Sparse Coding: Autoencoder Interpretation
稀疏编码
在稀疏自编码算法中,我们试着学习得到一组权重参数 W(以及相应的截距 b),通过这些参数可以使我们得到稀疏特征向量 σ(Wx + b) ,这些特征向量对于重构输入样本非常有用。
稀疏编码可以看作是稀疏自编码方法的一个变形,该方法试图直接学习数据的特征集。利用与此特征集相应的基向量,将学习得到的特征集从特征空间转换到样本数据空间,这样我们就可以用学习得到的特征集重构样本数据。
确切地说,在稀疏编码算法中,有样本数据 x 供我们进行特征学习。特别是,学习一个用于表示样本数据的稀疏特征集 s, 和一个将特征集从特征空间转换到样本数据空间的基向量 A, 我们可以构建如下目标函数:
(
是x的Lk范数,等价于
。L2 范数即大家熟知的欧几里得范数,L1 范数是向量元素的绝对值之和)
上式前第一部分是利用基向量将特征集重构为样本数据所产生的误差,第二部分为稀疏性惩罚项(sparsity penalty term),用于保证特征集的稀疏性。
但是,如目标函数所示,它的约束性并不强――按常数比例缩放A的同时再按这个常数的倒数缩放 s,结果不会改变误差大小,却会减少稀疏代价(表达式第二项)的值。因此,需要为 A 中每项 Aj 增加额外约束
。问题变为:
遗憾的是,因为目标函数并不是一个凸函数,所以不能用梯度方法解决这个优化问题。但是,在给定 A 的情况下,最小化 J(A,s) 求解 s 是凸的。同理,给定 s 最小化 J(A,s) 求解 A 也是凸的。这表明,可以通过交替固定 s和 A 分别求解 A和s。实践表明,这一策略取得的效果非常好。
但是,以上表达式带来了另一个难题:不能用简单的梯度方法来实现约束条件
。因此在实际问题中,此约束条件还不足以成为“权重衰变”("weight decay")项以保证 A 的每一项值够小。这样我们就得到一个新的目标函数:
(注意上式中第三项,
等价于
,是A各项的平方和)
这一目标函数带来了最后一个问题,即 L1 范数在 0 点处不可微影响了梯度方法的应用。尽管可以通过其他非梯度下降方法避开这一问题,但是本文通过使用近似值“平滑” L1 范数的方法解决此难题。使用
代替
, 对 L1 范数进行平滑,其中 ε 是“平滑参数”("smoothing parameter")或者“稀疏参数”("sparsity parameter") (如果 ε远大于x, 则 x + ε 的值由 ε 主导,其平方根近似于ε)。在下文提及拓扑稀疏编码时,“平滑”会派上用场。
因此,最终的目标函数是:
(
是
的简写)
该目标函数可以通过以下过程迭代优化:
- 随机初始化A
- 重复以下步骤直至收敛:
- 根据上一步给定的A,求解能够最小化J(A,s)的s
- 根据上一步得到的s,,求解能够最小化J(A,s)的A
观察修改后的目标函数 J(A,s),给定 s 的条件下,目标函数可以简化为
(因为 s 的 L1 范式不是 A 的函数,所以可以忽略)。简化后的目标函数是一个关于 A 的简单二次项式,因此对 A 求导是很容易的。这种求导的一种快捷方法是矩阵微积分。遗憾的是,在给定 A 的条件下,目标函数却不具备这样的求导方法,因此目标函数的最小化步骤只能用梯度下降或其他类似的最优化方法。
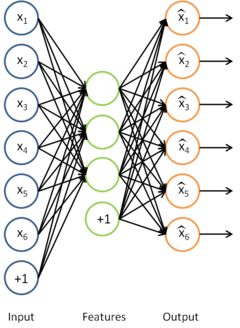
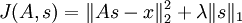
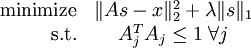
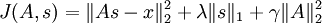
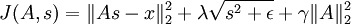
拓扑稀疏编码
通过稀疏编码,我们能够得到一组用于表示样本数据的特征集。我们希望学习到的特征也具有这样“拓扑秩序”的性质。这对于我们要学习的特征意味着什么呢?直观的讲,如果“相邻”的特征是“相似”的,就意味着如果某个特征被激活,那么与之相邻的特征也将随之被激活。
具体而言,假设我们(随意地)将特征组织成一个方阵。我们就希望矩阵中相邻的特征是相似的。实现这一点的方法是将相邻特征按经过平滑的L1范式惩罚进行分组,如果按 3x3 方阵分组,则用
代替
, 其分组通常是重合的,因此从第 1 行第 1 列开始的 3x3 区域是一个分组,从第 1 行第 2 列开始的 3x3 区域是另一个分组,以此类推。最终,这样的分组会形成环绕,就好像这个矩阵是个环形曲面,所以每个特征都以同样的次数进行了分组。 于是,将经过平滑的所有分组的 L1 惩罚值之和代替经过平滑的 L1 惩罚值,得到新的目标函数如下:
实际上,“分组”可以通过“分组矩阵”V 完成,于是矩阵 V 的第 r 行标识了哪些特征被分到第 r 组中,即如果第 r 组包含特征 c 则Vr,c = 1。通过分组矩阵实现分组使得梯度的计算更加直观,使用此分组矩阵,目标函数被重写为:
该目标函数能够使用之前部分提到的迭代方法进行求解。拓扑稀疏编码得到的特征与稀疏编码得到的类似,只是拓扑稀疏编码得到的特征是以某种方式有“秩序”排列的。
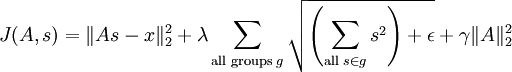
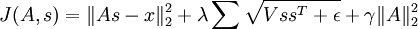
稀疏编码实践
如上所述,虽然稀疏编码背后的理论十分简单,但是要写出准确无误的实现代码并能快速又恰到好处地收敛到最优值,则需要一定的技巧。
回顾一下之前提到的简单迭代算法:
- 随机初始化A
- 重复以下步骤直至收敛到最优值:
- 根据上一步给定的A,求解能够最小化J(A,s)的s
- 根据上一步得到的s,求解能够最小化J(A,s)的A
这样信手拈来地执行这个算法,结果并不会令人满意,即使确实得到了某些结果。以下是两种更快更优化的收敛技巧:
- 将样本分批为“迷你块”
- 良好的s初始值
将样本分批为“迷你块”
如果你一次性在大规模数据集(比如,有10000 个patch)上执行简单的迭代算法,你会发现每次迭代都要花很长时间,也因此这算法要花好长时间才能达到收敛结果。为了提高收敛速度,可以选择在迷你块上运行该算法。每次迭代的时候,不是在所有的 10000 个 patchs 上执行该算法,而是使用迷你块,即从 10000 个 patch 中随机选出 2000 个 patch,再在这个迷你块上执行这个算法。这样就可以做到一石二鸟――第一,提高了每次迭代的速度,因为现在每次迭代只在 2000 个 patch 上执行而不是 10000个;第二,也是更重要的,它提高了收敛的速度
良好的s初始值
另一个能获得更快速更优化收敛的重要技巧是:在给定 A 的条件下,根据目标函数使用梯度下降(或其他方法)求解 s 之前找到良好的特征矩阵 s 的初始值。实际上,除非在优化 A 的最优值前已找到一个最佳矩阵 s,不然每次迭代过程中随机初始化 s 值会导致很差的收敛效果。下面给出一个初始化 s 的较好方法:
- 令
(x 是迷你块中patches的矩阵表示)
- s中的每个特征(s的每一列),除以其在A中对应基向量的范数。即,如果sr,c表示第c个样本的第r个特征,则Ac表示A中的第c个基向量,则令
无疑,这样的初始化有助于算法的改进,因为上述的第一步希望找到满足
的矩阵 s;第二步对 s 作规范化处理是为了保持较小的稀疏惩罚值。这也表明,只采用上述步骤的某一步而不是两步对 s 做初始化处理将严重影响算法性能。(TODO: 此链接将会对为什么这样的初始化能改进算法作出更详细的解释)
可运行算法
有了以上两种技巧,稀疏编码算法修改如下:
- 随机初始化A
- 重复以下步骤直至收敛
- 随机选取一个有2000个patches的迷你块
- 如上所述,初始化s
- 根据上一步给定的A,求解能够最小化J(A,s)的s
- 根据上一步得到的s,求解能够最小化J(A,s)的A
通过上述方法,可以相对快速的得到局部最优解。
Sparse Coding: Autoencoder Interpretation的更多相关文章
- Study notes for Sparse Coding
Sparse Coding Sparse coding is a class of unsupervised methods for learning sets of over-complete ba ...
- 理解sparse coding
理解sparse coding 稀疏编码系列: (一)----Spatial Pyramid 小结 (二)----图像的稀疏表示——ScSPM和LLC的总结 (三)----理解sparse codin ...
- sparse coding
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-04 ...
- [Paper] **Before GAN: sparse coding
读罢[UFLDL] ConvNet,为了知识体系的完整,看来需要实战几篇论文深入理解一些原理. 如下是未来博文系列的初步设想,为了hold住 GAN而必备的知识体系,也是必经之路. [Paper] B ...
- 稀疏编码(Sparse Coding)的前世今生(一) 转自http://blog.csdn.net/marvin521/article/details/8980853
稀疏编码来源于神经科学,计算机科学和机器学习领域一般一开始就从稀疏编码算法讲起,上来就是找基向量(超完备基),但是我觉得其源头也比较有意思,知道根基的情况下,拓展其应用也比较有底气.哲学.神经科学.计 ...
- sparse coding稀疏表达入门
最近在看sparse and redundant representations这本书,进度比较慢,不过力争看过的都懂,不把时间浪费掉.才看完了不到3页吧,书上基本给出了稀疏表达的概念以及传统的求法. ...
- sparse representation 与sparse coding 的区别的观点
@G_Auss: 一直觉得以稀疏为目标的无监督学习没有道理.稀疏表示是生物神经系统的一个特性,但它究竟只是神经系统完成任务的副产物,还是一个优化目标,没有相关理论,这里有推理漏洞.实际上,稀疏目标只能 ...
- 稀疏编码(Sparse Coding)的前世今生(二)
为了更进一步的清晰理解大脑皮层对信号编码的工作机制(策略),须要把他们转成数学语言,由于数学语言作为一种严谨的语言,能够利用它推导出期望和要寻找的程式.本节就使用概率推理(bayes views)的方 ...
- 转载 deep learning:八(SparseCoding稀疏编码)
转载 http://blog.sina.com.cn/s/blog_4a1853330102v0mr.html Sparse coding: 本节将简单介绍下sparse coding(稀疏编码),因 ...
随机推荐
- [HNOI2008]水平可见直线 单调栈
题目描述:在xoy直角坐标平面上有n条直线L1,L2,...Ln,若在y值为正无穷大处往下看,能见到Li的某个子线段,则称Li为可见的,否则Li为被覆盖的.例如,对于直线:L1:y=x; L2:y=- ...
- 使得nginx支持pathinfo访问模式
原理: 任意创建一个 in.php 文件: <?php echo '<pre>'; ...
- NodeJS学习笔记 (31)定时器-timers
https://github.com/chyingp/nodejs-learning-guide
- ArchLinux 音乐播放客户端ncmpcpp和服务端mpd的配置
Ncmcpp是一个mpd客户端,它提供了很多方便的操作 MPD是一个服务器-客户端架构的音频播放器.功能包括音频播放, 播放列表管理和音乐库维护,所有功能占用的资源都很少. --取自 wiki.arc ...
- django-xadmin定制之列表页searchbar placeholder
环境:xadmin-for-python3 python3.5.2 django1.9.12 列表页的searchbar如果提供的可搜索字段,都没提示哪个字段可搜索,很不友好,本次定制主要增加inpu ...
- Exchange2003迁移2010DAG的权限问题
exchange2010无法删除用户.在2010的控制台中新建一个通讯组.然后将它删除就会报告下面错误. MicrosoftExchange 错误:无法对对象"test"执行&qu ...
- HIT 2255 Not Fibonacci(矩阵高速幂)
#include <iostream> #include <cstdio> #include <cstring> using namespace std; cons ...
- 18.angularJS服务
转自:https://www.cnblogs.com/best/tag/Angular/ 服务 AngularJS功能最基本的组件之一是服务(Service).服务为你的应用提供基于任务的功能.服务可 ...
- 21.MFC进制转换工具
相关代码:链接:https://pan.baidu.com/s/1pKVVUZL 密码:e3vf #include <stdlib.h> #include <stdio.h> ...
- HDU 4349 Xiao Ming's Hope 组合数学
题意:给你n,问在C(n,1),C(n,2)...C(n,n)中有多少个奇数. 比赛的时候打表看出规律,这里给一个数学上的说明. Lucas定理:A,B非负整数,p是质数,A,B化为p进制分别为a[n ...