Linear Regression and Gradient Descent (English version)
1.Problem and Loss Function
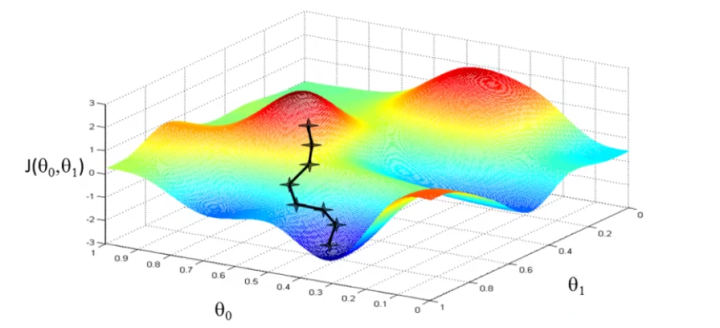
From the initial state, we probably have a really poor system (may be only output zero). By using X and Y to train, we try to derive a better parameter θ. The training process (learning process) may be time-consuming, because the algorithm updates parameters only a little on every training step.
2. Cost Function?
Suppose driving from somewhere to Toronto: it is easy to know the coordinates of Toronto, but it is more important to know where we are now! Cost function is the tool giving us how different between Hypothesis and label Y, so that we can drive to the target. For regression problem, we use MSE as the cost function.
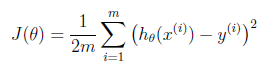
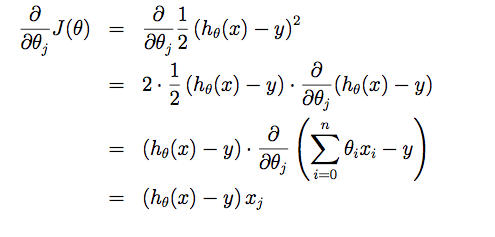

Linear Regression and Gradient Descent (English version)的更多相关文章
- Linear Regression Using Gradient Descent 代码实现
参考吴恩达<机器学习>, 进行 Octave, Python(Numpy), C++(Eigen) 的原理实现, 同时用 scikit-learn, TensorFlow, dlib 进行 ...
- 线性回归、梯度下降(Linear Regression、Gradient Descent)
转载请注明出自BYRans博客:http://www.cnblogs.com/BYRans/ 实例 首先举个例子,假设我们有一个二手房交易记录的数据集,已知房屋面积.卧室数量和房屋的交易价格,如下表: ...
- 斯坦福机器学习视频笔记 Week1 Linear Regression and Gradient Descent
最近开始学习Coursera上的斯坦福机器学习视频,我是刚刚接触机器学习,对此比较感兴趣:准备将我的学习笔记写下来, 作为我每天学习的签到吧,也希望和各位朋友交流学习. 这一系列的博客,我会不定期的更 ...
- 斯坦福机器学习视频笔记 Week1 线性回归和梯度下降 Linear Regression and Gradient Descent
最近开始学习Coursera上的斯坦福机器学习视频,我是刚刚接触机器学习,对此比较感兴趣:准备将我的学习笔记写下来, 作为我每天学习的签到吧,也希望和各位朋友交流学习. 这一系列的博客,我会不定期的更 ...
- Linear Regression and Gradient Descent
随着所学算法的增多,加之使用次数的增多,不时对之前所学的算法有新的理解.这篇博文是在2018年4月17日再次编辑,将之前的3篇博文合并为一篇. 1.Problem and Loss Function ...
- Logistic Regression and Gradient Descent
Logistic Regression and Gradient Descent Logistic regression is an excellent tool to know for classi ...
- Logistic Regression Using Gradient Descent -- Binary Classification 代码实现
1. 原理 Cost function Theta 2. Python # -*- coding:utf8 -*- import numpy as np import matplotlib.pyplo ...
- flink 批量梯度下降算法线性回归参数求解(Linear Regression with BGD(batch gradient descent) )
1.线性回归 假设线性函数如下: 假设我们有10个样本x1,y1),(x2,y2).....(x10,y10),求解目标就是根据多个样本求解theta0和theta1的最优值. 什么样的θ最好的呢?最 ...
- machine learning (7)---normal equation相对于gradient descent而言求解linear regression问题的另一种方式
Normal equation: 一种用来linear regression问题的求解Θ的方法,另一种可以是gradient descent 仅适用于linear regression问题的求解,对其 ...
随机推荐
- CSS的置换和非置换元素
一个来自面试的坑. 面试的时候考官先问了行内元素和块级元素的区别,这个不难理解.然后一脚就踩进了,置换元素的坑.例如img就是行内置换元素,这种行内元素是可以设置宽高的. 什么是置换元素 一个内容不受 ...
- 20、numpy——IO
NumPy IO Numpy 可以读写磁盘上的文本数据或二进制数据. NumPy 为 ndarray 对象引入了一个简单的文件格式:npy. npy 文件用于存储重建 ndarray 所需的数据.图形 ...
- ReplaceAll 特殊字符处理
用到Json与replaceAll Http拦截脚本中经常需要替换,replace虽然不需要处理特殊字符,但是不能匹配多个,ReplaceAll能够使用正则,不过需要处理的转移实在太多 比如,需要替换 ...
- SR-IOV
SR-IOV 来源 http://blog.csdn.net/liushen0916/article/details/52423507 摘要: 介绍SR-IOV 的概念.使用场景.VMware 和 K ...
- 实现combobox模糊查询的时候报错 InvalidArgument=“0”的值对于“index”无效
因为要对combobox实现模糊查询,因为系统实现的匹配只能从左到右进行匹配,所以利用两个list来进行模糊匹配,主要代码如下: List<string> listOnit = new L ...
- JS中的Number数据类型详解
Number数据类型 Number类型使用IEEE754格式来表示整数和浮点值,这也是0.2 + 0.3不等于0.5的原因, 最基本的数值类型字面量格式是十进制整数 var a = 10; 1. 浮点 ...
- ob_start()、ob_get_contents() 等使用方法
ob_start()ob_get_contents(); 获取缓冲区内容ob_end_clean():删除内部缓冲区的内容,并且关闭内部缓冲区 ob_end_flush() 发送内部缓冲区的内容到浏览 ...
- unity DOTween Pro的使用--简化流程--自动播放
当gameobject setActive(true)的时候自动播放动画 1) 添加DoTween Animation. 设置动画效果, 略 选中 AutoPlay, 取消 AutoKill 2) 在 ...
- 给公司个别安装好的系统环境处理-相当half系统初始化脚本shell
#!/bin/bash# Used for other system-environment update! echo -e '\n\033[35m~~请使用root权限运行此脚本~~\033[0m\ ...
- pip安装依赖包
pip install -r requirements.txt setup.py 模块使用 https://blog.csdn.net/neil_pan/article/details/7900129 ...