梯度下降(HGL)
线性回归:是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。
对于一般训练集:


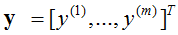
参数系统为:

线性模型为:

损失函数最小的目标就是求解全局最小值,loss函数定义为

目标:min Φ(θ),loss函数最小。估计最优系数(θ0, θ1, θ2, …, θn)。
1. 梯度下降法(最速下降法)
顾名思义,梯度下降法的计算过程就是沿梯度下降的方向求解极小值。
具体过程如下(如图1所示):
- 首先对θ赋值,这个值可以是随机的,也可以让θ是一个全零的向量(初值的选择非常影响梯度下降算法的好与坏)。
- 改变θ的值,使得Φ(θ)按梯度下降的方向进行减少。
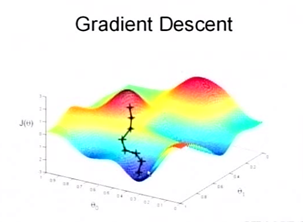
图1 梯度下降描述(来自于斯坦福大学,《机器学习》公开课[2])
过程2)可以表示为:

其中α为步长。
由于我们每进行一次参数更新需要计算整体训练数据的梯度,批量梯度下降会变得很慢,并且会遇到内存吃不下数据就挂了。同时批量梯度下降也无法支持模型的在线更新,例如,新的样本不停的到来。
2. SGD (随机梯度下降算法,Stochastic gradient descent)
在梯度下降中,对于θ的更新,所有的样本都有贡献,也就是参与调整θ,其计算得到的是一个标准梯度。如果数据量非常大,那么运算速度很慢。而随机梯度下降算法的随机也就是说我用样本中的一个例子来近似我所有的样本,来调整θ。这样速度更快,但是更容易陷入局部极小。随机梯度下降算法可以表示为:

每次只选用第i个样本
3. AdaGrad(自适应梯度,Adaptive Gradient)
自适应梯度与SGD类似,AdaGrad的更新速率是可变的。更新速率一定,不一定适合所有的更新阶段。所以AdaGrad调整的是Gradient,对于所有的参数,随着更新的总距离增多,学习速度随之变缓。可以表示为:

其中(θi)t是t步的参数,ε很小,保证非0。
缺点:学习率单调递减,训练后期学习率非常小;需要手动设置全局学习率;更新
θt时,左右两边单位不统一。
参考文献:Duchi, E. Hazan, and Y. Singer. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization
4. AdaDelta
AdaDelta基本思想是用一阶的方法,近似模拟二阶牛顿法,是对AdaGrad的缺点进行改进。可表示为:
 ?
?
5. RMSprop
RMSprop和Adadelta是在差不多的时间各自独立产生的工作,目的都是为了缓解Adagrad的学习速率减少的问题。实际上RMSprop和我们在Adadelta中推到的第一个更新向量是相同的:


其中,ρ建议取0.9,α建议取0.001。
6. NAG
这个算法严格的说来是凸优化中的算法,具有O(1/t^2)的收敛率,收敛速度比较快。因为 DNN是一个non-convex的model,所以NAG方法并不能达到这个收敛速度。caffe文档中指出,这个方法对于某些deeplearning 的 architecture是非常有效的。与SGD类似,具体更新过程如下:


7. Adam(个人认为一般都合适的caffe的solver方法)
Adaptive Moment Estimation(Adam) 也是一种不同参数自适应不同学习速率方法,与Adadelta与RMSprop区别在于,它计算历史梯度衰减方式不同,不使用历史平方衰减,其衰减方式类似动量,如下[4]:


Wt与Vt分别是梯度的带权平均和带权有偏方差,初始为0向量,Adam的作者发现他们倾向于0向量(接近于0向量),特别是在衰减因子(衰减率)ρ1,ρ2接近于1时。为了改进这个问题,对Wt与Vt进行偏差修正(bias-corrected):
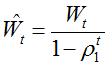

最终,Adam的更新方程为:

[1] http://www.cnblogs.com/denny402/
[2] http://open.163.com/movie/2008/1/M/C/M6SGF6VB4_M6SGHFBMC.html
[3] http://blog.sina.com.cn/s/blog_eb3aea990102v41r.html
[4] http://blog.csdn.net/heyongluoyao8/article/details/52478715?locationNum=7
梯度下降(HGL)的更多相关文章
- 梯度下降(Gradient Descent)小结
在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法.这里就对梯度下降法做一个完整的总结. 1. 梯度 在微 ...
- 从梯度下降到Fista
前言: FISTA(A fast iterative shrinkage-thresholding algorithm)是一种快速的迭代阈值收缩算法(ISTA).FISTA和ISTA都是基于梯度下降的 ...
- 线性回归、梯度下降(Linear Regression、Gradient Descent)
转载请注明出自BYRans博客:http://www.cnblogs.com/BYRans/ 实例 首先举个例子,假设我们有一个二手房交易记录的数据集,已知房屋面积.卧室数量和房屋的交易价格,如下表: ...
- 随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )的公式对比、实现对比[转]
梯度下降(GD)是最小化风险函数.损失函数的一种常用方法,随机梯度下降和批量梯度下降是两种迭代求解思路,下面从公式和实现的角度对两者进行分析,如有哪个方面写的不对,希望网友纠正. 下面的h(x)是要拟 ...
- 为什么是梯度下降?SGD
在机器学习算法中,为了优化损失函数loss function ,我们往往采用梯度下降算法来进行优化.举个例子: 线性SVM的得分函数和损失函数分别为: ...
- Stanford大学机器学习公开课(二):监督学习应用与梯度下降
本课内容: 1.线性回归 2.梯度下降 3.正规方程组 监督学习:告诉算法每个样本的正确答案,学习后的算法对新的输入也能输入正确的答案 1.线性回归 问题引入:假设有一房屋销售的数据如下: 引 ...
- Matlab梯度下降解决评分矩阵分解
for iter = 1:num_iters %梯度下降 用户向量 for i = 1:m %返回有0有1 是逻辑值 ratedIndex1 = R_training(i,:)~=0 ; %U(i,: ...
- 机器学习(一):梯度下降、神经网络、BP神经网络
这几天围绕论文A Neural Probability Language Model 看了一些周边资料,如神经网络.梯度下降算法,然后顺便又延伸温习了一下线性代数.概率论以及求导.总的来说,学到不少知 ...
- 梯度下降之随机梯度下降 -minibatch 与并行化方法
问题的引入: 考虑一个典型的有监督机器学习问题,给定m个训练样本S={x(i),y(i)},通过经验风险最小化来得到一组权值w,则现在对于整个训练集待优化目标函数为: 其中为单个训练样本(x(i),y ...
随机推荐
- Ace向你推荐一些实用的干货库~开发安卓的好帮手
1 毁灭地球的军火库arsenal- 你想要的枪这里都有卖 哈哈哈哈 , http://android-arsenal.com/ 2 黑科技---在线反编译----嘿嘿嘿 在线反编译 方便简单 客官 ...
- Beam编程系列之Python SDK Quickstart(官网的推荐步骤)
不多说,直接上干货! https://beam.apache.org/get-started/quickstart-py/ Beam编程系列之Java SDK Quickstart(官网的推荐步骤)
- javascript遍历表
定义表结构 1. 通过id遍历 <html> <body> <table id="tb" border="1"> <t ...
- vim代码折叠命令
1. 折叠方式 可用选项 'foldmethod' 来设定折叠方式:set fdm=*****. 有 6 种方法来选定折叠: manual 手工定义折叠 ind ...
- Java入门系列-06-运算符
这篇文章为你搞懂2个问题 java 中的常用运算符有哪些?如何使用? 这些运算符的运算优先级是怎样的? 算数运算符 明显是做数学运算的,包括以下符号: + 加法运算 敲一敲: public class ...
- spring-boot 1.4.x遇到的cpu高的问题
如果你的spring-boot应用里tomcat线程耗cpu较高,并主要耗在做读取jar的操作上(堆栈类似下面),可能跟我们遇到同样的问题. CRC32.update(byte[], int, int ...
- frp使用总结
笔者所知并成功实现内网穿透的方法: 花生壳 (需要花8块钱,使用花生壳给的二级域名,这里不做介绍) ngrok (免费,但是每次重启服务二级域名会变,付费的$5每月不会变) frp(开源免费,需要有自 ...
- JavaScript各类型变量和对象
一.javascript支持的数据类型: var x=1 数字 var x=0.1 小数 var x=true/false bool var x="abc" 字符串 ...
- 《本博客将搬至CSDN》 博客主QQ 654436731 有关于本博客任何文章的问题欢迎打扰
地址 http://blog.csdn.net/sajiazaici
- CSS如何设置换行文字自动对齐
CSS如何设置换行文字自动对齐 如图所示: 代码实现如下: <ul class='warn-page-content'> <li> ...