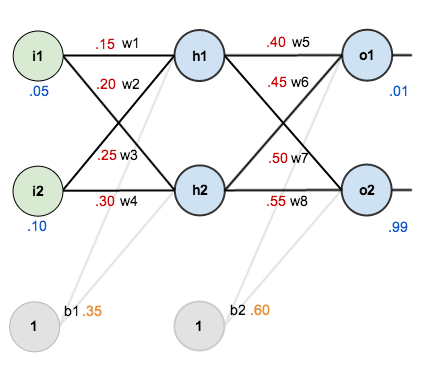
The goal of backpropagation is to optimize the weights so that the neural network can learn how to correctly map arbitrary inputs to outputs.
For the rest of this tutorial we’re going to work with a single training set: given inputs 0.05 and 0.10, we want the neural network to output 0.01 and 0.99.
The Forward Pass
To begin, lets see what the neural network currently predicts given the weights and biases above and inputs of 0.05 and 0.10. To do this we’ll feed those inputs forward though the network.
We figure out the total net input to each hidden layer neuron, squash the total net input using an activation function (here we use the logistic function), then repeat the process with the output layer neurons.
Here’s how we calculate the total net input for 


We then squash it using the logistic function to get the output of

Carrying out the same process for 

We repeat this process for the output layer neurons, using the output from the hidden layer neurons as inputs.
Here’s the output for 

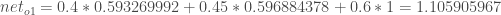
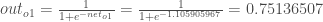
And carrying out the same process for 

Calculating the Total Error
We can now calculate the error for each output neuron using the squared error function and sum them to get the total error:

 is included so that exponent is cancelled when we differentiate later on. The result is eventually multiplied by a learning rate anyway so it doesn’t matter that we introduce a constant here [1].
is included so that exponent is cancelled when we differentiate later on. The result is eventually multiplied by a learning rate anyway so it doesn’t matter that we introduce a constant here [1].For example, the target output for

Repeating this process for

The total error for the neural network is the sum of these errors:

The Backwards Pass
Our goal with backpropagation is to update each of the weights in the network so that they cause the actual output to be closer the target output, thereby minimizing the error for each output neuron and the network as a whole.
Output Layer
Consider 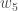
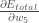
 is read as “the partial derivative of
is read as “the partial derivative of  with respect to
with respect to  “. You can also say “the gradient with respect to “.
“. You can also say “the gradient with respect to “.By applying the chain rule we know that:

Visually, here’s what we’re doing:

We need to figure out each piece in this equation.
First, how much does the total error change with respect to the output?



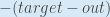 is sometimes expressed as
is sometimes expressed as 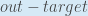
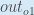 , the quantity
, the quantity  becomes zero because does not affect it which means we’re taking the derivative of a constant which is zero.
becomes zero because does not affect it which means we’re taking the derivative of a constant which is zero.Next, how much does the output of
The partial derivative of the logistic function is the output multiplied by 1 minus the output:

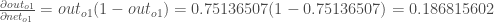
Finally, how much does the total net input of 
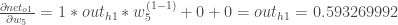
Putting it all together:


You’ll often see this calculation combined in the form of the delta rule:

Alternatively, we have 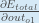




Therefore:

Some sources extract the negative sign from 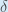
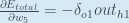
/*每个权重的梯度都等于与其相连的前一层节点的输出(即
To decrease the error, we then subtract this value from the current weight (optionally multiplied by some learning rate, eta, which we’ll set to 0.5):

 (alpha) to represent the learning rate, others use
(alpha) to represent the learning rate, others use 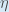 (eta), and others even use
(eta), and others even use  (epsilon).
(epsilon).We can repeat this process to get the new weights 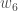
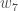


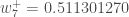
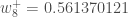
We perform the actual updates in the neural network after we have the new weights leading into the hidden layer neurons (ie, we use the original weights, not the updated weights, when we continue the backpropagation algorithm below).
Hidden Layer
Next, we’ll continue the backwards pass by calculating new values for 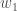
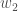


Big picture, here’s what we need to figure out:

Visually:
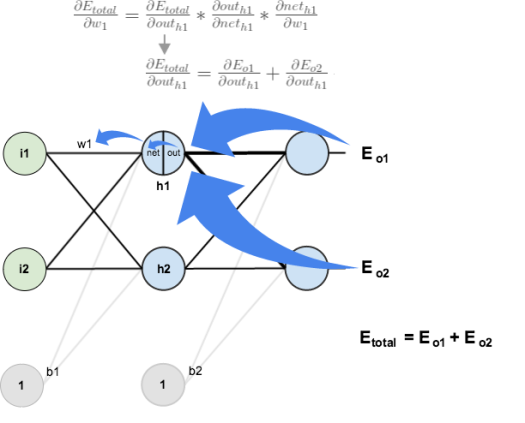
We’re going to use a similar process as we did for the output layer, but slightly different to account for the fact that the output of each hidden layer neuron contributes to the output (and therefore error) of multiple output neurons. We know that 
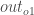



Starting with 

We can calculate 

And 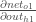
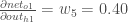
Plugging them in:
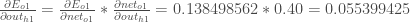
Following the same process for 

Therefore:
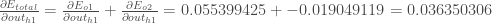
Now that we have 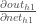

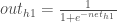

We calculate the partial derivative of the total net input to

Putting it all together:

You might also see this written as:
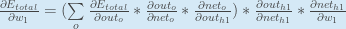


/*每个权重的梯度都等于与其相连的前一层节点的输出(即i1)乘以与其相连的后一层的反向传播的输出(即δh1,一层层求出δh1是关键)*/
We can now update

Repeating this for
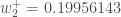

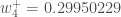
Finally, we’ve updated all of our weights! When we fed forward the 0.05 and 0.1 inputs originally, the error on the network was 0.298371109. After this first round of backpropagation, the total error is now down to 0.291027924. It might not seem like much, but after repeating this process 10,000 times, for example, the error plummets to 0.000035085. At this point, when we feed forward 0.05 and 0.1, the two outputs neurons generate 0.015912196 (vs 0.01 target) and 0.984065734 (vs 0.99 target).
总结:
1、每个权重的梯度都等于与其相连的前一层节点的输出 乘以 与其相连的后一层的反向传播的输出,重要的结论说三遍!
2、新权重 = 原权重 -
3、参考博文:http://blog.csdn.net/zhongkejingwang/article/details/44514073
BP算法演示的更多相关文章
- 一文彻底搞懂BP算法:原理推导+数据演示+项目实战(上篇)
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习.深度学习的知识! 反向传播算法(Backpropagation Algorithm, ...
- 深度学习——前向传播算法和反向传播算法(BP算法)及其推导
1 BP算法的推导 图1 一个简单的三层神经网络 图1所示是一个简单的三层(两个隐藏层,一个输出层)神经网络结构,假设我们使用这个神经网络来解决二分类问题,我们给这个网络一个输入样本,通过前向运算得到 ...
- [DL学习笔记]从人工神经网络到卷积神经网络_1_神经网络和BP算法
前言:这只是我的一个学习笔记,里边肯定有不少错误,还希望有大神能帮帮找找,由于是从小白的视角来看问题的,所以对于初学者或多或少会有点帮助吧. 1:人工全连接神经网络和BP算法 <1>:人工 ...
- Backpropagation反向传播算法(BP算法)
1.Summary: Apply the chain rule to compute the gradient of the loss function with respect to the inp ...
- JS写的排序算法演示
看到网上有老外写的,就拿起自已之前完成的jmgraph画图组件也写了一个.想了解jmgraph的请移步:https://github.com/jiamao/jmgraph 当前演示请查看:http:/ ...
- stanford coursera 机器学习编程作业 exercise4--使用BP算法训练神经网络以识别阿拉伯数字(0-9)
在这篇文章中,会实现一个BP(backpropagation)算法,并将之应用到手写的阿拉伯数字(0-9)的自动识别上. 训练数据集(training set)如下:一共有5000个训练实例(trai ...
- (转)神经网络和深度学习简史(第一部分):从感知机到BP算法
深度|神经网络和深度学习简史(第一部分):从感知机到BP算法 2016-01-23 机器之心 来自Andrey Kurenkov 作者:Andrey Kurenkov 机器之心编译出品 参与:chen ...
- 多层感知机及其BP算法(Multi-Layer Perception)
Deep Learning 近年来在各个领域都取得了 state-of-the-art 的效果,对于原始未加工且单独不可解释的特征尤为有效,传统的方法依赖手工选取特征,而 Neural Network ...
- 关于BP算法在DNN中本质问题的几点随笔 [原创 by 白明] 微信号matthew-bai
随着deep learning的火爆,神经网络(NN)被大家广泛研究使用.但是大部分RD对BP在NN中本质不甚清楚,对于为什这么使用以及国外大牛们是什么原因会想到用dropout/sigmoid ...
随机推荐
- ssh-config的使用
使用SSH的配置文件可以在很大程度上方便各种操作,特别适应于有多个SSH帐号.使用非标准端口或者写脚本等情况. man ssh_config 可以查看手册 如果之前是用密码方式来登录SSH,需要先改用 ...
- [转帖]OEM、ODM、OBM分别是什么?
OEM.ODM.OBM分别是什么? https://blog.csdn.net/liangtianmeng/article/details/83215500 感觉很多地方说明的都不对 OEM 别人的产 ...
- @-webkit-keyframes 动画 css3
Internet Explorer 10.Firefox 以及 Opera 支持 @keyframes 规则和 animation 属性. Chrome 和 Safari 需要前缀 -webkit-. ...
- 【SSL1786】麻将游戏
题目大意: 给出一个矩阵,查询其中两个点连通线段数 正文: 看这题好眼熟... 实质和这道题是一模一样的,只不过由一条询问升级到多条询问.
- java体系中OOP,OOD,OOA分别代表什么含义,以及OA,CRM,ERP
OOP:Object Oriented Programming 面向对象程序设计. OOD:Object Oriented Design 面向对象设计. OOA:Object Oriented Ana ...
- 使用 ELK 来分析你的支付宝账单
ELK 即 elasticsearch, logstash 以及 kibana.Elasticsearch 是一个基于 lucene 的分布式搜索引擎,logstash 是一种日志传输工具,也可以对日 ...
- 原生js实现深度克隆
总体思路: 判断对象当中的值为引用值还是原始值 如果是引用值,判断是数组还是对象,如果是原始值直接copy 递归 注意:不要忘了排除null,因为typeof null = 'object' func ...
- AVCaptureSession拍照,摄像,载图总结
AVCaptureSession [IOS开发]拍照,摄像,载图总结 1 建立Session 2 添加 input 3 添加output 4 开始捕捉 5 为用户显示当前录制状态 6 捕捉 7 ...
- 在Linux环境下部署MySql服务
之前有下载部署过几次,但是每次都会踩一些坑.特此记录在liunx下部署安装mysql的基本步骤: 1.卸载老版本的mysql find / -name mysql|xargs rm -rf 查 ...
- odoo ERP 系统安装与使用
https://hub.docker.com/_/odoo/ #!/bin/bash sudo docker pull postgres:10sudo docker pull odoo:11.0 su ...