Octavia 的实现与分析(OpenStack Rocky)
目录
文章目录
Octavia
Octavia is an open source, operator-scale load balancing solution designed to work with OpenStack.
自 Pike 以来 OpenStack 推荐使用 Octavia 代替 neutron-lbaas extension 作为 Load Balancing as a Service 的首选方案,并在 Queens 中将 neutron-lbaas 标记为废弃 —— Neutron-lbaas is now deprecated。
社区推崇 Octavia 的原因有很多,它解决了 neutron-lbaas 遗留的历史包袱,能够对外提供独立而稳定的 API(Neutron/LBaaS/Deprecation)。简单的说,社区认为 neutron-lbaas 使 Neutron 的项目管理变得拖沓,LBaaS 应该作为一个独立项目得到长足的发展,事实也是如此。
本篇基于 Rocky,记录、分析 Octavia 作为 OpenStack LBaaS 的抽象设计,开发性设计及其代码实现,并从中感受社区开发者们对 Octavia 的寄予。
基本对象概念
LBaaS:对于 OpenStack 平台而言,LB(负载均衡)被作为一种服务提供给用户,用户得以按需地、随时地获取可配置的业务负载均衡方案,这就是所谓 Load Balancing as a Service。
loadbalancer:负载均衡服务的根对象,用户对负载均衡的定义、配置和操作都基于此。
VIP:与 loadbalancer 关联的 IP 地址,每个 loadbalancer 最起码有一个 VIP,作为外部对后端业务集群的标准访问入口。
Listener:下属于 loadbalancer 的监听器,用户可配置监听外部对 VIP 的访问类型(e.g. 协议、端口)。
Pool:后端的真实业务云主机集群域,一般的,用户会根据云主机的业务类型进行划分。
Member:业务云主机,下属于 Pool,对应传统负载均衡体系中的 Real Server。
Health Monitor:挂靠于 Pool,周期性对 Pool 中的 Member(s) 进行健康检查。
L7 Policy:七层转发策略,描述了数据包转发的动作(e.g. 转发至 Pool,转发至 URL,拒绝转发)
L7 Rule:七层转发规则,下属于 L7 Policy,描述了数据包转发的匹配域(e.g. 转发至 Pool 中所有已 webserver 开头的 Members)
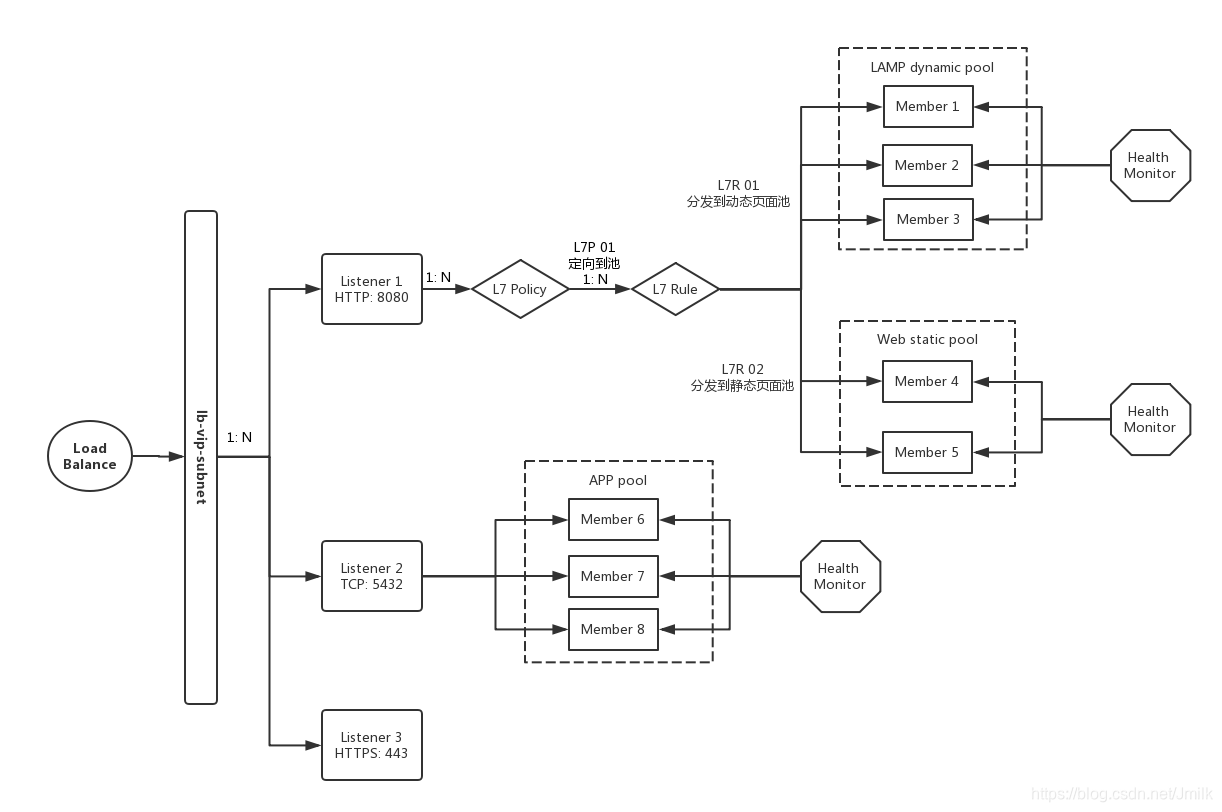
上图是一个简易的「动静页面分离」负载均衡应用架构,辅助理解这些概念及其个体与整体间的关系。
至此,我们尝试提出一个问题:为什么要抽象出这些对象?
基本使用流程
 继续从使用的角度来感性了解 Octavia 的样子。
继续从使用的角度来感性了解 Octavia 的样子。
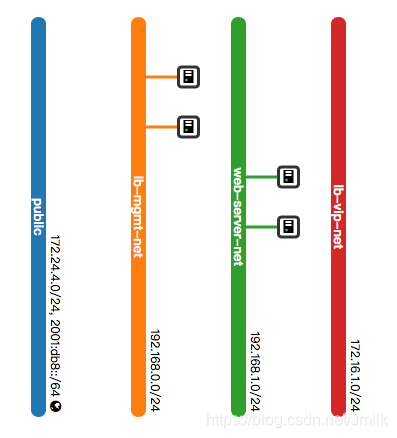
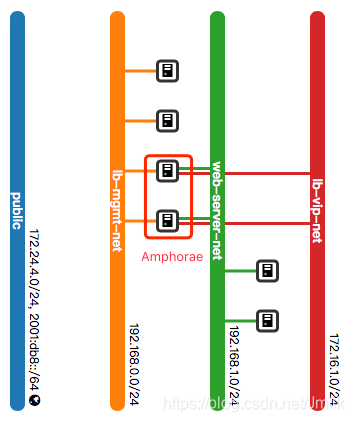
上图是一个标准的 Octavia 网络架构,包含了:
Amphora(e):实体为云主机,作为负载均衡器的载体,也是 Octavia 的 Default Loadbalancer Provider。
lb-mgmt-net:是一个与 OpenStack Management/API Network 打通的网络,project admin 可见,东侧连接 Amphora Instance、西侧连接 Octavia 服务进程。
tenant-net:业务云主机所在的网络
vip-net:提供 VIP 地址池的网络
NOTE:vip-net 和 tenant-net 可以是同一个网络,但在生产环境中,我们建议分开,以更有针对性的施加安全策略,划分不同级别的网络安全隔离域。
Step 1. 设定 loadbalancer 的 VIP。可以直接指定 VIP,或由 DHCP 分配。
Step 2. 设定 listener 监听的协议及端口。监听外部访问 http://<VIP>:8080/。
Step 3. 设定 pool 的负载均衡算法。这里选择 RR 轮询分发算法。
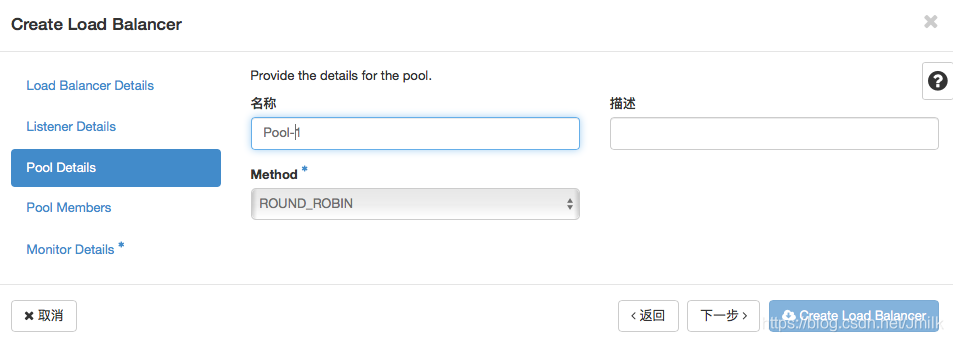
Step 4. 设定 pool 下属的 member 成员。设定 members 需要指定端口和权重,前者表示接受数据转发的 socket,后者表示分发的优先级。
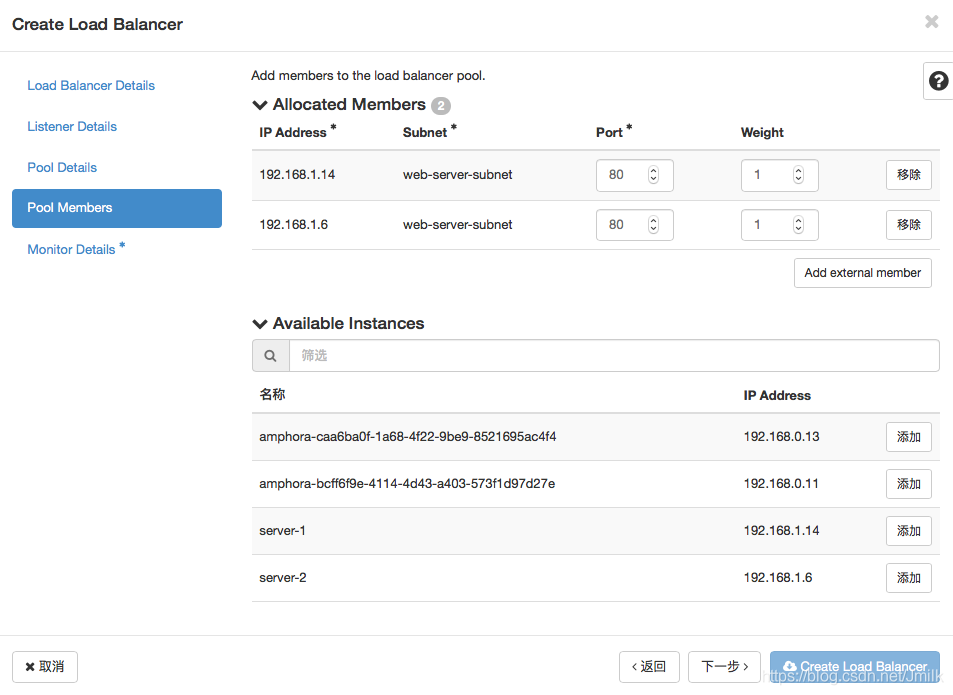
Step 5. 设定 health monitor 的健康检查规则。如果 member 出现 PING 不同的情况,则会被标记为故障,不再接受分发。
现在的网络拓扑变更如下图,可以看出,Amphorae 在之中起到了关键作用,使用端口挂载的方式将 3 个不同网络中的 VIP、Member 及 Octava 服务进程串连起来,Amphorae(双耳壶)也因此得名。
现在,我们粗浅的梳理一下 Octavia Amphora Provider 的设计思路:
- Amphora 作为负载均衡器软件(HAProxy)和高可用支撑(Keepalived)的运行载体,通过 Agent 与 Octavia 服务进程通信
- Octavia 服务进程接收到用户的 loadbalancer 和 VIP 的配置参数,通过 Agent 动态修改 haproxy、keepalived 的配置文件
- 将 Member 处于的 Subnet 接入 Amphora,Amphora 通过 Member Socket (IP, Port) 分发请求数据包。
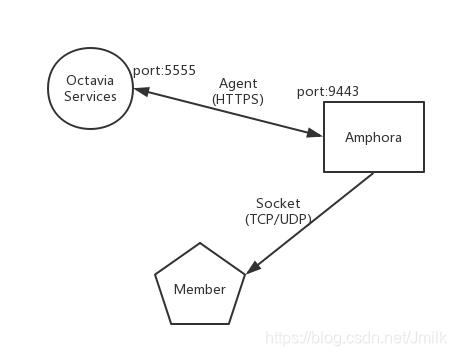
这里再补充一下与 Octavia 相关的 image 和 security group 的内容。Amphora Instance 使用特定的镜像启动,Octavia 提供了专门的镜像制作脚本,支持 centos 和 ubuntu 两种操作系统,也支持设定 password,不过在生成环境中还是建议使用 keypair 登录。至于安全组,从上图可以看出 Amphora 的安全组最起码要满足 ingress:UDP/5555 和 egress:TCP/9443 两条规则。
使用 amphora image 的步骤:
- Step 1. 上传 amphora image
$ /opt/rocky/octavia/diskimage-create/diskimage-create.sh -i ubuntu
$ openstack image create amphora-x64-haproxy \
--public \
--container-format=bare \
--disk-format qcow2 \
--file /opt/rocky/octavia/diskimage-create/amphora-x64-haproxy.qcow2 \
--tag amphora
- Step 2. 配置 amphora image
上传 amphora image 后还需要配置到[controller_worker] amp_image_owner_id, amp_image_tag中指定使用,e.g.
[controller_worker]
amp_image_owner_id = 9e4fe13a6d7645269dc69579c027fde4
amp_image_tag = amphora
...
使用 amphora security group 的步骤:
- Step 1. 创建 amphora 使用的安全组
$ openstack security group create amphora-sec-grp --project <admin project id>
$ openstack security group rule create --remote-ip "0.0.0.0/0" --dst-port 9443 --protocol tcp --ingress --ethertype IPv4 --project <admin project id> amphora-sec-grp
$ openstack security group rule create --remote-ip "0.0.0.0/0" --dst-port 5555 --protocol udp --egress --ethertype IPv4 --project <admin project id> amphora-sec-grp
- Step 2. 配置 amphora security group
[controller_worker]
amp_secgroup_list = <amphora-sec-grp id>
...
软件架构
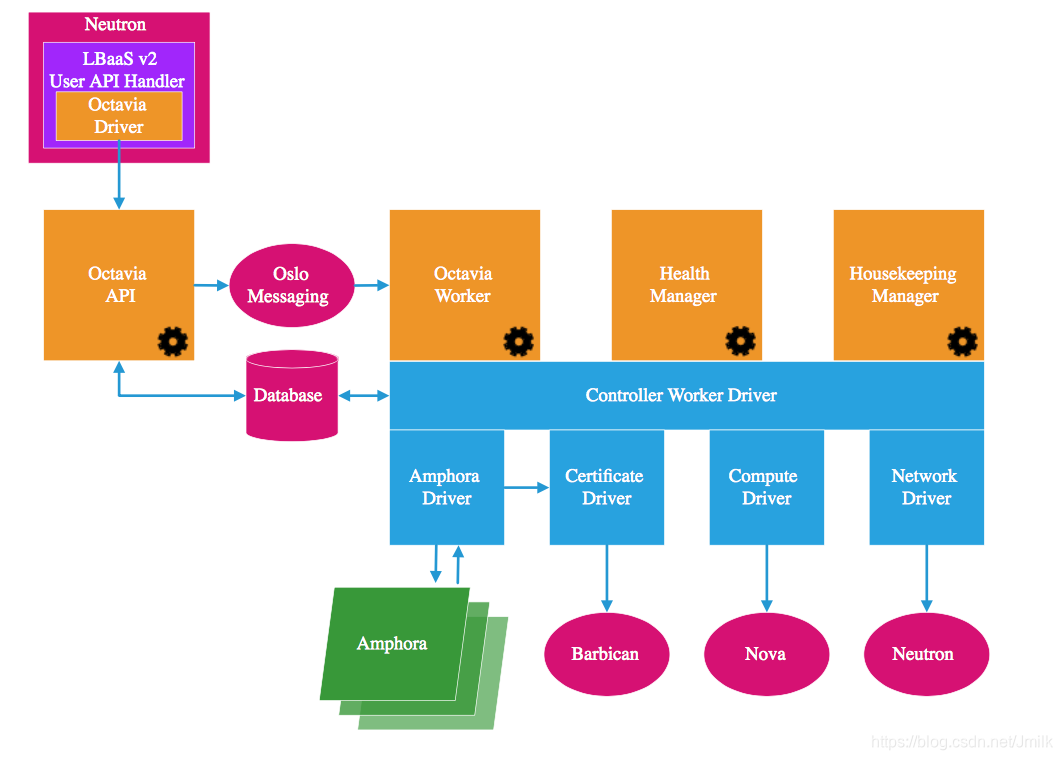
(注:图源自 Octavia 官方文档)
Octavia 的软件架构设计依旧是常见的「生产者-消费者」模型,API 与 Worker 分离并通过 MessageQueens 进行通信。
Octavia API:标准 RESTful API,Octavia v2 API(default enabled)是 LBaaS v2 API 的超集,完全向后兼容。所以版本滞后的 OS 平台也可通过 Neutron Octavia Driver 进行集成。
Octavia Controller Worker:Octavia 的核心,底层采用 Driver & Plugin 的方式代表了 OS 平台的开放性,并支撑上层实现的 3 个组件。
- Octavia Worker:负责完成 API 请求,是 Octavia 主干功能的执行者。
- Health Manager:负责保证负载均衡器的高可用性。
- Housekeeping Manager:名副其实的 Housekeeping(家政)服务,保障 Octavia 的健康运行。实现了 SpaceAmphora、DatabaseCleanup 和 CertRotation。
NOTE:需要特别说明的是,架构图中只给出了 Amphora 一种 LB Provider,但 Octavia 的 Driver 设计实际上是支持多种 LB Provider 的(e.g. F5)。其实社区一直有计划要将 openstack/neutron-lbaas repo 实现的 drivers 迁移到 Octavia,只是一直缺人做。
服务进程清单
服务清单就是软件架构的具象表现:
- octavia-api
- octaiva-worker
- octavia-health-manager
- octavia-housekeeping
代码结构
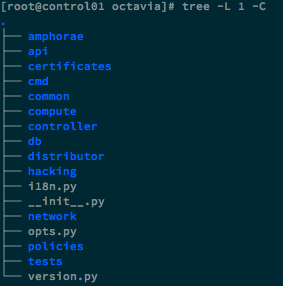
下面列举一些关键的目录:
- amphora:amphora rest api 和 amphora-agent 的实现
- api:Octavia API 的实现
- certificates:CA 认证的实现,支持 amphora 与 Octavia Worker 的 HTTPS 通信和 TLS 功能
- compute:实现了 Compute Driver 的抽象和 novaclient 的封装
- network:实现了 Network Driver 的抽象和 neutronclient 的封装
- db:ORM 的实现
- policies:定义了 API 请求的鉴权策略
继续展开 controller 目录:
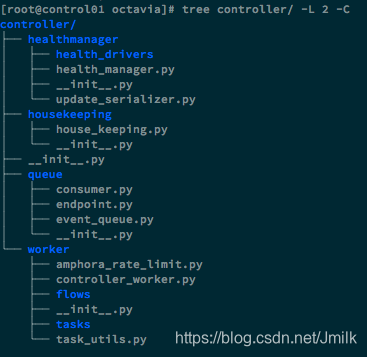
- healthmanager:Health Manager 的实现
- housekeeping Manager:HouseKeeping 的实现
- queue:内部 RPC 通信的实现,应用了 cotyledon 框架和 oslo_messaging
- 生产者:
api/handlers/queue/producer.py - 消费者:
controller/queue/consumer.py
- 生产者:
- worker:Octavia Worker 的实现,应用了 taskflow 框架
- flows:任务流的封装,每个任务都会被定义为一个 flow
- tasks:任务的封装,任务逻辑的抽象,使得任务可以高度重用
PS:cotyledon 是由社区开发用于替代 oslo.service 的第三方开源库。
Cotyledon provides a framework for defining long-running services. It provides handling of Unix signals, spawning of workers, supervision of children processes, daemon reloading, sd-notify, rate limiting for worker spawning, and more.
This library is mainly used in OpenStack Telemetry projects, in replacement of oslo.service. However, as oslo.service depends on eventlet, a different library was needed for project that do not need it. When an application do not monkeypatch the Python standard library anymore, greenlets do not in timely fashion. That made other libraries such as Tooz or oslo.messaging to fail with e.g. their heartbeat systems. Also, processes would not exist as expected due to greenpipes never being processed.
—— 摘自 cotyledon 官方文档
小结一下 Octavia 的架构设计,作为 OpenStack 的独立项目,继承了一贯优秀的开放性设计思想,在 LB Provider、Certificates Driver、Compute Driver 和 Network Driver 这些外部支撑节点都高度抽象出了 Driver 类,使得 Vendors 和 Users 更便于对接现有的基础设施。这无疑是 Octavia 甚至 OpenStack 受到欢迎的原因之一,也从一个方面回答了上文中提出的问题:为什么要抽象出这些对象?
loadbalancer 创建流程分析
要说最典型的 Octavia 实现规范,非 loadbalancer 的创建流程莫属。我们就以此作为切入点,辅以 UML 图继续深入 Octavia 的代码实现。
CLI:
$ openstack loadbalancer create --vip-subnet-id lb-vip-subnet --name lb1
API:
POST /v2.0/lbaas/loadbalancers
REQ body:
{
"loadbalancer": {
"vip_subnet_id": "c55e7725-894c-400e-bd00-57a04ae1e676",
"name": "lb1",
"admin_state_up": true
}
}
RESP:
{
"loadbalancer": {
"provider": "octavia",
"flavor_id": "",
"description": "",
"provisioning_status": "PENDING_CREATE",
"created_at": "2018-10-22T02:52:04",
"admin_state_up": true,
"updated_at": null,
"vip_subnet_id": "c55e7725-894c-400e-bd00-57a04ae1e676",
"listeners": [],
"vip_port_id": "6629fef4-fe14-4b41-9b73-8230105b2e36",
"vip_network_id": "1078e169-61cb-49bc-a513-915305995be1",
"vip_address": "10.0.1.7",
"pools": [],
"project_id": "2e560efadb704e639ee4bb3953d94afa",
"id": "5bcf8e3d-9e58-4545-bf80-4c0b905a49ad",
"operating_status": "OFFLINE",
"name": "lb1"
}
}
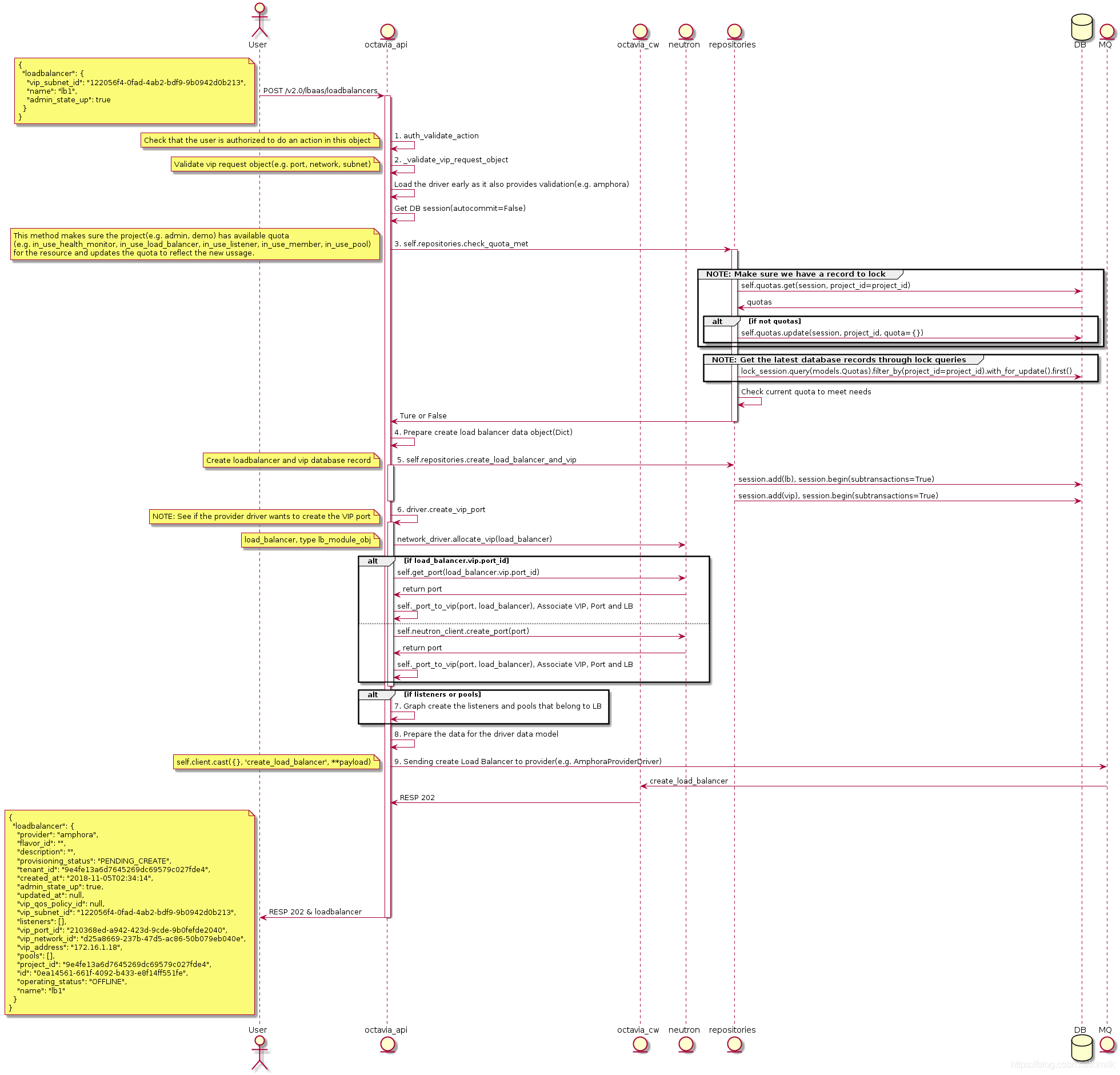
Create LB 的 Octavia API UML 图:
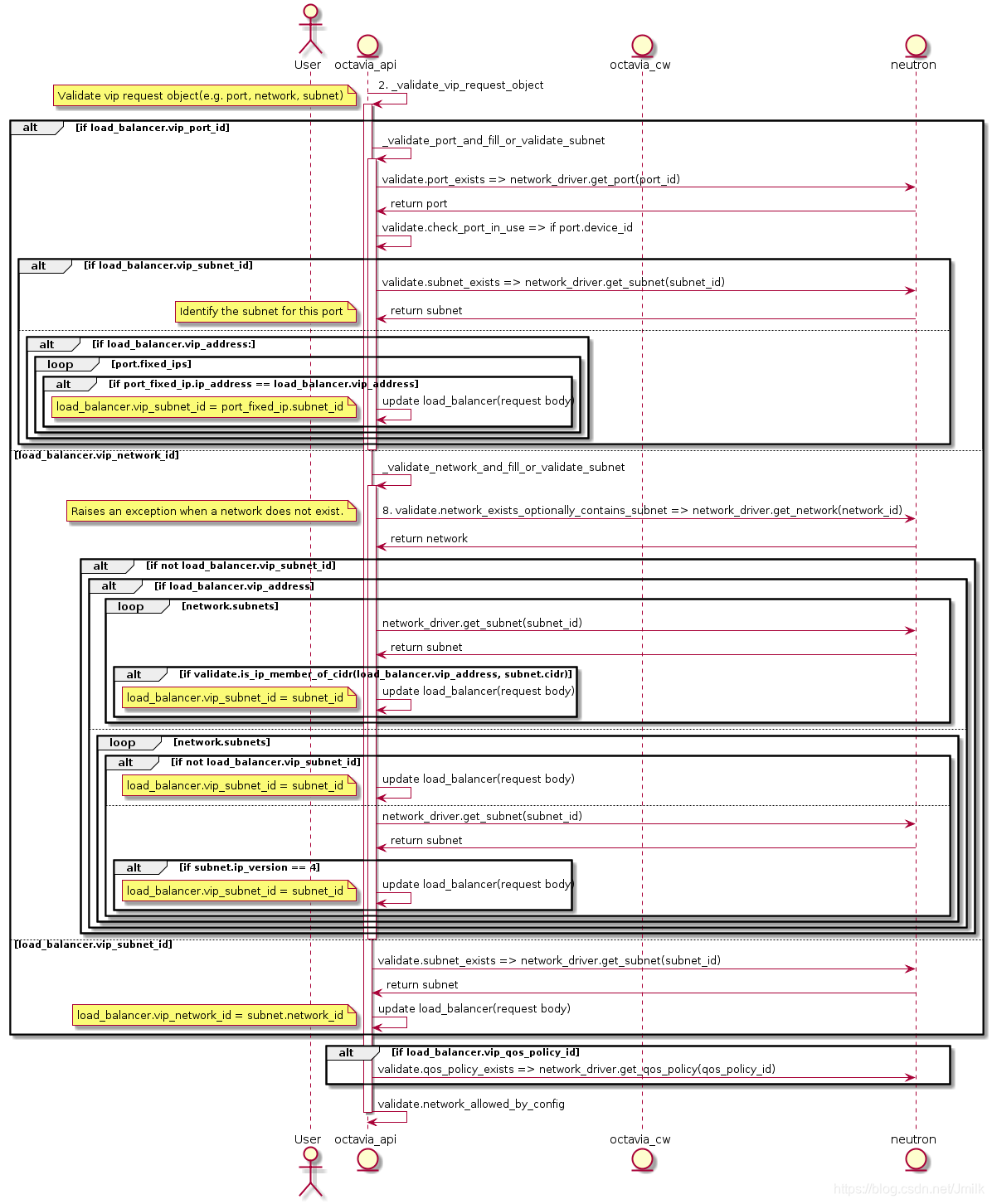
展开 2. _validate_vip_request_object 的 UML 图:
小结 octavia-api service 接收到 POST /v2.0/lbaas/loadbalancers 请求后处理的事情:
- 请求鉴权,判断用户是否有权限执行 loadbalancer 的创建。
- 验证 VIP 及其相关对象(e.g. port, subnet, network)是否可用,这里可以通过
config secition [networking]来配置Allow/disallow specific network object types when creating VIPs. - 检查用户 Project 的 LB Quota,可以通过
config section [quotas]来配置默认 Quota(e.g. 指定 Project1 只能创建 3 个 loadbalancer)。 - 创建 table load_balancer 和 vip 的数据库记录。
- 调用 Amphora driver(default lb provider)创建 VIP 对应的 port,并将 Port、VIP、LB 三者的数据库记录关联起来。
- 以 Graph flow(图流)的方式创建 loadbalancer 下属的 Listeners 和 Pools。
- 准备传入 create_loadbalancer_flow 的 stores。
- 异步调用 octavia-worker service 执行 create_loadbalancer_flow。
其中有几点值得注意:
- loadbalancer quota 依旧是通过指令
openstack quota set设定。 - 虽然
openstack loadbalancer create指令没有给出--listenersor--pools之类的选项 在创建 loadbalancer 的同时创建下属的 listeners 及 pools,但实际上POST /v2.0/lbaas/loadbalancers是可以接收这两个属性的。所以 Dashboard 的 UI/UE 可以作此项优化 。 - 如果指定的 VIP port 不存在,那么 octavia-api service 会先调用 neutronclient 创建并命名为 loadbalancer-<load_balancer_id>,所以你会在 vip-net 可以看见此类 Port。
- VIP 支持通过 network、subnet 和 port 的任意一种方式进行创建,还支持设定 VIP 的 Qos。
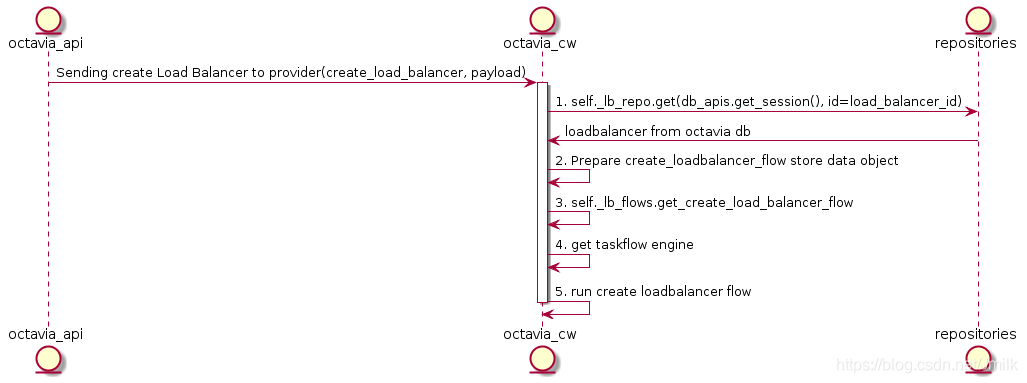
Create LB 的 Octavia Controller Worker UML 图:
展开 3. get_create_load_balancer_flow 的 UML 图:
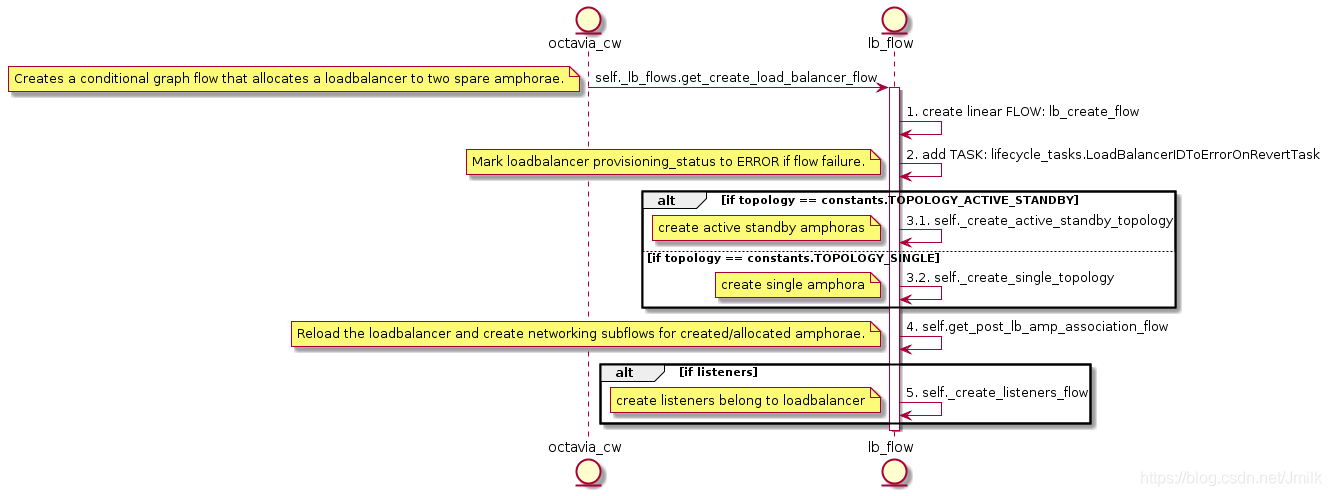
可以看出 create loadbalancer flow 主要有两点:
- create loadbalancer topology
- create networking for amphora(e)
首先解释第一点,所谓 loadbalancer topology 实质指的是 amphorae 的高可用拓扑。支持 SINGLE、ACTIVE_STANDBY 两种类型。SINGLE 顾名思义就是单节点的 amphora,不具备高可用性,也不建议在生产环境中使用;而 ACTIVE_STANDBY 则是实现了依赖 Keepalived Master/Backend 主从模式的 double amphorae。所以,本篇将不会讨论 SINGLE topology。
Create amphora topology 的 UML 图:

特意强调几个细节:
如果 loadbalancer topology 为 ACTIVE_STANDBY,还可以同时配置
[nova] enable_anti_affinity = True,应用 Nova 的反亲和性机制进一步提升高可用性。为 loadbalancer 准备 amphora 可以直接从 space amphora pool 获取,而无需即时创建 new amphora 导致浪费时间。amphora for lb flow 会先检查 space amphora pool 是否存在空闲的 amphora 可以映射到 loadbalancer。如果存在则直接映射,否则才需要启用 create new amphora 的任务流。space amphora pool 由 Housekeeping Manager 机制维护,根据配置
[house_keeping] spare_amphora_pool_size=2设定 pool size。amphora for lb flow 使用的是 graph flow(图流)类型,其特点就是无定向,即可自定义流向,开发者可以通过自定义的判断条件(
amp_for_lb_flow.link)来控制任务流向。在该 flow 中定义的判断条件为:
if loadbalancer mapping Amphora instance SUCCESS:
Upload database associations for loadbalancer and amphora
else:
Create amphora first
Upload database associations for loadbalancer and amphora
再说第二点 amphora 初始只挂靠在 lb-mgmt-net 上,被分配到 loadbalancer 后,amphora 还需要挂靠到 vip-net 上。octavia-api 阶段在 vip-net 创建的 port:loadbalancer-<load_balancer_id> 此刻就被使用上了。而且如果采用的是 ACTIVE_STANDBY topology,那么还会在 vip-net 上创建两个 VRRP_port(octavia-lb-vrrp-<amphora_id>)分别挂载到两个 amphorae 作为 Keepalived VIP 漂移的载体。
create networking for amphora(e) 的 UML 图:
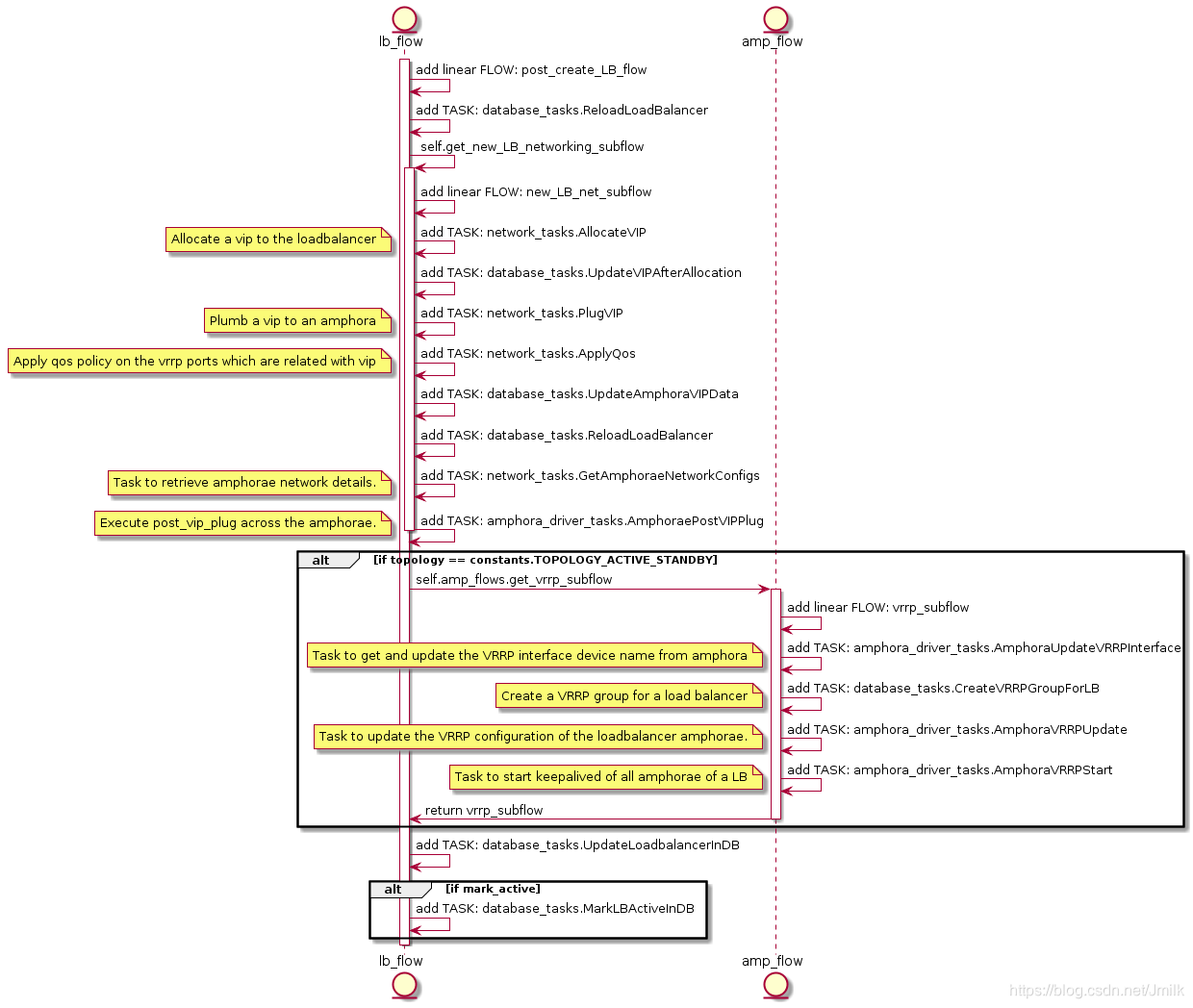
列出与 Amphora Networking 相关的几个关键任务:
- network_tasks.AllocateVIP
- network_tasks.PlugVIP
- amphora_driver_tasks.AmphoraePostVIPPlug
- amphora_driver_tasks.AmphoraVRRPUpdate
- amphora_driver_tasks.AmphoraVRRPStart
这些都是需要我们重点关注的实现,因为在实际操作中,笔者认为 Octavia Networking 是实现的重点,也是出现问题的高发区,只有掌握了底层实现才可以更好的精准定位问题。
network_tasks.AllocateVIP
AllocateVIP 调用的是 Neutron 的接口封装 AllowedAddressPairsDriver.allocate_vip method,负责确保 VIP 的 port 存在并返回一个关联了 Port、VIP 和 LB 三者的 data_models.Vip 对象。该 method 早在 octavia-api 就会被调用一次,所以程序流到 octavia-worker 一般已经把 VIP 的 Port 创建好了,之后会通过 Task:UpdateAmphoraVIPData 将 data_models.Vip 落库持久化。
network_tasks.PlugVIP
AllocateVIP 负载从 Neutron 分配 VIP,PlugVIP 则负责将 VIP 插入到 Amphora。
PlugVIP 的 UML 图:

在 PlugVIP 的逻辑实现主要有两个方面:
update VIP port 的 security_group_rules。因为外部是通过 VIP 来访问业务的,而且 Listener 也是依附于 VIP 的,所以 VIP 的安全组规则实际上是动态的。例如:为 loadbalancer 添加了一个 HTTP:8080 的 Listener,则会在相应的 VIP 上 Upload ingress HTTP:8080 规则。
轮询 loadbalancer 所有的 amphorae,检查 Amphora 是否完全具备当前所需要的 Ports,如果没有则调用 Neutron API 创建出来只有再调研 Nova API 挂载到 Amphora Instance。
create lb flow 在经过了 TASK:AllocateVIP 和 TASK:PlugVIP 之后就基本完成了 Amphora 的外部资源准备,接下来的程序流将会进入到 Amphora 的内部实现。因为之间还涉及了 Octavia Controller Worker 和 Amphora Agent 如何进行安全通信的问题。所以,我们不妨先讨论一下 Amphora Agent 和 AmphoraAPIClient 的通信实现,再回过头来看看剩下没有聊到的 3 个任务。
Amphora
上文我们提到过,Amphora 本质是一个 instance,作为 HAProxy 和 Keepalived 的运行载体。笔者认为 Amphora 是一个非常经典的类 Proxy 实现,在解决「Proxy 应该如何与中控(Octavia Controller Worker) 进行安全通信?如何自定义心跳协议?如何降低对宿主机运行环境的影响?」这些问题上作出了优秀的示范,非常值得借鉴和研究。
amphora-agent 与 Octavia Controller Worker 的通信模型图:
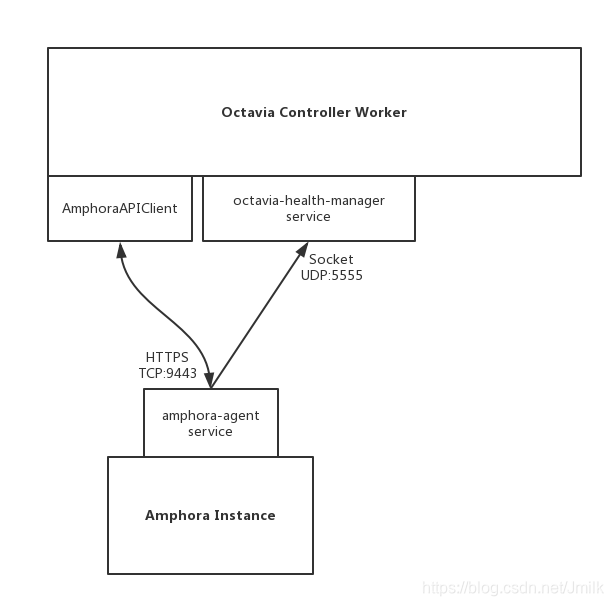
首先我们来看看 amphora-agent 与 AmphoraAPIClient 是如何建立通信的。
Amphora Agent
amphora-agent 服务进程随 Launch Amphora 一同启动,应用了 Flask & gunicorn 的实现,前者提供 Web Application,后者充当 WSGI HTTP Server。服务进程的 main 函数为 from octavia.cmd.agent import main。
# file: /opt/rocky/octavia/octavia/amphorae/backends/agent/api_server/server.py
class Server(object):
def __init__(self):
self.app = flask.Flask(__name__)
...
self.app.add_url_rule(rule=PATH_PREFIX +
'/listeners/<amphora_id>/<listener_id>/haproxy',
view_func=self.upload_haproxy_config,
methods=['PUT'])
...
上述 Server 类完成了 amphora-agent API 的路由定义和视图函数,是一个轻量级的 Flask 框架封装实现,app 对象最终被会 gunicorn 加载运行。配合官方文档 Octavia HAProxy Amphora API 即可理解各个 route_url 的含义,这里不再赘述。
AmphoraAPIClient
AmphoraAPIClient 就是 amphora-agent REST API 的客户端实现,封装了所有 Octavia HAProxy Amphora API 的 URL 请求,以供上层服务调用。
# file: /opt/rocky/octavia/octavia/amphorae/drivers/haproxy/rest_api_driver.py
class AmphoraAPIClient(object):
def __init__(self):
super(AmphoraAPIClient, self).__init__()
self.secure = False
...
回顾一下 Octavia 的通讯架构:
- Octavia API:提供面向外部的 REST API 通讯
- Queue:提供面向内部的 RPC 通讯
- Amphora Agent:提供 Amphora 与 Octavia Controller Worker 之间的 REST API 通讯

AmphoraePostVIPPlug
回过头来继续看 TASK:AmphoraePostVIPPlug 的实现。AmphoraePostVIPPlug 会轮询为所有 Amphorae 分别调用 AmphoraAPIClient 发送 PUT plug/vip/{vip} 请求到 amphora-agent 更新虚拟机的网卡配置文件和添加路由规则。为了防止出现 networks 的地址覆盖,和保证 Amphora 操作系统的清洁,AmphoraePostVIPPlug 会创建出 network namespace。将除了 Amphora 接入 lb-mgmt-net 之外的所有 NICs 都被划分到其中。
可见,AmphoraePostVIPPlug 的语义就是为 VIP 创建网卡设备文件,并将 vip-net Port 的网络信息注入到其中。具体实现为 Plug:plug_vip method,下面给出该任务的执行效果。
Amphora 初始状态下只有一个用于与 lb-mgmt-net 通信的端口:
root@amphora-cd444019-ce8f-4f89-be6b-0edf76f41b77:~# ifconfig
ens3 Link encap:Ethernet HWaddr fa:16:3e:b6:8f:a5
inet addr:192.168.0.9 Bcast:192.168.0.255 Mask:255.255.255.0
inet6 addr: fe80::f816:3eff:feb6:8fa5/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1450 Metric:1
RX packets:19462 errors:14099 dropped:0 overruns:0 frame:14099
TX packets:70317 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:1350041 (1.3 MB) TX bytes:15533572 (15.5 MB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
在 Amphora 被分配到 loadbalancer 之后会添加一个 vrrp_port 类型的端口,vrrp_port 充当着 Keepalived 虚拟路由的一张网卡,被注入到 namespace 中,一般是 eth1。
root@amphora-cd444019-ce8f-4f89-be6b-0edf76f41b77:~# ip netns exec amphora-haproxy ifconfig
eth1 Link encap:Ethernet HWaddr fa:16:3e:f4:69:4b
inet addr:172.16.1.3 Bcast:172.16.1.255 Mask:255.255.255.0
inet6 addr: fe80::f816:3eff:fef4:694b/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1450 Metric:1
RX packets:12705 errors:0 dropped:0 overruns:0 frame:0
TX packets:613211 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:762300 (762.3 KB) TX bytes:36792968 (36.7 MB)
eth1:0 Link encap:Ethernet HWaddr fa:16:3e:f4:69:4b
inet addr:172.16.1.10 Bcast:172.16.1.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1450 Metric:1
VRRP IP: 172.16.1.3 和 VIP: 172.16.1.10 均由 lb-vip-network 的 DHCP 分配,分别对应 lb-vip-network 上的 ports octavia-lb-vrrp-<amphora_uuid> 与 octavia-lb-<loadbalancer_uuid>。其中 interface eth1 的配置为:
root@amphora-cd444019-ce8f-4f89-be6b-0edf76f41b77:~# ip netns exec amphora-haproxy cat /etc/network/interfaces.d/eth1
auto eth1
iface eth1 inet dhcp
root@amphora-cd444019-ce8f-4f89-be6b-0edf76f41b77:~# ip netns exec amphora-haproxy cat /etc/network/interfaces.d/eth1.cfg
# Generated by Octavia agent
auto eth1 eth1:0
iface eth1 inet static
address 172.16.1.3
broadcast 172.16.1.255
netmask 255.255.255.0
gateway 172.16.1.1
mtu 1450
iface eth1:0 inet static
address 172.16.1.10
broadcast 172.16.1.255
netmask 255.255.255.0
# Add a source routing table to allow members to access the VIP
post-up /sbin/ip route add 172.16.1.0/24 dev eth1 src 172.16.1.10 scope link table 1
post-up /sbin/ip route add default via 172.16.1.1 dev eth1 onlink table 1
post-down /sbin/ip route del default via 172.16.1.1 dev eth1 onlink table 1
post-down /sbin/ip route del 172.16.1.0/24 dev eth1 src 172.16.1.10 scope link table 1
post-up /sbin/ip rule add from 172.16.1.10/32 table 1 priority 100
post-down /sbin/ip rule del from 172.16.1.10/32 table 1 priority 100
post-up /sbin/iptables -t nat -A POSTROUTING -p udp -o eth1 -j MASQUERADE
post-down /sbin/iptables -t nat -D POSTROUTING -p udp -o eth1 -j MASQUERADE
启动 Keepalived 服务进程
只有当 loadbalancer_topology = ACTIVE_STANDBY 时才会执行 Keepalived 启动流程,提供高可用服务。TASK:AmphoraVRRPUpdate 和 TASK:AmphoraVRRPStart 就分别负责了编辑 Keepalived 配置文件内容和启动 Keepalived 服务进程的逻辑。
TASK:AmphoraVRRPUpdate 的逻辑相对简单,就是根据 amphora topology 的 VIP port、VRRP_ports 的网络信息渲染到 keepalived.conf 配置文件的 Jinja 模板,然后通过 AmphoraAPIClient 发送 PUT vrrp/upload 请求到 amphora-agent 更新 Keepalived 配置文件的内容。
TASK:AmphoraVRRPStart 则是通过 AmphoraAPIClient 发送 PUT vrrp/start 请求执行 amphora-agent 的 view_func:manage_service_vrrp(action=start)。
# file: /opt/rocky/octavia/octavia/amphorae/backends/agent/api_server/keepalived.py
def manager_keepalived_service(self, action):
action = action.lower()
if action not in [consts.AMP_ACTION_START,
consts.AMP_ACTION_STOP,
consts.AMP_ACTION_RELOAD]:
return webob.Response(json=dict(
message='Invalid Request',
details="Unknown action: {0}".format(action)), status=400)
if action == consts.AMP_ACTION_START:
keepalived_pid_path = util.keepalived_pid_path()
try:
# Is there a pid file for keepalived?
with open(keepalived_pid_path, 'r') as pid_file:
pid = int(pid_file.readline())
os.kill(pid, 0)
# If we got here, it means the keepalived process is running.
# We should reload it instead of trying to start it again.
action = consts.AMP_ACTION_RELOAD
except (IOError, OSError):
pass
cmd = ("/usr/sbin/service octavia-keepalived {action}".format(
action=action))
try:
subprocess.check_output(cmd.split(), stderr=subprocess.STDOUT)
except subprocess.CalledProcessError as e:
LOG.debug('Failed to %s octavia-keepalived service: %s %s',
action, e, e.output)
return webob.Response(json=dict(
message="Failed to {0} octavia-keepalived service".format(
action), details=e.output), status=500)
return webob.Response(
json=dict(message='OK',
details='keepalived {action}ed'.format(action=action)),
status=202)
显然,amphora-agent 是通过执行指令 /usr/sbin/service octavia-keepalived start 来启动 keepalived 服务进程的。再看一看 octavia-keepalived.service 的内容:
# file: /usr/lib/systemd/system/octavia-keepalived.service
[Unit]
Description=Keepalive Daemon (LVS and VRRP)
After=network-online.target .service
Wants=network-online.target
Requires=.service
[Service]
# Force context as we start keepalived under "ip netns exec"
SELinuxContext=system_u:system_r:keepalived_t:s0
Type=forking
KillMode=process
ExecStart=/sbin/ip netns exec amphora-haproxy /usr/sbin/keepalived -D -d -f /var/lib/octavia/vrrp/octavia-keepalived.conf -p /var/lib/octavia/vrrp/octavia-keepalived.pid
ExecReload=/bin/kill -HUP $MAINPID
PIDFile=/var/lib/octavia/vrrp/octavia-keepalived.pid
[Install]
WantedBy=multi-user.target
从该文件可以得知:
- 真正的 keepalived 服务进程启动在了 namespace amphora-haproxy 中。
- keepalived 的配置文件路劲为
/var/lib/octavia/vrrp/octavia-keepalived.conf。
除了 start 之外,view_func:manage_service_vrrp 还支持 stop 和 reload 操作,而 keepalived 配置文件的更新则交由 view_func:upload_keepalived_config 来完成。下面继续看一看 keepalived 配置文件的内容:
# file: /var/lib/octavia/vrrp/octavia-keepalived.conf
vrrp_script check_script {
script /var/lib/octavia/vrrp/check_script.sh # VRRP check
interval 5
fall 2
rise 2
}
vrrp_instance 01197be798d5440da846cd70f52dc503 { # VRRP instance name is loadbalancer UUID
state MASTER # Master router
interface eth1 # VRRP IP device
virtual_router_id 1 # VRID
priority 100
nopreempt
garp_master_refresh 5
garp_master_refresh_repeat 2
advert_int 1
authentication {
auth_type PASS
auth_pass b76d77e
}
unicast_src_ip 172.16.1.3 # VRRP IP
unicast_peer {
172.16.1.7 # Backup router VRRP IP
}
virtual_ipaddress {
172.16.1.10 # VIP address
}
track_script {
check_script
}
}
可见 keepalived 使用了 eth1 作为 VRRP IP 和 VIP 的 interface,而且 eth1 早在 TASK:AmphoraePostVIPPlug 就已经准备好了在 namespace amphora 中。
其中脚本 check_script.sh 用于检查各个 Amphorae 的 HAProxy 的健康状况,以此作为 VIP 漂移的判断依据。
root@amphora-caa6ba0f-1a68-4f22-9be9-8521695ac4f4:~# cat /var/lib/octavia/vrrp/check_scripts/haproxy_check_script.sh
haproxy-vrrp-check /var/lib/octavia/d367b5ec-24dd-44b3-b947-e0ff72c75e66.sock; exit $?
Amphora Instance 除了会运行 amphora-agent 和 keepalived 这两个服务进程之外,肯定还少不了 haproxy。因为 haproxy 只有在创建了 listener 之后才会启动,所以我们等到分析 listener 穿件流程的时候再谈。
自此,创建 loadbalancer 的流程就终于分析完了,一言以蔽之无非准备 amphorae 和将 amphorae 接入 vip-net 尔,但其间有很多细节值得我们细细品味。
listener 创建流程分析
create listener flow 的 UML 图:
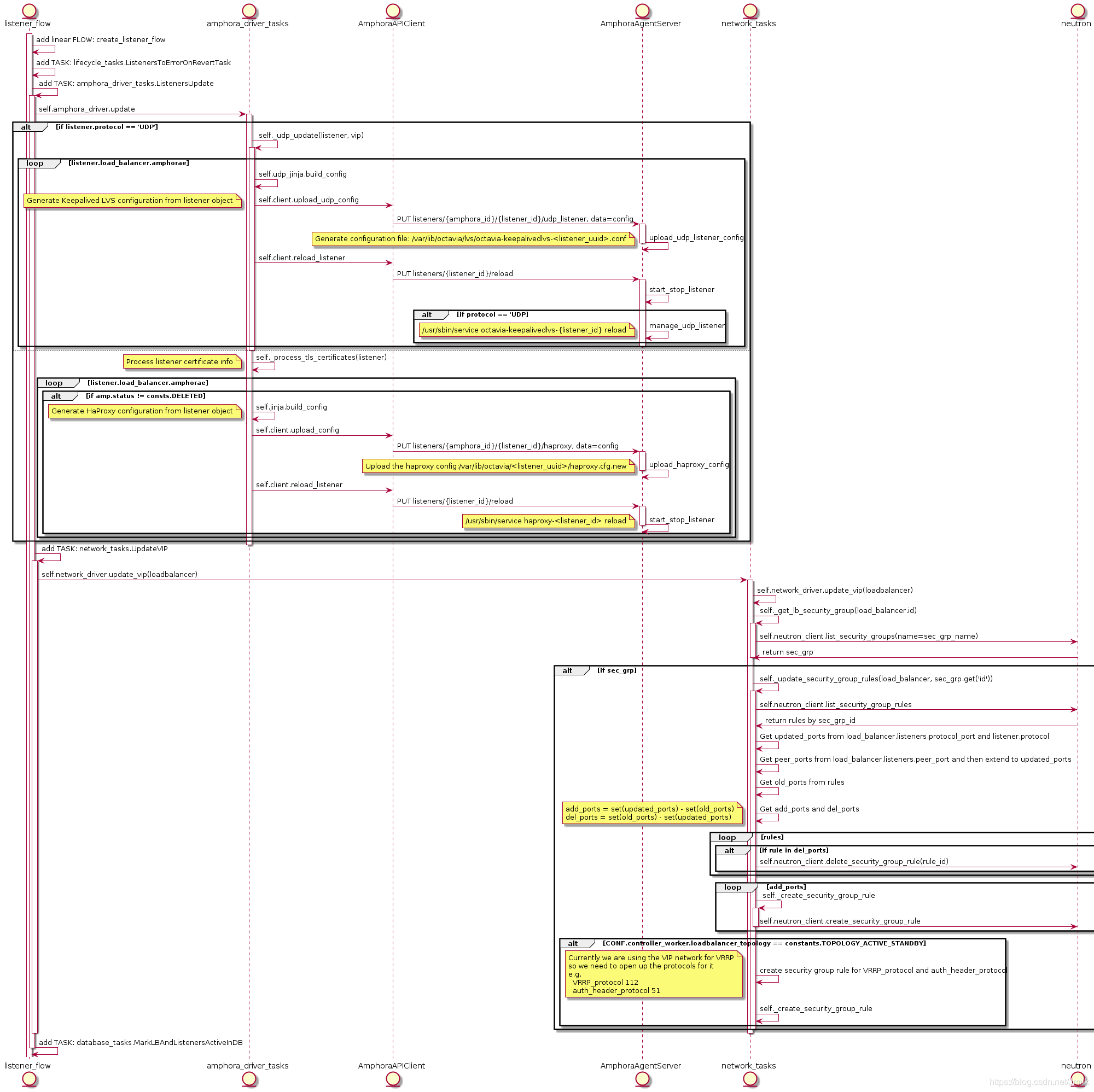
从上图可知,执行指令 openstack loadbalancer listener create --protocol HTTP --protocol-port 8080 lb-1 创建 Listener 时会执行到 Task:ListenersUpdate,在该任务中,AmphoraAPIClient 会调用:
PUT listeners/{amphora_id}/{listener_id}/haproxy:更新 haproxy 配置文件PUT listeners/{listener_id}/reload重启 haproxy 服务进程
所以,只有当为 loadbalancer 创建 listener 时才会启动 haproxy 服务进程。还有一点补充的是创建 Listener 时也会执行 Task:UpdateVIP,这是因为 Lisenter 含有的协议及端口信息都需要被更新到 VIP 的安全组规则中。
启动 haproxy 服务进程
登录 amphora 查看 haproxy 的配置文件:
# file: /var/lib/octavia/1385d3c4-615e-4a92-aea1-c4fa51a75557/haproxy.cfg, Listener UUID: 1385d3c4-615e-4a92-aea1-c4fa51a75557
# Configuration for loadbalancer 01197be7-98d5-440d-a846-cd70f52dc503
global
daemon
user nobody
log /dev/log local0
log /dev/log local1 notice
stats socket /var/lib/octavia/1385d3c4-615e-4a92-aea1-c4fa51a75557.sock mode 0666 level user
maxconn 1000000
defaults
log global
retries 3
option redispatch
peers 1385d3c4615e4a92aea1c4fa51a75557_peers
peer l_Ustq0qE-h-_Q1dlXLXBAiWR8U 172.16.1.7:1025
peer O08zAgUhIv9TEXhyYZf2iHdxOkA 172.16.1.3:1025
frontend 1385d3c4-615e-4a92-aea1-c4fa51a75557
option httplog
maxconn 1000000
bind 172.16.1.10:8080
mode http
timeout client 50000
因为 Listener 指定了监听 HTTP 协议和端口 8080,所以 frontend section 也被渲染了的 bind 172.16.1.10:8080 和 mode http 配置项。
在 Amphora 操作系统启动的 haproxy 进程是 haproxy-1385d3c4-615e-4a92-aea1-c4fa51a75557.service(ListenerUUID:1385d3c4-615e-4a92-aea1-c4fa51a75557),查看该进程的 service 配置:
# file: /usr/lib/systemd/system/haproxy-1385d3c4-615e-4a92-aea1-c4fa51a75557.service
[Unit]
Description=HAProxy Load Balancer
After=network.target syslog.service amphora-netns.service
Before=octavia-keepalived.service
Wants=syslog.service
Requires=amphora-netns.service
[Service]
# Force context as we start haproxy under "ip netns exec"
SELinuxContext=system_u:system_r:haproxy_t:s0
Environment="CONFIG=/var/lib/octavia/1385d3c4-615e-4a92-aea1-c4fa51a75557/haproxy.cfg" "USERCONFIG=/var/lib/octavia/haproxy-default-user-group.conf" "PIDFILE=/var/lib/octavia/1385d3c4-615e-4a92-aea1-c4fa51a75557/1385d3c4-615e-4a92-aea1-c4fa51a75557.pid"
ExecStartPre=/usr/sbin/haproxy -f $CONFIG -f $USERCONFIG -c -q -L O08zAgUhIv9TEXhyYZf2iHdxOkA
ExecReload=/usr/sbin/haproxy -c -f $CONFIG -f $USERCONFIG -L O08zAgUhIv9TEXhyYZf2iHdxOkA
ExecReload=/bin/kill -USR2 $MAINPID
ExecStart=/sbin/ip netns exec amphora-haproxy /usr/sbin/haproxy-systemd-wrapper -f $CONFIG -f $USERCONFIG -p $PIDFILE -L O08zAgUhIv9TEXhyYZf2iHdxOkA
KillMode=mixed
Restart=always
LimitNOFILE=2097152
[Install]
WantedBy=multi-user.target
从配置内容可以看出实际启动的服务为 /usr/sbin/haproxy-systemd-wrapper,同样运行在 namespace amphora-haproxy 中,从日志可以了解到它所做的事情就是调用了 /usr/sbin/haproxy 指令而已:
Nov 15 10:12:01 amphora-cd444019-ce8f-4f89-be6b-0edf76f41b77 ip[13206]: haproxy-systemd-wrapper: executing /usr/sbin/haproxy -f /var/lib/octavia/1385d3c4-615e-4a92-aea1-c4fa51a75557/haproxy.cfg -f /var/lib/octavia/haproxy-default-user-group.conf -p /var/lib/octavia/1385d3c4-615e-4a92-aea1-c4fa51a75557/1385d3c4-615e-4a92-aea1-c4fa51a75557.pid -L O08zAgUhIv9TEXhyYZf2iHdxOkA -Ds
除了 Listener 之外,Pool、Member、L7policy、L7rule 以及 Health Monitor 等对象的创建也会影响 haproxy 配置的变更。
pool 创建流程分析
create pool flow 的 UML 图:

create pool flow 最关键的任务依然是 Task:ListenersUpdate,更新 haproxy 的配置文件。当执行指令 openstack loadbalancer pool create --protocol HTTP --lb-algorithm ROUND_ROBIN --listener 1385d3c4-615e-4a92-aea1-c4fa51a75557 为 listener 创建一个 default pool,haproxy.cfg 就会添加一个 backend section,并且根据指令传入的参数渲染 backend mode http 和 balance roundrobin 配置项。
# Configuration for loadbalancer 01197be7-98d5-440d-a846-cd70f52dc503
global
daemon
user nobody
log /dev/log local0
log /dev/log local1 notice
stats socket /var/lib/octavia/1385d3c4-615e-4a92-aea1-c4fa51a75557.sock mode 0666 level user
maxconn 1000000
defaults
log global
retries 3
option redispatch
peers 1385d3c4615e4a92aea1c4fa51a75557_peers
peer l_Ustq0qE-h-_Q1dlXLXBAiWR8U 172.16.1.7:1025
peer O08zAgUhIv9TEXhyYZf2iHdxOkA 172.16.1.3:1025
frontend 1385d3c4-615e-4a92-aea1-c4fa51a75557
option httplog
maxconn 1000000
bind 172.16.1.10:8080
mode http
default_backend 8196f752-a367-4fb4-9194-37c7eab95714 # UUID of pool
timeout client 50000
backend 8196f752-a367-4fb4-9194-37c7eab95714
mode http
balance roundrobin
fullconn 1000000
option allbackups
timeout connect 5000
timeout server 50000
值得注意的是,创建 pool 时可以指定一个 listener uuid 或 loadbalancer uuid。当指定了前者时,意味着为 listener 指定了一个 default pool,listener 只能有一个 default pool,后续重复指定 default pool 则会触发异常;当指定了 loadbalancer uuid 时,则创建了一个 shared pool。shared pool 能被同属一个 loadbalancer 下的所有 listener 共享,常被用于辅助实现 l7policy 的功能。当 listener 的 l7policy 动作被设定为为「转发至另一个 pool」时,此时就可以选定一个 shared pool。shared pool 可以接受同属 loadbalancer 下所有 listener 的转发请求。执行指令创建一个 shared pool:
$ openstack loadbalancer pool create --protocol HTTP --lb-algorithm ROUND_ROBIN --loadbalancer 01197be7-98d5-440d-a846-cd70f52dc503
+---------------------+--------------------------------------+
| Field | Value |
+---------------------+--------------------------------------+
| admin_state_up | True |
| created_at | 2018-11-20T03:35:08 |
| description | |
| healthmonitor_id | |
| id | 822f78c3-ea2c-4770-bef0-e97f1ac2eba8 |
| lb_algorithm | ROUND_ROBIN |
| listeners | |
| loadbalancers | 01197be7-98d5-440d-a846-cd70f52dc503 |
| members | |
| name | |
| operating_status | OFFLINE |
| project_id | 9e4fe13a6d7645269dc69579c027fde4 |
| protocol | HTTP |
| provisioning_status | PENDING_CREATE |
| session_persistence | None |
| updated_at | None |
+---------------------+--------------------------------------+
注意,单纯的创建 shared pool 不将其绑定到 listener 的话,haproxy.cfg 配置文件是不会立即更改的。
member 创建流程分析
使用下述指令创建一个 member 到 default pool,选项指定云主机所在的 subnet、ipaddress 以及接收数据转发的 protocol-port。
[root@control01 ~]# openstack loadbalancer member create --subnet-id 2137f3fb-00ee-41a9-b66e-06705c724a36 --address 192.168.1.14 --protocol-port 80 8196f752-a367-4fb4-9194-37c7eab95714
+---------------------+--------------------------------------+
| Field | Value |
+---------------------+--------------------------------------+
| address | 192.168.1.14 |
| admin_state_up | True |
| created_at | 2018-11-20T06:09:58 |
| id | b6e464fd-dd1e-4775-90f2-4231444a0bbe |
| name | |
| operating_status | NO_MONITOR |
| project_id | 9e4fe13a6d7645269dc69579c027fde4 |
| protocol_port | 80 |
| provisioning_status | PENDING_CREATE |
| subnet_id | 2137f3fb-00ee-41a9-b66e-06705c724a36 |
| updated_at | None |
| weight | 1 |
| monitor_port | None |
| monitor_address | None |
| backup | False |
+---------------------+--------------------------------------+
在 octavia-api 层先会通过配置 CONF.networking.reserved_ips 验证该 member 的 ipaddress 是否可用,验证 member 所在的 subnet 是否存在,然后再进入 octavia-worker 的流程。
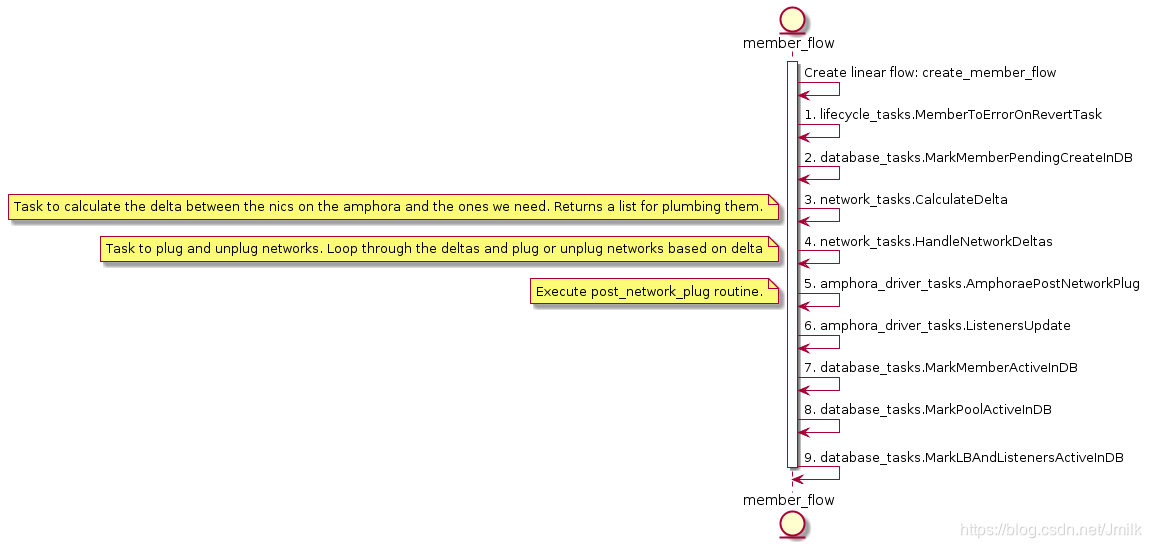
下面展开几个关键的 TASKs。
CalculateDelta
TASK:CalculateDelta 轮询 loadbalancer 下属的 Amphorae 执行 Task:CalculateAmphoraDelta,计算 Amphora 现有的 NICs 集合与预期需要的 NICs 集合之间的 “差值”。
# file: /opt/rocky/octavia/octavia/controller/worker/tasks/network_tasks.py
class CalculateAmphoraDelta(BaseNetworkTask):
default_provides = constants.DELTA
def execute(self, loadbalancer, amphora):
LOG.debug("Calculating network delta for amphora id: %s", amphora.id)
# Figure out what networks we want
# seed with lb network(s)
vrrp_port = self.network_driver.get_port(amphora.vrrp_port_id)
desired_network_ids = {vrrp_port.network_id}.union(
CONF.controller_worker.amp_boot_network_list)
for pool in loadbalancer.pools:
member_networks = [
self.network_driver.get_subnet(member.subnet_id).network_id
for member in pool.members
if member.subnet_id
]
desired_network_ids.update(member_networks)
nics = self.network_driver.get_plugged_networks(amphora.compute_id)
# assume we don't have two nics in the same network
actual_network_nics = dict((nic.network_id, nic) for nic in nics)
del_ids = set(actual_network_nics) - desired_network_ids
delete_nics = list(
actual_network_nics[net_id] for net_id in del_ids)
add_ids = desired_network_ids - set(actual_network_nics)
add_nics = list(n_data_models.Interface(
network_id=net_id) for net_id in add_ids)
delta = n_data_models.Delta(
amphora_id=amphora.id, compute_id=amphora.compute_id,
add_nics=add_nics, delete_nics=delete_nics)
return delta
简单的说,首先得到预期需要的 desired_network_ids 和已经存在的 actual_network_nics。然后计算出待删除的 delete_nics 和待添加的 add_nics,并最终 returns 一个 Delta data models 到 Task:HandleNetworkDeltas 执行实际的 Amphora NICs 挂载和卸载。
HandleNetworkDeltas
Task:HandleNetworkDelta 负载基于 Amphora Delta 挂载和卸载 networks。
# file: /opt/rocky/octavia/octavia/controller/worker/tasks/network_tasks.py
class HandleNetworkDelta(BaseNetworkTask):
"""Task to plug and unplug networks
Plug or unplug networks based on delta
"""
def execute(self, amphora, delta):
"""Handle network plugging based off deltas."""
added_ports = {}
added_ports[amphora.id] = []
for nic in delta.add_nics:
interface = self.network_driver.plug_network(delta.compute_id,
nic.network_id)
port = self.network_driver.get_port(interface.port_id)
port.network = self.network_driver.get_network(port.network_id)
for fixed_ip in port.fixed_ips:
fixed_ip.subnet = self.network_driver.get_subnet(
fixed_ip.subnet_id)
added_ports[amphora.id].append(port)
for nic in delta.delete_nics:
try:
self.network_driver.unplug_network(delta.compute_id,
nic.network_id)
except base.NetworkNotFound:
LOG.debug("Network %d not found ", nic.network_id)
except Exception:
LOG.exception("Unable to unplug network")
return added_ports
最后返回 added_port return 给后续的 TASK:AmphoraePostNetworkPlug 使用。
AmphoraePostNetworkPlug
Task:AmphoraePostNetworkPlug 负责将 member 所处网络的 port 的信息注入到 network namespace 中。需要注意区分 AmphoraePostNetworkPlug 与 AmphoraePostVIPPlug,前者在 create menber flow 中生效,用于添加连通 member tenant-net 的 interface;后者在 create lb flow 中生效,用于添加连通 vip-net 的 interface。当然了,如果说 member 与 VIP 来自同一个网络,则不再需要为 amphora 添加新的 inferface 了。
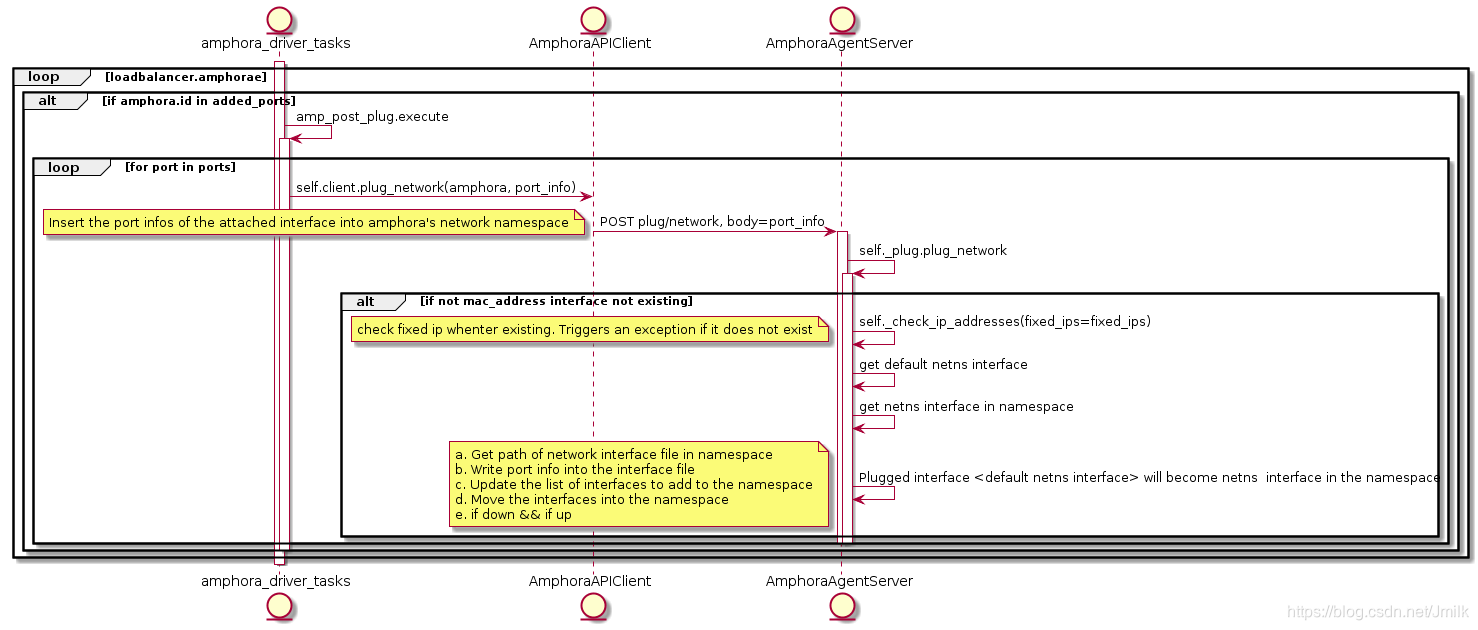
添加 member 之后再次查看 Amphora 的网络情况:
root@amphora-cd444019-ce8f-4f89-be6b-0edf76f41b77:~# ip netns exec amphora-haproxy ifconfig
eth1 Link encap:Ethernet HWaddr fa:16:3e:f4:69:4b
inet addr:172.16.1.3 Bcast:172.16.1.255 Mask:255.255.255.0
inet6 addr: fe80::f816:3eff:fef4:694b/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1450 Metric:1
RX packets:12705 errors:0 dropped:0 overruns:0 frame:0
TX packets:613211 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:762300 (762.3 KB) TX bytes:36792968 (36.7 MB)
eth1:0 Link encap:Ethernet HWaddr fa:16:3e:f4:69:4b
inet addr:172.16.1.10 Bcast:172.16.1.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1450 Metric:1
eth2 Link encap:Ethernet HWaddr fa:16:3e:18:23:7a
inet addr:192.168.1.3 Bcast:192.168.1.255 Mask:255.255.255.0
inet6 addr: fe80::f816:3eff:fe18:237a/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1450 Metric:1
RX packets:8 errors:2 dropped:0 overruns:0 frame:2
TX packets:8 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:2156 (2.1 KB) TX bytes:808 (808.0 B)
配置文件如下:
# Generated by Octavia agent
auto eth2
iface eth2 inet static
address 192.168.1.3
broadcast 192.168.1.255
netmask 255.255.255.0
mtu 1450
post-up /sbin/iptables -t nat -A POSTROUTING -p udp -o eth2 -j MASQUERADE
post-down /sbin/iptables -t nat -D POSTROUTING -p udp -o eth2 -j MASQUERADE
ListenersUpdate
最后 haproxy 配置的变更依旧是由 Task:ListenersUpdate 完成。
# Configuration for loadbalancer 01197be7-98d5-440d-a846-cd70f52dc503
global
daemon
user nobody
log /dev/log local0
log /dev/log local1 notice
stats socket /var/lib/octavia/1385d3c4-615e-4a92-aea1-c4fa51a75557.sock mode 0666 level user
maxconn 1000000
defaults
log global
retries 3
option redispatch
peers 1385d3c4615e4a92aea1c4fa51a75557_peers
peer l_Ustq0qE-h-_Q1dlXLXBAiWR8U 172.16.1.7:1025
peer O08zAgUhIv9TEXhyYZf2iHdxOkA 172.16.1.3:1025
frontend 1385d3c4-615e-4a92-aea1-c4fa51a75557
option httplog
maxconn 1000000
bind 172.16.1.10:8080
mode http
default_backend 8196f752-a367-4fb4-9194-37c7eab95714
timeout client 50000
backend 8196f752-a367-4fb4-9194-37c7eab95714
mode http
balance roundrobin
fullconn 1000000
option allbackups
timeout connect 5000
timeout server 50000
server b6e464fd-dd1e-4775-90f2-4231444a0bbe 192.168.1.14:80 weight 1
实际上,添加 member 就是在 backend(default pool)中加入了 server <member_id> 192.168.1.14:80 weight 1 项目,表示该云主机作为了 default pool 的一部分。
L7policy & L7rule & Health Monitor 的创建流程分析
L7policy 对象的语义是用于描述转发的动作类型(e.g. 转发至 pool、转发至 URL 或拒绝转发)以及 L7rule 的容器,下属于 Listener。
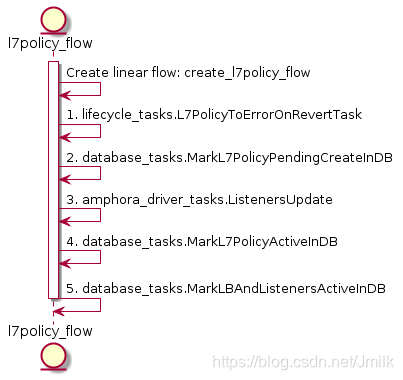
L7Rule 对象的语义是数据转发的匹配域,描述了转发的路由关系,下属于 L7policy。

Health Monitor 对象用于对 Pool 中 Member 的健康状态进行监控,本质就是一条数据库记录,描述了健康检查的的规则,下属于 Pool。
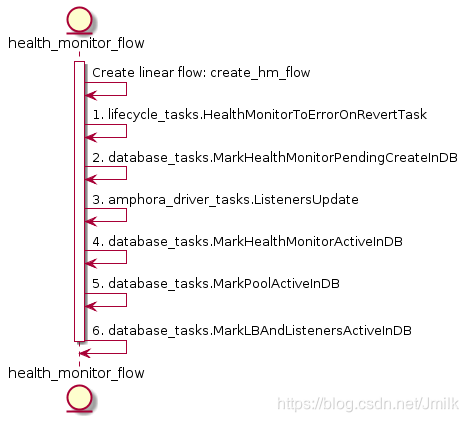
为什么将三者一同分析?从上述三个 UML 图可以感受到 Create L7policy、L7rule、Health-Monitor 和 Pool 实际上是非常类似,关键都是在于 TASK:ListenersUpdate 对 haproxy 配置文件内容的更新。所以,我们主要通过一些例子来观察 haproxy 配置文件的更改规律即可。
EXAMPLE 1. 转发至 default pool
$ openstack loadbalancer healthmonitor create --name healthmonitor1 --type PING --delay 5 --timeout 10 --max-retries 3 8196f752-a367-4fb4-9194-37c7eab95714
$ openstack loadbalancer l7policy create --name l7p1 --action REDIRECT_TO_POOL --redirect-pool 8196f752-a367-4fb4-9194-37c7eab95714 1385d3c4-615e-4a92-aea1-c4fa51a75557
$ openstack loadbalancer l7rule create --type HOST_NAME --compare-type STARTS_WITH --value "server" 87593985-e02f-4880-b80f-22a4095c05a7
haproxy.cfg:
# Configuration for loadbalancer 01197be7-98d5-440d-a846-cd70f52dc503
global
daemon
user nobody
log /dev/log local0
log /dev/log local1 notice
stats socket /var/lib/octavia/1385d3c4-615e-4a92-aea1-c4fa51a75557.sock mode 0666 level user
maxconn 1000000
external-check
defaults
log global
retries 3
option redispatch
peers 1385d3c4615e4a92aea1c4fa51a75557_peers
peer l_Ustq0qE-h-_Q1dlXLXBAiWR8U 172.16.1.7:1025
peer O08zAgUhIv9TEXhyYZf2iHdxOkA 172.16.1.3:1025
frontend 1385d3c4-615e-4a92-aea1-c4fa51a75557
option httplog
maxconn 1000000
# 前端监听 http://172.16.1.10:8080
bind 172.16.1.10:8080
mode http
# ACL 转发规则
acl 8d9b8b1e-83d7-44ca-a5b4-0103d5f90cb9 req.hdr(host) -i -m beg server
# if ACL 8d9b8b1e-83d7-44ca-a5b4-0103d5f90cb9 满足,则转发至 backend 8196f752-a367-4fb4-9194-37c7eab95714
use_backend 8196f752-a367-4fb4-9194-37c7eab95714 if 8d9b8b1e-83d7-44ca-a5b4-0103d5f90cb9
# 如果没有匹配到任何 ACL 规则,则转发至默认 backend 8196f752-a367-4fb4-9194-37c7eab95714
default_backend 8196f752-a367-4fb4-9194-37c7eab95714
timeout client 50000
backend 8196f752-a367-4fb4-9194-37c7eab95714
# 后端监听协议为 http
mode http
# 负载均衡算法为 RR 轮询
balance roundrobin
timeout check 10s
option external-check
# 使用脚本 ping-wrapper.sh 对 server 进行健康检查
external-check command /var/lib/octavia/ping-wrapper.sh
fullconn 1000000
option allbackups
timeout connect 5000
timeout server 50000
# 后端真实服务器(real server),服务端口为 80,监控检查规则为 inter 5s fall 3 rise 3
server b6e464fd-dd1e-4775-90f2-4231444a0bbe 192.168.1.14:80 weight 1 check inter 5s fall 3 rise 3
健康检查脚本,正如我们设定的 PING 方式:
#!/bin/bash
if [[ $HAPROXY_SERVER_ADDR =~ ":" ]]; then
/bin/ping6 -q -n -w 1 -c 1 $HAPROXY_SERVER_ADDR > /dev/null 2>&1
else
/bin/ping -q -n -w 1 -c 1 $HAPROXY_SERVER_ADDR > /dev/null 2>&1
fi
EXAMPLE 2. 转发至 shared pool
$ openstack loadbalancer healthmonitor create --name healthmonitor1 --type PING --delay 5 --timeout 10 --max-retries 3 822f78c3-ea2c-4770-bef0-e97f1ac2eba8
$ openstack loadbalancer l7policy create --name l7p1 --action REDIRECT_TO_POOL --redirect-pool 822f78c3-ea2c-4770-bef0-e97f1ac2eba8 1385d3c4-615e-4a92-aea1-c4fa51a75557
$ openstack loadbalancer l7rule create --type HOST_NAME --compare-type STARTS_WITH --value "server" fb90a3b5-c97c-4d99-973e-118840a7a236
haproxy.cfg:
# Configuration for loadbalancer 01197be7-98d5-440d-a846-cd70f52dc503
global
daemon
user nobody
log /dev/log local0
log /dev/log local1 notice
stats socket /var/lib/octavia/1385d3c4-615e-4a92-aea1-c4fa51a75557.sock mode 0666 level user
maxconn 1000000
external-check
defaults
log global
retries 3
option redispatch
peers 1385d3c4615e4a92aea1c4fa51a75557_peers
peer l_Ustq0qE-h-_Q1dlXLXBAiWR8U 172.16.1.7:1025
peer O08zAgUhIv9TEXhyYZf2iHdxOkA 172.16.1.3:1025
frontend 1385d3c4-615e-4a92-aea1-c4fa51a75557
option httplog
maxconn 1000000
bind 172.16.1.10:8080
mode http
acl 8d9b8b1e-83d7-44ca-a5b4-0103d5f90cb9 req.hdr(host) -i -m beg server
use_backend 8196f752-a367-4fb4-9194-37c7eab95714 if 8d9b8b1e-83d7-44ca-a5b4-0103d5f90cb9
acl c76f36bc-92c0-4f48-8d57-a13e3b1f09e1 req.hdr(host) -i -m beg server
use_backend 822f78c3-ea2c-4770-bef0-e97f1ac2eba8 if c76f36bc-92c0-4f48-8d57-a13e3b1f09e1
default_backend 8196f752-a367-4fb4-9194-37c7eab95714
timeout client 50000
backend 8196f752-a367-4fb4-9194-37c7eab95714
mode http
balance roundrobin
timeout check 10s
option external-check
external-check command /var/lib/octavia/ping-wrapper.sh
fullconn 1000000
option allbackups
timeout connect 5000
timeout server 50000
server b6e464fd-dd1e-4775-90f2-4231444a0bbe 192.168.1.14:80 weight 1 check inter 5s fall 3 rise 3
backend 822f78c3-ea2c-4770-bef0-e97f1ac2eba8
mode http
balance roundrobin
timeout check 10s
option external-check
external-check command /var/lib/octavia/ping-wrapper.sh
fullconn 1000000
option allbackups
timeout connect 5000
timeout server 50000
server 7da6f176-36c6-479a-9d86-c892ecca6ae5 192.168.1.6:80 weight 1 check inter 5s fall 3 rise 3
可见,在为 listener 添加了 shared pool 之后,会在增加一个 backend section 对应 shared pool 822f78c3-ea2c-4770-bef0-e97f1ac2eba8。
amphora 的安全通信实现
自建 CA 实现的 SSL 通信
继续看看 amphora-agent 与 Octavia Controller Worker 是如何建立安全通信的。我们不妨先思考一下:为什么 Octavia 需要自建 CA 证书?
Note: For production use the ca issuing the client certificate and the ca issuing the server certificate need to be different so a hacker can’t just use the server certificate from a compromised amphora to control all the others.
可以想象,如果 Octavia 与 Dashboard 共用证书,则不异于将 OpenStack Management/API Network 公示于众。简而言之,Octavia 自建 CA 证书主要有两个必要:
- amphora-agent 没有认证机制,需要证书来保证 API 安全
- 防止恶意用户利用 amphora 作为 “肉鸡” 攻击 OpenStack 的内部网络
Octavia 同样提供了自动化脚本,使用 OpenSSL 来创建 CA 中心。执行下述指令即可完成:
$ source /opt/rocky/octavia/bin/create_certificates.sh /etc/octavia/certs/ /opt/rocky/octavia/etc/certificates/openssl.cnf
对于 CA 中心,这里多说两句。所谓 CA,其外在表现就是一个 Directory,包含了各种类型的证书;而内在表现就是一个第三方信任机构,提供证书签发和管理服务,可以有效解决了非对称加密系统的中间人攻击问题。更多详情转《使用 OpenSSL 自建 CA 并签发证书》,这里不再赘述。
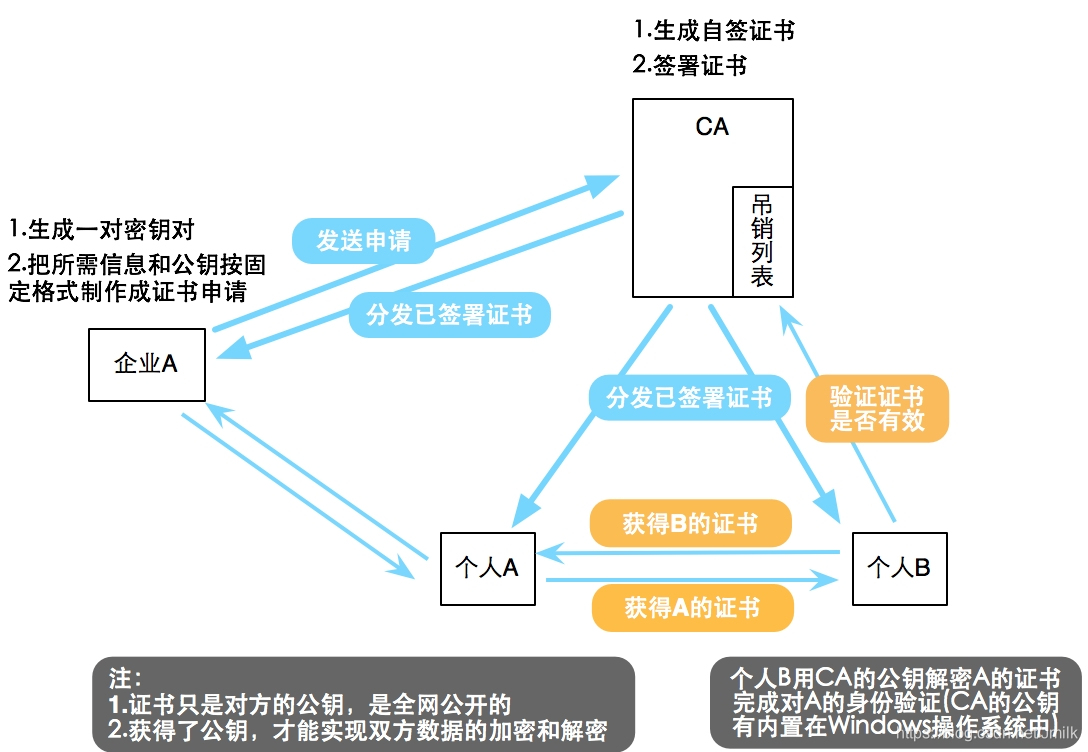
Octavia 自建的 CA 中心:
$ ll /etc/octavia/certs/
total 44
-rw-r--r-- 1 stack stack 1294 Oct 26 12:51 ca_01.pem
-rw-r--r-- 1 stack stack 989 Oct 26 12:51 client.csr
-rw-r--r-- 1 stack stack 1708 Oct 26 12:51 client.key
-rw-r--r-- 1 stack stack 4405 Oct 26 12:51 client-.pem
-rw-r--r-- 1 stack stack 6113 Oct 26 12:51 client.pem
-rw-r--r-- 1 stack stack 71 Oct 26 12:51 index.txt
-rw-r--r-- 1 stack stack 21 Oct 26 12:51 index.txt.attr
-rw-r--r-- 1 stack stack 0 Oct 26 12:51 index.txt.old
drwxr-xr-x 2 stack stack 20 Oct 26 12:51 newcerts
drwx------ 2 stack stack 23 Oct 26 12:51 private
-rw-r--r-- 1 stack stack 3 Oct 26 12:51 serial
-rw-r--r-- 1 stack stack 3 Oct 26 12:51 serial.old
- newcerts dir:存放 CA 签署(颁发)过的数字证书
- private dir:存放 CA 的私钥
- serial file:存放证书序列号(e.g. 01),每新建一张证书,序列号会自动加 1
- index.txt file:存放证书信息
- ca_01.pem PEM file:CA 证书文件
- client.csr file:Server CSR 证书签名请求文件
- client.key file:Server 私钥文件
- client-.pem:PEM 编码的 Server 证书文件
- client.pem:结合了 client-.pem 和 client.key 的文件
下面列举与 CA 认证相关的配置项:
# 应用于 create new amphora flow 的 TASK:GenerateServerPEMTask,生成 amphora 服务端证书
[certificates]
ca_private_key_passphrase = foobar
ca_private_key = /etc/octavia/certs/private/cakey.pem
ca_certificate = /etc/octavia/certs/ca_01.pem
# 应用于 AmphoraAPIClient,拿着 client.pem(包含 Server 证书、Server 私钥)和 CA 证书(公钥)向 amphora-agent 发起 SSL 通信
[haproxy_amphora]
server_ca = /etc/octavia/certs/ca_01.pem
client_cert = /etc/octavia/certs/client.pem
# 应用于 Task:CertComputeCreate,指定 CA 证书的路径
[controller_worker]
client_ca = /etc/octavia/certs/ca_01.pem
先简单梳理一下建立 SSL 通信的流程,然后再细看具体实现:
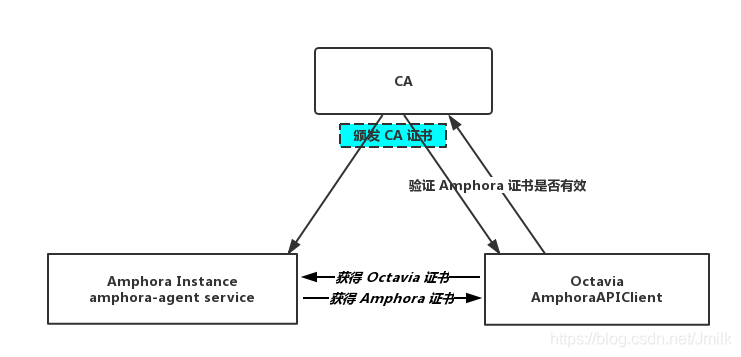
- 创建 amphora 时会向 CA 中心申请签署服务端证书,amphora-agent 服务进程启动时 Flask app 就会加载这张证书启用 HTTPS 协议。
- AmphoraAPIClient 首次发送请求至 amphora-agent 时,会使用 CA 证书来验证服务端证书,通过验证后得到服务器公钥建立 SSL 通信。
Amphora Agent 启动加载证书
首先看为 amphora 生成证书的实现:
# file: /opt/rocky/octavia/octavia/controller/worker/tasks/cert_task.py
class GenerateServerPEMTask(BaseCertTask):
"""Create the server certs for the agent comm
Use the amphora_id for the CN
"""
def execute(self, amphora_id):
cert = self.cert_generator.generate_cert_key_pair(
cn=amphora_id,
validity=CERT_VALIDITY)
return cert.certificate + cert.private_key
Octavia Certificates 提供了 local_cert_generator(default) 和 anchor_cert_generator 两种证书生成器,通过配置 [certificates] cert_generator 选用。
# file: /opt/rocky/octavia/octavia/certificates/generator/local.py
@classmethod
def generate_cert_key_pair(cls, cn, validity, bit_length=2048,
passphrase=None, **kwargs):
pk = cls._generate_private_key(bit_length, passphrase)
csr = cls._generate_csr(cn, pk, passphrase)
cert = cls.sign_cert(csr, validity, **kwargs)
cert_object = local_common.LocalCert(
certificate=cert,
private_key=pk,
private_key_passphrase=passphrase
)
return cert_object
上述 LocalCertGenerator.generate_cert_key_pair 的语义是:
- 生成 Amphora 私钥
- 生成 Amphora 证书签名请求(CSR)
- 向 CA 中心申请签署 Amphora 服务端证书
属于常规的证书创建流程,与 create_certificates.sh 脚本的区别在于,Octavia Certificates 应用了 cryptography 库来实现。
TASK:GenerateServerPEMTask 最终 return 了 Amphora 私钥和证书,然后被 TASK:CertComputeCreate 通过 Nova 的 userdata 和 Nova Store metadata on a configuration drive 机制将这些文件注入到 amphora instance 内。登录 amphora 即可查看这些文件,路径记录在配置文件中:
# file: /etc/octavia/amphora-agent.conf
[amphora_agent]
agent_server_ca = /etc/octavia/certs/client_ca.pem
agent_server_cert = /etc/octavia/certs/server.pem
Gunicorn HTTP Server 启动时就会将证书文件加载, 加载证书的 options 如下:
options = {
'bind': bind_ip_port,
'workers': 1,
'timeout': CONF.amphora_agent.agent_request_read_timeout,
'certfile': CONF.amphora_agent.agent_server_cert,
'ca_certs': CONF.amphora_agent.agent_server_ca,
'cert_reqs': True,
'preload_app': True,
'accesslog': '/var/log/amphora-agent.log',
'errorlog': '/var/log/amphora-agent.log',
'loglevel': 'debug',
}
key:certfile:上传 amphora-agent 的私钥和证书。key:ca_certs:上传 amphora-agent 的 CA 证书
AmphoraAPIClient 发送证书请求
class AmphoraAPIClient(object):
def __init__(self):
super(AmphoraAPIClient, self).__init__()
...
self.session = requests.Session()
self.session.cert = CONF.haproxy_amphora.client_cert
self.ssl_adapter = CustomHostNameCheckingAdapter()
self.session.mount('https://', self.ssl_adapter)
...
def request(self, method, amp, path='/', timeout_dict=None, **kwargs):
...
LOG.debug("request url %s", path)
_request = getattr(self.session, method.lower())
_url = self._base_url(amp.lb_network_ip) + path
LOG.debug("request url %s", _url)
reqargs = {
'verify': CONF.haproxy_amphora.server_ca,
'url': _url,
'timeout': (req_conn_timeout, req_read_timeout), }
reqargs.update(kwargs)
headers = reqargs.setdefault('headers', {})
...
上述代码是 requests 库启用 HTTPS 请求的常规实现:
self.session.cert:上传 Octavia(AmphoraAPIClient)的私钥和证书reqargs = {'verify': CONF.haproxy_amphora.server_ca, ...}:发送携带的 CA 证书的请求
最后简单终结一下 Octavia 通过自建 CA 实现 Amphora 与 Octavia Controller Worker 进行 HTTPS 通信的流程:当 AmphoraAPIClient 第一次请求 amphora-agent 时,AmphoraAPIClient 首先会拉下 amphora-agent 证书,然后与本地的 CA 证书进行验证。因为 amphora-agent 证书也是使用 CA 私钥加密的,所以可以被 CA 证书解密。若通过验证则获得 amphora-agent 的公钥,与 amphora-agent 上传的私钥比对,建立 SSL 通道。
amphora 的故障转移实现
Health Manager
Health Manager - This subcomponent monitors individual amphorae to ensure they are up and running, and otherwise healthy. It also handles failover events if amphorae fail unexpectedly.
简单的说,Health Manager 用于监控每个 amphora 的监控状态,如果 amphora 出现故障,则启动故障转移流程,以此来保障 LB 的高可用性。
那么掌握 Health Manager Service,就是要搞清楚它是如何监控 amphora 的健康状态的,然后再弄明白故障转移的流程细节。
监控 amphora 健康状态
还是从程序入口(octavia/cmd/health_manager.py)看起 ,启动 octavia-health-manager service 加载了 UDPStatusGetter.check() 和 HealthManager.health_check() 两个 method,我们先看看前者的实现。
# file: /opt/rocky/octavia/octavia/amphorae/drivers/health/heartbeat_udp.py
class UDPStatusGetter(object):
"""This class defines methods that will gather heatbeats
The heartbeats are transmitted via UDP and this class will bind to a port
and absorb them
"""
def __init__(self):
self.key = cfg.CONF.health_manager.heartbeat_key
self.ip = cfg.CONF.health_manager.bind_ip
self.port = cfg.CONF.health_manager.bind_port
self.sockaddr = None
LOG.info('attempting to listen on %(ip)s port %(port)s',
{'ip': self.ip, 'port': self.port})
self.sock = None
self.update(self.key, self.ip, self.port)
self.executor = futures.ProcessPoolExecutor(
max_workers=cfg.CONF.health_manager.status_update_threads)
self.repo = repositories.Repositories().amphorahealth
def update(self, key, ip, port):
"""Update the running config for the udp socket server
:param key: The hmac key used to verify the UDP packets. String
:param ip: The ip address the UDP server will read from
:param port: The port the UDP server will read from
:return: None
"""
self.key = key
for addrinfo in socket.getaddrinfo(ip, port, 0, socket.SOCK_DGRAM):
ai_family = addrinfo[0]
self.sockaddr = addrinfo[4]
if self.sock is not None:
self.sock.close()
self.sock = socket.socket(ai_family, socket.SOCK_DGRAM)
self.sock.settimeout(1)
self.sock.bind(self.sockaddr)
if cfg.CONF.health_manager.sock_rlimit > 0:
rlimit = cfg.CONF.health_manager.sock_rlimit
LOG.info("setting sock rlimit to %s", rlimit)
self.sock.setsockopt(socket.SOL_SOCKET, socket.SO_RCVBUF,
rlimit)
break # just used the first addr getaddrinfo finds
if self.sock is None:
raise exceptions.NetworkConfig("unable to find suitable socket")
Class:UDPStatusGetter 在 octavia-health-manager service 中负责接收从 amphora 发送过来的 heatbeats(心跳包),然后 prepare heatbeats 中的数据并持久化到数据库中。从 __init__() 看出 amphora 与 octavia-health-manager service 的通信实现是 UDP socket,socket 为 (CONF.health_manager.bind_ip, CONF.health_manager.bind_port)。
NOTE:这里需要强调一下 amphora 与 octavia-health-manager service 通信的网络拓扑细节。
如果部署 Octavia 时,直接使用 ext-net 作为 octavia 的 “lb-mgmt-net”,那么 CONF.health_manager.bind_ip 应该是物理主机的 IP 地址,amphora 与 octavia-health-manager service 直接通过 OpenStack Management Network 进行通信。不过这种方式,amphora 会占用 ext-net 的 fixed ip,所以在生产环境中并不建议使用该方式。
如果部署 Octavia 时,使用另外创建的 tenant network 作为 lb-mgmt-net,那么 CONF.health_manager.bind_ip 就应该是 lb-mgmt-net IP pool 中的地址。那么就需要解决 lb-mgmt-net 与 OpenStack Management Network 互通的问题。其中 devstack 的做法是将 lb-mgmt-net 的一个 port 挂载到 ex-int 上,lb-mgmt-net 中的 amphora 就可以通过这个 port 与运行在物理主机上的 octavia-health-manager service 进行通信了。而在生产环境中,就需要结合现场环境的网络环境由网管进行配置了。
Devstack 打通本地网络的指令:
$ neutron port-create --name octavia-health-manager-standalone-listen-port \
--security-group <lb-health-mgr-sec-grp> \
--device-owner Octavia:health-mgr \
--binding:host_id=<hostname> lb-mgmt-net \
--tenant-id <octavia service>
$ ovs-vsctl --may-exist add-port br-int o-hm0 \
-- set Interface o-hm0 type=internal \
-- set Interface o-hm0 external-ids:iface-status=active \
-- set Interface o-hm0 external-ids:attached-mac=<Health Manager Listen Port MAC> \
-- set Interface o-hm0 external-ids:iface-id=<Health Manager Listen Port ID>
# /etc/octavia/dhcp/dhclient.conf
request subnet-mask,broadcast-address,interface-mtu;
do-forward-updates false;
$ ip link set dev o-hm0 address <Health Manager Listen Port MAC>
$ dhclient -v o-hm0 -cf /etc/octavia/dhcp/dhclient.conf
o-hm0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 192.168.0.4 netmask 255.255.255.0 broadcast 192.168.0.255
inet6 fe80::f816:3eff:fef0:b9ee prefixlen 64 scopeid 0x20<link>
ether fa:16:3e:f0:b9:ee txqueuelen 1000 (Ethernet)
RX packets 1240893 bytes 278415460 (265.5 MiB)
RX errors 0 dropped 45 overruns 0 frame 0
TX packets 417078 bytes 75842972 (72.3 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
回到主题,UDPStatusGetter.check() 的实现是:
def check(self):
try:
obj, srcaddr = self.dorecv()
except socket.timeout:
# Pass here as this is an expected cycling of the listen socket
pass
except exceptions.InvalidHMACException:
# Pass here as the packet was dropped and logged already
pass
except Exception as e:
LOG.warning('Health Manager experienced an exception processing a'
'heartbeat packet. Ignoring this packet. '
'Exception: %s', e)
else:
self.executor.submit(update_health, obj, srcaddr)
self.executor.submit(update_stats, obj, srcaddr)
- 调用
self.dorecv()接收数据 - 调用
self.executor.submit(update_health, obj, srcaddr)将 health 持久化到 table amphora_health - 调用
self.executor.submit(update_stats, obj, srcaddr)将 stats 持久化到 table listener_statistics
继续看 amphora 是怎么发出 heatbeats。
# file: /opt/rocky/octavia/octavia/cmd/agent.py
def main():
# comment out to improve logging
service.prepare_service(sys.argv)
gmr.TextGuruMeditation.setup_autorun(version)
health_sender_proc = multiproc.Process(name='HM_sender',
target=health_daemon.run_sender,
args=(HM_SENDER_CMD_QUEUE,))
health_sender_proc.daemon = True
health_sender_proc.start()
# Initiate server class
server_instance = server.Server()
bind_ip_port = utils.ip_port_str(CONF.haproxy_amphora.bind_host,
CONF.haproxy_amphora.bind_port)
options = {
'bind': bind_ip_port,
'workers': 1,
'timeout': CONF.amphora_agent.agent_request_read_timeout,
'certfile': CONF.amphora_agent.agent_server_cert,
'ca_certs': CONF.amphora_agent.agent_server_ca,
'cert_reqs': True,
'preload_app': True,
'accesslog': '/var/log/amphora-agent.log',
'errorlog': '/var/log/amphora-agent.log',
'loglevel': 'debug',
}
AmphoraAgent(server_instance.app, options).run()
在启动 amphora-agent 服务进程时,加载了 health_daemon.run_sender 这就是 amphora 向 octavia-health-manager service 发送心跳包的实现。
# file: /opt/rocky/octavia/octavia/amphorae/backends/health_daemon/health_daemon.py
def run_sender(cmd_queue):
LOG.info('Health Manager Sender starting.')
sender = health_sender.UDPStatusSender()
keepalived_cfg_path = util.keepalived_cfg_path()
keepalived_pid_path = util.keepalived_pid_path()
while True:
try:
# If the keepalived config file is present check
# that it is running, otherwise don't send the health
# heartbeat
if os.path.isfile(keepalived_cfg_path):
# Is there a pid file for keepalived?
with open(keepalived_pid_path, 'r') as pid_file:
pid = int(pid_file.readline())
os.kill(pid, 0)
message = build_stats_message()
sender.dosend(message)
except IOError as e:
# Missing PID file, skip health heartbeat
if e.errno == errno.ENOENT:
LOG.error('Missing keepalived PID file %s, skipping health '
'heartbeat.', keepalived_pid_path)
else:
LOG.error('Failed to check keepalived and haproxy status due '
'to exception %s, skipping health heartbeat.', e)
except OSError as e:
# Keepalived is not running, skip health heartbeat
if e.errno == errno.ESRCH:
LOG.error('Keepalived is configured but not running, '
'skipping health heartbeat.')
else:
LOG.error('Failed to check keepalived and haproxy status due '
'to exception %s, skipping health heartbeat.', e)
except Exception as e:
LOG.error('Failed to check keepalived and haproxy status due to '
'exception %s, skipping health heartbeat.', e)
try:
cmd = cmd_queue.get_nowait()
if cmd == 'reload':
LOG.info('Reloading configuration')
CONF.reload_config_files()
elif cmd == 'shutdown':
LOG.info('Health Manager Sender shutting down.')
break
except queue.Empty:
pass
time.sleep(CONF.health_manager.heartbeat_interval)
run_sender function 调用了 build_stats_message() 构建 heatbeats,然后调用 UDPStatusSender.dosend() 来发送数据。注意,当 keepalived 服务进程没有正常运行的时候,是不会发送 heatbeats 的。也就是说 keepalived 不正常的 amphora 就会被当作故障 amphora 处理。数据发送依旧使用了 UDP socket,目标 URL 由 CONF.health_manager.controller_ip_port_list 设定。
# file: /etc/octavia/octavia.conf
[health_manager]
bind_port = 5555
bind_ip = 192.168.0.4
controller_ip_port_list = 192.168.0.4:5555
简而言之,octavia-health-manager 与 amphora-agent 之间实现了周期性的心跳协议来监控 amphora 的健康状态。
failover 故障转移
故障转移机制由 health_manager.HealthManager.health_check() 周期性监控和触发。
health_check method 周期性的从 table amphora_health 获取所谓的 stale amphora 记录,也就是过期没有上报 heatbeats 被判定为故障的 amphora:
# file: /opt/rocky/octavia/octavia/db/repositories.py
def get_stale_amphora(self, session):
"""Retrieves a stale amphora from the health manager database.
:param session: A Sql Alchemy database session.
:returns: [octavia.common.data_model]
"""
timeout = CONF.health_manager.heartbeat_timeout
expired_time = datetime.datetime.utcnow() - datetime.timedelta(
seconds=timeout)
amp = session.query(self.model_class).with_for_update().filter_by(
busy=False).filter(
self.model_class.last_update < expired_time).first()
if amp is None:
return None
amp.busy = True
return amp.to_data_model()
如果存在 stale amphora 并且 loadbalancer status 不处于 PENDING_UPDATE,那么就会进入 failover amphora 流程,failover amphora 的 taskflow 是 self._amphora_flows.get_failover_flow。
failover 的 UML 图:

很明显,整个 failover_flow 分为 delete old amphora 和 get a new amphora 两大部分。而且大部分的 TASKs 我们前文都有分析,所以下面简单罗列任务的功能即可。
- delete old amphora
- MarkAmphoraPendingDeleteInDB
- MarkAmphoraHealthBusy
- ComputeDelete:删除 amphora
- WaitForPortDetach:卸载 amphora 上的 port(s)
- MarkAmphoraDeletedInDB
NOTE:如果故障的 amphora 是一个 free amphora,那么直接删除掉即可。
- get a new amphora
- get_amphora_for_lb_subflow:获取一个可用的 free amphora
- UpdateAmpFailoverDetails:将 old amphora 的信息(table amphora)更新到 new amphora
- ReloadLoadBalancer & ReloadAmphora:从数据库获取 loadbalancer 和 amphora 的记录作为 stores 传入 flow 中
- GetAmphoraeNetworkConfigs & GetListenersFromLoadbalancer & GetAmphoraeFromLoadbalancer:获取 listener、amphora 及其网络信息, 作为 stores 传入 flow 中,准备重建 amphora 网络模型
- PlugVIPPort:为 amphora 设定 keepalived 的 VIP NIC
- AmphoraPostVIPPlug:将 amphora 的 VIP NIC 注入 network namespace 中
update_amps_subflow\AmpListenersUpdate:根据 listener 数据更新 amphora 的 haproxy 配置文件,该 flow 为 unordered 类型,所以如果存在多个 listener 则会并发执行。 - CalculateAmphoraDelta:计算 amphora 需要的 NICs 和 amphora 已存在的 NICs 的差值
- HandleNetworkDelta:根据上述的差值添加或删除 NICs
- AmphoraePostNetworkPlug:添加一个 port 连接到 member 所处于的 subnet 中
ReloadLoadBalancer - MarkAmphoraMasterInDB
- AmphoraUpdateVRRPInterface:根据 amphora 的 role 获取并更新 table amphora 中的 VRRP intreface name(字段:vrrp_interface)
- CreateVRRPGroupForLB:根据 amphora 的 role 更新 loadbalancer’s 主从 amphorae 的 group
- AmphoraVRRPUpdate:根据 amphora 的 role 更新 keepalived 服务进程的 VRRP 配置
- AmphoraVRRPStart:启动 keepalived 服务进程
- ListenersStart:启动 haproxy 服务进程
- DisableAmphoraHealthMonitoring:删除对应的 amphora_health 数据库记录
简单终结一下 amphora failover 的思路,首先删除故障的 old amphora,然后获取一个可用的 new amphora,将 old 的关联系数据(e.g. database)以及对象(e.g. 网络模型)转移的 new。
需要注意的是:
It seems intuitive to boot an amphora prior to deleting the old amphora, however this is a complicated issue. If the target host (due to anit-affinity) is resource constrained, this will fail where a post-delete will succeed. Since this is async with the API it would result in the LB ending in ERROR though the amps are still alive. Consider in the future making this a complicated try-on-failure-retry flow, or move upgrade failovers to be synchronous with the API. For now spares pool and act/stdby will mitigate most of this delay.
虽然故障转移就是 delete old amphora 然后 get new amphora,但实际上过程却是复杂的。例如:在删除 old amphora 成功后,创建 new amphora 却可能会由于资源限制导致失败;再例如:由于异步的 API 调用,所以也有可能 create new amphora 成功了,但 loadbalancer 的状态已变成 ERROR。对于异步 API 的问题,将来可能会考虑使用同步 API 来解决,但就目前来说更加依赖于 space amphora 来缓解异步创建的时延问题。
故障迁移测试
关闭 MASTER amphora 的电源,octavia-health-manager service 触发 amphora failover。
Nov 22 11:22:31 control01 octavia-health-manager[29147]: INFO octavia.controller.healthmanager.health_manager [-] Stale amphora's id is: cd444019-ce8f-4f89-be6b-0edf76f41b77
Nov 22 11:22:31 control01 octavia-health-manager[29147]: INFO octavia.controller.healthmanager.health_manager [-] Waiting for 1 failovers to finish
old amphorae:
2ddc4ba5-b829-4962-93d8-562de91f1dab | amphora-4ff5d6fe-854c-4022-8194-0c6801a7478b | ACTIVE | lb-mgmt-net=192.168.0.23 | amphora-x64-haproxy | m1.amphora |
| b237b2b8-afe4-407b-83f2-e2e60361fa07 | amphora-bcff6f9e-4114-4d43-a403-573f1d97d27e | ACTIVE | lb-mgmt-net=192.168.0.11 | amphora-x64-haproxy | m1.amphora |
| 46eccf47-be10-47ec-89b2-0de44ea3caec | amphora-cd444019-ce8f-4f89-be6b-0edf76f41b77 | ACTIVE | lb-mgmt-net=192.168.0.9; web-server-net=192.168.1.3; lb-vip-net=172.16.1.3 | amphora-x64-haproxy | m1.amphora |
| bc043b23-d481-45c4-9410-f7b349987c98 | amphora-a1c1ba86-6f99-4f60-b469-a4a29d7384c5 | ACTIVE | lb-mgmt-net=192.168.0.3; web-server-net=192.168.1.12; lb-vip-net=172.16.1.7 | amphora-x64-haproxy | m1.amphora |
new amphoras:
| 712ff785-c082-4b53-994c-591d1ec0bf7b | amphora-caa6ba0f-1a68-4f22-9be9-8521695ac4f4 | ACTIVE | lb-mgmt-net=192.168.0.13 | amphora-x64-haproxy | m1.amphora |
| 2ddc4ba5-b829-4962-93d8-562de91f1dab | amphora-4ff5d6fe-854c-4022-8194-0c6801a7478b | ACTIVE | lb-mgmt-net=192.168.0.23; web-server-net=192.168.1.4; lb-vip-net=172.16.1.3 | amphora-x64-haproxy | m1.amphora |
| b237b2b8-afe4-407b-83f2-e2e60361fa07 | amphora-bcff6f9e-4114-4d43-a403-573f1d97d27e | ACTIVE | lb-mgmt-net=192.168.0.11 | amphora-x64-haproxy | m1.amphora |
| bc043b23-d481-45c4-9410-f7b349987c98 | amphora-a1c1ba86-6f99-4f60-b469-a4a29d7384c5 | ACTIVE | lb-mgmt-net=192.168.0.3; web-server-net=192.168.1.12; lb-vip-net=172.16.1.7 | amphora-x64-haproxy | m1.amphora |
new amphora haproxy config:
# Configuration for loadbalancer 01197be7-98d5-440d-a846-cd70f52dc503
global
daemon
user nobody
log /dev/log local0
log /dev/log local1 notice
stats socket /var/lib/octavia/1385d3c4-615e-4a92-aea1-c4fa51a75557.sock mode 0666 level user
maxconn 1000000
external-check
defaults
log global
retries 3
option redispatch
peers 1385d3c4615e4a92aea1c4fa51a75557_peers
peer 3dVescsRZ-RdRBfYVLW6snVI9gI 172.16.1.3:1025
peer l_Ustq0qE-h-_Q1dlXLXBAiWR8U 172.16.1.7:1025
frontend 1385d3c4-615e-4a92-aea1-c4fa51a75557
option httplog
maxconn 1000000
bind 172.16.1.10:8080
mode http
acl 8d9b8b1e-83d7-44ca-a5b4-0103d5f90cb9 req.hdr(host) -i -m beg server
use_backend 8196f752-a367-4fb4-9194-37c7eab95714 if 8d9b8b1e-83d7-44ca-a5b4-0103d5f90cb9
acl c76f36bc-92c0-4f48-8d57-a13e3b1f09e1 req.hdr(host) -i -m beg server
use_backend 822f78c3-ea2c-4770-bef0-e97f1ac2eba8 if c76f36bc-92c0-4f48-8d57-a13e3b1f09e1
default_backend 8196f752-a367-4fb4-9194-37c7eab95714
timeout client 50000
backend 8196f752-a367-4fb4-9194-37c7eab95714
mode http
balance roundrobin
timeout check 10s
option external-check
external-check command /var/lib/octavia/ping-wrapper.sh
fullconn 1000000
option allbackups
timeout connect 5000
timeout server 50000
server b6e464fd-dd1e-4775-90f2-4231444a0bbe 192.168.1.14:80 weight 1 check inter 5s fall 3 rise 3
backend 822f78c3-ea2c-4770-bef0-e97f1ac2eba8
mode http
balance roundrobin
timeout check 10s
option external-check
external-check command /var/lib/octavia/ping-wrapper.sh
fullconn 1000000
option allbackups
timeout connect 5000
timeout server 50000
server 7da6f176-36c6-479a-9d86-c892ecca6ae5 192.168.1.6:80 weight 1 check inter 5s fall 3 rise 3
new amphora keepalived config:
vrrp_script check_script {
script /var/lib/octavia/vrrp/check_script.sh
interval 5
fall 2
rise 2
}
vrrp_instance 01197be798d5440da846cd70f52dc503 {
state MASTER
interface eth1
virtual_router_id 1
priority 100
nopreempt
garp_master_refresh 5
garp_master_refresh_repeat 2
advert_int 1
authentication {
auth_type PASS
auth_pass b76d77e
}
unicast_src_ip 172.16.1.3
unicast_peer {
172.16.1.7
}
virtual_ipaddress {
172.16.1.10
}
track_script {
check_script
}
}
new amphora 的配置文件和网络设置与 old amphora 一致,迁移成功。
Neutron-lbaas vs. LBaaS v2 API vs. Octavia vs. Octavia v2 API
在用户问过最多的问题中,LBaaS v2 API 与 Octavia v2 API 傻傻分不清当属排行第一位,这里简单对上述概念做一个标志性的区分。
- Neutron-lbaas:是 Neutron 的扩展项目,为早期提供 LBaaS 的实现。
- LBaaS v2 API:v2 版本的 LBaaS API 最早在 Neutron-lbaas 应用,实现了 loadbalancer、listener、pool 等资源对象。
- Octavia:OpenStack 的独立项目,最新的 LBaaS 推荐方案。
- Octavia v2 API:v2 版本的 Octavia API 是 LBaaS v2 API 的超级,所以能够兼容 Neutron-lbaas 的 octavia driver。
Octavia 的实现与分析(OpenStack Rocky)的更多相关文章
- 我非要捅穿这 Neutron(三)架构分析与代码实现篇(基于 OpenStack Rocky)
目录 文章目录 目录 Neutron 的软件架构分析与实现 Neutron Server 启动流程 获取 WSGI Application Core API & Extension API C ...
- octavia的实现与分析(一)·openstack负载均衡的现状与发展以及lvs,Nginx,Haproxy三种负载均衡机制的基本架构和对比
[负载均衡] 大量用户发起请求的情况下,服务器负载过高,导致部分请求无法被响应或者及时响应. 负载均衡根据一定的算法将请求分发到不同的后端,保证所有的请求都可以被正常的下发并返回. [主流实现-LVS ...
- openstack octavia的实现与分析(一)openstack负载均衡的现状与发展以及lvs,Nginx,Haproxy三种负载均衡机制的基本架构和对比
[负载均衡] 大量用户发起请求的情况下,服务器负载过高,导致部分请求无法被响应或者及时响应. 负载均衡根据一定的算法将请求分发到不同的后端,保证所有的请求都可以被正常的下发并返回. [主流实现-LVS ...
- CentOS7安装OpenStack(Rocky版)-01.控制节点的系统环境准备
分享一下Rocky版本的OpenStack安装管理经验: OpenStack每半年左右更新一版,目前是版本是201808月发布的版本-R版(Rocky),目前版本安装方法优化较好,不过依然是比较复杂 ...
- CentOS7安装OpenStack(Rocky版)-05.安装一个nova计算节点实例
上一篇文章分享了控制节点的nova计算服务的安装方法,在实际生产环境中,计算节点通常会安装一些单独的节点提供服务,本文分享单独的nova计算节点的安装方法 ---------------- 完美的分 ...
- openstack Rocky 社区版部署1.3 安装OpenStack packages
1 installing the Rocky release on all nodes. yum install centos-release-openstack-rocky 安装之后,会在/etc/ ...
- openstack octavia的实现与分析(二)原理,架构与基本流程
[了解] 其实说白了,Octavia就是将用户的API请求经过逻辑处理,转换成Haproxy或者Nginx的配置参数,下发到amphora虚机中. Octavia的内部实现中,逻辑流程的处理主要使用T ...
- Ubuntu 18.04.1 LTS + kolla-ansible 部署 openstack Rocky all-in-one 环境
1. kolla 项目介绍 简介 kolla 的使命是为 openstack 云平台提供生产级别的.开箱即用的自动化部署能力. kolla 要实现 openetack 部署分为两步,第一步是制作 do ...
- CentOS7安装OpenStack(Rocky版)-02.安装Keyston认证服务组件(控制节点)
本文分享openstack的认证服务组件keystone --------------- 完美的分割线 ---------------- 2.0.keystone认证服务 1)用户与认证:用户权限与用 ...
随机推荐
- 利用ios safari浏览器生成桌面快捷方式并唤醒app的示例代码
html 内容: //通过a链接唤醒app <a href="app约定好的scheme" id="qbt" style="display:n ...
- php打开csv
<?php $fh=fopen("a.csv","r");//这里我们只是读取数据,所以采用只读打开文件流 $arr=fgetcsv($fh);//这个函 ...
- 日语能力考试N2级必备外来语
日语能力考试N2级必备外来语 ア行外来语アンテナ:(antenna) 天线インタビュー :(interview) 采访,访谈ウイルス:(virus ) 病 ...
- 设备中LPC2368芯片个例参数问题导致故障的分析
最近公司的设备客户报告在终端客户那里出现了板卡加热不受控,出现了持续加热导致设备一些贵重部件损坏.由于历史上很多现场问题,板卡什么拆到别的地方搭复现平台,基本都是以失败告终,所以出差去现场分析. 过程 ...
- JQuery 时间戳转时间
JQuery 时间戳转时间 var date = new Date(stocks[i]['create_time'] * 1000); var y = date.getFullYear(); var ...
- Notepad++技巧
1 正则表达式的查找和替换,例如删除每行开始的数字ctrl+H, ^\d\d\d:null 2 删除所有的空行: TextFX插件->Edit->Delete Blank Lines 3 ...
- 集合综合练习<三>
package com.JiHeTotal; import java.util.Comparator; import java.util.Map; import java.util.Map.Entry ...
- C#调用Python(二)
python文件中有引入其他包.模块 一.源码 1.1 python源码,源码.python 打包方法,以及打包后的程序文件.请移步https://www.cnblogs.com/zhuanjiao ...
- chalk插件 使终端输出的字带颜色
1.使终端输出红色字体: const chalk = require('chalk'); console.log(chalk.red('this is red!') 这时运行终端,打印的this is ...
- Mysql5.7.26解压版(免安装版)简单快速配置步骤,5分钟搞定(win10-64位系统)
第一次安装mysql环境的时候,总会遇到各种各样的坑,在尝试了安装版和解压版的数据库之后,感觉mysql的解压版更加的简单方便,省去好多时间做专业的事情 我这里选择的是5.7.26版本,解压版下载地址 ...