hadoop学习第二天-了解HDFS的基本概念&&分布式集群的搭建&&HDFS基本命令的使用
一、HDFS的相关基本概念
1.数据块
1、在HDFS中,文件诶切分成固定大小的数据块,默认大小为64MB(hadoop2.x以后是128M),也可以自己配置。
2、为何数据块如此大,因为数据传输时间超过寻到时间(高吞吐率)。
3、文件的存储方式,按大小被切分成若干个block,存储在不同的节点上,默认情况下每个block有三个副本。
2.复制因子
就是一个block分为多少个副本,默认情况下是3个
3.fsimage文件作用:
fsimage是元数据镜像文件(保存文件系统的目录树)。
4.edits文件作用
fsedits 是元数据操作日志(记录每次保存fsimage之后到下次保存之间的所有hdfs操作)。
5.安全模式
当开启安全模式后,对文件的修改和删除都会有错误提示
enter 进入安全模式
leave 离开安全模式
get 返回安全模式是否开启的信息
6.NameNode
(HA集群启动时,可以同时启动2个NameNode。这些NameNode只有一个是active的,另一个属于standby状态)
作用是一个文件系统树,文件树中的文件和文件夹中的元数据。
namenode负责管理文件目录,文件和block的对应关系以及block和datanode的对应关系。
由两部分组成:
1.fsimage;
2.fsedits:
7.DataNode
作为NameNode的工作节点,根据客户端或者NameNode的调度存储和检索数据,
当客户端请求读或写时,NameNode会告知客户端去哪些DataNode进行读写,
然后客户端直接与相应的DataNode进行通信
8.SecondaryNameNode
由于Edit log不断增长,在NameNode重启时,会造成长时间NameNode处于安全模式,不可用状态,是非常不符合Hadoop的设计初衷。
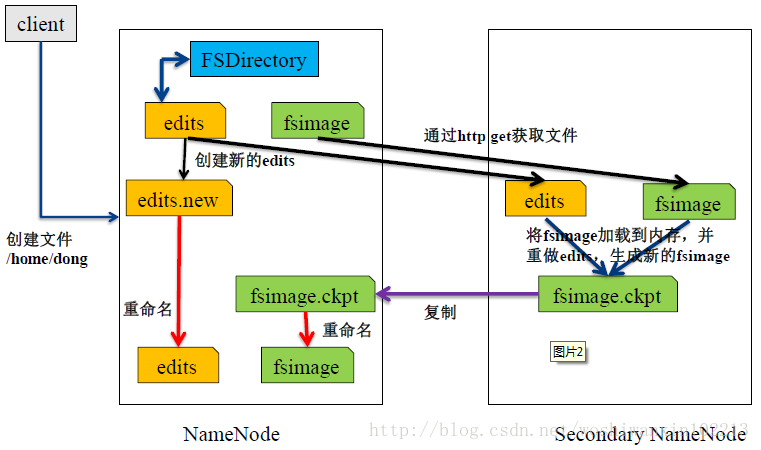
所以要周期性合并Edit log,但是这个工作由NameNode来完成,会占用大量资源,这样就出现了Secondary NameNode,它可以进行image检查点的处理工作。步骤如下:
(1)Secondary NameNode请求NameNode进行edit log的滚动(即创建一个新的edit log),将新的编辑操作记录到新生成的edit log文件;
(2)通过http get方式,读取NameNode上的fsimage和edits文件,到Secondary NameNode上;
(3)读取fsimage到内存中,即加载fsimage到内存,然后执行edits中所有操作(类似OracleDG,应用redo log),并生成一个新的fsimage文件,即这个检查点被创建;
(4)通过http post方式,将新的fsimage文件传送到NameNode;
(5)NameNode使用新的fsimage替换原来的fsimage文件,让(1)创建的edits替代原来的edits文件;并且更新fsimage文件的检查点时间。
关系图如下:
二、分布式集群的搭建
1.环境说明
在学习一中,已经配置好了伪分布式集群,即一个节点的集群测试。要搭的是在此基础上搭建的三个节点的集群
即master作为NameNode节点,slaver1 slaver2 作为DataNode节点
2.分布式集群搭建
1.创建三个虚拟机(通过vmware的克隆功能,直接克隆之前创建的qjx主机,然后修改主机名和IP地址,根据自己内存大小分配虚拟机内存)主机名和IP分别为
| master | 192.168.32.10 |
| slaver1 | 192.168.32.11 |
| slaver2 | 192.168.32.12 |
2.三个主机都关闭防火墙(root)
/etc/init.d/iptables stop
3.修改hosts文件,将IP和主机名添加到最后一行
vim /etc/hosts
192.168.32.10 master
192.168.32.11 slaver1
192.168.32.12 slaver2
4.添加三个主机的互信操作
ssh-keygen
ssh-copyid master
ssh-copyid slaver1
ssh-copyid slaver2
5.修改配置文件 hadoop-2.6.0/etc/hadoop/slaves.xml 添加子节点的主机名
vim hadoop-2.6.0/etc/hadoop/slavers
slaver1
slaver2
6.修改配置文件 hadoop-2.6.0/etc/hadoop/core-site.xml(tmp.dir配置中,目录可以根据自己主机更改)
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/qjx/hadoop/hadoop-2.6.0/dataSoft/tmp</value>
<description>Abasefor other temporary directories.</description>
</property>
7.修改配置文件 hadoop-2.6.0/etc/hadoop/hdfs-site.xml(目录配置为自己新建的一个临时目录,为了存储每次进入的临时文件,若没有指定,即为/tmp/下,每次进入主机都要改变)
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/qjx/dataSoft/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/qjx/dataSoft/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
8.修改配置文件 hadoop-2.6.0/etc/hadoop/mapred-site.xml(本来不存在,由hadoop-2.6.0/etc/hadoop/mapred-site.xml.temp文件复制来)
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
9.修改配置文件 hadoop-2.6.0/etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
10.将配置好的master的配置文件拷贝到slaver1,slaver2的配置文件中
scp -r hadoop-2.6.0/ etc/hadoop/*@slave1:~/hadoop/hadoop-2.6.0/etc/hadoop/
scp -r hadoop-2.6.0/ etc/hadoop/*@slave2:~/hadoop/hadoop-2.6.0/etc/hadoop/
11.格式化HDFS,在hadoop-2.6.0目录下执行
bin/hdfs namenode -format
注意:格式化只能操作一次,如果因为某种原因,集群不能用, 需要再次格式化,需要把上一次格式化的信息删除,在三个节点用户根目录里执行 rm -rf /home/qjx/hadoop/hadoop-2.6.0/dfs/*
12.在master节点执行sbin/start-all.sh 输入jps后,master节点显示4条,slaver1,slaver2节点各显示3条为配置正确
三、HDFS基本命令的使用
HDFS文件系统与Linux文件系统类似,都是从/根目录开始
1.上传
bin/hadoop fs -put 本地文件 hdfs文件路径
示例:bin/hadoop fs -put ~/put/test.txt /
2.下载
bin/hadoop fs -get hdfs文件 本地文件路径
示例:bin/hadoop fs -get /test ~/get/
3.查看文件列表
bin/hadoop fs -ls 文件路径
示例:bin/hadoop fs -ls /
4.查看文件内容
bin/hadoop fs -cat hdfs文件
示例:bin/hadoop fs -cat /test.txt
5.创建目录
创建一级目录
bin/hadoop fs -mkdir /aaa
创建多级目录
bin/hadoop fs -mkdir -p /a/b/c/
6.删除目录
bin/hadoop fs -rmdir /aaa
7.删除文件
删除文件
bin/hadoop fs -rm /test.txt
删除目录(非空)
bin/hadoop fs -rm -r /a//b/c
hadoop学习第二天-了解HDFS的基本概念&&分布式集群的搭建&&HDFS基本命令的使用的更多相关文章
- hadoop学习笔记(五)hadoop伪分布式集群的搭建
本文原创,如需转载,请注明作者和原文链接 1.集群搭建的前期准备 见 搭建分布式hadoop环境的前期准备---需要检查的几个点 2.解压tar.gz包 [root@node01 ~]# ...
- 『实践』VirtualBox 5.1.18+Centos 6.8+hadoop 2.7.3搭建hadoop完全分布式集群及基于HDFS的网盘实现
『实践』VirtualBox 5.1.18+Centos 6.8+hadoop 2.7.3搭建hadoop完全分布式集群及基于HDFS的网盘实现 1.基本设定和软件版本 主机名 ip 对应角色 mas ...
- Hadoop完全分布式集群环境搭建
1. 在Apache官网下载Hadoop 下载地址:http://hadoop.apache.org/releases.html 选择对应版本的二进制文件进行下载 2.解压配置 以hadoop-2.6 ...
- hadoop完全分布式集群的搭建
集群配置: jdk1.8.0_161 hadoop-2.6.1 linux系统环境:Centos6.5 创建普通用户 dummy 准备三台虚拟机master,slave01,slave02 hado ...
- Hadoop学习(一):完全分布式集群环境搭建
1. 设置免密登录 (1) 新建普通用户hadoop:useradd hadoop(2) 在主节点master上生成密钥对,执行命令ssh-keygen -t rsa便会在home文件夹下生成 .ss ...
- Hadoop伪分布式集群环境搭建
本教程讲述在单机环境下搭建Hadoop伪分布式集群环境,帮助初学者方便学习Hadoop相关知识. 首先安装Hadoop之前需要准备安装环境. 安装Centos6.5(64位).(操作系统再次不做过多描 ...
- hadoop分布式集群的搭建
电脑如果是8G内存或者以下建议搭建3节点集群,如果是搭建5节点集群就要增加内存条了.当然实际开发中不会用虚拟机做,一些小公司刚刚起步的时候会采用云服务,因为开始数据量不大. 但随着数据量的增大才会考虑 ...
- hadoop伪分布式集群的搭建
集群配置: jdk1.8.0_161 hadoop-2.6.1 linux系统环境:Centos6.5 创建普通用户 dummy 设置静态IP地址 Hadoop伪分布式集群搭建: 为普通用户添加su ...
- 阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建
准备: 两台配置CentOS 7.3的阿里云ECS服务器: hadoop-2.7.3.tar.gz安装包: jdk-8u77-linux-x64.tar.gz安装包: hostname及IP的配置: ...
随机推荐
- 浅谈C语言中断处理机制
一.中断机制 1.实现中断响应和中断返回 当CPU收到中断请求后,能根据具体情况决定是否响应中断,如果CPU没有更急.更重要的工作,则在执行完当前指令后响应这一中断请求.CPU中断响应过程如下:首先, ...
- ubuntu16安装docker
首先确保curl已经安装! 然后执行: curl -sSL https://get.docker.com/|sudo sh 这个是通过脚本的方式安装docker. 运行命令测试 sudo docker ...
- python基础-初识Python和不同语言之间的区别
一.Python的创始人谁? Python之父:吉多·范罗苏姆GuidovanRossum 吉多·范罗苏姆是一名荷兰计算机程序员,他作为Python程序设计语言的作者而为人们熟知.在Python社区, ...
- 华为终端-新浪微博联合创新,3D建模+AR 成就全新社交体验
近日,全球首款搭载3D感知摄像头的手机华为Mate 20发布. 通过Mate 20自带的景深摄像头及麒麟980的NPU加速能力,手机能够在获取物体表面信息后,完成高速的精细化3D建模. 那么,如何让3 ...
- 【Mac + Appium + Python3.6学习(三)】之IOS自动化测试环境配置
在做这一节之前先配置我的另一篇文章所需要安装的前提准备条件:<[Mac + Appium学习(一)]之安装Appium环境前提准备> 一.安装IOS自动化测试环境 配置环境: Appium ...
- python django -3 视图
视图 视图接受Web请求并且返回Web响应 视图就是一个python函数,被定义在views.py中 响应可以是一张网页的HTML内容,一个重定向,一个404错误等等 响应处理过程如下图: URLco ...
- python升级后pip 不可用 卸载pip
python版本由2.6升级到2.7之后,用pip提示报错 找了一下原因,网上的版本很多.弄来弄去比较麻烦 来点简单粗暴的 1.卸载pip yum remove python-pip 2.下载 cur ...
- hdu 4421(枚举+2-sat)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=4421 思路:枚举32位bit,然后2-sat判断可行性,这里给出2-sat矛盾关系构图: 1.a&am ...
- Linux学习目录
一.CentOS for Linux 大神博客:骏马金龙 Linux也可以参考,这篇博客进行学习 http://www.cnblogs.com/f-ck-need-u/p/7048359.html ...
- Nginx模块系列之auth_basic模块
1.1 介绍 ngx_http_auth_basic_module模块实现让访问着,只有输入正确的用户密码才允许访问web内容.web上的一些内容不想被其他人知道,但是又想让部分人看到.nginx的h ...