Python 爬虫从入门到进阶之路(八)
在之前的文章中我们介绍了一下 requests 模块,今天我们再来看一下 Python 爬虫中的正则表达的使用和 re 模块。
实际上爬虫一共就四个主要步骤:
- 明确目标 (要知道你准备在哪个范围或者网站去搜索)
- 爬 (将所有的网站的内容全部爬下来)
- 取 (去掉对我们没用处的数据)
- 处理数据(按照我们想要的方式存储和使用)
我们在之前写的爬虫程序中,都只是获取到了页面的全部内容,也就是只进行到了第2步,但是大部分的东西是我们不关心的,因此我们需要将之按我们的需要过滤和匹配出来。这时候我们就需要用到了正则表达式。
什么是正则表达式
正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
- 给定的字符串是否符合正则表达式的过滤逻辑(“匹配”);
- 通过正则表达式,从文本字符串中获取我们想要的特定部分(“过滤”)。

正则表达式匹配规则
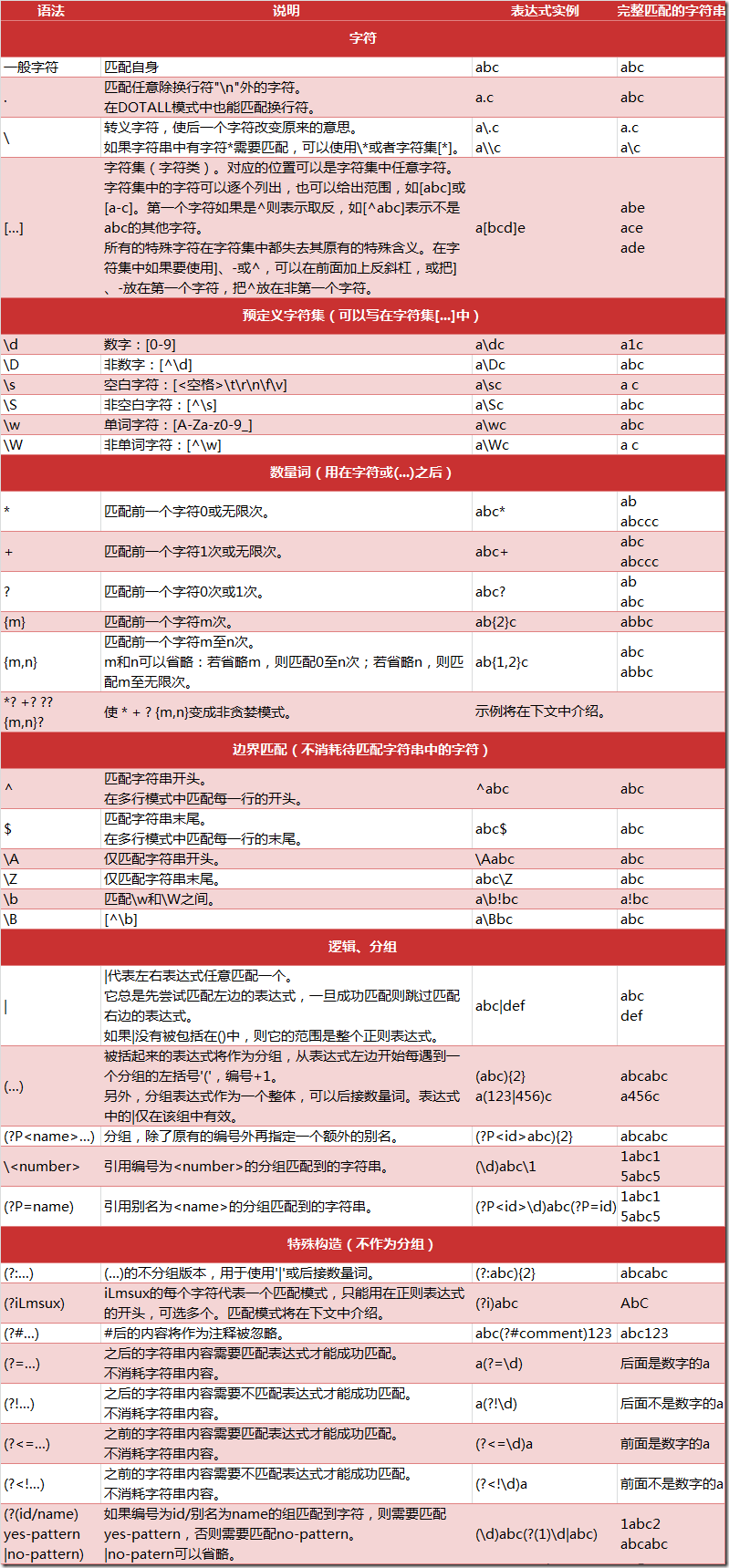
Python 的 re 模块
在 Python 中,我们可以使用内置的 re 模块来使用正则表达式。
有一点需要特别注意的是,正则表达式使用 对特殊字符进行转义,所以如果我们要使用原始字符串,只需加一个 r 前缀,如下:
r'python\t\.\tpython'
re 模块的一般使用步骤如下:
使用
compile()函数将正则表达式的字符串形式编译为一个Pattern对象通过
Pattern对象提供的一系列方法对文本进行匹配查找,获得匹配结果,一个 Match 对象。- 最后使用
Match对象提供的属性和方法获得信息,根据需要进行其他的操作
compile 函数
compile 函数用于编译正则表达式,生成一个 Pattern 对象,它的一般使用形式如下:
import re # 将正则表达式编译成 Pattern 对象
pattern = re.compile(r'\d+')
在上面,我们已将一个正则表达式编译成 Pattern 对象,接下来,我们就可以利用 pattern 的一系列方法对文本进行匹配查找了。
Pattern 对象的一些常用方法主要有:
- match 方法:从起始位置开始查找,一次匹配
- search 方法:从任何位置开始查找,一次匹配
- findall 方法:全部匹配,返回列表
- finditer 方法:全部匹配,返回迭代器
- split 方法:分割字符串,返回列表
- sub 方法:替换
match 方法
match 方法用于查找字符串的头部(也可以指定起始位置),它是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果。它的一般使用形式如下:
match(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。因此,当你不指定 pos 和 endpos 时,match 方法默认匹配字符串的头部。
当匹配成功时,返回一个 Match 对象,如果没有匹配上,则返回 None。
import re pattern = re.compile(r'\d+') # 用于匹配至少一个数字 str = 'abc123def456' p = pattern.match(str) # 查找头部,没有匹配
print(p) # None p = pattern.match(str, 2, 9) # 从'c'的位置开始匹配,没有匹配
print(p) # None p = pattern.match(str, 3, 9) # 从'4'的位置开始匹配,正好匹配, 返回一个 Match 对象
print(p) # <re.Match object; span=(3, 6), match='123'> p = p.group(0) # 可省略 0
print(p) # p = p.start(0) # 可省略 0
print(p) # p = p.end(0) # 可省略 0
print(p) # p = p.span(0) # 可省略 0
print(p) # (3, 6)
在上面,当匹配成功时返回一个 Match 对象,其中:
group([group1, …]) 方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用 group() 或 group(0);
start([group]) 方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;
- end([group]) 方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;
- span([group]) 方法返回 (start(group), end(group))。
我们再来看一下具体用法:
import re pattern = re.compile(r'([a-z]+) ([a-z]+)', re.I) # 用于匹配至少一个字母, re.I 表示忽略大小写 str = 'Hello world hello Python' p = pattern.match(str) # 查找头部,匹配成功,返回一个 Match 对象
print(p) # <re.Match object; span=(0, 11), match='Hello world'> p = p.group(0) # 返回匹配成功的整个子串
print(p) # Hello world p = p.group(1) # 返回第一个分组匹配成功的子串
print(p) # Hello
p = p.group(2) # 返回第二个分组匹配成功的子串
print(p) # world
p = p.group(3) # 不存在第三个分组
print(p) # IndexError: no such group p = p.span(0) # 返回匹配成功的整个子串的索引
print(p) # (0, 11)
p = p.span(1) # 返回第一个分组匹配成功的子串的索引
print(p) # (0, 5)
p = p.span(2) # 返回第二个分组匹配成功的子串的索引
print(p) # (6, 11)
p = p.span(3) # 不存在第三个分组
print(p) # IndexError: no such group p = p.start(0) # 返回匹配成功的整个子串的开始下标
print(p) #
p = p.end(0) # 返回匹配成功的整个子串的结束下标
print(p) #
p = p.start(1) # 返回第一个分组匹配成功的子串的开始下标
print(p) #
p = p.end(1) # 返回第一个分组匹配成功的子串的结束下标
print(p) #
p = p.start(2) # 返回第二个分组匹配成功的子串的开始下标
print(p) #
p = p.end(2) # 返回第二个分组匹配成功的子串的结束下标
print(p) #
p = p.start(3) # 返回第三个分组匹配成功的子串的开始下标
print(p) # IndexError: no such group
p = p.end(3) # 返回第三个分组匹配成功的子串的结束下标
print(p) # IndexError: no such group p = p.groups() # 等价于 (m.group(1), m.group(2), ...)
print(p) # ('Hello', 'world')
search 方法
search 方法用于查找字符串的任何位置,它也是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果,它的一般使用形式如下:
search(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。
当匹配成功时,返回一个 Match 对象,如果没有匹配上,则返回 None。
import re pattern = re.compile(r'\d+') # 用于匹配至少一个数字 str = 'abc123def456' p = pattern.search(str) # 查找头部,匹配成功,返回一个 Match 对象
print(p) # <re.Match object; span=(3, 6), match='123'> p = pattern.search(str, 1, 3) # 指定区间, 匹配失败,返回一个 None
print(p) # None p = pattern.search(str, 8, 10) # 指定区间, 匹配成功,返回一个 Match 对象
print(p) # <re.Match object; span=(9, 10), match='4'>
findall 方法
上面的 match 和 search 方法都是一次匹配,只要找到了一个匹配的结果就返回。然而,在大多数时候,我们需要搜索整个字符串,获得所有匹配的结果。
findall 方法的使用形式如下:
findall(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。
findall 以列表形式返回全部能匹配的子串,如果没有匹配,则返回一个空列表。
import re pattern = re.compile(r'\d+') # 用于匹配至少一个数字 str = 'abc123def456' p = pattern.findall(str) # 返回一个列表对象
print(p) # ['123', '456'] p = pattern.findall(str, 1, 3) # 返回一个列表对象
print(p) # []
finditer 方法
finditer 方法的行为跟 findall 的行为类似,也是搜索整个字符串,获得所有匹配的结果。但它返回一个顺序访问每一个匹配结果(Match 对象)的迭代器。
import re pattern = re.compile(r'\d+') # 用于匹配至少一个数字 str = 'abc123def456' p = pattern.finditer(str) # 返回一个 Match 对象
print(p) # <callable_iterator object at 0x1054eb400> p = pattern.finditer(str, 1, 3) # 返回一个 Match 对象
print(p) # <callable_iterator object at 0x10552e358>
在实际中我们很少应用 finditer 方法,因为我们还需要对获取的 Match 对象进行进一步处理,如循环,group() 等来获取直观数据。
split 方法
split 方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:
split(string[, maxsplit])
其中,maxsplit 用于指定最大分割次数,不指定将全部分割。
import re pattern = re.compile(r'[\s\,\;]+') # 匹配至少一个空格和 ; str = 'a,b;; c d' p = pattern.split(str)
print(p) # ['a', 'b', 'c', 'd']
sub 方法
sub 方法用于替换。它的使用形式如下:
sub(repl, string[, count])
其中,repl 可以是字符串也可以是一个函数:
如果 repl 是字符串,则会使用 repl 去替换字符串每一个匹配的子串,并返回替换后的字符串,另外,repl 还可以使用 id 的形式来引用分组,但不能使用编号 0;
如果 repl 是函数,这个方法应当只接受一个参数(Match 对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
- count 用于指定最多替换次数,不指定时全部替换。
import re pattern = re.compile(r'(\w+) (\w+)', re.I) # \w = [A-Za-z0-9] str = 'Hello 123, hello 456' p = pattern.sub(r'hello World', str) # 使用 'hello World' 替换 'Hello 123' 和 'hello 456'
print(p) # hello World, hello World p = pattern.sub(r'hello World', str, 1) # 使用 'hello World' 替换 'Hello 123', 1 表示最多替换一次
print(p) # hello World, hello 456
Python 爬虫从入门到进阶之路(八)的更多相关文章
- Python 爬虫从入门到进阶之路(二)
上一篇文章我们对爬虫有了一个初步认识,本篇文章我们开始学习 Python 爬虫实例. 在 Python 中有很多库可以用来抓取网页,其中内置了 urllib 模块,该模块就能实现我们基本的网页爬取. ...
- Python 爬虫从入门到进阶之路(六)
在之前的文章中我们介绍了一下 opener 应用中的 ProxyHandler 处理器(代理设置),本篇文章我们再来看一下 opener 中的 Cookie 的使用. Cookie 是指某些网站服务器 ...
- Python 爬虫从入门到进阶之路(九)
之前的文章我们介绍了一下 Python 中的正则表达式和与爬虫正则相关的 re 模块,本章我们就利用正则表达式和 re 模块来做一个案例,爬取<糗事百科>的糗事并存储到本地. 我们要爬取的 ...
- Python 爬虫从入门到进阶之路(十二)
之前的文章我们介绍了 re 模块和 lxml 模块来做爬虫,本章我们再来看一个 bs4 模块来做爬虫. 和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也 ...
- Python 爬虫从入门到进阶之路(十五)
之前的文章我们介绍了一下 Python 的 json 模块,本章我们就介绍一下之前根据 Xpath 模块做的爬取<糗事百科>的糗事进行丰富和完善. 在 Xpath 模块的爬取糗百的案例中我 ...
- Python 爬虫从入门到进阶之路(十六)
之前的文章我们介绍了几种可以爬取网站信息的模块,并根据这些模块爬取了<糗事百科>的糗百内容,本章我们来看一下用于专门爬取网站信息的框架 Scrapy. Scrapy是用纯Python实现一 ...
- Python 爬虫从入门到进阶之路(十七)
在之前的文章中我们介绍了 scrapy 框架并给予 scrapy 框架写了一个爬虫来爬取<糗事百科>的糗事,本章我们继续说一下 scrapy 框架并对之前的糗百爬虫做一下优化和丰富. 在上 ...
- Python 爬虫从入门到进阶之路(五)
在之前的文章中我们带入了 opener 方法,接下来我们看一下 opener 应用中的 ProxyHandler 处理器(代理设置). 使用代理IP,这是爬虫/反爬虫的第二大招,通常也是最好用的. 很 ...
- Python 爬虫从入门到进阶之路(七)
在之前的文章中我们一直用到的库是 urllib.request,该库已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 “HTTP for Hum ...
随机推荐
- 概率图模型(PGM) —— 贝叶斯网络(Bayesian Network)
概率图模型是图论与概率方法的结合产物.Probabilistic graphical models are a joint probability distribution defined over ...
- expdp&impdp
1 创建逻辑文件夹,该命令不会在操作系统创建真正的文件夹,最好以system等管理员创建. create directory dpdata1 as '/opt/oracle/dpdata1'; c ...
- 性能测试以及对redis
Ignite性能测试以及对redis的对比 测试方法 为了对Ignite做一个基本了解,做了一个性能测试,测试方法也比较简单主要是针对client模式,因为这种方法和使用redis的方式特别像.测 ...
- VC中引用第三方库,常见的库冲突问题
Q:VC中引用第三方库,常见的库冲突问题 环境:[1]VS2008 [2]WinXP SP3 A1(方法一): [S1]第三方库(Binary形式的)如果同主程序冲突,则下载第三方库的源码[S2]保持 ...
- Spring MVC 专题
Spring静态资源路径是指系统可以直接访问的路径,且路径下的所有文件均可被用户直接读取.在Springboot中默认的静态资源路径有:classpath:/META-INF/resources/,c ...
- Sync Framework Toolkit 开源库
Sync Framework Toolkit构建在Sync Framework 2.1之上,使用OData在所有平台或客户端——包括Windows Phone 7.Silverlight.Window ...
- Linux技术学习路线图
- EF延迟加载LazyLoading
优点 只在需要的时候加载数据,不需要预先计划,避免了各种复杂的外连接.索引.视图操作带来的低效率问题 缺陷:多次与DB交互,性能降低 阻止延迟加载解决方案:1.ToList(),返回的东西是个内存级的 ...
- 【wpf】在win10系统上弹出toast和notification
原文:[wpf]在win10系统上弹出toast和notification 老规矩,先看效果 右下角的notification: 操作中心的notification: 整体效果: 前提条件 1.需要在 ...
- liunx 系统 一键安装
本文转自:http://hi.baidu.com/iamcyh/item/e777eb81ba90ed5a26ebd9b0 linux VPS环境(MySQL/Apache/PHP/Nginx)一键安 ...