寄存器,cache、伙伴系统、内存碎片、段式页式存储管理
cache、伙伴系统、内存碎片、段式页式存储管理
目录
正文
存储管理是操作系统非常重要的功能之一,本文主要介绍操作系统存储管理的基础知识,包括缓存相关知识、连续内存分配、伙伴系统、非连续内存分配、内存碎片等,并结合linux系统对这些知识进行简单的验证。文章内容来自笔者学习清华大学和UCSD的操作系统课程的笔记和总结,以及自己的思考和实践。
分层的存储管理:
CPU(Central Processing Unit)是计算机的核心,其主要工作是解释计算机指令、处理数据。那么这些指令和数据来自哪里呢?和TCP/IP的分层设计思想一样,数据的存储管理也分为以下四层:
- 寄存器
- cache
- 内存
- 外存(外设)
四层中,越上层的速度越快,同时造价也更为昂贵,自然空间也更小。寄存器通常只有几十之多几百个字节,主要用来存放固定的指针或者计算的中间结果。cache是一个比较通用的术语,在计算机体系机构中,称之为高速缓冲存储器,直接由硬件来管理,不同的CPU有不同级别的cache内存由操作系统来管理。内存(一般又称为主存)在cache失效的时候访问,速度要比cache慢至少一个数量级,内存管理是操作系统中最复杂的功能之一。外存又称之为虚拟内存,是将外设的一部分空间用来存储未能加载到内存中的数据,当内存缺页(页的概念后面会介绍)的时候就会用到外存,外存的速度与内存比起来与天壤之别,慢个几十万倍都是可能的。
cache:
在计算机系统中,CPU的运行速度与主存(即我们平常所说的内存)的访问速度极不匹配,导致CPU的利用率比较低。为了提高CPU利用率,现代计算机体系结构中广泛采用高速缓冲存储器(Cache)技术。
cache也分为好多级,比如一级缓存(L1 cache)、二级缓存(L2 cache),基本上的CPU都至少有L1 cache与L2 cache,目前稍微好一点的CPU也会有L3 cache,对于性能更好的CPU还会有L4 cache。L1 cache、L2 cache一般都只有几十K个字节,存储指令或者数据,L3cache可以有几百个字节或者几M,L4 cache可以有几十、几百M。同样的,空间大小与速度、价格相关。
局部性原理:
我们看到,cache的容量(特别是效率最高的L1 cache、L2 cache)都非常小,那怎么保证有比较高的命中率呢,如果命中率比较低,每次还得去内存取数据,还要置换cache中的数据,反而得不偿失。幸好,程序的局部性原理保证了cache能有比较高的命中率。什么是局部性原理:程序一般以模块的形式组织,某一模块的程序,往往集中在存储器逻辑地址空间中很小的一块范围内,且程序地址分布是连续的。也就是说,CPU在一段较短的时间内,是对连续地址的一段很小的主存空间频繁地进行访问,而对此范围以外地址的访问甚少,这种现象称为程序访问的局部性(principle of locality)。具体来说,包括:
时间局部性(Temporal locality):最近被访问的数据在很短的时间内还会被访问;
空间局部性(Spatial locality):当前正在被访问的内存的临近的内存区域很快也会被访问。
置换算法:
有了程序的局部性原理,就能保证当一篇内存区域加载到cache中后,能被多次命中。但由于cache的容量小,所以总有命中失败的情况,当没有命中,那么就需要去内存把一段内存区域(以块为单位,一个块包括若干个字节)加载到cache,那么如果此时cache已经满了,那么需要将一些块交换出去,如何选择被置换的块被称为替换算法,包括:
1. 最不经常使用(LFU)算法
LFU(Least Frequently Used,最不经常使用)算法将一段时间内被访问次数最少的那个块替换出去。每块设置一个计数器,从0开始计数,每访问一次,被访块的计数器就增1。当需要替换时,将计数值最小的块换出,同时将所有块的计数器都清零。
这种算法将计数周期限定在对这些特定块两次替换之间的间隔时间内,不能严格反映近期访问情况,新调入的块很容易被替换出去。
2. 近期最少使用(LRU)算法
LRU(Least Recently Used,近期最少使用)算法是把CPU近期最少使用的块替换出去。这种替换方法需要随时记录Cache中各块的使用情况,以便确定哪个块是近期最少使用的块。每块也设置一个计数器,Cache每命中一次,命中块计数器清零,其他各块计数器增1。当需要替换时,将计数值最大的块换出。
LRU算法相对合理,但实现起来比较复杂,系统开销较大。这种算法保护了刚调入Cache的新数据块,具有较高的命中率。LRU算法不能肯定调出去的块近期不会再被使用,所以这种替换算法不能算作最合理、最优秀的算法。但是研究表明,采用这种算法可使Cache的命中率达到90%左右。
3. 随机替换
最简单的替换算法是随机替换。随机替换算法完全不管Cache的情况,简单地根据一个随机数选择一块替换出去。随机替换算法在硬件上容易实现,且速度也比前两种算法快。缺点则是降低了命中率和Cache工作效率。
LRU是非常聪明且适用的思想,在写代码的过程中,也经常会用到缓存,自然也会用到LRU
写回策略:
被加载到cache中的数据,除了被读取,也可能被修改,那么怎么保持cache中的数据与内存中的数据同步,这称之为写回策略:
1、写回法(Write-Back)
当CPU写Cache命中时,只修改Cache的内容,而不是立即写入主存;只有当此块被换出时才写回主存。
使用这种方法写Cache和写主存异步进行,显著减少了访问主存的次数,但是存在数据不一致的隐患。实现这种方法时,每个Cache块必须配置一个修改位,以反映此块是否被CPU修改过。
2、全写法(Write-Through)
当写 Cache命中时,Cache与主存同时发生写修改。
使用这种方法写Cache和写主存同步进行,因而较好地维护了Cache与主存的内容一致性。实现这种方法时,Cache中的每个块无需设置修改位以及相应的判断逻辑,但由于Cache对CPU向主存的写操作没有高速缓冲功能,从而降低了Cache的功效。
3、写一次法(Write-Once)
写一次法是基于写回法并结合全写法的写操作策略,写命中与写未命中的处理方法与写回法基本相同,只是第一次写命中时要同时写入主存,以便于维护系统全部Cache的一致性。
当代计算机,一般都有多个CPU,多个CPU可能各自有独立的cache,也可能共享一部分cache,这使得cache的管理(置换和写回)更加复杂。特别对于写回,怎么保证各个独立cache中的数据一致,计算机体系机构中,用MESI_protocol来解决这个问题,具体可以参加infoq上的《缓存一致性(Cache Coherency)入门》
linux环境下的cache
在linux(debian8)环境下,CPU的信息在/proc/cpuinfo文件里面,我们平常说的多少核CPU其实都是指逻辑CPU,在/proc/cpuinfo里面"processor"的数量就是逻辑CPU数量。逻辑CPU的数目实际上等于 物理CPU数目 * 单个物理CPU的核数 * 2(如果是intel的CPU并且启用了ht,hyper-threading, 超线程技术)。通过以下指令可以查看详细信息
- grep "processor" /proc/cpuinfo |wc -l 查看逻辑CPU数目
- grep "physical id" /proc/cpuinfo |sort |uniq |wc -l 查看物理CPU数目
- grep "cores" /proc/cpuinfo|uniq 查看单个物理CPU的CPU cores数目
- grep "flags" /proc/cpuinfo | grep ht |uniq 查看是否开启了ht
实测如下:

在/sys/devices/system/cpu 目录下面,有每一个逻辑CPU的信息,每一个逻辑CPU都对应一个CPU*文件夹, for example:

在cpu*文件有一个cache文件,事实上就是该CPU的缓存信息,随便选择一个逻辑CPU查看:

可以看到,在笔者的机器上有四级cache,每一级缓存目录下包含的文件可能是不同的,但至少都包含以下文件:
coherency_line_size
level
number_of_sets
physical_line_partition
shared_cpu_list
shared_cpu_map
size
type
ways_of_associativity
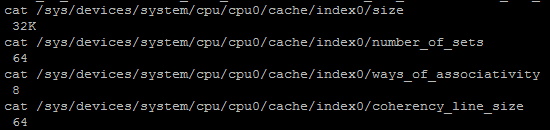
《Linux查看cache信息》这篇文章介绍了每个文件的意义。其中size是缓存的大小;type是缓存的类型(存数据、存指令、未指定);shared_cpu_list和shared_cpu_map是该cache在各个逻辑CPU之间的共享信息;coherency_line_size是每一个cache line包含多少自己,cache line是缓存与内存交换数据的最小单位,coherency_line_size = size / coherency_line_size / ways_of_associativity, 为什么这样设计,《关于CPU Cache -- 程序员需要知道的那些事》这篇文章有详细的介绍。
本机上每一级索引的类型

以第1级索引(index0)为例,查看coherency_line_size、 size、 coherency_line_size、 ways_of_associativity的关系:
连续内存分配与内存碎片
连续内存分配是指给进程分配一块不小于指定大小的物理地址连续的内存区域,不同进程可能需求的内存块大小是不一样的,但需要是连续的。对于这一需求,有不同的分配算法,但不管什么分配算法,操作系统都需要至少维护两部分信息:每个进程已经占用的分区、空闲的分区。
内部碎片与外部碎片:
内存碎片(fragmentation)是指操作系统在内存分配过程中,遗留下来的不能被利用到的内存区域。内存碎片导致部分内存被浪费,大量的内存碎片也会影响到系统的性能。
内部碎片(internal fragmentation),在连续内存分配策略中,操作系统按需分配一块连续的内存给应用程序。一般来说,实际上给到应用程序的会略大于需求,主要是为了计算的方便,比如应用程序需要23bytes,但事实上可能分配32bytes。这样多余的部分就成为了内部碎片。在连续内存分配策略中,内部碎片是很难避免的。但是如果使用非连续内存分配策略就能一定程度避免这个问题。
外部碎片(external fragmentation),开始的时候,可用的内存是一大块,但持续的分配释放过程中,就会形成一部分互相隔离的空闲区域,但这个部分区域尺寸较小,难以满足应用程序的需求,这就导致了外部碎片。 不同的策略,可能产生的外部碎片严重情况不一样。外部碎片的情况可以用下面这个公式衡量:
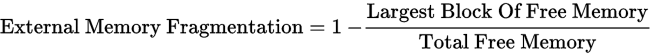
如果fragmentation为0%,那么表示所有的可用内存在一个空闲分区内。这个值越大,表明最大的空闲分区越小,空闲分区越零散。
动态分区分配策略
不同的连续内存分配策略,使用不同的数据结构,因此分配时的开销和释放时查找可合并区域并插入和合并后区域的开销是不同的,最常见的三种策略分别是:
- 最先匹配(first fit)
- 最佳匹配(best fit)
- 最差匹配(worst fit)
下面结合一个实例来形象观察三种策略的区别,假设现在需要400个字节的分区,目前内存中空闲分区如下图(黄色为空闲区域)

对于最先匹配,只需要找到第一个满足条件的空闲块就行了,于是在这里找到的就是“1K bytes”这个区域。在这种策略下,空闲分区按照地址排序就行了,在释放分区时,只需要检查相邻的分区是否可以合并就行了。优点是简单,缺点是有外部碎片,并且需要大块分区时可能比较慢(需要向后遍历)
对于最佳匹配,需要找到一个刚好比需要的分区稍微大一点的空闲分区,在这个环境中找到的就是“500 bytes”这个区域。在这种策略下,按照空闲分区的大小排序,能够迅速的找到可行的分配。但是在释放分区,合并的时候需要遍历找到临近的分区,判断是否合并。优点在于如果大部分需求的分区较小,这种策略能避免大块空闲区域去被拆分,而且能极大程度减小外部碎片的大小。缺点在于释放的时候速度较慢,而且可能存在大量较小的外部碎片。
对于最差匹配,直接选择最大的分区,在这个环境中找到的就是“2K bytes”这个区域。在这种策略下,按照空闲分区的大小逆序排序,能够O(1)时间复杂度找到可行的分配。但是在释放分区,合并的时候需要遍历找到临近的分区,判断是否合并。优点在于分配速度快,也能避免大量的小碎片。缺点在于释放时速度慢,而且因为每次都分配最大的空闲分区,在后期可能满意满足较大分区的需求。
伙伴系统(buddy system)
伙伴系统是非常出名的连续内存分配算法,Linux系统就是实用伙伴系统来做内核里的存储分配,很多语言或者内存数据库在做缓存的时候也会使用伙伴系统分配空间。
伙伴分配算法将可分配区间划分为2的N次方,初始的时候只有一个大小为2的M次方的最大空闲快。分配的时候,由小到大在空闲块数组(或者链表)中找最小的可用空闲块,如果空闲块过大(超过需求的两倍),则对空闲块进行二等分,直到得到合适的可用空闲块,由于伙伴系统一定是找到属于最合适的空闲块,那么属于上面提到的“最佳匹配策略”。释放的时候讲块放入空闲块数组(或者链表),然后合并满足合并条件的空闲块。
wiki上Buddy_memory_allocation的提到,在伙伴分配算法中,最小的块(即最基本的分配单元)不能太小,不然单纯为了记录哪一部分内存被使用或者空闲就先带来大量的内存和计算开销。但如果基本分配单元太大,会导致大量的内部碎片。因此理想的基本单元需要足够小,以避免内部碎片,同时要足够大,降低额外开销。
从上面的描述,伙伴系统比较适合用二叉树来实现,coolshell上的《伙伴分配器的一个极简实现》这篇文章给出了一个实现,值得借鉴。
伙伴系统的优点在于原理比较简单,而且外部碎片比较少,合并空闲分区开销也比较小。但缺点也很明显,内部碎片比较严重,比如最小单位为64K,如果需要65k的空间,那么不得不分配一块128K的空间,浪费了接近实际所需的一倍空间。因此在实际的应用中,会对伙伴系统进行一些修改和优化,以便减少内部碎片,提高利内存用率,比如Slab_allocation。
下面是wiki上的一个例子,最小的基本单元为64K,最大可分配空间为1M(64K* 16),本文只简单描述几个步骤,如果需要每一步都细看,那么可以参考wiki或者这篇文章,里面有中文翻译。
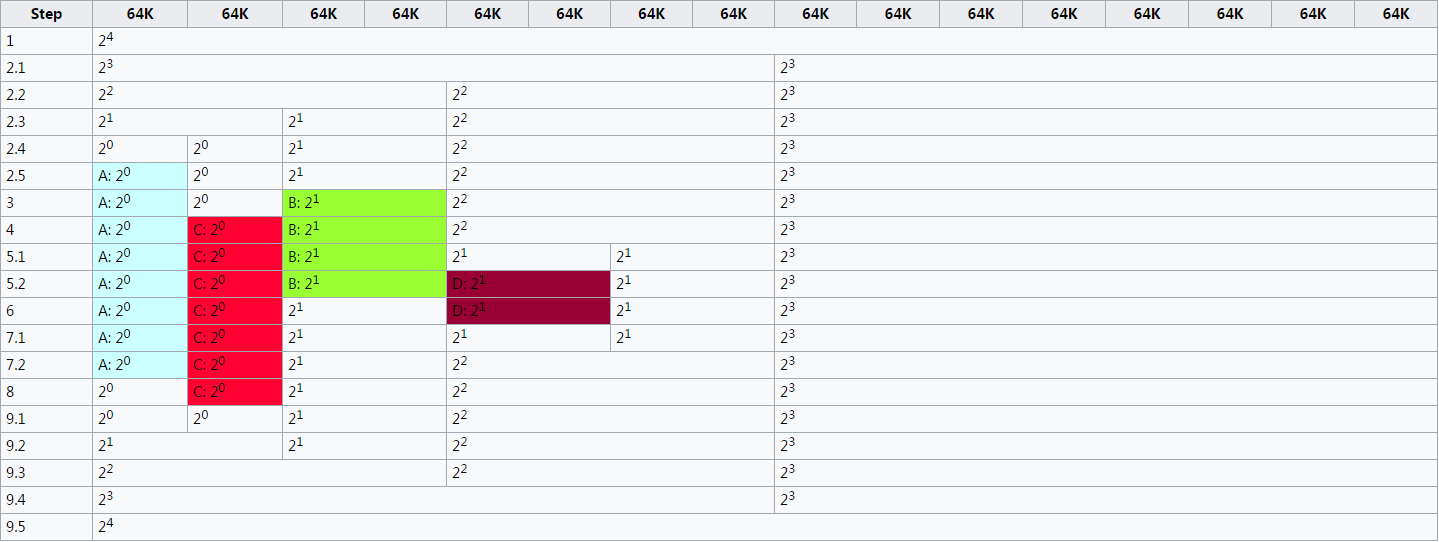
step1:这个是初始状态,所有空闲内存就只有一个1M的分区
step2:请求A需要分配一个34K的连续内存区域,满足条件的应该是一个64K的分区,但是现在只有一个1M的分区,所以连续4次二分,切出了一个64K区域(上图中浅蓝色部分),分配给请求A。
这一步分配之后,造成的内存碎片是64k - 34k = 30k。当前可分配的分区分别是:1个64K, 1个128K,1个256K,1个512K
step3:请求B需要一个66K的连续内存区域,满足条件的应该是一个128K的分区,事实上也是有的(上图中绿色部分),不过导致的内存碎片为128K - 66K = 62K
step4:请求C需要35K,目前有一个空闲的64K(上图中红色部分),直接分配。当前可分配的分区分别是:1个256K,1个512K
step5:请求D需要67K,但目前没有一个128K的空闲分区,于是将256K的二分,给一个128K给请求D(上图中暗红色部分)。当前可分配的分区分别是:1个128K,1个512K
step6:应用程序释放请求B占用的内存区域,虽然当前有两块128K的空闲分区,但由于地址不相邻,没法合并
step7:应用程序释放请求D占用的内存区域,这个时候D占用的空闲分区就可以和其右边的分区合并。
step8:应用程序释放请求A占用的内存区域,没有可合并的分区
step9:应用程序释放请求B占用的内存区域,递归合并,最终合成一块1M的分区。
非连续内存分配:
在上一章,详细介绍了连续内存分配的相关知识,可以看到连续内存分配虽然比较简单,但是也存在诸多的问题,比如内部碎片与外部碎片的问题,难以满足内存大小的动态修改需求,而且因为内存碎片的问题,导致内存利用率比较低。在本章介绍非连续内存分配策略,包括段式、页式、段页式。
顾名思义,非连续内存分配允许一个程序使用非连续的物理地址空间,即一个程序的逻辑地址空间被映射到物理地址空间不同的块(block),每一个块内部是连续的,但块与块之间可以不连续。其核心目标是提高内存利用率和管理灵活性,并允许代码和数据的共享。
当然,不连续也会引入相应的问题,需要有对应的解决方案或者折中权衡。首先是逻辑地址与物理地址的转换,对于连续内存分配,只需要起始地址和偏移就行了,对于非连续,需要记录逻辑地址与所有块的映射关系。其次,分块的粒度影响着逻辑地址与物理地址的转换,操作系统中常用两种粒度:段式(segmentation)与页式(paging) ,前者是粗粒度,使用段表做地址转换,后者是细粒度,用页表做地址转换。
段式
一个段表示的是访问方式和存储数据等属性相同的一部分地址空间,对应的是一个连续的内存“块”,若干个段组成进程的逻辑地址空间,比如堆、栈、数据、代码段。在段式策略中,逻辑地址由二元组(s, addr)组成,其中s为段号,addr为段内偏移。下面这个图形象描述了段式访问流程:
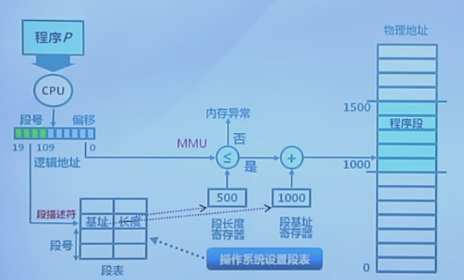
操作系统为应用程序设置段表,段表维护了每一个段的基址和长度,用段号(本质就是段表的索引)就能查找到对应的段基址和长度。内存访问顺序如下:CPU计算的时候取出逻辑地址(段号, 偏移);用段号去查找出对应的段基址和段长度;判断逻辑地址的偏移和段长度的大小关系,如果偏移大于段长度,那么直接报内存异常;通过段基址加上逻辑地址便宜,就找到了物理内存的实际地址。
页式
页式是比段式更细粒度的策略,对于页式存储管理,首先需要了解两个概念:页帧(Frame)、页面(Page)
页帧又称为物理页面,是指把物理空间划分为大小相同的基本分配单元, 基本单元的大小为2的N次方。因此内存物理地址可以由二元祖(f, o)表示,其中f为帧号, o为帧内偏移,假设每一帧的大小为2的S次方,那么物理地址 = f *2 S + o.
页面又称为逻辑页面,是指把逻辑地址空间划分为大小相同的基本分配单元。因此逻辑地址可以由二元祖(p, o)表示,其中p为页号, o为页内偏移,假设每一页的大小为2的S次方,那么逻辑地址 = p *2 S + o.在linux环境下,可以用shell命令 getconf PAGESIZE 来查看页面的大小。
为了方便,帧 与 页的基本大小相同,因此页内偏移 等于 帧内偏移; 但页号不等于帧号。因此只需要维护页号到帧号的映射关系就行了,这就是页表的作用。
每个进程都有一个页表,每个页面对应一个页表项,页表随进程的运行状态动态变化,页表基址寄存器(page table base register)记录页表的基址。由页表基址加上页号就能得到响应的页表项,页表项里面最重要的就是帧号信息,当然还有一些其他字段,如存在位、修改位等。下面看看页式存储管理的访问过程:
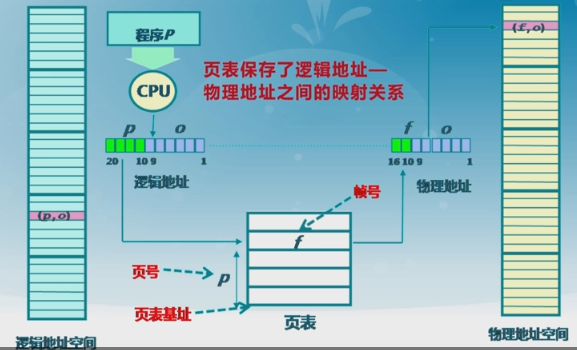
CPU计算的时候取出逻辑地址(页号, 偏移);用页号加上页表基址得到页表项,取出帧号;通过帧号和偏移,就找到了物理内存的实际地址。
从上面的描述不难想到页式存储管理的两个问题:第一,访问一个单元需要两次内存访问(先读页表项,再读数据),这是性能问题;第二,如果地址空间比较大,而页面的基本单元较小,那么一个页表的大小会很大,这个是额外空间消耗问题。为了解决这两个问题,又引入了快表(Translation look-aside buffe)、多级页面、反质页表,快表解决性能问题,后面两个解决页表大小的问题。现在的计算机都是采用页机制来进行地址转换(事实上是虚拟页式存储)。
段页式
段式、页式各有优劣段式存储在内存保护方面有优势,而页式存储在内存利用和优化转移到后备存储(即虚拟存储)方面有优势。段页式则是二者的集合,即在段式存储管理基础上 给每个段加一级页表。这样,逻辑地址就变成了三元组(s, p, o), 分别是段号、页号和页内偏移。
段页式存储管理,进程的段表项实际上存储的是该段的页表项,这样不同的段(属于不同的进程)可以指向同一个页表,这就可以共享段。
总结:
本文是操作系统存储管理的基础知识,主要介绍了分层的存储管理;cache(CPU告诉缓存)的工作原理、置换策略、写回策略;连续内存分配理论及其实例伙伴系统,内存碎片的产生;非连续存储的概念,段式、页式、段页式各自的特点,本文并不涉及虚拟存储相关知识。对于很多知识点,并没有深入,如果感兴趣,可以结合链接进一步学习。
references:
UCSD: Principles of Operating Systems
寄存器,cache、伙伴系统、内存碎片、段式页式存储管理的更多相关文章
- 操作系统之cache、伙伴系统、内存碎片、段式页式存储管理
存储管理是操作系统非常重要的功能之一,本文主要介绍操作系统存储管理的基础知识,包括缓存相关知识.连续内存分配.伙伴系统.非连续内存分配.内存碎片等,并结合linux系统对这些知识进行简单的验证.文章内 ...
- 【转帖】linux内存管理原理深入理解段式页式
linux内存管理原理深入理解段式页式 https://blog.csdn.net/h674174380/article/details/75453750 其实一直没弄明白 linux 到底是 段页式 ...
- 【av68676164(p54)】段式和段页式虚拟存储
段式存储管理 进程分段 把进程按逻辑意义划分为多个段,每段有段名,长度不定,进程由多段组成 例:一个具有代码段.数据段和堆栈段的进程 段式内存管理系统的内存分配 以段为的单位装入,每段分配连续的内存 ...
- Linux段式管理与页式管理
内存管理有2种机制:1.段式管理:2.页式管理 在80386CPU中增加了2个寄存器:1.全局性的段描述表寄存器GDTR 2.局部性的段描述表寄存器LDTR 段寄存器的高13位用于在全局或局部描述表项 ...
- 操作系统学习笔记(二) 页式映射及windbg验证方式
页式映射 本系列截图来自网络搜索及以下基本书籍: <Windows内核设计思想> <Windows内核情景分析> <WINDOWS内核原理与实现> 一个32位虚拟地 ...
- 分页式存储管理方式AND请求分页式存储管理
先说下什么是页(页面):就是将用户的程序的的地址空间分成固定大小的区域,称为”页“,或者”页面“ 之后将这些页离散的放进内存中,这样解决了内存的碎片问题 记得老师上课说了下这两个概念不能混,现在区分下 ...
- linux内核源码——内存管理:段页式内存及swap
os的内存管理大概可以分成两块:1.段页式管理(虚存)2.swap in 和 swap out 段页式管理 段式管理的图像:运行时重定位 多级页表的管理图像 块表加速 用户(程序员)希望用段,物理内 ...
- Vue单页式应用(Hash模式下)实现微信分享
前端微信分享的基本步骤: 一.绑定域名: 先登录微信公众平台进入"公众号设置"的"功能设置"里填写"JS接口安全域名".这个不多说,微信开发 ...
- c模拟 页式管理页面置换算法之FIFO
写的操作系统作业.... 放上来给需要的小伙伴 需要注意的地方: 1.该算法只涉及单进程 2.只是用c模拟FIFO的思想 FIFO思想:选择在内存中存活时间最久的页面淘汰 关于该算法我的理解: 一个进 ...
随机推荐
- 非常全的linux面试笔试题及参考答案
一.填空题: 1. 在Linux系统中,以 文件 方式访问设备 . 2. Linux内核引导时,从文件/etc/fstab 中读取要加载的文件系统. 3. Linux文件系统中每个文件用 i节点来标识 ...
- 学习笔记:mpvue开发小程序——入门
接下来可能要开发一个小程序,同事推荐使用mpvue,那么我提前熟悉下. 官网地址:http://mpvue.com/ 1.快速上手 http://mpvue.com/mpvue/quickstart/ ...
- HibernateCRUD基础框架(2)-HQL语句构造器(HqlQueryBuilder,HqlUpdateBuilder)
上篇讲述了最基本的实体类,本篇接着讲述HQL语句构造器,包括查询和更新等. 优点:通过面向对象的方式构造HQL语句,更快捷,不需要手动拼接HQL. 缺点:封装可能降低性能,只能支持常用的和较为简单的H ...
- js进阶 13-3 jquery动画显示隐藏,滑动,淡入淡出的本质是什么
js进阶 13-3 jquery动画显示隐藏,滑动,淡入淡出的本质是什么 一.总结 一句话总结:分别改变display,高度,opacity透明度这三种属性. 1.fade系列函数有哪四个? fade ...
- 9.3 Binder系统_驱动情景分析_服务获取过程
4. 服务获取过程 test_client客户端: (1)在用户态先构造name=“hello”的数据(服务的名字是hello),调用ioctl发送数据给service_manager(handle= ...
- Chrome 临时目录
mklink /J "C:\Users\%USERNAME%\AppData\Local\Google\Chrome\User Data\Default\Cache" " ...
- rabbitmq.config详细配置参数
原文:rabbitmq.config详细配置参数 rabbitmq.config详细配置参数 详细使用方法请点击:http://blog.csdn.net/Super_RD/article/detai ...
- (三)RabbitMQ消息队列-Centos7下安装RabbitMQ3.6.1
原文:(三)RabbitMQ消息队列-Centos7下安装RabbitMQ3.6.1 如果你看过前两章对RabbitMQ已经有了一定了解,现在已经摩拳擦掌,来吧动手吧! 用什么系统 本文使用的是Cen ...
- html5的float属性超详解(display,position, float)(文本流)
html5的float属性超详解(display,position, float)(文本流) 一.总结 1.文本流: 2.float和绝对定位都不占文本流的位置 3.普通流是默认定位方式,就是依次按照 ...
- Qt5 编译 & 打包依赖dll发布
十年前学C++的时候,无聊到把windows 文件夹下几乎所有的*.dll 都看过一遍.偶尔在程序运行时看到缺少 *.dll 的提示,都会直接找出来解决. 随着“开发平台”和“编译器”版本的逐年升级, ...